---
layout: post
title: Knowledge Base
subtitle: Codex 个人助理沉淀
date: 2026-07-28 08:17:47 -0400
tags:
- 个人助理
- 知识库
---
来源:notes/knowledge_base.md
Knowledge Base
People
Projects
- 2026 年 6 月回顾:
notes/projects/monthly_reviews/01_2026年06月回顾.md,基于 daily log、任务清单和 6 月正式笔记,提炼工作推进、投资纪律、内容沉淀三条主线,并明确 7 月应补的闭环动作。
- 域控芯片装机量排名图项目:
notes/projects/domain_chip_installation_rankings/01_域控芯片装机量排名图项目说明.md,归档 NE时代 2026年1-2月、3月、4月、5月域控芯片装机量榜单数据、生成脚本、排名表格图和后续新增月份的复用流程。
- 个人助理笔记同步到 GitHub Pages 博客流程:
notes/projects/github_pages_sync/01_个人助理笔记同步到博客流程.md,记录将 codex_personal_assistant/notes 导入 andywu1998.github.io 的一键脚本、执行流程、commit/push 规则和 2026-06-09 验证结果。
- VSCode 风格博客 Reader 工作模式方案:
notes/projects/github_pages_sync/02_VSCode风格博客Reader工作模式方案.md,记录为 GitHub Pages 博客新增 /reader/ 工作模式的目标、方案、数据生成脚本、前端交互、布局修正、部署提交和后续维护动作。
- flomo 整合进个人助理方案:
notes/projects/flomo_integration/01_flomo_整合进个人助理方案.md,核实 flomo Incoming Webhook、URL Scheme、MCP、HTML 导出能力,并设计接入个人助理和飞书多维表格的落地方案。
- 个人助理多维表格同步方案:
notes/projects/feishu_base_sync/01_个人助理多维表格同步方案.md,记录 lark-cli Base 能力验证、当前权限缺口、可入表内容和书籍 Markdown 上传回填方案。
- 个人助理多维表格同步结果(2026-06-04):
notes/projects/feishu_base_sync/02_同步结果_20260604.md,记录正式 Base、表 ID、记录数和已上传书籍 Markdown 链接。
- 个人助理飞书多维表格同步 SOP:
notes/projects/feishu_base_sync/03_个人助理飞书同步SOP.md,沉淀授权、建 Base、建表、上传 Markdown、写记录和 URL 字段修正的完整操作流程。
- cc-connect 使用手册:
notes/projects/cc-connect/01_cc_connect_使用手册.md,整理本机 cc-connect 项目的安装、配置、运行、平台接入、定时任务、附件回传和排障流程。
- 长音频转写与博客同步流程:
notes/projects/audio_transcription_workflow/01_长音频转写与博客同步流程.md,记录收到 MP3 后从环境检查、FunASR/SenseVoiceSmall 安装、长音频切片转写、逐字稿格式化、飞书同步到 GitHub Pages 博客发布的完整流程和踩坑。
Preferences
- 地平线机器人 2026-06-10 股东周年大会逐字稿:
notes/projects/地平线机器人20260610股东大会/01_逐字稿.md,记录 AGM 开场、12 项决议、股东问答、HSD/自研芯片/竞争格局/回购/FSD 入华等管理层表述。
- 地平线机器人 2026-06-10 股东周年大会公众号版:
notes/projects/地平线机器人20260610股东大会/02_公众号版_从股东大会看地平线的关键问题.md,基于股东大会逐字稿整理成公众号文章,聚焦车企自研芯片、平台定位、竞争格局、股价回购、HSD 出货、研发投入和 FSD 入华。
References
- 股海渡梦雪球发言与持仓态度侧写:
notes/topics/xueqiu_investor_profiles/01_股海渡梦雪球发言与持仓态度侧写.md,基于雪球公开可检索内容,梳理“股海渡梦”围绕黑芝麻智能、地平线机器人等港股科技标的的持仓主线、核心观点、阶段性态度和情绪变化。
- 大众在中国的合资版图梳理:
notes/topics/volkswagen_china/01_大众在中国的合资版图梳理.md,梳理大众集团中国、上汽大众、一汽-大众、大众安徽、奥迪一汽新能源、SAIC 奥迪和小鹏合作之间的关系,解释南北大众与新能源转型平台的分工。
- 百度自动驾驶旧将六年后复盘:
notes/topics/autonomous_driving_baidu_alumni/01_百度自动驾驶旧将六年后复盘.md,基于 2021 年“前百度人打下中国自动驾驶半壁江山”一文,回看地平线、小马智行、文远知行、Momenta、黑芝麻智能、毫末智行、中智行、DeepMap 等公司截至 2026 年的分化。
- 时间使用方式决定人生结构:
notes/topics/time_management/01_时间使用方式决定人生结构.md,记录“如果时间使用方式不变,人生轨道很难改变”的时间管理感悟,强调时间是人生底层资源,管理时间就是管理人生结构。
- 10小时计划:
notes/topics/time_management/02_10小时计划.md,记录通过地铁触发器、整点回顾和周度复盘,把上班日 10 小时主动分配给工作、阅读和创作的时间管理方案。
- 真正的价值投资:知乎原文排版版:
notes/topics/value_investing/02_真正的价值投资_知乎原文排版版.md,保留知乎作者 Michael 原文内容,仅增加标题和换行,便于阅读与引用。
- 真正的价值投资不是被套后的长期持有:
notes/topics/value_investing/01_真正的价值投资不是被套后的长期持有.md,整理知乎作者 Michael 关于真价投和伪价投的区分,提炼选标的、等好价、控仓位、跟踪逻辑和按基本面止损的投资纪律。
- 趋势交易与基本面投资的信号错配:
notes/topics/value_investing/03_趋势交易与基本面投资的信号错配.md,记录 2025 年以来多轮下跌后拉回带来的执念,复盘上涨时趋势止盈、下跌时用基本面利好硬抗的信号混用问题。
- 主动专注地处理事情:
notes/topics/active_attention/01_主动专注地处理事情.md,记录把微信、炒股、放松都主动定义成独立事项来处理的方法论,强调目的、时间边界、行动和记录。
- 肉身梭哈与注意力梭哈:
notes/topics/active_attention/02_肉身梭哈与注意力梭哈.md,记录科技从业者职业选择与公司股价周期的绑定,以及把注意力长期押注在早期公司研究、内容创作和认知网络上的方法。
- 微信作为信息源的注意力边界:
notes/topics/active_attention/03_微信作为信息源的注意力边界.md,结合《How to Break Up with Your Phone》整理微信信息源、回复等待、群聊分支和注意力边界,提出发送模式、收件箱模式、WWW 三问和微信 3 分钟回复法。
- 卓驭科技公司研究:
notes/topics/zhuoyu_technology/01_卓驭科技公司研究.md,梳理原大疆车载业务独立后的历史背景、创始/高管线索、客户、融资、技术路线和待验证风险。
- MQB 平台介绍:
notes/topics/automotive_platforms/MQB平台介绍.md,介绍大众集团横置发动机模块化平台的定义、工程思想、优点、局限及与 MEB/PPE 等平台的关系。
- 地平线跌破 5 元后的投资灵感:
notes/topics/horizon_robotics/01_地平线跌破5元后的投资灵感.md,记录地平线股价跌破 5 元引发的长期跟踪、看懂企业、判断虚高与错杀的文章素材。
- 地平线仓位管理与叙事反转等待:
notes/topics/horizon_robotics/02_地平线仓位管理与叙事反转等待_原文.md,原文记录 3 月降仓位、右侧博弈失败、集中现金、等待 BYD 芯片财报验证、管理层沟通判断和叙事反转前的仓位管理。
- 地平线 4.5 亿美元零息可转债定价公告解读:
notes/topics/horizon_robotics/03_地平线450百万美元零息可转债定价公告解读.md,串联 2026-07-22 的 CARIAD 借款修订和 2026-07-23 的新可转债定价公告,提炼融资结构、现金用途、转股价变化和潜在摊薄从约 4.9% 降至约 3.9% 的核心结论。
- 地平线余凯:技术从来没有成为过护城河:
notes/topics/horizon_robotics/04_余凯技术从来没有成为过护城河_原文.md,保存余凯关于科技创业、组织文化、智能汽车路径和“技术不是护城河,生态与组织才是长期壁垒”的 76 条商业思考原文。
- 地瓜机器人开发工程师岗位学习路线:
notes/topics/robotics_job_prep/01_地瓜机器人开发工程师岗位学习路线.md,基于岗位截图拆解机器人应用开发、ROS2、感知导航控制、边缘部署、VLM/VLA/Agent、仿真和技术输出能力,并附上可直接学习的官方教程、博客和视频链接。
Reading Notes
- 高盛 2026-05-19 地平线机器人研报详细解读:
notes/books/Horizon Robotics 2026-05-19 Goldman Sachs/01_详细解读.md,基于 Goldman Sachs 2026-05-19 会议纪要式研报,梳理 NOA 下沉、AD 芯片 ASP 提升、Starry + KaKaClaw 舱驾一体平台叙事、远期 EBITDA 估值假设和主要验证项。
- 高盛 2026-05-19 地平线机器人 PDF 全文转换稿:
notes/books/Horizon Robotics 2026-05-19 Goldman Sachs/source_materials/pdf_full_text.md,由用户上传 PDF 转换而来,作为后续研究地平线机器人 NOA 渗透、舱驾一体方案和 sell-side 观点差异的原始材料。
- Momenta Global 2026-06-23 PHIP 详细解读:
notes/books/Momenta Global 2026-06-23 PHIP/01_详细解读.md,基于 Momenta Global Limited 2026-06-23 港股聆讯后资料集,梳理“一个飞轮,两条腿”业务模式、城市 NOA 商业化进展、收入与毛利率拐点、亏损质量改善、客户集中度和 Robotaxi 监管风险。
- Momenta Global 2026-06-23 PHIP PDF 全文转换稿:
notes/books/Momenta Global 2026-06-23 PHIP/source_materials/pdf_full_text.md,由 HKEX 披露 PDF 转换而来,作为后续研究 Momenta、城市 NOA 和 Robotaxi 商业化路径的原始材料。
- BERT 详细解读:
notes/books/BERT/01_详细解读.md,单独梳理 BERT 的双向 Transformer encoder、MLM/NSP 预训练、fine-tuning 范式、与 GPT/ELMo 的区别和工程启发。
- BERT PDF 与全文转换稿:
notes/books/BERT/source_materials/README.md,记录 BERT 论文的 arXiv 来源、PDF 原文和全文 Markdown 路径。
- Transformer Papers 详细解读:
notes/books/Transformer Papers/01_详细解读.md,梳理 Attention Is All You Need、BERT、GPT-2、Transformer-XL、T5、ViT 六篇论文的技术主线、横向对比和学习计划。
- Transformer Papers PDF 与全文转换稿:
notes/books/Transformer Papers/source_materials/README.md,记录六篇核心 Transformer 论文的下载来源、PDF 原文和全文 Markdown 路径。
- 《为什么精英都是时间控》:
notes/books/为什么精英都是时间控/01_内容全梳理.md
- 《为什么精英都是时间控》内容全梳理(基于 EPUB 新版):
notes/books/为什么精英都是时间控/01_内容全梳理_基于EPUB新版.md
- 《为什么精英都是时间控》方法卡片:
notes/books/为什么精英都是时间控/02_方法卡片.md
- 《为什么精英都是时间控》EPUB 全文转换稿:
notes/books/为什么精英都是时间控/source_materials/epub_full_text.md,由用户上传 EPUB 转换而来,作为后续精读和重建笔记的原始材料。
- 《How to Break Up with Your Phone》内容全梳理:
notes/books/How to Break Up with Your Phone/01_内容全梳理.md,基于 EPUB 转换稿整理的中文结构化分析。
- 《How to Break Up with Your Phone》方法卡片:
notes/books/How to Break Up with Your Phone/02_方法卡片.md,将手机关系重建方法转成个人助理可执行规则。
- 《How to Break Up with Your Phone》EPUB 全文转换稿:
notes/books/How to Break Up with Your Phone/source_materials/epub_full_text.md,由用户上传 EPUB 转换而来,作为后续精读和计划拆解的原始材料。
- 《Deep Work》内容全梳理:
notes/books/Deep Work/01_内容全梳理.md,基于 MOBI 转换稿整理的中文结构化分析,聚焦深度工作假说、四条规则和个人助理落地。
- 《Deep Work》方法卡片:
notes/books/Deep Work/02_方法卡片.md,将深度工作方法转成每日专注块、生产性冥想、工具审计和停工仪式等可执行规则。
- 《Deep Work》MOBI 全文转换稿:
notes/books/Deep Work/source_materials/mobi_full_text.md,由用户上传 MOBI 转换而来,作为后续精读和计划拆解的本地原始材料。
- 《Urban Mindfulness》内容全梳理:
notes/books/Urban Mindfulness/01_内容全梳理.md,基于 EPUB 转换稿整理的中文结构化分析,聚焦城市生活中的正念练习。
- 《Urban Mindfulness》方法卡片:
notes/books/Urban Mindfulness/02_方法卡片.md,将城市正念转成通勤、等待、噪音、消息和公共情绪的可执行规则。
- 《Urban Mindfulness》EPUB 全文转换稿:
notes/books/Urban Mindfulness/source_materials/epub_full_text.md,由用户上传 EPUB 转换而来,作为后续精读和计划拆解的本地原始材料。
- 《Elon Musk》内容全梳理:
notes/books/Elon Musk/01_内容全梳理.md,基于 EPUB 转换稿整理的中文结构化分析,聚焦第一性原理、极限压强、制造、组织和代价。
- 《Elon Musk》方法卡片:
notes/books/Elon Musk/02_方法卡片.md,将传记中的创业和工程管理方法转成第一性原理、删除优先、危机模式边界等可执行规则。
- 《Elon Musk》EPUB 全文转换稿:
notes/books/Elon Musk/source_materials/epub_full_text.md,由用户上传 EPUB 转换而来,作为后续精读和计划拆解的本地原始材料。
- 《Elon Musk》早年经历解读:
notes/books/Elon Musk/06_早年经历_痛苦孤独与高强度生存模式解读.md,基于 EPUB 转换稿解读马斯克童年痛苦、孤独、父亲创伤和高强度生存模式如何影响后续管理与决策。
- 《Elon Musk》迁移与早期创业解读:
notes/books/Elon Musk/07_迁移与早期创业_从逃离南非到互联网浪潮解读.md,基于 EPUB 转换稿解读马斯克从南非到加拿大、Queen’s、Penn、硅谷、Zip2、X.com/PayPal 的早期创业路径和控制权经验。
- 《Elon Musk》SpaceX 第一性原理解读:
notes/books/Elon Musk/08_SpaceX_第一性原理打穿高壁垒行业解读.md,基于 EPUB 转换稿解读 SpaceX 早期如何用第一性原理、垂直整合、快速试错、固定价格合同和极限执行打穿商业航天高壁垒。
- 《纳瓦尔宝典》内容全梳理:
notes/books/纳瓦尔宝典/01_内容全梳理.md,基于博客反向同步回来的正文占位版,整理财富、判断力、幸福与长期主义的核心结构,后续可继续补充摘录和方法卡片。
- Horizon Robotics 2026 Bernstein 详细解读:
notes/books/Horizon Robotics 2026 Bernstein/01_详细解读.md,基于 Bernstein 2026-06-02 地平线机器人研报,梳理主机厂自研芯片压力、IP 授权模式、2026 年交付节奏、估值、反方风险和后续跟踪动作。
- Horizon Robotics 2026 Bernstein 全文翻译:
notes/books/Horizon Robotics 2026 Bernstein/02_全文翻译.md,将 Bernstein 2026-06-02 地平线机器人研报全文翻译为中文,便于后续阅读和引用。
- Horizon Robotics 2026 Bernstein 公众号版:
notes/books/Horizon Robotics 2026 Bernstein/03_公众号版_主机厂自研芯片压力下的地平线.md,基于研报第 1-6 页整理成面向公众号阅读的文章,聚焦主机厂自研芯片、ARM + Android 模式、2026 年前低后高节奏、华为竞争和 IP 授权下的单车毛利风险。
- Horizon Robotics 2026 Bernstein PDF 全文转换稿:
notes/books/Horizon Robotics 2026 Bernstein/source_materials/pdf_full_text.md,由用户上传 PDF 转换而来,作为后续研究地平线机器人和智能驾驶芯片产业链的原始材料。
- 瑞银 2026-05-27 地平线机器人研报详细解读:
notes/books/Horizon Robotics 2026-05-27 UBS/01_详细解读.md,基于公开转载摘要和本地既有引用,梳理瑞银下调 2026-2028 年收入预测、维持买入和目标价 10 港元的逻辑,并标注原始 PDF 待补。
- 摩根士丹利 2026-05-29 地平线机器人研报详细解读:
notes/books/Horizon Robotics 2026-05-29 Morgan Stanley/01_详细解读.md,基于用户提供 PDF 原文,梳理大摩对主机厂自研芯片、BPU IP 授权、HSD 软件带动、2026 年增长压力、DCF 估值和关键风险的判断。
- 摩根士丹利 2026-05-29 地平线机器人 PDF 全文转换稿:
notes/books/Horizon Robotics 2026-05-29 Morgan Stanley/source_materials/pdf_full_text.md,由用户上传 PDF 转换而来,作为后续研究地平线机器人和智能驾驶芯片商业模式切换的原始材料。
- 伯恩斯坦 2026-06-02 地平线机器人研报详细解读:
notes/books/Horizon Robotics 2026-06-02 Bernstein/01_详细解读.md,在独立目录中基于本地 PDF 全文重写解读,聚焦主机厂自研芯片、ARM + Android、IP 授权经济性和 2026 年前低后高节奏。
- 地平线机器人 2025 年中期业绩详细解读:
notes/books/Horizon Robotics 2025 Interim Results/01_详细解读.md,基于 9660.HK 2025 年中期业绩公告,梳理收入结构从授权服务向产品解决方案切换、征程 6 放量、HSD 量产、毛利率、研发投入、现金储备和营运资金风险。
- 地平线机器人 2025 年中期业绩 PDF 全文转换稿:
notes/books/Horizon Robotics 2025 Interim Results/source_materials/pdf_full_text.md,由用户上传 PDF 转换而来,作为后续研究地平线 2025H1 经营数据、财务质量和 HSD 量产进展的原始材料。
---
layout: post
title: 10小时计划
subtitle: Codex 个人助理沉淀
date: 2026-07-28 08:17:47 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/time_management/02_10小时计划.md
10小时计划
核心判断
如果上班日的 10 小时只能被工作被动切碎,那么职业成长、阅读积累和内容创作就很难稳定发生。
这份计划的重点不是把一天塞满,而是主动把通勤、整点回顾和周度复盘变成固定触发器,让工作、阅读和创作开始形成节律。
目标
- 利用好上班的 10 小时,高效工作,发展自己的兴趣爱好。
- 最终目标是成为职业投资人和自媒体创作者。
方法
1. 用触发器启动主动时间
上地铁后先打开便签,写下这趟地铁具体要做什么。任务可以很小,但必须明确,例如写文章、读书或整理想法。
这样做的作用不是提醒自己“不要浪费时间”,而是让通勤时间在开始的那一刻就被定义,不再被手机和随机信息流拿走。
2. 用整点回顾防止时间失控
每个整点回顾过去一个小时,看看时间是否真的用在了预设事项上。如果错过整点,也要在意识到之后尽快补看一次。
这个动作的本质是降低“无意识滑走”的时长,让偏离被更早发现,而不是等到一天结束才后知后觉。
3. 用周度复盘保证方向连续
每周开始前复盘上一周,并计划好这一周的创作、阅读和工作安排。最晚也要在周一早上的地铁上完成。
这样每周都能重新确认:哪些事情只是临时应付,哪些事情是真的在为长期目标积累。
第一日尝试
- 地铁上:听音乐,阅读《纳瓦尔宝典》,看完第一章。
- 工作:沟通修数据,预计上午完成。
- 创作:想一些未来创作的 idea,晚上把家里电脑写了一半的《一文讲清地平线》同步到云端。
- 阅读:继续读《纳瓦尔宝典》。
对自己的要求
- 从喜欢的事情入手,而不是为了完成而完成。
- 刻意练习的目标是逐步把“想做的事情”变成“稳定会做的事情”。
- 每天至少留下一个能沉淀的结果,例如读书进度、文章草稿、想法清单或问题复盘。
下一步动作
- 连续记录一周通勤时间实际做了什么,判断触发器是否真的有效。
- 给整点回顾设置一个尽量低打扰的提醒方式,避免完全依赖记忆。
- 到下周一前做第一次周度复盘,检查工作、阅读、创作三个方向是否都有真实投入。
---
layout: post
title: 第一部分 财富 PART ONE WEALTH
subtitle: Codex 个人助理沉淀
date: 2026-07-28 03:40:31 -0400
tags:
- 个人助理
- 读书笔记
- 纳瓦尔宝典
---
来源:notes/books/纳瓦尔宝典/01_内容全梳理.md
纳瓦尔宝典(美)埃里克·乔根森
版权信息书名:纳瓦尔宝典
作者:(美)埃里克·乔根森
译者:赵灿
出版社:中信出版社
出版时间:2022-04
ISBN:978-7-5217-4112-4
目 录关于本书的重要说明 DISCLAIMER推荐序一 财富与幸福源自选择推荐序二 一场反直觉的精神瑜伽序 PROLOGUE埃里克的笔记(关于这本书)纳瓦尔·拉维坎特经历表纳瓦尔亲述
第一部分 财富 PART ONE WEALTH
第一章 积累财富
认识财富创造的原理找到天赋所在,积累专长投资交友,着眼长远承担责任创立企业或买入股权找到杠杆用判断力赚钱分清主次,聚焦重点找到如玩耍般的工作如何获得运气保持耐心
第二章 增强判断力
判断力如何清晰地思考?
摆脱自我束缚,认清世界真相学习决策技巧发现好的心智模型
学会热爱阅读
第二部分 幸福 PART TWO HAPPINESS
第三章 学习幸福
幸福是一种技能幸福是一种选择幸福需要活在当下幸福需要心境平和欲望是主动选择的不开心成功不一定带来幸福嫉妒是幸福的敌人幸福源于好习惯于接受中寻找幸福
第四章 自我救赎
选择做自己选择关爱自己冥想+精神力量选择自我塑造选择自我成长选择解放自己
第五章 哲学
生命的意义按照自己的价值观生活理性佛教我们唯一拥有的是当下
额外推荐 BONUS
纳瓦尔的推荐读物图书
其他推荐纳瓦尔的写作生命公式一(2008年)纳瓦尔的个人原则(2016年)进一步了解纳瓦尔
致谢
附录
谨以此书献给我的父母,
感谢你们尽力给我所有,又不断给予我更多。
关于本书的重要说明DISCLAIMER
本书在创作时完全以纳瓦尔分享的文字记录、推文和谈话为基础。我尽力保留了纳瓦尔的原话和语言风格,但有几个问题需要重点说明:
-
为清晰简洁起见,文字记录经过多次编辑。
-
并非所有信息都来自第一手资料(部分内容来自其他作家引用纳瓦尔的话)。
-
我不能百分之百确定每个信息来源的真实性。
-
概念和解读会随着时间、媒介和背景的变化而变化。
-
若要引用本书中纳瓦尔的观点,请先用一手资料去核实。
-
对于书中纳瓦尔的观点,请以开放的心态解读,不必过于拘泥。
本书的内容经过搜集和整理而成,所有片段均有其固定语境,人们对它们的解读会随着时间的推移而变化。因此,在阅读和理解的过程中,请不必囿于原意。纳瓦尔的本意可能与读者在不同时间、媒介、形式和背景下的解读有所不同,这一点望读者知悉。
在本书的创作过程中,穿凿附会或移花接木等失误可能会时有发生。由于时间、空间和媒介的不同,在传播过程中,有些话语的措辞或许会有所变化。我虽然尽心竭力想保全纳瓦尔的初衷,但错误仍在所难免。
为了便于阅读,纳瓦尔的采访内容经过了多次转录、编辑和改写。我尽力保留了纳瓦尔的原话和语言风格。
在这本书里,一切亮点均属纳瓦尔,所有错误都归我一人。
推文和推特风暴推文使用了醒目的引文格式,是独一无二的内容,其作用是对文章的观点进行概括或强调。
这种格式是引用推文。
推特风暴(tweetstorms)是一系列连续的推文,格式如下:
这是推特风暴中的第一条推文。
这是第二条推文。推特风暴是一系列推文,主题统一,篇幅较长,类似于一篇博客文章。
访谈提问用黑体表示很多内容摘自谢恩·帕里什、萨拉·莱西、乔·罗根和蒂姆·费里斯等杰出创作者的访谈。访谈提问用黑体突出表示。为确保简单性和连续性,不同访谈之间未做区分。
篇章独立
本书无须按从头到尾的顺序阅读,读者可以根据喜好自行选择章节进行阅读。
查阅资料如果有不熟悉的词语或概念,请查阅相关资料,或者继续阅读,借助语境加深理解。一些前面提及的观点后面的章节会有详细阐述。
引文引文(如[1])表示摘录的结束。为确保阅读的顺畅性,我尽量把引文穿插在正文中。资料来源见附录,以供参考。有些资料来源会多次出现,没有先后顺序。
推荐序一 财富与幸福源自选择樊登博士 “樊登读书”创始人
这本书很薄,因为人生中真正重要的道理也确实不需要太多话。
纳瓦尔比我大两岁,9岁从印度移民美国。读这本书就好像看到时空中的另一个自己的精神成长史。虽然我们生活在不同的国家,从事着不同的工作,但高度重合的阅读书单让我们有着几乎相同的方法论和价值观。我们都喜欢佛陀、老子、达尔文、费曼、塔勒布、道金斯、查理·芒格、尤瓦尔·赫拉利和卡洛·罗韦利。我们都相信自由和幸福并不来自外在物质的满足,而是来自我们自身所做出的选择。放低自我是获得幸福的最有效方法,你越是喂养自己的自大,你对生活和整个世界的不满就越会吞噬你……所以,在读这本书的过程中绝大多数时候我的心里会说:“不能同意更多!”尤其是前半部分关于如何获得财富的内容,简直涵盖了我在拙作《低风险创业》中给出的全部核心建议。
凡是写书的人都怕自己的书被说成是“成功学”,而这本书的副标题竟然就是直白的“财富与幸福指南”!我一方面佩服作者的坦率和自我,一方面也在反思关于“成功学”的讨论。其实没有人反对成功,除非你一定要把成功定义成打了鸡血面目狰狞的样子。大部分人都希望自己能够获得世俗意义上的成功,事业有成,身体健康,心理平衡,家庭幸福。但之前流行的“成功学”恰好做不到这一点,反而容易让一个人头脑发疯,手舞足蹈,充满可怕而不受控制的欲望。真正能让你成功的书,是敢于说出也有能力说出这个世界真相的书。你如果能够通过读这样一本书,获得一个重要的启发,进而早日开始自我的进步和迭代,这本书就是真正的好书。而凡是向你承诺读了某本书或者上了某门课就能获得财富和方法的人,几乎都是“成功学”的骗子。纳瓦尔说:如果社会可以培训你,那么社会也可以培训他人来取代你。大家都能学会的东西是不可能让你致富的。凡是可以批量化培训的技能都是能够被雇佣的技能。只有你自己学到的东西,才是属于你独有的能力,才有可能让你创业成功。请仔细分辨两者的不同。同样是读书,有人指望书本能告诉他怎么开始怎么结束,所以总是失望(或者被骗)。而有人从书中获得启发,自己思考,自己实践,于是对书充满感激。从同一个教室里走出的学生天差地别,就是因为有人等着被打造,有人是自己在探索。
纳瓦尔说,如果现在让他一穷二白,他依然可以很快致富。我不敢这么说,但如果能够知道关于财富和幸福的一些基本规律,至少可以增加再次致富的概率,而且在这个过程中我们不至于太过焦虑。这本教大家如何成功的书最重要的观点是,成功没法教。这一点恰恰是关于成功最应该被知道的东西。我们陷入了一个悖论,也许可以把它称作“成功学悖论”。另外,纳瓦尔讲的也未必都对。一个处在人生风口浪尖上的人难免会说出一些过于绝对的话。比如,他说不要加入任何读书会。我想那是因为他没想过读书会在移动互联网时代可以有更多样的形式。我看到了这个需求并想办法解决它,于是社会把这个欠条给了我。(同样符合纳瓦尔的理论。)推荐序二 一场反直觉的精神瑜伽范冰 《增长黑客》作者
2020年初的新冠疫情,将彼时无数趾高气扬的创业者,从愚昧之巅推到了绝望之谷。周遭项目频繁爆雷,身边好友屡屡抱恙,使我警惕地将追逐增长的天际线,调低到了控制风险的警戒线。即便如此,我也关闭了一家亲手创建的公司。
愤懑彷徨数月后,我意外读到了一本出版不久的电子书。
此书平和却难掩锋芒,洗练中暗藏宝藏。它篇幅不长,平日阅读吞吐量尚可的我却花费了数倍于平时的时间,字斟句酌反复玩味。它就像一部思想的《洗髓经》,指引我反躬自省、突破心障,搭建了一套新的行事准则和信息系统,逐步走上了开悟之坡。
它就是《纳瓦尔宝典》。
纳瓦尔何许人也?他既是硅谷成功的创业家,创办了著名的股权众筹平台AngelList,也是顶级投资人,投中了推特、优步等公司。
1996年,纳瓦尔获得达特茅斯学院的计算机科学和经济学学位,进入硅谷工作。在帮助几家初创公司取得成功,并短期供职于一家风险投资公司后,他找到了自己的爱好——为投资人和创业者牵线搭桥。
最早他和合伙人开了一个叫Venture Hacks的博客,在网上教人们如何筹集创业必需的资金。很多创业者通过读Venture Hacks上的文章学习如何找风投,如何谈判风险投资协议,如何组织公司架构,如何进行财务管理。一段时间后,读者反馈希望纳瓦尔能代劳,所以他创立了AngelList。AngelList最初是一个电子邮件列表,每天会收到5 000封创业者提交的融资申请,之后渐渐演变成一个网站,陆续上线了在线融资、招聘等功能,成为硅谷最炙手可热的初创公司之一。
但真正让他火出圈的,是日常发的推特。
纳瓦尔最有名的一系列推特是“如何不靠运气致富”,堪称推特史上转载最多的推特之一。其核心思想是,你无法靠出卖时间变富,而是需要资产(公司、股票、实业)或被动收入(代码或媒体)。为此,你需要调动劳动力、资本的杠杆,并创造无复制成本的产品,最终将财富转换成享有幸福和自由的权利。
秉持开源精神,纳瓦尔允许埃里克将其推特整理成了电子版,挂在网站上供人免费下载。在上架亚马逊电子书店后,该书迅速拿下了年度财经榜第一名。
纳瓦尔像精明的商人,身体力行地演示着如何靠赚钱赢得时间自由,并在生命中最自由的那一年,全然跟随兴趣,赚了更多的钱。他又像哲学家,翩然世外地吟咏着对财富流动、科技演进、思想跃迁、幸福常驻的独到理解,从不主动寻求扩散,却在全球收获了一票忠实听众。
纳瓦尔的话题性,很大程度上源于这种跨界身份的对立统一。人们欣赏在多个领域结出硕果的成事之人,因为在内心深处,我们都期许自己独立多元、不被定义,就如海因莱因所说:“只有昆虫才专业化。”难能可贵的是,他以合乎道德的方式创造财富,又用不落窠臼的箴言将秘诀公开——既给鸡汤,又给汤勺。比如:
-
没有所谓的“商业”技能。不要把时间浪费在商业杂志和商业课程上。
-
最重要的是,要在重大决定上花更多时间。人生早期有三个重大决定:在哪里生活,和谁在一起,从事什么职业。
-
阅读数学、科学和哲学领域的经典作品。不要读畅销书,不要看新闻。避免加入任何所谓的“读书俱乐部”,避免追求任何的社群认同。把真理置于社群认同之上。
他说,发推特是整理思考的方式,它就像钩子一样,挂住灵感并把人导向更深入的思考。
阅读纳瓦尔的文字,就如经历一场精神上的瑜伽。你能时常在他富于节奏感的文字间隙,引入某个反直觉的思考角度,在一番修性吐纳之后,思绪更趋宁静。
纳瓦尔博览群书。他将自己所有物质上的成功和他可能拥有的任何智慧,都归于他的大量阅读。他很少将一本书从头到尾读完,而是喜欢在书里跳来跳去,搜寻自己感兴趣的段落。一旦对一本书失去兴趣,他就会停下来读别的书。在他看来,如果把读书这件事类比成进餐,那么挑食和剩饭是一件好事。他也从不将读书当成彰显学问的比赛,他更推崇将几本好书反复阅读、思考并吸收。他是费曼的超级粉丝,推崇费曼学习法——通过公开教授输出来巩固自己所学。
这也启发了我,用“年龄渐长表达欲减弱”“世事洞明便要少开尊口”“我已经写出过畅销书”等为借口,减少公开场合的发言,实则是一种故步自封的僵化心态。怕什么真理无穷,进一寸有一寸的欢喜。于是,我重新拾起尘封的邮件组、公众号,重新将日常思考的吉光片羽公开输出,还有滋有味地做起了视频和播客。它们反过来督促我更好地学习,也帮助我解锁了意外的机遇。
获益良多的我,将这本书发给身边的朋友,它确有阿司匹林那般普适镇痛的效果:从一线城市创业公司跳槽到互联网大厂的前同事,躺平未遂,陷入更加内卷的境地——发过去;在内陆省会开餐饮连锁店的大学同学,门店倒闭,陷入迷茫——发过去;供职传统金融单位的亲戚,工作乏味,生活割裂——发过去;即将毕业投身社会的读者,身无长物,憧憬未来——发过去。几乎从未收到差评。
我自己也会每年重新翻阅几次。现在出了纸质书,枕边常备书又多了一本。
如今,我依旧在社交网络和公开媒体上追踪着纳瓦尔的最新言行。在全球进入新常态的时代背景下,纳瓦尔将眼光投到用户隐私、分布式网络、加密平台、可移植数据等新兴Web3.0领域,在技术更迭和泡沫浪潮中,寻找下一个披沙拣金和降维打击的机会。
我期待着纳瓦尔继续将新的思想感悟,凝结成一本又一本智慧的宝典。也祝愿本书读者酣畅阅读,碰撞出智慧的火花,并将其绵延下去。
序
PROLOGUE
亲爱的读者:
写下这些文字的时候,感觉有点儿奇怪,因为我多年前就已下定决心不给别人的书作序了。
这次之所以破例,原因有三。第一,本书的电子版会免费提供给全球各地的读者,没有任何附加条件。第二,我与纳瓦尔相识十几年,早就希望有人能编写这样一本书。第三,给纳瓦尔作序,可以增加他给下一个孩子取名为“蒂姆”的可能性(如果他想用“蒂姆博”,我也可以接受)。
在我认识的人当中,纳瓦尔的智慧和勇气都是出类拔萃的。他的智慧和勇气不是“不假思索地一往无前”,而是“三思后行,谋定而动”。他很少随大溜,而是一直保持特立独行的生活节奏、生活方式、家庭关系和创业路径,他的人生成就源于他有意识地选择独树一帜。
纳瓦尔说话做事不绕弯子,有时会直言不讳,但这也正是我喜爱和尊重他的原因之一:他的想法永远不用别人去猜。他对我、对别人、对某种情况有什么看法和感受,无须揣度。在当今这个很多人口是心非、让人模棱两可的世界里,纳瓦尔直来直去的风格让人感受到一种巨大的解脱。
我们时常一起吃饭,一起做生意,一起在全球旅行。我自认为洞察各类人物,对纳瓦尔更是了解甚深。他是我最常打电话寻求建议的人,我也观察过他长年在各种情境下的表现,无论是顺境还是逆境,经济衰退还是经济繁荣等所有你能想到的低谷和巅峰时期。
没错,他是AngelList创投公司的首席执行官和联合创始人。没错,他曾经与人联合创立了分类广告平台Vast.com和大众消费点评网站Epinions(Epinions后来被Shopping.com收购,成功上市)。没错,他是一位天使投资人,在许多投资项目上大获成功,包括推特、优步、企业内部通信平台Yammer和免费域名解析服务提供商OpenDNS等等。
纳瓦尔的创业和投资经历由此可见一斑。这说明他是世界顶级的经营专家,而不是纸上谈兵的哲学家。
但我之所以十分重视他的观点、格言和思想,并不是因为他在商业领域的成功。世界上有太多的“成功人士”表面光鲜亮丽,个人生活却一塌糊涂,更无幸福可言。要谨慎效仿这些人的成功之道,不要好的坏的照单全收。
我看重纳瓦尔,是因为他:
-
对近乎一切都持怀疑态度;
-
从第一性原理出发进行思考;
-
可以对人对事进行有效测试;
-
从不自我欺骗;
-
不时调整自己的观点和看法;
-
经常开怀大笑;
-
有大局观;
-
眼光长远;
-
不把自己太当回事。
最后一点非常重要。
纳瓦尔脑海中的想法像一杯五彩纷呈的鸡尾酒,读者可以通过本书一品为快。
所以,请认真阅读体味,但不要机械模仿、简单照搬。可以遵循他的建议,但要在自己的生活中亲身体验,对建议进行压力测试,看看这些建议是否有用。可以深入思考他的观点,但不要将其视为真理。纳瓦尔希望别人挑战他的观点,只要挑战者有理有据。
我的生活因纳瓦尔的存在而变得更好。只要你能把这本书当成一个友善亲切又能力出众的陪练员,它就有可能改变你的生活。
以开放的心态拥抱纳瓦尔的智慧吧。
蒂姆·费里斯[1]
得克萨斯州奥斯汀市
[1]畅销书作者,著有《每周工作4小时》《巨人的工具》《巨人的方法》。——编者注埃里克的笔记(关于这本书)纳瓦尔在整个职业生涯中一直在慷慨地分享自己的智慧。全球数百万人遵循他的建议,积累财富,幸福生活。
在硅谷乃至全球创投圈,纳瓦尔都是一位标杆式的人物。他打造了一家又一家成功的公司(在2000年互联网泡沫破裂期间创立了Epinions,在2010年创立AngelList)。纳瓦尔还是一位天使投资人,在优步、推特、众包物流平台Postmates等数百家公司创立之初,就投资押注了这些公司。
纳瓦尔不仅取得了财务上的成功,还乐于分享自己的人生哲学和幸福之道,吸引了来自全球的读者和听众。纳瓦尔之所以广受追捧,是因为他不仅事业成功,而且生活幸福——这种组合是极为罕见的。
他一生都在研究和应用哲学、经济学和财富创造学,也用事实证明了自己的原则产生的影响。
直至今日,纳瓦尔依然保持着自己在创投领域的艺术风格,以一种近乎随性的方式创业和投资。与此同时,他身体健康,内心宁静,过着平和美好的生活。这本书收集整理了他分享的智慧片段,向读者展示了如何实现与纳瓦尔一样的成就。
纳瓦尔是一位善于自省的创始人,一位自学成才的投资者,一名工程师,他的人生经历颇具启示性和教育意义。
纳瓦尔思考问题总是从第一性原理出发,不惮说出自己的真实想法。他的思想往往新颖独到、发人深省。他能透过生活的表象看到本质,这种能力也改变了我看待世界的方式。
我从纳瓦尔身上学到了很多。我通过文字和音频学习了他的财富和幸福原则,并在自己的生活中加以应用,在人生旅途中获得了平静和信心,也学会了享受人生旅途的每一刻。我认真研究了他的职业生涯,看到了积跬步至千里的恒心和毅力,学到了坚持不懈方能成就伟大事业的行事方式,认识到个体也可以产生巨大的影响力。
我经常参详他的观点,也经常把他的观点推荐给自己的朋友。跟朋友的对话给我带来启发,我决定打造这样一本书,帮助熟知纳瓦尔的人和新晋读者学习他的观点。
这本书收集了纳瓦尔过去10年通过推特、博客和播客分享的智慧,保留了他的原话。有了书,你便可以在几个小时内学到受益终身的思想。
我创作这本书的目的是服务大众。推特、播客和采访很快就会被新信息覆盖,被时间遗忘,而纳瓦尔有价值的思想值得用一种更持久、更易于获取的形式留存下来。这是我编写这本书的使命。
我希望这本书可以作为对纳瓦尔思想的介绍。我收集了他最有力、最有用的思想,保留了他的原话,按照逻辑顺序串联起来,组成章节,以便读者参阅。
在做投资之前,我总会回顾这本书里关于投资的内容;每当心情低落时,我就会阅读关于幸福的章节。这本书的创作过程也改变了我。在生活的各个方面,我都感到更清醒、更自信、更平和了。我希望这本书也能给你带来同样的启迪和效果。
这本书提供了特定主题的阅读和查询指南,读者可以自行选择主题,阅读相关篇章。如果纳瓦尔没有回复你的邮件,我希望这本书成为你的第二选择,为你提供有用的建议。
这本书是对纳瓦尔的介绍,包含了他探索最深入的两个主题:财富和幸福。如果你想继续探索纳瓦尔和他的其他思想,请查看本书末尾“进一步了解纳瓦尔”部分。在这一部分,我分享了最终版删减的章节以及其他一些热门资源。
一切祝好。
埃里克
纳瓦尔·拉维坎特经历表
-
1974年,出生于印度德里
-
1983年,9岁,从印度新德里搬到美国纽约皇后区
-
1988年,14岁,就读于史岱文森高中
-
1995年,21岁,从达特茅斯大学毕业(学习计算机科学和经济学)
-
1999年,25岁,成为Epinions创始人/首席执行官
-
2001年,27岁,成为风投机构August Capital创业合伙人
-
2003年,29岁,成为分类广告平台Vast.com创始人
-
2005年,31岁,在硅谷被称为“放射性泥浆”
-
2007年,33岁,创立小型风险投资基金Hit Forge,最初设想是用作孵化器
-
2007年,33岁,创立VentureHacks博客
-
2010年,36岁,创立AngelList
-
2010年,36岁,投资优步
-
2012年,38岁,游说国会通过《就业法案》
-
2018年,44岁,获评“年度天使投资人”
纳瓦尔亲述背景我在单亲家庭长大,母亲既要工作,又要读书,还要抚养我和哥哥。我们从小就把家门钥匙挂在脖子上,学着照顾自己。困难当然是有的,但每个人都会遇到困难。困难在很多方面有助于我成长。
我们家是一个贫穷的移民家庭。在印度时,父亲是一名药剂师。
来到美国后,他的学位不被认可,只能在五金店工作。所以,我的成长环境并不好,没有受过良好的教育。父母后来也分开了。[47]条件虽然艰苦,但是母亲给了我们无条件的爱,毫无保留,始终不渝。在一无所有的人生中,如果至少还有一个人无条件地爱着你,你的自尊心就会得到极大的保护。[8]我们在纽约居住的社区不太安全。图书馆基本上就是我的课外活动中心。放学后,我会直接去图书馆,待到闭馆,然后回家。这就是我的日常生活。[8]刚搬到美国时,我年纪还小,也没什么朋友,所以不是很自信。
我大部分时间都在读书。我唯一真正的朋友就是书。书的确是人类的好朋友,因为过去几千年最优秀的思想家都是以书为媒,与你分享他们的超凡智慧的。[8]我的第一份工作是在一家非法经营的餐饮公司上班。当时我15岁,坐在一辆货车的后座,到处运送印度食物。甚至在更小的时候,我就送过报纸,在餐厅洗过盘子。
在纽约,我完全是个无名小卒,家庭也无足轻重,当时的人生模式就是“讨生活的移民”。后来,我考上了史岱文森高中,人生从此得以改写。因为在拿到史岱文森高中毕业证后,我考进了一所常春藤盟校,并由此进入科技行业。史岱文森高中就像一台智能抽奖机,当场开奖,从蓝领到白领,只需要一步。[73]我在达特茅斯学院读了经济学和计算机科学,一度以为自己会成为经济学博士。[8]如今,我是一名投资人,投资了约两百家公司。给一些公司做顾问,在一些公司担任董事。我也是一个加密货币基金的小合伙人,因为我非常看好加密货币的潜力。我一直在探索新想法,也一直在搞各种各样的副业。[4]
当然,除此之外,我还是AngelList的创始人兼董事长。[4]我出身寒门,一度困顿迷茫,而现在的我经济上宽裕,精神上幸福。我为达到这两个目标付出了很多努力。
我学到了一些经验和教训,总结了一些原则。我试着把自己的思考结集成文,希望对你有所启发。因为说到底,我什么也教不了。我只能给你带来些许启发,或者还有几个你能记住的“金句”。[77]
这里是纳瓦尔,在推特上现场直播(掌声响起)2007年5月18日
第一部分 财富
PART ONE WEALTH
如何不靠运气致富。
第一章 积累财富
赚钱不是一件想做就能做的事情,而是一门需要学习的技能。
认识财富创造的原理能学会。[78]假设有一天,我创业失败,身无分文,这时把我随意丢到任何一个说英语的国家的街道上,我相信自己会在5年或10年内重新变得富有,因为我已经掌握了“赚钱”这门技巧,而这门技巧人人都赚钱跟工作的努力程度没什么必然联系。即使每周在餐厅拼命工作80个小时,也不可能发财。要想获得财富,你就必须知道做什么、和谁一起做、什么时候做。与埋头苦干相比,更重要的是理解和思考。当然,努力非常重要,不能吝啬自己的努力,但必须选择正确的方式。
如果还不知道自己应该做什么,那么你先要弄清楚这个问题。在这之前,不要盲目发力。
十三四岁时,我就给自己列出一系列原则,详见下面的推特风暴。30年来,我一直谨记这些原则,也在生活和工作中践行这些原则。随着时间的推移,我发现自己愈加擅长观察企业,并从中找到最能创造财富的杠杆支点,然后抓住这部分财富(这种特长说不上是可悲还是幸运)。
下面推特风暴的内容,其中的推文广为流传,当然,每条都可以衍生出一个小时的谈话内容。这条推特风暴是一个很好的起点。我在其中写下了我所有的理念和原则,力求信息密集、简洁有力、影响广泛、历久弥新。如果你能吸收这些理念和原则,以此为指引,奋斗10年,你就一定能够得偿所愿。[77]
如何致富(不靠运气):
∨
追求财富,而不是金钱或地位。财富是指在你睡觉时仍能为你赚钱的资产。金钱是我们转换时间和财富的方式。地位是你在社会等级体系中所处的位置。
∨
创造财富和坚持道德标准是可以兼得的。如果你内心鄙视财富,财富就会对你避而远之。
∨
无视一味追求社会地位的人。他们获得地位的手段就是攻击创造财富的人。
∨
依靠出租时间是不可能致富的。你必须拥有股权(企业的部分所有权),才能实现财务自由。
∨
获得财富的一个途径,就是为社会提供其有需求但无从获得的东西,并实现规模化。
∨
选择一个有长期发展前景的行业,找到可以长期合作的人。
∨
互联网极大地拓展了职业空间,但大多数人还没有清晰地认识到这一点。
∨
培养迭代思维。生活中所有的回报,无论是财富、人际关系,还是知识,都来自复利。
∨
选择聪明过人、精力充沛的商业伙伴,但更重要的是,他们要正直诚信。
∨
不要跟愤世嫉俗和消极悲观的人合作。他们的预言会自我实现。
∨
学会销售,学会构建,两技傍身,势不可当。
∨
用专长、责任感和杠杆效应武装自己。
∨
专长指的是无法通过培训获得的知识。如果社会可以培训你,那么社会也可以培训他人来取代你。
∨
要想有所专长,就要追求真正的兴趣和热爱,而不是盲目追逐热点。
∨
累积专长的过程,对你而言就像玩耍,对他人来说则很吃力。
∨
专长的传授需要通过师傅带徒弟的方式完成,而无法通过学校教育完成。
∨
专长往往具有高度的技术性或创造性,不能被外包或自动化。
∨
培养责任感,勇于以个人名义承担商业风险。社会将根据责任大小、股权多少和杠杆效应回报你。
∨
“给我一根足够长的杠杆和一个支点,我就能撬动地球。”——阿基米德
∨
要想获得财富,就必须充分利用杠杆效应。商业杠杆来自资本、劳动力和复制边际成本为零的产品(代码和媒体)。
∨
资本是指金钱。要想获得融资,需要运用自己的专长和责任感,并表现出良好的判断力。
∨
劳动力杠杆就是让别人为你工作。这是最古老、争夺最激烈的一种杠杆。拥有劳动力杠杆会让你的父母觉得你很了不起,但不要过度追逐劳动力杠杆。
∨
资本和劳动力是需要获得许可才能使用的杠杆。人人都在追逐资本,但得有人愿意出资。人人都想领导他人,但得有人愿意追随。
∨
代码和媒体是不需要许可就能使用的杠杆。这两个杠杆是新富阶层背后的杠杆。你可以创建软件和媒体,让它们在你睡觉时为你工作。
∨
有一大批机器人可供我们免费使用。为了提高热效率、节约空间,这些机器人就集中放在数据中心。用起来吧。
∨
如果不会写代码,那就出书、写博客、做视频、录播客。
∨
杠杆是判断力的倍增器。
∨
判断力从经验中来,但可以通过学习基本技能快速建立起来。
∨
没有所谓的“商业”技能。不要把时间浪费在商业杂志和商业课程上。
∨
学习微观经济学、博弈论、心理学、说服术、伦理学、数学和计算机。
∨
读比听快,做比看快。
∨
你应该忙得没时间社交,但依然把日程安排得井然有序。
∨
设定一个大胆的个人时薪,并严格执行。如果解决一个问题节省的成本低于时薪,那就忽略问题;如果外包一项任务的成本低于时薪,那就选择外包。
∨
工作时要拼尽全力,毫无保留。不过,共事的人和工作的内容比努力程度更重要。
∨
在自己选择的职业领域里做到全球顶尖。不断重新定义自己的事业,直到理想成为现实。
∨
世界上没有快速致富的教程。即使有,那也只是提供教程的人想从你身上赚钱。
∨
运用专长,发挥杠杆效应,最终你会得到自己应得的。
∨
当你终于变得富有时,你会意识到,这并不是你最初的追求。但这是后话,此处暂且不提。[11]
总结:把自己产品化。
“把自己产品化”是什么意思?
这句话有两个重点,一个是“自己”,一个是“产品化”。“自己”具有独特性,“产品化”是发挥杠杆效应;“自己”具有责任感,“产品化”需要专长。“自己”其实也具有专长。因此,这两个重点就可以概括上述所有的理念。
如果想要实现致富的长期目标,你就应该问问自己:“这是我真正想要的东西吗?我的规划目标是我真正想要的吗?”得到肯定的答案后,再问问自己:“我实现产品化了吗?我实现规模化了吗?我选择规模化的方式是劳动力、资本,还是代码或媒体?”由此可见,“把自己产品化”这个阐述方便简单,便于记忆。[78]
“把自己产品化”很难。所以我才说“把自己产品化”要花几十年——并不是要花几十年执行,而是要把大部分时间用于思考:我能提供什么独特的价值?[10]
财富和金钱的区别是什么?
金钱是我们转移财富的方式。金钱是社会的信用符号,具有调用别人时间的能力。
如果我做好了本职工作,为社会创造了价值,社会就会对我说:“谢谢你,因为你在过去所做的工作,我们在未来欠你一些东西。
这是一张欠条,我们可以把这个叫作钱。”[78]
你真正想要的其实是财富。财富就是在你睡觉时也可以帮你赚钱的资产。财富是可以进行生产的工厂和机器人。财富是不分昼夜为客户服务的计算机程序。财富也可以是银行里被投资于其他资产或业务的钱。
甚至房子也可以成为一种财富,因为房子可以出租,带来租金收益。但与从事商业活动相比,这种土地利用方式的生产效益较低。
所以,我对财富的定义是在睡觉时也能带来收入的企业和资产。
[78]
技术让消费变得更大众化,也让生产变得更集中。在某个领域做到全球顶尖的人,现在可以为世界上任何人提供自己的产品或服务。
要想在社会上赚到钱,就要为社会提供其有需求但无从获得的东西。如果社会已经创造出需要的产品和服务,你也就不被需要了。
你家里、工作场所和大街上的几乎所有东西都曾是科技产品。曾几何时,石油这种科技产品让洛克菲勒变得富有,汽车这种科技产品让亨利·福特积累起财富。
因此,正如艾伦·凯所说,科技就是一套尚未完全发挥作用的东西(更正,是丹尼尔·希利斯所说)。某种东西一旦得到广泛应用,它就不再是科技了。社会总是需要新事物。如果想变得富有,你就要弄清楚你能为社会提供哪些其有需求但无从获得的东西,而提供这些东西对你来说又是轻松自然的事情,在你的技术和能力范围内。
下一步是思考如何规模化,因为只提供一个产品或一项服务是远远不够的,必须提供成千上万个,甚至几十万、几百万、几十亿个,最好人手一个。史蒂夫·乔布斯(当然还有他的团队)发现社会需要智能手机。他们设想的是一台可以装在口袋里随身携带的小型计算机,拥有电话的所有功能,甚至比电话的功能还强大100倍,使用起来也非常简单。然后,他们研究出了如何制造这样一部智能手机,以及如何实现规模化生产。[78]找到天赋所在,积累专长销售技能是一种专长。
有些人“天生”就是做销售的料儿。在创业公司和风投领域这种人很常见。天生的销售高手会让人眼前一亮。他们非常擅长自己的工作。也就是说,他们具备这方面的专长。
他们的销售技能显然也是习得的,但一定不是在课堂上学到的。
他们可能在学校操场上学会了如何推销,可能是在跟父母的沟通中学会了讨价还价,也可能有一些遗传基因在里面。
销售技能是可以得到提升的,可以读读罗伯特·西奥迪尼的书、参加销售培训班、挨家挨户上门推销等等。上门推销是对心理素质的巨大挑战,但确实可以快速提高销售技能。
专长无法被教授,但可以被学习。
想要找准适合自己的专长,可以回想一下在孩提时代或青少年时期,有哪些事情是你几乎不费吹灰之力就可以完成的。有时候,即使你自己不觉得那是一门技能,身边的人也会留意到。你的母亲或者你成长过程中最好的朋友会知道你有什么特别之处。
关于个人天赋和专长,举例如下:
-
销售技巧。
-
音乐天赋:学习任何乐器都不费力。
-
专注力强:容易沉浸在一个事物中,并很快记住相关知识点。
-
热爱科幻:喜欢读科幻小说,吸收新知识的能力特别强。
-
擅长游戏:对博弈论了解得透彻深刻。
-
喜欢八卦:深入挖掘朋友的社交网络,将来可能成为有所建树的记者。
在基因、成长环境和个人对环境的回应的共同作用下,每个人都形成了自己独一无二的专长。专长是一个人个性和身份的有机组成部分。一旦找到自己天生喜欢和擅长的领域,你就可以朝着这个方向持续前进。
在“成为自己”这件事情上,没有人能比得过你。
其实,人生大部分时间都是在寻找,寻找那些最需要你的人,寻找那些最需要你的事情。
以我为例,我喜欢阅读,也喜欢科技。我学得很快,但非常容易喜新厌旧。如果我的工作是对一个问题研究20年,那么我肯定做不好。我现在的职业是风险投资。要做好风投,就需要迅速跟上新科技的发展速度(由于新科技层出不穷,我“喜新厌旧”的个性反而是件好事),所以做风投与我的专长和技能相当契合。[10]我本来立志成为一名科学家。我心中的道德层级也源于此。我认为,科学家处于人类生产链的顶端。科学家实现了真正的突破,取得了切实的成果,为人类社会做出了巨大的贡献。科学家对人类社会的贡献应该超过了其他任何一类人群。这并不是说艺术、政治、工程或商业不重要,但是如果没有科学,我们就会过着茹毛饮血、刀耕火种的原始生活。
社会、商业和金钱是技术的下游产物,而技术本身又是科学的下游产物。应用科学是推动人类社会发展的引擎。
由此得出的推论是,应用科学家是世界上最有权威的人。这一点在未来几年会更加突出。
最初,我的整个价值体系是围绕科学家建立的,我梦想成为一名伟大的科学家。但是我独一无二的长处是什么?我最终把时间花在了哪里?回顾过去,我发现我做得更多的都是围绕着赚钱,与技术打交道,与人打交道,推销产品,谈经论道,兜售理念。
我拥有一定的销售技能,这是一种专长。我拥有一定的分析技巧,会研究如何赚钱。我痴迷于数据,擅长搜集数据,尤其擅长拆解数据。我也喜欢研究科技。所有这些对我来说就像玩耍一样轻松有趣,但对别人来说却需要付出努力。
有些人觉得销售很难,想知道怎样才能做到口齿伶俐、善于推销。事实上,如果你在现阶段仍不擅长做销售,或者对销售确实没什么兴趣,那么销售这个行业也许并不适合你,你还是要专注于自己真正喜欢的事情。
第一个明确指出我天赋的人是我母亲。十五六岁的时候,我在跟朋友聊天时说自己想成为一名天体物理学家。母亲在厨房听到后插了一句:“不会的,你会去做生意。”我当时心里想:“什么?妈妈说我会做生意?我要成为一名天体物理学家。妈妈是不是不知道自己在说什么?”事实上,母亲确实知道自己在说什么。[78]
要积累和发展专长,就要发挥自己的天赋,研究自己真正好奇的东西,追寻自己的热情所在,而不是选择一个当下的热门专业,然后在毕业后进入投资者宣称的热门行业。
通常情况下,专长属于知识领域的边缘地带。有些领域尚处于发轫或发展阶段,有些领域研究难度很大,这些领域更容易产生专长。
如果你在研究的时候不是百分之百投入,其他百分之百投入的人就会超过你。他们的表现会比你好不是一点儿,而是很多,因为我们讨论的是创意领域的竞争。在创意领域,复利效应非常明显,杠杆效应也非常明显。[78]
互联网极大地拓宽了职业空间。大多数人还没有清晰地认识到这一点。
通过互联网,每个人都可以找到自己的受众。只要在网上进行独特的自我表达,你就有机会传播快乐,累积财富,打造产品,创立企业。[78]
有了互联网,只要你在自己的领域做到最好,只要你能规模化你所提供的特别内容,那么就算你的兴趣很小众,你也能有所发展。令人欣慰的是,每个人都是独一无二的,因此,每个人在某些方面都能做到最好——在成为自己这个方面,没人能比你做得更好。
有一条推文我没有放入“如何致富”的推文风暴里,但值得一读。
这条推文的内容非常简单:“只有独辟蹊径,才能避开竞争。”从本质上看,竞争就是模仿,与他人竞争,是因为你跟别人在做一样的事情。但是,每个人都是独一无二的,不要模仿他人。[78]
只有独辟蹊径,才能避开竞争。
如果你打造和推介的内容是自我的衍生,那就没有人可以与你竞争。谁又能跟乔·罗根或史考特·亚当斯竞争呢?这是不可能的事。有谁能比史考特·亚当斯画出更好的《呆伯特》漫画吗?没有。有谁能比比尔·沃特森创作出更好的《凯文的幻虎世界》漫画吗?没有。这是因为原创作品都是独一无二、无可比拟的存在。[78]
最好的工作与委任或学位无关。最好的工作是终身学习者在自由市场中的创造性表达。
致富最重要的技能是成为终身学习者,无论想学什么,你都得找到途径和方法。以前的赚钱模式是读4年大学,拿到学位,在某个专业领域干上30年。现在不一样了,时代的发展日新月异,必须在9个月内掌握一门新专业,而这门专业在4年后就过时了。但在专业存在的这3年里,你可以变得非常富有。
终身学习
如今,在9到12个月内成为一个全新领域的专家比在很久以前选择了“正确的”专业要重要得多。只有掌握好基础知识,才能不忌惮任何书籍。如果在图书馆读到一本自己无法理解的书,那么你先要了解读懂这本书需要哪些基础知识,打好基础后再深入研究。基础是极为重要的。[74]
掌握基础知识
在生活中,基本的算术能力比微积分更重要。同样,能够用简单的英语词汇清楚地表达比能够写诗、词汇量丰富或者说7种不同的语言重要得多。
比起成为一名数字营销专家或点击优化专员,知道如何增强沟通说服力更重要。打好基础非常关键。在基础知识层面得90分或100分远胜于盲目地深入钻研。
当然,有些东西你需要深入研究,否则你只能做到“样样都通,样样稀松”,无法实现人生目标。一个人只能在一两件事上做到精通,而这一两件事通常是让你痴迷的事情。[74]投资交友,着眼长远你曾说:“生活中所有的回报,无论是财富、人际关系,还是知识,都来自复利。”如何判断自己是否获得了复利呢?
在一两件事上做到精通。
复利这个概念的内涵非常丰富。复利的概念源于资本,但不止于此。复利效应并不局限于资本领域。
商业关系中的复利效应非常重要。看看社会上的顶级角色,为什么有些人能够担任上市公司首席执行官,或者管理几十亿美元的资金?这源于别人对他们的信任。之所以能够得到信任,是因为他们打造的人际关系和事业产生了复利效应。他们以极为直观和负责的方式投入事业,向世界证明自己品行正直,高度诚信。
品行正直,高度诚信
个人声誉方面也存在复利效应。如果一个人声誉良好,数十年如一日,不断打造和积累自己的声誉,这个人就一定会得到关注和重视。而如果一个人才华横溢,却没有利用声誉的复利效应,相比之下,注重声誉的人的价值就会高出其成千上万倍。
注重声誉
与人共事也是同样的道理。如果你和一个人一起工作了5年、10年,依然乐在其中,那么显然你对他是信任的,即使小有缺点,也瑕不掩瑜。在商业关系中,有了彼此的信任,所有的常规谈判都可以化繁为简,因为你知道合作定能成功。
积累信任
举个例子,硅谷有一位叫埃拉德·吉尔的天使投资人。我很喜欢跟他共事。
原因就是,我知道在交易过程中,他会竭尽全力为我提供额外的利益。如果交易另有好处,他一定会把好处给我。如果产生了多余的成本,他就会自掏腰包,甚至对我提都不提。因为他毫无保留地对我好,于是我几乎所有交易都会找他,尽量让他参与其中。我也会不计成本地对他好。这种互信的关系就充分体现了复利的价值。[10]
出发点并不重要,行为本身才重要。因此,遵守道德标准并非易事。
一旦找到正确的事业和一同前行的人,就要全身心投入。接下来,持续精进几十年,就能从人际关系和经济利益上获得巨大的回报。因此,复利效应非常重要。[10]
99%的努力终将白费。
显然,没有一种努力是完全白费的,因为我们总能在努力的过程中学到一些东西。任何经历都可以成为学习的机会。举例来说,回顾求学生涯,当时写的论文、读的书、做的练习,99%不适用于现实社会。学到的一些地理和历史知识你从未派上用场,学的一门外语你早已不再使用,一些数学知识你也早已全然忘记。
当然,学校的学习经历的确教会了我们一些东西。比如,你理解了努力的重要性,一些理念也潜移默化地成为你的精神动力,或者在一定程度上促使你从事当前的职业,等等。然而,至少从以目标为导向的现实社会的角度看,你在学校里付出的努力只有1%得到了回报。
再以约会为例。在遇到你的人生伴侣之前,你会跟不同的人约会。从目标层面看,这些约会纯属浪费时间(虽然从个人成长和学习体验方面看并非如此)。
我说这些,并不是在自作聪明地断言“生命中99%的时间都被浪费了,只有1%被用在了正确的地方”。我想说的是,你应该在经过深思熟虑后,清醒地认识到自己需要从大多数事情(人际关系、工作、学习)中找到可以尽全力去付出的那部分,以充分获取复利效应。
在约会过程中,如果意识到两个人不会走入婚姻殿堂,那么你也许应当尽早结束这段关系,开始下一段旅程。当学习的时候,比如学习地理或历史,如果意识到学到的知识你永远不会用,那就放弃这门课程吧。把精力用在无用的东西上是浪费时间,浪费脑力。
我不是说那99%的事情都不要做,因为我们很难确定剩下的1%到底是什么。我的意思是:努力找到不会被浪费的1%。这1%对你是有意义的,值得你用余生去追求。一旦找到,你就要心无旁骛,全力以赴。[10]承担责任勇于以个人名义承担商业风险。社会将根据责任、股权和杠杆效应回报你。
努力找到不被浪费的1%。
获得财富需要杠杆。杠杆可以来自劳动力、资本、代码或媒体。
劳动力和资本等大多数杠杆需要有给予方。要获取劳动力,必须有人追随你。要获得资本,需要有人为你提供资金、管理资产或机械设备。
劳动力、资本、代码或媒体
因此,要得到劳动力或资本,必须建立信誉,尽可能以个人信誉做担保,而这种操作存在风险。因此,责任是把双刃剑:进展顺利,责任人会得到褒奖;一旦失败,责任人就会首当其冲。
明确的责任分配非常重要。没有责任,就没有动力。没有责任,就无法建立可信度。但责任也意味着风险:失败的风险,被羞辱的风险,以个人名誉承担失败的风险。
幸运的是,现代社会没有债务人监狱。一个人不会因为损失了别人的资金被监禁或处决。但是,作为社会性动物,我们依然认为,在大庭广众之下遭遇个人失败是无法接受的事情。实际上,那些有能力以个人名义在公众面前承担失败风险的人,会获得很大的原动力。
以我个人的经验为例。在2013年、2014年之前,我的公众形象完全围绕着创业和投资。直到2014年、2015年,我才开始涉猎更广泛的话题,比如哲学、心理学。因为我是在以个人名义表态,所以对这种转变略感紧张。创投界的朋友曾私下跟我说:“你这是在干什么?你的职业生涯完了!这也太愚蠢了。”
但我依然如故。我赌了一把,就像在加密货币诞生初期冒险投资一样。当以个人名义公开发表看法时,你就是在为某些观点和做法承担风险。同时,你也会因此得到回报,从中获益。[78]
以个人身份发表观点是在承担风险,但是同时也会获得回报。
在过去,船长的职业要求是与船同生死、共存亡。如果船要沉了,船长就是最后下船的人。这样的责任制确实伴随着生死存亡的风险,但我们现在讨论的是商业领域。
商业风险可能体现在成为最后一个撤资人,成为最后一个获得时间报酬的人,等等。投入时间和资本都会有风险。[78]
要认识到,在现代社会,下行风险并没那么大。在良好的生态系统中,即使个人破产,债务也可以被一笔勾销。我最熟悉的是硅谷的环境,但是整体而言,只要个人诚实正直,确实付出了努力,人们就会原谅你的失败。
失败真的没有那么可怕,所以我们都应该勇于承担更多责任。[78]创立企业或买入股权没有股权,就没有通往财务自由的路径。
失败没有那么可怕
为什么拥有企业股权是致富的关键所在?
我们需要了解获得权益回报和赚取薪资报酬的区别。如果你是通过出租时间来换取报酬的,即使从事律师和医生等高薪职业,你能够获得的报酬也非常有限,不足以让你实现财务自由。而如果拥有企业股权,你就可以获得被动收入——即使你在度假,企业也在帮你赚钱。[10]
这应该是有关财务自由最核心的一点。大家似乎认为可以通过工作创造财富,但事实可能并非如此。其中的原因有很多。
如果不持有企业股权,个人投入和收益的关联性就会非常强。几乎所有领取月薪的工作,即便是律师或医生这样的高薪职业,也需要投入时间才能获得相应的收入。
如果不持有企业股权,睡觉的时候没有收入,退休以后没有收入,度假期间也没有收入。总之,收入是相对固定的,根本无法实现实质性突破。
有些医生的确实现了财务自由,那也是因为他们自己开了公司。
他们设立私人诊所,打造品牌,以品牌吸引客户,也有些医生通过生产医疗设备、发明某种程序或流程等获得了知识产权收益。
从本质上看,上班就是给人打工。而企业所有者在承担风险和责任的同时也拥有知识产权和品牌效应。所以,他们支付给你的报酬一定低于你创造的价值。为了让你工作,他们会给你提供最低限度的报酬。这个最低限度的报酬可能很高,但依然不是真正的财富,因为你退休后,这份收入将难以为继。[78]
上班是在给人打工,企业所有者是承担风险和责任的同时,收获利益。
拥有企业股权意味着可以获得企业发展的收益。拥有一家公司的债券也是一项有保障的收入来源,但同时也承担了公司经营不善的下行风险。所以,要持有股权,如果没有企业股权,赚钱的机会就会非常渺茫。
所以,要努力工作,直到有能力拥有企业股权。你可以买入企业的股票,成为小股东,也可以创办一家属于自己的企业。总而言之,要想方设法拥有企业的所有权,这一点真的非常重要。[10]
买股权
最终真正能赚大钱的人都拥有产品和企业的所有权,或者拥有知识产权。如果在科技公司工作,那么你可以先持有股票期权。这是一个不错的起点。
但通常情况下,真正的财富是通过创建公司或者通过投资创造出来的。投资公司也是买入企业的股权。这些都是获得财富的途径。总之,真正的财务自由都不是靠单纯地投入大量时间来实现的。[78]找到杠杆在现在这个时代,杠杆无处不在,真正的求知欲所带来的高经济回报前所未有。[11]想要打造良好的职业基础,就要追随自己真正的求知欲上下求索,而不是盲目跟风眼下赚钱的热门行业。[11]
追寻自己的求知欲。
真正的财富自由是靠投资,而不是靠大量的时间。
有意思的是,正是在独特的热爱和爱好的驱动下,我们才得以掌握只有自己或一小部分人才知道的知识。如果能够把求知欲和兴趣爱好结合、相融,我们就更有可能找到自己的所爱。[1]
因为独特的爱好,所以说我们就能够知道,只有一小撮人才知道的知识。
如果一件事物一开始让你兴致盎然,后来又让你觉得索然无味,那么它只是暂时分散了你的注意力,并不是你心智上真正的好奇所在。请继续寻找。
如果你刚开始觉得有意思,后面觉得无聊了,那只是你分散了注意力,请你继续寻找。
无论做什么事情,我都以事情本身为目标。这也是艺术创作的一个鲜明特征。无论是创业、健身还是恋爱、交友,我始终都认为生命的意义在于专注于事情本身,体验过程,享受当下。神奇的是,当专注于事情本身时,你反而能做得更好。即使是赚钱,你也能成为赚得最多的那个。
以事情本身为目标。
我为自己创造财富最多的一年,实际上是工作最不努力、对未来最不关心的那一年。我做的大部分事情纯粹是为了好玩儿。我等于在昭告身边的人:“我退休了,不再工作了。”这样一来,我能把时间花在自己认为最有价值的项目上。由于只关心过程,我反而取得了最好的结果。[74]对一件事情的欲望越小,顾虑就越少,执念就越少,反而越会顺其自然,遵循内心。你会以自己擅长的方式,始终不渝地做下去,工作质量也会因此提高。[1]
赚钱最多的一年是单纯在玩,其实就和他上面说的一样,你找到你的长处,你的长处就是你觉得在玩,但是你做的比大部分人都要好。
不要追逐所谓的“热门”,而要追求自己真正感兴趣的事情。如果在追随好奇心和求知欲的过程中又满足了社会需求,你就能得到优厚的经济回报。[3]
同时,你更有可能获得这个社会还不能通过培训提供的技能。如果社会可以培训他人,这些人就可以取代你。如果你可以被轻易取代,社会就不需要为你支付重酬。要时刻牢记,掌握社会所需的独门绝技才是占据职业制高点的不二法门。[1]
如果社会可以培训你,那么总有一天,社会也可以编写代码,用计算机取代你。
要得到经济回报,你就需要提供社会有其需求但无从获得的东西。很多人认为,在学校里可以学到怎么赚钱,实则不然,学校教不会“经商”这个技能。[1]
社会有但无从获得的东西。
认真想一想,社会上还有哪些尚未得到满足的需求,而你怎样才能成为第一个提供相关产品或服务的人,并将其规模化。这才是赚钱真正的挑战。
关键在于,准确把握并满足社会所需。每一代人所需的产品或服务都不一样,但绝大多数都与科技相关。
当新的需求乍现,而你恰好又是唯一具备相关技能组合的人时,大显身手的时刻就到了。这期间,你可以通过免费提供产品或服务在推特、YouTube(视频网站)上建立自己的品牌。在这个过程中,你可能会承担一定的风险和损失,但是你为自己打造了个人品牌,赢得了声誉。当机会到来时,你就能最大限度地利用杠杆效应,扩大自己提供的产品或服务的规模。[1]
总体而言,杠杆有三种。
第一种是劳动力杠杆,也就是让别人给你打工。劳动力杠杆是一种最古老的杠杆,但在现代社会,这种杠杆的效果并不是最好的。[1]我甚至认为这是一种最落后的杠杆。因为管理他人是一件非常复杂、极具挑战的工作,需要高超的领导技巧,弄不好管理者会落个众叛亲离、被手下生吞活剥的下场。[78]
劳动力杠杆指的是管理别人,这不是好杠杆。
资本是第二种相对较好的杠杆形式。资本杠杆就是用钱来扩大决策的影响力。[1]资本是一种更现代的杠杆形式,利用资本杠杆有一定的难度,需要一定的技能。在20世纪,人们曾经利用资本杠杆获得了惊人的财富。资本杠杆是20世纪杠杆的主要形式。
资本杠杆
遍览最富有的人群,你就会发现,最有钱的人是银行家,是腐败国家的政客,他们本质上都是可以动用大量资金的人。再看看大型公司的高层,除了科技公司,绝大多数老牌大型公司的首席执行官其实都在做财务工作。
他们可以动的钱多,非科技企业CEO其实做的是财务工作。
资本杠杆的放大效应非常明显。管理资本要比管理人更容易,因为随着资本的不断增长,其管理难度会远远低于管理不断扩张的团
队。
最后一种杠杆是最新出现的,也是普通人最触手可及的。这种杠杆就是“ 复制边际成本为零的产品”。
其中包括书籍、媒体、电影、代码。在所有不需要他人许可就能使用的杠杆中,代码可以说是最强大的一种——只需要一台计算机就够了。[1]
新杠杆
不要再把人分为富人和穷人、白领和蓝领了。现代人的二分法是“利用了杠杆的人”和“没有利用杠杆的人”。
杠杆和无杠杆
复制边际成本为零的产品是最值得研究的杠杆,也是最重要的杠杆。这是一种全新的杠杆形式,问世仅几百年。这种杠杆始于印刷机。广播媒体加速了其发展,而互联网和编程的出现更是使其产生了爆发式增长。不需要他人为你打工,也不需要他人给你投资,你就可以把劳动成果放大成百上千倍。
复制边际成本为0的产品是最值得研究的杠杆
本书就是一种杠杆。在过去,如果要分享我的理念,我就得坐在讲堂里,现场讲课,最多也就讲给几百个人听。[78]
书籍也是杠杆
这种最新形式的杠杆创造了全新的财富,创造了所有新晋亿万富翁。对上一代人来说,财富是由资本创造的,发大财的是沃伦·巴菲特这些搞投资的人。
而新一代富翁的财富都是通过代码或媒体创造的。乔·罗根的播客每年给他带来5 000万到1亿美元的收入。还有网络主播PewDiePie(菲利克斯),我不清楚他具体赚了多少钱,但肯定比新闻报道里说的还要多。当然,还有杰夫·贝佐斯、马克·扎克伯格、拉里·佩奇、谢尔盖·布林、比尔·盖茨和史蒂夫·乔布斯等等。他们的财富都源自基于代码的杠杆。[78]
记录这些杠杆
新杠杆最重要的特点之一就是,使用它们或获得成功都无须经过他人的许可。要使用劳动力杠杆,就得有人决定追随你。要使用资本杠杆,就得有人给你提供资金,你再去进行投资或开发产品。
而编程、写书、录播客、发推特、拍视频这些事情不需要经过任何人的许可。由此可见,新杠杆就像一个均衡器,极大地缩小了人与人之间的差距,让社会变得更平等。[78]比如,每个出色的软件开发者现在都有一大群机器人在为其工作。写好代码后,这些机器人就开始工作,在开发者睡觉的时候也在为其赚钱。[78]
靠出租自己的时间是永远无法致富的。
无论处于人生的哪个阶段,努力的目标都是不断提高自己的独立性,而不是升职加薪。拥有独立性,为自己独特的产出成果负责(而不是像打工一样为投入的时间负责),这才是最理想的状态。[10]
人类在不断进化。曾几何时,人类社会是不存在杠杆的。如果我帮你砍柴打水,那8个小时的劳动所产出的就只是8个小时的成果,投入与产出是相等的。后来人类发明了杠杆,发明了资本、合作、科技、生产力等各种手段,人类社会进入杠杆时代。在这样的时代,作为一名劳动者,只有最大化地发挥杠杆效应,才能利用有限的时间和体力产生巨大的影响力。
社会原来是没有杠杆的。
与一个没有利用杠杆的劳动者相比,利用了杠杆的劳动者的产出会增加成千上万倍。对利用杠杆的劳动者而言,判断力的重要性远超投入时间的长短和工作的努力程度。
别说把编程效率提高10倍了,提高1 000倍的情况也是真实存在的,只是我们没有完全认识到这一点——看看推特上值得关注的约翰
举例来说,一位优秀的软件工程师只需要编写一小段正确的代码、创建一个正确的小程序,就能为公司创造5亿美元的价值。但如果有10位工程师,投入了10倍的时间和精力,却可能因为选择了错误的模型、错误的产品、错误的编程方式,或者错误的病毒营销模式而白白浪费了时间。投入与产出之间存在不匹配性,特别是对那些利用了杠杆效应的劳动者来说。
杠杆利用的不对,就有可能导致浪费时间。
人生的一大目标应该是掌控自己的时间。理想的工作是利用杠杆效应的工作。在这种工作模式下,你可以掌控自己的时间,并能对自己的产出成果负责。如果你通过提供绝佳的解决方案给企业带来了神奇的转机,那么你必将得到金钱的回报。特别是,如果别人根本不知道你是如何做到的,他们就必须不断地付钱给你,让你继续提供这种产品或服务。而你之所以能够做到这一点,就是因为你的痴迷、技能或天赋。
如果你有专长,有责任感,又懂得如何利用杠杆效应,社会为你提供的金钱回报就会与你的价值相匹配。这时,你就能节省下更多时间,进而变得超级高效。你不需要为开会而开会,不需要努力表现自己,也不需要通过汇报材料体现你的工作量——你只要关注工作本身就可以了。
高效,只需要关注本身。
只关注工作本身,效率就会变得极高。你可以合理调配自己的工作,在精力充沛的时候工作,不在状态不佳的时候做无用功。这样你就能够赢得属于自己的时间。
每周工作40小时是工业时代的产物。知识劳动者的时间安排与运动员如出一辙,有训练和冲刺的时间,也有休息和重新评估的时间。
销售就是一个例子,特别是高端销售。房地产经纪人可能不是一个理想职业,因为竞争实在太过激烈。但是,如果能够成为一个集自我推销和房屋销售能力于一身的顶级房地产经纪人,那么当别人还在为卖出10万美元的公寓苦苦挣扎时,你可能只用1/10的时间就卖出了价值500万美元的豪宅。房地产经纪人的投入与产出存在不匹配性。
任何一款产品的构建和销售都是这样的,投入与产出不存在必然联系。世界上的工作本质上分为两种:存在杠杆的工作和不存在杠杆的工作。所以不要选择类似客服这样的支持性工作。这种工作投入和产出的关系相对紧密,产出主要取决于投入的时长。[10]
投入和产出之所以脱节,是因为工具和杠杆的存在。一个职业的创造性越高,其投入与产出的不匹配性越高。而投入和产出高度相关的职业很难创造财富,从事这种职业也很难给自己带来财富。[78]想加入一家伟大的科技公司,销售技能和构建技能必备其一。如果二者都不具备,那就去学习。
学会销售,学会构建。同时掌握这两种技能的人会势不可当。
销售和构建是两个非常宽泛的概念。构建产品很难,因为涉及多个变量,涵盖设计、开发、制造、物流、采购等环节,甚至还包括服务的设计和运营。因此,“构建”的定义非常多元。
每个行业都定义了各自的“构建者”。在我们科技行业,“构建者”是首席技术官,是程序员,是软件工程师和硬件工程师。即便是洗衣行业,也存在“构建者”。洗衣行业的“构建者”就是设计洗衣服务的人,是确保流程正常运转的人,是确保所有衣服在正确的时间被运送至正确地点的人,等等。
另一个概念是销售。销售的定义同样很宽泛。销售不一定是针对个体顾客销售产品,也可以指市场营销、媒体传播、人才招聘、资金募集、员工激励、公共关系等,涉及面非常广。[78]
用头脑赚钱,而不是用时间赚钱。
还是以房地产行业为例。在房地产行业,最低级的工作莫过于做房屋维修。维修师傅按老板要求,早上8点到客户家里开始干活,每个小时能挣10到20美元。这里不存在任何杠杆效应。维修师傅需要承担一定的责任,但并不是真正的责任,因为他只需要对老板负责,不需要对客户负责。维修师傅没有任何真正的专长,因为他干的活很多人都会干。所以,做房屋维修挣不到什么钱。出售自己的技能、出租自己的时间,得到的报酬只能比最低工资略高一点儿。
往上一层是为业主修建房子的承包商。他们承包项目的合同金额可能是5万美元,给工人开出的工资是每小时15美元,他们把中间的差额装进了自己的腰包。
做承包商显然比做维修工人更好。但怎么衡量好与不好呢?怎么知道其中的差别呢?之所以说做承包商更好,是因为承包商需要承担一定的责任。承包商需要对结果负责。如果项目进展不顺利,他们会夜不能寐。承包商请工人来干活,获得了劳动力杠杆。他们也拥有更多专长,比如如何组织团队,如何确保团队按时完成任务,如何处理与城市管理相关的法律问题,等等。
再往上一层是房地产开发商。开发商做的事情就是买入房地产,雇用承包商通过改造提高房产价值,然后出售房产,获得利润。他们最开始可能需要以贷款或向投资者募资的方式买下房地产,然后拆除重建,进行销售。工人每小时能挣15美元,承包商一个项目能赚5万美元,而开发商的收入远不止这些。他们低价买入,高价卖出,除去建筑费用,还能赚取50万美元甚至100万美元的利润。这时需要注意了:
开发商需要做什么呢?他们需要做的就是承担重大责任。
开发商要承担更多的风险和责任,在拥有更大杠杆效应的同时,他们也需要拥有更多专长。他们需要了解融资方法、与城管相关的法律法规、房地产市场的走向等等,也需要判断风险是否值得承担。其工作难度比承包商要大得多。
再往上一层是房地产基金经理。房地产基金经理拥有巨大的资本杠杆。他们与许许多多开发商打交道,囤积了大量房屋。[74]
再往上一层可能是这样一个人:他想在房地产市场上发挥最大的杠杆效应,拥有最多的专长。这个人会说:“我了解房地产的方方面面,从基本的房屋建设到物业和销售,再到房地产市场的运转规律和繁荣周期。我同时也了解科技行业,知道如何招募开发人员,如何编写代码,如何构建一个好产品,我也知道如何获得风投,如何取得回报,对科技和金融的运转方式了如指掌。”
但很显然,这不现实,因为没有一个人拥有这么多知识。要实现目标,可以把具备不同技能的人才聚到一起,组成团队。这样,团队成员联手就拥有了在科技和房地产领域的专长。这样一个高风险、高回报的做法意味着公司将承担巨大的责任,同时也承担了重大的风险,因为创业者会把全部时间和精力投入其中。公司会聘用大量开发人员,这是代码杠杆。被吸引来的投资和创业者初始投入的资本构成了资本杠杆。公司同时雇用了行业顶尖人才,例如优秀的工程师、设计师和营销专家等,这是劳动力杠杆。
开发人员代表代码杠杆,因为开发人员离职之后,代码依然能被公司所用。
把具备不同能力的人聚集到一起。
最终的结果可能是打造出类似房地产搜索引擎Trulia、互联网房产中介网站Redfin或免费房产评估网站Zillow这样的公司,财富创造潜力可能有数亿甚至数十亿美元。[78]
随着层级不断向上,杠杆效应愈加明显,责任愈加重大,需要的专长也越来越多。在劳动力杠杆的基础上增加资本杠杆,在劳动力杠杆和资本杠杆的基础上增加代码杠杆,通过这种方式,创业规模越来越大,也越来越接近拥有所有上行潜力,实现价值极值,而不再仅仅是领取薪水那么简单。
以领取月薪的打工者为起点,志存高远,不断提升目标,努力获得更多杠杆效应,承担更多责任,学习更多专长。将这些结合起来,再加上复利效应的神奇作用,假以时日,你就可以变得非常富有。[74]
唯一需要避免的就是身败名裂的风险。
避免身败名裂的意思就是不要锒铛入狱。所以,不要做任何违法违纪的事情,任何事都不值得拿自己的自由和声誉去冒险。要避免一败涂地的灾难性损失。避免身败名裂也意味着不要做那些可能会威胁自身安全或健康的事情。你必须照顾好自己的身体。
不要做可能会让你全盘皆输的事情。不要孤注一掷、铤而走险。
相反,要把赌注押在那些胜算较大、能带来巨大利益的事情上。[78]用判断力赚钱要获得更多的自由时间,就要对选择的专业领域、工作性质、职业路径以及与雇主达成的交易类型做出审慎的判断。一旦做出正确的决策,你就无须担心时间管理的问题了。于我而言,我希望单纯靠判断力来获得报酬,而不是靠劳作。我想让机器人、资本或计算机完成实际工作,而我只靠判断力赚钱。[1]
靠判断力赚钱
做出正确决策,就无需担心时间管理问题。
不要去做那些一旦失败就代价非常大的事情。
我认为每个人都应该立志掌握某些领域的专业知识,并以此赚取经济回报。如果能够在实际工作中最大化地利用杠杆,无论是机器人、计算机,还是其他任何人或技术,那么我们都可以成为自己时间的主人,因为没有人会考核我们在工作中投入了多少时间,我们只需要对自己的产出负责。
没有人考核投入了多少时间,只需要对自己的产出负责。
可以想象,对一家市值1 000亿美元的公司而言,如果在判断准确率为75%和85%的两个人之间选择,那么公司会愿意支付5 000万美元、1亿美元,甚至2亿美元聘请准确率更高的人担任决策者。因为多出的10%的判断力对于引导企业的方向极具价值。首席执行官的报酬之所以很高,就是因为杠杆效应。在判断力和能力上,毫厘之差都会有天壤之别。[2]
CEO就是靠判断力赚钱
在实际操作中展现出色的判断力,拥有可信可靠的判断力,这一点非常关键。巴菲特之所以被称为“股神”,是因为他的可信度极高。
他对自己的业务极为负责,一次又一次在公开场合做出正确的判断。
他以高度正直著称,赢得了社会的充分信任,加上他判断力出色,所以人们敢在他身上押上不计其数的筹码。没有人问他工作有多努力,没有人问他几点起床、几点睡觉。大家都说:“巴菲特,你只要把业务搞好就行了。”
对自己的判断力负责。
下判断的时候要非常注意
拥有可靠的判断力
要具有出色的判断力——尤其是经过实操验证的判断力,以及高度的责任感和优秀的业绩记录,这几点至关重要。[78]
普通人把时间浪费在短期思考上,浪费在毫无价值的繁重工作上。而巴菲特会用一年斟酌判断,然后用一天采取行动。他一天的行动可以影响未来几十年。
只要在优秀的基础上稍微提高一点儿,做到卓越(比如把完成1/4英里[1]的短跑成绩提高零点几秒),经济回报就会呈数量级增加。而杠杆效应进一步放大了经济回报的差异。在杠杆时代,在自己的领域做到极致非常重要。[2]
在自己的领域做到极致
[1]1英里≈1.61千米。——编者注
分清主次,聚焦重点一路走来,我屡受挫折。我赚到的第一桶金被我在股市瞬间赔光。第二桶金刚到手,就被生意伙伴骗走了。事不过三,第三次,我终于赚到了一点儿。
即使在那个阶段,我的财富累积也是不温不火,一直都需要格外努力。我从未一次性赚到一大笔钱,都是积少成多,更多是通过持续不断地创办企业、创造机会和开展投资来创造财富,而不是毕其功于一役。我的个人财富也不是在关键的一年迅速累积起来的,而是积水成渊:持续创造更多选择、更多业务、更多投资,探索更多在我能力范围内的事情。
互联网带来无限机遇。说实话,现在我有太多赚钱的方法,只是时间不够用。我头脑里赚钱的点子都能从耳朵里溢出来,只是没有时间去实现。有太多方法可以创造财富、打造产品、创建企业,而获得社会的经济回报只是这些方法的副产品。我只是没有那么多时间和精力把所有想法付诸实践。[78]
赚钱点子多
给自己的时间设定价格,用时薪计算时间价值。如果用花钱的方式节省的时间价值更高,那就花钱,不要犹豫。要想真的赚到钱,先要相信你自己很值钱。
没有人会比你更看重自己。你要做的就是给自己设定一个极高的时薪,并坚持执行。即使在我年轻的时候,我也认为自己的时间比市场的定价更值钱,并一直遵循这个思路。
在做决策时,你要把时间作为一个考虑因素。做这件事需要多长时间?假设一个东西需要花费你一小时车程才能拿到,如果你给自己设定的时薪是100美元,那么这一趟基本上等于花掉100美元,你还要亲自去拿吗?[78]
从现在开始快进,一直到未来自己财务自由的那一天,其间为自己选择一个折中的时薪。拿我来说,你肯定支付不起我现在的时薪,但即使在我年轻那会儿,10年前,甚至20年前,当我还没什么钱的时候,你也雇不起我。当时,我就一遍又一遍地告诉自己,我的时薪是5 000美元。今天回想起来,我当时的时薪实际上是1 000美元左右。
那么我的时薪是。。。
当然,我也做了一些蠢事,比如跟电工吵架,要求退还坏掉的扬声器,等等。我根本不应该做这些浪费时间的事情,虽然朋友们浪费时间的次数比我多得多。我应该直接把东西扔掉或捐掉,而不是退换货;我应该找人帮我修理,而不是自己修。
大佬不纠结这些
不管是以前谈恋爱的时候,还是现在已经结婚了,我都会经常跟伴侣争论:“我不做,这个问题不是我能解决的。”即使母亲让我做点儿小事,我也会跟她争论。很多事情我是不会亲自去做的。我宁愿花钱给她雇个人。即使是没钱的时候,我也是这样做的。[78]
有个性
要从时间成本的角度做决策,如果做某件事外包的成本低于时薪,那就外包;如果不做的损失低于时薪,那就不做;如果花钱请人的成本低于时薪,那就花钱请人。甚至做饭也是同样的道理,你可能想吃健康的家常菜,但是如果可以外包,那就外包吧。[78]大胆地为自己设定一个很高的时薪,并坚持执行。一个理想的时薪应该高到近乎离谱的程度,如果不是这样,那就还不够高。无论你选择的时薪是多少,我都建议你进一步提高。就像我说的,即使是没钱的时候,我也有很长一段时间把5 000美元作为自己的时薪标准。如果换算成年薪,那就是每年几百万美元。
这里比较有争议,因为很多事情比如照顾家里人是不能外包的
假设时薪1000 人民币,那么浪费一个小时就是浪费一千块。
做饭也外包
有意思的是,现在我觉得自己的时薪实际上超过了这个目标。我其实比较懒散,并不是工作最努力的那个人,但如果遇到自己想做的事,我就会能量爆棚,全身心投入。如果用实际投入的时间来计算收入,那么我的时薪比上面的数字要高得多。[78]
你说过:“如果你内心鄙视财富创造,财富就会对你避而远之。”可以解释一下吗?
如果爱慕虚荣、事事攀比,当遇到比自己好的人时,你就会心生讨厌,甚至心怀忌恨。与别人进行商业合作,如果你对对方有任何负面的想法或评价,他们就会感受到。人类与生俱来就能感知其他人内心深处的感受。因此,做人必须摆脱攀比心态。[10]
必须摆脱攀比
摆脱攀比心
毫不夸张地说,仇富心理会阻碍你致富,因为你没有正确的心态和精神状态,也无法在正确的层面上与人交往。保持乐观,积极向上,这种态度非常重要。从长远看,乐观主义者往往会取得更好的发展。[10]
仇富心理会阻碍你致富
在商业世界里,大多数人在玩零和游戏,少数人在玩正和游戏,他们在人群中寻找志同道合者。
这世上的游戏不外乎两种。第一种是金钱游戏。金钱不能解决所有问题,但可以解决所有和金钱有关的问题。大家都明白这一点,所以每个人都想赚钱。
但与此同时,许多人内心深处觉得自己是赚不到钱的,所以,他们不喜欢看到创造财富的故事。他们会攻击整个商业体系,宣称“赚钱是邪恶的,不应该赚钱”。
但其实他们在玩第二种游戏,这种游戏叫地位游戏。他们之所以说“我不需要钱,我不想要钱”,是因为他们想占领高地,让别人高看一眼。地位就是一个人在社会等级中的位置。[78]
在人类进化史上,财富创造是近代才出现的活动,是一个正和游戏。而地位之争自古有之,是一个零和游戏。那些攻击财富创造的人往往只是为了追求地位。
创造财富是正和游戏,地位是零和游戏。
地位这个零和游戏非常古老。猴子在没有进化成人的时候,就已经开始玩地位游戏了。地位游戏是讲究等级的。谁排第一?谁排第二?谁排第三?三把手要想成为二把手,二把手的位子就必须先空出来。因此,地位游戏是零和游戏。
政治游戏就是地位游戏的一种。体育竞赛也是一种地位游戏,有赢家,就必定有输家。从根本上说,我并不喜欢地位游戏。地位游戏在社会中扮演着重要角色,因为我们需要知道谁说了算。但是,从本质上说,人们之所以玩地位游戏,是因为地位游戏是社会发展的必要之恶。[78]问题的关键在于,要想在地位游戏中获胜,就必须击败他人。这就是为什么应该避免在生活中玩地位游戏,因为这个钩心斗角、损人利己的游戏会让人变得心态失衡、易怒好斗,你会一直以贬低对手、打败他人为己任,从而让自己和自己喜欢的人上位。
地位游戏勾心斗角
地位游戏会一直存在,这是无法回避的。当你努力创造财富时,你可能会受到别人的攻击。这时,你需要意识到,大多数时候,他们是在试图牺牲你以提高自己的地位。他们玩的是另一个游戏,是一个不可取的游戏,因为它是一个零和游戏,而不是一个正和游戏。[78]
不要跟他们玩零和游戏
玩愚蠢的游戏,就只能赢得愚蠢的奖品。
对初出茅庐的年轻人来说,最重要的事情是什么?
最重要的是,要在重大决定上花更多时间。人生早期有三个重大决定:在哪里生活,和谁在一起,从事什么职业。
在开启一段亲密关系之前,我们总是很少花时间深思熟虑。我们把大量时间用于工作,> 却很少花时间想清楚自己应该从事什么样的工作。居住的城市几乎可以完全决定一个人的生活轨迹,但我们很少花时间认真思考哪个城市更宜居。
一位年轻的工程师在考虑要不要搬到旧金山,我建议他思考这个问题:“你想离开你的朋友吗?你想形单影只吗?”如果你将在一个城市生活十年,一份工作干上五年,或者跟一个人相伴十年,你就应该先花一到两年的时间认真思考再做决定。这些都是非常重大的决定,是人生的三大关键决定。
对于重要的问题,你应该放下手头所有的事情,专门拿出时间认真思考。而以上可能是人生最重要的三个问题。[1]
想要做到与成功人士为伍,你认为最重要的一件或两件事是什么?
找到自己擅长的领域,然后用自己的技能去帮助他人:提供免费的产品或服务,主动向世界传递善意。好人终有好报。只要始终如一,假以时日,付出就一定能获得相应的回报。但不要计较自己付出了多少——一旦开始计较,耐心就会被消耗殆尽。[7]
曾有上司告诫我:“你永远发不了大财。因为你的聪明显而易见、有目共睹,所以一直会有人给你提供‘刚刚好’的工作机会,让你觉得弃之可惜。”
你初次创业的决定是如何做出的?
我当时在一家名为家庭网络的科技公司上班,我跟老板、同事、朋友、身边的每个人都说:“硅谷的人都在创业,看起来他们能成功。
我也要开公司,我只是暂时在这里上班,其实我是个企业家。”
这不是我的什么策略,我也没有认真做什么规划。
我只是跟他们坦诚相待,把自己的真实想法大声说出来,实际上我并没有采取行动。那是1996年,当时创业还是一件难度系数很大的事情,非常需要勇气。然而,后来大家都开始问:“你怎么还在这里上班?你不是说要去开公司吗?”“天哪,你怎么还没走。”我实在是尴尬,迫不得已才离开公司走上创业之路。[5]
原来最开始只是因为被问得尴尬,大佬年轻的时候也没有自己的想法。
是的,我知道有些人从未想过自己创业。社会的普遍共识是,给别人打工才符合常理,才是明智的选择。但仔细想想,这种长久存在的观点究竟是如何产生的?这种想法本身就带有明显的等级色彩。[14]找到如玩耍般的工作在人类社会形成之初,每个人都扮演着狩猎者或采集者的角色,自己劳动养活自己。农业社会伊始,社会等级开始形成。工业革命和工厂的出现极大地强化了社会的等级划分,因为没有人可以凭一己之力拥有或建立一家工厂。但由于互联网的诞生和发展,现代社会越来越回归到每个人为自己劳动的时代。我宁愿成为一个失败的创业者,也不愿成为一个从未尝试过创业的人。因为,即使是一个失败的创业者,也拥有独立打拼的技能。[14]
记一个书友的分享:分享我之前学到的: 尽可能多的跟这个世界打交道“没有失败,只有反馈”,“要么得到,要么学到”
宁愿成为一个失败的创业者,也不愿意从未尝试过创业的人。
地球上有70亿人。我希望有一天也会有70亿家公司。
我学会了如何赚钱,因为钱是生活必需品。当赚钱的必要性消失后,我就不再关心钱的问题了。至少对我个人来说,工作是达到目的的一种手段。当然,赚钱也是达到目的的一种手段。但跟赚钱相比,我对解决问题更感兴趣。
已经财富自由的人。
任何终极目标被实现后,都会有新的目标出现,这个新的目标又会带来下一个新的目标。生活就是由一个又一个游戏组成的。一个人不断成长,从小到大玩上学游戏,玩社交游戏,玩赚钱游戏,玩地位游戏。至少对我而言,这些都是某种意义上的游戏,只是游戏的影响愈加深远。既然看透了游戏这一本质,结果就不那么重要了。
生活是由一个个游戏组成的。
看透游戏,就会厌倦游戏。我已经到了厌倦游戏的阶段。我认为没有什么终极目标或目的。我只是遵从内心的感受和想法,过好每一天。我是真的只活在当下。
遵从内心,活在当下。
我不想无休止地追求更多享乐。[1]其实,生命中最宝贵的是自由。你不想再为钱而烦恼,对吧?我觉得这很好。不管是通过降低生活标准还是通过拼命赚钱,一旦摆脱了金钱问题的困扰,你就可以退休了。我说的“退休”不是说到了65岁,在养老院领取退休金。我对“退休”有不一样的定义。
一旦摆脱了金钱问题,你就可以退休了。
你对退休的定义是什么?
退休就是不再为了想象中的明天而牺牲今天。当你能活在当下,内心充盈地度过每一天时,你就达到了退休的状态。
不再为了想象中的明天而牺牲今天。
如何达到退休状态?
第一种方法是存钱。只要存款够多,被动收入(不用动一根手指)就能满足开销。
第二种方法是把开销降为零——出家修行。
第三种方法是做自己热爱的事情,完全乐在其中,有钱没钱无所谓。所以,实现退休状态有很多种方法。
第三种还挺容易实现一些。
避开竞争陷阱的方法就是做独一无二的自己,找到自己能做到独步天下的事情。做到最好,只因热爱。如果你真的热爱一个事物,那就追随本心,努力找到利用它满足社会真实需求的切入点,利用杠杆效应扩大规模,以个人名义担起责任。这样,在承担风险的同时,你也将获得相应的回报,拥有自己所提供产品或服务的所有权或股权,然后持续精进。[77]
记录网友分享:作者的创富逻辑:热爱→需求→杠杆→承担
做独一无二的自己
财务自由后,你赚钱的动力下降了吗?
下降了,也没下降。说“下降”了,是因为缺钱带来的绝望感已经消失,压力变小了。
说“没下降”,是因为在现阶段,创业和赚钱于我而言更像是一门“艺术”,乐趣更多了。[74]
对于纳瓦尔来说赚钱是一门艺术。
无论是在商业、科学还是政治领域,青史留名的总是那些艺术家。
艺术就是创造。艺术的目的和关注点在于创作本身,是因为喜好、喜欢而创作,是为了自娱、自赏而创作。试想一下,生活中有哪些事情能像艺术创作那样只是以其本身为目的,而没有任何其他目的?我可以想到三个例子:毫无保留地爱,随心所欲地创造,无忧无虑地玩耍。对我来说,创业就是玩耍。我创业是因为创业本身很有趣,是因为我喜欢某个产品。[77]
我可以在三个月内创建一家新企业——筹集资金、组建团队、启动业务,感觉就像玩游戏一样轻松愉快。能够从无到有打造一个东西,对我来说是一件特别享受的事情,赚钱反而成了副产品。对创业这个游戏,我越来越得心应手。在这个过程中,我的动机也发生了变化。以前创业是为了实现某个目标,现在是为了把企业做到极致,使之成为精美的艺术品。有意思的是,我觉得现在反而比以前做得好多了。[74]
我决定给某个公司或项目投钱,也是因为喜欢其中的参与者。我跟他们在一起觉得很愉快,总能从他们身上学到东西,而且很喜欢他们的产品。如今,我会因产品没意思而放弃一些回报率很高的投资机会。
找到像玩耍一样的工作并不是一个非此即彼的选项,我们可以且行且思,逐步向目标靠近。
年轻的我无比渴望赚钱,只要能赚钱,我就什么都愿意做。如果那时有人问我愿不愿意做污水运输的生意,我肯定会说:“好啊,我想赚钱!”万幸的是,从来没有人给过我这个机会。我很庆幸自己走上科技这条我真正喜欢的道路,这让我能够把职业和爱好结合起来,鱼和熊掌兼而得之。
我永远都在“工作”。但是,别人眼里的工作于我而言就像是玩耍。正因如此,我才确信没有人可以在我的领域与我匹敌。因为我觉得工作就是玩耍,所以我可以一天玩16个小时。如果有人想跟我竞争,那么他们肯定会输,因为他们不可能一周工作7天,每天工作16个小时。[77]
但是他那些玩耍怎么产生价值呢
赚到多少钱会让你有安全感?
钱不是万恶之源。钱本身是无罪的,真正有害的是对钱的贪欲。
从道德层面看,追求金钱并不是坏事,它跟人品没什么关系,但是,贪欲对人是有害的。
对钱的贪欲之所以有害,是因为欲望是个无底洞。贪念会一直占据你的心灵,让你无法自拔。热爱金钱,赚取金钱,本身无可厚非,但关键是赚的钱再多也永远不会感到满足。人之所以永远不会感到满足,是因为欲望这个开关一旦被打开,就不会在某个具体数字面前自动关停,正所谓欲壑难填。所以,不要以为赚到某个数额的钱,人自然就会满足了、停手了。
当然,对贪欲的惩罚也是与金钱相伴相生的。赚到钱的人只会想要更多,他们会变得敏感、多疑、偏执,害怕失去眼下拥有的一切。
天下没有免费的午餐,每个人都要为自己的贪欲买单。
赚钱的目的是解决财务问题,满足物质需求。我认为,摆脱金钱贪念最好的办法就是,赚了钱之后不要升级自己的生活方式。赚到钱的人往往会自然而然地提高生活水准。假设你一次性赚到一大笔钱,而不是靠日积月累。此时你依然保持着原有的生活方式,还没来得及升级,你的金钱就会远远超出你的实际需求和欲望,这反而让你达到一种财务自由的状态。
还有一点对我有所裨益:我把自由看得高于一切。我说的自由是多种多样的:想做什么就做什么的自由,不想做什么就不去做的自由,不受自我情绪或外界影响的自由,等等。自由是我最珍视的价值。
从某种程度上说,金钱可以买到自由,这当然很好。但是从某种程度上说,金钱也会有损于我的自由,这一点我并不喜欢。[74]任何游戏的赢家都是那些沉迷于游戏的人,即使获胜的边际效用越来越少,他们也会继续玩下去。
我必须创办一家公司才能获得成功吗?
硅谷最成功的人分为两类。第一类是做风险投资的人,因为他们非常多元化,控制着曾经是稀缺资源的东西。第二类是极为擅长识别公司发展阶段和前景的人。这些人会精准地找到下一个多宝箱或爱彼迎,在公司的产品和服务刚刚与市场需求相衔接时加入它们。这些人拥有公司扩大规模急需的背景和专业知识,也能找到合适的引荐人。
就是那些本来在谷歌,却在脸书仅有100个员工时加入脸书,又在在线支付服务商Stripe刚发展到100人时加入Stripe的人吗?
扎克伯格在刚开始扩大公司规模时完全不知所措,他给吉姆·布雷耶(风险投资家和风投公司Accel Partners的创始人)打电话说:“我不知道该怎么做。”吉姆·布雷耶说:“我认识一个非常出色的产品主管,你需要他。”这个例子说明了专业知识和引荐人的重要性。在长期风险调整的基础上进行对比,这些专业人士的经济回报往往会超过风险投资者。[30]
我在硅谷见过的最成功的人往往在职业生涯早期就实现了突破,比如被提升为副总裁、董事或首席执行官,有些人转去创业也很快就实现了良好的发展。如果年轻时没有在职务上有所突破,职业生涯后期就很难后来居上。所以,在小公司创立之初就加入是一个不错的选择,因为此时没有那么多阻碍提前晋升的硬性条件。[76]
对刚刚开启职业生涯的人来说(甚至稍晚阶段的人也一样),最重要的资源是公司能给你带来的人脉资源。要思考一下自己会跟什么样的人共事,他们将来会如何发展。[76]如何获得运气你为什么主张“不要靠运气发财”?
如果有1 000个平行宇宙,你会想在999个宇宙中成为有钱人。你不想因为在一些宇宙中运气好,就腰缠万贯,也不想因为在另一些宇宙中运气差,就穷困潦倒。所以,在获得财富的过程中,你要排除“运气”这个不可控因素。
但是运气好的确有利于赚钱,对吗?
就在最近,我和我的联合创始人巴巴克·尼维在推特上讨论了运气这件事。我们讨论的运气其实分为四种。
第一种运气是不期而遇的运气,一个人的好运完全源于他控制范围之外、意料之外的事情,比如获得意外之财、遇到贵人等等。
第二种运气源于坚持不懈、孜孜不倦、屡败屡战、不断尝试,是靠个人主动创造机会获得的。你释放了大量能量,使出浑身解数,移山倒海,一往无前。就好像在做科学实验,把不同的试剂混合在一起,看看能产生什么结果。因为你不懈地努力,不停地奋进,不断地释放能量、积蓄力量,所以好运找到了你。
第三种获得好运的方式就是善于发现好运。如果你在某个领域技艺娴熟、经验丰富,那么当这个领域实现了意外突破时,你就会在第一时间洞悉,这时,其他不熟悉这个领域的人会无动于衷。这就是增加对好运的敏感性,幸运会眷顾有准备的大脑。
第四种运气是最奇妙、最难得的一种,那就是打造独特的个性、独特的品牌、独特的心态,让运气找到你。
第一种,预期之外的好运.第二种,坚持不懈尝试出来的.第三种,对一个行业比较了解,知道好运在哪.第四种,独特的个性,品牌,心态,让好运找到你.
例如,假设你是世界上最好的深海潜水员。大家都知道你会去做别人都不敢尝试的深海潜水。有人碰巧在他们无法到达的海岸附近发现了一艘沉没的宝船。这个时候,他们的好运也会成为你的好运,因为他们得请你帮忙打捞,而你会因此得到报酬。
这个例子比较极端,但道理是一样的。有人纯靠运气发现了宝藏。他们过来找你挖宝,并分你一半,这就不是完全靠运气了。是你的潜质创造了自己的好运。其他人没有给自己创造机会,而你把自己放在了一个可以利用运气或者吸引运气的位置。有果必有因,为了不靠运气致富,你就需要找到确定的因果关系,而不是听天由命。[78]
优秀的程序员,在商人发现互联网的商机的时候,就会找上门来.
获得好运的方法:
因果关系如此确定,所以运气就不再是运气了。所谓运气其实就是必然的结果。第四种运气总结一下就是,以某种方式塑造自己的性格,之后就由性格决定命运。
我认为,赚钱很关键的一点就是知名度和信誉度,也就是说,大家要知道你、信任你,这样人们便会通过你达成某些交易。前面举了潜水员的例子,由于你的潜水技能非常出色,知名度很高,寻宝的人会主动来找你,并分给你一些宝藏,以换取你的技能。
再进一步,如果你值得信赖,做事靠谱,诚信正直,目光长远,那么其他人在跟陌生人合作时,保险起见,他们会选择通过你来达成交易。他们会主动找到你,分给你一部分好处,仅仅因为你已经建立了诚信可靠的声誉。
巴菲特会源源不断地收到交易邀约,请他收购公司,购买认股权证,纾困银行,为他人之所不能为,而这一切都因为他的声誉。当然,他还有责任感和强大的品牌。
人品和声誉是可以自己建立的。一旦有了人品和声誉,你就会有很多机会。别人认为你是运气好,但你知道那不是运气,而是人品。
[78]我的联合创始人尼维说过:“在一个长线游戏中,似乎每个人都在
让彼此变得富有。而在一个短线游戏中,似乎每个人都在让自己变得富有。”
我觉得这个说法非常精准。长线游戏是正和游戏,我们在一起做蛋糕,把蛋糕越做越大。而短线游戏只是在分蛋糕。[78]
长线游戏,人类发展也是这样的,种植业越发达,种植的果实收获越多。
社交有多重要?
我认为商业社交纯属浪费时间。我知道有很多人和公司在推广“打造社交网络”这个概念,因为这符合他们的利益,能为他们的商业模式服务。但事实上,如果你建造的东西很有意思,那就会有更多人想要了解你。在经营业务之前先试图建立业务关系完全是在浪费时间。我的人生哲学会让人觉得更舒适:“做一个创造者,创造出人们想要的有趣的东西。展示你的技能,练习你的技能,最终会有合适的人找到你。”[14]
做一个创造者
如何确定一个人是否值得信赖?你会关注哪些信号?
如果一个人大谈特谈自己有多诚实,那么他很可能是不诚实的。
这只是我学到的一个小小的警示信号。当一个人不断宣扬自己的价值观,或者自我吹嘘时,那就意味着他在掩饰什么。[4]
鲨鱼吃得很好,但是过着被鲨鱼包围的生活。
我的生活中有一些极为成功、极具魅力的人(每个人都想成为他们的朋友),他们也很聪明。然而,我也看到他们做了一两件对别人不太好的事情。第一次看到,我会跟他们说:“我觉得你不应该这样对他。我这么说不是因为你会因此受到惩罚。我相信你这次能全身而退,但这件事最终会反噬你。”
我并不是想说“宇宙是平衡的”“世上存在因果报应”这样的话,而是认为我们在内心深处都知道自己是谁。你是瞒不过自己的。你的失德会深刻影响你的心智模式,你的过往对你是清晰可见的。如果你有太多道德缺陷,你就不会尊重自己。人活在这个世界上最糟糕的结果就是没有自尊。如果连你都不爱自己,那么还有谁会爱你呢?
瞒不过自己
我认为,做人要谨慎,不要做一些让自己觉得不光彩的事情,因为这些事最终会伤害到你。第一次有人这样做,我会警告他们。当然,江山易改,本性难移。他们自然没有做出改变。这时我就会和他们保持距离。我把他们从我的生活中抹去。我脑子里有这样一句话:“你越想接近我,你的价值观就必须越正确。”[4]保持耐心随着年龄和阅历的增长,我逐渐发现,只要有足够的耐心,优秀的人就会成就一番大事业(至少在硅谷的科技行业是这样的)。20年前,我的职业生涯刚刚开启。当时我遇到一些出类拔萃的年轻人,我被他们的聪明才智和敬业精神深深折服。这些人无一例外都在随后的发展中获得了巨大的成功。大凡优秀之人,假以时日,都会大放异彩。这个时间期限可能比你想象的要长,也可能与他们自己的预期不符,但是,是金子总会发光。[4]
有足够的耐心
不要做一些不光彩的事情
运用专长,结合杠杆效应,最终,你的才华和努力会得到相应的回报。
成功需要时间。即使万事俱备——你已经把成功所需的各个要素收入囊中,需要投入的时间也具有不确定性。而如果一直在掐算时间,在成功真正到来之前,你的耐心就会被消磨殆尽。
不必一直掐算时间
人人都想一夜暴富,但世界的运行遵循由量变到质变的规律,大自然的法则是春播秋收,极少有事情是立竿见影的。时间的投入是必需的,所以我认为,你需要做的就是拥有专长,有责任感,有影响力,利用杠杆效应,获得独步天下的技能组合,在自己的专业领域做到首屈一指。
专长,责任感,影响力。
对自己热爱的事物孜孜不倦,乐此不疲,不断精进,日积月累。
不要去计算自己投入的时间和精力,因为一旦开始计算,你就会失去
耐心。[78]
在最常见的劝诫中,我觉得最没有说服力的一个就是:“你太年轻了。”自古英雄出少年,只是他们的贡献在人生的后期才得到承认。亲身实践是获得真才实学的唯一途径。要虚心求教,莫等闲,白了少年头。[3]
亲身实践是获得真才实学的唯一途径。
江山易改,本性难移。所谓“性格决定命运”,就是一个人不断重复自己的行为模式,好的坏的、优点缺点,最终会得到与自己的行为相对应的结果。
始终主动付出、不断奉献,不要斤斤计较、患得患失。
“但行好事,莫问前程”不容易,不仅不容易,而且难于上青天。“只求付出,不求回报”是人生中最难做到的一件事,但也是让人收获最大的一件事。那些从小锦衣玉食、游手好闲的人,很难找到人生的意义和价值。
人生真正的履历,其实就是一生所承受痛苦的集合。如果临终前要直面真正的自我,回顾这一生做过哪些有意义的事,那么你能想起来的一定都是你所做出的牺牲和迎接过的挑战。
你从这个世界得到的任何东西都不过是身外之物,生不带来死不带去,于你而言并不重要。一个人有健全的四肢,有聪明的大脑,这些受之于父母的东西才是真正属于你的。无论如何,我们都要迎难而上,在这个过程中创造生命的意义。其中,创造财富可以是人生的一个目标。不懈奋斗吧。当然,奋斗不易,甚至可以说难之又难,但有志者事竟成,奋斗成功的人数不胜数,我们学有榜样。[77]
迎难而上
在物质世界里,金钱不能给人带来快乐,不能解决人的健康问题,不能让所有家庭变得美满和睦,不能让人免受情绪波动的困扰。
但金钱可以买到自由,可以解决许多外在的问题。所以,赚钱是一个合情合理的奋斗目标。[10]
金钱买到自由
赚钱能改善一个人的经济状况,可以消除一系列可能阻碍幸福的因素,但金钱本身并不能给人带来幸福。据我所知,很多超级富豪幸福感极低。大多数时候,为了赚到钱,他们必须承受极大的身心压力,毫不懈怠地努力工作,拼命保持自己的竞争力。即使这样坚持20年、30年、40年、50年,突然有一天实现财务自由了,你也无法在短时间内调整心态。因为你已经把自己磨炼成一个极度焦虑的人。有钱后,你必须重新学习如何获得幸福。[11]
超级富豪幸福感极低
我们还是先说“致富”。对于赚钱,我一直秉持务实的态度。释迦牟尼本来是一个王子,自幼过着锦衣玉食、无忧无虑的生活,之后出家苦行修道。
在过去,要想获得内心的宁静,可以选择出家,抛妻弃子,舍弃金钱和地位,切断与尘世间的一切联系,孑然一身,独自修行。也就是说,你必须放弃一切才能获得内心的自由。
现在不一样了,因为我们有了这个叫“钱”的神奇发明,而且还能把它存放在银行账户里。一个人努力工作,为新的社会需求提供解决方案,为社会做出杰出贡献,社会就会以金钱为回报。你可以把钱存进银行,也可以量入为出,把生活水准保持在略低于收入的水平上。
这样,即使身处俗世,你也可以拥有一定的自由。
金钱可以赋予你追求内心平静和幸福的时间和精力。我觉得,让每个人都开心的方法就是满足他们的欲望。
让每个人都富裕起来吧。
让每个人都健健康康吧。
让每个人都快快乐乐吧。[77]
我很惊讶许多人竟然把财富和智慧混为一谈。
现在有钱就可以自由
第二章 增强判断力
真正聪明的人,从不走捷径。
判断力在人的一生中,如果想赚尽可能多的钱,如果想以一种可预测的方式致富,就要时刻走在时代的最前沿,学习科技、学习设计、学习艺术,成为行业翘楚。[1]
如果用可预测的方式,就一直走在时代前沿.
把时间花在省钱上是不会致富的。
省出时间来赚钱才是正确的思路。
努力的作用被大大高估了。在现代经济中,工作的努力程度并没有那么重要。
那什么被低估了呢?
判断力。判断力被低估了。[1]
判断力被低估了
你能给判断力下个定义吗?
我对智慧的定义是“知道个人行为的长期后果”,用于解决外部问题的智慧其实就是判断力。或者说,智慧和判断力是高度关联的:一个智慧而富有判断力的人,首先要知道个人行为的长期后果,然后做出正确的决策并付诸行动。[78]
智慧的定义是知道个人行为的长期后果,用于解决外部问题的智慧就是判断力
在杠杆时代,一个正确的决策可以帮你赢得一切。
不付出努力,就无法培养判断力,也不会获得任何杠杆。
时间的投入是必需的,但判断力更重要。在前进的过程中,方向比速度更重要,特别是运用了杠杆以后。在每个岔路口选对方向,其重要程度要远远超过前进的努力程度。人生就是选择正确的方向,然后朝这个方向奋力前行。[1]
时间是必须的,但是判断力更重要.
如何清晰地思考?
与“聪明”相比,“思路清晰”是一种更好的赞誉。
真正的知识具有内在的关联性,就像一根链条,从基础层面到应用层面环环相扣。以数学为例,如果不懂算术和几何,你就无法理解三角函数。如果有人用词花哨,动辄谈论宏大而复杂的概念,那么他们很有可能并不了解自己所谈论的东西。我认为最聪明的人是可以把事情深入浅出地给孩子讲解清楚的人,否则他自己也没有真正理解。
这是一个我们都熟知的观点,确实说得很对。
理查德·费曼的教学方法广为人知。在他早期的“费曼讲物理”系列讲座中,他就用非常简单易懂的语言讲清楚了复杂的概念。他只用3页纸基本上就把数学的本质解释清楚了。他从数字开始,讲到计算,然后讲到微积分,其中的逻辑链条环环相扣,层层递进。他并没有用任何定义来讲解数学。
费曼学习法
真正聪明的人是思路清晰的思考者。他们把基础知识和基础层面了解得非常透彻。相较于背诵各种复杂的概念,我更愿意吃透基础知识。死记硬背学来的概念无法被有机地整合到一起,而且会与基础知识脱节。如果在需要用到一些概念时却无法通过基础知识推导出来,你就会迷失在现有知识的迷宫中,你就成了简单的背诵机器。[4]
吃透基础知识
一个领域的最新概念往往是没有经过充分验证的。使用这些概念会让我们看似很内行。熟知内行知识是很重要,但更重要的是牢牢掌
握基础知识。[11]
内化是最重要的,简单来说就是跟别人讲清楚
头脑清晰的思考者能够树立起自己的权威。
有效决策体现在很多方面,其中一个方面可以归结为处理现实问题。当你做决定时,你如何确保自己是在直面现实问题?
你真的是在直面问题吗
要直面现实,就要放下自我,消除自我意识,忘记自我判断,平复自我情绪。人虽然是高级动物, 但情绪化的自我意识的存在会带来反刍式思维,让一些欲望蒙蔽我们的双眼,让我们看不清现实,从而让我们对“世界应该怎样”妄下判断。这种情况经常发生,尤其是在把政治诉求和商业问题搅在一起时。
放下自我,自我意识带来的反刍思维
阻碍我们看清现实的最大因素就是我们对现实“应有的样子”有先入为主的印象。
阻碍的是我们心里想的应有的样子
痛苦时刻的一个定义是:当你看到事物的真面目不是你本来想要的样子时,你是痛苦的。举个例子,一直以来,你都确信自己的生意做得很好,但实际上,这是由于你无视生意不好的迹象而产生的错觉。结果,生意失败了,你痛苦万分。之所以如此,是因为你迟迟没有面对现实,一直在自欺欺人。
看到真面目不是想要的样子,是痛苦的
但痛苦的时刻就是真相大白的时刻。只有处于痛苦之中,你才会被迫接受现实,而只有接受现实,你才能做出有意义的改变,取得有意义的进步。由此可见,只有实事求是,才能不断改进,不断前行。
难点在于看清真相。要看清真相,就必须摆脱自我,因为自我不想面对真相。自我越弱小,对自己反应的限制越少,对自己想要的结果的执念越低,就越容易看清现实。
看清真相一定要摆脱自我
对美好现实的渴求蒙蔽了对真实世界的认知。所谓痛苦,就是无法继续无视事实。
假设你的朋友陷入一些困境,比如分手、失业、生意失败,或者出现了健康问题,你要对他表示安慰。你一定知道该怎么说,甚至想都不用想:“那个女孩啊,忘了她吧。反正她也不适合你。分手了你会更快乐。相信我,你将来会找到更合适的。”
你知道正确的答案,但你的朋友却看不到,因为他正在遭受痛苦,备受煎熬。他仍在期望现实会有所不同。然而,问题不在于现实。问题在于欲望与现实是互相冲突的,人总会因欲望而看不清现实,旁人的劝说都是无用的。我自己在做决策的时候,也会遇到同样的情况。
问题不在现实,而是在欲望和现实互相冲突
我深知,越是渴望以某种特定的方式解决问题,我就越不可能看清事实。因此,尤其是在涉及公司事务时,如果某件事进展不顺利,我就会尽力公开承认存在的问题,对合伙人、朋友和同事开诚布公。
渴望特定方式,可能是既有的惯例,会让你看不清现实,如果进展不顺利,就开诚布公
这样一来,我对任何人都不会有任何隐瞒。如果不用隐瞒别人,我就不用再欺骗自己,解除了心灵的羁绊和束缚,我就更能看清现实了。
[4]
感受跟事实是两码事。感受只是自我对事实的部分估计。
感受跟事实是两码事。感受只是自我对事实的部分估计。
事实上,留出空闲时间非常重要。如果每一天都被各种会议占满,都是忙忙碌碌的,你就无法进行思考。
没有思考,你就不会有出色的商业创意,也不可能做出正确的判断。我鼓励大家每周至少花一天时间来思考(最好是两天,因为即使预留了两天,最终也可能变成一天)。
留出空闲时间来思考
悠闲的大脑才能产生伟大的创意。一个倍感压力、案牍劳形、四处奔波、焦头烂额的人,是没有办法思考的。所以,一定要为思考挤出时间。[7]
焦头烂额的人是没办法思考的
非常聪明的人往往都是特立独行的,他们坚持独立思考、亲力亲为,以厘清事情的来龙去脉。
逆向投资者并非总是反对一切,事实上,反对一切是墨守成规的另一种表现。逆向投资者会根据实际情况独立思考,能够顶住盲目从众的压力。
反对一切是墨守成规的另外一种表现
玩世不恭很容易,随波逐流也很容易。
成为逆向投资的乐观主义者才最难得。
成为逆向投资的乐观主义者才最难得
摆脱自我束缚,认清世界真相我们的自我是在成长过程中被逐渐塑造的,主要是由人生的前20年决定的。塑造自我的因素包括成长环境、父母和社会等。长大成人后,我们会用一生的时间追求幸福,希望自我能够得到满足。当出现任何新的变化时,我们的自我都会发问:“我应该如何改造外部世界,让它更符合我的喜好和期待?”[8]
摆脱自我束缚,认清世界真相我们的自我是在成长过程中被逐渐塑造的,主要是由人生的前20年决定的。塑造自我的因素包括成长环境、父母和社会等。长大成人后,我们会用一生的时间追求幸福,希望自我能够得到满足。当出现任何新的变化时,我们的自我都会发问:“我应该如何改造外部世界,让它更符合我的喜好和期待?”[8]
佛曰:“有求皆苦,无求乃乐。”
佛曰:“有求皆苦,无求乃乐。”
在日常生活中,基于习惯的行为模式无处不在。人生会遇到各种各样的问题,我们不可能把遇到的每个问题都当成第一次。在解决各类问题的过程中,我们逐渐养成了很多习惯。我们把这些习惯和自我认知、自我认同、自我意识紧密地捆绑在一起,并对习惯形成深深的依赖。“我是纳瓦尔,我就习惯这样做。”
基于习惯的行为
当然,习惯有好有坏。要持续成长,很重要的一点是学会打破现有的条件反射,改掉不良习惯。要善于剖析自我,梳理每个习惯是怎样形成的。比如:“这个习惯可能是我在蹒跚学步的时候养成的,当时是为了吸引父母的注意。我在成长过程中不断强化这个习惯,现在它已经成为我的一部分。这个习惯对现阶段的我还有帮助吗?它会让我更快乐吗?会让我更健康吗?可以帮助我完成计划、实现目标吗?”
哪个习惯能改
跟大多数人相比,我的习惯性没有那么强。我不喜欢对日常生活进行规划。我也有一些习惯,但这些习惯都是我刻意培养的,而不是在成长过程中无意形成的。[4]
任何一个标签(比如“前民主党人”“天主教徒”“美国人”)都是一系列信仰、理念和身份的集合。我们应该秉持怀疑态度,从基本原则出发,对其重新评估。
我尽量避免预设的干扰。我认为,任何划分阵营和贴标签的行为都会给人造成束缚,让人看不清真相。
标签会让人看不清真相
要做到诚实,就要在发表观点时抛开自己的身份。
我曾经自认为是个自由主义者,但后来我发现,我之所以捍卫那些我没有真正思考过的立场,是因为这些立场是自由主义信条的一部分。只有立场却没有是非,这是不可取的。如果你所有的信念都能被整整齐齐地打包成某个“主义”,或某个思想流派,你就要对自己的信念保持高度怀疑。
只有立场却没有是非,这是不可取的。如果你所有的信念都能被整整齐齐地打包成某个“主义”,或某个思想流派,你就要对自己的信念保持高度怀疑。
在任何一个层面上实现自我认同,都会形成很多所谓的“稳定信念”。我不喜欢这种做法,因为这会妨碍我独立思考。[4]
我们每个人都有一些离经叛道的信仰,这些信仰不被社会接受。
但是,我们的身份和所在的族群越是排斥这样的信仰,它就越有可能是符合现实的。
从长远看,承受痛苦也是人生的必修课,它可以带来两大收获:
一是痛苦可以让人接受世界的本来面目;二是痛苦可以大大改变一个人的自我,虽然过程非常煎熬。
举例来说,如果一个竞技运动员身受重伤(比如,李小龙),他当然非常痛苦,但他必须接受现实,明白竞技运动并不是他生命的全部,运动员也不是他身份的全部。受伤的他也许可以去研究哲学,为自己赢得一个哲学家的新身份。[8]
脸书不断重新设计,推特也不断重新设计。个性、职业和团队也需要重新设计、推陈出新。在一个动态的系统中,没有一劳永逸的解决方案。
学习决策技巧传统美德对我们的决策具有很大的启发意义:要选择从长期来看让我们受益最大的做法,而不是只顾眼前得失。[11]
当把成功归于自己时,你要更加谨慎,因为难免出现认知偏差。
未来几年,我的重要目标就是摆脱很多以前的习得反应和习惯性反应。这样我就可以抛开记忆或固有的认知和判断,当机立断,做出更清晰的决定。[4]
几乎所有的偏见都是为了帮助人们在信息不完整的情况下迅速做出判断。对于重要的决策,要抛开记忆和身份,专注于问题本身。
我之所以极度坦诚,是因为我想获得自由。自由的表现之一就是可以心口如一,表达自己的真实想法。诚实和自由高度统一,相辅相成。理论物理学家理查德·有句名言:“不要欺骗自己,你自己才是最容易被欺骗的人。”对别人撒谎,就是对自己撒谎。你会慢慢地相信自己的谎言,继而脱离现实,走上错误的道路。
我从不考虑“我喜欢或不喜欢”这样的问题。我只关注事实,我思考问题的角度是“事实就是这样”,或者“事实不是这样”。
——理查德·费曼
做一个诚实的人对我来说极为重要。我不会有意做那些卑鄙下流之事。做人除了要极度诚实,还可以参照巴菲特很久之前说过的一个建议:具体地表扬,泛泛地批评。我努力遵循这个建议,虽然并不总能做到,但它确实给我的人生带来了积极的改变。
如果要提出批评意见,不要批评某个人,可以批评工作方法,或者批评某一类行为。如果要表扬,那就找到一个榜样,表扬这个特定的人。这样有助于维护你身边人的自尊心和身份感,获得他们的支持,让他们为你所用,而不是与你作对。[4]
关于培养诚实的态度和率直的表达方式使其成为本能这件事,你有什么建议吗?
把自己的真实想法告诉所有人。现在就开始这样做。表达方式不一定要很直白。当一个人同时展现出高度的自信和关爱的力量时,他就会散发出人格魅力。诚实待人、积极向上,这是我们在任何时候几乎都可以做到的。[71]
作为AngelList的投资者和首席执行官,你的工作就是在别人犯错时做出正确决策。你的决策流程是怎样的?
是的。决策就是一切。事实上,一个决策正确率为80%的人比正确率为70%的人在市场上的价值和获得的回报要高出数百倍。
人们好像很难从本质上理解决策的杠杆效应。我可以举例说明,如果我管理着10亿美元的资产,而且我的决策正确率比其他人高出10%,我就能通过一个判断、一个决策创造出1亿美元的价值。这就是决策的杠杆效应。随着现代科技的发展、劳动力规模的扩大和资本的不断积累,决策也将发挥越来越大的杠杆效应。
如果能做出更正确、更理性的决策,你得到的回报就是非线性的。我很喜欢Farnam Street这个博客,因为它致力于帮助读者提高决策的准确性,从各方面帮助他们成为一个更好的决策者。请记住:决策就是一切。[4]
越觉得自己无所不知,规避和处置风险的方法越少。
发现好的心智模型在决策的过程中,大脑是一台根据过往记忆进行预测的机器。
在根据记忆进行预测的过程中,推理逻辑是最靠不住的:“这件事在过去发生了,因此在未来也会发生。”这种推理过于依赖特定环境,带有经验主义色彩。其实,做决策要具体问题具体分析,有效决策需要的是原则和心智模型。
目前我发现的最好的心智模型来自进化论、博弈论和查理·芒格。
芒格是巴菲特的合伙人,是一位极为出色的投资大师。他有成千上万个绝佳的心智模型。另外,我还知道纳西姆·塔勒布、本杰明·富兰克林等等,他们都有出色的心智模型。我也会在自己的脑子里装满各种各样的心智模型。[4]
我把自己的推文和其他人的推文作为格言。发推文有助于我提炼所学知识的精髓,也有助于我温故而知新。大脑的空间是有限的,毕竟一个人的神经元数量是有限的,所以你可以把推文视为指针、地址或助记符,其目的是帮助你记住那些更深层次的原则。而只有将这些原则与过往的亲身经历相结合,你才能加深理解和记忆。
如果没有结合亲身经历,推文读起来就会像鸡汤集锦,内容精彩,一时间让人备受鼓舞。你甚至还把它们做成精美的海报,以时时激励自己。但很可能过段时间你就忘掉了,继续按部就班地生活。所谓的心智模型,其实就是有助于调取你所学知识的简单方法。[78]
进化论
我认为,现代社会的很多现象都可以用进化论来解释。有一种理论认为,文明的存在是为了解决交配权的分配问题。从纯粹的性选择角度看,人类社会精子充足,卵子稀少,所以存在分配问题。
究其根本,人类的所有发明和成就都是为了解决交配权的分配问题。
人生的很多问题都可以从进化论、热力学、信息论和复杂性理论中找到解释和预测。[11]
反推法我认为自己并没有能力找到“正确方法”。相反,我努力的方向是逐一排除不奏效的方法。我认为成功就是不犯错。成功的关键并不在于做出正确判断,而在于避免做出错误判断。[4]
复杂性理论20世纪90年代中期,我开始沉迷于研究复杂性理论。随着研究的深入,我越发认识到人类知识和预测能力的局限性。复杂性理论对我产生了至关重要的影响。这个理论帮助我打造了一个系统,它可以在存在信息盲点的情况下正常运作。我相信,从本质上说,人类是无知的,是极不善于预测未来的。[4]
经济学
微观经济学和博弈论都是基础性学科。如果不能深刻理解供求关系、劳资关系、博弈论等问题,你就不可能在商业上取得成功,甚至也无法很好地适应现代社会。[4]
忽略那些不同的声音。市场会做出决定。
委托和代理问题在我看来,委托和代理问题是微观经济学中最基本的问题。如果不了解什么是委托、什么是代理,你就无法在这个世界上应对自如。
如果想成功创业、成功达成交易,你就一定要研究委托和代理问题。
委托和代理问题非常容易理解。恺撒大帝有句名言:“如果你想完成一件事,那就亲自去做。如果不想完成,那就派人去做。”他的意思是,如果想把事情做好,你就必须自己去做。如果你是委托人,你就会有主人翁的责任感,因为在意结果,所以你会做得很好。而如果你是代理人,你就是在为别人做事,你可能会做得很糟糕,因为你不在乎。你追求的是自身利益最大化,而不是委托人资产最优化。
公司规模越小,每个人越会觉得自己是委托人、是主人。越不觉得自己是代理人,工作就会做得越出色。增加所获报酬与创造价值之间的相关性,可以改变员工的认知,让他们越发觉得自己是委托人,而不仅仅是代理人。[12]
我认为,我们内心深处都知道这一点。我们会天然地被委托人这个角色吸引,内心也更贴近这个角色。但媒体和现代社会不断给大众洗脑,让大众认为社会需要代理人,代理人在社会中发挥着不可或缺的作用,代理人学识渊博,等等。这样一来,大多数人会心甘情愿地成为勤勤恳恳的代理人。[12]
复利效应一提到复利,大部分人都知道这是一个金融词语。如果不懂复利是什么,那么你可以自行学习一下微观经济学教科书。从头到尾认真研读一本微观经济学教科书,你会受益匪浅。
我举个金融的例子来说明什么是复利。假设每年从1美元中获得10%的收益,那么第一年可以赚10%,最后得到1.10美元,第二年得到1.21美元,第三年得到1.33美元。收益金额会不断增加。如果以每年30%的复利利率计算,连续30年,最终得到的不是本金的10倍或20倍,而是数千倍。[10]
在智力成果领域,复利效应同样适用。一家公司现有100个用户,如果用户以每月20%的复合速率增长,公司将在短时间内累积起数百万用户。有时候,即使是公司的创始人,也会对如此庞大的业务规模感到惊讶。[10]
基础数学我认为,基础数学的重要性真的被低估了。如果要赚钱或者投资,你就必须学好基础数学。创业和经商不需要学习几何学、三角函数、微积分,也不需要学习其他任何复杂的数学课程,但是需要学习算法、概率学和统计学,这些分支学科都非常重要。要吃透基础数学,真正掌握加减乘除、复利计算、概率论和统计学。
黑天鹅概率统计学有一个新的分支,这个分支是关于“尾部事件”的。黑天鹅事件是极端概率事件。这里我想重提一下纳西姆·塔勒布,我认为他是我们这个时代最伟大的哲学家和科学家之一。他在研究黑天鹅事件方面做了很多开创性工作。
微积分我们可以借助微积分了解和认识变化的速度和自然界的运作方式,但更重要的是,要理解微积分的原理。微积分通过小的离散或连续事件来测量变化。进行积分运算或根据需要进行推导并不重要,因为在商业世界里你不需要这样做。
可证伪性对那些声称“科学”站在自己一边的人来说,最重要的原则,同时也是他们理解得最不透彻的原则,就是可证伪性。如果不能做出可证伪的预测,那就不是科学。要让人们相信某个理论是真理,这个理论就应该具有预测能力,而且必须是可证伪的。[11]
我认为宏观经济学不可信,因为宏观经济学家做出的预测是不可证伪的,而可证伪性才是科学的标志。现实只有一个,所以在研究经济时,反例永远不会出现,你永远不可能在美国经济发展的同时,找到另一个完全一样的国家做相反的经济实验。[4]
如果难以抉择,那答案就是否定的如果面临艰难选择,比如:
我应该跟这个人结婚吗?
我应该接受这份工作吗?
我应该买这栋房子吗?
我应该搬到这个城市吗?
我应该和这个人做生意吗?
如果你难以抉择,答案就是否定的。原因是,现代社会充满了选择,有成千上万个选择。我们生活在一个有70亿人口的星球上,我们和互联网上的每个人都相互连接,世界上有成千上万的职业供我们选择。大千世界,芸芸众生,选择永远不缺。
自古至今,生理上的局限决定了人类无法意识到自己到底有多少种选择。在远古时期的部落中,150个人就是运转和协作的极限了。当一个人出现在你的生活中时,这个人可能就是你唯一的伴侣选择。
一个重大决策可能会影响未来十几年,甚至几十年的人生轨迹。
创业可能需要10年时间。一段恋情可能会持续5年甚至更久。搬到一个城市可能会住上10年、20年。这些决定都将产生深远的影响。人做不到绝对确定,但是我们一定要在非常确定的情况下再做出决定。
有时我们实在难以抉择,甚至需要列出清单,对不同选项的利弊进行对比和权衡。选择放弃吧,如果难以抉择,答案就是否定的。[10]
迎难而上一条简单的人生经验:如果在一个艰难的决定上意见不统一,你就应该选择短期内更痛苦的道路。
如果面对两个选择,利弊各占50%,你就应该选择短期内更艰难、更痛苦的道路。
从本质上看,两条道路中的一条会带来短期痛苦,而另一条会在未来引发更长久的痛苦。为了回避矛盾,大脑会本能地选择摆脱短期痛苦。
前提条件是,两个选择利弊相当,但如果一条道路会带来短期痛苦,那么它也会带来长期收益。而根据复利效应,长期收益才是你想要的。
大脑会过分看重短期快乐,试图避免短期痛苦。
因此,你必须进行自我训练,主动迎接短期痛苦,压制回避痛苦的倾向(这种潜意识倾向非常强大)。如你所知,我们生命中的大部分收获都来自承受短期痛苦而获得的长期回报。
以运动为例。运动对我来说并不是一件快乐的事,因为我会在短期内感到痛苦。但是从长远看,我会变得更好,因为我的肌肉更发达
了,身体更健康了。
当运动时,肌肉会感到酸痛或疲劳。读书也一样,读有难度的书会让大脑不堪重负,短时间内感到疲劳。但从长远看,读书会让我变得越来越聪明,因为我在持续挑战大脑处理信息的极限,提高大脑的工作能力,进而不断吸收新概念。
因此,一般来说,应该选择短期痛苦,以换取长期收益。
建立新的心智模型最有效的方法是什么?
海量阅读,多多益善。[2]
每天花一个小时阅读科学、数学和哲学类书籍,7年内,你就可能跻身少数的成功人士之列。
学会热爱阅读(具体的书籍和博客推荐,请参阅“纳瓦尔的推荐读物”部分。)
真心热爱阅读,加上后天的引导和培养,你的能力将不可限量。
我们生活在亚历山大时代[1],只需要轻点指尖,任何图书和知识都唾手可得。我们学习的手段丰富多样,我们缺乏的是求知欲。[3]
阅读是我的初恋。[4]
我还记得祖父母在印度的宅院。祖父家里只有《读者文摘》,小时候,我就躺在地板上,一本接一本读完了他家所有的《读者文摘》。现在是信息爆炸的时代,任何人都可以随时阅读任何东西。但在我小时候,阅读的局限性要大得多。我会读漫画书、故事书,能找到什么就读什么。
我一直很喜欢阅读,仔细想来,其实主要是因为我非常内向,不善交际,喜欢宅在家里看书。从很小的时候起,我就沉迷于语言和思想的世界。我热爱阅读,部分原因也在于,我小时候的成长环境很宽松,没有人强迫我阅读特定的书籍。
父母和老师往往会引导孩子阅读或者避开特定的书籍,我小时候读的很多书,以现在的标准来看,都属于精神垃圾。[4]
阅读自己喜欢的题材,直到热爱阅读。
读书的唯一原因应该是喜欢,不需要其他任何理由。不要把读书当成一项任务,读书就是因为乐在其中。
我发现自己现在开始重读很多书,甚至超过了读新书的时间。来自@illacertus的一条推文说:“我不想什么书都读,我只想把100本好书读上一遍又一遍。”我觉得这个想法很有道理。关键是找到适合自己的好书,因为每个人阅读的喜好和需求不同。这样做,你会受益良多。
不要比谁读书更快。书越好,你越要慢慢阅读、慢慢吸收。
我不知道大家的情况,但我本人注意力非常差。我会略读、速读、跳读,也记不住书里具体的段落或内容。但这些并不重要,重要的是,在某个更深的层面,我吸收了书中的精华,这些书成为我心灵织锦上的丝线,编织成我灵魂的一部分。
我相信你一定有过这样的感觉,当拿起一本书开始读的时候,你会说:“这本书真有意思,内容真不错。”读着读着,你越来越有一种似曾相识的感觉。读到一半,你突然意识到:“原来我读过这本书。”但真的没关系,既然忘得差不多了,那就意味着你已经准备好重新阅读它了。[4]
我精读的书其实并不多。我会略读很多书,但精读的只有几本,而这几本书构成了我知识的基础。
事实上,我的阅读量并没有大家想象中那么大。我每天可能阅读一两个小时,不过这已经足够让我名列全球阅读时间的前0.000 01%了。阅读是我一生中所有物质和精神层面所取得的成就的来源。绝大多数人不会每天读一个小时的书。普通人每天可能只读一分钟的书,甚至更少。把读书培养成习惯是最重要的一件事。
阅读的题材和内容并不重要。最终,你会追随自己的兴趣,完成大量阅读。你的生活也会因此得到极大的改善。这就好比最好的锻炼方式就是做自己感兴趣的、每天都能坚持的运动。同样的道理也适用于书籍、博客、推特,或者任何有思想、有信息、有学习内容的东西,最好的阅读就是自己感兴趣的、爱不释手的阅读。[4]
一书在手,便不觉得浪费时间了。
——查理·芒格
每个人大脑的工作方式都不相同。有些人喜欢记笔记,而我的笔记本就是推特。我持续、大量阅读,如果遇到让我眼前一亮、豁然开朗、拍案叫绝的观点或概念时,我就会在推特上分享。但为了满足推文的字数要求,我又必须推敲文字。最终,我会努力提炼出一条格言,放在推特上。但总会有各种各样的人愤怒地跳出来攻击我,对我推文的内容断章取义、以偏概全地横加指责。这时,我会想:“我怎么又发推文了,真是不长记性。”[4]
指出别人观点中明显的偏颇,意味着要么你攻击的对象不聪明,要么你自身不聪明。
刚拿起一本书的时候,你是会先浏览一下,找到有意思的部分,还是随便翻到某一页就开始阅读?你是怎样阅读的?
我会从头开始读,但会读得很快。如果书的内容没什么意思,我就会跳着读,或者大概翻一下后面的内容。如果书的第一章没有什么实质性或有启发意义的内容,没有吸引我的注意力,我就会放下书,不再读了,或者跳过几章,从中间开始读。
我读书的时候不相信“延迟满足”,读不堪卒读的书本身就是痛苦的,何来满足?世界上的书太多了,有那么多好书,这本不喜欢就果断舍弃,换下一本。
统计阅读数量是为了满足虚荣心。知识面越广,思想越独立,读不完的书就越多。不要刻意追求读完多少本书,而要时刻关注可以预测未来趋势的新概念。
一般来说,我会略读和跳读,找到能吸引我注意力的章节。大部分图书都有一个论点(我讲的是非虚构类作品,不是小说),作者提出一个论点,引用海量实例证明自己的观点,然后用自己的观点去论证世界上各种各样的现象。一旦觉得自己已经明白了这个论点,我就不再读下去了。这样的书太多了,我称其为伪科学畅销书。别人会问我:“这本书你读了吗?”我总是说读过了,其实我可能只读了两章,但书的主旨我已经了解了。
如果一本书被写出来只是为了赚钱,那么不要读它。
对阅读中获得的信息你如何消化吸收并融会贯通?
向别人讲解你学到的东西。教学相长。
人与人的区别不是“受过教育”和“没受过教育”,而是“喜欢阅读”和“不喜欢阅读”。
如果想成为一个更清醒、更独立的思考者,在接下来的60天里,我能做些什么?
阅读数学、科学和哲学领域的经典作品。不要读畅销书,不要看新闻。避免加入任何所谓的“读书俱乐部”,避免追求任何的社群认同。把真理置于社群认同之上。[11]
学习逻辑和数学。一旦掌握了逻辑和数学,无论读什么书你都不会发怵了。
图书馆里的任何一本书都不应该让你望而却步,无论是数学、物理、电气工程、社会学还是经济学。你应该不畏惧阅读书架上的任何一本书。其中一些书对你来说难度可能有点儿大,但是没关系,你还是应该接着读,只要有机会就一遍又一遍地阅读。
读书时感受到的困惑,就像运动时感受到的肌肉酸痛。阅读是在锻炼精神的肌肉,运动是在锻炼身体的肌肉。要学会如何阅读书籍。
“不用想太多,读就是了”,这句话的问题在于,现在的垃圾内容太多了。写作者良莠不齐,很多人会写出很多垃圾作品。
我遇到过很多人,他们貌似博览群书、知识渊博,但实际上没什么智慧。原因在于,他们虽然读了很多书,却是以错误的顺序读了错误的内容。在开始阅读之旅时,他们读的东西没有什么实质性内容,也不包含什么真理,这些内容构成了他们世界观的基础。然后,当新事物出现时,他们会根据已经建立起来的基础对新想法加以评判,他们的评判自然也没什么见地。所以,打好阅读的基础非常关键。
大多数人对数学都有一种天然的畏惧感,他们不能对数据进行独立评判,因此,在遇到以数学方法或伪科学为支撑的观点时,难免会高估这些观点的价值。
打下一个高质量的阅读基础至关重要,只有这样才能站得高行得远,更好地辨别真伪优劣。
打好基础的最佳方法或诀窍就是坚持科学,坚持基础理论(你可能不喜欢这个答案)。一般来说,不存在任何争议的真理是屈指可数的,而数学就是其中之一,数学很少存在争议,几乎没有人不同意2+2=4,对吧?数学是一门非常严谨的学科,可以为阅读打下坚实的基础。
同样,自然科学和微观经济学都能为阅读打下坚实的基础。一旦脱离了这些坚实的基础,麻烦就来了,因为你会难辨真伪。我会尽我所能,为自己的阅读打下一个坚实的基础。
擅长算术和几何比深入研究高等数学要有用得多。所以,我建议多花些时间阅读微观经济学——从微观经济学入门课程开始。
另一种方法是阅读原著和经典。如果对进化论感兴趣,那就去读一读达尔文的作品,不要从理查德·道金斯读起(尽管我认为他很棒)。先读达尔文,再读道金斯。
如果想学宏观经济学,就先读亚当·斯密、冯·米塞斯或哈耶克,从最早的那批经济哲学家读起。如果喜欢共产主义或社会主义思想,可以从卡尔·马克思的作品读起。不要读解读性或评论性的内容,它们只是别人告诉你,你应该如何做事,世界应该如何运行。
以原著和经典为基础,你能够获得足够完备的世界观和深刻的理解力,你不会再畏惧任何书籍。你可以顺利开启自己的学习之旅。如果能成为一台永动学习机,你就永远不缺赚钱的途径。你会拥有洞察社会现象本质的能力,你会找到真正的价值和需求所在,然后通过学习,紧跟时代发展的脚步。[74]
要想思路清晰,就要了解基础知识。如果只是死记复杂概念,却无法融会贯通、学以致用,那么记得再多也是一窍不通、无济于事。
我们现在身处推特和脸书的时代,得到的都是碎片化的智慧精华,吸收起来非常困难。读书对现代人来说已经非常困难了,因为我们的大脑已经被训练成特定模式,大脑同时接受了两个相互矛盾的训练。
一方面,我们注意力的持续时间越来越短,因为总有海量信息扑面而来。我们希望快速略读,总结要点,直奔主题。
推特降低了我的阅读能力,却大大提高了我的写作能力。
另一方面,我们从小受到的教育就是,书必须读完一本再读下一本。书是神圣的——在学校里,老师给你指定一本书,你就必须读完它。随着时间的推移,我们逐渐忘记了如何阅读。我认识的每个人都卡在某一本书上,很难开始下一本。
我相信,你现在一定也卡在某本书的某一页读不下去了,但同时你又觉得应该把这本书读完。这个时候你会怎么做?你可能干脆什么书都不读了。
对我来说,放弃阅读是一个悲剧。阅读伴着我一路长大,成年之后我才开始用博客,后来开始玩推特和脸书。之后我意识到,我没有从网络上学到任何东西。上网的每一天我都是在吃多巴胺零食,每块零食就是140个字符。我每次做的就是发推文,然后看看谁转发了我的推文。这件事很美妙很有趣,却只是个游戏。
这个时候我意识到,我必须回归阅读。[6]
我知道回归阅读非常困难,因为我的大脑已经被训练成这种模式,只会花时间在脸书、推特和其他碎片化的内容上。
于是,我想了一个办法,那就是把书当成博客文章集锦或推文合集,这样我就不用必须读完这本书了。如果有人跟我提起一本书,我就把这本书买回来。现在我会同时阅读10本、20本书,都是一目十行、囫囵吞枣地读。
如果书的内容有点儿枯燥,我就跳过这部分内容。有时候,我会从一本书的中间开始读,因为有些段落抓住了我的眼球。然后,我想读多少就读多少,并不觉得一定要从头至尾读完。突然间,书籍又回到我的阅读百宝箱里。这真是太棒了,因为书籍中蕴含着古老的智慧。[6]
在解决问题时,问题越古老,解决方案存在的时间越长。
如果想学开车或者驾驶飞机,你就应该阅读一些现代指南,因为这个问题是在现代社会产生的,而且现代社会可以提供很好的解决方案。
而如果是一个古老的问题,比如如何保持身体健康,如何保持冷静和平和,什么样的价值体系是好的,如何经营好家庭,诸如此类的问题,古老的解决方案可能更好。
任何流传了两千年的图书都经过了许多代人的甄别和筛选,其中的一般性原则更有可能是正确的。我想重新开始阅读这类书。[6]
你的脑海中是不是会偶尔出现一首歌曲的旋律,它总是挥之不去?这就是记忆痕迹。其实所有思想的形成莫不是痕迹效应的结果。
所以要慎重选择阅读内容。
一颗平静的心,一个健康的身体,一个充满爱的家。这些东西是金钱买不到的,必须通过努力才能获得。
[1]亚历山大时代是人类历史上文化大交流大融合的时代,在世界文化发展史上具有重要意义。——编者注
第二部分 幸福
PART TWO HAPPINESS
人生的三大要素是财富、健康和幸福。
我们依次追求财富、健康和幸福,但按重要性排序,则是反过来的。
第三章 学习幸福
别太把自己当回事。你只是一只会做计划的猴子。
幸福是一种技能10年前,如果你问我是否幸福,我会避而不谈,因为我不想讨论关于幸福的话题。
如果要给幸福感打分,满分10分,我当时的幸福感应该是2分或3分。状态最好的时候,也许能达到4分。但幸福感对那时的我来说并不重要。
而现在,我的幸福感是9分。有钱确实能提高幸福感,但金钱其实只发挥了很小的作用。幸福感的提升主要是因为,随着时间的推移,我逐渐认识到,让自己幸福对我来说是最重要的事,我也运用了大量技巧来培养自己的幸福感。[10]
可以说,幸福与基因无关,甚至与选择无关,它是一种与个体密切相关、可以后天习得的技能,就像通过锻炼强健体魄、通过吃饭摄取营养一样。
我认为,幸福就像所有其他的宏大话题一样,其含义会随着时空的转换而不断变化。小时候,你会问妈妈:“人死了以后会发生什么?
世界上真的有圣诞老人吗?真的存在上帝吗?我应该感到快乐吗?我应该跟谁结婚?”诸如此类的问题都没有显而易见的正确答案,因为没有哪个答案适用于所有人。当然,这些问题最终会有答案,只不过答案只适用于单一的个体。
甲之真理,乙之谬论,反之亦然。我所理解的幸福与你所理解的幸福可能大相径庭。我认为,探索自己对幸福的定义非常重要。
我认识的一些人认为幸福是一种心流状态,另一些人认为幸福是欲望得到满足,还有人认为幸福就是知足常乐。我对幸福的定义也在不断变化,我一年前给出的答案跟现在的就完全不同。
现在,我认为幸福就是一种不需要主动作为的状态。当把“缺憾感”从生活中剔除时,幸福感就会油然而生。
人类是具有高度主观意识的生存和繁殖机器,会一刻不停地对周围的一切做出评判。我们不断地接收和判断周围的信息,想着“我需要这个”或者“我需要那个”,深陷欲望之网,难以自拔。而幸福就是一种毫无缺憾感的充盈状态。当感到生命中并不缺少什么时,大脑就会处于休眠状态,不再追忆昨天,也不再畅想明天,不会悔不当初,也不会谋求未来。
在没有缺憾感的短暂时间里,你的内心会一片宁静。当内心宁静时,你是满足的,是快乐的。当然,你完全可以不同意我的观点。但我还是要再说一次,每个人的情况都不一样,每个人对幸福的理解也不一样。
人们往往误将积极乐观的想法和行为等同于幸福。随着阅读量、知识面和阅历的增加(阅历很重要,因为实践出真知),我发现每个积极的想法其实都包含一个消极的想法。积极和消极是如影随形的相对概念。《道德经》对此进行了全面深刻的阐述,我的分析当然不能与其相提并论,但归根到底,万物皆有二元性和极性。如果我说现在我很开心,那就意味着在某个时刻我很伤心。如果我说一个人有魅力,意思就是其他人没有魅力。每一个积极想法都有一个消极想法的种子蕴含其中,反之亦然,这就是为什么生命的伟大在很大程度上源于苦难。人必须先看到消极的一面,才能去憧憬和欣赏积极的一面。
对我来说,幸福不等同于积极的心态,也不等同于没有消极的想法。幸福是一种无欲无求的状态,特别是对外界事物的欲望。欲望越少,越能接受事物的当前状态,头脑越平静。所谓“万般烦恼皆因心动”,就是头脑在一刻不停地设计未来或追忆过去。我越是活在当下,越能感受到快乐,感受到满足。而如果我试图抓住当下快乐的感受,想要一直保持快乐的状态,快乐就不会持久。因为,这时我的心在动,欲念在动,希望依附于一个外部事物,欲将一个短暂的情景变成永恒。
对我来说,幸福的含义主要是没有痛苦,没有欲望,不沉溺于对未来或过去的思考,真正拥抱当下,拥抱现状,拥抱现实的一切。[4]
如果想获得内心的平和,你就必须超越对万事万物的善恶评判。
大自然没有幸福或不幸福的概念。从宇宙大爆炸到现在,自然的发展遵循完备的数学定律和一系列因果关系。大自然的一切都浑然天成。幸福或不幸福只存在于我们的大脑,因为我们有欲望,所以给事物贴上了“完美”或“不完美”的标签。[4]
世界只是折射个人感受的一面镜子。现实是中性的,现实不做评判。一棵树没有对与错、好与坏的概念。人生在世,我们从大千世界中获得各种各样的感官体验和刺激,耳得之而为声,目遇之而成色。
至于如何思考、判断和对待你所感知的一切,全由你自己决定——选择权在你手上。
我所说的“幸福是一种选择”就是这个意思。如果你相信幸福如我所说是一种选择,那么你可以着手做出这个选择。[77]
情绪看似是外力作用的结果,但其实并非如此。
随着时间的流逝,我也开始相信,个体是渺小的,如沧海之一粟,微不足道。这样的认知对我获得幸福感很有裨益。假如你自认为是全宇宙最重要的人,你就会有让整个宇宙屈从于你的意志——既然你是最重要的,那么宇宙怎么可以不符合你的心意呢?如果宇宙不按照你的意志来运转,你就会觉得不对劲儿。
但如果你把自己看成一个细菌或变形虫,把自己毕生的努力都看成在水上写字、在沙滩上建城堡,你就不会对生活“本来该有”的模样抱有期待。生活就是这样,现实就是如此。接受了这一点,就无所谓幸不幸福。“幸福”并不是一种客观存在,而是一种主观感受。
幸福就是消除缺憾感之后的感受。
剔除了“幸福”和“不幸福”的状态,剩下的就是中性状态,但中性状态并不意味着平淡。很多人认为,中性状态是索然无味、缺乏激情的。事实并非如此,中性状态是孩子才有的状态。我们会发现孩子通常都很快乐,那是因为他们真的会沉浸在周围的环境里,沉浸在当下,而不是期待环境来契合自己的喜好和欲望。我认为,中性状态其实是一种完美的状态。只要不沉溺于自己的想法、不执着于自己的欲望,你就可以获得快乐。[4]
人生转瞬即逝,如黑夜中的萤火虫。尘世光阴等刹那,白驹过隙一瞬间。活着就是要充分利用每一分钟。“充分利用”不是说要穷尽所有时间去追逐一些愚蠢的欲望,而是要认识到自己在这个星球上的每一分每一秒都是非常宝贵的。生而为人,就有责任确保自己的幸福,确保用最好的方式诠释万事万物。[9]
我们都认为江山易改,本性难移,但事实是,我们是可塑的,而世界基本上是固定不变的。
练习冥想能帮助你接受现实吗?
可以,但作用其实微乎其微。(大笑)即使你长期练习冥想,但有人说错了话,刺激到你,你的平和状态也可能瞬间被打破,再次回到受自我驱动的状态。这就像当你还在练习举1磅[1]的哑铃时,突然有人给你加了一个巨大的杠铃,还在你头上放了一摞盘子,这自然令你难以招架。
冥想当然比什么都不做要好。但即使练习冥想,当真正的精神或情感痛苦到来时,你也难有招架之力。[8]所以,真正的幸福只是内心平和的副产品,主要还是源于接受现实,而不是改变外部环境。[8]理性很强的人可以通过训练自己的无感反应获得平和,即学会漠视自己无法控制的事物。
我降低自己的身份感。
我屏蔽脑海中的噪声和杂念。
我不在乎那些无关紧要的事。
我不参与政治。
我远离郁郁寡欢的人。
我珍惜光阴。
我阅读哲学作品。
我进行冥想练习。
我和快乐知足的人交往。
这些方法很有效。
可以有条不紊、循序渐进地稳步提高自己的幸福基线,就像提高身体素质一样。[10]
[1]1磅≈0.45千克。——编者注
幸福是一种选择幸福,爱,激情……这些都不是我们追寻的事物,而是我们做出的选择。
幸福是一种选择,是一种可以培养的技能。
大脑就像身体一样,是可塑的。我们花费大量时间和精力,努力改造外部世界,改造他人,改造自己的身体,却没有考虑过改造自己的大脑,只是简单地接受了年轻时被塑造的自己。
我们无条件地听从自己脑海中的声音,以为这个声音就是一切真理的来源。殊不知,大脑也是可塑的,每一天都是崭新的。记忆和身份只是来自过去的负担,让我们无法自由自在、心无旁骛地活在当下。[3]幸福需要活在当下在任何时候(比如走路的时候),大脑都只有很小一部分是关注当下的。大脑把主要精力用于规划未来或悔恨过去。这样的运行机制让人无法获得绝妙的体验,无法欣赏周遭一切事物的美妙之处,无法因为现状常怀感恩之心。如果每天都沉浸在对未来的规划和幻想中,那就是在亲手扼杀自己的幸福。[4]
我们渴望那些让我们能感知当下的体验,殊不知,这样的渴望却让我们脱离了当下。
我认为,过去就是过去了,没有回忆,没有遗憾,没有放不下的人,没有忘不掉的旅行。既往不恋。人之所以感到痛苦,很多时候是因为拿以往和现在做比较。[4]
以往种种未能实现的欲念会带来现在的缺憾感,而我们又将弥补现实缺憾的希望寄托于未来。消除缺憾感会让人更容易活在当下。
关于“开悟”,我读到过一个很好的定义:“思考的间隙即开悟。”意思是说,开悟不需要在山顶修行30年,而是一个时时刻刻都可以达到的境界。你每天都可以提高自己的开悟水平。[5]你有没有想过,现在的生活可能就是上帝承诺给你的天堂,而你却毫不珍惜,肆意挥霍?
幸福需要心境平和幸福感与目的感是相互关联的吗?
人们赋予“幸福”太多内涵,我都不确定这个词是什么意思了。对现在的我而言,幸福的本质更倾向于平和,而不是快乐。我觉得平和与目的无法共存。
如果你是在追随内在的目的,做自己想做的事情,那么你自然会觉得幸福。但如果目的是外界强加给你的,你做的是不得不做的事情,如“社会希望我做这件事”,“爸爸是爷爷的长子,我又是爸爸的长子,因此我必须这样做”,“我欠债了,负担很重,必须努力”,等等,那么你是不会幸福的。
我觉得,大多数人都有如影随形的轻微焦虑感。有时你四处奔忙,感觉状态一般。这时,如果停下来感知一下自我,你就会发现大脑在一刻不停地念叨。又或许,你就是没有办法安静地坐下来。即使身体坐下来了,你的大脑也会一直想着“下一步”应该做什么。
事情总是一件压着一件,处理完这件,下一件会接踵而至,永远有做不完的事,所以焦虑感才会普遍存在。
如果你找个地方坐下来,尝试着什么都不做,这个时候,焦虑感是最明显的。我说的什么都不做,是不要读书,不要听音乐,不要做任何事情,只是坐着。只是这一件事,你就做不到,因为焦虑感会让你如坐针毡,会不停地催促你站起来去做事。所以,很重要的一点就是,你要意识到,是焦虑感让你感到不快乐。而这种焦虑感源于一连串不断涌现的想法。
我应对焦虑的方法就是不与之对抗,让自己意识到这种焦虑感源于脑海中此起彼伏的想法。然后,我会问自己:“我是想一直执着于这些想法,还是想重获内心的平静?”如果大脑中一直存在各种各样的想法,我就无法获得平静,所以,答案是显而易见的。
你也注意到了,我说的“幸福”,指的就是拥有平和的内心。很多人说的幸福指的是开心快乐,但于我而言,幸福就是内心的平和。[2]
幸福的人并不是时时刻刻都快乐的人。
幸福的人是可以轻松地以特定的方式诠释事件、保持内心平和的人。
欲望是主动选择的不开心我觉得人类最常犯的一个错误就是,认为自己会因外部环境变化而获得幸福。我不这样认为。我知道我的想法并非原创,也不新颖,这并不是我的总结,而是佛学的终极智慧。我是最近才从根本层面上理解这种智慧的,也认识到自己过去对“幸福”的理解有偏差。
举例来说,我买了一辆新车,现在等着提车。我自然会很关注这件事,每天晚上都上论坛查看、研究相关信息。我为什么要这样做?
只是一辆普普通通的车,不会给我的生活带来什么实质性改变。我知道,只要车一到手,我就不会再关注它了。问题的关键在于,我沉迷于对外物的“欲望”。我对外部事物会带给我幸福和快乐的执念其实是一种痴念。
从根本层面上看,从自身以外的事物中寻求幸福,本身就是缘木求鱼。当然,我并不是说物质世界不重要。作为一种社会性动物,人需要去履行一些社会职责。人的一生就是在力所能及的范围内减少无序状态,即所谓“局部熵减”,这是你的人生责任。
每个人都有自己的责任。我们生活在这个世界上,不可能每天躺在沙滩上冥想。人需要实现自我价值,应当承担起属于自己的职责和使命。
如果认为通过改变外部世界就能获得内心的平静、永久的开心、应得的幸福,那本质上就是痴心妄想。每个人都深受这种想法的毒害,包括我自己。我们一遍又一遍地坚持着自己的执念,认为“等得到那个东西,我就快乐了”。这就是一个我们时时刻刻都在犯的根本错误。[4]
我们的根本错觉是:总有一样东西会让我一直满足、永远快乐。
欲望就是你跟自己的约定,约定的内容是:不得到我想要的东西,我是不会快乐的。我觉得大部分人都没有意识到,这就是欲望的本质。我们每天都生活在欲望中,又奇怪为什么自己不快乐。我已然认识到,欲望是我痛苦的来源。所以,我会对欲望保持清醒,这样我就可以慎重选择自己的欲望。我的目标是,无论在什么情况下,都尽量不让自己对生活有一个以上的欲望。当然,我知道,即使只选择一个欲望,我也是在自寻烦恼。[5]
欲望就是你跟自己的约定,约定的内容是:不得到我想要的东西,我是不会快乐的。
最近我明白了一个道理:相较于做一些不是自己百分之百想要做的事情,努力调整欲望更重要。[1]
人在年富力强的时候,能做的事情更多。做得越多,欲望越多。
你没有意识到,这种模式正在破坏你的幸福。我发现,人越是年轻,身体越好,幸福指数越低。随着年龄的增长,身体没那么好了,幸福指数反而提升了。
年轻的时候有时间、有健康,但没有钱。到了中年,有钱、有健康,但没有时间。老了以后,有钱、有时间,但没了健康。人生的大赢家就是同时拥有时间、健康和金钱。
等到人们觉得自己已经拥有足够的金钱时,他们却失去了时间和健康。[8]成功不一定带来幸福幸福就是满足现状。
而成功源于对现状的不满,是对现状的改造。
两者只能选一个。
有人说,人有两次生命,第二次生命始于你意识到生命只有一次的那一刻。你的第二次生命是何时开始的?又是怎样开始的?
这是一个非常深刻的问题。大多数人到了一定的年纪都会有这种感受。他们以某种方式生活,到达了一定的人生阶段后,不得不做出巨大的改变。我就属于这类人。
我花了很多时间奋力拼搏,就是为了获得物质上的成功和社会的认可。得到之后(至少当这些东西对我来说已经没有那么重要的时候),我意识到,身边跟我一样成功或正在奋力取得更大成功的人,似乎并没有那么幸福。我个人的经验完全符合享乐适应理论:再好的东西,我也很快就习惯了,它们无法再带给我刺激或愉快的感觉了。
于是我得出这样一个结论:幸福是一种内在感受。这句话听起来像老生常谈,但正是由于这个结论,我开启了一场自我对话、自我完善之旅,这让我意识到,所有真正意义上的成功都是内在的,与外部环境关系不大。
当然,有些事情还是必须做的,这是由人的生物性和社会性决定的,不是一个按钮就能关掉的。当你获得属于自己的人生体验时,这种体验会把你带回内在之旅。[7]
当我们对一个游戏尤其是回报很大的游戏逐渐上手时,一个问题就会出现——你会沉迷其中,无法停止,即使这个游戏对你来说早已过于简单。
生存和繁衍的本能驱使人们劳作,而享乐适应让我们步履不停。
幸福的秘诀在于,知道何时停下劳作的脚步,开始随心去玩耍。
谁是你心目中的成功人士?
大多数人对成功人士的定义都是赢得游戏的人,无论是什么游戏。如果你是运动员,你眼中的成功人士就是顶级运动员。如果你经商,你眼中的成功人士也许就是埃隆·马斯克。
几年前,我会说我眼中的成功人士是史蒂夫·乔布斯,因为他参与推动的创新项目改变了全人类的生活方式。马克·安德森在我看来也是成功的,不是因为他最近摇身一变,成为风险投资人,而是因为他创立了卓越的网景公司。还有创造了比特币的中本聪,比特币是一项了不起的技术创造,其影响要延续至未来几十年。当然,还有埃隆·马斯克,他改变了大众对现代科技和创业可能性的认知。我认为,这些能成功实现商业化的人都是成功人士。
对现在的我来说,真正的赢家是那些已经完全退出游戏的人,甚至根本不玩游戏的人,是那些已经超越了游戏的人。这些人的内心无比强大,有极强的自控力和清醒的自我意识,他们不需要从任何人那里获得任何东西。这样的人我也认识几个,比如耶日·格雷戈雷克。他就不需要任何人为他提供任何东西。他内心平静,身体健康,无论赚的钱跟别人相比是多还是少,他的心理状态都不会受到影响。
纵观人类历史,传奇的佛陀和克里希那穆提在我看来都是成功的。我喜欢阅读与他们有关的作品。我之所以认为他们成功,是因为他们完全退出了游戏,输赢对他们来说并不重要。
布莱士·帕斯卡说过:“人之所以有烦恼,是因为他不能独自安静地在一个房间里坐着。”如果你能坐上30分钟,同时保持幸福的心境,你就是成功的。这是一种超然物外的境界,不过极少有人能做到。[6]
我认为,幸福的自然属性是平和。如果你身心宁静平和,那么你终将得到幸福。但是,平和的心境是很难获得的。颇具讽刺意味的是,我们大多数人都试图通过斗争找到平和。在某种程度上,创业就像打仗。当你和室友争论谁该洗碗的时候,你们也是在打仗。它们都是试图通过现阶段的挣扎换取日后的些许安全与平和。
在现实生活中,内心的平和状态不是一劳永逸的,也不会是一成不变的。心理状态总在不断变化。在大多数情况下,接受并顺应现实,是获得幸福的核心技能。[8]
基本上你可以从生活中得到自己想要的一切,但前提是,你的目标只有一个,而且你对这件事的渴望超过其他一切。
就个人的经验而言,我最想要的就是内心的平和。
平和是静态的幸福,幸福是动态的平和。只要愿意,你就随时可以把平和激活,使之变成幸福。但是大部分时间你想要的其实是被封印的幸福,即平和。如果你是一个内心平和的人,那么无论做什么事你都可以获得幸福的体验。
人们以为,获得平和心境的方式是解决所有的外部问题。但外部问题是无穷无尽的。
因此,获得内心平静的唯一方法是摒弃“问题”这个概念。[77]嫉妒是幸福的敌人我认为,生活本身没有那么难,是我们自己把生活变难了。我在生活中努力摆脱“应该”这个词。当“应该”在脑海中出现时,其背后隐藏的是负罪感或社会规训。如果做一件事是因为“应该”,那就表示你内心是不想这么做的,而违背自己的心意会让你变得痛苦不堪。因此,我努力在生活中减少“应该”做的事。[1]
内心平和的敌人是社会和其他人灌注给你的期望。
社会告诉我们:“快去锻炼吧。好好打扮吧。”这是一场多人竞争的游戏,我们做得好不好会受到别人的检视。社会还告诉我们:“快去赚钱吧。去买栋大房子吧。”这又是一场外在的多人竞争游戏,参与游戏的人也会受到别人的检视。而训练自己获得幸福感完全是内在的,不需要外界评判你的进展,认可你的结果。你是在跟自己竞争,这是一场单人游戏。
人类和蜜蜂或蚂蚁一样是社会性生物。我们遵从一定的社会规则,受到社会反馈的驱动。结果就是,我们已经不知道如何玩儿和赢得这些单人游戏了。我们完全投身于多人游戏的竞争。
而现实是,生活就是一场单人游戏。人独自出生,独自死亡,独自解读人世间的一切。你的记忆只属于你一个人。你出生前无人在意,你离开人世后也无人在意,你存在于人世间只是短短几十年,人生就是一场单人游戏。
瑜伽和冥想很难坚持的一个重要原因也许就是,它们只关乎内心,没有外在价值,属于纯粹的单人游戏。
巴菲特曾经提出这样一个问题,你是想成为世人眼里最差但自己心里最好的情人,还是想成为世人眼里最好但自己心里最差的情人?这个问题就是一个很好的例子,它说明存在内在和外部两套评价标准。
这个问题完全抓住了重点,即所有真正的评价标准都是内在的。
嫉妒是一种很难克服的情绪。我年轻的时候嫉妒心很强。随着阅历的增加,我逐渐学会了克服嫉妒,当然,嫉妒仍会时不时地冒出来。嫉妒是一种有害的情绪,因为归根到底,它并不能改善你的生活,只会让你不快乐,而你嫉妒的那个人仍然是成功的、美丽的,仍然拥有你所嫉妒的一切。
直到有一天,我意识到,我嫉妒别人,只是嫉妒他们的某些方面,而我不可能只拥有我嫉妒的那些东西。我不能只想要那个人的身材、财富或个性。如果要交换人生,我就必须接受对方全部的人生,包括他的反应、欲望、家庭、幸福感、人生观、自我形象等各个方面。你可以接受吗?如果你不愿意与别人进行百分之百的交换,嫉妒就毫无意义。
当我意识到这一点时,嫉妒心瞬间就消失了,因为我不想成为其他任何人。我很高兴我是我自己。顺便说一下,即使是“开心做自己”这件事,也在我的掌控之下,只是社会不会因此给我任何奖励。[4]幸福源于好习惯在过去的5年中,最让我意外的发现是,获取平和与幸福其实是一种技能,这种技能不是与生俱来的。当然,基因会决定一个人感受的上限和下限,环境也会产生较大的影响,但个体可以突破环境的塑造,主动进行自我重塑。
幸福感是可以逐渐增加的,而要做到这一点,首先要相信自己可以做到。
获取幸福是一种技能,就像懂得营养搭配是一种技能,节食减肥是一种技能,锻炼是一种技能,赚钱是一种技能,与异性交往是一种技能,拥有良好的人际关系是一种技能,爱也是一种技能一样。要掌握这些技能,首先要认识到技能是可以通过学习获得的。一旦下定决心学习技能,你的世界就会变得更加美好。
工作时,和比自己更成功的人在一起。
玩耍时,和比自己更快乐的人在一起。
幸福是一种什么样的技能?
要掌握获取幸福这个技能,你需要不断试错,通过亲身体验找到哪些方法有用。比如,你可以试试坐姿冥想,它对你有用吗?是密宗冥想有用,还是内观冥想有用?是需要10天的静修,还是20分钟就够了?
如果这些冥想都不管用,那就试试瑜伽、冲浪、赛车或者烹饪。
去尝试各种各样的事情,看哪件事能让你进入禅定状态。你必须广泛尝试,直到找到适合自己的事情。
在精神疾病的药物治疗中,安慰剂效应是百分之百存在的——只要病人相信药物有效,就算吃的是安慰剂,也能缓解病情。因此,想要改善心境,你需要主动尝试不同的方法,而不是顾虑重重,自我封闭。对于任何针对心灵的方法,你都应该保持开放的心态,但试无妨。
例如,前段时间我读了埃克哈特·托利写的《当下的力量》。这本书介绍了如何活在当下,内容非常精彩,对没有宗教信仰的人来说尤其有用。托利认为,人生最重要的事情就是活在当下。为了让读者真正理解,他在书中苦口婆心地反复陈述了这个观点。
书中介绍了一种身体能量练习,就是平躺下来,感知能量在身体四周流动。要是放在以前,读到这里我肯定把书扔到一边去了,因为我会觉得这纯属一派胡言。但是,现在的我不一样了。现在的我会想:“也许心诚则灵。”于是,我以积极的心态尝试了一下身体能量练习。我躺下冥想,结果获得了特别好的体验。
我们该如何打造获取幸福的技能?
可以通过养成好习惯来获取。不喝酒、不吃糖可以提高情绪的稳定性,远离社交媒体(脸书,Snapchat和推特)也可以提高情绪的稳定性。玩电子游戏会带来短暂的快乐(我一度痴迷于游戏),但会摧毁长期的幸福。喝咖啡也属于用长期健康换取短期兴奋。这些不受你控制的外界因素会刺激你体内多巴胺的分泌,刺激因素一旦消失,多巴胺水平就会下降。
从本质上讲,生活的过程就是用精心培养的好习惯替换那些在不经意间养成的坏习惯,努力成为一个更幸福的人。你的幸福指数最终取决于你的习惯和你花最多时间与之相处的人。
先说习惯,小时候,我们是没有什么习惯的。后来,我们知道了哪些事情不能做,拥有了自我意识,开始养成习惯和行为模式。
随着年龄的增长,有些人的幸福感越来越强,而有些人变得越来越不快乐,一个重要的原因就是,两类人群习惯不同。在选择习惯的时候,你需要考虑清楚:这是能增加我的长期幸福感的习惯吗?
再说一下你花最多时间与之相处的人。你可以试着回答这些问题:他们都是积极乐观的人吗?维系跟他们的关系需要耗费很大的心力吗?我是否对他们心怀钦佩和尊敬,毫无嫉妒之心?
“五只黑猩猩理论”讲的是,通过观察最常与一只黑猩猩一起玩耍的五只黑猩猩,你就能准确预测这只黑猩猩的行为方式。我觉得这一理论也适用于人类。这也是为什么我们在选择朋友时一定要明智,道理的确如此。不能因为一个人恰好是你的邻居或同事,你就不加选择地跟他成为朋友。最幸福和最乐观的人会选择五只正确的黑猩猩做朋友。[8]
处理冲突的首要原则是,不要和经常参与冲突的人在一起。我对任何不可持续甚至难以维系的事情都不感兴趣,包括人际关系。[5]如果不想跟一个人共事一生,那就一天都不要和他共事。
我有个伊朗朋友叫贝赫扎德,他热爱生活,无暇理会不快乐的人。
如果你问贝赫扎德有什么幸福的秘诀,他只会抬头望天,然后说:“停止追问,开始欣赏。”世界如此神奇,而人类却对此如此麻木,习惯把一切都视为理所当然。就像此刻的你我,身处室内,衣食无忧,可以跨越空间相互交流。我们应该感恩所有,因为如果不是现代文明,我们可能还只是猴子,坐在丛林里,看着太阳落山,不知道晚上栖身何处。
如果贪心不足,当有所得时,我们就会认为这本是世界欠我们的。反之,如果活在当下,怀有感恩之心,我们就能觉察到被赐予了丰厚的礼物,时刻都被无穷无尽的财富围绕着。要获得幸福感,真正需要的就是拥有这种觉知。此时此刻,我就在这里,这么多不可思议的东西都能为我所用。[8]
获得幸福最重要的诀窍之一就是,认识到这是一种你可以锻炼的技能,是一个你可以做出的选择。也就是说,一个人可以选择幸福,并为之奋斗。这跟选择减脂增肌、为事业奋斗、学习微积分没什么两样。
“幸福对我来说很重要”——这是一个决定。这时,你会把幸福感置于人生一切事务的首位,你会花时间研究与幸福相关的探讨。[7]
幸福习惯
我有一系列可以帮助我活在当下、提升幸福感的技巧。刚开始,这些技巧看上去有些傻里傻气,很难掌握,需要集中注意力才能做到。但现在,大部分技巧已经成为我的第二天性。我认真虔诚地运用这些技巧,成功地提高了自己的幸福指数。
效果最明显的技巧是洞察冥想。我在冥想时有一个明确的目标,就是弄清楚自己的思维是如何运转的。[7]
其实就是时时刻刻都保持洞察。如果我意识到自己正在对别人评头论足,我就会停下来自问:“我能不能正面解读这件事?”我过去常常因为一些事情感到恼火,但现在总会尝试看到积极的一面。刚开始,我可能需要花几秒钟,动用理性分析才能想出一种积极的解读方式。现在,不到一秒钟我就可以完成。[7]
我努力让更多阳光照射在自己的皮肤上。我心中敞亮,抬头微笑。[7]
每当意识到自己对什么东西产生了欲望时,你可以自问:“这个东西对我来说真的那么重要吗?我至于因为这件事不合我意就感到不开心吗?”在大部分情况下,你会发现,这个东西对你来说其实并没有那么重要。[7]
我觉得戒掉咖啡因提高了我的幸福感,因为我的情绪更稳定了。
[7]
我认为每天锻炼让我更快乐了。身体健康,内心就更容易平和。
[7]
对周遭评判得越多,自我就越膨胀。在某个瞬间,你状态极佳,因为此时你自我感觉良好,觉得自己比别人强。过了一会儿,你就会被孤独感吞噬,目之所及都是烦恼。这个世界是一面镜子,会把你的感受反射给你。[77]
告诉你的朋友你是一个幸福的人,这样你就不得不表现出幸福的状态。一致性偏见此时便会发挥作用,因为你得言出必行,过得符合自己的描述。你的朋友也会期待你是一个幸福的人。[5]
尽量不要使用电话、日历和闹钟这三个手机应用程序,重获时间和幸福感。[11]
你的秘密越多,幸福感就越低。[11]
陷入惶恐怎么办?用冥想、音乐和运动重新调整情绪。然后把让你感到惶恐的事情放下,选择新的事情,把情绪能量投入其中。
人造物品(汽车、房子、衣服、金钱)比自然物品(食物、性、运动)更容易导致享乐适应。[11]
看屏幕的时间越长,幸福感越低;看屏幕的时间越短,幸福感越高。[11]
幸福指数的个人衡量标准是,一天中你有多少时间用于履行职责,而不是追随兴趣。[11]
新闻的目的就是让人感到焦虑和愤怒。但新闻背后的科学、经济学、教育和冲突趋势是有积极意义的。要保持良好的心境、乐观的心
态。[11]
政治、学术和社会地位都是零和游戏。正和游戏才能造就积极向上的人。[11]
阳光、运动、正向思考和色氨酸,这些不是药物,但都可以增加大脑中的血清素,使人始终保持健康、清醒、积极、乐观。[11]
如何改变习惯选择一件事情,许下一个愿望,并使其具象化。
规划一条可持续的路径。
确定需求、诱因和替代品。
把自己的规划告诉朋友。
一丝不苟地稳步前行。
自律是通向新的自我形象的桥梁。
全面接受新的自我形象,这就是现在的你。[11]
这就是改变习惯的步骤:首先,知道自己要做什么;其次,知道该怎么做;再次,把规划告诉朋友,让一致性偏见发挥作用;最后,严格自律,知行合一,进行自我重塑,直至蜕变成全新的自己。
于接受中寻找幸福在生活中,无论面对何种状况,你都有三种选择:改变现状,接受现状,逃避现状。
试图改变现状是一种欲望。在成功改变现状之前,欲望会让人感到痛苦。所以不要总想着去改变外部环境。在任何特定的时间段,只选择一个最有价值的欲望,作为自己的奋斗目标和动力之源。
为什么不能同时选择两个欲望?
因为这样会让人分心。
即使追求一个欲望,也已经很难了。平静的内心源于毫无杂念的大脑。而消除杂念,很大程度上依赖于活在当下。如果你一直在想,“我需要这样做,我想要那个东西,这种情况必须改变”,你就很难保持心态平和。[8]
再次强调,无论面对何种状况,你都有三种选择:改变现状,接受现状,逃避现状。很多人在遇到问题时会踟蹰不前,陷入空想:希望改变现状却没有横下一条心去改变,希望转身离开却没有毅然决然地离去,同时又不能心平气和地接受现状。这种纠结和回避的态度正是人生中大部分痛苦的来源。我在脑海里对自己说得最多的就是两个字:接受。[5]
你所谓的“接受”是什么样子的?
所谓接受,就是无论结果如何,都可以泰然处之;就是保持心态平衡,大脑专注;就是退一步海阔天空;就是观大势,顾全局,谋长远。
人生不如意事十之八九。但是,该来的终归要来,有时,正在发生的也许就是最好的。我们越早接受现实,就能越早适应现实。
达到“接受”的状态是很难的。我尝试了几个小方法,但不敢说每个方法都百分之百有用。
一个方法是退后一步,回顾经历过的痛苦。我还会把这些痛苦写下来:上次分手,上次生意失败,上次健康出问题,后来都发生了什么?这样我就可以看到在随后的几年里我的成长和进步。
另一个应对小挫折的方法就是换个角度看问题。当我遭遇挫折时,部分自我会立即做出消极反应。但现在我已经学会自问:“这种情况有什么积极的意义吗?”
比如,开会要迟到了,这件事对我有什么好处吗?好处就是我可以放松一下,看鸟观云。而且,我也可以少花一些时间在那个无聊的会议上。任何事情都有积极的一面。
就算找不到积极的意义,你也可以这样想:“宇宙现在要给我上一课了,我要认真听讲,好好学习。”
举个最简单的例子,我参加了一个活动,后来主办方往我的邮箱里发了一大堆照片。
我的第一反应就是:“搞什么鬼,就不能挑几张好的发给我吗?谁会给别人邮箱发100多张照片?”但是我会马上问自己:“这件事有积极的一面吗?”积极的一面就是,我可以选择自己最喜欢的5张照片,我可以靠自己的判断力来选择了。
过去一年,经过勤奋练习,我已经成功地降低了自己的反应时间。最开始我需要花几秒钟才能找到一件事的积极面,现在,我的大脑几乎瞬间就能做出反应。这是一个可以训练自己去养成的习惯。[8]
如何学会接受无法改变的事情?
从根本上说,就是学会坦然面对死亡。
死亡是人的一生中最重大的事情。人终有一死,选择正视、承认死亡而不是逃避死亡,将赋予人生巨大的意义。我们在一生中会花费大量时间试图逃避死亡。我们的很多奋斗目标都可以归结为对永生的追求。
如果你有宗教信仰,相信有来世,那么你会相信你将得到照顾,无须担心身后事。如果你不信宗教,也许你会生孩子,把自己的基因传承下去。如果你是一位艺术家或画家,你会想要留下自己的艺术作品。如果你是商人,你会想要留下一笔商业遗产。
但是,在这里我要特别提醒一下,其实,我们没有什么遗产,没有什么可以留下的,也没有什么会永垂不朽。我们都会离开这个世界,我们的孩子也会离开这个世界;我们的成就终将化为尘土,人类文明也会化为尘土;我们的地球将变成尘埃,太阳系也会化作尘埃。
从宏观角度看,宇宙已经存在了100亿年,并将继续存在100亿年。
相对于宇宙,你就像一只在夜空中闪烁的萤火虫,你的生命转瞬即逝。如果能彻底认识到你所做的一切不过是徒劳,你就能获得巨大的幸福感和平和感,因为你会意识到,生命不过是一场游戏。但生命是一场有趣的游戏。在这场游戏中,唯一重要的事情就是,随着生命的展开,你要不断地体验现实。既然如此,你为什么不以最积极的方式去诠释自己经历的一切呢?
你那些不开心的时刻、没有享受人生的时刻,不会给任何人带来任何好处。宇宙的幸福值并不是恒定的,别人不会因为你不幸福而变得更加幸福。你在地球上所拥有的时间稍纵即逝,无比宝贵,你一定要好好珍惜。你要把直面和正视死亡放在第一位。人的一生,不否认、不回避死亡是极其重要的,因为这是你学会坦然接受无法改变的事情、活在当下的本原。
每当陷入自我斗争时,我就会回想所有曾经辉煌、后遭覆灭的文明。以苏美尔人为例,我敢肯定,苏美尔人中有过很多重要人物,他们取得了很多伟大的成就。但是,你现在能想起任何一个苏美尔人的名字吗?你能想到苏美尔人做过什么有趣或重要的事情吗?你肯定什么都想不到。
所以,也许1万年、10万年后,人们会说:“哦,对,美国人,我听说过美国人。”[8]
人固有一死,死后万事皆空。所以,好好享受生命吧。对社会做一些积极的贡献。向世界主动释放和传播爱。给他人带来快乐和幸福。让生活多一些笑声。珍视眼前的每个瞬间。承担使命,尽职尽责,不枉此生。[8]
第四章 自我救赎
医生不能让你健康。
营养学家不能让你苗条。
老师不能让你变聪明。
禅师不能让你冷静。
智者不能让你富有。
教练不能让你健壮。
最终,你必须自己负起责任。
救赎靠自己。
选择做自己当今社会存在的一个普遍现象,也是许多人此刻正在做的事情,就是苦苦挣扎,自我鞭策:“我需要做这件事,我需要做那件事,我需要……”不,你什么都不需要做。
你唯一应该做的事,是你自己想做的事。别人总希望你以特定的方式做事,但如果不再费心去揣摩别人的期待,你就能听到自己脑海中那个微弱的声音。那个声音代表了你真实的想法。倾听它,你就可以做自己了。
我从未亲眼见过那位伟大的导师。我一度极其渴望成为他那样的人。但是,他传达给我的信息恰恰相反:做自己,全情投入、义无反顾地做自己。[1]
在“做自己”这件事情上,没有人能与你竞争。你永远不会像我一样擅长做我自己,我也永远不会像你一样擅长做你自己。当然,做人要虚心聆听,博采众长,但不要盲目模仿。模仿他人纯属徒劳。相反,每个人都有独一无二的资质技能、专业知识、能力才干、个人欲望,这些是世界上其他人所没有的,是先天基因和后天经验共同作用的结果。
先天基因和后天经验的组合会造就个体惊人的独特性。没有任何两个个体可以互相替代。
你的人生目标是找到最需要你的人、事业、项目或艺术。大千世界,芸芸众生,总有一些人和事会与你完美契合。不要基于别人正在做的事为你自己列清单、做决策。你永远不会成为他们,你永远都不擅长做另一个人。[4]
要做出原创性贡献,必须非理性地痴迷。
[1]该推文发表于2011年10月10日,乔布斯逝世后第五天。——编者注选择关爱自己我生活中的第一要务是我的身体健康。对我来说,健康的重要性高于幸福,高于家庭,高于工作。我的身体健康是一切的起点,排在第一位,紧随其后的是我的心理健康和精神健康。接着是家人的健康和幸福。在确保了这些之后,我就可以按照自己的意志在这个世界上自由活动了。[4]
健康问题是对人生影响最大的问题。
作为一种高级动物,人类应该遵循符合自然规律的生活方式,现代社会是如何让我们逐渐背离了应有的生活方式的?
这种背离体现在方方面面。
从生理层面看,现代人的饮食结构不符合进化的目标。正确的饮食结构应该更接近旧石器时代,以蔬菜为主,辅以少量的肉类和浆果。
就运动而言,人类更应该去户外玩耍活动,而不是在跑步机上挥汗如雨。在正常的进化过程中,我们本该更均衡地使用视觉、听觉、嗅觉、味觉、触觉这五种感官,而不是如此侧重视觉。在现代社会,几乎所有的输入和交流都依靠视觉。我们在走路时本不该穿鞋,很多背部和脚部问题都是穿鞋造成的。我们不应该一直穿着衣服来保持身体的温度,而应该不时接触冷空气,因为寒冷可以激活人体的免疫系统。
我们本不该生活在一个完全无菌、彻底干净的环境中,因为这种环境无法有效训练人体的免疫系统,进而导致过敏频发,这就是所谓的“卫生假说”。我们应该一直生活在成员众多、子孙满堂的部落式大家庭中,因为这样的家庭模式有利于心理健康。我在印度长大,印度的家庭规模一般都很大,你会和堂兄弟姐妹、姑姑、叔叔等亲人生活在一起,很少有独自待着的时候,所以一般不会抑郁(我说的不是因体内化学物质水平变化导致的抑郁,而是青少年会普遍经历的存在主义焦虑和不安)。但另一方面,生活在这样的家庭里,你没有隐私,因此无法获得自由。凡事有利必有弊。
我们本不该每5分钟就拿起手机查看一下社交媒体。当看到别人给我们点赞时,我们会很开心,如果别人留下一句愤怒的评论,我们就会很生气。情绪上的大起大落让我们无比焦虑。生物进化的目标本来是适应物质的匮乏。为了应对匮乏,基因决定了我们看到糖分、酒精、毒品就难以抗拒,遇到亲密关系也无法拒绝。但是,现代人生活在一个富足的世界里,面对琳琅满目、应有尽有的一切,当我们的基因一直在说“要要要”的时候,我们本该拒绝,但我们的身体已经不知道如何说不了。所以,在现代社会,我们逐渐背离了符合自然规律的生活习性,形成了病态的生活方式。[8]
当所有人都有病时,我们就不认为这是一种病了。
饮食
除了数学、物理和化学,并没有什么“科学定论”。所以,关于“最佳饮食”问题,我们一直争论不休。
你如何看待生酮饮食法?
我觉得生酮饮食法很难被人们普遍接受和坚持。人的大脑和身体存在备用机制,大自然的这种设计是有意义的。例如,在冰期,人类在没有很多植物可供食用的环境中进化。后来,在备用机制的作用下,人们选择多种植物作为自己的食物。到现在,人类食用植物已有几千年的历史。我虽然并不认为植物对身体有害,但我感觉接近原始的饮食结构应该更好。
我觉得糖和脂肪的相互作用非常有意思。给人带来饱腹感的食物是脂肪,因此,高脂肪的食物容易让人吃饱。产生饱腹感最简单的方法就是进行生酮饮食,大量吃培根,吃到恶心、想吐,吃到你再也不想看到脂肪了。
让人产生饥饿感的食物是糖。糖会给你的身体发出这样的信号:“在我们进化的环境中竟然有这么好的食物资源。”于是你会迫不及待地摄取糖分。问题在于,糖效应凌驾于脂肪效应之上。在高脂高糖的饮食中,糖会让人产生饥饿感,脂肪会提供卡路里,从而导致暴饮暴食。这也是为什么所有的甜点都含有大量的脂肪和碳水化合物。
在自然界中,集合了脂肪和碳水化合物的食物较为罕见,椰子、杧果、香蕉等水果属于这类食物,但它们基本上都是热带水果。糖和脂肪的结合是致命的,在饮食中我们必须注意避免摄入此类食物。
我不是专家。但问题是,饮食和营养就像政治一样,每个人都认为自己是专家。因为他们认为饮食关乎身份,所以他们吃的东西或者他们认为应该吃的东西显然应该是正确的答案。关于饮食,每个人都有自己的理念,很难达成共识。我只想说,一般来说,任何合理的饮食都会避免糖和脂肪的混合摄入。[2]
膳食中的脂肪会带来饱腹感,糖会导致饥饿感。但糖效应占据主导地位,所以我们需要相应地控制自己的食欲。
大多数身体健康的人更关注自己吃什么,而不是吃多少。控制质量比控制数量更简单易行,而且控制质量也在一定程度上控制了数量。[11]
颇具讽刺意味的是,禁食(以低碳水化合物或旧石器时代的食物为主)比控制饮食更容易。身体一旦检测到食物的信号,生物本能就会掌控大脑发出指令。[11]
我一直很好奇,神奇面包是如何做到在室温下存放数月依然保持柔软的。如果连细菌都不吃这种面包,你觉得你应该吃吗?[11]
五千年已经过去了,我们还在争论是肉有毒还是植物有毒。我们要做的是,停止这种毫无意义的讨论,抛弃极端主义者的观点,而且不要食用过去几百年内发明的任何食物。[11]
任何涉及药物和营养的问题,都要先做减法,再做加法。[11]
我的教练有时会给我发他吃饭的照片。他吃的东西非常简单清淡,这让我意识到,我们都已经口味成瘾了。[11]
世界上最简单的饮食原则:食物加工程度越深,就应该越少摄入。
运动锻炼越卖力,一天越轻松。
你认为哪种运动习惯对你的生活有最积极的影响?
晨练。晨练完全改变了我的人生。晨练让我感觉更健康、更年轻。为了晨练,我得早早起床,这样我就不能太晚回家了。想要养成晨练的好习惯,其实很简单。但是,基本上,无论你什么时候跟别人分享所谓的好习惯,他们都会给自己找到借口,最常见的借口就是“我没时间”。表面上说的是“我没时间”,但其实说的是,“这对我来说不是优先事项”。到底要不要做,就要看这件事是不是你优先考虑的事项。如果一件事是你的首要任务,你就会去做。生活就是这样。如果你有10个或15个不同的优先事项,都不分主次地被丢到同一个筐里,那就等于没有优先级,最终你一件事都做不成。
我所做的就是,认定我生命中的第一要务是自己的身体健康,这件事的优先级高于我的幸福,高于我的家庭,高于我的工作。一切始于身体健康。[4]我把身体健康放在第一位,所以我永远不会以“没时间”为理由不去健身。基本上我每天都坚持晨练,不管多长时间,我都会坚持,雷打不动。如果这一天没有晨练,我就不会开始工作。即使是山崩地裂、世界末日我也不管,世界可以再为我等上30分钟,直到我完成晨练。
我几乎每天早上都锻炼,只有个别几天,可能因为旅行、受伤、生病,或别的什么原因,不得不休息。我每年跳过晨练的次数屈指可数。[4]
一个月的瑜伽练习让我感觉年轻了10岁,保持身体的柔韧性就是保持年轻的状态。
养成习惯的方法和过程并不重要,甚至连做什么都不重要,重要的是每天坚持。很多人纠结于举重训练、网球、普拉提、高强度间歇训练和“快乐身体”健身法到底哪个最有效。其实他们搞错了重点。我要重复一遍,每天坚持才是最重要的,坚持做什么是次要的。对个人而言,最好的锻炼就是每天都能坚持去做的那种锻炼。[4]
边走边开会的好处:
-
提高大脑工作效率
-
锻炼身体,享受阳光
-
时间简短,省去客套话
-
增加对话交流,减少自说自话
-
不用播放幻灯片
-
结束很简单——走回去就行了
生活中的所有事情都一样,如果愿意做出短期的牺牲,你就会得到长期的好处。我的体能教练耶日·格雷戈雷克是个非常聪明的人。他总是说:“选择简单模式,人生会越来越困难;选择困难模式,人生会越来越简单。”
现在选择困难的饮食模式,也就是虽然很想吃垃圾食品,但是忍住不吃,同时选择困难的锻炼模式,不怕辛劳。长此以往,你的生活会变得越来越容易。你不会轻易生病,不会不健康。价值观的培养、未雨绸缪的储蓄、人际关系的处理都是如此。 如果你现在选择一条容易的路,那么你的未来会变得更加艰难。 [4]冥想+精神力量情绪是生物进化的产物,能预测当前事件对未来的影响。在现代社会环境中,情绪反应通常是夸张的,甚至是错误的。
为什么冥想的力量如此强大?
人体的周围神经系统由自主神经系统和随意神经系统两部分构成。两个系统有少数重合之处,呼吸就是其中之一。呼吸是无意识的动作,但也可以通过大脑自主控制。
很多冥想练习都强调呼吸,因为呼吸是进入自主神经系统的入口。医学文献和精神文献中的众多案例表明,有些人可以深度控制自己的身体,可以控制那些本来自主的活动。
人的思想力量非常强大。前脑向菱脑发送信号,然后由菱脑向整个身体调配和分发资源。那么,这一过程是如何调节的?又有什么不同寻常之处?
其实,你通过呼吸就可以完成资源的合理调配和分发。放松的呼吸会告诉身体你现在处于安全状态。这样,前脑所需的资源不会像平常那么多。额外的能量可以被送到菱脑,而菱脑可以将这些资源重新分配给身体的其他部分。
这并不是说,仅靠激活菱脑就能战胜任何疾病,而是可以把大部分正常情况下关心外部环境所需的能量用在免疫系统上,以此提高你
的身体机能。
我强烈推荐读者收听蒂姆·费里斯与维姆·霍夫共同录制的一期播客。维姆·霍夫是一个奇迹般的存在。维姆的绰号是冰人,他保持着冰浴和冰泳时间最长的世界纪录。他给了我很大的启发,不仅因为他能够完成超人般的体能壮举,还因为他同时保持着和善乐观的个性——这就很难得了。
他提倡接触低温环境,因为他认为人类已经过于脱离自然环境了。我们饿了就吃东西,冷了就穿衣服,一直让自己处于温暖的状态,身体已经忘记了寒冷的滋味。寒冷对我们来说很重要,因为它可以激活我们的免疫系统。
因此,他提倡进行长时间的冰浴。我出生在印度次大陆,所以对冰浴非常抵触。但是受到维姆的启发,我决定尝试一下冷水澡。结果,通过使用维姆·霍夫呼吸法,我成功地做到了。这种呼吸法要求你进行强力呼吸,以使更多氧气进入血液,提高核心温度。核心温度提高后,你就可以去冲冷水澡了。
最初的几次,情景非常滑稽,因为缩手缩脚,瑟瑟发抖,我只能站在花洒下面一点一点慢慢放松自己。我四五个月前开始洗冷水澡。
现在,我已经可以把花洒开到最大,然后径直走进去。我不给自己任何犹豫的时间。一旦听到脑海里有个声音说水非常冷,我就知道自己必须走进去。
这件事给我上了非常重要的一课:我们大部分的痛苦都来自逃避。洗冷水澡的痛苦主要源于进入冷水时的蹑手蹑脚和小心翼翼。一旦站到冷水下面,你就会发现那其实一点儿都不痛苦,只是有点儿冷。身体感觉到的冷跟头脑中想象的冷是不一样的。承认身体感到冷,并直面这种感受,应对它,接受它,但不要因此感到精神痛苦。
洗两分钟冷水澡不会要了你的命。
每天早上洗个冷水澡,可以帮助你不断复习这一课。现在,我已经把热水澡从生活中剔除了,我的需求又少了一个。[2]
冥想是思想意识的间歇性禁食。
太多糖会导致身体超重,太多干扰会导致大脑过载。
拿出时间独处,用来专注地自省、写日记、冥想,这可以解决
那些没有解决的问题,让超负荷的精神变得清明疏朗。
你现在在进行冥想练习吗?
我觉得冥想就像节食,大家似乎都有一套自己的方法。每个人都说自己在节食,但实际上没有人真正在做这件事。同样,真正定期冥想的人也屈指可数。对于冥想,我发掘并尝试了至少四种不同的形式。
我发现,对我最有效的一种冥想叫“无选择觉知”,或叫“无评判觉知”。这种冥想方式就是在处理日常事务时(最好有跟大自然接触的机会),不跟任何人交谈,练习接受自己所处的当下时刻,不做任何评判。既不去想,“那边有个流浪汉,我最好到马路对面去”,也不要看着跑步的人暗想,“这人身材走样了,我的身材比他好”。
从前,每次看到发量很少的人,我的第一反应通常都是:“哈哈,这个人头发真少。”我为什么要通过嘲笑他人让自己感觉良好呢?我为什么需要感觉自己的发量还不错呢?原因就是,我已经开始脱发了,我很担心自己的头发会掉光,所以才试图通过嘲笑发量不如我的人来获得心理安慰。我发现,我90%的想法都受到恐惧的驱动,剩下的10%可能受到欲望的驱动。
而在练习无选择觉知冥想的过程中,你不做任何决断,不评判任何事情,只是全盘接受。如果能在散步时这样做10到15分钟,你就能达到一种非常平静和感恩的状态。无选择觉知这种冥想法对我很有用。[6]
第二种方法是超觉冥想,就是通过反复唱诵,在头脑中制造一种白噪声来掩盖自己的想法。第三种方法就是对自己的想法保持高度敏锐和警觉。通过观察自己的想法,你会意识到很多想法都源于恐惧。
在你识别出恐惧的那一刻,恐惧感自然就消失了。一段时间过后,你的思绪就会平静下来。
思绪一旦平静下来,你就会认识到周围的一切都不是理所当然、天经地义的,你开始留意生活中的点滴细节。你会想:“哇,原来我生活的地方这么美。我有衣服穿,这多好啊,我还可以随时去星巴克喝咖啡。你看看周围的人,每个人的脑海里都有一个鲜活、丰富、完整的人生。”
在日常生活中,我们每个人都会不停地跟自己对话,沉浸在自己编织的故事中,而这种对周围事物的觉知会让我们从中跳脱出来。哪怕只有10分钟,你也能意识到我们已经处在马斯洛需求层次较高的阶段,生活其实非常美好。[6]生活技巧:躺在床上的时候,可以尝试冥想。这样,你要么进入深度冥想,要么会入睡。不管结果是哪种都很好。
我学到的第四种冥想方法是,坐在那里闭上眼睛,每天至少一个小时。此时,你以臣服的姿态接受发生的一切,不争取,不对抗。如果有想法在头脑中涌现,那就任其涌现。
人的一生会经历大大小小的事情,有好事,有坏事,其中大部分都会得到处理和解决,但还有一些会长久地伴随着你。随着时间的推移,这类事情会越积越多,就像藤蔓一样将你层层缠住。
这些不曾解决的痛苦、错误、恐惧和欲望已经成为你的一部分,像藤蔓一样附着在你的周身,让你失去童年时的好奇心,失去活在当下、乐在其中的能力,失去内心的快乐。
那怎样才能把这些藤蔓从身上扯下来呢?答案就是冥想。当冥想的时候,你只是坐在那里,不去对抗自己的思想。此时,这些事情开始在你头脑中翻滚。你就像面对一个充满了未回复邮件的巨大收件箱,这些邮件可以一直追溯到你的童年。问题一个接一个冒出头来,你不得不一一处理。
你别无选择,必须去解决这些问题,而解决问题不需要你付出任何努力——只要静静观察就好。现在,你已经是成年人了,以往的事件已经与你拉开了距离,你可以隔着时间和空间,以更客观的态度看待这些问题,进而直面、解决这些问题。
这样一来,你就会慢慢解决掉脑海中许多根深蒂固但尚未解决的问题。总有一天,全部问题都会得到解决,而到那个时候你再坐下来冥想,大脑就会进入“收件箱为零”的状态。当你打开大脑的“电子邮箱”,里面没有任何邮件时,那种感觉会特别奇妙。
那是一种快乐、幸福、平静的状态。一旦拥有了这种状态,你就不想再放手。如果每天早上只是闭上眼睛坐着就可以获得一个小时的幸福,那是多么弥足珍贵,它会改变你的人生。
我建议每天早上冥想一小时,因为少于一小时无法真正进入深度冥想。如果真的想尝试冥想,我建议以60天为周期,每天一小时,早上起来先冥想。大约60天后,你会厌倦倾听自己的心声。你应该已经解决了很多问题,或者你已经听够了自己的心声,看穿了那些恐惧和问题。
冥想并不难。你要做的就是坐在那里什么都不做。只是坐下来,闭上眼睛告诉自己:“我只想让自己休息一小时。这是我远离喧嚣生活的一小时,在这一小时里,我什么都不会做。”
“如果有想法喷涌而出,那就任其喷涌吧。我不会与之对抗,也不会进一步思考,既不接受,也不拒绝。我就在那里闭着眼睛坐一小时,什么都不做。”这样做能有多难呢?你怎么就不能在一小时内什么都不做呢?给自己一小时的休息时间有那么难吗?[74]
有没有哪一刻你意识到自己是可以控制对事物的理解的?我觉得一个普遍存在的问题是,人们没有意识到自己可以控制对一件事的理解和应对。
我觉得其实大家是知道的,在一定程度上,毒品的吸引力是精神层面的。人们摄入毒品(酒精、迷幻药、大麻等等),是因为他们试图控制自己的精神状态和反应。有些人喝酒,是因为喝酒可以让他们变得麻木;有些人吸毒,是因为吸毒可以让他们浑然无觉;还有些人使用迷幻药,让自己感受与当下和现实的强烈连接以及与大自然的联结。所以,毒品的吸引力是精神层面的。
从某种程度上说,整个社会都有沉迷和上瘾的症状。人们追求刺激的行为、心流状态或性高潮,其目的就是摆脱自己的思维,摆脱脑海中的声音,摆脱过分强烈的自我意识。
我的最低目标是,不让自我意识随着年龄的增长继续发展并被强化。我希望自我意识减弱、变柔和,这样我就可以更好地融入当下的现实生活,接受大自然和这个世界的本来面目,像孩子一样随心所欲、天真烂漫地欣赏一切。[4]
而要实现这一目标,先要认识到你是可以观察自己的精神状态的。冥想并不会瞬间赋予你控制内在状态的超能力,但会让你觉察到你的思想意识是多么失控。思想意识就像一只猴子,在房间里跑来跑去,大喊大叫,摔盆砸碗,投掷粪便,制造麻烦。思想意识是完全不受控的,就像一个失控的疯子。
你必须先看到这个疯子在肆无忌惮地横冲直撞,你感到不胜其扰。只有感到不胜其扰,你才会对其感到厌倦;只有感到厌倦,你才会与之分开,而这种分开就是解脱。你会意识到:“我不想成为那个人,我怎么会如此失控?”拥有这种觉知能让你平静下来。[4]洞察冥想是在“调试模式”下运行大脑,最终你会意识到自己只是一个大程序的子程序。
我有意识地密切关注自己的内心独白,不过有时也做不到。如果用计算机编程做类比,那就是我会尽可能地在“调试模式”下运行我的大脑。在跟他人交流或者参加团体活动时,想要运行“调试模式”几乎是不可能的,因为大脑有太多事情需要处理,但在独处的时候我可以做到。比如,今天早上我一边刷牙,一边在脑子里想象一期播客。我开始想象沙恩问我一些问题,也想象自己如何回答。然后,我突然意识到,我在天马行空地想象。于是我把大脑调整为“调试模式”,就这样看着指令一条条闪过。
这时,我就想:“我为什么要幻想未来的规划?我为什么就不能站在这里,集中精力刷牙?”我觉察到自己的大脑已经奔向未来,觉察到因为自我的存在,我开始幻想未来的一些场景。我就想:“我真的在乎自己会不会出丑吗?谁在乎呢?无论如何我都会死的。一切都会归零,我什么都不会记得,所以这一切毫无意义。”
然后,我停止大脑的运转,继续刷牙。我开始注意到牙刷有多好,自己的感觉有多好。下一刻,我又开始想别的事情了。我不得不再次审视自己的大脑,自问:“我真的需要现在就解决这个问题吗?”
大脑中95%的所思所想都是不需要即刻就处理的。大脑就像肌肉,最好让它多多休息,保持平静,只有在特定问题出现时才调动大脑,全身心地解决问题。
在我们聊天的当下,我就不能让大脑在“调试模式”下运行。这时,我需要全身心地投入我们的谈话,让自己百分之百专注,而不是想着“我早上刷牙的方式对不对”。
高度集中注意力是一种能力,这种能力与放松自我、活在当下、保持快乐的能力有关,当然,也与提高效能的能力有关。[4]
注意力高度集中就像把自己从一个特定的框架中抽离出来,虽然你还保持着自己的思维,但你看问题的角度已经变了,是这样吗?
佛教徒会探讨觉知与自我。我喜欢用计算机和极客的语言来比喻佛教的这种理念。其实他们真正讨论的是,可以把大脑和意识视为一个多层次的机制。这个机制以一个内核级的操作系统作为核心基础,其上又运行着一些应用程序。
我实际上是回到了大脑操作系统的觉知层面。在觉知层面,我是宁静的、平和的、快乐的、满足的。我试图保持觉知模式,而不是激活自己的心猿(浮躁不安之心),因为它总是提心吊胆、焦虑不已。
心猿当然有它的重要价值,但我希望只在需要的时候才激活它。当需要调动它的时候,我希望可以专注其中。如果思维每天24小时不间断运行,那就是对精力的浪费,也会让心猿主宰我的全部状态。但我不能只有心猿这一种状态,还要有其他状态。
我还想补充一点,无论是灵性、宗教(包括佛教),还是其他任何你所追随的东西,最终都会让你意识到,你不仅仅是自己的思维,你不仅仅是自己的习惯,你不仅仅是自己的偏好,你是一种觉知水平,你还是一具肉身。现代人对自己的身体感知太少,觉知水平也远远不够。我们过多地活在存在于大脑的内心独白里。而这些是我们年轻时由社会和环境塑造形成的。
每个人都有自己独特的基因组合。小时候,你的基因组合会对外部环境做出反应,同时你的大脑会记录下所有经历,不管是好的还是坏的。此后,你会利用这些记忆预判未来的所有事件,不断尝试预测和改变未来。
随着年龄的增长,你会积累海量的偏好。这些习惯性反应最终会变成失控的货运列车,控制你的情绪。但情绪不应该被下意识的反应控制,而应该由我们的意识主动控制。我们应该研究如何控制自己的情绪。如果一个人能按照意志调整状态,那就非常有掌控感。你只需要想“现在我想处于好奇的状态”,就可以真的进入好奇的状态。或者你可以想:“我现在想陷入哀伤的状态,我在哀悼一个我爱的人,向他献上我浓浓的哀思。我真的想有这种感觉。我不想为明天必须解决的计算机编程问题分心。”
大脑本身就是一块肌肉,可以被训练,可以被调节。但由于社会的随意破坏、随机塑造,大脑已经在我们的控制范围之外了。如果带着觉知和意图审视自己的大脑(这种审视应该是一个时时刻刻都要进行的长期练习),你就可以分析自己的思想、情绪、想法和反应。在自我剖析、自我了解的基础上,你就可以重新配置自己的系统了。你可以根据自己的需要重写程序。[4]
冥想是屏蔽社会的噪声,倾听自己的声音。
只有以冥想本身为目的,冥想才会“起作用”。
徒步旅行是行走冥想。
写日记是书写冥想。
冲澡是意外冥想。
静坐是直接冥想。
选择自我塑造最了不起的超能力就是改变自我的能力。
你一生中犯过的最大的错误是什么?你是怎么走出来的?
我犯过很多错。面对错误,我都用同样的方式进行反思和总结。
这些错误都是那个年龄段难以避免的,当时并不能觉察,只有事后才会显现出来。为了走出错误的阴影,我扪心自问:“当30岁时,你会给20岁的自己什么建议?当40岁时,你会给30岁的自己什么建议?”(如果年纪更小,你可以每5年为一个时间段这样问自己。)坐下来认真思考自己过去每一年的经历和感受:“2007年,我在做什么,我感觉怎么样?2008年,我在做什么,我感觉怎么样?2009年,我在做什么,我感觉怎么样?”
人生旅程有时顺风顺水,有时惊涛骇浪,生活总会以自己的方式继续,而每个人的旅程体验主要取决于自己的解读。生而为人,我们拥有三观五感、七情六欲,最后与世长辞。如何解读自己的遭遇,完全取决于自己,每个人对这些遭遇都有不同的解读方式。
说真的,如果人生可以重来,我还是会做出同样的选择,只是希望自己可以控制情绪波动,多一些宽容和平静,少一些戾气和愤怒。
以我年轻时的一个经历为例,这件事很多人都知道。当时我创立了一家非常成功的公司,但我没有获得相应的报酬,于是,我起诉了一些相关人员。最后,问题基本上得到顺利解决,我也得到自己想要的结果,但在此过程中,我却极度焦虑、无比愤怒。
换作今天,我不会再让自己被这种焦虑和愤怒的情绪控制。我会直接跟当事人谈:“事情是这样的,我准备这样做,我准备用这种手段。这样公平,那样不公平。”
我会意识到,怒气冲冲、情绪激动会带来完全不必要的严重后果。现在,我依然会坚持做自己认为正确的事情,但我从过往吸取教训,学会了从长计议,减少不必要的愤怒情绪。如果可以从长远角度冷静客观地看待问题,很多问题其实并不是问题。[4]
再强调一次,习惯就是一切——主导着我们的一切行为和思维方式。有些习惯是从小养成的,包括如厕、什么时候能哭、什么时候不能哭、什么时候能笑、什么时候不能笑等等。于是,我们逐渐养成了各种习惯——通过后天学习,一些行为变成了我们的一部分。
长大后,我们已经累积了成千上万个习惯。习惯成自然,这些习惯在我们的潜意识里不间断地运行,而大脑皮质只会留出一点点思考力来应对新问题。我们终究会成为自己的习惯。
我是从自己健身的过程中认识到这一点的。我以前从未坚持过日常训练。后来,我的健身教练给我制订了每天的训练计划,内容并不难,不会给身体带来太大的负担,但我必须每天坚持。久而久之,我感觉自己的身心状况发生了令人难以置信的变化。
想要拥有内心的平静,必须先拥有身体的平静。
坚持锻炼让我看到了习惯的力量。我开始意识到,一切都与习惯有关。在日常生活的每时每刻,我们要么是在养成新的好习惯,要么是在摒弃以前的坏习惯,而习惯的养成和摒弃都需要时间。
有人会说:“我想要保持身材,想要健康。现在我太胖了,身材都走样了。”塑形需要锻炼,如果只坚持三个月,是不能养成习惯的,锻炼的效果也无法维持。养成习惯、保持身材至少需要十年的时间。正常情况下,我们每过六个月就要改掉一些坏习惯、养成一些好习惯,当然,具体周期取决于自我改变的速度。[6]
印度哲学家克里希那穆提提出的一个观点就是,一切存在时刻处于一种内部变革的状态。人应当时刻准备好迎接彻底的改变。每当说“我打算尝试一个新东西”或者“我打算养成一个新习惯”时,我们其实都是在畏缩。[6]
我们实际上是在说:“我要为自己争取更多时间。”但我们应该做的是追随内心的渴望。如果你想认识一个漂亮姑娘,那就去认识她;
如果你想喝杯饮料,那就去喝一杯;如果你真的想做一件事,那就去做好了。
说“打算”,就是在拖延,就是在给自己找借口。不过,即使没有把想法付诸行动,至少也要对自己真实的心理活动保持觉知:“虽然我说我想做这件事,但其实并不是真的想。因为如果真的想,我早就去做了。”
如果真的想做一件事,有一个方法就是广而告之,让身边的人都知道。比如,你想戒烟,你可以对你认识的每一个人说:“我戒烟了,我做到了。我向你保证。”有想法就直接采取行动,就是这么简单。但大多数人都会说自己还没准备好,所以也就不会对朋友广而告之了。如果是这样,你就应该对自己诚实一点儿,直接承认:“我还没有准备好戒烟。我太喜欢抽烟了,要戒掉太难了。”
而如果真的想戒烟,你可以这样想:“我会为自己设定一个更合理的目标,先降到这个数量。我可以让身边的人监督我。我会先坚持三到六个月。达成这个目标后,我会设定下一个目标。我会采取力所能及的实际行动,而不是什么都不做,陷入自我责备。”
当真的想做出改变时,你就会直接去做。然而,大多数人并不是真的想改变,暂时也不想承受其中的痛苦。但至少我们可以承认这一点,对自己的感受和想法保持觉知,这样,我们就可以给自己设定切实可行的小目标,让自己真正行动起来。[6]
迅速采取行动,并对结果保持耐心。
需要做,就去做,还等什么呢?生命的长河奔腾不止,青春一去不复返。不要浪费时间拖延等待,不要浪费时间踟蹰徘徊。每个人都有自己的使命,不要浪费时间做不属于自己人生使命的事情。
一旦决定去做,就要迅速采取行动,并全神贯注,全力以赴。同时,要对结果保持耐心,因为你唯一能把握的只有自己,他人和外界环境都纷繁复杂、充满变数。
市场接受一个产品需要经历很长时间。商业上的合作、职场上的配合都需要一定的磨合期。想要做出优秀的产品是需要时间的,因为你需要不断地、一遍又一遍地打磨它。一旦采取行动,就要速战速决,但等待结果要从容沉着。正如尼维所说,灵感易逝。当灵感乍现时,要马上行动起来。[78]选择自我成长我觉得设定具体目标的做法并不科学。史考特·亚当斯有句名言:“要建立系统,而不是设定目标。”运用你的判断力确定什么样的环境有助于你茁壮成长,然后在周围创造一个这样的环境,由此增加成功的概率。
当前的环境会塑造大脑,但是聪明的大脑也可以选择和塑造未来的环境。
我不会也不想成为世界上最成功的人。我只想尽力通过最高效的方式成为最成功的自己。我想要的生活是,如果能活1 000次,那么其中的999次,我都过着成功的生活。我未必是亿万富翁,但每一次的人生都不差。我做不到让生活的方方面面都遂心如意,但我建立了自己的系统,确保不合心意的情况屈指可数。[4]
你还记得吗?我最开始就是一个来自印度的穷孩子。所以,既然我能成功,那么任何人都能成功。当然,我四肢健全,智力正常,受过教育。想要成功,一些先决条件是不可或缺的。但是,如果你正在读这本书,很可能你已经具备了获得成功的必要条件,那就是一个正常运作的身体和一个功能正常的大脑。[78]
如果有什么事情是你以后想做的,现在就去做,人生没有“以后”。
你个人如何学习新的学科?
大多数情况下,我只学习基础知识。即使在学习物理或科学时也一样。我会阅读那些高级复杂的概念,但主要是为了好玩儿。比起微积分,我更喜欢做算术。我这辈子是不会成为一位厉害的物理学家了。也许来生可以,也许我的孩子可以做到,但对我来说为时已晚。
我只能做自己喜欢的事情。
对我而言,科学就是对真理的研究。科学是唯一真正的学科,因为科学做出的预测是可证伪的。科学具有改变世界的力量。应用科学变成技术,技术把我们和动物区分开来,让我们拥有手机、房子、汽车、暖气和电力。
总之,对我来说,科学是研究真理的学问,而数学是科学和自然的语言。
我没有宗教信仰,但我有精神信仰。对我来说,研究宇宙法则是我所能做的最虔诚的事情。有宗教信仰的人会去麦加或麦地那朝圣,向先知致敬,而在学习科学的时候,我能获得同样的敬畏感,也能深刻地感受到自我的渺小。对我来说,这种感受是无与伦比的。虽然只学习了最基础的知识,但是我有这样的体验。这就是阅读科学知识的美妙之处。[4]
你是否认同这样的观点:“如果阅读的内容与他人相似,思考的东西就会和别人雷同?”我觉得现在大家不管读什么,几乎都是为了获得社会认可。[4]有些人读了上百本解读进化论的书,却从未读过达尔文关于进化论的原著。这个世界上的宏观经济学家多如牛毛,我认为他们中的大多数人虽然读过大量的经济学论文,但是没有读过亚当·斯密的任何著作。
在某种程度上,这种阅读是为了获得社会认可。这么做是为了融入其他猴子,为了适应群体生活。但要从生活中获得回报,你需要做的并不是合群,而是从人群中脱颖而出。
社会认可是在群体内部进行的。如果想得到社会认可,就需要去阅读整个社会群体都在阅读的东西。而要想在群体中脱颖而出,就需要有一定的逆向思维和反叛精神,能够说出:“不,我就是要做自己选择的事情。不管社会结果如何,我就是要学自己觉得有意思的东西。”
你认为选择离经叛道是损失厌恶心理在起作用吗?因为一旦背离当前的轨道,你就不能确定是在朝着积极还是消极的结果发展,是吗?
正是如此。我想这就是为什么我所认识的最聪明、最成功的人一开始都是失败者。如果自认为人生失败,被社会抛弃,在正常的社会中没有合适的角色,你就能专心做自己的事情,而不会被能否成功困扰。这样反而更有可能找到一条成功的道路。“我永远不受欢迎,我永远不被接受。我已经是个失败者了。反正也得不到别人拥有的东西,我只要开心地做自己就好了。”这样想对开始做事的人来说是一种很好的心态。
要想不借助自律而实现自我提升,你需要更新自我形象。
每个人都有一些做起来动力十足的事情,只是这些事因人而异。
即使是那些所谓“没有动力”的人,在打游戏的时候也会突然充满干劲儿。所以,我认为动力是相对的,你只需要找到自己感兴趣的东西。
[1]
流血流汗,埋头苦干,直面困难,这些都是一夜成名的必经之路。
如果你要给子女传授一两条人生原则,这些原则会是什么?
第一条原则是阅读,广泛地阅读。阅读面要广,不要局限于社会认可的书,更不要局限于我推荐的书。要为了阅读而阅读,培养对阅读的热爱。即使喜欢读言情小说、侦探书或漫画书也没关系,不存在所谓的垃圾。开卷有益,尽管读吧。假以时日,你会找到那些你应该读和喜欢读的东西。
第二条原则是,掌握与阅读技巧相关的数学和说服技能。这两种技能有助于你在现实世界里活得游刃有余、畅行无阻。
拥有说服技能很重要,因为如果能影响自己的同胞,你就可以做成很多事情。我认为,说服力是一项实实在在的技能,而且是可以学会的,并没有那么难。
数学有助于解决生活中所有复杂的难题。如果想赚钱,如果想研究科学,如果想了解博弈论、政治、经济、投资或计算机,你就需要学好数学,因为所有这些都以数学为核心。数学是自然界最基本的语言。
数学是大自然的语言。所以,我们可以利用数学对大自然进行逆向工程,以此了解大自然。不过,我们目前的了解也只是皮毛。但幸好,作为普通人我们并不需要掌握很多数学知识,只需要知道基本的统计学、算术等就够了。你应该对统计学和概率了如指掌,烂熟于心。[8]选择解放自己最难的不是做自己想做的事,而是知道自己想要什么。
要注意,这个世界上根本没有什么“成年人”,假装成熟的人多了,也就有了成年人。你必须找到属于自己的路,按照自己的方式去挑选、抉择、取舍。先想清楚自己想要的是什么,然后付诸行动。[71]
你的价值观发生了怎样的变化?
年轻的时候我无比珍惜自由。自由是我的核心价值观之一。不过,现在依然如此。自由是我的三大价值观之一,只是现在我对自由的理解不同了。
以前我对自由的定义是“随心所欲即自由”——想做什么就做什么,想什么时候做就什么时候做。而现在,我追求的是内在的自由,“无忧无虑即自由”。例如,从愤怒中解脱的自由,从悲伤中解脱的自由,无须做出反应的自由,无须被迫做事的自由,等等。以前我总是在追求“想做什么就做什么”的自由,现在我追求“不想做什么就不做什么”的自由,追求内心和外在的无拘无束。[4]
给年轻时的自己一个建议:“做最真实的自己。”
伪装意味着要年复一年地(而不是几分钟)让自己身处烦心伤脑的关系和工作中。
从期待中解脱出来我压根就不评估自己的效率。我不赞成自我评估,我觉得这是一种自我约束、自我惩罚和自我冲突。[1]
如果他人因对你抱有期待而受伤,那就是他们的问题。如果他们和你有约在先,那就是你的问题。但如果他们只是单方面对你有所期待,那就完全是他们的问题,与你毫无关系。他们会对生活有各种各样的期待,越早打破他们对你的期待越好。[1]
勇气不是在枪林弹雨中冲锋陷阵,而是不在乎别人怎么想。
所有与我熟识的人都知道,我有两大性格特点:缺乏耐心,非常任性。我不喜欢等待,痛恨浪费时间。比如,在参加聚会、活动、晚宴时,如果意识到那是在浪费我的时间,我就会马上离开,不管什么社交礼节。大家都知道我这个特点。
珍惜自己的时间。你唯一真正拥有的就是时间。时间比金钱更重要,比朋友更重要,比什么都重要。你的时间就是你的一切。不要浪费自己的时间。
珍惜时间并不意味着不能放松下来享受生活。只要是做自己想做的事情,你就不是在浪费时间。但是,如果没有把时间花在想做的事情上,既没有赚到钱,也没有学到东西,你就要问问自己到底在瞎忙什么。
不要花自己的时间去取悦别人。别人快不快乐是他们的问题,不是你的问题。你快乐了,别人也会快乐。你快乐了,别人会问你是如何快乐起来的,他们会从中学到点儿什么,但是你没有责任让别人快乐。[10]
从愤怒中解脱出来什么是愤怒?愤怒是一种强烈的情绪表达,是一个人尽可能向对方表明自己有能力使用暴力的情绪表达。愤怒是暴力的前兆。
观察自己愤怒时的样子。愤怒就是对情况失去控制时的表现。愤怒是跟自己的契约,你同意让自己陷入身体、精神和情感的混乱,直到现实发生改变。[1]
愤怒本身就是一种惩罚。一个愤怒的人试图把你的头摁到水下,但同时他也在溺水。
从雇佣关系中解脱出来那些生活水平远远低于自己收入水平的人享受着一种自由,这种自由是那些忙于不断提升自己的生活方式的人无法企及的。[11]
一旦真正掌握了自己的命运,无论好坏,你就再也不会让别人告诉你你该做什么了。[11]一旦品尝到自由的滋味,你就再也不想被别人雇用了。
从不受控制的思考中解脱出来我正在努力培养一个很重要的习惯,那就是试图叫停自己的心猿。在孩童时期,每个人都是一张白纸,可以无忧无虑地活在当下,基本上都可以根据自己的本能对环境做出反应。我认为这时可谓生活在“真实世界”里。到了青春期,欲望开始萌发,这是你第一次真正渴望得到某样东西。你开始进行长期规划,开始大量思考,开始逐步打造身份,培养自我意识,争取得到自己想要的东西。
举个例子,你走在一条人来人往、有着一千个人的马路上,那么这一千个人无时无刻不在头脑中喃喃自语。他们不断地评判着自己看到的一切,头脑中回想着昨天发生在自己身上的事情,也在幻想明天会发生什么。他们唯一没有做的事情就是关注当下最基本的现实。这种思维模式在我们做长期规划或者解决问题时是好事,对我们完成生存和繁衍的任务也有益处。
但是,我觉得它非常不利于个人幸福。对我来说,大脑应该是仆人和工具,而不是主人。我不应该全天候地受到心猿的控制和驱使。
大脑总会陷入不受控制的思考,我想改掉这个习惯。当然,这并不容易。[4]
忙碌的思绪会加速主观时间的流逝。
自我意识和自我发现没有终点,是毕生的功课,我们在这条路上不断精进。人生没有一个有意义的答案,也没有人可以完全解决人生的所有问题,除非你成为一个大彻大悟的人。也许有人能最终做到,但我知道我不太可能做到,因为我已经被卷入这场无休止的“老鼠竞赛”。在最好的情况下,我能做到偶尔抬头看看天上的云。
我觉得大多数人最多也就是意识到,自己是一只竞争中的老鼠,仅此而已。[8]
现代斗争:
孤独的个体召唤出非人的意志力,进行断食、冥想、锻炼……对抗大批科学家和统计学家以充足的食物、药物和电子屏幕为武器制造出的垃圾食品、标题党新闻、无限的色情内容、无穷无尽的游戏、令人上瘾的毒品。
第五章 哲学
真理经常会被当成异端邪说,无法被公开讨论。真理只能靠探索去发现、靠耳语去传播,也许还能编撰成文,供人阅读。
生命的意义我要提的这个问题,内涵和外延都非常丰富:生命的意义和目的是什么?
确实非常丰富。这个问题很大,我会给你三个答案。
第一个答案:生命的意义是一个私人问题。每个人都必须找到自己生命的意义。其他人(无论是佛陀还是我)给你的任何智慧听起来都像是胡说八道。从根本上说,每个人都必须自己去寻找答案,所以重要的不是答案,而是问题。你得坐下来深入思考,努力探究这个问题。寻找人生的意义可能需要几年甚至几十年。一旦找到令自己满意的答案,这个答案就会成为你生活的根基。
第二个答案:生命没有意义,生活没有目的。有人说:“人生如水上写字或以沙建房。”宇宙已经存在了100亿年,未来可能会继续存在700亿年。与宇宙的历史相比,你的生命相当于不存在——在过去的100亿年中并不存在,在未来的700亿年中也将不复存在。宇宙终将归于热寂。
你做的任何事情都将烟消云散,你存在的一切痕迹都将无处可寻。人类终将灭亡,地球也会荡然无存。即使是移民火星的群体也会消失。无论你是艺术家、诗人、征服者、贫民,还是其他任何人,几代人过后,都不会有人记得你。总之,生命没有任何意义。
归根到底,一个人必须创造自己人生的意义。你必须想清楚:
“生命只是一场戏,而我只是一个观众?”
“我做的事情是为了自我实现吗?”
“我对某种东西的渴望是因为其本身吗?”
所有这些都是你编造出来的意义。
对宇宙来说,没有什么基本的内在目的或意义。如果有,在得知了这一意义之后,你就会接着问:“为什么这就是生命的意义?”正如物理学家理查德·费曼所说:“就好像一个东西被一只乌龟驮在背上,这只乌龟下面是一只更大的乌龟,再下面都是乌龟。一个问题总会带来另一个问题,‘为什么’会不断累积。任何一个答案都会引出另一个‘为什么’。”
我不相信“永恒的来世”这类回答。仅仅因为在这个星球上生活了70年,你就能获得永恒的来世——我觉得这个说法毫无依据,
荒谬至极。我觉得“来世”跟“前世”差不多。你还记得自己的“前世”吗?不记得了吧。“来世”也一样。
在你出生之前,这个世界上并不存在一个“你”,你不关心任何事和任何人,包括你所爱的人,包括你自己,包括人类,包括人类是要移民火星还是留在地球上,包括是否有人工智能,等等。在你死后,这个世界上的“你”就消失了,你也不会在乎这些了。
第三个答案:这个答案有点儿复杂。根据我所阅读的科学领域的书籍(我的朋友写过相关主题的书),我拼凑出一些理论。也许人生有意义也有目的,但我要说的这个目的或许并不能令你满意。
说白了,在物理学中,时间之箭来自熵。根据热力学第二定律,随着时间的推移,熵只会增加,不会减少,这意味着宇宙中的无序状态只会增加,集中的自由能只会减少。如果把人类或植物等任何一种生物或人类文明视为一个系统,这些系统就是在局部熵减。人类在局部熵减,因为我们有行动力。
而在人类局部熵减的同时,整个地球在整体熵增,直到宇宙归于热寂。在宇宙热寂理论之下,你可以提出一些很有意思的解释,我也非常乐于看到。在热寂状态里,能量不再集中,万物都处于同等的能量水平。此时,万物归一,毫无二致。
作为生命系统,我们所做的一切都是在推动宇宙加速达到热寂。
创作艺术、研究数学、组建家庭、发明计算机、创建文明等等——所有这些更复杂的系统都在使宇宙加速达到热寂。你正在把我们推向“万物一体”的终极境界。[4]按照自己的价值观生活你的核心价值观是什么?
我从未完整地总结过自己的价值观,但可以在此列举几个。
诚实是我最核心的价值观之一。我说的诚实,指的是做真实的自己。在某些环境中,我们需要注意自己的言谈举止,在跟一些人相处时,我们说话要字斟句酌。我不想待在这样的环境里,也不想跟这样的人相处。如果心里一套、嘴上一套,我的大脑就需要多个线程同时处理信息,这样我就无法活在当下,因为每次与人交谈,我都在追悔过去或计划未来。我只想跟一类人相处,在他们面前我可以做到心口如一。
在对别人撒谎之前,你必须先对自己撒谎。
另一个基本的价值观是,我不赞成任何短期思维或短期交易。如果生意伙伴在跟他人的合作中一味追求短期利益,我就不想跟他们合作了。生活中所有的回报,无论是财富、人际关系、爱情、健康、活动,还是习惯,都来自复利。我只想选择值得一辈子深交的伙伴和能获得长期回报的事情。
另一个价值观是,我赞同平级关系,不接受等级关系。我不想高于任何人,也不想低于任何人。如果我和别人不能像平级那样对待彼此,我就不想和他们交往了。
还有一个价值观,现在我觉得愤怒是毫无意义的。年轻的时候我认为愤怒是好事,是男子汉气概的象征,但现在,我喜欢佛教的说法:“执怒就像握了一把要丢向他人的热煤炭,被烫伤的人反而是你。”我不想生气,也不想和愤怒的人在一起。我把愤怒的人从自己的生活中剔除了。我不是在评判他们。我自己也经历了很多愤怒。他们必须自己解决这个问题。去别的地方生别人的气吧,不要影响我。
我不知道以上说的这几点是否符合价值观的一般定义,但这些都是我不会妥协的事情,我的整个人生都以它们为参考和标杆。[4]我认为,每个人都有自己的价值观。要想获得好的人际关系、好的同事、好的恋人、好的妻子、好的丈夫,就要找到与自己价值观相契合的人。志同则道合,道合则无虞。我发现,人们如果因为什么事情争执不休,乃至大打出手,一般来说,就是价值观不一致。如果价值观一致,人们就不会计较那些鸡毛蒜皮的小事了。[4]
我与妻子的携手经历了很大的考验。我真的很想和她在一起,但她一开始并不确定。最后,我们在一起了,因为她看到了我的价值观。我很庆幸自己在当时已经拥有了这套价值观,如若不然,我就不会得到她,因为我配不上她。正如投资大师查理·芒格所说:“若要找到一位优秀的伴侣,你先要成为一位优秀的伴侣。”[4]
我的妻子是个非常可爱的人。她重视家庭,我也如此。这是把我们两个联结在一起的基本价值观之一。
生儿育女会改变一个人。有了子女的那一刻,生命的意义、生命的目的等类似问题突然就有了答案,这种感觉非常神奇。突然间,宇宙中最重要的东西从你的身上转移到孩子的身上。你会因此而改变,你的价值观从本质上变得不那么自私了。[4]理性佛教问题越古老,答案存世的时间越长。
你把自己的生活哲学体系称为“理性佛教”。
理性佛教与传统佛教有何不同?你经历了怎样的探索?
理性部分意味着我必须接受科学和进化论,我必须拒绝所有无法亲自验证的理念。例如,冥想有好处吗?是的。厘清思绪是件好事吗?是的。心猿之下是否有一个基本的意识层?是的。所有这些我都亲自验证过。
与此同时,我相信并遵循一些来自佛教的说法。原因是,我已对这些说法进行了验证,或者通过思想实验对其进行了论证。我不能接受类似“前世的业果,今生来偿还”的说法。我没见过前世,也不记得任何前世,所以没有办法相信。
还有“第三脉轮开启”等等,我觉得都有些玄虚。我无法证实,也无法确认。有的东西可能是真的,也可能是假的,但如果我无法证实,或者无法通过科学证明,那么无论是真是假,这个东西都是不可证伪的。不可证伪的东西不能被视为基本真理。
另一方面,我确定进化论是真的。进化赋予人类的使命是成为生存和繁殖机器。人类产生了自我意识,于是直立行走、制造工具、采取行动。对我来说,理性佛教意味着理解佛教所倡导的内在修行,以此让自己变得更快乐、更富有、更能活在当下、更能控制自己的情绪——成为一个更好的人。
我不会因为一个高深的概念被写进书里就觉得它是对的。我觉得自己不能飘浮起来,我也不认为冥想能给我带来什么超能力。要勇于尝试,亲自验证,始终保持怀疑精神,沙里淘金,使其为我所用。
所以,我的人生哲学就包含这两个方面:一方面是进化论,进化论是约束性原则,因为它解释了关于人类的诸多问题;另一方面是佛教,佛教是关于我们每个人内心状态的精神哲学,是最古老、最经得起时间考验的哲学。
我认为这两点并不矛盾,可以相辅相成,互为补充。实际上,我想写一篇博客,讨论一下如何把佛教的教义,尤其是那些可以验证的教义,直接映射到虚拟现实中。[4]
人之初,性本善,而后被污染腐化。智慧就是通过追求知识,去伪存真,抛弃罪恶,回归美德。
你如何定义智慧?
智慧是一种知道个人行为的长期后果的思维能力。[11]
如果仅仅通过语言就可以传授智慧,我们今天就不需要努力了。
我们唯一拥有的是当下除了当下,一切都是不存在的。没有人能够回到过去,也没有人能够以任何有意义的方式成功地预测未来。唯一存在的就是此时此地,就是你恰好存在的这个时刻和在宇宙空间里的这个位置。
就像所有伟大而深刻的真理一样,这些都是悖论。任何两个点都是无限不同的。任何时刻都是独一无二的。每一刻都转瞬即逝,时光是抓不住的。[4]
你每时每刻都在死亡和重生。是遗忘还是牢记,取决于你自己。
[2]
只因在劫难逃,万物更显美好。你永远不会比此刻更美,我们也永远不会重回此地。
——荷马,《伊利亚特》
我甚至不记得两分钟前我说了什么。过去最多只是我脑海中一些虚幻的记忆片段。在我看来,我的过去早已死去,消失不见。死亡唯一的真正含义就是不再有未来的时刻。[2]灵感本易逝,行动应当时。
额外推荐BONUS
科技的大众化使得任何人都可以成为创造者、企业家、科学家。
未来会更加光明。
从统计学上看,更加先进的外星文明很可能存在。
希望他们是善良的环保主义者,而且觉得我们很可爱。
纳瓦尔的推荐读物我阅读不是为了自我提升,而是出于好奇心和兴趣。最好的书就是让人欲罢不能、爱不释手的书。
图书(这部分包含很多链接,所以电子版可能更加方便。请在navalmanack.com下载本章内容的电子版,以便访问链接。)
大量阅读可以提高阅读品位,然后你会自然地开始阅读更多理论、概念和非虚构类作品。
非虚构类《无穷的开始:世界进步的本源》,戴维·多伊奇这本书不是很好理解,但确实让我变得更聪明了。[79]
《人类简史:从动物到上帝》,尤瓦尔·赫拉利这本书介绍了人类的历史。书中的观察、框架和心智模型会让你以不同的方式看待历史和人类。[1]
《人类简史》是我过去10年读过的最好的一本书。作者花了几十年写这本书,书中有很多精彩绝伦的想法,每一页都是思想的精华。
[1]
《理性乐观派:一部人类经济进步史》,马特·里德利这是我过去几年读过的最精彩、最具启发性的一本书。我推荐书单的前20本书中,有4本出自马特之手。
我推荐马特·里德利的所有作品。马特是一名科学家,一位乐观主义者,也是一名具有前瞻性的思想家。他是我最喜欢的作家之一。我读过他所有的作品,每一本都读了好几遍。[4]
→《基因组:生命之书23章》
→《红色皇后:性与人性的进化》
→《美德的起源:人类本能与协作的进化》
→《自下而上:万物进化简史》
《非对称风险》,纳西姆·塔勒布这是我在2018年读的最好的一本书,强烈推荐。书中有很多引人入胜的观点,还有很多先进的心智模型和构想。作者对很多事情都带有批判态度,但这也是因为他太优秀了,有资格这样做。所以,不要在意他的态度,只学习书中的概念就好。《非对称风险》是我读过的最好的商业书之一。幸运的是,这本书并没有被包装成一本商业书。
[10]
《随机生存的智慧:黑天鹅语录》,纳西姆·塔勒布纳西姆在书中呈现了一系列古代智慧。他的其他著作包括《黑天鹅》《反脆弱》《随机漫步的傻瓜》等,这些书都值得一读。[7]
《费曼讲物理:入门》,理查德·费曼我会把这本书和《费曼讲物理:相对论》都送给我的孩子。理查德·费曼是一位著名的物理学家。我非常喜欢他为人处世的风格和对物理的理解。
我正在读《费曼手札》。他的传记《天才:理查德·费曼的生命与科学》我也读了好几遍。[8]
《万物解释者:复杂事物的极简说明书》,兰道尔·门罗兰道尔·门罗是科学漫画网站xkcd的创始人。他写的这本书特别棒。他在书中只用了英语中最常用的1 000个单词就清楚地阐释了潜艇、气候变化、物理系统等各种极为复杂的概念。比如,他把土星五号火箭称为“上行者五号”,因为如果用宇宙飞船等概念来解释“火箭”太复杂了,也解释不清楚,所以他用了“上行者”这个词。所谓“上行者”,就是一个向上升的东西,孩子们一下就懂了。[4]
《趣味物理寻答集》,刘易斯·卡罗尔·爱泼斯坦
这本书特别好,我没事就会翻开读读。书的封底上有这样一句话,我很喜欢:“全球唯一一本小学生和研究生都可以使用的教材。”这句话说得很对。书中都是一些简单的物理难题,12岁的孩子能理解,25岁的物理研究生也可以深入思考。书中都是基本的物理学知识。尽管问题有点儿难度,但是任何人都可以通过纯粹的逻辑推理找到答案。[4]
《历史的教训》,威尔·杜兰特、阿里尔·杜兰特这本书特别好,我非常喜欢。它提纲挈领地总结了一些宏大的历史主题。不同于大多数历史书,这本书实际上篇幅不长,却涵盖了多方面内容。[7]
《主权个体:把握向信息时代的过渡》(The Sovereign Individual:Mastering the Transition to the Information Age),詹姆斯·戴尔
这是自《人类简史》以来我读过的最好的一本书(但远远没有《人类简史》畅销)。
《穷查理宝典:查理·芒格智慧箴言录》,查理·芒格、彼得·考夫曼(编)这本书看起来像是一本商业书,但实际上是伯克希尔-哈撒韦公司董事会副主席查理·芒格的人生建议,讲的是如何超越自我,过上成功而正直的生活。[7][80]
《现实不似你所见:量子引力之旅》,卡洛·罗韦利这是我2019年读过的最好的书。文笔优雅,简单易懂,涵盖了物理学、诗歌、哲学和历史等内容。
《七堂极简物理课》,卡洛·罗韦利这本书我读了至少两遍。
想了解博弈论,除了玩策略游戏,你还可以读一下J.D.威廉斯的《竞争策略:策略博弈论入门》(The Compleat Strategyst:Being a Primer on the Theory of Games of Strategy)和罗伯特·阿克塞尔罗德的《合作的进化》。[11]
哲学和灵性类杰德·麦肯纳的全部作品。
杰德在书中揭露了赤裸裸的真相,不加掩饰,毫无保留。他的风格或许不招人喜欢,但他对真相的坚持是无与伦比的。[79]
《万物理论(启蒙的视角)》——梦境三部曲
《杰德·麦肯纳笔记本》(Jed McKenna’s Notebook)
《杰德演讲#1》(Jed Talks #1)
《杰德演讲#2》(Jed Talks #2)
医学博士卡皮尔·古普塔的全部作品。
卡皮尔最近成了我的私人顾问和教练,而我以前从不信“教练”这一套。[79]
《大师的生活秘语:消除生活噪声,寻求生命真相》(A Master’s Secret Whispers:For those who abhor noise and seek The Truth…about life and living)
《直触真理:如何应对人生问题》(Direct Truth:Uncompromising,non-prescriptive Truths to the enduring questions of life)
《生命之书》,吉杜·克里希那穆提克里希那穆提没有那么出名。他是一个出生于19世纪末、生活在20世纪的印度哲学家,对我影响极大。他坚定执着,直截了当。他的主要观点是,要时刻观察自己的思想。我深受他的影响。他最好的书应该就是《生命之书》,这是他各种演讲和图书的节选。[6]
我会把《生命之书》送给我的孩子,并告诉他们长大之后再读,因为年轻时读不懂其中的深意。[8]《全然的自由:克里希那穆提要义》,吉杜·克里希那穆提这是一本写给理性主义者的书,推荐给更有追求的人。作者在书中指出了人类思想的危险之处。这本书是我常翻常新的精神之书。[1]
《悉达多》,赫尔曼·黑塞我非常喜欢这本关于哲学的经典著作,对刚刚起步的人来说,它是一部很好的入门作品,也是我最常赠送给别人的一本书。[1]
我会反复阅读克里希那穆提等人的作品,他们是我最喜欢的哲学家。[4]
(更新:现在我把杰德·麦肯纳、卡皮尔·古普塔、瓦希斯塔瑜伽和叔本华也加入阅读清单。)
《爱的方式:安东尼·德·梅勒的最后沉思》(The Way to Love:The Last Meditations of Anthony de Mello),安东尼·德·梅勒
《清醒地活》,迈克·辛格
《沉思录》,马可·奥勒留马可·奥勒留对我的人生产生了巨大的影响。奥勒留是罗马皇帝,这本书是他的私人日记。所以,书中的内容都是奥勒留写给自己的,他从未想过会被出版。奥勒留应该是当时世界上最有权势的人。然而,打开这本书,你会发现他竟然也有着跟我们同样的问题和精神挣扎;他一直努力让自己成为一个更好的人。
读了这本书,你就会明白成功和权力并不能改善一个人的内在状态——你仍然需要为此付出努力。[6]
《让爱自己变成好习惯》,卡马尔·拉维坎特这本书其实是我哥哥写的,我觉得语言非常简洁(显然此处为植入广告)。
他是我们家的哲学家,我只是个业余爱好者。这本书里有一句话说得特别好:
我曾经问一个和尚,他是如何找到内心的平静的。
他说:“无论发生什么,我都说‘好的’。”[7]
《塞涅卡之道:斯多葛派大师的实用书信》(The Tao of Seneca:Practical Letters from a Stoic Master)
这是我最爱听的一本有声书,也是最重要的一本。
《改变你的心智》,麦可·波伦这本书写得很好,我觉得每个人都应该读一读。
这本书讨论的是迷幻药。迷幻药在自我观察中有点儿像作弊密码。我不会向任何人推荐药物,因为通过纯粹的冥想就可以做到自我观察,药物起的只是加速作用。[74]
《醒思录:李小龙的生活智慧》,李小龙可能出乎大家的意料,李小龙也写过一些非常精彩的哲学文章,《醒思录》这本书很好地总结了他的一些哲思。
《先知》,纪伯伦这本书读起来像一本现代宗教诗集,对《薄伽梵歌》《道德经》《圣经》《古兰经》都有涉及。
纪伯伦的写作风格带有一种宗教感,但没有教派之分,讲述的都是真理,文风优雅亲切,文笔优美。我很喜欢这本书。
纪伯伦很有写作天赋,写的东西充满诗意:孩子是什么样子的;
爱人是什么样子的;婚姻应该是什么样子的;应该如何对待敌人和朋友;应该如何处理金钱;每次必须杀生吃肉的时候,可以想些什么。
我觉得这本书就像那些伟大的宗教著作一样,对如何处理生活中的主要问题给出了非常深刻、有哲理,同时又非常真实的答案。无论你信不信教,无论你是基督徒、印度教徒、犹太教徒还是无神论者,我都向你推荐《先知》这本书。我觉得这是一本很棒的书,值得一读。[7]
科幻类我最开始读的是漫画和科幻小说,后来开始阅读历史和新闻类,最后喜欢上了心理学、科普和技术类。
《虚构集》,豪尔赫·路易斯·博尔赫斯我喜欢豪尔赫·路易斯·博尔赫斯这位阿根廷作家,他的短篇小说集《虚构集》写得精彩绝伦。博尔赫斯可能是我读过的最有影响力的作家。他不是直接写哲学,而是以科幻小说的形式表达自己的哲学理念。[1]
《你一生的故事》,特德·姜特德·姜的《领悟》是我目前最喜欢的科幻短篇小说。
这篇小说被收录在《你一生的故事》中。其中同名短篇小说《你一生的故事》被改编成电影《降临》。[1]
《呼吸》,特德·姜这是我们这个时代最优秀的科幻短篇小说作家对热力学奇迹的思考。
《软件体的生命周期》这本也是特德·姜的科幻巨作。
《雪崩》,尼尔·斯蒂芬森《雪崩》是一本令人拍案叫绝的书,可以说独一无二、无可匹敌。斯蒂芬森还写了《钻石年代》。
《最后的问题》艾萨克·阿西莫夫的短篇小说。
我经常引用《最后的问题》里的故事。我小时候就很喜欢这部小说。
你最近在重读什么书?
这是个好问题,我现在就打开Kindle。我一般会反复读一些科学著作。
我在读一本关于勒内·基拉尔模仿理论的书。准确地说,这本书是对基拉尔理论的概述和解读,因为我读不懂他的原著。我还在读蒂姆·费里斯的《巨人的工具》,书中记录了他从许多采访过的杰出人士那里学到的东西。
另外还有《热信息复杂性》(Thermoinfocomplexity)。这本书是我的朋友贝赫扎德·莫希特写的。我刚读完罗伯特·西奥迪尼的《先发影响力》。我只是大概翻了一下,看得并不仔细。因为我觉得不需要从头至尾看完就可以知道整本书的观点,但略读一下还是很好的。这是一本不错的历史书。我还在读威尔·杜兰特写的《哲学的故事》。
我现在有一个年幼的孩子,所以我看了很多育儿类图书,也经常去里面查阅一些信息。我最近读了一些爱默生和查斯特菲尔德的作品。我这里还有一本列夫·托尔斯泰的书。
还有阿兰·瓦茨和史考特·亚当斯的书。我最近重读了《上帝的碎片》。另外还有《道德经》,我重读这本是因为我的一个朋友在重读它。
还有很多书,我可以一直说下去。我这里有尼采的书,还有蒂姆·哈福德写的《卧底经济学》,理查德·巴赫的《幻象》(Illusions:The Adventures of a Reluctant Messiah),以及几本杰德·麦肯纳的书。
这里还有几本戴尔·卡内基的作品,刘慈欣的《三体》,维克多·弗兰克尔的《活出生命的意义》,克里斯托弗·瑞安的《黎明时的性行为》(Sex at Dawn),等等。
顺便说一下,我在分享书目的时候,大概有2/3的书是不会说的。
之所以不说,是因为我觉得不好意思,这些书听上去不像好书,谈论的话题似乎微不足道或傻里傻气。人们听了之后会说,“读这个干什么”。所以我不会把自己读的所有书都跟人分享。我什么书都读,包括被别人视为垃圾的书,甚至别人认为应该受到谴责的书。我也读那些跟我观点完全相反的书,以此启发自己思考。[4]
对于买书,我毫不吝啬,从不犹豫。我从不把买书视为一种开销,反而认为是一种投资。[4]
博客(这部分包含很多链接,所以电子版可能更方便。请在navalmanack.com下载本章内容的电子版,以便访问链接。)
一些很棒的博客:
@KevinSimler——Melting Asphalt,https://meltingasphalt.com/
@farnamstreet——Farnam Street,A Signal in a World Full of Noise,https://fs.blog/
@benthompson——Stratcher y,https://stratechery.com/@baconmeteor——Idle Words,https://idlewords.com/[4]
“The Munger Operating System:How to Live a Life That Really Works”by @FarnamStreet
自助和成功学类:
“The Day You Became a Better Writer”,史考特·亚当斯。
我从小就进行大量写作,还是很会写东西的,但是每当要写一些重要的文章时,我仍然会把这篇博客打开,以做参考。这篇文章非常好,我将其视为写好文章的基本模板。文章的标题很有吸引力。在这篇简短的博客里,史考特·亚当斯说明了出其不意、标题,以及简洁和直奔主题对写好一篇文章的重要性。他还建议,不要使用某些形容词和副词,要使用主动语态而不是被动语态,等等。如果你放平心态,认真学习,这篇文章能永远改变你的写作风格。[6]
你想在10分钟内变得更聪明吗?那就去读一下凯文·希姆勒的博客文章“Crony Beliefs”。
我读过的最好的有关“职业选择”(在硅谷和科技圈)的文章来
自博客eladgil。
尤瓦尔·赫拉利《人类简史》在You Tube视频上的讲座或课程。
每个商学院都应该开设一门关于聚合理论的课程,或者直接向科技领域最好的分析师本·汤普森(推特账号:benthompson)学习。
埃利泽·尤德科夫斯基写的《像现实一样思考》是一篇很棒的文章。这篇文章的主要观点是“奇怪的不是量子物理学,而是你自己”。
必读博客:Lazy Leadership,推特账号:Awilkinson
博主Edlatimore网站的所有内容对所有想取得更高成就的人来说都值得一读:https://edlatimore.com/。作为一个白手起家的人,博主毫无保留地分享了自己的智慧。
如果按照“新闻”所倡导的方式吃饭、投资、思考,你最终会变得营养不良、两手空空、道德败坏。
其他推荐推特账号推荐:
AmuseChimp (我最喜欢的推特账户)
mmay3r
nntaleb
Art De Vany(脸书账户)
天赋在人间,只是分布不均匀。
必读内容:博主zaoyang的推文“智力复利”。[11]
还有一些特别好的漫画小说。如果你能接受漫画元素,那么我推荐沃伦·埃利斯的《大都市》和《行星》,加思·恩尼斯的漫画《男孩》,尼尔·盖曼的漫画《睡魔》。我认为其中一些是我们这个时代最好的艺术作品。我是看漫画长大的,所以我对漫画作品可能颇为偏爱。[1]《瑞克和莫蒂》(电视节目+漫画书)《瑞克和莫蒂》是最好的电视节目(纯属个人愚见)。你看一集就知道有多好了。《瑞克和莫蒂》是《回到未来》和《银河系漫游指南》这两部经典科幻作品的结合。
扎克·戈尔曼创作的《瑞克和莫蒂》系列漫画跟动画片一样精彩纷呈。
《你和你的研究》,理查德·哈明。
这篇文章非常精彩,我强烈建议大家都读一下。从表面上看,这篇文章是为从事科学研究的人写的,但我认为它适用于所有人。文章的中心议题是如何把工作做到出色,里面都是过来人的建议。文章让我想起理查德·费曼曾经的观点,不过我认为,哈明的表达是最有说服力的。[74]纳瓦尔的写作生命公式一(2008年)这些是我写给自己的笔记。如果参照系不同,计算方法就会有所不同。这些不是定义,而是成功的算法。欢迎读者提供自己的见解。
→幸福=健康+财富+良好的人际关系
→健康=锻炼+饮食+睡眠
→锻炼=高强度耐力训练+体育运动+休息
→饮食=天然食物+间歇性禁食+植物
→睡眠=不要闹钟+8~9小时+昼夜节律
→财富=收入+财富×(投资回报率)
→收入=责任+杠杆+专长
→责任=个人品牌+个人平台+承担风险?
→杠杆=资本+人力+知识产权
→专长=无法通过培训获得的知识
→投资回报=“买入并持有”+估值+安全边际[72]
纳瓦尔的个人原则(2016年)→人生要义:活在当下。
→欲望即痛苦。(佛陀)
→执怒就像握了一把丢向他人的热煤炭,被烫伤的人反而是你。
(佛陀)
→如果不想跟一个人共事一生,那就一天都不要和他共事。
→阅读(学习)是终极元技能,可以换来其他任何东西。
→生活中所有的回报都来自复利。
→用头脑赚钱,而不是用时间赚钱。
→99%的努力终将白费。
→任何时候都要完全诚实。诚实待人、积极向上,这是我们几乎在任何时候都可以做到的。
→具体地表扬,泛泛地批评。(沃伦·巴菲特)
→真理是具有预测能力的理论。
→观察每一个想法。(自问:“为什么我会有这个想法?”)
→生命的伟大在很大程度上源于苦难。
→爱是给予,不是接受。
→思考的间隙即开悟。(埃克哈特·托利)
→数学是自然的语言。
→每一刻都自成一体,自有意义。[5]
健康、爱和使命,以此为序,其他的都不重要。
进一步了解纳瓦尔如果你喜欢这本书,还有很多途径可以进一步了解纳瓦尔。我正在Navalmanack.com上发布名为“纳瓦尔宝典”的系列短篇。其中的章节是从这本书的原始手稿中摘选出来的(原始手稿非常厚)。我已经把删减的内容发布到网上,供有兴趣了解纳瓦尔具体见解的读者参考:
→教育
→AngelList的故事
→投资
→创业公司
→加密货币
→人际关系
纳瓦尔会在以下平台继续创造并分享他的独到见解:
→推特:Twitter.com/naval
→播客:Naval
→个人网站:https://nav.al/
当编撰本书时,纳瓦尔最受欢迎的内容是:
→纳瓦尔播客汇编:如何致富
→知识工程播客对纳瓦尔的采访
→乔·罗根播客对纳瓦尔的采访
Readwise.io慷慨地创建了这本书的摘录集,读者可在Readwise.io/naval网站获取。订阅后,每周会收到一封电子邮件,其中附有本书的重要摘录。这样,即使在读完本书很久以后,你也能把纳瓦尔的理念铭记于心。
如果喜欢杰克·布彻的插图,你可以在Navalmanack.com上找到更多他创作的纳瓦尔宝典插图,也可以在VisualizeValue.com上找到更多他的作品。
致谢
有太多人、太多事值得我感恩。这本书的背后凝结了很多人的付出和心血,每每想到这些,我就感到无比幸福,心底充满感激之情。
下面是我写的奥斯卡式的致谢:
我非常感谢纳瓦尔信任一个网上的陌生人,信任我把他说过的话编纂成书。这一切都始于一条漫不经心的推文。因为你的信任和支持,现在,一条推文变成了一部了不起的作品。我感激你的回应、慷慨和信任。
感谢巴巴克·尼维为我提供了最简洁、最精确的写作建议。谢谢你不吝时间让这本书变得更好。
谢谢蒂姆·费里斯,你打破了自己的铁律,为本书作序。你的参与对我来说意义重大,一定会让更多人受益于纳瓦尔的智慧。
这本书的主要内容来自谢恩·帕里什、乔·罗根、萨拉·莱西和蒂姆·费里斯等杰出创作者的访谈。我非常感谢你们在访谈时付出的所有努力。在创作这本书的过程中,我和其他人都从你们的工作中受益良多。
我很感激杰克·布彻伸出援手,用他的天赋和才华为本书创作了插图。我一直非常欣赏他在Visualize Value(扩展程序)上的作品,完全是天才之作,我们都很幸运能在本书里看到他的作品。
感谢父母赐予我的天资,也谢谢你们付出的所有努力和牺牲,让我能够创作出这本书。你们为我所做的一切奠定了本书的基础,我会永远牢记。这本书就是“消除疑惑”家庭实践的鲜活例子。
感谢让尼娜·塞德尔,你是我强大的后盾,为我提供了无尽的爱和鼓励。你总是积极耐心,一直给我提供非常好的建议。谢谢你一直为我加油鼓气。
感谢凯瑟琳·马丁。你是一位真正出色的文本编辑,为这本书付出了巨大努力(也感谢戴维·佩雷尔介绍我们认识)。
感谢库沙尔·库拉拉特纳的诸多贡献。你在本书写作之初就相信它一定可以成功,你是本书的早期读者,在它羽翼未丰、漏洞百出的阶段提供了巨大的帮助。谢谢你的付出。
感谢马克斯·奥尔森、艾米莉·霍德曼和泰勒·皮尔逊。你们都是我的挚友,在本书创作和出版的整个过程中,你们成了我的顾问,为我提供了大量帮助。如果没有你们,我现在还在网上一通乱搜,叫骂不止。
感谢我的早期读者,感谢你们付出的时间、编辑和明智的建议。
你们每个人都为本书做出了宝贵的贡献。没有你们,本书就不会是现在的样子。我向你们每个人致以我最诚挚的谢意:安德鲁·法拉、特里斯坦·霍姆西、丹尼尔·杜瓦永、杰西·雅各布斯、肖恩·奥康纳、亚当·韦克斯曼、凯兰·佩里、克里斯·金特罗、乔治·麦克、布伦特·贝肖尔、沙恩·帕里什、泰勒·皮尔逊、本·克兰、坎达丝·吴、沙恩·马克、杰西·鲍尔斯、特雷弗·麦肯德里克、戴维·佩雷尔、纳塔莱·康斯坦丁、本·阿克森、诺厄·马登、克里斯·吉勒特、梅根·达内尔和扎克·安德森·佩蒂特。
感谢给本书的诞生带来灵感的书籍作者和内容创作者。在我的生命中,有一些类似的书彻底改变了我的人生,我对它们深怀感激。这也是我创作和分享本书的直接动力。在这里我想特别列出其中几本:
→彼得·考夫曼编辑的《穷查理宝典:查理·芒格智慧箴言录》→布莱克·马斯特斯的《从0到1》→皮特·贝弗林的《探索智慧:从达尔文到芒格》→马克斯·奥尔森编辑的《巴菲特致股东的信》→瑞·达利欧及其团队的《原则》感谢Scribe媒体公司团队在本书的编撰初期给予的真诚支持。扎克·奥布朗特提供了绝佳的建议,编辑哈尔·克利福德充满耐心,精益求精。
感谢塔克·马克斯创立了Scribe媒体公司,组建了一支出色的团队,并亲自关注和支持本书的创作。我很感激你为了追求伟大的产品而忽略我的感受。我非常感谢你对我的信任,谢谢你相信我可以做好这个工作。
感谢博和扎里的整个团队,谢谢你们包容我对这本书的痴迷和努力,谢谢你们的耐心和风度。
同时,我也非常感谢许多网上的朋友和陌生人,谢谢你们支持和鼓励我完成了本书的创作。我的私信里充满了亲切的话语和热切的询问。感谢大家每一个善意的举动,你们的能量帮助我度过了上千个小时,这本书为你们而作。
附录
[1]Ravikant,Naval.“Naval Ravikant Was Live.”Periscope,January 20,2018.https://www.pscp.tv/w/1eaKbqrWloRxX.
[2]Ravikant,Naval.“Naval Ravikant Was Live.”Periscope,February 11,2018.https://www.pscp.tv/w/1MnGneBLZVmKO.
[3]Ferriss,Tim.Tribe of Mentors:Short Life Advice from the Best in the World.New York:Houghton Miffin Harcourt,2017.https://amzn.to/2U2kE3b.
[4]Ravikant,Naval and Shane Parrish.“Naval Ravikant:The Angel Philosopher.”Farnam Street,2019.https://fs.blog/naval-ravikant/.
[5]Ferriss,Tim.Tools of Titans:The Tactics,Routines,and Habits of Billionaires,Icons,and World-Class Performers.New York:Houghton Miffin Harcourt,2016.
[6]Ferriss,Tim.“The Person I Call Most Often for Startup Advice(#97).”The Tim Ferriss Show,August 18,2015.https://tim.blog/2015/08/18/the-evolutionary-angel-naval-ravikant/.
[7]Ferriss,Tim.“Naval Ravikant on the Tim Ferriss Show—Transcript.”The Tim Ferriss Show,2019.https://tim.blog/naval-ravikant-on-the-tim-ferriss-show-transcript/.
[8]Killing Buddha Interviews.“Chief Executive Philosopher:Naval Ravikant On Suffering and Acceptance.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/2/7/naval-ravikant-ceo-of-angellist;“Chief Executive Philosopher:Naval Ravikant On the Skill of Happiness.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/2/10/chief-executive-philosopher-naval-on-happiness-as-peace-and-choosing-your-desires-carefully;“Chief Executive Philosopher:Naval Ravikant On Who He Admires.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/2/19/naval-ravikant-on-who-he-admires;“Chief Executive Philosopher:Naval Ravikant On the Give and Take of the Modern World.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/2/23/old-bodies-in-a-new-world;“Chief Executive Philosopher:Naval Ravikant On Travelling Lightly.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/9/19/naval-ravikant-on-travelling-lightly;“Naval Ravikant on Wim Hof,His Advice to His Children,and How He Wants to Look Back on His Life.”Killing Buddha,2016.http://www.killingbuddha.co/blog/2016/12/28/naval-ravikant-on-advice-to-his-children.
[9]DeSena,Joe.“155:It’s All About Your Desires,Says AngelList Founder Naval Ravikant.”Spartan Up!,2019.https://player.fm/series/spartan-up-audio/155-its-all-about-your-desires-says-angel-list-founder-naval-ravikantunder-naval-ravikant.
[10]“Naval Ravikant was live.”Periscope,April 29,2018.https://www.pscp.tv/w/1lDGLaBmWRwJm.
[11]Ravikant,Naval.Twitter,Twitter.com/Naval.
[12]Naval Ravikant,“What the World’s Smartest People Do When They Want to Get to the Next Level,”interview by Adrian Bye,MeetInnovators,Adrian Bye,April 1,2013.http://meetinnovators.com/2013/04/01/naval-ravikant-angellist/.
[13]“Episode 2—Notions of Capital&Naval Ravikant of Angellist,”Origins from SoundCloud.https://soundcloud.com/notation-capital.
[14]“Naval Ravikant—A Monk in Silicon Valley Tells Us He’s Ruthless About Time.”Outliers with Panjak Mishra from Soundcloud,2017.https://soundcloud.com/factordaily/ep-06-naval-ravikant-angellis.
[15]Ravikant,Naval and Babak Nivi.“Before Product-Market Fit,Find Passion-Market Fit.”Venture Hacks,July 17,2011.https://venturehacks.com/articles/passion-market.
[16]Cohan,Peter.“AngelList:How a Silicon Valley Mogul Found His Passion.”Forbes,February 6,2012.https://www.forbes.com/sites/petercohan/2012/02/06/angellist-how-a-silicon-valley-mogul-found-his-passion/#729d979bbbe6.
[17]Ravikant,Naval.“Why You Can’t Hire.”Naval,December 13,2011.https://startupboy.com/2011/12/13/why-you-cant-hire/.
[18]Ravikant,Naval.“The Returns to Entrepreneurship.”Naval,November 9,2009.https://startupboy.com/2009/11/09/the-returns-to-entrepreneurship/.
[19]Ravikant,Naval.“Build a Team That Ships.”Naval,April 27,2012.https://startupboy.com/2012/04/27/build-a-team-that-ships/.
[20]Ravikant,Naval.“The 80-Hour Myth.”Naval,November 29,2005.https://startupboy.com/2005/11/29/the-80-hour-myth/.
[21]Ravikant,Naval.“The Unbundling of the Venture Capital Industry.”Naval,December 1,2010.https://startupboy.com/2010/12/01/the-unbundling-of-the-venture-capital-industry/.
[22]Ravikant,Naval.“Funding Markets Develop in Reverse.”Naval,December 1,2010.https://startupboy.com/2010/12/01/funding-markets-develop-in-reverse/.
[23]Nivi,Babak.“Startups Are Here to Save the World.”Venture Hacks,February 7,2013.https://venturehacks.com/articles/save-the-world.
[24]Nivi,Babak.“The Entrepreneurial Age.”Venture Hacks,February 25,2013.https://venturehacks.com/articles/the-entrepreneurial-age.
[25]Ravikant,Naval.“VC Bundling.”Naval,December 1,2005.https://startupboy.com/2005/12/01/vc-bundling/.
[26]Ravikant,Naval.“A Venture SLA.”Naval,June 28,2013.https://startupboy.com/2013/06/28/a-venture-sla/.
[27]Nivi,Babak.“No Tradeoff between Quality and Scale.”Venture Hacks,February 18,2013.https://venturehacks.com/there-is-no-finish-line-for-entrepreneurs.
[30]Ravikant,Naval,“An interview with Naval Ravikant,”interview by Elad Gil,High Growth Handbook,Stripe Press,2019.http://growth.eladgil.com/book/cofounders/managing-your-board-an-interview-with-naval-ravikant-part-1/.
[31]Ferriss,Tim.“Tools of Titans-A Few Goodies from the Cutting Room Floor.”The Tim Ferriss Show,June 20,2017.https://tim.blog/2017/06/20/tools-of-titans-goodies/.
[32]Delevett,Peter.“Naval Ravikant of AngelList Went from Dot-Com Pariah to Silicon Valley Power Broker.”The Mercury News,February 6,2013.https://www.mercurynews.com/2013/02/06/naval-ravikant-of-angellist-went-from-dot-com-pariah-to-silicon-valley-power-broker/.
[33]Coburn,Lawrence.“The Quiet Rise of AngelList.”The Next Web,October 4,2010.https://thenextweb.com/location/2010/10/04/the-quiet-rise-of-angellist/.
[34]Loizos,Conny.“His Brand Burnished,Naval Ravikant Plans New Fund with Babak Nivi.”The PEHub Network,November 5,2010.
[35]Nivi,Babak.“Venture Hacks Sucks Now,All You Talk About Is AngelList.”Venture Hacks,February 17,2011,https://venturehacks.com/articles/venture-hacks-sucks.
[36]Kincaid,Jason.“The Venture Hacks Startup List Helps Fledgling Startups Pitch Top Angel Investors.”TechCrunch,February 3 2010.https://techcrunch.com/2010/02/03/startuplist-angel-investors/.
[37]Babak,Nivi.“1.5 Years of AngelList:8000 Intros,400 Investments,and That’s Just the Data We Can Tell You About.”Venture Hacks,July 25,2011.https://venturehacks.com/articles/centi-sesquicentennial.
[38]Smillie,Eric.“Avenging Angel.”Dartmouth Alumni Magazine,Winter 2014.https://dartmouthalumnimagazine.com/articles/avenging-angel.
[39]Babak,Nivi.“AngelList New Employee Reading List.”Venture Hacks,October 26,2013.https://venturehacks.com/articles/reading.
[40]Babak,Nivi.“Things We Care About at AngelList.”Venture Hacks,October 11,2013.http://venturehacks.com/articles/care.
[41]Rivlin,Gary.“Founders of Web Site Accuse Backers of Cheating Them.”The New York Times,January 26,2005.https://www.nytimes.com/2005/01/26/technology/founders-of-web-site-accuse-backers-of-cheating-them.html.
[42]PandoDaily.“PandoMonthly:Fireside Chat with AngelList Co-Founder Naval Ravikant.”November 17,2012.YouTube video,2:03:52.https://www.youtube.com/watch?v=2htl-O1oDcI.
[43]Ravikant,Naval.“Ep.30—NavalRavikant—AngelList (1 of 2).”Interview by Kevin Weeks.Venture Studio,2016.236 ·THE ALMANACK OF NAVAL RAVIKANT
[44]Sloan,Paul.“AngelList Attacks Another Startup Pain Point:Legal Fees.”CNet,September 5,2012.https://www.cnet.com/news/angellist-attacks-another-startup-pain-point-legal-fees/.
[45]Ravikant,Naval.“Naval Ravikant on How Crypto Is Squeezing VCs,Hindering Regulators,and Bringing Users Choice.”Interview by Laura Shin.UnChained,November 29,2017.http://unchainedpodcast.co/naval-ravikant-on-how-crypto-is-squeezing-vcs-hindering-regulators-and-bringing-users-choice.
[46]Ravikant,Naval.“Introducing:Venture Hacks.”Naval,April 2,2007.https://startupboy.com/2007/04/02/introducing-venture-hacks/.
[47]Ravikant,Naval.“Ep.31—Naval Ravikant—AngelList (2 of 2).”Interview by Kevin Weeks.Venture Studio,2016.
[48]AngelList.“Syndicates/For Investors.”https://angel.co/syndicates/for-investors#syndicates.
[49]Ferriss,Tim.“You’d Like to Be an Angel Investor?Here’s How You Can Invest in My Deals…”The Tim Ferriss Show,September 23,2013.https://tim.blog/2013/09/23/youd-like-to-be-an-angel-investor-heres-how-you-can-invest-in-my-deals/.
[50]Buhr,Sarah.“AngelList Acquires Product Hunt.”TechCrunch,December 1,2016.https://techcrunch.com/2016/12/01/angelhunt/.
[51]Wagner,Kurt.“AngelList Has Acquired Product Hunt for around$20 Million.”Vox,December 1,2016.https://www.recode.net/2016/12/1/13802154/angellist-product-hunt-acquisition.
[52]Hoover,Ryan.“Connect the Dots.”Ryan Hoover,May 1,2013.http://ryanhoover.me/post/49363486516/connect-the-dots.
[53]“Naval Ravikant.”Angel.https://angel.co/naval.
[54]Babak,Nivi.“Welcoming the Kauffman Foundation.”Venture Hacks,October 5,2010.http://venturehacks.com/articles/kauffman.
[55]“Introducing CoinList.”Medium,October 20,2017.https://medium.com/@coinlist/introducing-coinlist-16253eb5cdc3.
[56]Hochstein,Marc.“Most Influential in Blockchain 2017 #4:Naval Ravikant.”CoinDesk,December 31,2017.https://www.coindesk.com/coindesk-most-influential-2017-4-naval-ravikant/.
[57]Henry,Zoe.“Why a Group of AngelList and Uber Expats Launched This New Crowdfunding Website.”Inc.,July 18,2016.https://www.inc.com/zoe-henry/republic-launches-with-angellist-and-uber-alumni.html.
[58]“New Impact,New Inclusion in Equity Crowdfunding.”Republic,July 18,2016.https://republic.co/blog/new-impact-new-inclusion-in-equity-crowdfunding.
[59]AngelList.“Done Deals.”https://angel.co/done-deals.
[60]Ravikant,Naval.“Bitcoin—the Internet of Money.”Naval,November 7,2013.https://startupboy.com/2013/11/07/bitcoin-the-internet-of-money/.
[61]Token Summit.“Token Summit II—Cryptocurrency,Money,and the Future with Naval Ravikant.”December 22,2017.YouTube video,32:47.https://www.youtube.com/watch?v=few99D5WnRg.
[62]Blockstreet HQ.“Beyond Blockchain Episode #3:Naval Ravikant.”December 5,2018.YouTube video,6:01.https://www.youtube.com/watch?v=jCtOHUMaUY8.
[63]Ravikant,Naval.“The Truth About Hard Work.”Naval,December 25,2018.https://startupboy.com/2018/12/25/the-truth-about-hard-work/.
[64]“Live Stories:The Present and Future of Crypto with Naval Ravikant and Balaji Srinivasan.”Listen Notes,November 16,2018.
[65]Blockstack.“Investment Panel:Naval Ravikant,Meltem Demirors,Garry Tan.”August 11,2017.YouTube video,27:16.https://www.youtube.com/watch?v=o1mkxci6vvo.
[66]Yang,Sizhao (@zaoyang).“1/Why Does the ICO Opportunity Exist at All?”August 19,2017,1:43 p.m.https://twitter.com/zaoyang/status/899008960220372992.
[67]Ravikant,Naval.“Towards a Literate Nation.”Naval,December 11,2011.https://238st·arTtHupEboAy.LcMomA/2N01A1/C12K/11O/tFowNarA dsV-Aa-lLiteRrAatVe-InKatAioNn/T.
[68]Ravikant,Naval.“Be Chaotic Neutral.”Naval,October 31,2006.https://startupboy.com/2006/10/31/be-chaotic-neutral/.
[69]AngelList.“AngelList Year in Review.”2018.https://angel.co/2018.
[70]Ravikant,Naval.“The Fifth Protocol.”Naval,April 1,2014.https://startupboy.com/2014/04/01/the-fifth-protocol/.
[71]“Is Naval the Ravikant the Nicest Guy in Tech?”Product Hunt,September 21,2015.https://blog.producthunt.com/is-naval-ravikant-the-nicest-guy-in-tech-7f5261d1c23c.
[72]Ravikant,Naval.“Life Formulas I.”Naval,February 8,2008.https://startupboy.com/2008/02/08/life-formulas-i/.
[73]@ScottAdamsSays.“Scott Adams Talks to Naval…”Periscope,2018.https://www.pscp.tv/w/1nAKERdZMkkGL.
[74]@Naval.“Naval Ravikant was live.”Periscope,February 2019.https://www.pscp.tv/w/1nAKEyeLYmRKL.
[75]“4 Kinds of Luck.”https://nav.al/money-luck.
[76]Kaiser,Caleb.“Naval Ravikant’s Guide to Choosing Your First Job in Tech.”AngelList,February 21,2019.https://angel.co/blog/naval-ravikants-guide-to-choosing-your-first-job-in-tech?utm_campaign=platform-newsletter&utm_medium=email.
[77]PowerfulJRE.“Joe Rogan Experience #1309—Naval Ravikant.”June 4,2019.YouTube video,2:11:56.https://www.youtube.com/watch?v=3qHkcs3kG44.
[78]Ravikant,Naval.“How to Get Rich:Every Episode.”Naval,June 3,2019.https://nav.al/how-to-get-rich.
[79]Ravikant,Naval.Original content created for this book,September 2019.
[80]Jorgenson,Eric.Original content written for this book,June 2019.
---
layout: post
title: 地平线余凯:技术从来没有成为过护城河(原文)
subtitle: Codex 个人助理沉淀
date: 2026-07-24 04:54:54 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/horizon_robotics/04_余凯技术从来没有成为过护城河_原文.md
地平线余凯:技术从来没有成为过护城河(原文)
记录时间:2026-07-24 16:54 CST
来源
- 用户提供知乎链接:
https://zhuanlan.zhihu.com/p/654824123
- 正文抓取来源:博客园转载页
https://www.cnblogs.com/yymn/p/17695941.html
- 原文标题:
地平线余凯:技术从来没有成为过护城河
- 说明:知乎原页存在反爬限制,本地保存正文以博客园转载页为抓取来源,内容标题与知乎链接检索结果一致;原知乎页面排版和图片细节待人工复核。
摘要
这篇文章整理了地平线创始人兼 CEO 余凯的 76 条商业思考,主线包括:科技创业不能把技术本身当作护城河,真正的壁垒来自客户关系、品牌、行业标准、生态和组织;科学家创业要从“我有什么技术”切换到“客户是谁、谁愿意反复付钱”;地平线从机器人愿景收敛到智能汽车,是在真实需求、市场容量和技术可达性之间做出的阶段性选择。
可复用观点
- 技术行业更像冲浪模型,不是一条护城河可以长期防守,而是每一代技术浪潮都必须浪过去。
- 科技公司的长期沉淀不是单点技术,而是品牌、客户关系、行业标准、生态,以及能持续建设这些壁垒的组织。
- 从 0 到 1 阶段最重要的是证明真实客户和可重复付费需求,过早追求流程效率反而可能加速错误方向。
- 硬科技创业需要找到“根据地”:市场未来足够大,同时不在巨头主攻射程内。
- 地平线选择汽车作为中间路径,不是终局放弃机器人,而是用有钱、有需求、有规模的汽车场景击穿机器人通用计算所需的芯片与操作系统能力。
下一步动作
- 后续研究地平线时,将本文作为理解余凯战略语言和组织文化的原始材料。
- 对比地平线上市后公告、财报和管理层交流,验证“汽车作为机器人通用计算中间路径”的执行进展。
- 若需要对外写文章,可围绕“技术不是护城河,生态和组织才是”提炼成一篇地平线商业模式分析。
正文
地平线余凯:技术从来没有成为过护城河
余凯的76条商业思考。
近年来,在政策支持下,我国智能汽车行业景气度不断提高。无论是造车新势力,还是传统车厂,在智能汽车赛场角逐愈发激烈,智能驾驶也成为汽车行业发展的主流方向。作为汽车的“智能大脑”,智能芯片的市场需求也在变得日益旺盛。
地平线作为智能驾驶计算方案的提供商,主要从事智能芯片的研发,具有智能算法和芯片设计能力,是国内率先并最大规模实现车规级智能芯片前装量产的企业,并与奥迪、比亚迪、长城、红旗、上汽、理想等超过20家车企达成合作。创立仅8年,如今的地平线已经成为国内人工智能芯片设计和智能驾驶计算方案领域的领军企业之一。
身为地平线创始人兼CEO,科学家出身的余凯履历足够耀眼,他曾在慕尼黑大学获得计算机科学博士,曾任百度IDL常务副院长、百度研究院副院长,在此之前在微软、西门子和NEC工作过,是中国深度学习技术主要推动者。而在余凯身上,也拥有诸多“第一名”的标签。“2012年,他在一众华人顶尖科学家中率先回国,第一个在中国开启深度学习;2013年,他领衔百度团队,第一个在中国发起自动驾驶;2015年,他转身创业,第一个从软件领域提出做芯片。”
余凯是如何打造一家硬核科技企业的?背后有哪些战略思考和推进?地平线又是如何渡过从0到1阶段的?2023年8月19日,嘉宾派北京站访学走进地平线,地平线创始人兼CEO余凯为嘉宾派企业家学员进行了《软硬结合的科技创新与全域开放的生态共建》主题授课,并讲授了自己的创业及管理心得。
嘉宾商学长期关注企业家、创始人及管理者的经营理念和管理思想,为此,我们从嘉宾派课堂内容中提炼,并结合余凯往年的采访、演讲等资料,整理编辑出余凯个人的76条商业思考,主要分为经营管理、组织文化、创业心得、商业认知4个板块内容,希望给诸位提供启发和参考。
以下,Enjoy~
1、经营管理
1、我觉得企业家在所谓的那种高光时刻说的话其实都是虚幻,那都是骗别人或者骗自己,最讨厌的就是骗了自己的话还以为是真的,其实大部分时间都是在黑暗中度过的。企业家本来就是一种比较变态的animal(动物),就是去解决一些最难的问题,然后拥抱了一种比较非正常的生活方式。
2、教授或者学者最好别当CEO,一定要劝他们,要忍住那种觉得自己什么都能当的冲动,老老实实地当个首席科学家,站在一边。甚至技术这件事情都叫他不要瞎说,原因是什么?因为真正在商业世界里,你需要的这个技术,往往不是原理性的技术。乔布斯说,实际上的好产品是什么?是无数的细节的打磨,无数的苦活、脏活、累活,而不是突然一下一个屌炸天的原理性突破。
3、地平线一直的战略观,就是在没有竞争的地方竞争,像李云龙那样的亮剑精神,两军相逢勇者胜,我觉得都是电视剧里的。真实的商业世界里,那是傻叉战略,是赌概率。真正好的战略是不赌概率的,一定是在某一个领域,你没有竞争对手,或者说你比竞争对手多十倍的资源,饱和式攻击。所以我们在19年的时候,思考到我们的客户应该是车厂,想明白这个道理以后,我们把非汽车业务全部砍掉。
4、中国估计没有一个企业把耐得寂寞作为自己的核心价值观,但地平线把「耐得寂寞」作为核心价值观。在整个科技创业史里,很长的时间里我们一直都不是明星,这样反而好。因为当时大部分被资本市场或自认为是明星的企业,后来都变为平庸。我们叫自己「打剩」的团队,不是打胜仗的胜,是打剩下的剩。我们少犯错,少当明星,少吹牛,然后(坚持)长期主义,反共识,真正的把利他作为我们价值的出发点。每天修身养性,耐着寂寞去思考。
5、面向未来,终局思维,保持一个扇面——不要去对未来的判断做精确的错误,要做大致的正确。我的方法是,先通过战略驱动,把组织推到接近炮火的地点,接近炮火之前尽量少争论,这是自上而下;接近炮火后,就让炮声来牵引,这是自下而上。自上而下和自下而上交织演进着往前走,不断动态调整平衡。
6、我是巴菲特跟查理·芒格的信徒。芒格曾说过,如果知道我会死在哪里,那我将永远不去那个地方。我们内部有句话,不要在悬崖边跳舞。如果要跳,也要离悬崖有足够的安全距离。
7、关于未来,其实大家都是盲人摸象——世界客观存在,但每个人都是从一个狭窄的认知通道去摸它。那你怎样在承认你是瞎子的情况下,保证你接近真实?所以你需要打破过去的认知,不断打破,不断重建,这不是某个阶段,是不断的循环。
巴菲特为什么每天花那么多时间饥渴般地读各种报纸、书?他为什么不觉得他已经够了?他对世界有敬畏之心,承认好多事他是不明白的,不断突破自己的边界——这是强大的心力和脑力的组合。企业家其实是对学习最贪婪的人群。你越懂得世界的不可知,越会更加积极。
所以对于地平线来讲,表面看战略,看技术,但不变的底层逻辑是:你是不是把成长看得比结果更重要?只有突破这一点,企业才能不断从一个境地,突破到下一个阶段,再突破到下一个阶段。
8、一个企业“最虚”的东西——使命、愿景、价值观——长久来讲才是“最实”的企业的核心竞争力。
9、使命跟愿景驱动的企业特别难管理。好处是当这种组织经历过黑暗,厚积薄发的能量就很大。它能够赢一次还能赢两次,还能赢三次。
10、要站在镁光灯的边缘,不要在中央。要做品牌也应该围绕客户去做。“头痛医头、脚疼医脚”地跟着市场节奏跑,短期可以跑,长期跑不过。你要做的是锁定一个维度,每年增加10%。
11、你跑什么样的方向很重要。因为你方向错了,跑得再快,再有驱动,只能错得更远——方向的核心就是商业模式,然后技术使得你在这个方向上跑得更快,就是这样一个关系。
12、今天任何企业的发展一定要真正的去创造价值,并且企业的规范、承诺都要去按照世界级的水平打造。不然的话,都会出问题。
13、我们认为利他跟利己本来就是一回事,成就客户就是成就自己。耐得寂寞,意味着我们不去做热热闹闹的事情,意味着长期主义,愿做二传手而非一定要自己进球,意味着很多批判性的思考,意味着延迟满足,专注当下,把眼前的事做好。
14、享受内部夸奖的老板,在现在这个时代其实很少了,内部的人夸你有什么用?因为市场在不断打你的脸,客户在不断打你的脸。
过去我对于组织管理是没什么感觉的,虽然也在大公司带过几百人。但跟现在复杂度完全不一样。大公司已经把体系和架子都搭好了,你以为自己很牛,其实不过是在一个成熟的体系上,做点加机油的工作,螺丝松了拧紧一点。
在大企业里很多人会支撑你,就容易导致会过高评价自己。你说我们部门今年挣了20个亿,但这么多部门支撑你对不对?而真的从零到一把一套东西建立起来,是非常难的,因为他完全是在黑暗丛林里摸索出来的。你要是发挥得不好,系统给予你的反馈非常明显。
15、我说地平线永远会在生存线上挣扎,这不是虚幻地激发自己,这种饥饿感就是现实——世界上不存在完美的组织,不存在完美的流程,只有不断突破的企业家精神。
16、每个企业其实有一万种死法,可能钱不够,可能客户没找对,可能被竞争对手干死……各种死法,当然也有组织涣散,尤其谈到管理这件事,它本来就是一个你既要顺着人性,又要反着人性去干的事情,组织走向涣散几乎是必然的。
我们看历史上凡是标杆型的企业,比如GE的杰克韦尔奇,曾经是全球CEO的标杆,可是没有杰克韦尔奇的GE,其实已经不是那个GE了,这个曾经的美国之光,现在从美国的道琼斯指数被拿掉了。长存的企业是不存在的,企业从诞生的第一天,它每天面对的都是死亡的可能性。
IBM在郭士纳的时代,大象也能跳舞,它的整个管理流程体系非常棒,可是没有郭士纳的IBM 也不是那个IBM,今天的IBM已经非常的boring(无聊)。所以其实每个企业都面临着熵增,面临着涣散,面临着各种死法。但我觉得,这可能也是创业或者是做企业本身既折磨人又迷人的地方。
地平线创始人兼CEO余凯在嘉宾派授课
2、组织文化
1、我越来越意识到,一个企业要完成一个很大、很难的目标,所有的资源禀赋都不重要,最终撬动变革的力量是人。人的核心不是体力,是脑力和心力。有章可循的是脑力;没章可循的是心力。
2、首先,通过满足对方来让对方做事,这是常人都能做到的,不是什么了不起的领导力;第二,真正成就一个人,必须在深层次做,而不是在表面做。表面上,你可能是个挑战者,给员工最难的工作,挑战他的目标,调整他的心性,但你一定要坚信你的底层逻辑,这是真正在帮他——在挑战中、在历练中、在常人所不能达的地方,你却让他做到了,这才是真正的领导力。
3、你要说服别人,首先要说服自己。如果你不能统一大家,就是因为你没有想透。
如果你没想透,自己不信,你讲的时候两眼不会放光,周围的人是不会被感染的。想得透,是有穿透力和说服力的。你一定要绝对地相信,才能在周围十个人的情况下感染两三个人。
所以企业家本人,一定是企业里最花时间思考的人。如果一个企业家天天开会,那个发布会、这个发布会,这个party、那个party,这个企业一定完蛋。
4、一个阶段的战略一定要匹配到组织。打仗要排兵布阵,也要加强组织文化建设。三分靠战略、七分靠组织。战略有的是事后总结的。
5、永远存在的企业几乎没有,所谓的制度流程文化一旦建立,确实能够为商业模式的起飞带来增长引擎。但跑了一段时间,人的惰性会使这些制度流程异化。比如说你制定KPI,互联网行业衡量大家的业绩,核心指标是用户量、流量。这个制度的确定在一开始会帮你把产品给做起来。过了一段时间,产品经理会变成老油条。他会想老板要的是流量,那我就跟友商去换,你给我导一些流量,我给你导一些流量,至于有没有质量增长,我不管。
6、一开始你靠十个人挣十块钱,当你要挣到100快的时候,人也要到一百人规模。最后你会发现你从十人增长到100人,效率并不是十倍的增加,因为人跟人之间的交流总是很难的。所以你要打造流程,建立机制,建立文化,让组织一边打仗,还能保持有序。这里面有一个核心就是市场导向,有一个外力的牵引,组织会更加有序。
所以我们要打造“成就客户”的企业文化,这些都是常识。我觉得牛逼的企业,中国不超过五个,优秀的企业都是最尊重常识的。
7、企业永远会面临这些问题。所以企业文化很重要,让你的企业永远拥有很强的生命力。年轻还是老年并不重要,精气神非常重要。人天然有周期,有些企业为什么要让年纪大的员工提前退休?你年轻的时候,很激情澎湃,房子没有,也没结婚,你什么都没有,就会特别的拼,没日没夜的干,等到有家有口,有孩子了,你还会这么拼吗?等到一定程度,人也疲了,战斗力也没有了。组织的成长跟人的机体是一样的,都会从充满斗志,生命力到归于平淡。
8、我擅长带着大家试错、摸索、成长,我跟核心管理团队说,你们不要把我看成是老板,我就是个班长。你们参加这个班,就是一起来学习,一起来锤炼的。说白了就是一个不断的学习成长试错的过程。
9、我觉得需要刻意地找到一些方法,找到现实世界的 BUG,包括商业模式、战略判断、组织建设里的 BUG。这些 BUG,都是通往高维世界的一道窄门。我也不断提醒自己,不要陷入到自洽的低维世界里。
我的方法是,团队要高频地去一起共创、迭代,内部的红军、蓝军去挑战习以为常的说法;第二,就是不能陷在组织里面,一定要向外看,去找那种不 care 你的人。他会真实地跟你讲自己的看法;第三,就是叫行万里路,读万卷书,见万种人,干一件事。
10、如果我们有一点点的不谦卑,我们的团队、我们的同学,他在日常的行为中也会体现出来一种傲慢,我们的客户也能看出来,这样我们就走不远。
11、尊重人才的最好方法是给予非常坦诚的反馈。不要隐藏,不要害羞或太过礼貌。给予直率而直接的反馈——无论积极还是消极都会让事情变得更简单。
12、一个企业的形成是因为一个愿景,一个Dream。好的企业会把这个Dream内化成每一个人的梦想。如果没有做到这一点的话,企业会越做越难,大家都很被动。尤其是你规模越来越大,复杂度越来越高的时候,主人翁精神的缺失,会导致最后没法做这个事。
想要完成愿景内化为每一个人的梦想,企业不断进化是核心,每个人都能感受到自我否定和进化的过程和快感。如果你没有这种体验,是很难跟上的,所以我们讲要打造学习型组织。我们的核心团队,每次到了假期都有学习列表,回来要交读书笔记。
13、如果一个组织总顺着人性,会变成一个泯然众人的组织,不能变成一个卓越的组织。
我特别讨厌别人做什么我们就做什么。99%的组织更愿意花时间在“术”的层面,却很少在“道”的层面花精力。但你看强大的组织,无论我们党、美国西点军校、华为、阿里巴巴,在人的思想层面,功夫做得入木三分。
我看柏拉图的《理想国》,讲理想的政治形态是一群智者领导众人,智者不是靠法律,而是把“道”想得特别透。地平线一直有个调性,希望在“道”的层面想透一点。有了道,一生二,二生三,三生万物。
嘉宾派校友参访地平线展厅
3、创业心得
1、我是2015年6月初正式离职百度的,7月14号公司才注册。中间这些时间干什么呢?都是创业者该干的事情,就是接受采访,然后找投资人。当时有个汽车媒体采访我,问我们要做什么?我们当时就说要做机器人大脑芯片,我们要让每一辆车、每个电器都具有环境感知、人机交互、决策控制的能力。
这段话其实已经基本上成为公司创世纪的 bible (圣经)了,你会发现一开始的信仰也很重要,因为中间你干很多兜兜转转的事情,但是总好像冥冥之中有个引力去牵引着你,去往这个方向走。
所以我觉得一个企业的创始人他一定要有信仰,一定要有个vision(愿景),然后那vision会冥冥之中牵引你很多的组织的整个行为。
2、创业公司一定要思考什么地方是你的根据地。第一,这个根据地未来能不能长大;第二,它是不是在巨头射程范围之内。
3、搞企业的人本来就是一群奇怪的人,就喜欢折腾,喜欢挑战,甚至面临市场竞争,你可能就是那种喜欢在刀尖上舔血的人,所以我觉得实际上是一种生活方式。比如我为什么创业,我自己个人的使命,肯定不是为了钱,如果说为钱的话,你想想看,我们股票又不能卖,给自己发点工资、发点奖金还不好意思,如果我在百度待着,一年工资加奖金之类的也不少,把钱甩在家里面,老婆老开心了,现在天天很晚回家,老婆真是……对吧,也不容易。
4、地平线创业从15年开始,到了19年,花了整整5年时间,付出巨大的代价,才明白一个道理,就是科学家创业,很容易出现一种情况,就是他会觉得我有超牛逼的技术,然后我可以去360行,到处找客户,每个客户我都能搞定。其实不是这样的。我们花了五年时间,才意识到真正商业的第一性原理,不是说你有什么技术,而是你需要回答的问题是你的客户是谁?你的客户到底是谁?然后围绕着你的客户的需求跟痛点去展开你整个的商业模式、组织壁垒、营销、研发所有的动作跟行为。
而且在这个过程中,你还要不断地去思考,如果你赢了一把,怎么赢第二把,你赢了第二把,怎么赢第三把?如果这个生意本身是赚钱的,那你在夜深人静,在睡觉的时候,一定有100家公司的CEO在想着第二天怎么干死你。所以你还必须以一种难以被复制的方式去解决你客户的需求跟痛点,这就是护城河。
5、创业最好的一个切入点,是从已经被验证的需求入手。比如小米做手机,这个时候已经证明了这个商业模式,证明了有用户对智能手机是有需求的,并且你会看到好多人花钱买。记得早年的时候iPhone在中国是没有官方渠道的,靠走私水货,每年都有100多万台的iPhone 进来,所以这个商业模式是已经被验证了,这是真实的需求。很多企业其实都是死在搞不明白需求这件事情。
6、我们15年创业的时候,那个时候基于的几乎是一个人类未来 20年、30年的愿景,就是机器人可能会无处不在,这里面需要芯片跟操作系统,可是眼前有谁为这件事情付钱呢?完全没有。所以从一个具体的已经被验证的需求去切入创业是更容易的,但如果是基于一个对未来的很长时间的愿景去创业是极其难的,因为你的商业闭环的场景你真的是闭环不了,这是科学家创业的一个典型的困境。
7、我们从愿景出发,然后我们想机器人第一应用场景在哪,玩具、智能家居,什么乱七八糟的试了一堆,从15年到19年,花了五年时间。后来我们做战略复盘,复盘完以后发现,这些无数的垂直场景全都不靠谱,他们要么太碎片化,说白了就是钱不够多,没油水。比如玩具这样的垂直场景,本身这个垂直领域就不大,而且对智能化也没有什么需求。要不就是什么呢?比如家庭服务机器人,它能够把吃完饭的桌子收拾干净,能够衣服洗完了以后拿出来烘干了,叠好了放到柜子里去,如果这个能解决,我估计5万块钱可能大家愿意买,因为这解决了绝大部分的夫妻矛盾问题,但是技术又不行。
所以你这样判断,其实你就发现,智能汽车是这里面既有油水,是技术的可能性跟需求的拐点,在19年那个时间点我们判断是将好,那个时候其实也是预判,为什么?因为那时候智能电动车其实处在很艰难的时候,但是那个时候我们觉得如果只有一颗子弹,我们射向哪个靶心?一堆的靶子,我们当时的判断就是射向汽车战场。
8、关于判断力本身,我觉得创业其实有一个核心能力是什么?就是运气,不要太夸大自己的能力,什么判断不判断的,狗屎运也很重要。你想2020年发生什么事情?特斯拉的股价狂涨,从两三百亿美金涨到差不多1万亿美金,其实蔚小理主要应该感谢特斯拉,我们也应该感谢特斯拉。
然后正好是19年的时候,我们推出了第一款车规级芯片,因为地平线从一开始刚创业的时候,第一天我们就规划两个产品线,一个是汽车级的芯片的产品线,一个是非汽车的产品线,一开始我们不知道需求在哪,所以我觉得该交的学费也得交。你在创业一开始的时候,是需要保持一个扇面去向未来探测,这个雷达要保持一定的覆盖面去扫描。
如果你是运气好的玩家,比如我们可能在自己的钱还没烧光没死掉的时候,突然这个雷达探知到了,嘟嘟嘟,这个地方有一个巨大的市场。所以我们在19年的时候,恰好第一颗车规级的芯片,征程二代推出来了。
2020年的时候,智能汽车市场就开始爆发了,然后我们成为这个战场一开打的时候,整个战场里,已经挖好了战壕,架起了一款机枪,正准备开打的几乎唯一的部队。
9、我认为在企业0到1的时刻,找到那个商业的切入点,证明了你有真实的客户,证明了你不是只有一个客户,你还有两个客户、三个客户,还有很多客户排着队,这是最重要的。你这个玩意儿是有需求的,这个需求不是别人说“哎呀,你要做,你做了我们就买”,不是这样,这里面很多都是陷阱,有谁愿意真金白银地从口袋里面掏钱给你?而且不是掏一笔钱,是反复掏。证明了这个东西,我认为一个企业的商业模式就走过了0-1。
从0到1的过程,这个过程其实非常黑暗,因为你要做很多试错。这个时候谈领导力跟组织力,讲再多的管理流程都是瞎扯淡,这个时候你最需要的就是心力。而且你有时候你还不能骂下属,骂销售或者骂什么东西你怎么不达标?实际上是你的方向定错了,你能怪人家吗?你还得忍住,你夜深人静的时候,只能骂自己。
而且这个时候因为你要保持一种方向的联动性,所以你这个时候一定要做一个反效率的事情。我们讲管理,一种是创新管理,一种是效率管理,创新管理是要找对方向,而效率管理是要不断地提升你整个的经营效率跟ROI,可是在0 到1的阶段,本质上你要解决的唯一的问题是创新管理,所以你这个时候,你太多的管理套路,什么流程体系,什么东西,做多了你反而死得快。你最需要的就是心力,组织未来虽然在黑暗中,然后从一个失败走向下一个失败,但是你还能扛过去。
10、我们有一个投资人,有一次给他的投资人也就是LP去分享,因为他们是美元基金,他的LP是一帮美国人。他就说这些年投了好多企业,这些企业的成功失败你都可以总结出好多理由来,但是他通过最终的复盘发现,然后他就放了一个视频,那帮美国人看那个视频目瞪口呆。视频里是杭州的一道名菜,就是拿活鱼蒸,蒸完了以后,端上桌,那个鱼嘴巴还在一张一张地动,眼睛怒目圆睁。然后他说,我复盘半天,发现什么呢?就是最好的创业者就像这条鱼一样,宁死不屈、怒目圆睁,就是能扛过去。
所以我觉得企业从0-1阶段其实就是这个东西,没有太多的套路,就是你要不断地复盘,不断地调整。
11、世界上的发达国家都在北边,因为温度适中,比较冷静。冷静的性格是适合创业的。如果温度比较高,大家就喜欢在户外去party,而比较冷的地方,大家有更多的时间独处,思考,就容易产生更多的哲学家、科学家、数学家,当然也会有幸存者偏差。如果创业的目标很高,你必然就会处于逆境中,那就更需要冷静。
12、我觉得地平线,我们的彼岸确实是迎来机器人无处不在的一个时代,我们认为它是一个比PC时代跟智能手机时代更大的一个科技浪潮,但是它的时间其实不会来的那么快,它取决于很多关键技术,包括大模型,通用人工智能,机械等很多东西。
我们基本上不关注机械这些东西,我们相信业界肯定有其他哥们可以做,我们就是专注于计算本身,就是芯片跟操作系统。走向这样的一个彼岸,我们觉得它一定有一个中间路径,就是先把智能汽车、智能驾驶这件事给击穿。
我们为什么一定要走这一步?这个领域有钱。因为你要把一个技术给滋养出来,把人才滋养出来,你需要找到一个垂直领域,这里面得有海量的资源的投入,能够吸引世界上最优秀的人才,并且有巨大的市场需求。你想当年如果不是智能手机这么一个大的战场,就不可能有IoT之类的,智能家居这些应用。因为他把很多比如安卓操作系统,包括把光学、声学的传感器,从以前的价格都很贵,通过这样的一个市场把它的规模一下打到成本非常低。汽车这个市场,我认为它可能是孕育人工智能、孕育机器人的把核心技术给击穿的一条必经之路。
所以我们整个战略路径的推演,就是从一个愿景出发,扫出未来很大的扇面,到最后聚焦到汽车。但汽车并不是我们的终局,我们之所以做汽车,是因为这里面的环境感知、预测建模、人机交互,还有复杂场景下的决策控制,路径规划,实际上都是机器人的通用计算需要的东西。所以我们需要有个场景,把这个技术给击穿,因此我们做汽车的芯片跟操作系统。
13、创业这件事情本身,我认为它是一种修行的方式,我自问什么东西给我带来快乐,我觉得是如果有一件事情我真的是明白了,我内心会非常非常开心。我在公司成立第二年的时候,跟管理团队分享,我就觉得“朝闻道夕死可矣”。就是只要明白了某个道理,关于世界、关于人生、关于商业、关于管理,每天如果有这样的收获,我这一天都开心。所以我觉得这是我的个人使命,就是不断地修行跟成长。
我觉得人生就是一场游戏,终局大家都是一样的。你唯一能够不同的就是这个过程,就是每一天的Delta(变量),我觉得每一天的那个变量,实际上才是人生的常量,我们应该把精力花在这件事情上面。
14、创业的核心第一是创新,去做别人没有做过的事儿。第二就是能够创造价值。当你在做一个有未来感的事情,一个别人没有做过的事情,其实已经在创造价值了。什么叫价值?价值就是对社会有用,表现形式是别人愿意付钱给你, 因为你为别人做了他们需要的事情。
要达到这个“有价值”的结果,你除了要有提出创新的目标,还要有手段、路径和组织。这些挑战你在大公司也会遇到,所以身处何处并不重要。你可以在大公司养老,也可以在小公司非常的passion(激情)。
15、很多人是被恐惧驾驭的,而不去思考是不是有价值。但世界从来都是非线性变化的,历史从来不是直线往前走。你敢于做预判,敢于迈开第一步,这些都是创业。
16、有人把创业的目标定为要买多少套房子,赚多少钱。另一种人的心态是,把每天的成长当作他人生的常量,他更加关注每天的思考、学习、进步、实践和反思。所以你要问我是怎么想到这个的,我不知道。你就做一个漫游者就行了,拥有开放的心态,不断的去学习和复盘。同时你也得是一个实践主义者,因为只有通过实践才能支撑认知,而不是幻想。
17、(问:创业最烦人的是什么?)其实确实最烦的是组织,你怎么打造一个有使命愿景的组织?如何让大家不被眼前的机会点给迷惑住?能够去更长远一点,更脚踏实地。
第二,我们希望内部的管理更加目标导向,而不是把精力放在争辩你我之间的边界上。这是人性的弱点,就是对于不确定性,不舒适性的恐惧,人的恐惧会战胜他对于目标的关注。
很多人做事情的desire(欲望),花的精力,是出于害怕,而不是出于passion和love。我看到的很多人都这样,但还要去管理这群人。
我经常说别人多做一点,你就少做一点,但你也要满足目标的达成,别人少做了,你就多做,无论做多做少,都不能妨碍最终大目标的达成。但很少有人会这么想。
18、选择去创办一家公司,还能做到不错程度的人,通常都是企业家自己的选择。这是他很passion的事情,所以怎么会后悔呢?在创业的过程中,我从来没有用过痛苦这个词,我会使用tough(坚韧)这个词。老板肯定是个乐观者,哪怕再硬的墙,都可以想办法用铁锤敲碎。有些事情虽然很难,但还是有招的。保持冷静、学习的状态。
19、我提出来做芯片,然后我们也有很多年轻人,有一颗To C的心,恨不得把整个自动驾驶车做出来在路上跑。年轻人总是想征服世界,觉得人家做自动驾驶那么风光,比我们做底层芯片的,听起来更性感。
我一直给团队泼冷水。我觉得汽车从辅助驾驶到自动驾驶,是一步一步的过程。中间每一步都需要芯片,我希望做一个生意模式,跟着整个产业演进的节奏,每一步都能挣钱。我不想最后把它搞成了才能挣钱,这样的商业模式不够健全。
这个事情,我们内部经过了很长时间的争论。最终冷静思考,我们觉得还是应该做产业的赋能者,把大家拓展商业边界的膨胀的思维,不断地收敛回来。
20、很多人说科学家不适合创业,其实跟性格特质有关。越是科学家,越喜欢深思熟虑、万事俱备再去做事,但我认识到一件事,无论你自认为多么聪明、做多么充分的设想、事先对战场状况多么了解,一旦冲入战场,形势的变化会远超你已有的经验。创业就是要赌。如果什么东西都看到,完全放在桌面上你才去做的话,那不叫创业,那叫工作。你唯一要做的事是勇敢,勇敢地放第一炮,看第一炮离你的目标有多远,再决定怎么放第二炮。
21、创业每天都是不断地在兴奋和不安中切换,活在现实和理想的巨大差距里。我天性是比较乐观的,要不然真没法创业,创业太苦逼了。未来并不是客观存在的,是一个illusion(幻觉),你要把脑袋里那些悲观的东西全关掉,坚定地相信一个非常大的未来,要不然真跨不过去。
22、从0到1阶段我们也总结了一些思维模型。首先是能力圈模型。我做了二十几年的研究,大部分时间都在写论文推公式,如果让我去做消费或者社交,我是绝对做不来的。但是关于芯片、操作系统、软件硬件架构,我天然是有敏锐度的,这里面所有的关键决策我是敢去拍的,所以一定要在自己的能力延长线上去做这件事情。
另一个是终局思维。可能每个战略会,我们会花70%的时间来讨论未来10年、20年必然会发生的最大的趋势是什么,听起来虚的不得了。之后我们再把地平线带入这个趋势里,要么就是顺势而为,要么就是把这个趋势拉进、加快。
如果先讨论10年的大趋势,再讨论三年目标就会非常容易。进而你发现都不用讨论,就可以把每个部门、每个团队、每个人一年的目标拉出来。以终为始的战略框架很让团队达成共识。
从眼前一两步出发也有可能能赢,但是我认为不如从终局来倒推。因为眼前诱惑太多,机会太多,迷惑和噪音太多。更何况对于基于长期愿景的技术性创业,眼前一两步可能不容易找到。
再就是千万不要随大流,要做非主流。主流市场是没有初创公司的机会的,你不能去假设真的就是天赋异禀。在地平线内部我们讨论人才优势时候,结论是我们没有人才优势。每一家头部公司每年都会在各个顶尖高校招到一批顶级学生。今年招的跟明年会有很大本质不同吗?并不会。所以也不能做人才优势这种假设,当前生意做得好的公司,肯定是因为他在3年前、5年前做了某些关键决策和组织准备,把一些核心能力建立起来了。
我们一定要在没有竞争的地方竞争,不要有侥幸心理,因为一旦陷入这种泥潭的竞争,这种贴身肉搏,你就要看造化,赢也是惨胜,不会赢得有气势,赢得动作优雅。我们常说要让胜负决定于交手之前,不断往前看,滚动迭代我们的认知。
另外就是压强原则,一旦你发现某个爆点,验证了这是一个真需求,你最应该做的事情是把所有的弹药往这个地方去倾斜,10倍的压强,10倍的弹药去炸一个山头。
当然我讲的所有的这些思维模型,它只是地平线的路径,只是你可以借鉴的工具之一而已,它并不是真理,也不一定适合每个人。
23、创始人之间一定要彼此能讲真话,不一定讲对的话,但是讲真话非常重要。在你偏执的时候有人去戳戳你,激活你的神经元,让你去意识到其他地方也应该思考。
对于联合创始人以及公司核心管理层,格局和领导力比专业能力要重要。创业过程中肯定要面对很多未知问题,你不能假设你什么都能学得会,要做的就是提升格局和领导力,找到比你更牛的人,外挂CPU把运算做完。
24、我们在从0到1的过程中,有大量的优秀的人才后来待不住、离开了,后来我们在想,公司在乱中取胜、在找方向的时候,其实很多优秀的人才是发挥不出来的。只有方向找对了,把专业能力给配上,才真正的恰到好处。如果还在找方向,或者这是一个伪需求时,专业能力用得更好,其实错的更多。所以在这个阶段,核心能力就是心力大于脑力。
25、那种认为年轻人只有创业一条路该走的观点,显然是不对的。究竟要不要创业,我觉得结论还是因人而异、因时而异,而且也不必太过刻意。回想我当初做出创业决定,可以说是水到渠成。一方面,我做人工智能已经很多年了,是世界上最早意识到专用芯片会有更好效果的人之一,同时我又做过自动驾驶方面的工作;另一方面,我父亲就是一名汽车工程师,这对我有着潜移默化的影响。其实很多事情兜兜转转,最终是相关因素相互作用的自然结果,而非刻意追求而成,我自己走上创业这条路就是如此。所以,我建议年轻人对于创业无需有太多执念,确保自己每天都在成长才是最重要的。
4、商业认知
1、我是互联网出身,地平线就把车看作四个轮子上面的计算机,这是我们公司的信仰。
2、这几年,我们也看到特斯拉,他是从另外一个路径,从一开始就干汽车,然后干汽车的芯片,现在开始用到他的机器人芯片,他们是从汽车芯片到通用机器人的芯片。我们是从通用机器人的芯片落脚到汽车的芯片,本质上我们两家企业其实是从两个不同的坡往上爬,爬着爬着,其实发现爬的是同一座山。
3、实话实说,中国智能电动车的整体技术水平,领先德国、日本大概5-6 年,这是目前的情况。
4、因为中国市场的这种特性,你会发现特别有意思的一个现象,就是高端汽车的芯片,它的第一个应用场景现在全在中国,无论是英伟达的汽车芯片,高通的汽车芯片,Intel,Mobileye,包括地平线的汽车芯片,第一个量产都不是在德国,也不是在日本,都是在中国。而且还不是合资品牌,都是中国的自主品牌。所以中国已经成为高端汽车智能芯片的一个主战场,世界杯决赛的战场。
5、其实我觉得技术从来没有成为过护城河,当年看英特尔打赢摩托罗拉,其实不是靠技术,英特尔的技术当时是不如摩托罗拉的,不如当时一大票的竞争对手,英特尔能打赢他们CPU这场战役,很重要的就是靠营销,它的品牌 Intel Iinsight “当当当当”深入人心,让你那个时候觉得你的PC里面如果装的是AMB的芯片,就是水货。这是一个相信,但并不一定是真实。包括他们当时宣传的个人色彩浓厚的“只有偏执狂才能生存”的口号,是整个品牌的一个战役,打的很漂亮。
你觉得苹果的护城河是技术吗?根本不是。其实苹果很少在核心技术上投入研发,业界都知道,研究苹果的产品战略最好的一个策略是什么?一般来讲,就是他们在每代产品推出大概4到5年之前,会抢注一大票专利,然后他们会 sourcing(采购)很多的供应商。
苹果最牛逼的能力在于什么?是对用户需求的理解,以此为基础去整合全球资源,所以它的研发投入是很低的。但是苹果如果只是推出了iPhone 14,不推出 iPhone 15 ,或者 iPhone 15 失败了,塌掉一代,苹果还有苹果吗?它很可能被竞争对手给干死。
技术科技行业,不像卖包包,卖个LV的包或者香水,那是真的有护城河,强大的护城河。技术的话,我们觉得它是冲浪模型,它没有护城河,它就是每一代的技术浪潮,你一定得浪过去,你一浪被掀翻了就没有你了。
6、为什么巴菲特长期不投高科技公司?段永平也一直讲,因为投资科技公司,你是很难获得长期收益的,但什么促使他投苹果,或者说投别的企业,比如现在英伟达市值也到1万亿了,他们确实是值得,因为他们有护城河,苹果的护城河是品牌,英伟达的护城河实际是生态。当你的客户在上面已经写了超过100万行代码的时候,它还能从英伟达的手掌心跑掉吗?跑不掉的,每一行代码都是天数。所以软件生态是极其强大的粘性。为什么操作系统公司值钱?操作系统的模式就是有生态。
所以我觉得科技公司其实核心要什么呢?就是通过一浪一浪的科技浪潮,你始终浪下去,但你沉淀下来其实不是技术,沉淀下来的应该是品牌、是客户关系、是行业标准、是生态,那些才是真正的护城河。当然它自身的护城河,肯定是打造一个强大的,能够去建设这样护城河的组织,我认为这是最重要的。
7、机器人这个战场,因为是一个新战场,它不是巨头目前的主攻方向,我们对这件事情有长期耐心,这个东西本身不可能一蹴而就。因为在这个生态上面,长出什么APP,其实你是不知道的,这不是一个计划经济,它是一个自然涌现的,但是你必须有长期的耐心去运营的事情。
对于机器人的应用,我们不知道除了汽车以外哪个垂直场景能长出来,但是我们绝对不能主动出击,主动出击去做这个证明题会死得非常快。
因为每个商业闭环,比如说一个新品类的创造,几乎是需要有大师级的魔法才行。历史上到目前为止我们觉得像大师级的魔法是不多的,乔布斯算一个,创造了一个智能手机的品类,马斯克也算一个,但你千万不要假设你有这个能力,所以我们自己是不去创造新品类的。
我们对于这个战略,就是守株待兔,长期耕耘,我们希望如果那个兔子跑过来的话,撞到我们身上就好。而且一定要控制投入,不要投入的过大,投入过大的话容易出问题。这是目前我们在这方面的想法。
8、在专用车领域,自动驾驶会提前实现,比如说矿山无人驾驶。其实我很少讲无人驾驶,因为我觉得无人驾驶在特定领域会实现,但真正的现在乘用车其实都是辅助驾驶、智能驾驶,而不是无人驾驶。
9、我们觉得操作系统比芯片更值钱,从历史上看也都是这样。安卓的商业价值估计是ARM或者高通的10倍,Windows的商业价值估计是Intel的大概10倍。原因是什么呢?就是真正附着在你的生态上面的,实际上是操作系统。而且你看每一代的商业的演进,一般来讲第一波的王者是芯片厂家,然后随之而来的第二波但是更大的玩家是操作系统。
10、中国有好多业界的人希望去打造操作系统,适配所有的硬件,或者是说做个硬件去适配所有操作系统,其实都是想多了,做软硬协同这件事情,是有它深刻的技术规律和产业规律的。我自己在15年创业的时候,到现在我都一直觉得中国的创业者跟中国的投资人对于从2000年开始的整个C端的互联网,对于C端的营销,包括这里面的转化率、客单价这些东西非常厉害,但是很少有人去研究美国战后一直到2000年,一大票的核心硬科技企业,是怎么成长起来的,他们的商业模式是怎么演进的,他们发展的产业规律是什么样的,这个研究非常非常少,这是我看到过去十年中国的硬科技失败的一个主要原因。
11、我觉得不被人质疑的梦想不值得做,不被人嘲笑的想法也不值得尝试。我现在反而担心,地平线被越来越多的人认同,可能意味着我们变成了一家无聊的公司,不是真正有前瞻性的公司。中国有很多商业上很成功、挣钱很多的公司,但缺少有未来感的、冷静的、犀利技术判断的公司。
12、要自洽,做自己的公司才是好公司。
比如微软,看见Google做搜索引擎,它也做搜索引擎,看见苹果做iPhone成功了,它也去做智能手机。结果学别人都成为不了别人,只是做得更差的自己。直到新的CEO纳德拉来了以后,重新找回微软的灵魂,坚定地去做云计算,去做ToB的业务。当它做回自己、不学别人的时候,反而变得更强大了。
如果一个企业总是看别人做的什么东西好,你就眼红,就去做。它的格局不会很大。像古代的武林高手,如果你剑之所指,跟自己的心之所向不是合一的,那这一剑出去其实没有力道。
今天别人要学我们也很难。为什么?因为你看到的只是我今天的冰山一角。地平线今年的业务进展,其实跟我今天做的决策不会有什么关系,一定是前面几年的延长线。所以我为什么说,我们是非常地厌恶竞争,永远要在没有竞争的地方竞争。
13、只要被大家需要就是幸福,如果不被需要了,说明在地平线之外有更能创造价值的公司、创新生态、技术体系起来了,我们证明了此路不通也是一种价值。没必要太“我执”,还是要把我放得小一点。
14、不要假设自己比别人聪明,运气比别人好,大家都差不多。唯一的可能性,就是比别人在这件事上的passion和精力花得更多。
15、造车新势力成立之初,大家都说他们不懂造车什么的,其实都是门外汉干死内行的过程。我发现美国创新也是这样的,大部分人按照过去行业规律看未来,总是误判。你要根据第一性的原理来看,规律来看,而不是看经验,经验都是欺骗性的。
16、大部分人趋于冷静是被动的,并不是主动的。如果现在出现一个party,大家更愿意去参加party,只不过现在没有party。历史已经无数次证明人性的贪婪,没有坚持,更愿意堕落,往下走,不愿意往上走,因为往上走太费劲。每次经济周期里,真正挣大钱的都是意识到并且会利用人性弱点的人,但也有人把自己玩进去。
17、第一,“道”是客观存在的,我们必须相信它在那个地方;第二,我们永远和它有距离,但有距离不代表不能找到方法接近它。这个世界有很多火灾无可预测,不代表你不能防患于未来。世界的不可知性和超越自己边界的主观能动性,看似矛盾,但破局点在于你一定要找到矛盾的转化点,一定要统一。
18、人的底层性格不会变,但认知可以变——杀伐决断的力道,根本原因是你有没有把底层逻辑想清楚。一旦想清楚了,你就会特别决断。我改变自己的方法,不是变得比以前强势,而是让自己想得更透。
19、未来汽车行业,一定会复制手机行业和PC行业的规律:一类企业(像苹果)选择垂直整合,所有东西都自己做;绝大多数企业,则会把精力更多地放在产品、品牌、渠道和用户上,而不可能具备所有的底层技术能力。
20、基于自身的成功发展,一般大型企业会寻求高收益的庞大业务,因而难以发现从小处着手开发,着眼未来的颠覆性技术创新。
创业公司本质上更具创新力,倾向于做更加颠覆性的工作。实际上,大多数颠覆性技术或创新都是从很小的事情开始,这也正是小型创业公司成长壮大的领域。他们会培养目前看上去很小但未来几年有望扩大的机会。
当大型企业意识到这些业务实际上有大展宏图的发展机会时,已经晚了。这种情况发生在硅谷,也发生在中国。
21、太多人喜欢当兔子了,这个热门就跳到这,那个热门又跳到那去……我觉得还是当乌龟比较好,就是长期找到一个方向,不要想那么多,不要太功利。
22、孤注一掷可能不成功,但不孤注一掷根本不可能成功。
嘉宾派在地平线
---
layout: post
title: 地平线 4.5 亿美元零息可转债定价公告解读
subtitle: Codex 个人助理沉淀
date: 2026-07-22 23:37:56 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/horizon_robotics/03_地平线450百万美元零息可转债定价公告解读.md
地平线 4.5 亿美元零息可转债定价公告解读
记录时间:2026-07-23 CST
主题
围绕地平线机器人 2026-07-23 披露的《2027年到期之450,000,000美元零息可转换债券之定价》公告,整理一版可复用的中文解读,重点保留交易结构、关键数字、与前一日 CARIAD 借款修订公告的关系,以及对摊薄和现金流的实际影响。
说明:
- 本笔记不收录港交所公告全文逐字翻译,仅保留结构化中文解读与关键数字。
- 原始公告链接:
https://www1.hkexnews.hk/listedco/listconews/sehk/2026/0723/2026072300028_c.pdf
一句话结论
地平线用一笔 4.5 亿美元、零票息、初始转股价 5.55 港元/股 的新可转债,去置换前一日为解决 CARIAD 旧可转借款而需要支付的 3.989 亿美元 现金;相较旧借款 3.99 港元/股 的转股价,这笔新债的潜在摊薄更低。
关键数字
- 发行规模:
450,000,000 美元
- 票息:
0
- 到期日:
2027-07-27 前后
- 初始转股价:
5.55 港元/股
- 固定汇率:
1 美元 = 7.8395 港元
- 全额转股对应股份数:约
635,635,135 股
- 占当前已发行股本:约
4.36%
- 占全面摊薄后股本:约
4.18%
- 预计所得款项净额:约
445.5 百万美元
和前一日 CARIAD 公告的关系
前一日修订公告的核心是:地平线提前处理原本由大众体系 CARIAD 持有的旧可转借款。
旧借款的已知结构:
- CARIAD 实际支付现金:
8 亿美元
- 合同本金:
924,855,491.33 美元
- 原转股价:
3.99 港元/股
- 到
2026-07-21 应计利息约:8,190 万美元
- 因此本息合计约:
10.0676 亿美元
修订后的处理方式:
- 先发行
1,301,763,486 股,结清约 6.624 亿美元 本息,使 CARIAD 持股到 9.9%
- 再支付现金
3.989 亿美元
- 其中:
- 偿还超额贷款部分约
3.444 亿美元
- 额外现金付款约
5,450 万美元,用于买断超出 9.9% 上限部分的转换权
本次 4.5 亿美元 新可转债,主要就是为这 3.989 亿美元 现金支付提供资金。
为什么市场会把这件事看成“债务重组”
因为公司不是单纯再借一笔新钱,而是把原来那笔对股东更不友好的旧工具替换掉:
- 旧工具:
CARIAD 可转借款,转股价 3.99 港元/股
- 新工具:
2027 到期零息可转债,初始转股价 5.55 港元/股
同样是一种“以后可能转股”的融资方式,但新债的转股价更高,所以如果未来发生转股,需要发行的新股更少,对老股东的分薄更轻。
这份定价公告里最关键的几点
1. 转股价明显高于旧借款
- 新债转股价:
5.55 港元/股
- 旧 CARIAD 借款转股价:
3.99 港元/股
这意味着:对同样一笔融资金额,新债若未来转股,需要发出的股份数量会少于旧借款。
2. 转股价相对现价有溢价
公告写明:
- 较
2026-07-22 收盘价 4.75 港元 溢价约 16.8%
- 较前五个交易日平均收盘价
4.44 港元 溢价约 25.0%
这说明公司这次不是按折价发股融资,而是按高于现价的转股价发行新可转债。
3. 潜在摊薄低于旧方案
公告直接给出比较:
- 若沿用旧可转借款处理相同的
3.989 亿美元,潜在摊薄约 4.9%
- 改成这笔新可转债后,潜在摊薄约降至
3.9%
这就是本次融资结构最重要的股东层面意义。
主要条款速记
- 发行价:面值
100%
- 利息:
0
- 到期赎回:按本金
100%
- 转股期:发行后第
15 个营业日开始,到到期日前第 10 个营业日结束
- 公司可赎回:
2027-01-29 后若股价在 30 个交易日中至少 20 日达到转股价的 120%- 或原债券超过
90% 已被赎回、买回注销或转股
- 若退市或发生控制权变动,债券持有人可要求公司按本金赎回
发售地点与对象
这笔可转债不是在香港面向散户公开发售,而是一次面向境外专业投资者的国际配售。
- 公告明确写明:该等证券不会在美国公开发售,而是依据
Regulation S 在美国境外提呈发售及出售
- 经办人告知公司:将向不少于
6 名独立认购方发售
- 认购方将为独立个人、企业及/或机构投资者
- 债券拟上市地点并非港交所,而是维也纳证券交易所运营的
Vienna MTF
因此,更准确的理解是:这是一笔面向境外专业投资者发售、并在 Vienna MTF 挂牌的国际可转债。
资金用途
净募资约 4.455 亿美元,用途分两块:
3.989 亿美元 用于支付 CARIAD 修订协议下的现金对价- 剩余部分补充营运资金和一般企业用途
对地平线的实际影响
股权层面
- 减少未来按
3.99 港元/股 继续低价转股的风险
- 把潜在摊薄从约
4.9% 压到约 3.9%
- 新债若未来转股,摊薄依然存在,但条件比旧借款更友好
现金流层面
- 公司仍然要先完成对 CARIAD 的大额现金支付
- 这笔新债本质上是为那笔现金流出再融资
报表层面
- 旧 CARIAD 工具的公允价值波动曾显著影响利润表
- 提前处理旧工具后,这部分历史包袱被实质性切断
- 但新可转债未来仍可能带来新的估值和摊薄讨论,只是条款更简单、价格更高
待继续跟踪
2026-07-29 前后是否顺利完成发行- 最终认购对象结构和二级市场表现
- 交割后 CARIAD 提前赎回是否按计划落地
- 2026 年中报对旧 CARIAD 工具公允价值变动的正式披露金额
- 新可转债在后续财报中的会计处理和潜在摊薄披露
下一步动作
- 等中报出来后,把这份公告与中报附注里的金融负债、公允价值变动数字对上
- 若后续需要写对外文章,可把本笔记扩成“地平线如何用一笔更贵的新可转债,拆掉旧借款摊薄炸弹”的短文
---
layout: post
title: 地瓜机器人开发工程师岗位学习路线
subtitle: Codex 个人助理沉淀
date: 2026-07-14 07:37:08 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/robotics_job_prep/01_地瓜机器人开发工程师岗位学习路线.md
地瓜机器人开发工程师岗位学习路线
日期:2026-07-14
一句话结论
这个岗位本质上不是单纯写业务代码,而是要做“机器人应用工程 + AI 新技术验证 + 开发者教育输出”的复合型工程师。想拿下这个岗位,最关键的是把能力补成 5 条主线:Python/C++/ROS2、机器人感知导航控制、数据采集到部署、VLM/VLA/Agent 新范式、以及能落地成 demo 和技术文档的工程输出能力。
岗位要求拆解
从截图里的 JD 反推,核心要求可以拆成下面几块:
-
机器人应用开发能力
需要基于 RDK 套件做感知、导航、操控、交互类 demo,说明你不能只懂算法,还要能把系统跑起来。
-
AI 新技术验证能力
要跟踪 VLA、VLM、Agent + 机器人这类前沿方向,并验证它们在 RDK 平台上的可行性。
-
AI 辅助研发能力
JD 明确写了要深度使用 Cursor / Copilot / Claude 这类工具,说明他们希望你不是传统开发者,而是“会借助 AI 放大产出”的工程师。
-
技术内容输出能力
岗位要求输出高质量代码与文档,还要协同社区答疑,所以你需要把“做出来”变成“讲清楚、复现出来”。
-
机器人项目经验
如果没有完整机器人项目,面试竞争力会明显弱;至少要补出 2-3 个能讲清架构、传感器、算法、部署和踩坑的项目。
你应该重点学什么
1. 编程与系统基础
这是硬门槛,优先级最高。
- Python
- 数据处理、模型推理脚本、机器人 glue code、快速原型。
- C++
- ROS2 节点、性能敏感模块、驱动接口、控制逻辑。
- Linux
- Git + CMake + colcon
建议目标:
- Python 能独立写推理/数据处理/部署脚本。
- C++ 能独立写 ROS2 节点、消息通信、简单库封装。
- 能在 Ubuntu 下独立编译、调试、定位依赖问题。
2. ROS2 与机器人软件栈
这是岗位里的核心底座。
重点学习:
- ROS2 基础通信:
topic / service / action / parameter / launch / tf2
- 机器人描述:
URDF
- 导航:
Nav2
- 控制:
ros2_control
- 常见传感器接入与融合
- 日志、录包、回放:
rosbag2
建议目标:
- 自己从 0 搭一个双轮底盘或仿真机器人,把建图、定位、导航链路跑通。
- 能解释清楚 ROS2 节点间的消息流和系统拓扑。
3. 感知、导航、控制基础
这部分决定你是不是“懂机器人”。
重点学习:
- 相机、IMU、LiDAR 的基本原理和噪声特性
- 坐标系、外参、标定
- OpenCV 基础
- SLAM / 定位 / 路径规划基础概念
- PID、运动学、轨迹跟踪、状态估计
建议目标:
- 能说清楚 IMU 为什么漂移、LiDAR 为什么需要时空对齐、相机为什么依赖标定。
- 能独立做一个“感知输入 -> 决策 -> 控制输出”的最小闭环 demo。
4. 数据采集 -> 训练 -> 部署
JD 明确要求理解机器人数据采集、训练、部署的基本流程。
重点学习:
- 数据采集与标注
- 训练集 / 验证集划分
- 模型训练与评估
- ONNX / TensorRT / 边缘部署
- 推理延迟、吞吐、内存占用、量化
建议目标:
- 能把一个感知模型从训练结果部署到板端或边缘设备。
- 能解释“精度下降和实时性提升”之间的取舍。
5. VLM / VLA / LLM Agent
这是岗位的差异化重点。
重点学习:
- VLM:视觉输入 + 语言理解
- VLA:视觉语言动作,把 perception 和 action 接起来
- Agent:任务分解、tool use、function calling、多步执行
- LLM 在机器人中的典型角色:
建议目标:
- 能讲清楚 VLM、VLA、传统感知控制 pipeline 的区别。
- 能做一个“自然语言指令 -> 感知理解 -> 动作执行”的 demo,即使是仿真版也可以。
6. 仿真与 Sim-to-Real
如果你没有真实机器人平台经验,仿真是最现实的补法。
重点学习:
- MuJoCo:偏控制、强化学习、动力学
- Isaac Sim:偏机器人仿真、传感器、合成数据、ROS2 联动
- Sim-to-Real 的常见问题:延迟、噪声、动力学差异、传感器偏差
建议目标:
- 至少熟一个仿真平台。
- 能把仿真里的传感器、控制器、ROS2 通信串起来。
7. 技术文档与开发者输出
这个岗位不是闷头开发型岗位,必须会输出。
重点学习:
- README、部署文档、故障排查文档
- demo 复现说明
- 方案文档与架构图
- 技术博客 / 视频脚本表达
建议目标:
- 每个项目都要有:项目背景、架构图、依赖、启动步骤、效果视频、已知问题。
推荐学习顺序
第一阶段:2-4 周
目标:补硬基础。
- Python 基础和常用工程写法
- C++ 基础语法、类、内存、STL
- Linux / Git / CMake / colcon
- ROS2 基础通信模型
第二阶段:4-8 周
目标:跑通机器人基本链路。
- URDF、tf2、rosbag2
- Nav2、ros2_control
- OpenCV
- 相机 / IMU / LiDAR 基础
- 做一个 ROS2 机器人 demo
第三阶段:4-8 周
目标:补 AI + 机器人前沿。
- VLM / Agent / Function Calling
- OpenVLA / RT-2 这类 VLA 范式
- MuJoCo 或 Isaac Sim
- 做一个“语言指令控制机器人”的仿真项目
第四阶段:持续进行
目标:把学习变成作品集。
- 每学完一块就写博客
- 每做完一个 demo 就录视频
- 把项目整理成 GitHub 仓库
最值得补的项目作品
如果你现在项目经验不够,优先补这 3 个。
项目 1:ROS2 + Nav2 自主导航 demo
最低要求:
- 仿真或实物底盘
- 激光雷达或深度相机
- 建图、定位、导航跑通
- 能讲清楚地图、定位、规划链路
项目 2:视觉感知 + 板端部署 demo
最低要求:
- 用相机做目标检测或跟踪
- 模型转换并部署到边缘端
- 记录时延、帧率、精度损失
项目 3:VLM / Agent + 机器人交互 demo
最低要求:
- 用户输入自然语言命令
- LLM 或 VLM 做解析
- 触发具体工具或机器人动作
- 最好能接 ROS2 或仿真环境
教程 / 博客 / 视频链接
下面按学习方向整理,优先放官方文档和长期有效资料。
1. RDK 与地瓜机器人官方资料
- RDK 官方文档入口:https://developer.d-robotics.cc/
- RDK X5 文档中心:https://developer.d-robotics.cc/api/v1/fileData/documents_rdk/rdk_x5/index.html
- D-Robotics 官方 GitHub:https://github.com/D-Robotics
- 地瓜机器人官方 B 站主页:https://space.bilibili.com/3494375642948662
- RDK X3 / X5 相关官方视频示例(B 站):https://www.bilibili.com/video/BV1hp4y1j791/
为什么先看这个:
这个岗位直接围绕 RDK 套件,越早熟悉官方 SDK、板卡能力、样例工程和部署方式,越能减少“学了一堆通用知识但和岗位不贴”的问题。
2. Python / C++ / 通用编程
- Python 官方教程:https://docs.python.org/3/tutorial/
- C++ 参考文档:https://en.cppreference.com/w/
- LearnCpp(系统教程,非官方但质量高):https://www.learncpp.com/
3. ROS2 / 导航 / 控制
- ROS 2 官方教程(Jazzy):https://docs.ros.org/en/jazzy/Tutorials.html
- Nav2 官方文档:https://docs.nav2.org/
- ros2_control 官方文档:https://control.ros.org/
- URDF 教程入口:https://docs.ros.org/en/jazzy/Tutorials/Intermediate/URDF/URDF-Main.html
4. 感知 / 视觉 / 机器人基础
- OpenCV 官方教程:https://docs.opencv.org/4.x/d6/d00/tutorial_py_root.html
- Modern Robotics 官网:https://modernrobotics.northwestern.edu/
- Modern Robotics 课程视频:https://modernrobotics.northwestern.edu/chapters/chapter1/
- 《Underactuated Robotics》课程与讲义:https://underactuated.mit.edu/
说明:
Modern Robotics 更适合补机器人运动学、动力学、控制基础;Underactuated Robotics 更适合把控制和系统思维拉高一个层次。
5. 仿真
- MuJoCo 官方文档:https://mujoco.readthedocs.io/en/stable/
- MuJoCo 官方 Python 入门:https://mujoco.readthedocs.io/en/stable/python.html
- NVIDIA Isaac Sim 官方文档:https://docs.isaacsim.omniverse.nvidia.com/latest/
- Isaac Sim ROS2 教程入口:https://docs.isaacsim.omniverse.nvidia.com/latest/ros2_tutorials/index.html
6. VLM / VLA / Agent
- Hugging Face Agents Course:https://huggingface.co/learn/agents-course/unit0/introduction
- Lilian Weng 博客《LLM Powered Autonomous Agents》:https://lilianweng.github.io/posts/2023-06-23-agent/
- OpenVLA 项目页:https://openvla.github.io/
- RT-2 项目页:https://robotics-transformer2.github.io/
说明:
Lilian Weng 这篇非常适合建立 Agent 基本框架。OpenVLA 和 RT-2 适合建立“VLA 到底是什么、为什么对机器人重要”的直觉。
7. AI 编程工具与 Agent 工程化
- OpenAI Function Calling 指南:https://platform.openai.com/docs/guides/function-calling
- OpenAI Building Agents 指南:https://platform.openai.com/docs/guides/agents
- Anthropic Prompt Engineering 文档:https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overview
说明:
这部分不是让你背 API,而是要理解:
- 如何把任务拆成多步
- 如何让模型调用工具
- 如何做失败重试、状态管理和结果校验
面试前你最好准备到什么程度
最低目标不是“全会”,而是能把一条完整链路讲明白。
建议你至少准备好下面 4 类面试素材:
-
一个机器人系统项目
你做了什么、用了什么传感器、节点如何通信、踩了什么坑、怎么验证。
-
一个板端部署项目
模型如何转换、为什么选这个模型、板端性能如何、优化了什么。
-
一个 AI + 机器人结合项目
哪怕只是仿真,只要你能讲清楚任务规划、感知输入、工具调用、动作执行,也比空谈强很多。
-
一份高质量文档或博客
这个岗位重视开发者案例输出,你最好拿得出已经公开整理过的技术内容。
如果时间有限,优先级怎么排
如果你现在时间不够,按这个顺序学最划算:
Python + C++ + ROS2Nav2 + ros2_control + 传感器基础OpenCV + 边缘部署MuJoCo 或 Isaac SimVLM / Agent / VLA技术博客与 demo 输出
最后判断标准
你是否适合投这个岗位,不看你学过多少名词,而看你能否同时证明下面三件事:
- 你能把机器人系统真正跑起来
- 你能快速试用 AI 新技术并判断是否可落地
- 你能把结果整理成别人可复现的代码和文档
如果这三点都能做到,这个岗位会很匹配你。
下一步动作
- 先判断你当前最短板的是哪一块:
ROS2、机器人项目经验、还是 VLM/VLA/Agent。
- 用 6-8 周补出一个可演示的机器人项目,而不是只刷教程。
- 每完成一个模块就沉淀博客和仓库,面试时直接作为作品集。
---
layout: post
title: 高盛 2026-05-19 地平线机器人研报详细解读
subtitle: Codex 个人助理沉淀
date: 2026-07-07 07:28:43 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026-05-19 Goldman Sachs
---
来源:notes/books/Horizon Robotics 2026-05-19 Goldman Sachs/01_详细解读.md
高盛 2026-05-19 地平线机器人研报详细解读
标的:地平线机器人-W 9660.HK
机构:Goldman Sachs
报告标题:Horizon Robotics (9660.HK): Asia Communacopia + Technology — Key Takeaways: NOA penetration up; Integrating Cockpit-Driving SoC/OS
发布时间:2026-05-19 10:39 HKT
本地原文:source_materials/高盛5月18日研报.pdf
全文转换稿:source_materials/pdf_full_text.md
处理日期:2026-07-07
说明:本文基于用户提供 PDF 的个人助理沉淀,不构成投资建议。
1. 核心结论
这篇高盛研报的重点,不是新增了很多财务细节,而是把地平线当前的多头逻辑压缩成两个最核心的增长引擎:
NOA 等高阶 ADAS/AD 功能继续从中高端车型向主流车型、再向更低价位车型渗透。- 地平线开始把“智驾芯片”升级为“舱驾一体平台”,试图通过
Starry 芯片和 KaKaClaw OS 同时拿硬件价值量和软件入口。
高盛维持 Buy,12 个月目标价 HK$15.30,以 2026-05-18 收盘价 HK$5.97 计算,隐含约 156.3% 上行空间。
一句话概括:高盛押注的不是短期业绩 surprise,而是地平线能否借助 NOA 下沉和舱驾一体平台,在 2027-2028 年之前完成收入放量、ASP 提升和盈利拐点。
2. 报告最重要的新信息
2.1 舱驾一体不只是降本,而是平台叙事
管理层在会上重点推介了舱驾一体解决方案,包括:
Horizon Starry 芯片;KaKaClaw 车载 OS。
高盛认为,这套方案对 OEM 的吸引力首先来自降本:
- 更少的 memory;
- 更少的 PCB;
- 更低的散热与 cooling 成本;
- 更少的系统级重复器件。
但更重要的是,地平线想把自己从“一个 AD 芯片供应商”往“智能车操作平台”方向推。只要这个方向成立,公司未来收入来源就不只是芯片 ASP,还可能扩展到 OS、座舱交互、软件订阅和更深的系统绑定。
2.2 管理层判断软件整合会先于硬件整合
报告里有个细节值得单独记住:管理层认为,受当前硬件架构和 OEM 内部组织分工影响,真正的硬件级舱驾融合不会一夜之间全面发生,但软件层面的整合会更快。
这意味着:
- 近期更容易落地的不是“所有车都一颗芯片搞定”;
- 而是智能驾驶和智能座舱在交互逻辑、OS 和体验层先打通。
对跟踪地平线来说,这个判断很重要,因为它决定了验证节奏。未来不能只盯芯片是否全面融合量产,也要看 KaKaClaw 这类软件层产品是否先拿到客户。
3. 多头逻辑的真正支点:NOA 下沉
高盛反复强调的并不是一个抽象的“智驾行业增长”,而是 Highway/City NOA 正在穿透主流车型。
报告的底层假设是:
- 高阶 ADAS/AD 功能会继续从高价车向大众化车型扩散;
- 功能扩散带来的不只是销量,而是更高价值量芯片的上车;
- 只要地平线仍在主流 OEM 供应链里,功能渗透率上升就能同时推升出货量和 ASP。
这是这篇报告最关键的一点。它不是单纯说“车卖得更多”,而是说“每辆车上搭载的 AD 能力更强,所以芯片和解决方案的单车价值量也更高”。
4. ASP 提升为什么被高盛看得很重
管理层提到,2025 年 ASP 已因为更高端 AD 芯片出货而显著提升,并预计 2026 年继续延续。
这对估值非常关键,因为如果只有出货量增长,而 ASP 不抬升,公司更可能只是一个薄利硬件供应商;但如果量和价同时上行,财务杠杆就会明显更强。
所以后续看财报,不能只看:
- 出货量;
- 收入同比。
还要额外看:
- 产品结构是否继续向高阶 AD 芯片升级;
- 单车价值量是否在提高;
- 毛利率和绝对毛利是否同步改善。
5. 高盛给出的财务路径
报告给出的核心预测如下:
| 年度 |
收入 Rmb mn |
EBITDA Rmb mn |
EPS Rmb |
| 2025 |
3,758.3 |
-3,593.4 |
-0.83 |
| 2026E |
7,033.9 |
-1,630.3 |
-0.29 |
| 2027E |
12,051.6 |
2,044.9 |
0.15 |
| 2028E |
20,985.4 |
6,547.5 |
0.51 |
这组数字说明高盛押注的是一条很陡的经营杠杆曲线:
2026E 仍然亏损,但亏损快速收窄;2027E 转正 EBITDA 和 EPS;2028E 进入更明显的利润释放期。
换句话说,目标价成立的前提不是“明年就证明一切”,而是市场愿意提前为 2027-2028 年的利润兑现付费。
6. 估值方法偏激进,意味着执行要求更高
高盛的估值方法是:
- 基于
2029E EBITDA;
- 给予
28.0x EV/EBITDA;
- 再用
11.5% COE 折现回 2026E。
这说明两件事:
- 这是一个明显偏中长期的成长估值,而不是基于近一年利润的保守估值;
- 只要市场怀疑地平线到不了
2027-2029 这条利润轨迹,目标价弹性就会被快速压缩。
因此,这篇研报虽然看起来给了很高上行空间,但本质上对执行要求并不低。
7. 这篇报告的局限
这份材料只有前两页是实质研究内容,剩余部分大多是披露和历史目标价表,因此它更像“会议纪要式增量更新”,而不是完整深度覆盖。
需要特别注意的局限包括:
- 它大量引用管理层表述,独立验证信息不多;
- 对竞争格局没有展开,比如华为、英伟达、Momenta、OEM 自研芯片的压力没有细拆;
- 对舱驾一体平台的商业化节奏、客户名单、收入贡献没有定量披露;
- 目标价依赖远期 EBITDA,短期业绩波动对股价情绪仍可能有很大影响。
所以这篇报告适合拿来理解“多头现在最想抓住什么”,但不适合单独作为投资结论。
8. 风险点
高盛列出的主要下行风险包括:
- 竞争加剧或汽车供应链价格压力超预期;
- 产品结构向 AD 升级的节奏低于预期;
- 客户扩张慢于预期;
- 地缘政治下的供应链风险。
如果结合当前行业环境,我认为还应额外关注两个延伸风险:
- 舱驾一体如果最终只体现为降本,而没有形成软件平台粘性,估值很难长期抬升;
- 如果 NOA 的大众化渗透速度低于市场乐观预期,量和价齐升的逻辑会同时受压。
9. 对个人研究最有价值的启发
这篇高盛报告的价值,不在于它比别家多知道多少,而在于它把地平线的多头逻辑提炼得很清楚:
NOA 渗透继续下沉;- 高阶 AD 芯片继续推 ASP;
Starry + KaKaClaw 打开舱驾一体平台叙事;- 利润拐点被市场提前贴现。
后续跟踪地平线时,可以把问题压缩成四个验证项:
- 主流车型和更低价位车型的 NOA 渗透是否真的持续上升;
- 高阶 AD 芯片占比是否继续提高;
KaKaClaw 和舱驾一体方案是否拿到明确客户和量产车型;- 财务上是否正在向
2027E 转正路径靠近。
10. 后续跟踪动作
- 跟踪公司后续财报或交流纪要中是否披露
Starry、KaKaClaw 的客户进展和 SOP 节奏。
- 跟踪主流价格带车型的城市 NOA 搭载率变化,验证“下沉”是否真的发生。
- 对比高盛、瑞银、摩根士丹利、Bernstein 对地平线
2026-2028 收入与盈利路径的差异,找出市场分歧真正落点。
- 单独观察舱驾一体逻辑最终体现为“降本卖点”还是“平台粘性”,这决定估值上限。
11. 来源与限制
已使用来源:
- 用户提供 PDF:
source_materials/高盛5月18日研报.pdf
- PDF 转换稿:
source_materials/pdf_full_text.md
限制和待验证点:
- PDF 第 3-7 页主要为披露、价格目标历史和评级定义。
- 报告未披露舱驾一体方案的明确客户名单、收入贡献和量产时间表。
- 报告披露 Goldman Sachs 过去 12 个月与 Horizon Robotics 存在投行业务关系,应将其观点作为单一输入而非最终结论。
---
layout: post
title: Momenta Global 2026-06-23 PHIP 详细解读
subtitle: Codex 个人助理沉淀
date: 2026-07-06 08:08:14 -0400
tags:
- 个人助理
- 读书笔记
- Momenta Global 2026-06-23 PHIP
---
来源:notes/books/Momenta Global 2026-06-23 PHIP/01_详细解读.md
Momenta Global 2026-06-23 PHIP 详细解读
来源:notes/books/Momenta Global 2026-06-23 PHIP/source_materials/pdf_full_text.md
原始文件:Momenta Global Limited 于 2026-06-23 发布的港股聆讯后资料集(PHIP)。
说明:本文是对招股书核心信息的中文结构化解读,不构成投资建议。重点是梳理业务模式、行业位置、财务拐点、核心风险和后续跟踪动作。
1. 核心结论
Momenta 这份招股书最值得关注的,不是“自动驾驶故事”本身,而是它已经把故事拆成了两条商业化路径:一条是面向整车厂的量产智能驾驶软件,一条是面向 Robotaxi 的自动驾驶运营。公司把这套模式概括为“一个飞轮,两条腿”。
如果只看叙事,Momenta 是一家押注 L4 的自动驾驶公司;但如果看收入结构,它当前真正支撑公司的是量产车解决方案,尤其是城市 NOA 软件的技术开发服务和量产后单车许可费。也就是说,这家公司现阶段更像“先靠量产车软件变现,再把数据、算法和现金流反哺更高级别自动驾驶”的平台型玩家,而不是单纯烧钱等 Robotaxi 放量。
这份 PHIP 释放出的积极信号主要有三点:
- 商业化已经明显跨过最早期阶段。2025 年收入达到
人民币 24.13 亿元,同比增长 82.1%,毛利率升至 71.6%。
- 定点和量产车型增长很快。到
2025-12-31,累计定点 170 款,累计正式量产车型 68 款;到 2026-02-28,累计定点进一步增至 180 款,安装量超过 73.3 万套。
- 亏损质量在改善。虽然 IFRS 口径净亏损仍大,但经调整亏损已从
2023 年的 10.93 亿元 收窄到 2025 年的 3.03 亿元。
但这份招股书也有几个不能忽视的约束:
- 公司仍未盈利,且研发投入极重,
2025 年研发开支达 18.69 亿元。
- 量产车业务集中度仍高,前五大客户在
2025 年贡献 62.6% 收入。
- Robotaxi 业务现在更多是未来期权,而不是利润中心;即使管理层不断强调海外和上海推进,当前收入贡献仍不重大。
- 账面“净负债”很大,但相当部分来自优先股按会计准则计入金融负债;上市完成后这部分会自动转股,因此要区分“会计负债压力”和“真实现金压力”。
2. 公司到底在卖什么
2.1 量产车解决方案是当下主业务
Momenta 当前最重要的业务,是给整车厂提供面向量产车的智能驾驶软件解决方案,重点放在城市 NOA。
它的收入模式分成两部分:
- 量产前技术开发服务:把方案适配、验证并集成到客户车型中。
- 量产后许可费:按搭载方案的车辆销量一次性收取单车许可费。
这意味着公司收入前期更像项目制,后期更像随车型放量而释放的 license 收入。这个结构解释了为什么 2025 年收入增速和毛利率同时大幅提升:不是单纯多接了项目,而是更多定点开始进入正式量产阶段。
2.2 Robotaxi 是第二条腿,不是当前主收入
招股书把另一块业务定义为“自动驾驶出租车服务解决方案”,实际就是 Robotaxi 及未来可能拓展到自动驾驶货运和卡车。
目前它的商业模式主要是和出行平台合作分成车费收入。招股书明确说,这部分在往绩记录期内对总收入不重大,仍处于早期变现阶段。
所以更准确的理解是:Momenta 现在不是靠 Robotaxi 养活自己,而是希望先用量产车业务积累数据、现金流、客户关系和工程能力,再去换取 L4 运营的长期机会。
3. 这家公司最关键的投资逻辑
3.1 “一个飞轮,两条腿”不是口号,而是商业结构
Momenta 的核心说法是:
- 量产车业务提供规模化部署、真实道路数据和当前收入。
- Robotaxi 业务提供更高级别自动驾驶的验证场景。
- 两边共用一套技术底座、数据体系、工具链和算法能力。
这个模型要成立,前提不是“公司会讲故事”,而是两条腿之间真的有复用关系。招股书给出的核心论据是:
- 大规模量产车会持续提供海量真实世界驾驶数据。
- 这些数据能提升模型训练效率,尤其是低频长尾场景。
- 主线平台和无图化路线能让能力在不同整车厂、不同地区、不同场景中复用。
如果这个逻辑成立,Momenta 的优势不是单点功能,而是“量产软件商业化 + 通往 L4 的数据飞轮”。
3.2 城市 NOA 是当前真正的战略支点
招股书反复强调,城市 NOA 是量产车商业化最重要的细分场景。
关键数据包括:
- 截至
2025-12-31,城市 NOA 安装量超过 65 万辆。
- 截至同日,城市 NOA 累计定点
155 款,其中 57 款已量产。
- 按截至
2026-02-28 过去 12 个月销量计,公司在全球独立城市 NOA 方案商中排名第一,份额 64.5%。
这说明 Momenta 当前真正要证明的不是“未来能否做 L4”,而是“能否持续守住城市 NOA 量产领先地位,并把定点转成 license 收入”。
4. 商业化进展比很多纯自动驾驶公司扎实
截至 2025-12-31,公司披露:
- 累计定点
170 款。
- 累计正式量产车型
68 款。
- 安装量超过
68 万辆。
- 已与
24 家全球领先整车厂建立合作关系。
截至 2026-02-28,又进一步披露:
- 累计定点增至
180 款。
- 安装量超过
73.3 万套。
- 新增与福特建立合作关系,使其覆盖的全球前十大整车厂数量增至
9 家。
这一组数字的重要性在于,它说明 Momenta 不只是有技术 demo,而是在持续拿项目、过 SOP、进量产,并且客户结构已经覆盖全球大型车企和中国头部车企。
5. 财务拐点在哪里
5.1 收入已经进入加速期
收入数据:
2023 年:7.43 亿元2024 年:13.25 亿元2025 年:24.13 亿元
同比增速:
2024 年:78.4%2025 年:82.1%
这说明公司还在高速放量阶段。最关键的不是增长本身,而是增长来源越来越偏向量产后许可费,而不是只有前端项目收入。
5.2 收入结构正在从“项目驱动”走向“量产放量”
收入结构变化非常关键:
2023 年技术开发服务占比 96.8%,许可服务占比 3.1%2024 年技术开发服务占比 77.9%,许可服务占比 22.1%2025 年技术开发服务占比 59.9%,许可服务占比 40.1%
这反映出更成熟的商业阶段。因为许可费本质上依赖量产车型出货,通常比单次开发项目更接近可复制的规模化收入。
5.3 毛利率改善非常明显
毛利率从 17.5% 提升到 49.0%,再到 71.6%。
这通常说明几件事同时发生:
- 软件许可收入占比提升;
- 前期平台投入开始被更大规模收入摊薄;
- 标准化复用能力在增强。
对投研来说,这比单纯看收入更重要,因为它意味着 Momenta 不是“收入大了亏得也更快”,而是出现了经营杠杆。
5.4 亏损仍大,但质量在改善
IFRS 口径净亏损:
2023 年:25.70 亿元2024 年:32.06 亿元2025 年:34.58 亿元
经调整亏损:
2023 年:10.93 亿元2024 年:9.59 亿元2025 年:3.03 亿元
表面上看,净亏损还在扩大;但如果拆开看,核心原因之一是优先股及其他金融负债公允价值变动,这一项在 2025 年达到 28.43 亿元。这是典型的上市前融资结构带来的会计波动,不完全等于经营质量恶化。
所以更值得跟踪的是经调整亏损、经营现金流和研发效率,而不是只盯着 IFRS 净亏损 headline。
5.5 经营现金流也在改善
经营活动所用现金净额:
2023 年:-10.69 亿元2024 年:-8.36 亿元2025 年:-2.81 亿元
这说明公司虽然仍在烧钱,但单位收入对应的现金消耗已经明显下降。对这种尚未盈利的科技公司来说,这是非常重要的二阶信号。
6. 需要怎么理解它的“高负债”
招股书披露截至 2025-12-31:
- 流动负债净额
189.61 亿元
- 净负债
178.91 亿元
这组数字如果不拆解,会显得非常吓人。但招股书也明确说,上市完成后优先股将自动转换为普通股,不再作为负债列示,净负债状态将转为净资产状态。
因此这里要分清两层:
- 会计口径的负债高,主要受可转换优先股影响;
- 真实经营层面的现金压力,要看现金、经营现金流、融资能力以及未来资本开支需求。
截至 2025-12-31,年末现金及现金等价物为 13.07 亿元。这不算特别宽裕,但结合公司称“可满足未来 12 个月营运资金需求”,说明短期流动性尚可,长期则仍依赖继续放量和资本市场支持。
7. 风险点不能忽略
7.1 还没有真正实现盈利闭环
公司现在最容易被市场质疑的点仍然是:高增长是否足以覆盖持续高研发投入。2025 年研发开支 18.69 亿元,约占收入 77.5%。如果行业竞争加剧、定点转量产放缓,盈利拐点可能继续后移。
7.2 客户集中度仍偏高
2025 年前五大客户占收入 62.6%,最大客户占 21.6%。这意味着少数客户的项目节奏、车型销量、合作深度变化,都可能显著影响收入确认和市场预期。
7.3 技术开发服务存在非经常性波动
招股书专门提示,技术开发服务通常带有项目属性、定制属性和非经常性特征。这意味着即使长期趋势向上,季度和年度收入仍可能有较强波动。
7.4 Robotaxi 监管和商业化节奏仍有不确定性
公司在“近期监管发展”里专门回应了中国自动驾驶许可放缓的媒体报道,强调当前对量产车业务无重大直接影响。这个判断短期合理,因为 Robotaxi 收入占比不大;但如果未来市场开始重新给 L4 业务估值,这部分监管节奏仍会影响第二条腿的想象空间。
7.5 自动驾驶行业是强竞争行业
Momenta 当前占优,不代表以后能稳坐龙头。城市 NOA 是快速变化的赛道,车企自研、华为体系、海外 Tier 1、芯片和软件生态变化,都会改写市场结构。
8. 这份招股书最值得盯的验证点
后续跟踪 Momenta,建议重点看下面几项,而不是只看“上市首日涨跌”:
- 累计定点增速是否继续提升,尤其是新增高价值车型和国际客户。
- 正式量产车型数能否继续增长,定点到量产的转化是否顺畅。
- 许可服务收入占比能否继续提升。
- 毛利率是否维持高位,还是因为竞争而回落。
- 研发费用率是否随着规模扩大而下降。
- 经营现金流能否进一步逼近盈亏平衡。
- Robotaxi 海外落地是否真能形成新增收入,而不只是 PR 叙事。
- 与头部车企合作是否深化到 L3 或全球化项目。
9. 对个人研究最有价值的启发
这份 PHIP 最大的启发,是看自动驾驶公司时不能只问“技术牛不牛”,而要问四个更硬的问题:
- 现在靠什么挣钱。
- 收入是项目制还是可复制的规模化许可。
- 数据飞轮到底是叙事还是真正建立在量产部署之上。
- L4 业务是当下利润中心,还是长期期权。
放到 Momenta 身上,当前更合理的理解是:
- 它不是纯 Robotaxi 公司。
- 它本质上先是一家量产智能驾驶软件公司。
- 它试图用量产软件商业化去支撑更高级别自动驾驶。
- 它已经证明“能卖出去”,但还没有完全证明“能稳定赚到钱”。
10. 下一步动作
- 继续跟踪 Momenta 后续正式招股书,重点比较估值区间、募资用途细化和基石投资者名单。
- 对比同赛道可比公司,尤其是地平线、黑芝麻智能以及全球自动驾驶软件/Robotaxi 玩家,拆解商业模式差异。
- 单独整理 Momenta 的客户版图和车型定点,评估其量产兑现质量。
- 跟踪
2026 年上市后首份中报或季节性经营更新,验证许可收入和经营现金流改善是否延续。
---
layout: post
title: 2026 年 6 月回顾
subtitle: Codex 个人助理沉淀
date: 2026-07-06 03:46:07 -0400
tags:
- 个人助理
- 项目
- monthly_reviews
---
来源:notes/projects/monthly_reviews/01_2026年06月回顾.md
2026 年 6 月回顾
结论
2026 年 6 月,你的核心特征不是“做得少”,而是输出密度很高,但注意力和决策系统还没有完全跟上产出速度。这个月已经形成了三条明显主线:一是工作上从需求、PRD、开发到接口优化都有推进,但 review 和交付闭环偏弱;二是投资上高度聚焦地平线,同时开始更清楚地意识到“基本面研究”和“交易纪律”是两套不能混用的系统;三是内容和知识沉淀明显提速,已经从单篇笔记转向项目化、系列化和可复用流程化。
如果用一句话概括 6 月:这是一个“认知产出快速扩张,但执行闭环还需要收紧”的月份。
本月三条主线
1. 工作主线:推进存在,但闭环不够硬
- 6 月上旬到中旬,你持续围绕技术方案、PRD、工单和汇率重构推进工作。
- 6 月 4 日和 6 月 8 日,多次记录“写技术方案”,说明你已经意识到高认知任务不能靠临场硬切,需要先加载上下文再进入产出。
- 6 月 12 日开始开发汇率重构,6 月 15 日完成汇率时间配置代码开发,6 月 16 日又处理了同步问题并优化接口,说明实质工作已经往前走了。
- 但 6 月 15 日和 6 月 16 日连续出现“还没有仔细 review 代码”的记录,这说明你的问题不是不会推进,而是容易把“代码写完”误当成“交付完成”。
本月工作侧最关键的复盘点不是执行力,而是闭环质量。你已经能启动、能推进、也能解决局部问题,但 review、验证和交付定义还不够前置。
2. 投资主线:研究越来越深,但交易纪律和叙事开始冲突
- 6 月大量记录围绕地平线展开,节点包括跌破 5 元、累计跌约 50%、接近破发、计划集中账户专门做地平线交易等。
- 6 月 16 日到 6 月 18 日的记录尤其关键,你已经明确意识到:上涨时用趋势信号止盈、下跌时用基本面利好硬抗,是一套会把自己困住的混合系统。
- 6 月 22 日你清仓了新易盛和中微公司,这说明你并非完全没有执行动作,而是在主动收缩非核心仓位。
- 你对地平线的研究已经不只是情绪关注,而是延伸到市占率、新产品、吉利出海、比亚迪自研芯片与 IP 关系、研报解读、股东大会逐字稿等一整套跟踪体系。
这个月投资上的真正进步,不是判断对错,而是你第一次比较清楚地看到了自己容易在哪个环节把“研究”变成“硬抗理由”。
3. 内容主线:已经从零散记录进入系统化沉淀
- 6 月是明显的高产月,完成了多篇正式笔记、项目说明、研报解读、书籍解读和公众号版内容。
- 主题上主要集中在四块:投资与地平线、智能汽车产业、时间/注意力管理、个人助理系统本身。
- 你不再只是“写一篇”,而是开始把一次输入沉淀成项目目录、源材料、结构化数据、生成脚本、正式笔记和博客发布链路。
- 6 月 11 日把域控芯片榜单整理成可复跑项目,6 月 10 日把长音频转写和博客同步流程系统化,说明你已经开始把临时工作转成复用资产。
这是 6 月最确定的优势项。内容生产不只是多,而是越来越像一个可积累、可检索、可迁移的系统。
本月代表性产出
工作与系统
- 汇率重构相关推进:PRD、技术方案、开发、时间配置、同步问题修复、接口优化。
- 个人助理与发布系统:飞书多维表格同步方案、同步 SOP、博客同步流程、长音频转写与博客同步流程、flomo 整合方案。
投资与行业研究
- 地平线机器人 2026-06-10 股东周年大会逐字稿与公众号版解读。
- Bernstein、Morgan Stanley、UBS 等地平线相关研报解读。
- 大众在中国的合资版图梳理、卓驭科技研究、百度自动驾驶旧将六年后复盘。
方法论与自我管理
主动专注地处理事情时间使用方式决定人生结构趋势交易与基本面投资的信号错配微信作为信息源的注意力边界肉身梭哈与注意力梭哈
本月最值得保留的几个判断
- 高认知任务不能直接开干,先做上下文加载,再进入产出。
- 代码完成不等于交付完成,review 和验证必须是显式步骤。
- 投资研究和交易纪律不能混用,否则上涨拿不住、下跌扛过头。
- 时间使用方式如果不变,人生结构就很难改变。
- 一次性工作尽量沉淀成可复跑项目,而不是只交付一次结果。
本月暴露出来的问题
- 工作闭环偏弱。方案、开发、接口优化都有推进,但“认真 review”和“验证完成”没有形成固定收尾动作。
- 投资集中度在上升,但仓位纪律还没有被写成明确规则。尤其遇到心理价位和连续下跌时,容易被价格牵着走。
- 信息输入边界还不够稳定。你已经意识到股价、群聊、公众号、小红书需要限时处理,但还没有完全固化成执行规则。
- 生活与关系记录偏少,工作、投资、写作很多,但恢复、关系维护和日常秩序的系统化记录还比较薄。
7 月第一优先级
- 给工作流补闭环:把
review -> 验证 -> 交付确认 写成固定模板,避免“写完即结束”。
- 给投资补纪律:把地平线相关仓位上限、再评估条件、减仓/加仓触发器单独写成规则。
- 给时间补结构:继续追踪早起,并记录早起后的睡眠、专注时段和输入边界是否同步改善。
- 给内容补筛选:保留高质量高杠杆主题,减少为了记录而记录,让产出继续服务你的判断系统。
下一步动作
- 补一份“地平线交易纪律清单”正式笔记。
- 完成“汇率时间配置代码”和“同步问题修复”的一次认真 review。
- 做一次最近 7 天时间流向复盘,验证早起是否带来真实结构变化。
---
layout: post
title: 域控芯片装机量排名图项目说明
subtitle: Codex 个人助理沉淀
date: 2026-07-01 19:25:48 -0400
tags:
- 个人助理
- 项目
- domain_chip_installation_rankings
---
来源:notes/projects/domain_chip_installation_rankings/01_域控芯片装机量排名图项目说明.md
域控芯片装机量排名图项目说明
项目目标
把用户提供的 NE时代域控芯片装机量榜单截图沉淀为一个可复用项目:保存结构化数据、生成脚本和图表成品。下次有新月份数据时,可以直接在同一项目里追加数据并重新生成图。
当前数据范围
- 2025年1-12月:单月榜单,已生成全年月度排名变化图。
- 2026年1-2月:两个月合计榜单。
- 2026年3月:单月榜单。
- 2026年4月:单月榜单,使用用户后续更正的 4 月原图。
- 2026年5月:单月榜单,本次新增。
核心字段:
目录结构
data/domain_chip_source_data.csv:从原图提取的标准源数据,包含装机量、市占率和排名。data/domain_chip_2025_source_data.csv:2025年1-12月从原图提取的标准源数据。data/domain_chip_rank_table_chart_data.csv:排名表格图使用的数据。data/domain_chip_line_chart_data.csv:折线图使用的数据。scripts/generate_2025_rank_bump_chart.js:生成 2025 全年月度排名连线图。scripts/generate_rank_table_chart.js:生成“排名表格图 + 公司连线”的主脚本。scripts/generate_line_chart.js:生成折线图的备份脚本。outputs/domain_chip_2025_rank_bump_chart.png:2025 全年月度排名连线图。outputs/domain_chip_2025_rank_bump_chart.svg:2025 全年月度排名连线图的矢量版。outputs/domain_chip_rank_table_chart.png:当前最终交付图。outputs/domain_chip_rank_table_chart.svg:当前最终交付图的矢量版。outputs/domain_chip_line_chart.png:早期折线图版本。outputs/domain_chip_line_chart.svg:早期折线图矢量版。source_images/README.md:原图归档说明。
当前最终图表
2025 全年月度图
2025 年 1-12 月数据采用“月份横轴 + 排名纵轴”的 bump chart:
- 横轴是 2025 年 1-12 月。
- 纵轴是每月排名 1-8。
- 每家公司固定一种颜色。
- 仅在连续上榜月份之间连线,缺席月份不强行连接。
- 每个点旁边显示公司、装机量和市占率。
当前输出文件:
outputs/domain_chip_2025_rank_bump_chart.png
outputs/domain_chip_2025_rank_bump_chart.svg
2026 阶段图
最终采用“排名表格图 + 公司连线”的形式:
- 每个时间段是一列表格,按装机量降序排列。
- 每家公司固定一种颜色。
- 公司在不同时间段之间用同色曲线连接,表现排名变化。
- 每行同时显示装机量和市占率。
当前输出文件:
outputs/domain_chip_rank_table_chart.png
outputs/domain_chip_rank_table_chart.svg
复用步骤
下次用户提供新月份图片后:
- 将新图保存到
source_images/。
- 从图中提取公司、装机量、市占率和排名,追加到
data/domain_chip_source_data.csv。
- 更新
scripts/generate_rank_table_chart.js:
- 在
periods 中增加新月份。
- 在
data 中为每家公司追加 values 和 shares。
- 如果出现新公司,为该公司新增一行并分配颜色。
- 在项目目录运行:
node scripts/generate_rank_table_chart.js
rsvg-convert -w 1700 -h 1120 outputs/domain_chip_rank_table_chart.svg -o outputs/domain_chip_rank_table_chart.png
如果是追加 2025 或类似“全年月度图”,运行:
node scripts/generate_2025_rank_bump_chart.js
rsvg-convert -w 4600 -h 1480 outputs/domain_chip_2025_rank_bump_chart.svg -o outputs/domain_chip_2025_rank_bump_chart.png
- 检查 PNG 排版后,用飞书机器人发送:
lark-cli im +messages-send --as bot --user-id ou_a0558e2fc4190751fee80e93d0895616 --image notes/projects/domain_chip_installation_rankings/outputs/domain_chip_rank_table_chart.png --format json
本次注意事项
- 最初 4 月图片口径错误,已按用户更正后的 4 月图替换。
- 当前环境无法直接复制对话图片附件到本地文件,因此本项目保存了结构化源数据,并在
source_images/README.md 记录原图来源和后续归档方式。
- 数据来源是用户提供截图,未额外做外部核验。
下一步动作
- 新月份数据到来时,优先补齐
source_images/ 原图文件,再追加结构化数据。
- 如果月份继续增加,图表宽度需要随列数扩展,或改为分页/横向长图。
---
layout: post
title: Source Images
subtitle: Codex 个人助理沉淀
date: 2026-07-01 19:25:48 -0400
tags:
- 个人助理
- 项目
- domain_chip_installation_rankings
---
来源:notes/projects/domain_chip_installation_rankings/source_images/README.md
Source Images
本项目原图来自 2026-06-11 当前对话中用户上传的 NE时代榜单截图:
- 2026年1-2月域控芯片装机量
- 2026年3月域控芯片装机量
- 2026年4月域控芯片装机量(用户后续更正版本)
- 2026年5月域控芯片装机量
当前运行环境没有为对话图片附件暴露可复制的本地文件路径,因此本目录暂未保存原图二进制文件。已保存的可复用源数据见:
../data/domain_chip_source_data.csv../data/domain_chip_rank_table_chart_data.csv
下次有新图时,优先把原图文件保存到本目录,命名建议:
2026-01-02_domain_chip_installation.png2026-03_domain_chip_installation.png2026-04_domain_chip_installation.png2026-05_domain_chip_installation.png
然后更新 ../data/domain_chip_source_data.csv 与 ../scripts/generate_rank_table_chart.js 中的 periods 和 data。
---
layout: post
title: 股海渡梦雪球发言与持仓态度侧写
subtitle: Codex 个人助理沉淀
date: 2026-06-24 05:18:11 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/xueqiu_investor_profiles/01_股海渡梦雪球发言与持仓态度侧写.md
股海渡梦雪球发言与持仓态度侧写
整理时间:2026-06-24
资料范围:雪球公开可检索页面与搜索片段。雪球完整时间线可能需要登录或受反爬限制,因此本文是“公开发言侧写”,不是完整持仓审计,也不构成投资建议。
核心结论
“股海渡梦”是一个交易感很强、情绪表达直接的港股科技股投资者。公开发言里最核心的主线是黑芝麻智能,辅助观察和交易地平线机器人,同时阶段性出现过狮腾控股、马克数字科技、融创中国等高波动港股。
他的长期叙事不是传统低估值投资,而是押注港股小市值科技公司的产业催化:自动驾驶芯片、舱驾一体、机器人业务、主机厂合作、量产节奏、与地平线的估值对比。情绪上则在“坚定深耕黑芝麻”和“错失行情、亏损煎熬、想切换到地平线”之间反复摇摆。
如果用一句话概括:他不是单纯的价值投资者,更像是把基本面叙事、产业催化和短线交易弹性混在一起的港股成长股交易者。
公开资料里的账号画像
雪球公开主页显示,“股海渡梦”的简介是“以交易为生”,IP 属地北京,主页资料显示关注、粉丝、自选和组合等基础信息。公开发言高度集中在港股智能驾驶产业链,尤其是黑芝麻智能与地平线机器人。
这个账号有两个明显特征:
第一,表达很个人化。他不太像机构研究员那样只写结论和数据,而是经常把自己的操作、后悔、亏损、麻木、煎熬一起写出来。
第二,交易色彩很重。他会讨论基本面和产业进展,但也会频繁评价买点、卖点、反弹、清仓、加仓、错过涨幅等交易问题。
持仓与关注主线
黑芝麻智能:最核心的长期押注
公开发言显示,黑芝麻智能是他最核心、最长期、情绪投入也最高的标的。
2025 年 5 月,他已经在讨论黑芝麻 A2000 的节奏,关注“年底量产、2026 年初批量上车”这类节点。这说明他并不是短期看图买入,而是围绕公司产品周期建立了中期预期。
2025 年 12 月,他提到自己把 7.35 港元买入的地平线机器人全部卖出,并说“继续深耕黑芝麻智能”。这句话很关键,说明在黑芝麻和地平线之间,他当时选择把主要研究和资金重心放在黑芝麻上。
到 2026 年 6 月,他仍然在为黑芝麻估值辩护。他认为不能静态看当下低毛利率,因为当前收入主要来自老产品,真正要看的是 A2000、机器人业务、小体量高增长,以及未来边际变化。
这条主线可以概括为:黑芝麻不是他的短线票,而是他的“主战场”。他不断用 A2000、舱驾一体、机器人、比亚迪、地平线估值对比这些线索,来解释为什么黑芝麻值得继续看。
地平线机器人:重要对标,也是一只交易票
地平线机器人在他的发言里地位也很高,但性质和黑芝麻不同。
他认可地平线的交易机会,也多次参与。但公开发言里,他说自己买过很多次地平线,却“一直没重仓”,原因是地平线的不确定性比较多。这说明他对地平线不是完全不看好,而是把它当作弹性和对标对象,而不是情绪上最重的长期押注。
2026 年 4 月,他给过比较典型的交易策略:地平线跌破 7 港元可以建仓,越跌越买,6 港元以下会有反弹,但反弹差不多就出来。这不是长期死拿的语言,而是波段交易语言。
地平线对他的作用有三层:
第一,是黑芝麻估值的参照物。黑芝麻该不该涨,经常需要拿地平线市值、业务位置、芯片进展来比较。
第二,是资金切换对象。黑芝麻走弱时,他会动念切换到地平线。
第三,是港股高弹性交易工具。他对地平线的价格区间和反弹更敏感,而不是只讲长期基本面。
其他港股:高波动机会与学费
除黑芝麻和地平线之外,他还提到过狮腾控股、马克数字科技、融创中国等。
2026 年 1 月,他说如果港股前几天也这么活跃,自己就不会把狮腾控股出了。这是典型的卖飞后悔表达。
他还提到自己在马克数字科技亏过 150 万。这个数字很重,说明他不是低波动、小仓位体验港股,而是真正承受过较大的港股波动损失。
2026 年 5 月,他又提到融创中国 1 块多买入、涨到 5 块但没做好。这个表述说明他对自己“选到过大机会,但没有把收益做好”的遗憾很深。
这些标的共同构成他的港股经验:他并不是只看一个公司,而是在港股高波动市场里寻找弹性,但多次出现“方向看到了,操作没做好”的挫败感。
投资观点
1. 看重产业催化,而不是静态财务
他的核心观点不是“现在利润好、估值低”,而是“未来产品周期和产业节点会带来重估”。
黑芝麻的 A2000、舱驾一体、机器人业务,以及地平线的 HSD、芯片和主机厂合作,都是这种思路下的关键变量。
这类投资方法的优势是,如果产业节奏兑现,小市值公司的弹性会很大。风险是,在兑现前,股价可能长期被情绪、流动性、收入确认、毛利率和市场风格压制。
2. 喜欢用对标估值寻找错杀
他经常把黑芝麻和地平线放在一起比较。对他来说,地平线不只是另一家公司,也是黑芝麻估值是否合理的锚。
如果地平线能给高市值,而黑芝麻有 A2000、机器人和高增长期权,那么黑芝麻就不应该被市场长期低估。这是他反复维护黑芝麻叙事的核心逻辑。
3. 交易纪律和基本面信仰经常冲突
他的发言里有很多“卖了”“清仓”“继续深耕”“越跌越买”“反弹出来”之类的词。这说明他不是纯粹长期持有者。
但同时,他又会用基本面叙事支撑持有,比如产品量产、业务切换、机器人期权、公司体量小、毛利率未来改善等。
这就形成一个典型冲突:上涨时容易想交易止盈,下跌时又会用基本面逻辑说服自己坚持。这个冲突也是他情绪波动的来源。
态度和情绪变化
2025 年中到年底:对黑芝麻建立主线,看产品周期
2025 年中,他已经围绕黑芝麻 A2000 建立预期,关注年底量产和 2026 年初上车。
到 2025 年 12 月,他卖出地平线,选择“继续深耕黑芝麻智能”。这一阶段的情绪基调是偏乐观、偏坚定的:他相信黑芝麻还没被市场充分理解,也相信产业节点会逐渐兑现。
但乐观里已经有交易焦虑。卖出地平线之后,后续涨跌会让他产生“亏大了”“赚差不多要跑”之类的反馈,说明他并不是完全能屏蔽短期价格。
2026 年 1 月:机会成本焦虑明显加重
2026 年 1 月,他开始更频繁表达“错过”的情绪。
他说为了黑芝麻错过很多,今年行情好但自己业绩差。这是很典型的机会成本痛苦:持有一个长期逻辑未兑现的标的时,其他票上涨会让人怀疑自己是否押错了节奏。
同一阶段,他还提到如果港股前几天也这么活跃,狮腾控股就不会出。这说明他的注意力不只是黑芝麻基本面,也在被市场短线赚钱效应牵动。
这个阶段的情绪关键词是:后悔、焦躁、对比、机会成本。
2026 年 2 月:出现强烈摇摆
2026 年 2 月,他有过一次明显的态度摇摆:公开说黑芝麻当天清仓,开始打算买地平线,不过等 3 块再买。
这条发言不一定能完全等同于真实最终持仓,因为社交平台上可能存在情绪化表达或盘中操作变化。但它至少说明,当时他对黑芝麻短期走势非常失望,并且有过把主线切到地平线的念头。
这个阶段的情绪关键词是:失望、切换、短线防御。
2026 年 3-4 月:重新回到黑芝麻主线,但地平线作为波段工具
3 月底,他又说要“大举加仓”黑芝麻,等年报出来上涨。这说明黑芝麻主线并没有被放弃。
4 月,他对地平线的表达更像交易计划:跌破 7 港元可建仓,越跌越买,6 港元以下会反弹,反弹差不多就出来。
这个阶段的特点是:主线回到黑芝麻,但同时承认地平线有交易机会。情绪从 2 月的失望切换为“继续赌兑现”,但交易上仍然很灵活。
2026 年 5-6 月:煎熬、麻木,但仍在维护黑芝麻叙事
2026 年 5 月,他说自己清仓 A 股、满仓港股,作为港股新手交了很多学费,也说自己已经“死心塌地”留在港股。这个表述非常有信息量:它既像一种认错,也像一种重新押注。
同一阶段,他出现“麻木”“熬得麻麻的”之类表达,说明港股波动和长期不兑现已经对情绪造成明显消耗。
2026 年 6 月,他仍然围绕黑芝麻基本面和估值争辩,强调不能静态看毛利率,要看 A2000 和机器人业务;但也承认黑芝麻是开户以来亏损最多的一只票,主要靠加仓降低成本。
这个阶段最准确的描述是:煎熬但没放弃。不是轻松看多,而是在亏损和不确定中继续为主线找证据。
对这个账号的阅读方式
读“股海渡梦”的发言,不能只看他说看多还是看空,更要看他在哪个情绪位置说话。
当他说黑芝麻有机会时,背后是产品周期和估值对标逻辑;当他说清仓或切地平线时,背后往往是短期价格、机会成本和心理压力;当他说麻木或交学费时,说明他已经在港股高波动里付出过真实代价。
因此,读他的发言可以重点看三件事:
- 他有没有拿出新的产业证据,比如 A2000 量产、客户、订单、机器人业务进展。
- 他是不是在价格下跌后用旧逻辑反复自我确认。
- 他的仓位表述和情绪表述是否开始超过事实信息本身。
下一步跟踪动作
- 继续跟踪黑芝麻智能 A2000 量产、客户、上车节奏和毛利率变化,判断“未来改善”是否进入财务报表。
- 对比地平线机器人与黑芝麻智能的收入结构、毛利率、研发投入、现金储备和客户确定性,避免只用市值做粗糙对标。
- 记录“股海渡梦”后续是否继续持有黑芝麻,还是切换到地平线或其他港股弹性票。
- 把他的发言当作市场情绪样本,而不是直接当作操作依据。
公开来源
- 雪球主页:“股海渡梦”账号公开资料。https://www.xueqiu.com/2575637181
- 2025-05:黑芝麻 A2000 量产与上车预期。https://xueqiu.com/2575637181/335439131
- 2025-12:卖出地平线,继续深耕黑芝麻智能。https://xueqiu.com/2575637181/364962516
- 2026-01:港股活跃、狮腾控股卖出后的后悔,以及马克数字科技亏损表述。https://xueqiu.com/3240702838/370938039/392703362
- 2026-01:为了黑芝麻错过其他机会、今年行情好但业绩差。https://xueqiu.com/2575637181/370902439
- 2026-02:黑芝麻清仓、考虑买地平线的情绪化表述。https://xueqiu.com/2575637181/374944927/396072015
- 2026-03:大举加仓黑芝麻、等待年报上涨。https://xueqiu.com/2575637181/381785632
- 2026-04:地平线交易策略,跌破 7 建仓、6 以下反弹。https://xueqiu.com/2369775149/386241124/404624702
- 2026-04:多次买地平线但未重仓。https://xueqiu.com/2575637181/384061701
- 2026-05:清仓 A 股、满仓港股、港股新手交学费等情绪表达。https://www.xueqiu.com/8824683307/388647453/406507888
- 2026-06:黑芝麻估值、毛利率、A2000 与机器人业务讨论。https://www.xueqiu.com/2575637181/393313584/410356087
- 2026-06:黑芝麻为亏损最多标的、靠加仓降低成本的表述。https://www.xueqiu.com/2575637181/395064084
---
layout: post
title: 大众在中国为什么这么复杂:一汽大众、上汽大众、大众安徽到底怎么分
subtitle: Codex 个人助理沉淀
date: 2026-06-23 23:51:23 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/volkswagen_china/01_大众在中国的合资版图梳理.md
大众在中国为什么这么复杂:一汽大众、上汽大众、大众安徽到底怎么分
截至 2026-06-24,大众在中国不是一个单一公司,而是一组围绕不同历史阶段、不同地方伙伴、不同品牌和不同技术路线形成的公司网络。理解它的关键不是先记公司名,而是先分清三层关系:
- 大众集团中国是集团在中国的统筹和投资平台;
- 上汽大众、一汽-大众、大众安徽是三条最核心的整车合资生产线;
- 奥迪、进口大众、小鹏合作、100%TechCo 等是叠加在三条主线之外的品牌、进口和技术协作体系。
如果一句话概括:上汽大众是一条更早进入中国、以上海为基地、覆盖大众和斯柯达等品牌的合资线;一汽-大众是以长春为起点、覆盖大众、奥迪、捷达等品牌的合资线;大众安徽则是大众为新能源和智能电动车时代在合肥重新搭的一条更高控制权平台。
关键股权口径
根据大众集团中国公开资料,几个关键主体的股权口径可以这样看:
| 主体 |
主要股东 |
直观理解 |
| 上汽大众 SAIC VOLKSWAGEN |
上汽 50%;大众汽车股份公司 40%(含斯柯达、奥迪等集团内权益);大众中国投资 10% |
上汽与大众长期对半合作的上海系平台,大众侧权益通过集团内主体分拆持有 |
| 一汽-大众 FAW-Volkswagen |
一汽 60%;大众汽车股份公司 25%;大众中国投资 10%;奥迪 5% |
一汽控股,德国大众和奥迪共同参与,是大众和奥迪在一汽体系的核心平台 |
| 大众安徽 Volkswagen Anhui |
大众中国投资 75%;安徽江淮汽车集团 25% |
大众控股的合肥新能源平台,控制权明显高于传统南北大众 |
| 奥迪一汽新能源汽车 Audi FAW NEV |
奥迪 55%;一汽 40%;大众中国投资 5% |
奥迪控股的高端纯电平台,和传统一汽-大众奥迪不是同一个法律主体 |
一张简化关系图
Volkswagen AG / Volkswagen Group
|
|-- Volkswagen Group China / Volkswagen (China) Investment
|
|-- 上汽大众 SAIC Volkswagen
| 伙伴:上汽集团
| 定位:上海系合资生产体系,传统燃油车 + 新能源转型
| 代表:大众品牌、斯柯达品牌、SAIC 奥迪相关项目
|
|-- 一汽-大众 FAW-Volkswagen
| 伙伴:中国一汽
| 定位:长春系合资生产体系,覆盖大众、奥迪、捷达
| 代表:一汽-大众大众品牌、一汽奥迪、捷达品牌
|
|-- 大众安徽 Volkswagen Anhui
| 伙伴:安徽江淮汽车集团 / JAC
| 定位:合肥新能源与智能电动车平台
| 代表:ID. UNYX 与后续面向中国开发的电动车
|
|-- 奥迪一汽新能源汽车 Audi FAW NEV
| 伙伴:中国一汽
| 定位:PPE 平台高端纯电奥迪生产基地
|
|-- 小鹏汽车合作
| 性质:战略投资 + 联合开发,不是传统整车合资公司
| 定位:补齐中国智能电动车软件、电子电气架构和本土开发速度
先分清“大众集团中国”和“合资车企”
大众集团中国不是消费者买车时常说的“一汽大众”或“上汽大众”。它更像大众集团在中国的总部和投资/协调平台,负责集团层面的战略、投资、研发资源协调、品牌管理和合资关系。
消费者真正接触到的国产大众车,通常来自几类主体:
- 上汽大众:上海大众体系,历史最早。
- 一汽-大众:长春一汽体系,包含大众、奥迪和捷达。
- 大众安徽:合肥新能源体系,承担大众在中国电动化转型的一部分新试验。
- 奥迪一汽新能源汽车:奥迪电动化专用体系,和一汽-大众奥迪有关系,但法律主体和产品平台要分开看。
- 进口大众 / 进口奥迪 / 进口保时捷等:由集团进口销售体系处理,不等同于国产合资公司。
所以“大众在中国”复杂,是因为它不是“一个品牌 + 一个工厂”,而是“集团总部 + 多个合资公司 + 多个品牌 + 多套平台 + 新旧技术路线并行”。
上汽大众:最早的上海合资线
上汽大众的前身是上海大众,成立于 1984 年,是大众进入中国乘用车市场最早、也最具历史象征意义的合资公司之一。它的核心伙伴是上汽集团,基地在上海安亭,并逐步扩展到南京、仪征、宁波、长沙、乌鲁木齐等生产体系。
上汽大众早期最典型的产品是桑塔纳。它不仅是一款车,更是大众在中国建立品牌认知、供应链、经销商网络和本地制造能力的入口。后来帕萨特、途观、朗逸等车型,让上汽大众长期覆盖家庭轿车、SUV 和主流合资车市场。
从品牌上看,上汽大众主要包括:
- 大众品牌:朗逸、帕萨特、途观等主流车型。
- 斯柯达品牌:曾经承担大众集团在中国的第二主流合资品牌角色,但近年存在明显边缘化压力。
- SAIC 奥迪项目:奥迪与上汽合作推出的新产品和销售模式,和传统“一汽奥迪”并不是同一条线。
上汽大众的优势是历史深、渠道强、上海和长三角供应链基础好;压力是传统合资燃油车红利变弱后,需要在新能源、智能座舱、智能驾驶和中国消费者偏好上补速度。
2024 年,大众与上汽宣布把合资协议延长到 2040 年。这说明上汽大众不会因为电动化压力立刻退出历史舞台,而是继续作为大众在中国的重要基本盘之一。但它的角色正在从“合资车销量支柱”转向“燃油车现金流 + 新能源转型平台”。
一汽-大众:长春系,大众与奥迪的核心国产平台
一汽-大众成立于 1991 年,核心伙伴是中国一汽,总部和起点在长春。它和上汽大众最大的区别,不只是地方伙伴不同,更重要的是它承载了奥迪在中国长期国产化的主线。
一汽-大众大致可以拆成三块理解:
- 一汽-大众大众品牌:速腾、迈腾、探岳等主流车型。
- 一汽奥迪:奥迪在中国最核心、历史最深的国产销售与生产体系。
- 捷达品牌:从一款车独立出来的入门合资品牌,主要覆盖更低价格带。
一汽-大众的历史意义在于,它是大众集团在中国做“多品牌分层”的关键平台:大众品牌覆盖主流中高端家庭市场,奥迪覆盖豪华车市场,捷达尝试下探到更低价格带。
相比上汽大众,一汽-大众更容易和“奥迪国产”绑定在一起理解。很多人说“奥迪在中国”,默认想到的是一汽奥迪,而不是上汽奥迪或进口奥迪。这种先发优势让一汽-大众长期在豪华车国产化、本地供应链和经销商网络上积累很深。
但到了新能源时代,一汽-大众也面对两类压力:
- 大众品牌的燃油车主力车型要守住基本盘,同时不能被自主品牌插混和纯电车型持续挤压。
- 奥迪品牌要从燃油豪华车强势地位,切到智能电动豪华车竞争,而这个赛道里中国消费者对智能化、座舱和辅助驾驶的要求明显提高。
因此一汽体系里又出现了新的奥迪一汽新能源汽车公司。
奥迪一汽新能源汽车:不要和一汽-大众奥迪混为一谈
奥迪一汽新能源汽车有限公司是为了高端纯电奥迪在中国本地化而设立的新主体,生产基地在长春,重点围绕 PPE 平台产品展开。它和一汽-大众奥迪在品牌上相连,但在公司主体、平台任务和新能源定位上需要分开看。
可以这样理解:
- 一汽-大众奥迪:奥迪在中国长期的国产燃油车和部分新能源车基本盘。
- 奥迪一汽新能源汽车:面向下一代高端纯电平台的新生产和电动化主体。
这反映出大众集团在中国的一个典型做法:不完全推倒旧合资体系,而是在旧体系旁边再搭新的电动化主体。这样做的好处是能保留原有销量、渠道和供应链,坏处是组织结构更复杂,品牌和产品线更容易让外部观察者混淆。
大众安徽:合肥新能源线,是大众在中国的新试验田
大众安徽的前身可以追溯到江淮大众。大众后来提高持股比例,使其成为大众在中国更具控制权的新能源合资平台。它位于合肥,和大众集团在合肥建设的研发、采购、软件与智能电动车能力高度相关。
大众安徽和上汽大众、一汽-大众最大的不同在于:它不是燃油车时代形成的传统合资主力,而是为新能源时代重新布局的平台。
它承担几个任务:
- 更快开发面向中国市场的电动车。
- 承接大众在合肥的本地研发、采购和软件协同。
- 让大众在中国拥有一个更接近“本土新势力节奏”的组织实验场。
- 和大众中国科技公司 100%TechCo、小鹏合作等形成技术组合。
ID. UNYX 是大众安徽面向中国新能源市场的重要产品信号。它不只是又一款大众电动车,更代表大众试图在中国建立一条不同于传统南北大众的新电动化路径。
为什么选合肥?原因不难理解:合肥已经形成新能源车和智能电动车产业集群,蔚来、江淮、国轩等供应链资源集中,地方政府也长期押注新能源产业。大众安徽不是孤立存在,而是大众把“中国本土开发速度”搬到合肥的一部分。
小鹏合作:它不是“一汽大众/上汽大众/大众安徽”的第四个合资厂
大众与小鹏的合作经常被误解成“大众又成立一个合资公司”。更准确地说,它是战略投资和联合开发关系。大众投资小鹏,并围绕中国市场车型、电子电气架构、软件平台等展开合作。
这件事的意义在于,大众承认单靠传统合资体系很难追上中国智能电动车的迭代速度。小鹏合作补的是智能化、软件、电子电气架构和中国本土产品定义能力,而不是简单补一座工厂。
所以小鹏合作要和三大整车合资线分开:
- 上汽大众、一汽-大众、大众安徽:生产和销售大众集团车型的公司主体。
- 小鹏合作:技术和产品开发协作,帮助大众在中国电动车上更快做出本土化车型。
为什么中国会有“南北大众”
“南北大众”通常指上汽大众和一汽-大众。这个结构不是偶然,而是中国汽车工业早期合资模式的结果。
上汽大众先进入,以上海为基地,是大众在中国的第一块主阵地。一汽-大众随后建立,以长春为基地,叠加了一汽的共和国汽车工业背景和奥迪国产化机会。两个地方集团、两套产业链、两个销售网络、两批产品规划,最终形成了南北大众长期并行的局面。
这种并行一度非常成功:大众可以用两个合资公司覆盖更多车型、更多产能、更多渠道,也能在中国不同区域建立更强的供应链和政企关系。但在今天,它也带来管理复杂度:
- 同一个大众品牌,在两个合资公司里可能有相近定位的车型。
- 产品命名和平台关系不直观,普通消费者很难分辨。
- 新能源转型时,不同合资主体的速度、资源和职责需要重新分配。
- 奥迪、斯柯达、捷达、进口车、SAIC 奥迪等品牌线又进一步增加复杂度。
过去复杂性是规模优势;今天复杂性既是资源,也是包袱。
一个实用判断框架
以后再看到“大众在中国”的新闻,可以按五个问题快速定位:
- 这是集团层面,还是某个合资公司层面?
- 是上汽体系、一汽体系,还是安徽/合肥体系?
- 是大众品牌、奥迪品牌、斯柯达、捷达,还是进口车?
- 是燃油车基本盘,还是新能源/智能化转型项目?
- 是股权合资、生产制造,还是技术合作?
套用这个框架,几个常见问题就清楚了:
- 朗逸、帕萨特、途观多看上汽大众。
- 速腾、迈腾、探岳多看一汽-大众。
- 一汽奥迪是传统奥迪国产主线。
- SAIC 奥迪是奥迪在上汽体系下的新合作线。
- 大众安徽是合肥新能源和中国本土开发速度的试验田。
- 小鹏合作是智能电动车技术补课,不是传统意义上的南北大众之一。
对大众中国战略的观察
大众在中国的复杂结构,本质上是两个时代叠在一起。
燃油车时代,大众的核心能力是品牌、平台化、供应链、本地制造和合资渠道。上汽大众和一汽-大众正是这个时代的产物,也支撑了大众在中国几十年的成功。
新能源时代,竞争维度变了:产品定义更快,软件和智能化权重更高,电子电气架构更关键,中国本土用户对座舱、辅助驾驶、补能、价格和配置的敏感度更强。大众安徽、100%TechCo、小鹏合作、奥迪一汽新能源汽车,都是大众为新竞争维度补能力的动作。
所以大众中国不是简单地从“上汽大众/一汽-大众”切换到“大众安徽”。更现实的结构是:
- 上汽大众和一汽-大众继续承接存量销量、渠道和燃油/混动转型;
- 大众安徽和合肥研发体系承担更激进的本土新能源试验;
- 奥迪一汽新能源汽车负责高端纯电奥迪本地化;
- 小鹏合作帮助大众缩短智能电动车开发周期;
- 集团中国总部负责把这些资源重新组织起来。
这也解释了为什么外部看起来很乱:大众不是一个新势力,可以从零搭一张组织图;它是在几十年合资历史、多个地方伙伴、多个品牌、多个平台和新能源转型压力之间重新排兵布阵。
下一步跟踪
后续跟踪大众在中国,重点不应只看“南北大众销量谁高”,而应关注四个指标:
- 大众安徽和合肥研发体系是否能持续推出真正符合中国市场节奏的车型。
- 小鹏合作车型和电子电气架构能否按期落地,并改善大众电动车智能化口碑。
- 一汽奥迪、SAIC 奥迪、奥迪一汽新能源之间是否能形成清晰分工,而不是互相稀释。
- 上汽大众和一汽-大众的燃油车基本盘能否稳住现金流,同时完成新能源产品更新。
如果这四点推进顺利,大众在中国的复杂结构会变成多线作战的资源优势;如果推进不顺,复杂结构就会变成组织惯性和品牌混乱。
参考来源
- Volkswagen Group China:Volkswagen Group China 及在华业务介绍,https://www.volkswagengroupchina.com.cn/
- Volkswagen Group China:在华主要合资主体股权资料,https://uploads.vw-mms.de/system/production/files/vwn/040/906/file/2116e099eda99404967d93370ee974ae0af3c907/EN_Volkswagen_Group_China.pdf?1740038963=
- Volkswagen Group:40 years of Volkswagen in China,https://www.volkswagen-group.com/en/articles/40-years-of-volkswagen-in-china-group-accelerates-its-realignment-with-in-china-for-china-strategy-18322
- Volkswagen Group:Volkswagen Group and SAIC extend joint venture agreement to 2040,https://www.volkswagen-group.com/en/press-releases/all-set-for-future-mobility-volkswagen-group-and-saic-strengthen-long-standing-partnership-with-new-joint-venture-agreement-18844
- FAW-Volkswagen:企业介绍,https://www.faw-vw.com/en/enterprise-introduction
- SAIC Volkswagen:企业介绍,https://www.svw-volkswagen.com/
- Volkswagen Anhui:官方介绍,https://m.volkswagengroupchina.com.cn/en/partner/volkswagenanhui
- Audi MediaCenter:Audi FAW NEV Company 相关资料,https://www.audi-mediacenter.com/
- Volkswagen Group:Volkswagen enters into agreement with XPENG for fast joint development of two smart e-cars,https://www.volkswagen-group.com/en/articles/ready-for-next-ev-push-volkswagen-enters-into-agreement-with-xpeng-for-fast-joint-development-of-two-smart-e-cars-18246
- Volkswagen Group China:Volkswagen and XPENG expand platform and software partnership,https://m.volkswagengroupchina.com.cn/en/news/Detail?ArticleID=A1E618D41AF04B0DA512A7E159801D67
---
layout: post
title: 地平线仓位管理与叙事反转等待:原文
subtitle: Codex 个人助理沉淀
date: 2026-06-23 03:34:38 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/horizon_robotics/02_地平线仓位管理与叙事反转等待_原文.md
地平线仓位管理与叙事反转等待:原文
记录时间:2026-06-23 15:33:34 CST
原文
这一轮先是3月的时候降仓位,再然后是一次次试图右侧博弈失败,以至于我把其他股票卖了,汇集现金到一个账户了,如果全部加仓的话成本在6 HKD,不过现在不会加仓了。
如果时间线拉长看,从上市以来地平线的股价就是一个轮回,虽然这一次跌得远超预期。
很多需要验证的东西得等财报,不过从我昨天接触CFO来看,如果他不骗我的话,大概率BYD这一次芯片的事情会在财报中得到确认。
另外一方面如果他骗我的话,投资路上碰到管理层欺骗亏钱几乎是不可避免的了。
但是我这点资金量没有必要骗我,而且他们是真正做事的,比如现在AI这么火,如果要造假卖公司,直接说改做服务器AI芯片,造势等拉高市值。
目前我们的优势就是越来越了解这个企业,以及有钱加仓。还有就是灵活,每一次右侧博弈失败我都会认错挨打。将来涨了的话我也会因为相信紧紧拿住。
我之前一直说,账户会随着股价波动,但是认知是一直提升的。
群友从25年2月的时候4-5 HKD的时候买,看着翻倍。
再到现在跌破4,这期间我因为深入研究公司和自媒体创作接触到了投资大户和公司管理层,可以说是非常Amazing的体验。如果不是长期持仓不会亏损这么多,但可能也不会有这样的旅程。
反正就是,做好自己心态上的仓位管理,把仓位降到自己舒服的位置,不要加到心态崩了,等叙事反转再加仓。
耐心观察,耐心等待。
标签
地平线机器人 / 仓位管理 / 右侧博弈 / BYD 芯片 / 管理层沟通 / 叙事反转 / 投资心态
下一步动作
- 等待财报验证 BYD 芯片相关信息,不在财报前把待验证信息当成确定事实。
- 维持让心态舒服的仓位,不因摊低成本而加到影响判断。
- 记录后续叙事反转信号,再决定是否追加仓位。
---
layout: post
title: 02_中国车厂自研芯片必修课还是选修课_原文
subtitle: Codex 个人助理沉淀
date: 2026-06-22 05:55:07 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/automotive_platforms/02_中国车厂自研芯片必修课还是选修课_原文.md
中国车厂:自研芯片,必修课还是选修课?
这两年,很多小伙伴和笔者探讨过同一个问题:中国车企到底要不要自研芯片?
先把结论放前面:
芯片能力,是必修课。
芯片自研,却不一定是必修课。
这两个东西,千万不要混在一起。
各位小伙伴都知道,今天的智能汽车,已经不是过去那种发动机+变速箱+底盘就可以定义胜负的时光了。车越来越像一个跑在轮子上的实时AI系统。摄像头、激光雷达、毫米波雷达、底盘、座舱、车身控制、云端训练、车端推理,全都在往一个方向收敛:算力、数据、模型、操作系统、车载娱乐加整车体验的闭环。
所以,车企必须懂芯片。
必须懂车载多芯片算力怎么分布,这些算力怎么才不会被浪费,怎么才能被调度,哪些部分会被编译器吃掉,怎么被内存带宽卡住,怎么被功耗墙拦住,芯片怎么才能在高温、震动、电磁干扰、十年生命周期里老老实实工作。
车企如果不懂这些,只会看TOPS,只会问“你这个芯片比Orin强几倍”,那基本上还是在用买轮胎的方式买车机大脑。而现在部分传统车企为什么现在在竞争中掉队,不懂芯片也是核心的原因。
但懂芯片,和自己下场做芯片,是两件不同的事情。
这些年,大家都看到了头部车企的动作。
小鹏图灵,蔚来神玑,理想马赫,比亚迪璇玑,吉利体系里的芯擎(SiEngine);再加上传统的车规芯片算力厂商地平线,黑芝麻和华为;神呀,这个赛道拥挤了。
确实,头部车企自研芯片,有它非常硬的核心逻辑:
成本:一颗高阶智驾芯片,外购方案并不便宜。尤其到了百万级出货以后,账就会变得很直白。今天省下来的不是一颗芯片的钱,而是一整套平台、模块、库存、议价权和毛利结构。蔚来李斌说过,一年少买很多英伟达芯片,这句话很多人听着像宣传,但做过供应链的人都知道,这不是文学表达,这是财务报表里的真金白银。
效率:通用芯片再强,也要照顾很多客户、很多算法、很多场景。它必须通用,通用就意味着妥协。车企自己的算法、自己的感知路线、自己的模型结构、自己的数据闭环,如果能和芯片架构一起设计,效率一定有机会提升。车企最近都在推动大模型上车,但是这个模型能不能在车端实时跑,能不能在极端场景里稳定跑,能不能在功耗限制里长期跑,能不能在一次OTA之后还安全跑。这时候,芯片是整个模型的地基,而效率的高低决定了客户的最终体验。
节奏:外部供应商都有自己的Roadmap。你要等它下一代芯片,等它的SDK,等它的工具链,等它的安全认证,等它来适配你的算法,等着等着,可能一个产品周期就过去了。而智能汽车竞争最残酷的地方就在这里:车企可能没有输在某一个车辆配置或者参数上,却是输在迭代节奏上。所以,头部车企要把芯片抓到自己手里,本质上为了把技术节奏从供应商节奏,变成自己的产品节奏。
按照惯例,接下来笔者要说点别的了。
请注意:自研芯片绝对不是在车的规格书里面写一句“全栈自研”就完事。车规芯片是一个很慢、很重、很冷的行业。
慢到什么程度?一颗芯片,从定义、架构、设计、验证、流片、封装、车规测试、功能安全、系统适配、整车验证,到真正量产上车,三年都是很快的。
重到什么程度?研发费用动辄几十亿。先进制程一次流片就是大钱,回来以后还不一定能用。用上以后还要做工具链、编译器、驱动、OS适配、算法迁移、硬件安全岛、功能安全、信息安全、失效分析、供应链管理。芯片本身只是冰山露出来的一小块。
冷到什么程度?车规芯片不是消费电子。手机芯片两三年一代,卖完就翻篇。汽车芯片要陪一辆车跑十年,甚至十五年。只要车还在路上跑,芯片公司就不能说“这个产品不再维护了”。车企还在卖售后,你的供应链就不能断。客户出了事故,芯片公司不能说“这不是我们软件的问题”。
这才是车规芯片的真实门槛。
所以,车规芯片厂的真实竞争力,
不是彩页上宣传的5nm;
也不是4nm;
更不是1000 TOPS的算力;
这些IP和制造,都是可以买来集成的;
但是车规芯片厂有没有能力,让这颗芯片在真实世界里,稳定地、可追溯地、可量产地、可维护地活十年十五年甚至更久,这才是车规芯片厂的真正的核心竞争力。
所以在笔者看来,目前行业里和媒体上最危险的一种误会,是把“流片成功”当成“造芯成功”。
流片成功,只能说明你把图纸变成了硅片;量产上车,说明你走进了考场;真正核心的是你的芯片要跑满一个车型生命周期,经历高温、低温、返修、召回、OTA、供应链波动、算法大改,还能稳稳交付,那才叫真正毕业。
喧嚣的媒体往往只看到了第一天的发布会,不会看到和想到后面十年的运营和售后的成本。
车企造芯应该分成三本账。
第一本,研发账。
你有没有钱投?有没有人?有没有架构能力?有没有系统工程能力?有没有能坐十年冷板凳的组织?芯片不可能今年烧钱明年增长。芯片的回报周期很长,错误成本极高。一个架构判断错了,不是改个App版本那么简单。一次定义失误,可能拖累整代平台。
第二本,量产账。
你一年到底能装多少颗?不是PPT里的未来销量,是实打实的车型、配置、渗透率和生命周期出货。没有百万级规模,先进制程智驾芯片很难摊薄。简单算个帐,你一个年出货量30万台车的车企,投了30亿研发了一颗5nm的车规芯片,平均下来每一颗芯片光是分摊研发成本就要1万块。这账要怎么算?
第三本,事故账。
对消费者而言,你的芯片上车了,那么最终你要承担安全责任。消费电子芯片坏了,最多重启、换机、赔钱。车规芯片出问题,可能是刹车、转向、感知、控制、辅助驾驶误判。这里没有“差不多能用”的说法,也不会有“用户会理解”。
归根结底,车规行业最贵的不是投多少钱研发,最贵的是用户的信任。一旦信任出现任何问题,再多的发布会都不能弥补回来。
自研芯片到底适合谁?笔者认为有几个硬条件。
你得有足够大的销量,三到五年内能形成数百万级的芯片出货。
你的算法和模型是核心差异化,而且变化速度显著快过外部平台。
你必须有完整的软件、操作系统、数据闭环和验证体系。
你得能做设计,能做工具链、功能安全、信息安全、可靠性、量产质量和供应链连续性。
你得愿意接受三年没有掌声,五年才看结果,十年才验证能力。
如果以上你都有,那么恭喜你:自研芯片对你来说,就是必修课。因为你已经到了必须掌握底层计算架构的阶段。
很多车企真正需要的,不是自己从RTL写起,不是自己养一支完整芯片团队,不是每一颗MCU、每一颗电源芯片、每一颗传感器芯片都贴上自己的名字。
真正需要的是“知道自己需要什么样的芯片”。
你要知道自己的车需要什么样的算力;
你要知道自己的模型瓶颈在哪里;
你要知道 ISP、NPU、CPU、内存带宽、接口、功耗、安全岛之间怎么取舍;
你要知道一颗芯片上车以后,如何和整车电子电气架构、域控、中央计算、线控底盘、座舱系统打通;
你要知道什么时候该自己做,什么时候该联合定义,什么时候该交给专业供应商。
这才是必修课。至于芯片产品本身的所有权在谁,是选修课。
换句话说:不是每一家车企都需要拥有一家芯片公司。但每一家认真做智能汽车的车企,都必须拥有芯片判断力。
---
layout: post
title: 趋势交易与基本面投资的信号错配
subtitle: Codex 个人助理沉淀
date: 2026-06-17 23:13:35 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/value_investing/03_趋势交易与基本面投资的信号错配.md
趋势交易与基本面投资的信号错配
原始触发
这条记录来自一次投资心理复盘。
从 2025 年 2 月到现在,标的大概经历了 3 个明显波段:每次跌下去之后,后来又能拉回来。尤其是 2025 年 4.7 附近那次,下跌过程中已经“跌麻了”,最后直接抄底,基本没有再管风险控制。
连续几次这种经历之后,一个心理结构会被强化:只要之前跌了还能拉回来,这一次下跌也可能只是又一轮波动。于是“执念”变得很重。
核心问题
这里的难点不只是判断标的对错,而是两套交易系统在心理上混在了一起:
- 趋势交易:认准趋势。趋势坏了就先避险,趋势好了再参与。
- 基本面投资:认准基本面。只要基本面逻辑没有变,就继续持有或等待。
两套系统本身都可以成立,问题在于不能临场切换解释体系。
理想情况是:
- 下跌时,用趋势交易做避险,减少回撤和心理压力。
- 上涨时,用基本面逻辑拿住,避免太早被波动洗出去。
实际情况更容易反过来:
- 上涨时,拿趋势交易作为理由提前止盈。
- 下跌时,找基本面利好作为理由继续硬抗。
这会导致一个很隐蔽的结果:赚钱时按照短线纪律走,亏钱时按照长线信仰扛。长期看,容易形成“截断盈利、放大亏损”的行为模式。
为什么执念会变重
执念不是凭空出现的,它来自被市场反复奖励过的路径。
过去几次下跌后又拉回的经验,会让人形成一种身体记忆:下跌不是风险,而是机会;痛苦不是警告,而是抄底前的必要代价。
如果某一次在极度痛苦中抄底成功,这个记忆会更强。因为它不只是一次赚钱经验,还是一次“我扛住了、我看对了”的自我证明。
后续再遇到下跌时,大脑很容易把当前情境套进过去模板:
- 以前也是这么跌的。
- 以前多头也很难受。
- 以前最后还是拉回来了。
- 所以这次也应该继续扛。
真正危险的地方在于:这个推理可能对,也可能错。它本身不能证明基本面逻辑仍然成立。
基本面投资的难点
基于基本面的投资,本来就要求抗到基本面逻辑变化才卖。
但这句话在现实里非常难执行,因为股价下跌会先于信息确认发生。基本面是否变化,往往不是当天就能清楚判断的;而股价和账户回撤每天都在给压力。
所以基本面投资的痛苦不只是“亏钱”,而是:
- 不知道市场是在错杀,还是在提前反映基本面恶化。
- 不知道自己是在坚持逻辑,还是在用逻辑包装不愿认错。
- 不知道心理建设是在增强持有能力,还是在训练自己硬抗错误。
这也是为什么“下跌过程非常难顶”。它会跌到多头也扛不住,甚至让原本相信逻辑的人开始怀疑自己。
需要避免的混用方式
最需要警惕的不是趋势交易,也不是基本面投资,而是事后选择对自己最舒服的解释。
常见表现:
- 股价上涨时,担心回撤,于是用趋势交易止盈。
- 股价下跌时,不愿止损,于是用基本面利好安慰自己。
- 明明买入前没有明确基本面框架,下跌后才开始补基本面理由。
- 明明说自己是基本面投资,但没有预先定义哪些基本面指标一旦变化就必须重估。
- 明明说自己看趋势,但趋势破坏后又临时改成长期持有。
这类行为的本质,是没有在买入前确定“自己到底听哪个系统的信号”。
下跌时研究公司的边界
股价一直下跌的时候,继续研究公司本身未必有用。
不是因为公司研究没有价值,而是因为研究结论在不同价格状态下承担的功能不同。上涨时,研究出来的利好可以成为“坚定拿住”的力量,帮助自己不被短期波动过早洗出去;但下跌时,同样的利好很容易变成“证明自己不该卖”的理由。
这里真正危险的是叙事逻辑的转变:
- 原本是在研究公司,后来变成替持仓找支撑。
- 原本是在验证基本面,后来变成抵消账户亏损带来的痛苦。
- 原本是在积累上涨时拿住的信念,后来变成下跌时继续硬抗的安慰。
哪怕主观上知道这一点,仍然会被逆流影响。因为持续下跌会改变信息的心理用途:利好不再只是利好,而会被自动拿来服务于“我还可以坚持”的结论。
所以,下跌时更应该先看预先定义好的风险纪律、仓位上限、趋势信号和基本面再评估条件,再决定是否继续深入研究公司。研究本身不能替代交易纪律。
更好的约束
后续每次持仓或加仓前,至少要先写清楚三个问题:
- 这笔仓位归属于哪套系统:趋势交易,还是基本面投资?
- 如果归属于趋势交易,趋势破坏的退出条件是什么?
- 如果归属于基本面投资,基本面逻辑被破坏的具体信号是什么?
不要用“我相信基本面”替代指标,也不要用“趋势不好”替代完整的投资判断。
更可执行的做法是把仓位分层:
- 趋势仓:服从价格和趋势纪律,破位或趋势恶化就减仓。
- 基本面仓:服从业务逻辑和估值纪律,只在基本面逻辑变化、估值严重透支或仓位风险失控时调整。
- 机动现金:专门用于应对极端波动,而不是在情绪最差时被迫做决定。
这样可以避免同一笔仓位在上涨和下跌时被不同系统反复解释。
下一步动作
- 为当前核心标的写一页投资卡片,明确它到底是趋势交易仓、基本面仓,还是两者分层。
- 单独列出“基本面逻辑变化”的硬指标,避免下跌后只寻找利好信息。
- 对过去 3 个波段做复盘:每次下跌时的买入理由、风险控制、后续拉回原因,哪些是能力,哪些是运气。
- 建立下跌场景预案:如果继续下跌 10%、20%、30%,分别检查什么、减什么、加什么,以及什么情况下不动作。
一句话总结
趋势交易和基本面投资都可以成立,真正危险的是上涨时按趋势止盈、下跌时按基本面硬抗。关键不是证明自己有没有信仰,而是先规定每一笔仓位到底服从哪套纪律。
---
layout: post
title: 百度自动驾驶旧将六年后复盘:当年那批人,后来都去哪了?
subtitle: Codex 个人助理沉淀
date: 2026-06-16 22:59:21 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/autonomous_driving_baidu_alumni/01_百度自动驾驶旧将六年后复盘.md
百度自动驾驶旧将六年后复盘:当年那批人,后来都去哪了?
说明:本文基于 2021-02-26 雷峰网/新智驾文章《30 个「前」百度人,打下了中国自动驾驶半壁江山》及截至 2026-06-17 可核验的公开资料整理。部分早期创业公司后续公开信息有限,涉及经营状态的判断以公开报道、公司官网、上市公告和监管披露为准。本文仅作为行业研究记录,不构成投资建议。
2021 年那篇文章现在回头看,很有意思。
它写的是一个特别典型的中国科技产业故事:百度在自动驾驶上起了个大早,聚集了一批中国最早做自动驾驶、深度学习、地图、感知、规划控制、芯片和机器人出行的人才。后来这些人陆续离开百度,去了小马智行、文远知行、地平线、Momenta、黑芝麻智能、禾多科技、毫末智行、白犀牛、主线科技、DeepMap、Roadstar.ai 等公司。
当时文章的标题很重,叫“30 个前百度人,打下了中国自动驾驶半壁江山”。
放在 2021 年看,这句话有点像行业热闹时期的夸张表达。放到 2026 年再看,它反而更像一个阶段性结论:百度自己没有成为中国自动驾驶商业化的绝对赢家,但它确实成了中国自动驾驶产业最重要的人才母体之一。
后来的故事并不整齐。
有人带公司上市了,有人还在一级市场和车企客户之间艰难推进,有人被大公司收购,有人项目已经停摆,有人则从明星创业者变成了行业清算周期里的案例。
这篇文章不想简单做一张“成功/失败”名单,而是想回答一个更重要的问题:
为什么同样从百度自动驾驶体系里出来的人,后来命运差别会这么大?
一、最成功的一批:从百度出来,最后把公司推上资本市场
先看最清楚的一批:上市公司。
到 2026 年,前百度系自动驾驶人才相关公司里,已经出现了几家真正进入公开市场的公司。
最典型的是地平线。
地平线创始人余凯曾任百度深度学习研究院负责人,也是中国深度学习和自动驾驶产业早期非常关键的人物。2024 年 10 月 24 日,地平线在香港交易所主板挂牌上市,股票代码 9660.HK。公司官网披露,上市时地平线的智能驾驶解决方案已获得 27 家 OEM、42 个 OEM 品牌采用,并装备于 290 款车型。
这个结果很关键。
因为地平线并不是去做 Robotaxi,而是选择了“车载智能计算芯片 + 算法 + 工具链 + 量产方案”的路线。它没有把自己锁死在 L4 的长周期故事里,而是很早切到车企量产链条。这个选择让它更早拿到了收入、更早进入主机厂供应链,也更早获得二级市场定价。
这说明一个问题:自动驾驶行业里,最先商业化的不一定是最炫的无人车,而是能进入量产车 BOM、能跟随车型交付、能持续迭代的软件和芯片平台。
第二个是小马智行。
小马智行由彭军、楼天城等人创立。彭军曾是百度首席架构师,楼天城是知名算法竞赛选手,后来也成为中国自动驾驶行业非常有标识度的技术创业者。2024 年 11 月 27 日,小马智行宣布 IPO 定价,并在纳斯达克以 PONY 为股票代码交易。
小马智行走的是 Robotaxi、Robotruck 和自动驾驶出行服务路线。和地平线相比,它离最终消费者更近,但商业化路径也更长。Robotaxi 的难点不是演示,也不是局部区域试运营,而是监管、成本、安全责任、车队运营和单位经济模型。
小马能上市,说明资本市场仍然愿意给 Robotaxi 一个窗口,但它上市后的核心问题并没有消失:规模化运营到底何时能跑通?
第三个是文远知行。
文远知行由韩旭创立。韩旭也曾在百度自动驾驶相关体系中工作。2024 年 10 月 28 日,文远知行在纳斯达克上市,股票代码 WRD。上市稿中提到,文远知行覆盖 Robotaxi、Robobus、Robovan、Robosweeper 和 ADAS 等产品形态,并在多个国家和城市开展测试和运营。
文远知行的特点是“场景铺得很广”。这有好处,也有风险。好处是它不把公司命运押在单一 Robotaxi 场景上;风险是每个场景都需要交付、运营和商业闭环,公司容易变成一个很重的综合型自动驾驶工程公司。
第四个是黑芝麻智能。
黑芝麻智能创始团队不是完全意义上的百度 Apollo 原班人马,但黄浴等前百度技术人物曾在其中扮演重要角色。2024 年 8 月 8 日,黑芝麻智能在香港交易所主板上市,股票代码 2533.HK。它的路线也是车规级智能汽车计算芯片和基于芯片的解决方案。
黑芝麻智能和地平线放在一起看,很能说明 2021 年之后行业的变化:单纯讲 L4 故事越来越难,能落到车规芯片、行泊一体、NOA、域控和量产车型上的公司,反而更容易被市场理解。
第五个是 Innovusion,后来的 Seyond。
Innovusion 由鲍君威、李义民等人创立,后来品牌升级为 Seyond。2025 年 12 月 10 日,Seyond 宣布在香港交易所主板上市。它不是自动驾驶整套方案公司,而是激光雷达公司。
这类公司的命运取决于两个变量:一是激光雷达在乘用车智能驾驶中的渗透率,二是能否在价格快速下降的情况下守住毛利和客户。激光雷达从早期“高端 Robotaxi 标配”变成后来“部分量产车型感知配置”,商业空间打开了,但竞争也更激烈。
这几家公司有一个共同点:它们都找到了资本市场能理解的产品形态。
地平线和黑芝麻智能是芯片和智能驾驶计算平台;小马智行和文远知行是自动驾驶出行和多场景运营;Seyond 是激光雷达硬件。
不管各自未来股价如何,这几家公司至少完成了一件很难的事:从百度人才外溢,走到独立公司,再走到公开市场。
二、还在牌桌上的公司:没有上市,但没有出局
第二批公司没有上市,但仍然在牌桌上。
最值得看的,是 Momenta。
Momenta 创始人孙刚也有百度背景。它早期就提出“飞轮”思路:量产辅助驾驶积累数据,数据反哺自动驾驶能力,再推动更高阶系统。这条路线后来被证明更符合中国智能驾驶商业化节奏。
到 2025 年和 2026 年,Momenta 的公开动态仍然很密集。公司官网显示,它与 Uber、Valeo、奔驰、Grab、BMW、本田、上汽通用、广汽埃安等合作不断推进。尤其是奔驰和 Momenta 在中国智能驾驶上的合作,以及 Uber 与 Momenta 围绕 Robotaxi 的合作,说明它仍然是中国自动驾驶创业公司中少数能同时打入国内外主机厂和出行平台的玩家。
Momenta 的特殊之处在于,它没有急着把自己包装成一个单纯的 L4 Robotaxi 公司,而是把量产辅助驾驶当成商业化入口。这让它在资本寒冬中有更强的生存能力。
另一个是白犀牛。
白犀牛由朱磊、夏添等人创立,方向是无人配送。这个赛道没有 Robotaxi 那么性感,但商业逻辑反而更朴素:低速、封闭或半封闭场景、配送成本、即时零售需求。2025 年之后,白犀牛仍然有融资和产品动态,说明它没有完全掉队。
无人配送的问题在于市场天花板和运营密度。它不像乘用车智能驾驶那样一旦进入车企供应链就可能随着车型放量,也不像 Robotaxi 那样有巨大的想象空间。但它有一个优点:场景更具体,商业问题更容易算账。
主线科技也还在推进。
主线科技聚焦自动驾驶卡车和港口、干线物流等场景。张天雷、何贝、李博等人均与早期百度自动驾驶人才网络有关系。到 2025 年和 2026 年,主线科技仍有融资、合作和项目落地动态。
自动驾驶卡车是一个非常难但也非常真实的赛道。它不只是技术问题,还涉及物流组织、车辆资产、运营调度、保险责任和法规。这个赛道不会像 2018 年想象得那么快,但只要中国物流成本优化的需求还在,长期就仍然有产业价值。
还有宽凳科技。
宽凳科技由刘骏创立,早期聚焦高精地图和自动驾驶数据。后来整个高精地图行业的逻辑发生了变化:一方面,主机厂和自动驾驶公司越来越追求“轻地图”甚至“无图”;另一方面,地图资质、数据合规和更新成本都让这个赛道变得更重。
所以宽凳后来的叙事逐渐从单纯高精地图,转向 AI 数据、道路数据和空间智能服务。这不是原来那条自动驾驶主线的胜利,但也不是完全出局,而是行业变化后的再定位。
这一批公司的共同点是:它们还没有给出二级市场意义上的答案,但也没有进入明显的死亡名单。
它们更像还在等商业化最终判卷。
三、被并购的一类:独立故事结束,但技术价值被确认
DeepMap 是一个很好的例子。
DeepMap 由 James Wu、Mark Wheeler 等人创立,两人都有百度背景。它做的是自动驾驶高精地图。2021 年,NVIDIA 宣布收购 DeepMap,用来增强自动驾驶行业的地图能力。
这类结局不能简单说失败。
从创业公司的角度看,DeepMap 没有独立上市,也没有成长为一个长期独立平台。但从技术资产角度看,它能被 NVIDIA 收购,说明其地图能力在全球自动驾驶供应链里有价值。
只是它也反映出高精地图公司的一个结构性问题:如果你不能成为主机厂和自动驾驶公司的长期基础设施,最后很可能变成更大平台公司的能力模块。
在自动驾驶行业里,被并购往往意味着两个判断同时成立:
第一,技术是真的有价值。
第二,单独撑起一家大公司的商业闭环不够清晰。
DeepMap 后来的命运,正是这个逻辑。
四、掉队的一批:自动驾驶创业不是光靠履历和融资就能穿越周期
再看最残酷的一批。
Roadstar.ai 是早期自动驾驶创业潮里最有戏剧性的案例之一。
它曾经拿到不少关注,也有百度系技术人员背景。但这家公司后来因为创始团队内讧、管理问题和融资环境变化快速瓦解。它的故事说明,自动驾驶创业不是只有算法、融资和 Demo,组织治理同样是核心能力。
一个自动驾驶公司很重。
它需要技术、工程、车辆、测试、数据、客户、政府关系、安全体系和融资节奏同时在线。只要创始团队内部治理出大问题,外部再热的赛道也救不了。
中智行也是一个明显走弱的案例。
王劲曾是百度自动驾驶事业部总经理,离开百度后创办中智行。早期看,中智行具备非常强的“明星高管 + 百度履历 + 自动驾驶叙事”光环。但后续公司发展并不顺利。到 2025 年,公开报道已经出现员工数量接近归零、执行转破产或清算相关信息。
这个案例有点警示意义。
百度背景能帮创业者拿到第一张名片,但不能替公司解决产品、客户、现金流和组织管理。自动驾驶从讲技术故事进入商业化阶段后,履历的溢价会快速衰减,真正重要的是:你到底能交付什么?谁愿意持续买单?单位经济模型能不能跑通?
毫末智行也从明星项目走到困难状态。
毫末智行背靠长城汽车体系,顾维灏曾担任公司关键负责人。早期它讲的是数据智能和辅助驾驶量产,算是比纯 L4 更务实的路线。但到 2025 年之后,公开报道中已经出现停摆、债务和善后等信息。
毫末的困难说明,即使路线看起来更接近量产,也不代表一定安全。
智能驾驶供应商必须面对一个现实:主机厂既需要你,又会防着你;既希望你快速交付,又会压价;既希望你有技术领先性,又可能随时转向自研或其他供应商。一旦母体资源、外部融资、客户订单和交付节奏之间出现错配,压力会非常快地传导到公司现金流。
禾多科技同样值得放进这一类观察。
倪凯曾有百度背景,禾多科技早期也是中国自动驾驶创业公司中的重要名字,聚焦高阶辅助驾驶和量产方案。但 2024 年之后,围绕禾多的资金压力、重组、人员流动等公开信息明显增多。它还没有像一些公司那样彻底从行业视野中消失,但已经不是早年那个被资本追捧的明星样本。
这一批公司共同说明一件事:自动驾驶创业最难的不是起跑,而是中后段。
2016 到 2021 年,只要团队背景强、Demo 做得出来、融资故事够大,就有机会站上牌桌。2021 年之后,行业判卷标准变了。
资本不再只看“你是不是前百度”“你是不是做 L4”“你是不是有顶尖算法团队”,而是看:
你有没有收入?
你有没有量产?
你有没有稳定客户?
你有没有可控成本?
你有没有继续融资的能力?
你能不能在主机厂自研、华为入场、英伟达平台、地平线和黑芝麻智能这类芯片平台之间找到自己的位置?
回答不上来,就会被周期带走。
五、为什么同样是百度旧将,后来差距这么大?
如果只看个人履历,很容易得出一个简单结论:百度培养了很多厉害的人。
但如果看公司命运,就会发现真正拉开差距的不是履历,而是商业化路径。
第一条分界线,是 L4 还是量产辅助驾驶。
早期行业最热的是 L4 Robotaxi。这个故事大、天花板高,也最容易吸引资本。但它的商业化周期太长,需要监管、车队、运营、城市合作、车辆成本、安全冗余和乘客信任一起成熟。
相比之下,L2/L2+ 辅助驾驶、NOA、芯片和域控平台虽然没有那么理想主义,但更贴近车企真实需求。地平线、黑芝麻智能、Momenta 能走到今天,很大程度上就是因为它们切进了量产链条。
第二条分界线,是做产品还是做项目。
自动驾驶公司很容易陷入项目制:给某个客户定制一套方案,拿一个示范项目,跑一个试点。但项目制的问题是不可复制、毛利不稳、交付成本高。
真正能长大的公司,必须把能力产品化。芯片是产品,域控是产品,标准化算法平台是产品,车规级工具链是产品,可规模部署的 Robotaxi 运营系统也是产品。
第三条分界线,是技术强还是组织强。
百度出来的人,技术标签通常不弱。但公司能不能活下来,最后不只看技术。融资节奏、创始团队治理、客户关系、现金流纪律、量产交付和战略聚焦,都会决定命运。
Roadstar.ai 的内讧,中智行的后期困境,毫末智行的停摆压力,都说明技术履历不能替代组织能力。
第四条分界线,是有没有找到产业链位置。
自动驾驶不是一个孤立行业,它嵌在汽车产业链里。这里面有主机厂、Tier 1、芯片公司、传感器公司、地图公司、出行平台、物流公司、地方政府和监管部门。
创业公司如果找不到清晰位置,就会很尴尬。
你做整套自动驾驶,主机厂可能怕被你卡脖子。
你做算法,主机厂可能要求你深度定制,最后变成外包。
你做高精地图,行业可能转向轻地图。
你做硬件,价格战可能迅速吃掉利润。
你做 Robotaxi,商业化周期可能长到融资支撑不住。
真正活下来的公司,本质上都找到了一个相对稳的位置:要么成为车企智能化底座的一部分,要么成为出行平台和城市运营的一部分,要么成为核心硬件供应链的一部分。
六、百度自己呢?
这个问题绕不开。
如果说百度输出了这么多人才,那百度自己后来怎么样?
百度 Apollo 仍然是中国自动驾驶的重要玩家,尤其在 Robotaxi 和 Apollo Go 运营上仍有行业影响力。但从“人才外溢”这个角度看,百度的尴尬在于:它既培养了行业,又没有完全收割行业。
这不是百度一家公司的问题,而是大公司创新的经典矛盾。
大公司有资金、有数据、有工程体系、有品牌、有政府和产业资源,适合做长期重投入。但大公司内部也有业务优先级、组织边界、商业化考核、资源竞争和战略摇摆。
很多技术人才在大公司里完成了原始积累,但真正想创业、想做独立产品、想押注一个方向时,最终会选择离开。
所以百度在中国自动驾驶中的角色,有点像“黄埔军校”。
它不一定是战场上赢得最多城池的那一个,但它训练出了大量后来去各个战场打仗的人。
七、这篇旧文章真正值得记住的,不是名单,而是周期
2021 年那篇文章最有价值的地方,不是列出了多少前百度人。
真正有价值的是,它记录了一个产业从人才集中到人才扩散的瞬间。
早期技术革命通常是这样发生的:
先有一个大平台聚集人才。
然后人才在平台里完成训练。
接着,平台内部空间不够,或者外部资本窗口打开,人才开始外溢。
再然后,一批创业公司出现,赛道开始热闹。
最后,产业进入商业化和资本收缩周期,泡沫被挤掉,只有少数公司穿越。
中国自动驾驶刚好走完了这条路径。
2015 到 2018 年,是人才和技术启蒙期。
2018 到 2021 年,是创业和融资扩张期。
2021 到 2024 年,是商业化压力显性化期。
2024 到 2026 年,是上市、并购、停摆和分化同时发生的判卷期。
从这个角度看,“前百度人”不是一个简单标签,而是中国自动驾驶产业第一阶段的历史切片。
八、今天再看这些公司,最该跟踪什么?
如果后面继续跟踪这批公司,我会看五件事。
第一,上市公司的真实收入质量。
地平线、黑芝麻智能、小马智行、文远知行、Seyond 都已经进入公开市场或完成上市节点。接下来不能只看新闻稿,而要看收入结构、毛利率、现金消耗、客户集中度和订单兑现。
第二,量产辅助驾驶公司的主机厂绑定深度。
Momenta 这类公司能不能长期胜出,关键不是合作新闻有多少,而是能不能在主机厂车型上持续放量,并且从项目收入变成平台收入。
第三,Robotaxi 的单位经济模型。
小马智行、文远知行、百度 Apollo 等最终都要回答:没有补贴、没有宣传意义、没有资本故事时,一辆车每天能不能赚到钱?
第四,主机厂自研对供应商的挤压。
车企不会永远把智能驾驶灵魂交给外部供应商。供应商要么变成平台型底座,要么变成可替换模块。中间位置最危险。
第五,掉队公司的资产如何被行业吸收。
毫末、禾多、中智行、Roadstar.ai 这类案例即使公司本身困难,团队、代码、数据、专利和客户经验也可能被其他公司吸收。行业不会凭空消失,只是牌桌上的玩家会换。
九、最后一句话
2021 年那篇文章说,前百度人打下了中国自动驾驶半壁江山。
到 2026 年再看,这句话需要改一下:
前百度人确实参与塑造了中国自动驾驶的半壁江山,但最后真正留下来的,不是履历最亮的人,也不是故事讲得最大的人,而是那些更早找到商业化入口、更能进入产业链、更能穿越资本周期的公司。
自动驾驶是一个特别残酷的行业。
它既需要天才,也需要耐心;既需要技术,也需要现金流;既需要 Demo,也需要量产;既需要理想主义,也需要供应链里的脏活累活。
百度给了这批人第一张地图。
后面的路,靠他们自己走。
而现在,行业已经走到了真正看结果的时候。
参考资料
- 雷峰网/新智驾:《30 个「前」百度人,打下了中国自动驾驶半壁江山》,2021-02-26。
- 地平线:《扬帆新征程!地平线正式在香港交易所主板挂牌上市》,2024-10-24。
- Pony AI Inc. Announces Pricing of Initial Public Offering,2024-11-27。
- WeRide Officially Listed on Nasdaq,2024-10-28。
- 黑芝麻智能:《黑芝麻智能成功于港交所主板挂牌上市!》,2024-09-09。
- NVIDIA Blog: NVIDIA to Acquire DeepMap, Enhancing Mapping Solutions for the AV Industry,2021-06-10。
- Seyond: Seyond Officially Lists on the Main Board of the Hong Kong Stock Exchange,2025-12-10。
- Momenta 官网新闻中心,2024-2026。
---
layout: post
title: 地平线机器人 2025 年中期业绩详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-16 03:55:57 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2025 Interim Results
---
来源:notes/books/Horizon Robotics 2025 Interim Results/01_详细解读.md
地平线机器人 2025 年中期业绩详细解读
- 记录时间:2026-06-16 15:50:26 CST
- 对象:Horizon Robotics 地平线机器人,股份代号 9660
- 文件:截至 2025 年 6 月 30 日止六个月的中期业绩公告
- 原文归档:
source_materials/2025半年报.pdf
- 全文转换稿:
source_materials/pdf_full_text.md
- 类型:财报解读 / 公司研究
核心结论
这份半年报的主线很清楚:地平线的收入正在加速增长,且增长动力正在从高毛利的授权及服务,切换到更大规模的汽车产品解决方案。征程 6 和支持高速公路辅助驾驶功能的处理硬件放量,是 2025 年上半年最关键的经营信号。
但从财务质量看,公司还没有进入利润释放阶段。研发投入、云服务费用、股份支付、权益法投资亏损和金融负债公允价值变动仍然显著拖累利润表。更准确的判断是:地平线处在“产品出货放量 + HSD 研发加码 + 商业模式切换”的阶段,而不是盈利拐点已经确认的阶段。
关键财务数据
2025 年上半年,公司实现收入人民币 1,566.8 百万元,同比增长 67.6%;毛利人民币 1,024.0 百万元,同比增长 38.6%;毛利率 65.4%,较 2024 年同期的 79.0% 明显下降。
公司经营亏损为人民币 1,592.1 百万元,2024 年同期为亏损 1,105.4 百万元;经调整经营亏损为人民币 1,111.3 百万元,2024 年同期为亏损 824.0 百万元;经调整亏损净额为人民币 1,332.5 百万元,2024 年同期为亏损 803.9 百万元。
账面期内亏损达到人民币 5,233.0 百万元,但其中包含优先股及其他金融负债公允价值变动亏损人民币 3,406.7 百万元。这一项主要与向酷睿程发行的可转换借款因股价波动产生的公允价值变动有关,属于重要的非经营性扰动。
截至 2025 年 6 月 30 日,公司现金及现金等价物为人民币 16,069.1 百万元,较 2024 年底的 15,370.9 百万元增加 4.5%。现金储备仍然充足。
业务进展
2025 年上半年,中国自主品牌车企销量增长、辅助驾驶渗透率提升,以及智驾平权趋势,共同推动车载智能驾驶方案需求增加。公司披露,中国乘用车市场中辅助驾驶渗透率已从 2024 年底的 51% 上升到 2025 年上半年的 59%;中高阶辅助驾驶功能车型占智能汽车新车销量的比例从 2024 年底的 20% 上升到 2025 年上半年的 32%。
在这个背景下,地平线车载级征程系列处理硬件出货量达到 198 万套,同比翻倍。其中,支持高速公路辅助驾驶功能的处理硬件出货量达到 98 万套,占总出货量 49.5%,为去年同期六倍。公司称这一增长主要由新一代征程 6 系列产品推动。
截至报告期末,公司累计获得近 400 款新车型定点,其中具备高速公路辅助驾驶及以上功能的定点车型超过 100 款。2025 年上半年,超过 15 款搭载中高阶辅助驾驶解决方案的车型量产上市。
海外拓展也出现早期进展。公司披露,基于征程 6B 处理硬件的新一代基础辅助驾驶解决方案 Horizon Mono 已获得两家日本车企在中国以外市场的车型定点,预计全生命周期出货量超过 750 万套。此外,国内 9 家合资车企的 30 款车型定点了公司解决方案。
收入结构变化
2025 年上半年,汽车解决方案收入人民币 1,516.3 百万元,同比增长 66.1%,占总收入 96.8%。非车解决方案收入人民币 50.4 百万元,占比 3.2%,对公司整体判断影响较小。
汽车解决方案内部发生了非常重要的结构切换:
- 产品解决方案收入人民币 777.8 百万元,同比增长 250.0%,占总收入 49.7%。
- 授权及服务业务收入人民币 738.5 百万元,同比增长 6.9%,占总收入 47.1%。
2024 年同期,产品解决方案只占总收入 23.8%,授权及服务业务占 73.9%。这意味着地平线不再主要依靠高毛利授权收入支撑收入表,而是在向“硬件出货 + 软件授权 + 技术服务”的混合模式过渡。
这个变化有两面性。积极的一面是,硬件产品放量让收入规模更容易扩大,也说明公司方案进入更多量产车型。压力的一面是,硬件产品天然毛利率低于授权业务,综合毛利率会被收入结构拖低。
毛利率分析
公司 2025 年上半年综合毛利率为 65.4%,较 2024 年同期的 79.0% 下降 13.6 个百分点。主要原因不是单个业务线盈利能力全面恶化,而是收入组合变化。
汽车产品解决方案毛利率从 2024 年同期的 41.7% 提升到 45.6%,毛利同比增长 282.5% 至人民币 354.7 百万元。这说明硬件放量和征程 6 相关产品平均售价提升,对产品毛利率有正面影响。
授权及服务业务毛利率从 93.0% 下降到 89.7%,仍然极高,但由于其收入占比下降,对综合毛利率的拉动减弱。公司解释授权及服务毛利率下降与部署最新一代处理硬件搭载的更先进解决方案相关技术服务人力增加有关。
因此,毛利率下降本身不能简单解读为竞争力恶化。更准确的理解是:公司正在用较低毛利率的产品出货换更大的市场规模和装机基础。
费用与亏损
2025 年上半年研发开支人民币 2,300.0 百万元,同比增长 62.0%,主要来自云服务费、其他技术服务采购增加,以及研发人员相关人工开支和股份支付增加。
以收入比例看,研发费用率仍高达约 146.8%。这说明公司仍处于高强度研发投入阶段,收入增长尚不足以覆盖研发体系。
销售及营销开支人民币 272.1 百万元,同比增长 37.1%;行政开支人民币 307.2 百万元,同比增长 26.3%。销售及营销费用率约 17.4%,行政费用率约 19.6%。
经营亏损人民币 1,592.1 百万元,经调整经营亏损人民币 1,111.3 百万元。经调整经营亏损率约 70.9%。即使剔除股份支付和非经常性集资开支,公司距离经营层面盈亏平衡仍有明显距离。
现金与资产负债表
截至 2025 年 6 月 30 日,公司现金及现金等价物人民币 16,069.1 百万元,现金储备非常充足。按 2025 年上半年经调整亏损净额年化粗略估算,现金约可覆盖 6 年左右的经调整净亏损。当然这只是静态估算,未来投入节奏、融资、投资和业务扩张都会改变现金消耗速度。
资产负债率从 2024 年底的 41.5% 上升至 2025 年上半年的 51.2%。负债增加主要与优先股及按公允价值计入损益的其他金融负债有关,其中非流动部分达到人民币 9,699.9 百万元,流动部分人民币 556.1 百万元。
这部分负债会对利润表造成较大公允价值变动扰动。分析经营质量时,需要把经营亏损、经调整亏损和公允价值变动亏损分开看。
营运资金质量
贸易应收款项净额从 2024 年底的人民币 703.6 百万元上升至 2025 年 6 月底的人民币 1,109.0 百万元,增长 57.6%,略低于收入同比增速。应收增长与收入增长基本匹配,没有明显失控,但规模已经需要持续跟踪。
存货从人民币 585.4 百万元上升至 791.5 百万元,增长 35.2%,低于收入增速。对于产品解决方案快速放量的阶段,这个存货增速暂时可接受。
合同负债从人民币 248.7 百万元下降至 46.3 百万元。这意味着预收款或递延收入缓冲减少,后续需要关注新订单、客户付款节奏和收入确认节奏。
粗略用平均应收、平均存货和平均应付款估算,2025 年上半年 DSO 约 105 天,DIO 约 230 天,现金转换周期约 317 天。这个数值偏长,符合汽车芯片/硬件供应链和车型项目周期较长的特点,但也意味着公司对大客户交付、回款和备货节奏有较强依赖。
客户集中度
2025 年上半年,公司客户 A、B、C 收入占比分别为 19.70%、12.76%、11.16%,前三大客户合计约 43.6%。2024 年同期,客户 C 和客户 E 占比分别为 37.62% 和 22.85%,客户结构较集中。
客户集中度高有两种解释。一方面,这说明公司已进入核心车企供应链,定点和量产项目对收入贡献明显。另一方面,大客户车型销量、采购节奏、议价能力和方案切换都会对公司收入和毛利产生较大影响。
HSD 的关键性
公司在半年报中多次强调 Horizon SuperDrive,称 HSD 已获多家整车企业定点,覆盖十余款车型,并计划于 2025 年下半年量产。
HSD 是理解公司下一阶段的核心变量。基础辅助驾驶和高速辅助驾驶硬件出货已经证明公司有量产交付能力,但未来估值叙事更大程度上取决于 HSD 能否在全场景城区辅助驾驶中建立产品体验、客户定点、量产速度和持续软件收费能力。
如果 HSD 量产顺利,并带动更高单车价值量,当前研发投入可以被解释为前置投入。如果 HSD 延迟、体验不及预期,或客户上量慢,那么研发和云服务投入会继续压制利润。
积极信号
- 收入同比增长 67.6%,汽车产品解决方案收入同比增长 250.0%,说明产品化和量产交付进入加速期。
- 征程系列处理硬件出货 198 万套,同比翻倍;支持高速公路辅助驾驶功能的处理硬件出货 98 万套,为去年同期六倍。
- 产品解决方案毛利率从 41.7% 提升到 45.6%,显示放量和产品结构升级带来一定规模效应。
- 现金储备超过 160 亿元,为高研发投入提供缓冲。
- 海外车企定点和合资车企项目增加,显示公司不只依赖单一自主品牌客户群。
主要风险
- HSD 下半年量产进度和实际用户体验存在不确定性。
- 综合毛利率可能随着硬件产品收入占比继续提升而承压。
- 研发费用和云服务费用刚性较强,收入增长尚未转化为经营亏损收窄。
- 客户集中度仍高,大客户采购节奏会放大业绩波动。
- 应收、存货和合同负债变化需要持续跟踪,尤其是量产放量后的回款质量。
- 公允价值变动和酷睿程相关会计处理会持续扰动利润表,容易掩盖经营层面的真实趋势。
后续跟踪清单
- 2025 年下半年 HSD 是否按计划量产,首批车型是谁,量产规模如何。
- 征程 6 系列出货是否继续提升,支持高速/城区辅助驾驶的产品占比是否提高。
- 产品解决方案毛利率能否维持在 45% 以上。
- 经调整经营亏损率是否随收入增长而收窄。
- 应收款增长是否继续低于或接近收入增长,账龄结构是否改善。
- 合同负债是否恢复增长,反映新项目和客户预付款情况。
- 酷睿程亏损、可转换借款和公允价值变动对利润表的扰动是否下降。
一句话判断
地平线 2025 年中期业绩显示,公司正在从高毛利授权驱动转向量产硬件与软件方案驱动,经营进展强于利润表现;当前最值得跟踪的不是短期净亏损,而是 HSD 量产、征程 6 放量、产品毛利率和经调整经营亏损率能否形成正向拐点。
---
layout: post
title: 微信作为信息源的注意力边界
subtitle: Codex 个人助理沉淀
date: 2026-06-15 20:35:20 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/active_attention/03_微信作为信息源的注意力边界.md
微信作为信息源的注意力边界
- 记录时间:2026-06-16 08:33:17 CST
- 类型:主题文章
- 标签:微信、信息源、注意力管理、手机关系、主动使用
微信为什么容易变成默认信息源
我习惯把微信当信息源,并不只是因为微信里面信息多。
更重要的是,微信把几种东西压缩在了同一个入口里:信息、关系、反馈、市场情绪、创作素材和机会感。
普通新闻 App 里的信息是冷的。它告诉我发生了什么,但不一定告诉我“谁在关注这件事”。微信里的信息不一样。一条行业消息如果出现在群聊里,被朋友转发,被熟悉的人讨论,被某个我认可的人评价,它就不只是信息,而是带上了人际权重。
所以微信对我来说不只是信息流,更像一个社交化雷达。
我看微信,可能是在看行业动态,比如智驾、地平线、投资圈讨论;也可能是在看社交信号,比如谁在关注什么、谁转发了什么、群里怎么讨论;还可能是在找内容素材,维持朋友和同行关系,或者获得即时反馈。
这些价值都是真实的。
问题不在于微信有没有价值,而在于它很容易从“工具”变成“默认注意力入口”。
微信的危险在于混合奖励
《How to Break Up with Your Phone》里有一个很重要的判断:手机不是中立工具,很多应用会利用人的新奇偏好、不确定奖励、社交认可和焦虑缓解机制,让人不断把注意力交出去。
微信尤其符合这个机制。
每次打开微信之前,我并不知道会看到什么。可能是重要消息,可能是朋友反馈,可能是投资线索,可能是行业讨论,也可能只是一些无关紧要的群聊。
正是这种不确定性,让微信比一篇固定的研报、一本书或者一份财报更容易启动。
这也是为什么“我只是回复一下微信”很容易变成一段很长的注意力漂移。
一开始的任务可能只是:
但实际流程会变成:
回复消息
等待对方回复
顺手看另一个群
看到一个话题
点进公众号或聊天记录
又想起另一个人
再回到原来的对话
到这个时候,微信已经不是一个具体任务,而是一个开放环境。
“等消息”会把注意力挂在微信上
回复微信最麻烦的地方,不是回复本身,而是回复之后的等待。
消息发出去以后,大脑会默认这件事还没有结束。只要对方还没回,我的注意力就会有一部分挂在微信上。这个未完成状态会让我反复想打开微信看一眼。
一旦打开,微信又提供了太多旁路:未读群、朋友圈、公众号、小窗、搜索、聊天记录。
所以真正要管理的不是“能不能回微信”,而是要把回复动作和等待动作切开。
一句更适合自己的规则是:
消息发出就是本次任务完成,不需要用等待对方回复来定义任务结束。
微信可以是雷达,但不能是判断终点
更合理的定位是:
可以把不同系统的分工拆开:
微信:发现线索、观察情绪、获取社交反馈
notes:沉淀观点、整理素材、形成主题
研报 / 财报 / 数据:验证判断
写作:输出阶段性结论
这样微信仍然有价值,但它不再是思考的终点。
微信里看到一个观点,不代表这个观点成立。群里讨论很热,不代表它重要。朋友转发一条消息,不代表它已经被验证。
微信适合提供“我应该关注什么”的线索,但不适合直接提供“我应该怎么判断”的结论。
用 WWW 三问给微信加阻尼
《How to Break Up with Your Phone》里有一个很实用的方法:WWW 三问。
每次想打开手机前问自己:
What For? 我要拿手机做什么?
Why Now? 为什么必须现在做?
What Else? 有没有更好的替代?
放到微信上,可以改写成:
我要打开微信做什么?
为什么必须现在看?
看完以后产出什么?
如果打开微信前,我能说清楚:
这是工具使用。
如果答案只是:
这就是默认注意力入口。
把微信拆成两个模式
微信最容易失控,是因为不同模式混在一起。回复消息、等消息、看群、找素材、处理关系、休息放松,全都混在同一个动作里。
更好的方式是拆成两个模式。
1. 发送模式
发送模式只处理明确对象,不等待。
规则是:
打开微信前先写清楚:我要回复谁?
只回复这个人。
发完立刻退出。
不等对方回。
比如:
本次微信任务:回复某个朋友关于地平线文章的问题。
完成条件:消息发出。
退出条件:发出后马上关掉微信。
这里的关键是把完成条件定义为“消息发出”,而不是“对方回复”。
2. 收件箱模式
收件箱模式用于集中处理所有未读,但不深入展开。
规则是:
固定时间看微信。
只处理收件箱。
能回就回,不能回就记录。
不因为一个群的话题临时展开研究。
如果看到有价值的信息,不要当场追下去,而是写成一条待处理记录:
待处理:看某群关于比亚迪自研芯片的讨论,可能适合做地平线素材。
然后退出。
这一步很重要。因为很多时候,让人被带走的不是信息本身,而是“我现在就顺便研究一下”的冲动。
微信 3 分钟回复法
可以先做一个很小的实验:
1. 打开微信前,说出或写下要回复谁。
2. 回复。
3. 发出后立刻退出。
4. 如果想看别的群,把群名写到 inbox,不当场点开。
这个方法不要求少用微信,只要求给每次使用加上完成条件。
只要进入微信没有完成条件,它就会自动变成开放世界。
微信信息源窗口
对于真正有价值的信息获取,可以设定固定窗口:
每天 2-3 次,每次 15 分钟。
进入前写目的。
出来后留一条记录。
例如:
本次看微信目的:看地平线 / 智驾相关信息。
看到的有效线索:
1. ...
2. ...
后续动作:查数据、写笔记,或转成文章素材。
如果一次微信信息获取结束后没有留下任何记录,那这次大概率不是信息获取,而是注意力消费。
通知也要分层
如果所有群、所有人、所有公众号都能通过通知打断我,那微信就永远不会只是工具。
通知应该按真实重要性分层:
少数紧急联系人:保留通知。
普通朋友和工作协作:固定窗口处理。
群聊和公众号:默认静默。
否则每一个群都在伪装成“可能重要”。
最终原则
微信不是不能用。
微信的问题在于,它太容易把一个明确任务变成无边界浏览,把一次回复变成等待,把一个线索变成一串分支。
所以更适合自己的原则是:
微信可以是信息雷达,但不能是判断终点。
微信可以负责连接人,但不能持续占用我的注意力主线程。
微信可以提供线索,但线索必须进入 notes、数据、研报和写作系统,才算真正变成我的东西。
下一步动作
- 试行“微信 3 分钟回复法”:只回复明确对象,发完退出,不等待。
- 设置每天 2-3 个微信信息源窗口,每次结束后至少留一条有效记录。
- 把群聊和公众号默认静默,只保留少数紧急联系人通知。
- 在 inbox 中建立“微信待处理线索”记录方式,避免当场顺手展开。
---
layout: post
title: 个人助理笔记同步到 GitHub Pages 博客流程
subtitle: Codex 个人助理沉淀
date: 2026-06-15 07:27:10 -0400
tags:
- 个人助理
- 项目
- github_pages_sync
---
来源:notes/projects/github_pages_sync/01_个人助理笔记同步到博客流程.md
个人助理笔记同步到 GitHub Pages 博客流程
背景
2026-06-09,将 andywu1998.github.io 仓库中已有的个人助理笔记导入脚本封装成一键同步脚本,便于后续把 codex_personal_assistant/notes 下的正式 Markdown 笔记发布到 GitHub Pages 博客。
仓库位置
- 博客仓库:
/home/admin/code/cc-connect-work-space/andywu1998.github.io
- 个人助理仓库:
/home/admin/code/cc-connect-work-space/codex_personal_assistant
- 导入脚本:
andywu1998.github.io/scripts/import_personal_assistant_notes.py
- 一键同步脚本:
andywu1998.github.io/scripts/sync_personal_assistant_notes.sh
- 端到端总同步脚本:
codex_personal_assistant/scripts/sync_all_outputs.sh
- 兼容入口:
codex_personal_assistant/scripts/sync_feishu_and_blog.sh,内部转发到 sync_all_outputs.sh
- 私密数据加密发布脚本:
codex_personal_assistant/scripts/publish_private_blog_data.js
- 私密博客密钥配置:
codex_personal_assistant/config/private_blog_secret.json
- 博客私密入口:
andywu1998.github.io/private.html,访问路径为 /private/
一键同步命令
如果本轮是“帮我记一下”这类个人助理记录,推荐使用总同步脚本:
cd /home/admin/code/cc-connect-work-space/codex_personal_assistant
scripts/sync_all_outputs.sh
它会先同步飞书多维表格和飞书日历,再提交并推送个人助理仓库,然后调用博客同步脚本发布笔记到 GitHub Pages。
总同步脚本还会在博客同步前执行私密数据发布:
node scripts/publish_private_blog_data.js
该脚本读取 logs/daily_log.md、tasks/todo.md、tasks/in_progress.md、tasks/done.md,在私密仓库侧解析为结构化 JSON,并使用 config/private_blog_secret.json 中的密钥加密。博客仓库只接收密文文件:
andywu1998.github.io/assets/private/personal-assistant.encrypted.json
博客页面 /private/ 通过浏览器 Web Crypto API 输入密钥后解密,并在本地展示日历、日志、待办和搜索。
如果只想同步博客,可以直接运行博客仓库脚本:
cd /home/admin/code/cc-connect-work-space/andywu1998.github.io
scripts/sync_personal_assistant_notes.sh
脚本支持把参数透传给 Python 导入脚本,例如:
scripts/sync_personal_assistant_notes.sh --days 3
执行流程
博客同步脚本
- 切到
andywu1998.github.io 仓库根目录。
- 执行
python3 scripts/import_personal_assistant_notes.py --clean "$@"。
- Python 脚本扫描
../codex_personal_assistant/notes 下的 Markdown 笔记。
- 排除
.tmp、.venv、.venv_mobi_tools、source_materials、__pycache__。
- 为每篇笔记生成 Jekyll front matter,并写入博客
_posts/。
- Reader 首页在 Jekyll 构建时直接通过 Liquid 遍历
site.posts 获取文章列表和内容,不再需要额外生成 reader-posts.json。
- 如果工作区没有变化,输出
No changes to commit. 并退出。
- 如果有变化,执行
git add _posts。
- 使用
$(date +%F) sync 作为 commit message,例如 2026-06-09 sync。
- 执行
git push 推送到 origin/master。
- GitHub Pages 仓库的 CI 在 push 后运行 Jekyll build。
飞书 + 博客总同步脚本
codex_personal_assistant/scripts/sync_all_outputs.sh 的执行流程:
- 显示个人助理仓库状态。
- 执行
python3 scripts/sync_daily_log_outputs.py,同步飞书多维表格和飞书日历。
- 如果个人助理仓库有变更,执行
git add -A、commit、push。
- 切到博客仓库前,执行
node scripts/publish_private_blog_data.js,刷新私密密文数据。
- 切到博客仓库,执行
scripts/sync_personal_assistant_notes.sh。
- 博客脚本负责导入
_posts,并提交 _posts、private.html、私密页面静态资源和 assets/private 密文数据。
- 最后显示个人助理仓库和博客仓库状态。
常用参数:
scripts/sync_all_outputs.sh --dry-run
scripts/sync_all_outputs.sh --skip-feishu
scripts/sync_all_outputs.sh --skip-blog
scripts/sync_all_outputs.sh --skip-personal-git
scripts/sync_all_outputs.sh -m "2026-06-11 personal assistant sync"
已验证结果
2026-06-09 已执行:
chmod +x scripts/sync_personal_assistant_notes.sh
scripts/sync_personal_assistant_notes.sh
执行结果:
- 导入 34 篇个人助理笔记到
_posts/。
- 生成提交:
c996d4b 2026-06-09 sync。
- 推送成功:
a95ea9c..c996d4b master -> master。
注意事项
- 该脚本只提交
_posts 目录,不会自动提交脚本自身或其他博客配置改动。
- 2026-06-11 起,Reader 已改为 Jekyll 构建时直接内嵌
site.posts 数据,不再依赖 assets/data/reader-posts.json。
- 新增或修改同步脚本后,需要单独
git add scripts/sync_personal_assistant_notes.sh、commit、push。
- 新增或修改总同步脚本后,需要在个人助理仓库提交
scripts/sync_all_outputs.sh;兼容入口 scripts/sync_feishu_and_blog.sh 会转发到新脚本。
- 默认使用
--clean 重建个人助理生成的文章,文章日期取源 Markdown 的最后修改时间,因此旧文章文件名可能随源文件 mtime 改变而发生重命名。
- 如果只想同步最近几天修改的笔记,可传
--days N,但默认流程仍会先清理旧生成文章;谨慎使用。
- 私密页面不是后端登录系统,任何人都可以下载密文和前端代码;安全性依赖密钥强度、PBKDF2 派生和 AES-GCM 加密。不要把明文日志、明文待办、密钥或解密后的 JSON 写入博客仓库。
- 当前私密数据密钥保存在私密个人助理仓库
config/private_blog_secret.json。如需提升抗暴力破解能力,应替换为更长的随机口令。
后续动作
- 如需一键同时提交脚本自身,可扩展
git add _posts scripts/sync_personal_assistant_notes.sh。
- 如需避免旧文章重命名,可在导入脚本中改为读取源文件内固定日期或维护路径到文章文件名的映射。
---
layout: post
title: 肉身梭哈与注意力梭哈
subtitle: Codex 个人助理沉淀
date: 2026-06-12 12:37:07 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/active_attention/02_肉身梭哈与注意力梭哈.md
肉身梭哈与注意力梭哈
- 记录时间:2026-06-13 00:36:24 CST
- 类型:原文记录
- 标签:职业选择、科技公司、投资观察、长期跟踪、内容创作
摘要
科技从业者的职业选择本质上可能是一种“肉身梭哈”:把自己的时间、简历、现金收入和股权收益押在某家公司或某个产业周期上。早期加入成长型公司可能吃到市值上涨红利,但如果高位进入、股价下跌,公司也可能裁员,个人同时承受财富预期和职业稳定性的冲击。
当“肉身梭哈”失败或机会窗口变小后,可以转向“注意力梭哈”:选择一家仍处早期、产品和创始团队有特点、长期有素材的公司,持续研究、记录、写作和连接相关人群。真正看好一个公司时,股价低迷时更应该持续更新,而不是等股价上涨后才追热点。
原文
肉身梭哈
在我21年毕业选择offer的时候,当时有阿里、百度、Shopee,这几个选择,然后当时Shopee发展地很好,股价也涨得猛,一度和国内的美团一样千亿美元市值。
当时我同学问我咋不去阿里,我说一个是我不想卷了,国内互联网没有前途,另外一个我觉得sea集团以后就是东南亚的阿里+腾讯。
我入职那年年终发了一点股票,大概是290美元一股。
后面股价跌到50多,公司就在大规模裁员了,然后我就领了大礼包。刚看了一下在我离职之后最低跌到34。
我记得股价高位的时候部门来了个架构师,应该这种大佬的薪资里很大一部分是股票,我有时候听他在工位说“昨天晚上公司价又跌了”。
类似的故事还有陆奇在百度的时候百度接近千亿市值,陆奇离职后最低跌到300亿左右。
蚂蚁即将上市之前据说杭州很多高管都在看房。
对于科技从业者来说,股价确实很影响工作!
好的案例是比如早期加入bat字节这些公司,吃到公司市值上涨的红利,不好的案例就是像之前我和我的前同事那样,股价下跌就开始裁员,喜提大礼包。
注意力梭哈
上面说的肉身梭哈,在刚毕业的时候肉身梭哈失败了,基本上没啥希望了。
下一个就是注意力梭哈。
找一家尚在早期的企业,持续关注。
比如地平线、理想这一类科技公司。
有一个公众号叫“理想TOP2”,他的简介写着“花20年,中性分析理想”
确实产品做得不错,创始人有自己的想法,公司很有特点,其实会有非常多的创作素材。
最近更新地平线系列有点频繁,起初是我在雪球上看到几位球友写得很好就转载过来。后面又想到苏箐、余凯的观点其实也很多创作素材。
另外一个,如果真的看好一个公司,就得在股价低的时候更要更新。而不是股价涨了过来蹭热点。
长期关注是有好处的,比如我现在对智驾行业就有所了解,然后也因为投资这个认识了很多朋友。也因为最近得到了地平线管理层的关注。
比如像比亚迪自研这个事情,我是越来越清楚了。这种假的叙事逻辑崩塌根本就不影响我的判断。
下一步动作
- 把“注意力梭哈”作为一个长期内容策略:持续跟踪地平线、理想等少数公司,而不是分散追热点。
- 对每个长期跟踪公司维护固定素材池:创始人观点、管理层访谈、财报、产品进展、产业争议和市场叙事。
- 股价低迷时优先记录判断依据和反方叙事,避免只在上涨时写作。
---
layout: post
title: 《Elon Musk》迁移与早期创业解读:从逃离南非到互联网浪潮
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/07_迁移与早期创业_从逃离南非到互联网浪潮解读.md
《Elon Musk》迁移与早期创业解读:从逃离南非到互联网浪潮
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 5 章 Escape Velocity、第 6 章 Canada、第 7 章 Queen's、第 8 章 Penn、第 9 章 Go West、第 10 章 Zip2、第 12 章 X.com、第 13 章 The Coup。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释马斯克如何从“逃离南非”进入互联网创业浪潮,并在 Zip2 与 X.com/PayPal 中形成关于速度、资本、产品、技术架构和控制权的早期经验。
1. 结论
马斯克从南非到加拿大,再到美国和硅谷,不只是地理迁移,而是一条“逃离旧系统、寻找新战场、押注技术浪潮”的路径。
这段经历塑造了他后来的几个核心模式:
- 逃离不是休息,而是寻找更大的竞争场。
- 贫穷和移民处境强化了他的风险承受力。
- Queen’s 和 Penn 这两所大学给了他社交、物理、商业和策略游戏的训练场。
- 硅谷让他意识到技术浪潮比传统职业路径更有杠杆。
- Zip2 让他第一次学到:产品、代码和创始人愿景会被资本和职业经理人重新塑形。
- X.com/PayPal 让他进一步学到:网络效应、品牌信任、金融系统和控制权会决定公司方向。
- PayPal 政变给他留下深刻教训:如果不能控制公司,创始人的宏大愿景会被组织政治、风险偏好差异和短期聚焦逻辑压制。
这段不是 SpaceX/Tesla 的前奏那么简单。它是马斯克“必须控制方向”的起源之一。
2. 离开南非:逃离旧环境,而不是单纯追求美国梦
第 5 章标题是 Escape Velocity,这个词很准确。逃逸速度原本是航天概念,意思是物体摆脱引力束缚所需的速度。Isaacson,也就是本书作者 Walter Isaacson,用它写马斯克离开南非,暗示这不是普通留学,而是逃离一个强大引力场。
这个引力场包括:
- 父亲 Errol Musk 的情绪压迫和现实扭曲。Errol 是马斯克的父亲,书中把他写成对马斯克早年心理影响很深的人。
- 南非社会环境中的暴力和封闭。
- 马斯克对更大技术世界的渴望。
- 对美国硅谷和未来产业的想象。
17 岁时,马斯克意识到自己必须离开。他先尝试直接去美国,发现通过母系的加拿大身份更现实,于是自己去加拿大领事馆办护照,还给母亲、弟弟、妹妹填了申请,但没有给父亲填。
这个细节很关键。它说明他不是被动被家庭安排出国,而是在主动设计逃离路线。他还没有公司、资本和成熟能力,但已经具备后来反复出现的行为模式:先确定目标,再寻找可行路径,不等别人同意。
3. 加拿大阶段:移民处境和金融系统问题的早期刺激
到加拿大后,马斯克并没有带着巨额财富开始创业。书中特意纠正了“靠父亲翡翠矿暴富”的传言。他带着有限现金、亲戚名单和一包书抵达蒙特利尔,先住青年旅舍,再买 Greyhound 通票横穿加拿大。Greyhound 是北美长途巴士公司,类似跨城市大巴网络。
这里有几个重要经验。
第一,他真正体验了低资源状态。农场劳动、清理粮仓、住一居室、睡沙发、母亲多份工作维持家庭,这些让他早期不是以舒适阶层身份进入北美,而是以移民和低成本生存者的身份重新开始。
第二,旅途中丢失旅行支票和衣物,让他第一次直观感受到支付系统的低效。书中明确指出,补办旅行支票耗时数周,这成为他后来理解金融支付系统需要被改造的一个早期体验。
第三,艰苦工作没有让他转向稳定保守,反而强化了他对高杠杆技术路径的追求。普通路径是找工作、读书、稳定下来;马斯克的路径是把这些经历转化成对系统缺陷的敏感度。
4. Queen’s:第一次获得社交接纳,也训练竞争策略
Queen’s 指 Queen’s University,加拿大安大略省金斯顿的一所大学,不是公司。马斯克 1990 年进入 Queen’s,本科早期两年在这里度过。
马斯克在 Queen’s 的选择很有意思。他没有去工程更强的 Waterloo,也就是加拿大滑铁卢大学,而是选择社交环境更吸引他的 Queen’s。这说明他当时并不只是技术脑,也强烈渴望摆脱童年的孤独。
在 Queen’s,他遇到 Navaid Farooq。Navaid Farooq 是马斯克在大学认识的朋友,书中称他是马斯克家庭之外第一个真正持久的朋友之一。两人因为电脑、棋盘游戏、历史和科幻建立联系。对一个长期孤独的人来说,这不只是友情,而是第一次进入“可以做自己”的环境。
但 Queen’s 更重要的是策略训练。
他沉迷策略游戏,包括 Diplomacy、Civilization、Warcraft 这类资源管理和帝国建设游戏。这些游戏训练了几个后来会在商业里反复出现的能力:
- 资源配置。
- 技术路线选择。
- 供应链与生产设施建设。
- 联盟、威胁和谈判。
- 对胜负节点的判断。
他还在商业模拟课里逆向工程游戏规则,从而反复获胜。这和他后来的第一性原理有相似之处:他不是只在规则内努力,而是试图理解规则生成机制。
Queen’s 也暴露了一个矛盾。他后来把这里的收获描述为学会协作和苏格拉底式讨论,但书中也讽刺地指出,这项能力后来只被部分打磨完成。也就是说,他学会了和聪明人共同追求目标,但并没有完全学会平衡权力、同理心和合作关系。
5. Penn:物理、商业和社交外壳的形成
Penn 指 University of Pennsylvania,中文通常译为宾夕法尼亚大学,是美国常春藤盟校,不是公司。马斯克 1992 年从 Queen’s 转到 Penn,后来在那里学习物理和商业。
马斯克转到 Penn 后,进入了更接近美国精英路径的环境。他选择物理,是因为他相信工程问题要回到最基本的物理原理;同时学习商业,是因为他不想被只懂商业的人管理。
这两个选择后来构成他的典型组合:
- 用物理和工程判断产品可行性。
- 用商业和资本工具放大工程成果。
- 不接受纯管理者对技术方向拥有最终控制。
Penn 阶段还有一个变化:他开始通过派对走出孤独外壳。Adeo Ressi 是马斯克在 Penn 期间的重要朋友和室友式伙伴,性格外向,热衷社交和派对;书中写他帮马斯克进入更开放的社交场景。这让马斯克不再只是沉浸在书、电脑和策略游戏里的孤独青年,而开始接触美国创业文化中的社交、融资、展示和自我包装。
这很重要,因为后来的马斯克既是工程型创业者,也是极会制造叙事和注意力的人。Penn 和硅谷之间,正是这个能力开始成形的阶段。
6. 走向硅谷:抓住一次性技术浪潮
第 9 章 Go West 展示了马斯克做出的关键选择:他没有走华尔街路线,而是被硅谷吸引。
当时 Ivy League 学生常见选择是去金融行业。Ivy League 指美国常春藤盟校联盟,通常代表美国精英大学群体。马斯克认为银行家和律师对社会贡献有限。他更想去西海岸,参与互联网、电子游戏、电动车、空间技术这些新领域。
最关键的转折,是他在 Penn 最后一年想到把在线黄页和地图结合起来。他判断传统电话公司没有能力真正理解交互式互联网,于是和 Kimbal 说“为什么不自己做”。Kimbal 指 Kimbal Musk,马斯克的弟弟,后来和他一起创办 Zip2。这成为 Zip2 的起点。
Stanford 录取是他的备选项,但他没有真正进入 PhD 路径。他咨询 Scotiabank 的 Peter Nicholson 后,被提醒互联网革命一生只有一次。Scotiabank 是加拿大丰业银行,加拿大大型银行之一;Peter Nicholson 是该银行负责战略规划的高管,工程和数学背景很强,马斯克在 Queen’s 期间曾通过主动联系认识他,并在他的战略规划团队做过暑期工作。马斯克于是选择“catch the internet wave”。
这背后有一个很强的机会判断:
- 学位是可延后的。
- 技术浪潮窗口不可延后。
- 当基础设施刚出现、传统公司还没理解时,创业者可以用速度抢位。
这成为他后来的长期模式:当他认为某个技术窗口打开时,会把稳定路径放到一边,迅速押注。
7. Zip2:第一次创业训练场
Zip2 是马斯克和 Kimbal 早期创办的互联网公司,核心产品是把在线商户目录和地图导航结合起来。Zip2 的想法今天看很普通:在线商户目录加地图导航。但在 1995 年,这属于互联网早期组合创新。它不是凭空发明,而是把两个已有元素结合起来:商户信息和地图数据。
Zip2 给马斯克提供了四个训练。
7.1 产品训练:把静态信息变成交互体验
传统黄页是静态目录,Zip2 把它变成可以搜索、缩放、移动、导航的互联网产品。这里体现了马斯克的产品直觉:真正的互联网不是把纸质内容搬到网页上,而是让用户能直接操作信息。
这个思路后来延续到 X.com:金融不是把银行柜台搬到网页上,而是把钱作为数据库记录实时流转。
7.2 极限工作训练:睡办公室、写代码、快速交付
Zip2 早期资源极少,兄弟俩睡办公室、去 YMCA 洗澡、吃廉价快餐。YMCA 是北美常见社区机构,这里可理解为他们去附近公共设施洗澡。马斯克负责大量编码,甚至会在别人下班后重写同事代码。
这种强度帮助公司快速成形,但也暴露了他的管理缺陷:他追求结果,不太在意别人是否被羞辱或被冒犯。早期员工和朋友 Navaid Farooq 很快意识到,和马斯克一起工作会伤害友谊,于是离开。
Zip2 阶段已经可以看到后来所有公司的影子:高强度、低同理心、极快速度、技术下沉、亲密关系和工作关系容易冲突。
7.3 资本训练:VC 既给钱,也会重塑公司
Mohr Davidow Ventures 是硅谷风险投资机构。它投资 300 万美元后,Zip2 得到资本、签证帮助、社会合法性和商业资源。但资本也带来了“adult supervision”:职业经理人 Rich Sorkin 被引入。Rich Sorkin 是投资人安排进入 Zip2 的职业经理人,担任 CEO,马斯克从创始人 CEO 被移到 CTO。
这让他学到一个决定性教训:如果你不是 CEO,你就不真正控制产品和技术方向。
原书中他总结得很明确:他原本以为可以只当技术或产品负责人,但后来发现,如果不是 CEO,就无法真正成为首席技术或产品负责人。
这个教训后来直接影响他对 SpaceX、Tesla、Twitter/X 的控制欲。他不再相信只掌握技术愿景就够了,他要掌握最终组织权力。
7.4 战略训练:B2B 路线和消费者愿景的冲突
Zip2 在投资人和职业经理人推动下,从直接面向消费者,转向给报纸提供本地目录软件。这条路线短期更容易卖,因为报纸已有销售网络和客户关系。
但马斯克不喜欢成为无品牌供应商。他想做 city.com,直接成为消费者入口,和 Yahoo、AOL 竞争。这是他早期宏大愿景与现实商业路径的冲突。
最终公司被 Compaq 以 3.07 亿美元收购。Compaq 是当时重要的美国计算机公司,后来被惠普收购。马斯克获得 2200 万美元。财务上成功,但控制权和方向上他并不完全满意。这种“赚钱但失去方向”的经验,会在 PayPal 再次出现。
8. X.com:从支付痛点到超级金融平台愿景
Zip2 卖掉后,马斯克没有选择享受财富。他把大部分资金继续押到新公司 X.com。X.com 是马斯克 1999 年创办的在线金融公司,不是后来的普通网站名;它的目标不是做一个小工具,而是做“一站式金融平台”:银行、支付、支票、信用卡、投资、贷款都在一个系统里。
这个愿景的底层逻辑是:钱本质上是数据库里的记录。如果能让交易安全、实时、低摩擦地更新,就能重构金融系统。
这里可以看到马斯克的第一性原理雏形:他不从银行网点、柜台、清算流程出发,而从“钱是什么”这个问题出发。
同时,X.com 也复现了 Zip2 的问题。
- 他设置疯狂截止日期。
- 他睡办公室,要求别人也进入高压状态。
- 联合创始人和员工要求他下台。
- 投资人再次引入成人监管。
- 他仍然不愿放弃控制。
但 X.com 也做出非常关键的产品突破:用最少按键开户,用邮箱作为用户身份,以及让用户通过 email 转账。尤其是 email 转账,在 eBay 场景中迅速爆发。eBay 是美国电商和拍卖平台,当时大量用户需要给陌生卖家付款,所以非常适合 PayPal 这类支付工具增长。
这说明马斯克的宏大愿景里,有些部分过大、过早;但他的产品简化能力和对摩擦的敏感是真实有效的。
9. PayPal 合并:网络效应决定只能活一个
X.com 和 Confinity/PayPal 都在做个人间支付,并且都用高额拉新奖励抢用户。Confinity 是 Peter Thiel 和 Max Levchin 等人创办的公司,PayPal 是它推出的支付产品。Thiel 指 Peter Thiel,后来成为硅谷知名投资人;他形容这场竞争是看谁先烧完钱的比赛。
这时网络效应成为核心逻辑。支付产品不是孤立工具,用户越多,越值得使用;谁先形成规模,谁的增长就会更快。因此,双方如果继续互相补贴竞争,可能一起死;合并比死斗更理性。
这段让马斯克看到平台型业务的关键:
- 产品价值不只来自功能本身,还来自网络密度。
- 用户增长速度可以决定生死。
- 资本市场收紧时,烧钱竞赛必须收敛。
- 合并有时不是妥协,而是为了保住网络效应窗口。
但合并也引入了更复杂的权力结构。X.com 和 PayPal 团队文化不同,技术路线不同,风险偏好不同,品牌判断也不同。这些矛盾很快集中到马斯克身上。
10. PayPal 阶段的关键冲突:宏大愿景 vs 聚焦支付
PayPal 成长最快的部分,是 eBay 上的支付服务。Thiel、Levchin、Hoffman 等人更倾向于聚焦这个已经验证的场景,成为强大的支付工具。Levchin 指 Max Levchin,Confinity/PayPal 的技术核心;Hoffman 指 Reid Hoffman,PayPal 早期高管,后来创办 LinkedIn。
马斯克则不满足。他认为支付只是开场,真正目标是改造整个金融系统。他坚持 X.com 品牌,想把 PayPal 作为更大金融平台的一部分。
这不是简单谁对谁错,而是两种创业逻辑冲突:
- 马斯克逻辑:如果只做支付,就错过重构金融系统的机会。
- PayPal 团队逻辑:如果不聚焦 eBay 支付,就会被 fraud、技术债、品牌混乱和资金消耗拖死。
从短期公司生存看,PayPal 团队更现实;从马斯克长期执念看,X.com 愿景一直没有消失。二十多年后他收购 Twitter/X,仍然提到社交网络加支付平台可以实现当年 X.com 的构想。Twitter/X 指原 Twitter 社交平台,马斯克 2022 年收购后改名为 X。
这说明 PayPal 不是他放下的项目,而是一个未完成的心理和战略母题。
11. 技术架构冲突:Windows vs Unix 不是纯技术问题
Musk 和 Max Levchin 关于 Windows/Unix 的争论,表面上是操作系统选择,实际是权威、判断和技术文化的冲突。Windows 是微软的操作系统体系;Unix 是一类多用户、多任务操作系统及其衍生系统,早期互联网基础设施中使用广泛。
Levchin 认为 Windows NT 不安全、不稳定、不适合这个业务;马斯克则信任微软体系,希望统一到他认可的方向。最终马斯克推动团队花一年重写代码,Levchin 认为这浪费了宝贵时间,也让公司没能集中处理欺诈问题。
这段很重要,因为它显示马斯克的技术判断并非总是高效。他有强大的跨领域理解能力,也能突然击中技术细节;但当他把控制欲和技术偏好绑定时,也可能让组织付出巨大机会成本。
这给工作系统一个很好的复盘框架:
- 一个判断是基于第一性原理,还是基于控制欲?
- 技术重构是否真的服务用户增长和风险控制?
- 领导者的高智商判断,是否掩盖了团队更接近一线的问题?
12. PayPal 政变:控制权创伤的关键来源
2000 年 PayPal 政变是这段的高潮。这里的“政变”不是政治事件,而是公司内部权力更替:核心高管和董事会联合,把马斯克从 CEO 位置上撤下。Levchin 对欺诈问题焦虑,认为马斯克没有足够重视;Thiel 等人认为 PayPal 品牌更有价值,反对马斯克坚持 X.com;多位核心人物最终联合董事会,在马斯克蜜月期间把他从 CEO 位置上拿下。
马斯克感到被背叛。他认为自己投入了所有精力和大量资金,却没有机会为自己辩护。回到公司后,他试图反击、说服 Hoffman、争取董事会,但最终失败。
这次失败有两个层面。
第一,治理层面:公司不是只属于创始人个人。董事会、投资人、核心团队、技术风险、品牌判断都会决定 CEO 是否还能继续领导。
第二,心理层面:马斯克再次体验到“我创建的东西被别人接管”。Zip2 已经发生过一次,PayPal 又发生一次。对一个强控制、高使命感、害怕被边缘化的人来说,这会强化一个结论:以后必须掌握最终控制权。
后来他在 SpaceX、Tesla、Twitter/X 中对股权、董事会、CEO 位置和产品方向的执着,都可以从这两次经历看到来源。
13. 他在失败中的现实感
值得注意的是,马斯克不是只会硬扛到底。PayPal 被罢免后,他很快表现出一种现实感:他告诉追随者不要辞职抗议,愿意让公司活下去,也努力修复与 Thiel、Levchin 等人的关系。
这点很重要。马斯克是 street fighter,但不是完全不会计算结果。当继续斗争会毁掉公司时,他能接受失败,把筹码转向下一局。
这也是他后来成功的一个关键:
- 他会all-in。
- 他会强烈反击。
- 但在某些关键失败后,他也能把失败转化为下一轮资源。
PayPal 后来上市并被 eBay 收购,马斯克获得约 2.5 亿美元。这笔钱成为 SpaceX、Tesla 和 SolarCity 等后续押注的资金基础。SpaceX 是马斯克后来创办的商业航天公司;Tesla 是他后来领导的电动车和能源公司;SolarCity 是马斯克参与推动、由其亲属创办的太阳能公司,后来被 Tesla 收购。也就是说,虽然他失去 CEO 位置,但保留了经济收益和未来创业弹药。
14. 这段经历对后来的马斯克意味着什么
这段迁移与早期创业经历,至少留下五个长期影响。
14.1 速度崇拜
从 Zip2 到 X.com,他反复用极限期限推动团队。速度确实创造了窗口优势,但也制造了怨恨、人员流失和组织不稳定。
14.2 控制权执念
两次被职业经理人、投资人或合伙人边缘化,让他形成强烈信念:如果不是 CEO,就不能真正控制技术和产品方向。
14.3 宏大平台愿景
Zip2 想做城市入口,X.com 想做金融入口,后来的 Tesla、SpaceX、Twitter/X 也都有平台化和系统化倾向。他不满足于单点产品,更想控制基础设施。
14.4 高风险资本循环
Zip2 的 2200 万美元没有变成保守财富,而是投入 X.com;PayPal 的 2.5 亿美元又继续投入 SpaceX 和 Tesla。他的模式是不断把上一局收益押到下一局更大的游戏。
14.5 对组织政治的警惕
PayPal 政变让他明白,技术正确、愿景宏大、资金投入都不足以保证控制权。公司内部联盟、董事会判断、品牌数据、风险问题都会改变权力结构。
15. 管理启发
15.1 区分“机会窗口”和“稳定路径”
马斯克放弃 Stanford,不是因为学历没价值,而是因为互联网窗口不可复制。做决策时可以记录:这是可延后的稳定路径,还是不可延后的机会窗口?
15.2 重要项目要提前定义控制权
如果一个项目强依赖你的长期愿景,就不能只定义任务,还要定义谁有最终决策权、谁能改方向、谁控制资源。
15.3 警惕宏大愿景压过当前验证
X.com 的超级金融平台愿景很大,但 PayPal 真正增长来自 eBay 支付场景。复盘时要问:当前最强 traction 是什么?我是不是因为不满足于“小成功”而破坏了已验证路径?
15.4 技术重构必须绑定业务风险
Windows/Unix 争论说明,技术路线不能只看领导者偏好。重构必须回答:它解决什么用户问题,降低什么风险,是否值得牺牲增长和反欺诈资源?
15.5 失败后保留下一局筹码
马斯克被 PayPal 罢免后没有毁掉公司,也没有让追随者集体离开。这保留了股权价值和关系网络。个人项目失败时,也要问:怎样结束这一局,才能保留下一局的现金、信用和人脉?
16. 一句话总结
马斯克从南非到 PayPal 的早期路径,是从逃离旧环境到押注互联网浪潮的连续升级;Zip2 和 X.com/PayPal 让他学会了速度、产品、资本和网络效应,也让他形成了一个深刻信念:没有控制权,宏大愿景就会被现实组织力量改写。
---
layout: post
title: 《Elon Musk》管理算法解读:删除、简化、加速、自动化
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/10_管理算法_删除简化加速自动化解读.md
《Elon Musk》管理算法解读:删除、简化、加速、自动化
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 18 章 Musk's Rules for Rocket-Building、第 46 章 Fremont Factory Hell 中的 The algorithm,以及 SpaceX、Tesla、Starship、Twitter/X 多处关于需求质疑、删除流程、现场加速和自动化顺序的案例。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释马斯克式管理算法的有效边界和误用风险。
1. 结论
马斯克的管理算法可以概括为五步:
- 质疑每一项需求。
- 删除尽可能多的部件、步骤和流程。
- 简化并优化剩下的部分。
- 加快循环速度。
- 最后才自动化。
这套算法的价值,是把组织从官僚惯性、过度设计、供应商锁定和流程崇拜里拉出来。它迫使团队回到最基本的问题:这个要求是谁提的?为什么存在?删掉会怎样?真正受物理或用户约束的是什么?
但它也有明显风险:
- 删除过头会破坏冗余和安全边界。
- 加速过头会让团队进入恐惧驱动。
- 把硬件工程算法迁移到社会系统时,会低估信任、舆论、治理和人的承受力。
- 自动化顺序如果搞反,会把混乱流程固化。
这套算法最适合处理工程系统和制造系统中的浪费,不适合被当成所有组织问题的万能刀。
2. 算法不是口号,而是从失败中提炼出来的
书中对算法的呈现很重要:它不是马斯克一开始就完整拥有的管理理论,而是在 SpaceX 和 Tesla 多次危机中被逐步打磨出来的。
SpaceX 早期,他从火箭供应商的离谱报价中学到要质疑成本;从 NASA 和军工流程中学到要质疑需求;从 Falcon 失败中学到要快速测试和真实反馈。
Tesla 阶段,尤其是 Model 3 production hell,他从过度自动化失败中学到:自动化应该放在最后,而不是最前面。流程如果没有被理解,机器人只会让问题更难修改。
所以这套算法不是抽象管理哲学,而是危机经验的压缩版。它真正有用的地方,是把复杂问题转化成一组连续动作。
3. 第一步:质疑每一项需求
马斯克对需求的基本态度是:所有需求都应被怀疑,尤其是来自聪明人的需求。因为聪明人写出的需求更容易被别人无条件接受。
这一步的关键不是“反规则”,而是追问需求来源:
- 谁提出了这个要求?
- 它解决什么真实问题?
- 它是物理约束、法律约束、安全约束,还是组织习惯?
- 如果删掉,会发生什么可验证后果?
- 有没有更低成本的方式满足同一目的?
这一步在 SpaceX 特别有效。传统航天有大量规格、审查和文档,其中有些来自真实安全经验,有些来自多年叠加的组织惯性。马斯克的做法是把权威从文件转回现实:如果需求无法解释,就不能默认保留。
风险也在这里。很多安全规范看起来繁琐,是因为它们承载了过去失败的教训。质疑需求是必要的,但不能把“我暂时不理解”误判为“它没有价值”。
4. 第二步:删除,而不是先优化
算法最反直觉的一点,是先删除,不是先优化。
普通组织遇到复杂流程,常见反应是优化:加工具、加人、加会议、加自动化、加协调层。马斯克的反应是删除:这个步骤能不能不存在?这个零件能不能取消?这个审批能不能砍掉?这个指标能不能合并?
删除之所以重要,是因为优化一个本不该存在的东西,是最隐蔽的浪费。
SpaceX 的零件自制、Tesla 的产线调整、Starship 的快速迭代,都体现这种倾向。马斯克常常要求团队删得更狠,并提醒如果最后没有把一些东西删错,说明删得还不够多。
这句话有启发,也危险。启发在于,真正的删除需要承担犯错成本;危险在于,组织可能为了迎合领导者而删除安全冗余、维护能力或人的缓冲。
5. 第三步:简化和优化剩下的部分
删除之后,才是简化和优化。这里的顺序很关键。
如果没有先删除,优化会让系统越来越复杂。每个部门都在自己的局部做优化,最后整体反而更慢。先删除,才能迫使团队面对系统的核心路径。
简化包括:
- 减少零件数量。
- 减少接口。
- 减少审批。
- 减少角色切换。
- 减少等待时间。
- 减少指标冲突。
- 让负责人直接面对结果。
这和马斯克的垂直整合有关。外包和多层供应商会增加接口,一旦接口变多,优化就变成谈判和等待。内部做虽然更难,但反馈短,修改快。
对工作系统来说,简化也很具体:一个任务如果需要跨太多工具、太多文件、太多入口,就会自然拖延。简化不是让目标变小,而是让路径变短。
6. 第四步:加快循环速度
马斯克式管理非常强调速度。速度不是简单“催快点”,而是缩短从发现问题到验证方案的循环。
在工程系统里,速度的价值很大:
- 更快暴露错误。
- 更快积累真实数据。
- 更快摆脱会议和猜测。
- 更快形成团队共同理解。
SpaceX 的测试文化就是典型例子。火箭、发动机、Starship 和 Raptor 的迭代都依赖快速试验。只要测试成本足够低,失败就不只是损失,也是数据。
但速度有边界。公共道路上的自动驾驶、社交平台的内容治理、金融系统、医疗系统,都不是单纯内部测试场。外部用户和社会承受失败成本时,速度不能单独成为最高原则。
7. 第五步:最后才自动化
最后才自动化,是 Model 3 危机后最重要的教训。
自动化本身不是错。错误在于把自动化当作解决混乱的第一步。没有稳定流程、没有清晰接口、没有成熟质量标准时,自动化会放大混乱。
正确顺序应该是:
- 先确认需求真实存在。
- 删除不必要步骤。
- 简化留下的流程。
- 用人工或半自动方式快速跑通。
- 当流程稳定后再自动化。
这对个人系统尤其有用。很多人一开始就想搭复杂自动化、模板、数据库和脚本,但真正的问题可能是目标不清、输入不稳定、复盘缺失。自动化应该服务稳定流程,而不是掩盖不稳定。
8. 这套算法为什么有效
它有效的原因有四个。
第一,它对抗组织熵增。组织天然会增加流程、角色、会议和检查点,因为每个人都想降低自己的局部风险。算法迫使组织反向运动。
第二,它把权威从职位转向解释能力。谁提需求,谁就要解释需求。不能解释,就不能只靠头衔保留。
第三,它缩短反馈周期。删除和加速让问题更快暴露,不让错误藏在长期计划里。
第四,它迫使团队面向真实约束。火箭会不会飞、车能不能下线、用户是否购买,这些结果比内部汇报更真实。
这也是为什么算法在 SpaceX 和 Tesla 多次奏效。它打穿的是大组织和成熟行业里最常见的疾病:复杂性被当成专业性,缓慢被当成稳健,成本被当成不可质疑。
9. 这套算法为什么危险
算法的危险来自三个误用。
第一,把所有需求都当成官僚浪费。现实中,有些需求代表安全、伦理、法规、历史事故和用户信任。如果删除这些需求,短期速度可能变快,长期风险会爆发。
第二,把人的承受力排除在系统之外。马斯克常把任务拆成物理和工程问题,但团队不是零件。持续高压会损害判断、信任、家庭、健康和人才保留。
第三,把工程系统方法迁移到社会系统。Twitter/X 是典型案例。社交平台不是火箭发动机。它涉及政治、广告主、用户身份、内容治理、公共讨论和品牌安全。快速删除和快速改动会影响外部信任,而信任一旦丢失,反馈不像工程测试那样清晰可逆。
10. 算法和第一性原理的关系
第一性原理回答“问题底层约束是什么”,管理算法回答“组织如何围绕底层约束行动”。
两者配合时很强:
- 第一性原理拆解成本、材料、物理和用户需求。
- 管理算法删除伪需求、压缩流程、加速验证。
但如果第一性原理变成自信过度,算法就会变成粗暴删除。真正的第一性原理不是忽视领域知识,而是把领域知识也拆清楚:哪些是惯例,哪些是历史教训,哪些是法律责任,哪些是安全边界。
11. 在工作系统中的应用
11.1 每周做一次需求审查
把正在做的任务逐条问一遍:
- 这个任务是谁要求的?
- 如果不做会怎样?
- 它服务哪个目标?
- 有没有更小的替代动作?
11.2 对流程先删后优
不要一上来优化所有流程。先删掉低价值记录、重复入口、无用模板和只为安心存在的检查项。
11.3 设定“删除回滚点”
删除不是永久不可逆。可以把删除动作设置为试验:先暂停一周,如果出问题再恢复。这样能降低删除恐惧。
11.4 自动化前必须跑通三次
任何自动化前,先人工跑通至少三次,确认输入稳定、输出有用、异常情况可处理。
11.5 给速度加上代价指标
只记录“更快完成”会鼓励透支。应同时记录睡眠、情绪、返工、人际摩擦和后续维护成本。
12. 一句话总结
马斯克的管理算法真正有价值的地方,是用质疑、删除、简化、加速和最后自动化来对抗复杂系统的惯性;真正危险的地方,是当它被脱离领域边界和人的承受力使用时,会把高效工程方法变成高伤害组织方法。
---
layout: post
title: 《Elon Musk》私人关系解读:高成就背后的长期代价
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/13_私人关系_高成就背后的长期代价解读.md
《Elon Musk》私人关系解读:高成就背后的长期代价
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 11 章 Justine、第 16 章 Fathers and Sons、第 26-27 章关于离婚和 Talulah、第 35 章、第 39 章、第 44 章 Rocky Relationships、第 49 章 Grimes、第 56 章 Family Life、第 61 章、第 68 章 Father of the Year、第 75 章 Father's Day,以及全书关于 Errol、Kimbal、孩子和伴侣关系的段落。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释马斯克的高成就系统如何在亲密关系、家庭关系和自我稳定上产生长期代价。
1. 结论
《Elon Musk》里的私人关系线,不是商业主线的花边,而是理解马斯克行为模式的关键证据。
书中反复显示:马斯克可以把极端能量投入公司危机、火箭发射、工厂产线和平台改造,但同一套人格系统进入亲密关系后,常常带来伤害。
这条线有几个核心结论:
- 童年创伤和父亲阴影没有消失,而是长期影响他处理冲突、亲密和控制的方式。
- 他强烈渴望陪伴和家庭,但经常用任务、强度、控制和情绪波动破坏关系。
- 他能在使命中承受极端压力,却不擅长为身边人提供稳定情绪环境。
- 伴侣、孩子、兄弟姐妹和朋友经常被卷入他的高压系统。
- 高成就不是免费资源,代价会在家庭、信任、健康和长期关系里显现。
这部分最重要的提醒是:如果一个人的操作系统只为任务胜利优化,亲密关系会被当成附属变量,最后成为长期债务。
2. 父亲 Errol:逃离与重复
马斯克和父亲 Errol 的关系,是全书最深的心理底色之一。Errol 在书中呈现为复杂、聪明、危险、情绪不可预测且具有伤害性的人。马斯克一方面极力与父亲切割,另一方面又被身边人指出在压力下会重复某些类似模式。
这种“逃离与重复”很常见。一个人可能在意识层面厌恶某种父母模式,但在高压、恐惧或失控时,身体会自动调用早年学到的冲突方式。
对马斯克来说,这种重复表现为:
- 语言攻击。
- 情绪骤变。
- 对弱点的低容忍。
- 把控制当成安全。
- 在冲突中升级而不是安抚。
这并不意味着他等同于父亲,而是说明创伤不只是记忆,它也会成为行为模板。除非被持续觉察和修正,否则人会在反抗旧模式时携带旧模式。
3. Justine:亲密关系被使命和控制挤压
Justine 是理解马斯克早期婚姻的重要人物。两人在大学和早期创业阶段相识,关系中既有吸引、浪漫和共同成长,也有权力、控制和情绪伤害。
马斯克在创业阶段的状态,几乎总是把公司危机放在最高优先级。他不是普通意义上的忙,而是会把人生组织成任务战场。伴侣关系很容易被卷入这个战场:支持他的使命、承受他的缺席、适应他的强度、接受他的节奏。
问题在于,亲密关系不能长期只靠对方适应。它需要稳定回应、情绪承接、平等协商和共同生活秩序。马斯克擅长动员人共同完成不可能任务,却不擅长让关系中的另一个人感到被平等看见。
这段关系还伴随孩子夭折的巨大创伤。失去孩子本应需要共同哀悼和支持,但马斯克的典型方式是关闭痛苦、继续前进。这种处理方式或许帮助他活下来,却会让伴侣感到孤立。
4. 情绪关闭:高压中的能力,关系中的隔离
马斯克很早学会在痛苦中继续运转。这让他能在 SpaceX 和 Tesla 濒死时保持行动,也让他在巨大压力下不轻易崩溃。
但情绪关闭有代价。一个人关闭恐惧和痛苦时,往往也会关闭柔软、共情和亲密中的可接近性。
在公司里,这种关闭可能被解释为冷静、坚强、使命优先;在家庭里,它可能表现为:
- 无法共同处理悲伤。
- 不愿停下来倾听。
- 把对方情绪视为干扰。
- 用解决问题替代陪伴。
- 在关系需要修复时继续切换到任务模式。
这不是简单“工作太忙”,而是系统问题:当一个人的核心能力来自情绪切断,他就很难在亲密关系里保持情绪开放。
5. Talulah:反复靠近与反复退出
Talulah Riley 相关章节显示了马斯克关系模式中的另一个特征:强烈吸引、快速靠近、反复分开和重新连接。
这类关系节奏常见于高波动人格和高压生活。马斯克需要陪伴,也渴望被理解;但当工作危机、情绪低谷或控制需求上升时,关系就会被拉扯。
亲密关系需要可预测性,而马斯克的生活充满不可预测性:
- 公司危机随时优先。
- 情绪状态波动明显。
- 工作地点和生活安排不断变化。
- 重大决定经常以极高速度发生。
这会让伴侣长期处在等待、适应和不稳定中。关系可能有强烈情感,但缺少稳定生活结构。
6. Grimes:创造性吸引与混乱生活系统
Grimes 与马斯克的关系体现了另一种吸引:科技、未来、艺术、幽默、网络文化和宏大想象的共振。两人都带有强烈创造性和非常规气质,因此关系一开始有高度互相吸引。
但吸引不等于稳定系统。孩子、工作、公众关注、平台争议、居住安排和马斯克多重关系网络,使这段关系长期处在复杂状态中。
这说明对马斯克来说,亲密关系经常不是安静生活的基础,而是被纳入他的高速世界:媒体、项目、孩子、公司、舆论和个人身份交织在一起。
创造性相似可以点燃关系,但维持关系还需要边界、节奏、责任分配和可预期承诺。
7. 孩子:强烈父职愿望与陪伴能力之间的裂缝
书中多处写到马斯克对孩子的重视。他希望有很多孩子,也关心文明延续、人口问题和家族未来。从理念上,他非常强调生育和下一代。
但父职不是只有理念。父职还包括稳定陪伴、情绪可得、日常照料、尊重孩子独立性,以及在孩子与自己价值观不一致时仍保持连接。
马斯克在这方面明显存在裂缝。他可以用宏大叙事解释孩子和未来,却很难在每段关系里提供稳定、低压、不被任务吞噬的父亲角色。
尤其当孩子的身份、价值观或选择与他冲突时,他容易把问题解释为外部意识形态侵蚀,而不是先进入具体关系修复。这种解释方式能保护他的自我叙事,却可能进一步拉远亲子关系。
8. Kimbal:亲密战友关系也会被高压损伤
Kimbal Musk 是马斯克生命中非常重要的人:弟弟、创业伙伴、家庭连接者,也是少数长期理解他的人之一。
但即使是 Kimbal,也会被马斯克的高压和攻击性伤害。书中写到两人的关系曾出现明显裂痕。这说明马斯克的模式不是只伤害不理解他的人,也会伤害最亲近、最支持他的人。
亲密战友关系有一个风险:因为对方长期理解你、包容你、和你共同经历危机,你会默认对方能承受更多。但承受不是无限资源。越亲近的人,越容易被当成系统缓冲垫。
这对工作系统很有启发:最支持你的人,不应该成为你最常透支的人。
9. 朋友和伴侣常被任务系统吞没
马斯克的许多关系都带有任务化倾向。朋友可能变成投资者、同事、顾问、战友;伴侣可能被卷入公开叙事、搬家、孩子安排和工作节奏;家庭聚会也可能被公司危机中断。
这不只是他个人时间少,而是他很难把“非任务关系”作为独立价值保存下来。
当一个人长期用任务衡量世界,关系会被分成两类:
这种分类对创业有效,对亲密关系有害。亲密关系的很多价值无法立刻服务任务:一起吃饭、倾听、休息、陪伴、共同无所事事、重复小事。这些低效率时间恰恰是关系的基础设施。
10. Demon mode:公司里的推进力,关系里的伤害源
书中多次提到马斯克的黑暗状态或 demon mode。进入这种状态时,他可以极端专注、强硬、攻击、压缩时间线,也会对周围人造成强烈压力。
在公司危机里,这种状态有时能推动事情穿过瓶颈;在亲密关系里,它几乎总是破坏性的。
因为亲密关系不是靠压服解决的。伴侣和孩子不应该被当成低效流程、错误代码或供应商瓶颈。对亲近的人使用战时模式,会让对方逐渐学会防御、撤退或断开连接。
这也是高成就者常见误区:在外部世界有效的强控制,进入家庭后会变成不安全感来源。
11. 高成就的隐性账单
马斯克的故事容易让人只看结果:火箭成功、电动车普及、公司市值、技术突破、平台控制。但私人关系线把账单展示出来。
这些账单包括:
- 离婚。
- 伴侣关系反复破裂。
- 孩子关系紧张。
- 兄弟关系裂痕。
- 朋友离开。
- 团队成员被伤害。
- 自身长期睡眠和情绪问题。
这不是为了否定成就,而是为了反对一种危险叙事:只要成果足够大,关系代价就可以忽略。
对个人系统来说,关系代价不是外部噪音,而是长期能力的一部分。一个人如果长期损耗关系,最后会损耗反馈、支持、信任和恢复能力。
12. 私人关系线的管理启发
12.1 把关系作为核心资产记录
不要只记录工作成果。重要关系也需要记录:最近一次高质量交流是什么时候?是否有未修复冲突?是否长期只在索取支持?
12.2 高压状态禁止处理亲密冲突
睡眠不足、愤怒、羞辱冲动和控制欲上升时,不适合做亲密关系中的重大决定。先暂停,再沟通。
12.3 区分陪伴和解决问题
对方表达痛苦时,不一定需要方案。复盘时可以提醒:此刻目标是陪伴、确认和理解,不是立刻优化。
12.4 不要让最亲近的人承担最多副作用
如果工作压力总是转嫁给家人、伴侣或最亲近朋友,说明系统没有真正消化压力,只是把成本外包给关系。
12.5 为恢复留出不可侵占时间
高强度任务后需要恢复窗口。没有恢复,关系会变成压力释放口,而不是支持系统。
13. 一句话总结
马斯克的私人关系线说明,高成就系统如果只为使命、速度和控制优化,就会把亲密关系变成长期代价;真正成熟的个人操作系统,必须把关系、恢复和情绪责任纳入核心指标,而不是把它们当成任务之外的附属品。
---
layout: post
title: 《Elon Musk》早年经历解读:痛苦、孤独与高强度生存模式
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/06_早年经历_痛苦孤独与高强度生存模式解读.md
《Elon Musk》早年经历解读:痛苦、孤独与高强度生存模式
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:序章 The playground、Adversity shaped me,以及第 2-3 章关于童年孤独、父母关系、学校经历和与父亲共同生活的段落。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释“痛苦、孤独和高强度生存模式”如何成为马斯克后续行为模式的一部分。
1. 结论
Walter Isaacson 在《Elon Musk》里写马斯克早年经历时,并不是为了给他的所有行为找借口,而是在解释一个高强度人格系统是如何形成的。
马斯克童年的关键不是单一事件,而是三类长期环境叠加:
- 外部世界充满暴力:南非社会环境、学校霸凌、生存营训练和公共场合的真实暴力。
- 家庭内部缺少稳定保护:父亲 Errol 的情绪虐待、父母冲突、母亲经济压力和家庭撕裂。
- 自身又高度孤独和不合群:社交困难、沉浸阅读、强烈求知、对“愚蠢”的低容忍,以及很早形成的自我封闭。
这些因素共同塑造出一种“高强度生存模式”:
- 面对威胁时不退缩,甚至主动迎战。
- 对痛苦有很高耐受度。
- 把危机、压力和冲突当成常态环境。
- 能在极端压力下推进事情。
- 但也容易关闭情绪、降低同理心、制造压迫和戏剧性冲突。
这套模式后来在 SpaceX、Tesla、Twitter 等场景里反复出现。它既是能力来源,也是风险来源。
2. 第一层:南非成长环境让“世界是危险的”成为默认假设
原书一开始就把马斯克放在 1980 年代南非的暴力背景里。这里的童年不是安全、被保护、可以慢慢探索的童年,而是一个孩子很早就接触到攻击、死亡、血腥和生存竞争。
最典型的是 veldskool 生存营。书中描述这个营地像军事化版的儿童丛林法则:孩子们得到很少的食物和水,被默许甚至鼓励互相争夺。马斯克第一次去的时候年纪小、身材弱、社交笨拙,被打过,也明显吃了亏。
第二次去时,他已经长高,也学了一些柔道,于是形成了一个很直接的生存判断:如果别人欺负你,你必须让对方付出疼痛代价。即使你最后还是被打,你也要让对方知道攻击你有成本。
这个判断后来很重要。它不是“和平解决冲突”,而是“威慑”。马斯克后来的很多行为都带有这种威慑逻辑:
- 对供应商强硬压价或转向自研。
- 对团队设极端期限。
- 对批评者公开反击。
- 在冲突中倾向于升级,而不是降温。
这不是说这些行为都合理,而是它们有共同的心理底层:如果世界是危险的,就不能显得软弱;如果被攻击,就必须反击到对方不敢再来。
3. 第二层:校园霸凌让“孤立无援”成为身体记忆
书中写到马斯克在学校长期被欺负。他年纪小、身材弱、不擅长读懂社交信号,也不愿意为了讨好别人而调整自己。他经常说别人“stupid”,这进一步加剧了同龄人对他的反感。
其中最严重的一次,是他被一群学生从背后攻击、踢头、推下台阶,最后进医院休养。这个事件不仅是身体伤害,更重要的是它强化了两个体验:
- 群体会围攻你。
- 没有人会及时保护你。
当一个人很早形成这种经验,他后续很容易发展出两种策略:
- 一种是躲进自己的世界,比如阅读、游戏、编程和科幻。
- 另一种是把自己训练成不会轻易被击垮的人。
马斯克两种都发展出来了。他一方面沉浸在书、百科、漫画、科幻和电脑里;另一方面又逐渐把“不怕痛”“不怕冲突”“不怕风险”变成自我形象。
这解释了为什么他后来既像一个极度理性的工程师,又像一个总要进入战斗状态的人。前者来自他的知识避难所,后者来自他的生存环境。
4. 第三层:父亲 Errol 的伤害比外部暴力更深
书中明确把父亲 Errol 的情绪伤害放在比学校暴力更深的位置。关键不是父亲偶尔严厉,而是他在马斯克最脆弱的时候没有提供保护,反而站到伤害者一边。
马斯克被打进医院后,父亲没有安慰他,而是训斥他,指责他。这件事的心理破坏很大:外部世界伤害你,家庭本应是恢复区;但如果家庭也变成审判区,孩子就很难建立稳定的安全感。
Errol 的模式在书里有几个特点:
- 情绪不可预测,一会儿友好,一会儿长时间攻击。
- 语言羞辱,反复让孩子觉得自己无价值。
- 强调强硬和痛苦耐受,把暴力视作成长教育。
- 叙事经常自我合理化,把责任推给别人。
这种父亲形象后来在马斯克身上留下复杂痕迹。他努力远离父亲,也害怕变成父亲;但书中多处人物反馈也指出,他在压力下会重复某些类似模式:羞辱、冷酷、强控制、压迫式管理。
这正是这部分最关键的矛盾:马斯克不是简单“战胜了创伤”,而是把创伤转化成了能量,同时也把一部分创伤模式带进了自己的组织和关系。
5. 第四层:孤独不是短期状态,而是人格底色
第 2 章里,书写到马斯克小时候很孤独。他不是没有兴趣,而是很难自然融入同龄人。他会进入出神状态,被老师认为不听讲;他想交朋友,但不知道如何交朋友;弟弟和妹妹能很快带朋友回家,他却经常没有朋友。
这种孤独有几个后果。
第一,他把书籍和想象世界当成庇护所。他长时间读书,沉浸在百科、科幻、漫画、未来发明和电子游戏里。书里的英雄、火箭、AI、外星文明和拯救世界主题,为他提供了另一套身份系统:现实里他是孤独、不合群、被欺负的小孩;想象世界里,他可以成为理解宇宙、拯救人类、创造未来的人。
第二,他对“陪伴”和“控制”会有复杂需求。他害怕孤独,但又不擅长柔和地建立亲密关系。书中后面写到他在伴侣关系和家庭关系里的紧张,也可以从这里看到根源:他需要连接,但连接方式常常被控制、强度和任务感污染。
第三,他对“使命”的依赖很强。孤独的人如果找到一个宏大使命,使命会成为心理支架。对马斯克来说,保存人类意识、移民火星、推动电动车、发展 AI 和机器人,既是商业目标,也是他给自己构建的存在意义。
6. 第五层:情绪关闭带来风险偏好,也带来同理心缺口
书中借 Justine 的观察指出,马斯克可能很早学会了关闭情绪。如果父亲持续羞辱你,如果表达脆弱只会招来攻击,那么关闭恐惧、关闭痛苦、关闭需求,就会成为一种生存策略。
这种策略有明显收益:
- 他能承受常人难以承受的压力。
- 他能在公司濒临死亡时继续推进。
- 他能做高风险判断,不被恐惧完全控制。
- 他能把失败当成工程反馈,而不是人格崩溃。
但代价也很明显:
- 关闭恐惧时,也可能关闭快乐和共情。
- 对自己痛苦迟钝,也容易对别人痛苦迟钝。
- 把自己能承受的强度默认要求别人也承受。
- 在压力下更容易进入冷酷、羞辱和极端否定状态。
这就是“高强度生存模式”的核心悖论:它让一个人能在极端环境中活下来,也可能让他在不需要极端的环境里继续制造极端。
7. 第六层:危机感成为动力系统,而不是临时反应
书中有一个很重要的判断:马斯克似乎最适合在风暴中运转。他会被危机、期限、戏剧性冲突和高强度工作激活。Kimbal 称他像“drama magnet”,意思是他不只是遇到戏剧性事件,而是会被这类事件吸引。
这能解释他后来的创业节奏:
- SpaceX 前三次发射失败,公司接近死亡。
- Tesla 资金链和 Model 3 产能多次接近崩盘。
- Twitter 收购和改造几乎主动把自己推进舆论、财务和组织风暴。
普通人把危机当成异常状态,马斯克更像把危机当成高性能状态。问题在于,一个人可以在危机里爆发,但组织不能长期靠危机维持。危机会带来速度,也会带来失真、疲惫、恐惧和信任损耗。
因此,早年经历不只是解释他的“抗压”,也解释他的“危机成瘾”。他可能并不只是会处理危机,而是会在没有危机时不自觉创造危机。
8. 第七层:从“被欺负的操场”到“拥有操场”
原书在序章末尾把 Twitter/X 写成一种象征:当马斯克感到被威胁或进入黑暗状态时,会回到童年操场被欺负的记忆;而收购 Twitter 像是获得了拥有操场的机会。
这个解释很有穿透力。Twitter 不只是一个商业资产,也像一个全球公共操场:人们在上面攻击、结盟、羞辱、表演、争夺地位。对一个童年在操场上被围攻的人来说,拥有这个操场有很强的心理象征。
这不意味着收购 Twitter 只是心理创伤驱动,但它提示我们:重大商业决策有时不只是理性财务计算,也可能被身份、旧伤、控制欲和象征性补偿影响。
做决策复盘时,这一点很有价值:当一个决策带有过强情绪能量时,要问一句:我是在解决现实问题,还是在补偿旧场景?
9. 这部分不能被误读成“痛苦造就伟大”
这部分最容易被误读为:痛苦、霸凌、冷酷父亲和高压环境造就了马斯克,所以痛苦是必要的。
这个结论是不严谨的。
更准确的说法是:马斯克在痛苦环境中发展出了一套强大的生存和进攻能力,但这套能力伴随巨大副作用。他的成就不能证明创伤是好事,只能说明他把创伤中的一部分能量转化成了行动力。
痛苦可能带来:
- 高痛阈。
- 高风险承受力。
- 强烈逃离和证明自己的动力。
- 对安全区的低依赖。
但痛苦也可能带来:
- 情绪关闭。
- 关系破坏。
- 对他人痛苦不敏感。
- 危机常态化。
- 把控制误认为安全。
所以更有价值的读法不是“复制他的痛苦”,而是识别这套模式中哪些可以学习,哪些必须加边界。
10. 管理启发
10.1 记录“高强度推进”的同时记录代价
如果一个任务靠极端压力完成,不能只记录成果,也要记录代价:睡眠、情绪、人际关系、健康和信任。否则系统会错误奖励高伤害推进。
可用记录格式:
HH:MM 完成某任务。标签:高强度推进。复盘含义:成果是什么,代价是什么,下次如何降低代价。
10.2 区分“抗压能力”和“危机成瘾”
抗压能力是危机来了能稳住;危机成瘾是没有危机也要制造危机。个人复盘时要问:这个紧急是外部造成的,还是我用拖延、控制欲、过度承诺制造的?
10.3 给自己的“demon mode”做预警
当出现以下信号时,应暂停不可逆决策:
- 睡眠不足。
- 急于羞辱或否定别人。
- 觉得所有人都太慢、太蠢。
- 想通过强控制立刻恢复安全感。
- 把反击看得比解决问题更重要。
10.4 把孤独转化为结构化输入,而不是只靠宏大使命硬撑
马斯克把孤独转向科幻、工程和使命感。对工作系统来说,更可持续的方式是把孤独、焦虑和高压状态记录下来,转成可复盘的结构化材料,而不是只靠更大的目标压过去。
10.5 警惕“旧场景补偿型决策”
当一个决策带有强烈证明、反击、夺回控制权的意味时,要额外复盘:
- 我现在面对的是真问题,还是旧伤触发?
- 我是在解决业务问题,还是在重新赢一次过去的操场?
- 这个决策如果没有情绪加成,还值得做吗?
11. 一句话总结
马斯克早年经历塑造的不是简单的“坚强”,而是一套以痛苦耐受、威慑反击、情绪关闭和危机驱动为核心的生存系统;这套系统后来帮助他推进极难任务,也不断把他和周围人拖进高压、冲突和代价之中。
---
layout: post
title: 《Elon Musk》方法卡片
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/02_方法卡片.md
《Elon Musk》方法卡片
用途:把 Walter Isaacson《Elon Musk》中的创业、工程和管理方法转成可执行规则。重点吸收可复制的方法,同时给高压模式加边界。
卡片 01:第一性原理拆解
- 适用场景:遇到“行业惯例”“一直这么做”“供应商就是这么贵”的问题。
- 触发条件:成本异常高、流程异常慢、团队把惯例当理由。
- 操作步骤:把问题拆到物理约束、材料成本、时间成本、用户真实需求和法规底线;重新计算哪些限制是真限制,哪些只是路径依赖。
- 失败信号:讨论只停留在“别人都这么做”。
- 补救动作:要求列出每项限制的来源和证据。
- 效果指标:是否找到可删除、可替代或可自研的关键环节。
卡片 02:需求质疑清单
- 适用场景:产品需求、内部流程、会议、报表、审批、技术方案。
- 触发条件:需求膨胀,交付周期变长。
- 操作步骤:逐项问:谁提出的,服务哪个目标,不做会怎样,有没有更小实现,是否只是为了规避责任。
- 失败信号:团队默认所有需求都要保留。
- 补救动作:先删除 10%-20% 低价值需求做小范围验证。
- 效果指标:交付范围缩小但核心目标不受损。
卡片 03:删除优先于优化
- 适用场景:流程复杂、代码臃肿、工具链过长、会议过多。
- 触发条件:大家开始讨论“如何优化”但没人问“是否需要”。
- 操作步骤:先列出可删除项;删除后观察失败点;只有真正必要的部分才进入优化。
- 失败信号:把无价值流程做得更高效。
- 补救动作:设定“删除试验期”,允许一周后恢复。
- 效果指标:流程步骤减少、决策速度提高、返工没有显著增加。
卡片 04:真实测试缩短反馈
- 适用场景:技术验证、产品假设、运营策略、个人习惯实验。
- 触发条件:讨论超过两轮仍无法判断。
- 操作步骤:设计一个最小真实测试,用实际结果替代争论;测试要能暴露问题,而不是只证明自己正确。
- 失败信号:用 PPT、观点和头衔替代数据。
- 补救动作:把测试范围缩小到 1 天、1 个用户、1 个模块或 1 个样品。
- 效果指标:反馈周期缩短,下一步动作更明确。
卡片 05:现场观察
- 适用场景:制造、运营、用户体验、服务流程、线上故障。
- 触发条件:管理者只听汇报但问题长期不解决。
- 操作步骤:到现场看真实行为、真实瓶颈和真实返工点;直接问一线人员哪里最浪费。
- 失败信号:会议里结论很多,现场问题没有变化。
- 补救动作:把复盘地点从会议室移到问题发生现场。
- 效果指标:发现汇报链条中没有暴露的关键约束。
卡片 06:关键能力内化
- 适用场景:核心系统依赖外包、供应商、平台或单点专家。
- 触发条件:外部依赖决定你的速度、成本或质量。
- 操作步骤:识别哪些能力是战略核心;核心能力逐步自建或至少建立内部判断力。
- 失败信号:外部说不行,团队就无法判断是否真的不行。
- 补救动作:先内化评估能力,再决定是否完全自研。
- 效果指标:关键决策不再被外部黑箱卡住。
卡片 07:危机模式退出条件
- 适用场景:项目救火、上线前冲刺、重大事故、关键交付。
- 触发条件:需要短期高强度投入。
- 操作步骤:启动危机模式前写清楚:目标、最长期限、负责人、不可突破底线、退出条件、恢复安排。
- 失败信号:危机模式变成日常管理方式。
- 补救动作:超过期限必须复盘是否目标错误或资源不足。
- 效果指标:危机结束后组织能恢复,而不是持续透支。
卡片 08:成果与代价双记账
- 适用场景:复盘高强度工作、创业项目、重大决策。
- 触发条件:结果很好但过程明显伤人或透支。
- 操作步骤:复盘同时记录成果、时间成本、健康成本、关系成本、信任成本和机会成本。
- 失败信号:只用结果证明手段正确。
- 补救动作:要求写出如果再做一次,哪些伤害可以避免。
- 效果指标:下一次能保留结果,同时降低副作用。
卡片 09:跨领域迁移检查
- 适用场景:想把一个领域的成功方法套到另一个领域。
- 触发条件:出现“以前这样成功过,所以这次也这样”的判断。
- 操作步骤:判断当前问题属于工程系统、组织系统、市场系统还是社会系统;列出反馈速度、失败成本、人的信任和外部监管差异。
- 失败信号:忽视领域差异,直接复制管理动作。
- 补救动作:先做小规模迁移实验,不做全量硬切。
- 效果指标:方法迁移后没有破坏关键关系和外部信任。
卡片 10:Demon Mode 预警
- 适用场景:高压决策、冲突沟通、连续睡眠不足、被质疑时。
- 触发条件:出现羞辱他人、极端否定、急于裁撤、非黑即白、强迫立刻表态。
- 操作步骤:暂停不可逆决策;把判断写下来;至少等待一个睡眠周期或找可信第三方复核。
- 失败信号:把情绪强度误认为判断质量。
- 补救动作:先处理睡眠、食物、身体状态,再处理决策。
- 效果指标:减少事后需要道歉、补救或返工的决策。
卡片 11:任务压强分级
- 适用场景:安排工作节奏和个人项目推进。
- 触发条件:所有任务都被当成最高优先级。
- 操作步骤:把任务分为普通推进、加速推进、危机推进;只有少数任务允许进入危机推进。
- 失败信号:长期“全员紧急”。
- 补救动作:每周复盘哪些紧急是计划失败造成的。
- 效果指标:高压资源用于真正关键任务。
卡片 12:愿景与现实校准
- 适用场景:设定大目标、产品承诺、公开计划。
- 触发条件:愿景很强但路径不清晰。
- 操作步骤:区分愿景、路线图、当前事实和可验证里程碑;对外承诺必须绑定实际证据。
- 失败信号:用宏大叙事掩盖当前风险。
- 补救动作:把目标拆成 30 天内可验证的工程或行为指标。
- 效果指标:目标仍有拉力,但不会持续透支信任。
---
layout: post
title: 《Elon Musk》实验记录
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/04_实验记录.md
《Elon Musk》实验记录
实验模板
日期:YYYY-MM-DD
实验名称:
使用卡片:
场景:
行动:
结果:
代价:
下次调整:
待执行实验
- 需求质疑清单:每周 2 次,用于工作需求和工作流。
- 删除优先复盘:每周 1 次,删除一个低价值步骤。
- 危机模式标签:遇到高压任务时记录推进级别和退出条件。
- 成果与代价双记账:每周复盘一个高强度成果。
记录
暂无。后续执行本书方法时追加到这里。
---
layout: post
title: 《Elon Musk》复盘与修订
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/05_复盘与修订.md
《Elon Musk》复盘与修订
初始判断
这本书对工作系统的价值在于提供一套极端高强度执行系统的正反样本。可复用部分包括第一性原理、删除优先、快速测试、现场观察和关键能力内化;需要警惕的部分包括长期危机模式、低同理心管理、跨领域误用和愿景过度承诺。
后续复盘方向
- 哪些马斯克式方法在个人工作中真正提高了速度?
- 哪些方法一使用就带来明显情绪或关系副作用?
- 危机模式是否被限制在短期任务中?
- 是否真的做到“删除优先”,还是仍然只是在优化复杂系统?
- 是否能把第一性原理用于生活流程,而不是只用于工作项目?
修订记录
- 2026-06-04:基于 EPUB 转换稿创建首版笔记、方法卡片、落地计划、实验记录和复盘文件。
---
layout: post
title: 《Elon Musk》内容全梳理
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/01_内容全梳理.md
《Elon Musk》内容全梳理
作者:Walter Isaacson
出版:Simon & Schuster,2023
本笔记基于用户上传 EPUB 转换稿整理,目标不是复述传记细节,而是把书中关于创业、组织、技术决策和个人代价的内容转成可复盘的知识资产。
1. 这本书解决什么问题
这本书表面上是埃隆·马斯克的传记,实际上回答的是一个更复杂的问题:一个极端目标导向、风险偏好极高、同理心不稳定、执行压强极强的人,如何连续推动互联网支付、商业航天、电动车、卫星通信、AI、脑机接口和社交平台这些高不确定性领域。
书的核心不是“马斯克是否值得崇拜”,而是展示一种高能量创业者的完整系统:童年创伤、第一性原理、硬核工程文化、极限压榨、快速迭代、危机驱动、亲密关系破坏、公众争议和组织成果交织在一起。
可以把全书压缩成一句话:
马斯克的成功来自极端使命感、第一性原理和超高执行压强,但同一套机制也持续制造组织伤害、关系破裂和判断失控。
2. 全书主线
2.1 早年经历:痛苦、孤独和高强度生存模式
书从南非童年写起。马斯克经历了校园暴力、家庭冲突、父亲的情绪虐待和南非社会环境中的暴力氛围。这些经历塑造了两个长期特征:对痛苦的高耐受,以及在冲突中不轻易退让。
这一部分不是简单心理解释,而是为后面的管理模式埋下线索:他后来经常把自己能承受的压力默认投射给组织,认为极限压力可以筛出真正能解决问题的人。
2.2 迁移与早期创业:从逃离南非到互联网浪潮
马斯克离开南非,经加拿大进入美国,在 Queen’s、Penn 和硅谷阶段逐渐形成技术创业路径。Zip2 和 X.com/PayPal 是他的早期训练场:他学习到速度、资本、产品、技术架构和控制权的重要性,也经历了被董事会和合伙人边缘化的创伤。
PayPal 阶段尤其关键。它让马斯克看到软件平台、金融系统和网络效应的力量,也让他意识到如果不能控制公司方向,创始人的愿景会被组织政治和短期妥协稀释。
2.3 SpaceX:用第一性原理打穿高壁垒行业
SpaceX 的主线是把火箭从政府承包和成本加成模式中拉出来,用固定价格、垂直整合和快速试错重构商业航天。马斯克不断追问“为什么这么贵”“哪些部件必须这样做”“能不能自己造”。
书中反复出现的模式是:质疑每个需求,删除不必要流程,缩短反馈周期,把失败当作工程学习的一部分。前三次发射失败几乎耗尽资金,第四次成功和 NASA 合同共同救了公司。
SpaceX 的长期意义在于,它把不可能任务拆成可以连续试验的工程问题:Falcon、Dragon、可回收火箭、Starlink、Starship 都沿着这个逻辑推进。
2.4 Tesla:产品愿景、制造地狱和供应链控制
Tesla 章节展示了马斯克从投资人、董事长到实际掌舵者的过程。Roadster、Model S、Model 3、上海工厂、Cybertruck、Autopilot 和机器人项目贯穿其中。
最重要的主题是“制造”。马斯克不是只做概念和营销,而是持续下沉到工厂、产线、零部件、成本和供应链。他对制造速度和垂直整合的执念,让 Tesla 在电动车产业化上形成优势,也制造了著名的 production hell。
Model 3 产能危机是全书的一个高压样本:过度自动化失败后,他转向人工、帐篷产线、现场指挥和逐环节排障。这里体现出他的优点和问题:能快速承认某个技术路线失败,但往往要在组织被压到极限后才修正。
2.5 管理算法:删除、简化、加速、自动化
书中多次出现马斯克式“算法”:
- 质疑每一项需求。
- 删除尽可能多的部件和流程。
- 简化和优化剩下的部分。
- 加快循环速度。
- 最后才自动化。
这套方法在火箭、汽车、工厂、软件和 Twitter 中都被重复使用。它的价值是反官僚、反惯性、反过度设计;风险是删除过头、压强过大、忽视人的承受力和社会系统复杂性。
2.6 AI、Autopilot、Optimus 和 Neuralink:现实工程与愿景膨胀
在 AI 和自动驾驶部分,书呈现了马斯克对视觉路线、端到端学习、机器人和脑机接口的长期押注。他倾向于把问题压缩成“数据、计算、工程速度”的问题,并相信只要快速迭代就能逼近突破。
这带来了强大的研发动员力,但也带来承诺过度的问题。Autopilot 和完全自动驾驶相关章节提醒:工程愿景和实际安全边界之间存在张力,尤其当产品面向公共道路和用户生命安全时,单纯用迭代速度思维会产生伦理和监管风险。
Twitter 收购是全书后半部分的重心。马斯克把 SpaceX/Tesla 的硬核工程管理方法迁移到社交平台:裁员、代码审查、压缩成本、快速改功能、重新设计认证体系、内容审核亲自介入。
这部分最能看出“领域迁移”的问题。火箭和工厂可以通过物理规律、成本和性能指标快速反馈,但社交平台涉及广告主、用户信任、政治议题、舆论、内容治理和社会情绪。相同的压强和速度在这里未必产生同样效果。
Twitter 章节的启发是:第一性原理不是忽视领域知识。越是社会系统,越需要把人的信任、制度稳定性和外部预期纳入系统边界。
2.8 私人关系:高成就背后的长期代价
书中穿插婚姻、孩子、伴侣、兄弟关系和父亲阴影。马斯克能够在公司危机中投入极端能量,但亲密关系经常被同一套压强、控制和情绪波动损伤。
这条线让传记不只是商业案例。它提示:个人操作系统如果只为任务和使命优化,可能牺牲恢复、关系、稳定和自我觉察。高能量不是免费资源,代价会在家庭、团队和公众信任中显现。
3. 核心概念
3.1 第一性原理
不是用行业惯例作为约束,而是回到物理、成本、材料、软件和用户需求本身,重新计算问题。它适合打破“大家都这么做”的成本结构。
3.2 极限压强
通过紧迫期限、现场追责、直接质疑和高强度工作推进组织突破惰性。它可以在危机中释放巨大执行力,但长期使用会损伤信任和组织健康。
3.3 垂直整合
尽可能掌握关键部件、软件、制造和供应链,而不是完全依赖外包。优点是速度、成本和技术掌控力;缺点是管理复杂度上升。
3.4 快速迭代
用真实测试代替长周期规划,允许失败暴露问题。适合硬科技研发和工程优化,但在涉及安全、公共舆论和社会治理时必须设置边界。
3.5 Demon mode
书中用这个词描述马斯克进入极端冷酷、压迫和目标单一的状态。这种状态可能在关键时刻推进结果,也可能伤害人、组织和判断质量。
4. 管理启发
4.1 区分“高标准”和“高伤害”
马斯克案例说明,高标准有价值,但高伤害不是高标准的必要条件。工作系统可以记录一个任务是否推进了结果,同时记录推进方式是否透支人际关系、身体和长期信任。
4.2 用算法处理复杂任务
遇到复杂项目时,可以引入马斯克式算法,但要加一层安全阀:
- 质疑需求。
- 删除流程。
- 简化方案。
- 加速反馈。
- 自动化。
- 检查人、合规、安全和信任成本。
最后一步是复盘机制需要补上的部分。
4.3 把危机模式限定为临时状态
危机模式可以救火,但不能成为日常默认。记录任务时,可以标注“正常推进”或“危机推进”,并要求危机推进后必须复盘恢复成本。
4.4 防止跨领域误用成功经验
SpaceX/Tesla 的成功方法迁移到 Twitter 时出现明显不适配。工作系统在复用方法时,应要求先判断领域:这是工程系统、组织系统、市场系统,还是社会系统。
4.5 关注长期复利而不是戏剧性强度
传记容易让人被高强度故事吸引,但对个人成长更可复制的是:持续学习、第一性原理、现场观察、快速反馈、掌握关键资源,而不是情绪爆发和长期压榨。
5. 最值得落地的 8 个动作
- 对重要项目先写“需求质疑清单”:这个需求是谁提的,为什么必须存在,删掉会怎样。
- 每周选择一个流程做删除实验,先删除再验证,而不是默认优化。
- 复杂任务先做真实小测试,缩短反馈周期,不在纸面上无限推演。
- 关键能力尽量内化,避免核心判断完全依赖外部供应商或平台。
- 进入高压推进前先定义退出条件,避免危机模式常态化。
- 复盘时同时记录成果和代价:时间、情绪、关系、健康、信任。
- 复用成功方法前先判断领域边界,尤其警惕把工程方法直接套到社会系统。
- 对自己的“demon mode”建立预警:急躁、羞辱他人、极端否定、睡眠不足时,不做不可逆决策。
6. 一句话总结
《Elon Musk》最有价值的地方,不是证明马斯克应被崇拜或否定,而是提供了一个高能量创业操作系统的完整样本:它能创造惊人成果,也会制造同样惊人的代价。
---
layout: post
title: 《Elon Musk》个人落地计划
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/03_个人落地计划.md
《Elon Musk》个人落地计划
1. 本书的落地定位
这本书不适合作为单纯的励志材料,更适合作为“高压执行系统样本库”。落地目标是:吸收第一性原理、删除优先、现场观察、快速反馈等有效方法,同时明确高压模式的使用边界,避免把伤害误认为能力。
2. 未来 30 天实验
实验 01:需求质疑清单
- 周期:每周 2 次。
- 场景:工作中的新需求、脚本改造、数据分析任务、工作流。
- 动作:每次开始前写 5 个问题:谁需要,目标是什么,不做怎样,能否缩小,是否可删除。
- 记录位置:
logs/daily_log.md 或项目笔记。
- 成功标准:至少有 1 个需求被缩小、删除或改成更快验证。
实验 02:删除优先复盘
- 周期:每周 1 次。
- 场景:笔记目录、飞书同步流程、读书笔记流程、工作流脚本。
- 动作:找一个流程先删除一步,而不是优化一步。
- 成功标准:流程更短,结果没有明显变差。
实验 03:危机模式标签
- 周期:持续。
- 场景:加班、紧急开发、临时高压任务。
- 动作:在 daily log 中标注
普通推进 / 加速推进 / 危机推进。
- 成功标准:危机推进不能连续超过 2 天;如果超过,必须复盘原因和恢复安排。
实验 04:成果与代价双记账
- 周期:每周复盘。
- 动作:选一个最重要成果,记录它消耗了多少睡眠、情绪、关系、健康和机会成本。
- 成功标准:下周能保留成果,同时降低一种代价。
3. 日常记录新增字段建议
在 logs/daily_log.md 中遇到高压任务时,可以增加:
标签:第一性原理 / 删除优先 / 现场观察 / 危机推进 / 成果代价复盘
复盘含义:这次推进是高标准,还是高伤害?下次如何降低代价?
4. 每周复盘问题
- 本周我有没有把“惯例”当成不可变限制?
- 哪个流程应该先删除,而不是继续优化?
- 哪个任务被我错误地推成了危机模式?
- 哪个成果的代价被我低估了?
- 哪个方法不能跨领域硬套?
5. 风险提醒
马斯克式方法最容易被误用的地方,是只学习强度,不学习工程判断;只学习压迫,不学习现场排障;只学习宏大愿景,不学习真实测试。个人落地时必须把“结果”和“代价”一起记录。
---
layout: post
title: 《Elon Musk》Twitter/X 解读:同一套方法进入社会系统后的失控
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/12_Twitter_X_同一套方法进入社会系统后的失控解读.md
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 69 章关于政治转向,第 72-74 章关于 Twitter 投资与收购出价,第 78 章关于收购不确定性,第 81-88 章关于接管、裁员、代码审查、蓝 V 和 hardcore,第 90-91 章关于 Twitter Files 与内容治理,第 94 章关于 X.AI。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释为什么马斯克把 SpaceX/Tesla 的高压工程方法迁移到 Twitter/X 后,会遇到更复杂的社会系统反作用。
1. 结论
Twitter/X 主线是全书后半部分最能暴露方法边界的案例。马斯克把在 SpaceX 和 Tesla 中形成的管理方式带进社交平台:质疑需求、删除流程、裁员压成本、代码审查、快速改功能、亲自介入内容治理、用极限期限筛人。
这套方法在 Twitter 上确实产生了一些短期效果:
- 成本迅速下降。
- 组织层级被打穿。
- 长期积累的内部惯性被迫暴露。
- 产品和工程改动速度提高。
- 马斯克重新掌握了自己想要的公共表达平台。
但更大的问题是,Twitter 不是火箭、汽车或工厂。它是社会系统,核心资产不是单纯代码,而是用户信任、广告主信心、内容治理合法性、品牌安全、公共讨论质量和外部预期。
在工程系统里,删除一个多余零件可以减重;在社会系统里,删除一个看似低效的审核流程,可能损害信任。马斯克的 Twitter 实验说明:第一性原理不是忽视领域知识,尤其不能忽视人的系统。
马斯克收购 Twitter 不能只用一个原因解释。
第一,有商业和产品动机。他长期想做 X.com 式的一体化平台,支付、社交、身份、内容和金融都可以合并。Twitter 提供了现成的社交图谱和公共讨论入口。
第二,有政治和文化动机。书中显示,马斯克在 2020-2022 年间逐渐转向更强烈的反建制、反 woke、自由言论和文化战争叙事。他越来越把 Twitter 看成公共广场,并认为原管理层的内容治理带有意识形态偏向。
第三,有心理动机。Twitter 是全球最大的公共操场之一。对一个高度在意攻击、羞辱、舆论和反击的人来说,拥有这个平台有强烈象征意义。
第四,有冲动和游戏化因素。马斯克习惯在 Twitter 上即时表达,投资、发起投票、提出收购、反悔和重新推进,都带有他典型的高波动决策风格。
这些动机叠加,使 Twitter 收购从一开始就不是纯财务交易,而是身份、权力、技术平台和公共话语权的混合项目。
3. 从投资到收购:开放回路不断扩大
书中关于收购前期的章节显示,马斯克最初可以只是主动投资者或董事会成员,但他很快把问题升级为全盘收购。
这符合他的行为模式:一旦发现自己不能控制方向,就会倾向于提高控制权。Zip2、PayPal 和 Tesla 的经历让他很难接受“有影响力但没有最终决定权”的位置。
问题是,Twitter 的控制权并不等于问题解决权。买下公司可以获得组织权力,但不能自动获得广告主信任、用户信任、监管信任和内容治理能力。
这就是 Twitter 与 Tesla/SpaceX 的不同:火箭和汽车的核心问题最终会落到物理性能、成本和交付;社交平台的核心问题还包括外部解释权和群体心理。
4. 接管时刻:文化冲突不是附属问题
马斯克带着洗手池进入 Twitter 总部,是一个高度符号化的场景。它符合他的幽默和注意力风格,也预示他会把收购当成一场文化接管。
Twitter 原有文化更接近旧金山互联网公司的政策、沟通、内容治理和员工福利体系。马斯克带来的则是 SpaceX/Tesla 式 hardcore 工程文化:现场、代码、成本、速度、服从、极限产出。
两种文化冲突不是“员工太娇气”或“老板太粗暴”这么简单,而是组织处理风险的方式不同。
- Twitter 原文化重视舆论、政策、法律、广告关系和员工沟通。
- 马斯克文化重视速度、直接负责人、代码产出、成本压缩和战时状态。
Twitter 的问题在于,它确实可能有过度膨胀、流程僵化和执行缓慢;马斯克的问题在于,他把文化冲突当作可以用裁员和羞辱直接解决的效率问题。
5. 代码审查:工程能力可以检查,但产品信任不能只看代码
接管后,马斯克让工程师打印代码、接受审查、证明贡献。这是他熟悉的方式:打穿管理层,直接看底层产出。
这种做法有一定有效性。大公司里确实会有人远离核心产出,组织也可能用会议和协调掩盖低贡献。代码审查能快速识别部分工程真实能力。
但 Twitter 的价值不只在代码。它还有:
- 内容审核政策。
- 广告主关系。
- 法务和监管应对。
- 安全与隐私。
- 社区规则。
- 品牌和公共信任。
- 反滥用和反垃圾系统。
如果把公司简化成代码仓库,就会低估这些非代码系统。它们看起来不像产出,却维持平台不崩。
这对工作系统也有启发:不要只用可见产出衡量所有工作。维护、协调、风险控制和信任建设也是真实产出,只是反馈更慢。
6. 裁员和 hardcore:成本降低与组织记忆损失
马斯克接管 Twitter 后快速大规模裁员,并要求员工选择是否进入 hardcore 模式。这延续了他的危机筛选逻辑:留下愿意极限投入的人,淘汰不适应高压的人。
短期看,这种方式能快速降低成本,也能让留下的人明确权力结构。但长期风险很大:
- 关键系统知识流失。
- 安全和合规能力削弱。
- 留下的人进入恐惧驱动。
- 外部人才品牌受损。
- 组织记忆被当成冗余删除。
在 SpaceX 和 Tesla,极端筛选有时能形成高密度工程团队;在 Twitter,这种筛选会伤害平台治理所需的多元专业能力。社交平台需要工程师,也需要政策、信任安全、法务、广告和社区理解。
7. 蓝 V 认证:把身份系统当成功能改版的代价
Twitter Blue 和蓝 V 认证改造,是方法迁移失控的典型案例。
马斯克从产品和收入角度看,旧认证体系有精英化和不公平问题,也没有为平台创造足够收入。因此他想把认证变成订阅产品,让普通用户也能购买标识。
这个方向并非完全没有道理。旧认证体系确实存在不透明和身份等级感。但问题是,认证不只是装饰功能,它是平台信任基础设施的一部分。用户看到认证标识,会推断身份真实性、信息可靠性和公共人物属性。
当身份标识突然被商品化,且验证机制不足时,假冒、恶搞、广告主恐慌和公共信息混乱就会出现。
这说明在社会系统里,产品功能往往同时是制度。改功能就是改制度,不能只按按钮、收入和发布速度评估。
8. 内容治理:Council of one 的结构性问题
马斯克强调自由言论,但接管后多次亲自介入具体内容治理事件。这形成一个矛盾:他批评旧 Twitter 内容审核不透明,却把很多判断集中到自己身上。
内容治理难,是因为它不是简单“删或不删”。它涉及:
- 法律边界。
- 地区差异。
- 暴力和骚扰。
- 政治操纵。
- 垃圾信息。
- 儿童安全。
- 新闻价值。
- 平台规则一致性。
如果由一个高度情绪化、政治立场不断卷入争议、且本人也是平台最大用户的人来临时决策,就很难建立稳定预期。
Twitter/X 的问题不是一定要维持旧规则,而是新规则必须可解释、可预期、可执行。否则“自由言论”会被用户理解成平台所有者的即时偏好。
9. 广告主和用户信任:社会系统的反馈更慢也更脆弱
马斯克很擅长处理工程反馈。发动机炸了,原因可以追踪;产线堵了,瓶颈可以定位;成本高了,零件可以拆解。
广告主信任和用户信任不同。它们不是单一物理反馈,而是预期、声誉、风险评估和舆论共同形成的结果。
广告主担心品牌安全,不只是某条内容是否违规,而是整个平台是否可预测。用户担心平台质量,也不只是某个功能好不好,而是身份、社区、规则和信息环境是否稳定。
马斯克式速度会制造一种外部观感:平台随时可能因为老板一条推文改变规则。这种不确定性本身就是成本。
Twitter Files 体现马斯克想证明旧 Twitter 存在偏向和不透明操作。公开内部资料在某种意义上可以服务透明,但选择性发布、政治语境和参与者立场,也会让透明行动变成政治叙事工具。
如果目标是重建平台信任,更稳健的做法应是制度化审计、明确规则、第三方机制和长期透明报告。马斯克更倾向于戏剧性揭露和舆论战,这符合他的反击模式,却未必能建立稳定治理。
这再次说明:社会系统不是只靠曝光和强攻就能修复。信任需要制度,而不只是胜负。
11. X 愿景:超级应用的吸引力与现实障碍
马斯克把 Twitter 改造成 X,延续了他 X.com 时代的未完成愿景:社交、支付、金融、内容、身份和 AI 的统一平台。
这个愿景有战略吸引力。拥有社交图谱、用户表达、实时信息流和支付能力的平台,理论上可以形成强大网络效应。
但现实障碍也很大:
- 美国用户没有强烈超级应用习惯。
- 金融和支付监管复杂。
- 广告主和用户信任受损会影响扩展。
- 内容治理争议会阻碍金融业务。
- 平台品牌从 Twitter 转向 X 的过程中损失了原有资产。
X 的愿景不是不可能,但它不是靠改名和高压管理就能自然实现。它需要稳定产品、合规能力、支付信任和长期生态建设。
12.1 不要把领域知识当成官僚
进入新领域时,先区分哪些流程是浪费,哪些流程是风险控制和信任基础设施。
12.2 社会系统要把信任纳入核心指标
如果一个系统涉及他人预期、合作、声誉或公共表达,速度和成本不是唯一指标。要记录信任、稳定性和外部影响。
12.3 功能改动可能就是制度改动
身份、权限、可见性、排序和审核规则,不只是产品功能。它们会改变人的行为和信任结构。
12.4 高压筛选会丢失隐性知识
快速裁撤或退出机制能降低成本,但也会带走组织记忆。复盘时要评估“失去的人知道什么”。
12.5 情绪驱动的公共决策要延迟
当决策涉及反击、羞辱、证明自己或夺回控制权时,应延迟发布,先做事实和后果检查。
13. 一句话总结
Twitter/X 证明马斯克的工程管理算法在社会系统中会遇到硬边界:代码可以快速重写,成本可以快速砍掉,但信任、治理、身份和公共预期不能用同样的速度粗暴删除后再修。
---
layout: post
title: 《Elon Musk》Tesla 解读:产品愿景、制造地狱与供应链控制
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/09_Tesla_产品愿景制造地狱与供应链控制解读.md
《Elon Musk》Tesla 解读:产品愿景、制造地狱与供应链控制
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 20-21 章关于 Tesla 创立和 Roadster,第 24-25 章关于 Roadster 成本危机和马斯克接管,第 31-32 章关于 2008 年融资和 Model S,第 36 章关于 Fremont 制造,第 42 章关于 SolarCity,第 45-46 章关于 Model 3 production hell,第 50-51 章关于上海工厂和 Cybertruck,第 55 章关于 Giga Texas。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释 Tesla 主线中“产品愿景、制造地狱和供应链控制”如何共同塑造马斯克的汽车工业方法。
1. 结论
Tesla 章节的核心不是“马斯克做了电动车”,而是他把电动车从环保小众产品重新定义为高性能科技产品,并把竞争焦点从概念、品牌和资本市场,逐步压到制造、成本、供应链和工厂执行。
这条主线有几个关键结论:
- Tesla 的突破来自产品愿景和制造控制的结合,而不是单纯营销。
- Roadster 证明电动车可以令人兴奋,但也暴露了外包、拼装和成本失控的脆弱性。
- Model S 把 Tesla 从改装跑车公司推向真正汽车制造商。
- Model 3 production hell 证明马斯克式自动化迷信会失败,但他也能在失败后迅速转向现场排障。
- 上海工厂、Gigafactory、Gigapress 和供应链控制显示 Tesla 后期优势越来越来自制造系统。
- Tesla 的成功伴随极端组织代价:高压、裁撤、羞辱、反复危机化和对个人生活的吞噬。
如果 SpaceX 是马斯克把火箭拆回物理和成本,那么 Tesla 是他把汽车拆回零件、产线、节拍、供应链和单位成本。
2. Tesla 的起点:不是发明电动车,而是改变电动车叙事
Tesla 不是马斯克独自从零创立的公司。书中写到 Martin Eberhard、Marc Tarpenning、JB Straubel 等人在早期构想、技术判断和公司创建中有重要作用。马斯克最初以投资人和董事长身份进入,后来逐步变成实际控制者。
这点很重要,因为 Tesla 主线不是一个“天才独创”的故事,而是多个技术、资本和产品判断汇聚后,被马斯克用极端控制方式推向规模化的故事。
早期电动车的问题不只是技术,还包括用户心智。多数人把电动车想成慢、丑、妥协、环保但无趣的产品。Tesla 的第一步是用 Roadster 改写这个叙事:电动车可以快、酷、昂贵、有欲望感。
这和传统环保产品路径不同。传统路径强调节能和道德正确,Tesla 路径强调性能和吸引力。马斯克很早理解到:如果新能源车只是让用户牺牲体验,它很难进入主流;如果它比燃油车更好玩、更快、更先进,用户会主动选择。
3. Roadster:概念验证成功,制造系统失败
Roadster 的价值在于证明了两个判断。
第一,锂电池、电机和电控系统可以组合成令人兴奋的高性能汽车。Tesla 借助 Lotus 底盘和外部供应链,把电动车从实验室和政策补贴语境里拉到消费者欲望层面。
第二,靠拼接外部资源做车会迅速遇到成本和质量问题。Roadster 不是一个成熟的端到端制造系统,而是多个供应商、既有底盘、电池包和 Tesla 自研部分的组合。组合创新能让产品快速面世,但一旦进入量产,接口、质量、成本、交付和责任边界都会变成问题。
这段让马斯克学到一个与 SpaceX 相似的教训:如果核心能力被供应商和外部系统锁住,最终就会被成本、速度和质量牵制。
Roadster 的成功给 Tesla 带来品牌和资本故事,Roadster 的痛苦则把马斯克推向更深的制造控制。
4. 接管 Tesla:控制权再次成为核心变量
Roadster 成本失控后,Tesla 内部出现权力变化。马斯克对 Martin Eberhard 的管理、成本控制和交付节奏不满,最终推动其离开 CEO 位置,自己后来实际接管公司。
这和 Zip2、PayPal 的经历形成呼应。早期创业让马斯克相信:如果不控制公司,愿景会被别人稀释;Tesla 则让他进一步相信:如果不亲自压进细节,成本和进度会失控。
这里的矛盾也很清楚:
- 从公司生存角度,Tesla 确实需要更强成本纪律和执行压力。
- 从组织伦理角度,马斯克处理创始人归属、功劳分配和人员关系的方式带有明显攻击性。
Tesla 后来围绕“谁是创始人”的争议,不只是名分问题,而是马斯克控制叙事的一部分。他不满足于当投资人或推动者,而要成为公司身份本身。
5. 2008 年危机:Tesla 和 SpaceX 同时濒死
2008 年是全书最重要的压力测试之一。金融危机爆发,SpaceX 前三次发射失败,Tesla Roadster 延误且资金紧张。马斯克个人财富、婚姻和身体状态都被推到极限。
这段最能体现他的 all-in 模式。理性投资者可能会选择保一个项目,放弃另一个项目。但马斯克拒绝在 SpaceX 和 Tesla 之间做普通意义上的组合优化,因为在他眼里二者都承载文明使命:
- SpaceX 对应人类多星球未来。
- Tesla 对应可持续能源转型。
这种使命叙事带来极强韧性,也带来风险集中。它让马斯克能在别人已经撤退时继续下注,但也让团队、家庭和投资人被拖入极端压力。
Tesla 最终靠临界点上的融资、Daimler 投资和政府贷款活下来。这里的经验是:宏大愿景必须穿过现金流窄门,不能只停在叙事层。
6. Model S:从改装跑车到真正汽车公司
Model S 是 Tesla 的关键跃迁。Roadster 证明电动车可以有吸引力,Model S 则证明 Tesla 有机会做完整平台、完整设计和完整品牌体验。
Model S 的重要性在于几个方面:
- 它不是把电动车做成传统车的替代品,而是重新设计空间、屏幕、软件体验和驾驶感。
- 它把电池包放到底盘中,带来低重心和结构优势。
- 它让 Tesla 的软件更新、用户界面和整车体验成为差异化的一部分。
- 它使 Tesla 从“新奇跑车项目”变成“可能重构汽车行业的公司”。
这也体现马斯克的产品观:产品不只是功能集合,而是体验、性能、制造、品牌和未来叙事的结合。Model S 让用户感觉自己不是在买一辆替代能源车,而是在提前进入未来。
7. Fremont:制造成为真正战场
买下 Fremont 工厂后,Tesla 获得了进入大规模制造的物理空间,也获得了全新的复杂性。汽车制造不是做原型,也不是发布演示,而是每天重复生产数千个高一致性、高安全要求的复杂产品。
书中关于 Fremont 的细节显示,马斯克越来越沉迷于产线、工位、零件、机器人、节拍和质量。他不是只坐在总部看报表,而是会走到现场,盯住红色警报、瓶颈工序和具体零件。
这正是 Tesla 和许多新能源概念公司的区别。很多公司可以讲电动车故事,但无法稳定制造。Tesla 的长期护城河不是单点技术,而是把电池、软件、电子电气架构、工厂、供应链和资本市场叙事整合起来。
但 Fremont 也展示了马斯克方法的伤害面:现场高压、公开否定、临时改动、极端期限和人员消耗成为常态。制造战场越具体,人的代价也越具体。
8. Model 3 production hell:自动化迷信的失败
Model 3 是 Tesla 从高端市场进入大众市场的关键产品。战略上,Model 3 是正确的:如果 Tesla 只做昂贵车,就无法真正推动电动车普及,也无法支撑更大规模的制造系统。
问题出在生产系统。马斯克一度过度相信自动化,试图用高度机器人化的产线实现高速生产。这个方向听起来符合未来工业想象,但现实中复杂装配、变化、故障处理和供应链波动让系统变得脆弱。
production hell 的关键教训是:自动化不能过早。流程还没有稳定、产品还在变化、工序还没有被充分理解时,自动化会把问题固化,并让每次调整更慢、更贵。
这正好对应后来马斯克总结的管理算法:最后才自动化。Model 3 产能危机不是这套算法的证明,而是这套算法形成过程中的惨痛反例。
9. 帐篷产线:承认失败后的现场修正能力
马斯克的一个重要能力是,在路线失败后可以迅速切换到非常粗粝但有效的方案。Model 3 自动化失败后,他推动拆除部分机器人,增加人工环节,甚至搭建帐篷产线。
帐篷产线看起来不像现代汽车工业的优雅方案,但它解决了当时最关键的问题:让车下线,让现金流和市场信心活下来。
这里体现了马斯克方法的两面:
- 优点:不被面子和原计划绑架,愿意现场改、快速试、用非标准方案打穿瓶颈。
- 问题:常常要等系统被压到极限后才修正,组织已经承受巨大伤害。
对工作系统来说,这里有一个重要提醒:承认路线错误越早,代价越低。不要把“现场救火能力”误认为“前期判断正确”。
10. 供应链控制:垂直整合在汽车行业的延伸
Tesla 的制造优势,很大程度来自供应链控制和垂直整合。这一点与 SpaceX 一脉相承。马斯克不喜欢被供应商报价、节奏和保守文化锁住,于是倾向于把关键环节拉回内部。
在汽车行业,这包括:
- 电池包和电池供应。
- 电机与电控。
- 软件和车载计算。
- 工厂布局和产线设计。
- 大型压铸、车身结构和装配流程。
- 充电网络和用户体验。
垂直整合的好处是速度快、反馈短、系统优化空间大;坏处是资本开支高、管理复杂度高、组织压力大。Tesla 能承受这条路,是因为它同时拥有资本市场叙事、强产品需求和马斯克式极限执行。
11. 上海工厂:速度、政策和制造学习曲线
上海工厂是 Tesla 制造能力成熟的重要标志。它显示 Tesla 不只是靠美国工厂苦撑,而是能在更高效的供应链、政策环境和制造生态中复制并放大产能。
上海工厂的意义不只是销量,而是把 Tesla 的制造学习曲线加速。中国供应链、工程执行、地方协调和产业集群,让 Tesla 更深地进入全球汽车工业竞争。
这也说明马斯克并非只靠个人英雄主义。Tesla 后期能力来自系统:工厂、政府关系、供应商、工程团队、资本、品牌和用户需求共同作用。
12. Cybertruck:产品愿景和制造约束的再次冲突
Cybertruck 体现马斯克产品愿景中最极端的一面:反传统、强辨识度、材料先行、愿意冒犯审美共识。他选择不锈钢和棱角设计,是一次把材料、制造和品牌冲击合在一起的尝试。
它的优点是极高辨识度。没有人会把 Cybertruck 当成普通皮卡。它把 Tesla 的未来主义和反常规形象推到极致。
但它也暴露同一个问题:越极端的产品愿景,对制造、维修、法规、用户习惯和供应链的要求越高。差异化不是免费午餐,越是挑战行业惯例,越要付出工程复杂度。
Cybertruck 可以看作马斯克式产品哲学的浓缩:要么做得非常不一样,要么不值得做。但这种哲学并不适合所有产品,也不适合所有阶段。
13. Tesla 主线的管理启发
13.1 把愿景拆到制造层
愿景如果不能落到交付系统,就只是叙事。个人项目也一样:不要只写目标,要写清楚产出物、流程、节奏、瓶颈和复盘方式。
13.2 先稳定流程,再考虑自动化
Model 3 production hell 的教训是:混乱流程自动化后,只会得到更昂贵的混乱。工作系统也应先用人工流程跑通,再决定哪些环节自动化。
13.3 记录每次救火背后的前置错误
帐篷产线很强,但它也是前期自动化判断失误后的补救。复盘时不能只奖励救火成功,还要记录为什么会烧到必须救火。
13.4 识别供应链依赖
个人工作也有供应链:资料来源、工具、平台、协作者、审批链和时间窗口。关键任务要识别哪些环节外部依赖过强,提前准备替代方案。
13.5 不要把高压当成默认生产方式
高压可以穿过短期危机,但不能长期替代系统能力。Tesla 的经验说明,真正的优势是让制造系统越来越强,而不是让所有人永远处在 production hell。
14. 一句话总结
Tesla 主线展示的是马斯克如何把电动车愿景压进真实制造系统:他用产品吸引力打开市场,用垂直整合和供应链控制建立优势,也在 Model 3 production hell 中暴露出过度自动化、极端压强和危机化管理的高昂代价。
---
layout: post
title: 《Elon Musk》SpaceX 解读:用第一性原理打穿高壁垒行业
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/08_SpaceX_第一性原理打穿高壁垒行业解读.md
《Elon Musk》SpaceX 解读:用第一性原理打穿高壁垒行业
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 14 章 Mars SpaceX, 2001、第 15 章 Rocket Man SpaceX, 2002、第 17 章 Revving Up SpaceX, 2002、第 18 章 Musk's Rules for Rocket-Building、第 19 章 Mr. Musk Goes to Washington、第 22 章 Kwaj、第 23 章 Two Strikes、第 28 章 Strike Three、第 29 章 On the Brink、第 30 章 The Fourth Launch。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释 SpaceX 早期如何用第一性原理、垂直整合、快速试错、固定价格合同和极限执行,打穿商业航天这个高壁垒行业。
1. 结论
SpaceX 早期故事的核心,不是“马斯克想去火星”这么简单,而是他把一个被政府、军工巨头、高成本供应链和风险规避文化锁住的行业,重新拆成几个可被攻击的问题:
- 火箭的物理材料到底值多少钱?
- 哪些要求是真正来自物理定律,哪些只是组织惯例?
- 哪些零部件必须外购,哪些可以自己造?
- 航天公司为什么不能像软件和硬件创业公司一样快速测试、失败、修正?
- 政府为什么要按成本加利润付钱,而不是按结果付钱?
- 私人资本是否可以承担前期风险,换取更高效率和更低成本?
SpaceX 的突破,就是同时攻击了技术成本、制造方式、测试方式、合同模式和组织文化。
这也是“第一性原理打穿高壁垒行业”的含义:不是只想得更远,而是把一个看起来不可进入的行业拆到底层约束,然后重新组合。
2. 从 PayPal 到火星:使命先行,而不是商业计划先行
第 14 章 Mars SpaceX, 2001 里,马斯克刚从 PayPal 被罢免出来,身体还经历过严重疟疾,按常理应该休息或做下一个互联网项目。但他开始学习飞行、买军用教练机,并重新被飞行和空气动力学吸引。
真正转折发生在他和 Adeo Ressi 的一次谈话中。Adeo Ressi 是他在 Penn 时期的朋友,两人在从汉普顿回纽约的车上讨论:个人有没有可能做一些和太空有关的事?传统答案是不可能,因为火箭太贵。但马斯克开始追问基本物理要求:不就是金属和燃料吗?这些东西本身并没有贵到不可承受。
这就是第一性原理的早期形态。普通人看到“火箭公司”会想到 NASA、军方、Boeing、Lockheed、几十亿美元预算、国家工程。马斯克看到的是材料、燃料、质量、推力、单位载荷入轨成本。
这段也体现了马斯克的使命驱动方式。Reid Hoffman 后来评价说,马斯克不是先从商业模型出发,而是先从使命出发,再反向补一个财务上能维持的模型。SpaceX 最初不是典型商业计划,而是一个使命:让人类成为多星球物种。
3. 为什么是火星:技术进步不是自动发生的
马斯克给自己进入航天行业找了三个理由。
第一,他认为技术进步不是自动发生的。美国曾经登月,但之后航天进展放缓。马斯克担心文明会像古埃及、罗马那样失去曾经掌握的能力。这个判断很重要:在他看来,停滞本身就是风险。
第二,他认为人类需要多星球备份。小行星、气候变化、核战争等风险都可能威胁地球文明。如果意识是宇宙中稀有现象,那么延长人类意识存在时间就是一个足够大的目标。
第三,他认为人类需要激动人心的梦想。生活不能只是解决日常问题,还需要伟大的、能让人早上起床的目标。
这三个理由共同构成 SpaceX 的使命叙事:不是造一家公司,而是恢复技术进步、保护文明、重新点燃探索精神。
这个使命叙事有双重作用。它能吸引人才、承受失败、解释高风险;但也容易让人把马斯克的个人判断包装成“历史使命”,从而降低组织对风险和代价的抵抗力。
4. 俄罗斯买火箭失败:从采购思维转向制造思维
第 15 章 Rocket Man SpaceX, 2002 讲了一个关键失败:马斯克本来想买俄罗斯退役火箭,用来把一个小温室送到火星,让公众看到绿色植物在红色星球上生长,从而激发 NASA 和公众重新关注火星。
他找了 Jim Cantrell 这类熟悉美俄火箭项目的工程师,一起去俄罗斯谈判。第一次谈判充满羞辱和荒诞,第二次价格又不断上涨。马斯克本来以为能买两枚 Dnepr 火箭,结果发现俄罗斯方面要价越来越高,且态度轻蔑。
这次失败很关键。如果俄罗斯人愿意便宜卖火箭,马斯克可能只是做一次火星公益实验。但谈判失败迫使他重新框定问题:为什么我要买别人的旧火箭?为什么不能自己造?
这就是从采购思维到制造思维的转变。
- 采购思维:火箭很贵,我要找到便宜供应商。
- 制造思维:火箭为什么贵?材料本身贵吗?制造流程贵在哪里?行业结构为什么允许这种贵?
马斯克生气后会重新框定问题,这是书里反复出现的模式。俄罗斯谈判失败,反而把他推向更大的目标:不再买火箭,而是创办火箭公司。
5. 第一性原理:idiot index 与火箭成本拆解
书中最直接对应“第一性原理”的小节就是 First principles。
马斯克在飞机上开始用电子表格计算中型火箭所需材料:碳纤维、金属、燃料和其他基本材料。结论是,火箭成品价格至少是材料成本的五十倍。这就是他所谓的 idiot index:成品价格相对基础材料成本的倍率。
如果一个产品的 idiot index 很高,说明高成本不完全来自物理材料,而来自制造、供应链、认证、组织层级、低效率采购、垄断和惯例。这就意味着成本可以被攻击。
这套思路的威力在于,它把“火箭很贵”这个社会事实,拆成了“材料成本 + 制造成本 + 供应链加价 + 规范成本 + 组织效率”这些可分析项。
对传统航天来说,高价格像自然现象;对马斯克来说,高价格是一个工程问题。
6. SpaceX 的初始策略:先做小火箭,聚焦单位入轨成本
马斯克没有一开始就做巨型火箭。他选择从较小的 Falcon 1 开始,因为这样犯错成本较低。他的判断是:会做蠢事,但不要在大规模上做蠢事。
这个策略体现了高风险中的风险控制:
- 使命很大,但第一步要小。
- 目标是火星,但商业落点先是小卫星发射。
- 愿景是多星球文明,但现金流要来自商业和政府卫星发射。
他聚焦的关键指标是:每磅载荷进入轨道的成本。这个指标把复杂行业简化成一个可优化目标:用更低成本把更多有效载荷送入轨道。
这也解释了为什么 SpaceX 后来会执着于推力、质量、垂直整合和可重复使用。所有这些都服务于同一件事:降低单位入轨成本。
7. 早期团队机制:找不怕风险、愿意动手的工程师
第 17 章 Revving Up SpaceX 的重点,不是给早期成员做人物介绍,而是说明 SpaceX 如何搭建一支不同于传统航天公司的团队。
传统航天公司往往依赖大部门、长流程和供应商体系。SpaceX 早期更需要的是三类能力:懂关键技术、愿意亲自上手、能承受高不确定性。
所以早期团队的筛选标准,不只是履历是否光鲜,而是能不能在小公司里直接解决真实问题。SpaceX 早期不像传统航天公司那样有巨大部门和层层流程,而是更像硬核工程作坊:工程师亲自设计、制造、测试、修复。
这对打穿高壁垒行业很重要。进入高壁垒行业,不能只招“懂流程的人”,还要招“能把流程拆掉、亲手把东西做出来的人”。
8. 火箭制造规则一:Question every cost
第 18 章是核心章节,标题就是 Musk's Rules for Rocket-Building。
第一条是质疑每一项成本。SpaceX 早期发现,传统供应商报价经常离谱:一个阀门可能报价 25 万美元,一个执行器可能报价 12 万美元。马斯克的反应是:这东西真的有这么复杂吗?能不能自己做?
他的思路不是简单压价,而是拆解功能:这个部件到底要完成什么任务?有没有其他行业的类似部件?能不能改造?书里提到,SpaceX 工程师甚至把汽车清洗系统里的阀门改造成火箭燃料系统可用的部件。
这背后的方法是跨行业类比:航天行业说一个东西很贵,马斯克会问汽车、家用设备、工业设备里有没有类似功能的东西。只要物理要求能满足,就不接受“航天级所以贵”的默认解释。
9. 火箭制造规则二:质疑每一项需求
比质疑成本更深一层,是质疑需求。
传统航天充满军事、NASA、大公司积累下来的规格要求。大公司工程师通常把这些要求当成法律。马斯克不接受。他会问:谁写的这个要求?为什么有这个要求?写这个要求的人叫什么名字?如果回答只是“军方要求”或“法务要求”,他认为不够。
他的原则是:所有要求都只是建议,只有物理定律不可改变。
这句话是 SpaceX 文化的核心。它把权威从组织文件转移到物理现实。文件可以错,流程可以错,部门可以错,只有物理约束不能错。
但这里也有风险。不是所有规范都是愚蠢的,有些规范是血的教训。马斯克式质疑的价值在于打破僵化;危险在于过度轻视安全冗余和组织记忆。
10. 火箭制造规则三:maniacal sense of urgency
马斯克反复强调极端紧迫感。他会把已经很紧的进度再砍半,要求工程师压缩时间。Tom Mueller 认为这有时能逼出不可思议的结果,有时也会严重打击士气。
这种紧迫感对高壁垒行业的价值在于,它打破了“航天项目天然要十年”的默认节奏。传统大公司和政府合同可以慢慢推进,因为延期也能拿钱。SpaceX 没有这种保护,时间就是生死。
但这也是马斯克方法最有争议的地方。合理紧迫感能逼迫团队删除浪费、减少等待、直接测试;不合理紧迫感会让工程师觉得目标物理上不可能,从而变成羞辱和消耗。
所以这条规则不能简单复制。更准确的表达是:用紧迫感打破惯性,但必须识别物理不可能和组织懒惰之间的区别。
11. 火箭制造规则四:Learn by failing
SpaceX 的测试文化是“快速原型、测试、炸掉、修正、再来”。这和传统航天追求发射前大量文档、认证和预防性测试不同。
书里举了发动机测试例子:传统军事规格要求每个新版本发动机在各种条件下测试很多小时。马斯克倾向于先造一个,点火,推到坏掉,从坏掉中知道极限。
这不等于盲目冒险。它是一种不同的风险模型:
- 传统模型:尽可能在纸面和地面上消除风险。
- SpaceX 模型:通过更快、更便宜、更频繁的真实测试暴露风险。
前者适合失败成本极高且不能频繁试验的系统;后者适合能把测试成本降下来、并快速从失败中学习的系统。SpaceX 的优势在于,它通过垂直整合和低成本制造,让“失败一次”的成本下降,从而让快速迭代成为可能。
12. 火箭制造规则五:Improvise
即兴修复是 SpaceX 早期重要能力。闪电击中测试台导致燃料箱鼓包和破裂,传统航天公司可能要更换部件、等待数月。马斯克让工程师现场敲回去、焊好、继续测。
有些即兴修复成功了,节省数月。有些失败了,比如发动机推力室裂纹,马斯克尝试用环氧胶修补,最后失败,还是要重新设计。
这说明马斯克的即兴不是总正确,但它改变了团队的心理边界:不要默认损坏就意味着停摆,不要默认只有标准路径可以解决问题。
即兴能力对创业公司尤其重要,因为资源有限、时间有限、没有大公司后备方案。但即兴不能替代工程判断。最好的状态是:敢于尝试非标准方案,同时用测试结果迅速判定是否继续。
13. 华盛顿和 NASA:技术突破还不够,还要打穿制度壁垒
第 19 章显示,SpaceX 要成功,不只要会造火箭,还要进入政府航天采购体系。这里 Gwynne Shotwell 的作用很大:她负责把工程能力转化成客户沟通、商业合同和政府关系,补上马斯克和工程团队不擅长的外部接口。
SpaceX 早期赢得国防部小卫星发射合同,又把 Falcon 1 火箭拉到华盛顿展示,引起 NASA 注意。随后,NASA 给 Kistler Aerospace 一个无竞争合同,让马斯克非常愤怒。他认为 NASA 不该用合同去救一家财务不稳的老公司,而应该开放竞争。
他最后选择起诉 NASA。这个动作风险很大,因为 SpaceX 还需要 NASA。但结果是 SpaceX 赢得争议,项目被迫开放竞争,SpaceX 得到重要机会。
这里的关键是:马斯克不只挑战技术成本,也挑战制度成本。传统 cost-plus 合同让承包商按成本加利润拿钱,项目越拖越贵,承包商仍然有钱赚。SpaceX 推动固定价格、里程碑式合同,承包商承担风险,按结果拿钱。
这改变了激励结构。传统模式奖励过程和成本,SpaceX 模式奖励结果和效率。
14. Kwaj:远离舒适区的硬核执行实验
第 22 章 Kwaj 讲 SpaceX 为什么去夸贾林环礁发射。原计划在加州 Vandenberg 空军基地发射,但军方规则复杂,还要等一颗秘密卫星发射,时间不可控。SpaceX 没有 cost-plus 合同兜底,等不起。
于是他们转向太平洋中部的 Kwajalein Atoll。这个地点物流极差,距离洛杉矶约 4800 英里,去一趟要接近 20 小时。实际发射点 Omelek 是更小的无人岛。
从理性角度,马斯克后来也承认去 Kwaj 是错误选择,因为盐雾、物流和距离极大降低成功概率。但从组织文化角度,Kwaj 也锻造了团队。工程师住简陋营地,自己铺路、自己修设备、自己搬运和抢修。
Kwaj 是 SpaceX 文化的极端样本:没有舒适条件,没有大公司基础设施,只有目标、工程师、火箭和不断出问题的现场。
15. 第一次失败:发射了,但没有活下来
2006 年 3 月 24 日,Falcon 1 第一次发射。火箭升空后很快失去推力,坠入海中。原因后来追溯到燃料泄漏和 B-nut 腐蚀问题,Kwaj 的海边环境也是因素。
这次失败暴露了两个问题。
第一,SpaceX 的工程还不成熟,低成本和快速推进带来的风险真实存在。
第二,马斯克的责任文化有副作用。他强调每个部件、流程和规格都要有人负责,但失败后容易把复杂系统问题人格化,快速归咎给某个工程师。Jeremy Hollman 事件就是例子。后来事实显示他并非真正原因,但伤害已经产生。
这里能看出 SpaceX 方法的阴影:快速学习需要追责,但如果追责变成公开归咎,会损害信任和人才保留。
16. 第二次失败:接受风险的代价
第一次失败后,SpaceX 更谨慎了,开始记录更多组件细节,但马斯克没有允许团队消除所有风险。因为如果消除所有风险,SpaceX 会变得像传统航天一样昂贵、缓慢。
第二次发射时,Falcon 1 进入太空但未能入轨。原因是第二级燃料晃动,也就是 slosh 问题。团队此前把 slosh 风险排在风险清单第 11 位,决定不加装会增加重量的上级 slosh baffles。结果这个低概率风险成了失败原因。
这次失败说明,第一性原理不是保证正确,而是让风险选择更明确。马斯克选择轻量化和速度,接受部分风险,现实测试给出反馈:这个风险不能忽略。
失败后他说,以后风险清单不能只看前 10 项,要看到第 11 项。这句话体现了真实测试如何改变组织认知。
17. 第三次失败:技术问题叠加生死压力
第 28 章 Strike Three 是第三次失败。第三次 Falcon 1 发射中,第一级分离后与第二级发生碰撞,导致未能入轨。
这次失败的严重性在于,马斯克原本只预算三次尝试。三次都失败后,SpaceX 没有自然的下一次机会。它不只是技术失败,而是公司死亡边缘。
到这里,SpaceX 的第一性原理、低成本制造、快速试错还没有被证明是成功方法。外界完全可以认为这只是一个互联网富豪烧钱造火箭的失败实验。
高壁垒行业的残酷之处就在这里:你可以在方法论上看起来对,但只要关键验证没过,市场和资本都不会承认你。
18. 2008:SpaceX 和 Tesla 同时濒死
第 29 章 On the Brink 把 SpaceX 危机和 Tesla 危机放在一起。2008 年金融危机爆发,Tesla 也接近破产,SpaceX 还没有入轨成功。马斯克个人也接近破产,还背负离婚成本。
这段很重要,因为它显示马斯克不是在资源宽裕时坚持理想,而是在极限约束下拒绝放弃任何一个“孩子”。旁人建议他放弃 SpaceX 或 Tesla,至少保住一个。他拒绝,因为放弃 Tesla 会强化“电动车不行”,放弃 SpaceX 会断掉“多星球物种”的目标。
从理性投资角度,这可能是不合理的风险集中。从使命驱动角度,这是马斯克式 all-in 的典型样本。
这个阶段也揭示了高强度模式的代价:夜惊、呕吐、体重剧烈变化、身体濒临崩溃。SpaceX 的胜利不是轻盈的创新故事,而是几乎把人压碎的危机推进。
19. 第四次发射:从死亡边缘到行业重新定价
第 30 章 The Fourth Launch 是 SpaceX 早期故事的转折点。
PayPal 旧关系网络在此时发挥作用。Founders Fund 投资 SpaceX,给第四次发射提供资金。讽刺的是,这些 PayPal 旧人当年曾把马斯克从 CEO 位置上赶下去,但马斯克后来没有彻底断绝关系,反而在关键时刻得到帮助。
这说明商业世界中的失败关系也可能转化为未来资源。马斯克如果当年和 PayPal 旧人彻底决裂,SpaceX 可能无法撑到第四次发射。
第四次发射前,马斯克要求六周内把新火箭送到 Kwaj。团队包 C-17 军用运输机运火箭,途中火箭压力失衡,外壳像可乐罐一样凹陷。工程师想运回去,马斯克要求继续送到 Kwaj 现场修。
这就是 SpaceX 文化的集中体现:
- 时间不够,就包军机。
- 火箭受损,就现场抢修。
- 文件流程太慢,就压缩要求。
- 团队觉得不可能,就在死亡边缘完成。
最终,2008 年 9 月 28 日,Falcon 1 第四次发射成功入轨,成为首个由私人公司建造、从地面发射并进入轨道的液体燃料火箭。
这次成功改变了行业认知。SpaceX 不再只是疯狂故事,而变成可被验证的商业航天公司。
20. NASA 合同:技术验证变成商业生命线
第四次成功后,NASA 授予 SpaceX 16 亿美元合同,为国际空间站执行 12 次货运往返。这不只是收入,更是信任背书。
这也证明了 SpaceX 早期策略的闭环:
- 用第一性原理降低火箭成本。
- 用私人资本承担早期技术风险。
- 用快速失败完成真实验证。
- 用固定价格/里程碑合同进入政府市场。
- 用成功发射赢得更大合同。
NASA 合同让 SpaceX 从“可能死亡的创业公司”变成“美国航天体系的新供应商”。
21. SpaceX 打穿高壁垒行业的机制
综合这些章节,SpaceX 的突破不是单点创新,而是系统性重构。
21.1 成本结构重构
通过 idiot index、供应商替代、自制零件和跨行业采购,SpaceX 把传统航天成本当作可攻击对象。
21.2 制造边界重构
传统航天大量依赖外包和供应商,SpaceX 尽量垂直整合,把关键部件、发动机、测试和制造掌握在内部。
21.3 测试节奏重构
传统航天追求少失败、重文档、慢验证。SpaceX 通过快速真实测试,把失败变成学习机制。
21.4 合同激励重构
传统 cost-plus 合同奖励成本和过程,SpaceX 推动固定价格、按结果付费,让效率成为公司生死线。
21.5 人才文化重构
传统航天强调资历、流程和组织层级。SpaceX 更看重能否亲手解决问题、是否能承受高压、是否愿意快速试错。
22. 这套方法的副作用
这部分不能只写成成功学。SpaceX 方法有明显副作用。
第一,极限紧迫感会损伤士气。Mueller 明确指出,如果目标被认为物理上不可能,工程师会被打击。
第二,低成本和快速试错会带来真实失败。前三次 Falcon 1 发射失败都不是小问题,每一次都可能让公司死亡。
第三,责任到人容易变成归咎个人。Jeremy Hollman 事件显示,系统失败可能被简化成某个人的错。
第四,危机推进会伤害身体和关系。2008 年马斯克承受的压力已经接近崩溃。
第五,使命叙事容易合理化过度风险。为了火星和人类文明,团队可能接受过高强度和过高个人代价。
因此,SpaceX 的可学习部分不是“无脑压榨”,而是:拆成本、拆需求、缩短反馈、掌握关键制造、改变激励结构。不可学习部分是:长期把人维持在崩溃边缘。
23. 管理启发
23.1 处理高壁垒任务时,先算 idiot index
遇到看起来很贵、很难、很专业的任务,先拆成本:真正不可替代的材料、工具、权限、知识是什么?哪些只是中间商、流程、品牌、惯例带来的成本?
23.2 所有需求都要追问来源
当有人说“必须这样做”,要追问:谁说的?为什么?如果不这样会发生什么?这是物理限制、法律限制、业务限制,还是历史习惯?
23.3 用小规模失败降低大规模失败
不要在脑子里无限规划。把任务拆成可测试版本,允许早失败、低成本失败、快速修正。
23.4 控制关键环节,而不是控制所有环节
SpaceX 的垂直整合不是把所有东西都自己做,而是把决定成本、质量、速度和技术路线的关键部分抓在手里。个人项目也应识别关键环节。
23.5 危机模式必须有退出条件
SpaceX 早期靠危机推进成功,但代价极大。工作系统记录高强度任务时,必须写清楚:危机从何时开始,目标是什么,什么时候退出,恢复如何安排。
23.6 固定价格思维:按结果而不是按过程评估
cost-plus 合同的问题是过程越长越赚钱。个人工作也容易这样:花很多时间,但没有结果。应该更多用“交付了什么”而不是“忙了多久”评估。
24. 一句话总结
SpaceX 早期的本质,是马斯克把航天从一个被高成本、慢流程、供应商垄断和政府合同锁死的行业,重新拆成物理、成本、制造、测试和激励问题;这种第一性原理方法让 SpaceX 打穿壁垒,但也伴随着极高失败率、极限压力和组织伤害。
---
layout: post
title: 《Elon Musk》AI、Autopilot、Optimus 与 Neuralink 解读:现实工程与愿景膨胀
subtitle: Codex 个人助理沉淀
date: 2026-06-12 02:09:05 -0400
tags:
- 个人助理
- 读书笔记
- Elon Musk
---
来源:notes/books/Elon Musk/11_AI_Autopilot_Optimus与Neuralink_现实工程与愿景膨胀解读.md
《Elon Musk》AI、Autopilot、Optimus 与 Neuralink 解读:现实工程与愿景膨胀
来源:notes/books/Elon Musk/source_materials/epub_full_text.md
主要依据:第 40 章 Artificial Intelligence、第 41 章 The Launch of Autopilot、第 54 章 Autonomy Day、第 64 章 Optimus Is Born、第 65 章 Neuralink、第 66 章 Vision Only、第 77-80 章关于 Optimus 和 Robotaxi、第 89 章 Miracles、第 93-94 章关于 Tesla AI 与 X.AI。
说明:本文是基于原书转换稿的中文解读,不是原文翻译。重点解释马斯克如何把 AI、自动驾驶、机器人和脑机接口纳入同一套现实工程与宏大愿景之间的张力。
1. 结论
AI、Autopilot、Optimus 和 Neuralink 这条线展示的是马斯克面对智能技术时的典型模式:他会把复杂问题压缩为数据、算力、工程迭代和人才密度问题,然后用极高强度推动团队逼近突破。
这套方法确实有力量:
- 它让 Tesla 很早把汽车看成移动计算平台。
- 它让自动驾驶从传统规则系统转向更依赖数据和神经网络的路径。
- 它让 Optimus 不只是机器人项目,而是 Tesla AI 能力的延伸。
- 它让 Neuralink 把脑机接口从实验室愿景推向可工程化产品。
- 它让马斯克在 OpenAI、Tesla AI、X.AI 之间持续追逐通用人工智能入口。
但这条线也暴露出严重风险:马斯克经常把长期可能性说成短期确定性,把工程方向说成即将完成的产品,把迭代速度扩展到涉及生命安全、公共道路、动物实验、人体试验和社会影响的领域。
这部分最重要的启发是:愿景可以拉动工程,但不能替代安全边界和现实进度。
2. AI 对马斯克不是工具,而是文明风险
书中关于 AI 的部分,不只是 Tesla 技术路线。马斯克很早就把 AI 看成文明级风险。他参与 OpenAI 的早期创建,担心少数公司控制强大 AI,也担心 AI 目标与人类不一致。
这解释了他在 AI 议题上的矛盾行为:
- 他一方面警告 AI 风险。
- 一方面又在 Tesla、X.AI 和其他项目中强力推进 AI。
- 他批评别人可能失控,但自己也想掌握核心能力。
这不是简单虚伪,而是他的典型控制逻辑:如果某项技术危险且重要,就更不能让别人单独控制。他会把风险感转化成进入理由。
问题在于,这种逻辑会导致永久升级。越觉得技术危险,越想亲自推进;越亲自推进,越增加风险集中和速度压力。
3. Autopilot:把汽车变成数据和软件平台
Autopilot 的关键意义,是 Tesla 不再只是汽车公司,而是拥有巨大真实道路数据的 AI 公司。
传统汽车公司更多把驾驶辅助看成零部件和功能包。Tesla 的路径不同:车辆是传感器终端,用户车队是数据来源,软件更新让能力持续变化,神经网络从真实世界行为中学习。
这条路线有几个优势:
- 数据规模大。
- 软件迭代快。
- 车辆和用户反馈直接连接。
- 产品体验可以通过 OTA 更新持续变化。
但它也带来一个根本张力:汽车不是纯软件。软件可以灰度发布,公共道路上的驾驶功能却直接关系生命安全。一个功能的命名、宣传、默认设置和用户理解,都可能影响真实风险。
4. 视觉路线:第一性原理还是路径依赖
马斯克长期坚持视觉路线,后来推动 Tesla 删除雷达,强调人类驾驶主要依靠视觉,因此汽车也应通过摄像头和神经网络实现驾驶。
这个判断有第一性原理色彩:如果人类可以靠眼睛驾驶,那么机器也应能用视觉理解道路。
但这里也有争议。人类视觉不是单独摄像头,人类拥有常识、身体经验、注意力机制和复杂预测能力。机器视觉系统是否应删除其他传感器,不只是哲学问题,而是工程、安全和冗余问题。
马斯克的优势是敢于砍掉传统方案,避免系统复杂度无限上升。风险是当他过早相信单一路线,会把冗余也当成浪费删除。
这和管理算法的风险一致:不是所有冗余都是官僚,有些冗余是安全系统。
5. 承诺过度:Autonomy Day 与现实进度差
Autonomy Day 体现马斯克的叙事能力,也体现他的承诺过度。Robotaxi、完全自动驾驶和车队自动赚钱的想象,极大推高了 Tesla 的科技公司估值逻辑。
这类发布有战略作用:
- 吸引资本。
- 吸引人才。
- 让团队围绕宏大目标加速。
- 改变市场对 Tesla 的定位。
但代价是用户预期、监管风险和信任损耗。当时间表反复落空,愿景本身会从激励变成压力源。
工程里可以说“我们朝这个方向快速迭代”;商业宣传里说“很快就会实现”,性质完全不同。前者是内部目标,后者会影响用户购买、使用和风险判断。
6. Optimus:从自动驾驶 AI 到人形机器人
Optimus 的逻辑,是把 Tesla 在电池、电机、传感器、制造和 AI 上的能力延伸到人形机器人。马斯克认为,如果 Tesla 能让汽车理解世界并移动,那么机器人就是类似问题的扩展。
这个判断有合理性。机器人确实需要:
- 感知。
- 运动控制。
- 电池和执行器。
- 低成本制造。
- 真实世界 AI。
- 大规模数据和训练。
但人形机器人也比汽车更开放。汽车主要在道路环境中移动,任务边界相对清晰;人形机器人要进入家庭、工厂和人类空间,操作对象高度复杂,安全和可靠性要求更细。
Optimus 的价值在于,它让 Tesla 的 AI 叙事从汽车扩展到通用劳动力。风险在于,通用劳动力是极难问题,短期演示容易掩盖长期落地难度。
7. Neuralink:治病愿景与高风险工程
Neuralink 是马斯克最能体现“现实工程与科幻愿景结合”的项目之一。它一方面面向真实医疗需求,比如帮助瘫痪、神经损伤或运动障碍患者恢复部分能力;另一方面又带有更宏大的目标:增强人类与 AI 共存的能力。
这条线的正当性很强,因为脑机接口如果成功,可能显著改善患者生活。但它的风险也高,因为它涉及动物实验、人体植入、长期安全、监管审批和伦理边界。
马斯克在这里仍然使用类似方法:
- 提高工程速度。
- 压缩设备体积。
- 推动芯片、机器人手术和数据处理一体化。
- 用宏大愿景吸引人才。
但医疗工程不是火箭试验。失败成本不只是设备损坏,还可能是生命、健康和伦理后果。Neuralink 最需要的是在速度和审慎之间建立更强边界。
8. X.AI:数据流、算力和控制权
到 X.AI 这条线,马斯克对 AI 的关注从风险警告和应用工程,进一步转向基础模型竞争。他关心数据、算力、人才和平台入口。
这和 Twitter/X 也有关。社交平台拥有实时人类表达数据,Tesla 拥有真实世界视觉和驾驶数据,SpaceX/Starlink 拥有基础设施能力。这些资源在马斯克视角里不是孤立资产,而可能构成 AI 竞争中的数据和分发网络。
这里再次出现他的控制逻辑:重要技术不能只依赖外部平台。如果 AI 是未来核心层,他就会想要自己的模型、自己的数据流、自己的分发入口。
9. 现实工程和愿景膨胀的分界线
马斯克的强项,是把科幻愿景拉进工程现实。他不会只停在“未来会有机器人”这种描述,而是会问电机、芯片、成本、数据、产线和团队怎么做。
但他的风险,是把工程推进中的可能性说得过于确定。
可以用三个问题区分现实工程和愿景膨胀:
- 当前系统在哪些条件下已经可靠工作?
- 哪些部分仍依赖演示、假设或理想环境?
- 失败成本由谁承担?
如果失败成本主要由内部测试承担,快速迭代更合理。如果失败成本由道路用户、患者、动物、消费者或公共系统承担,就必须增加外部约束。
10. 这条线的管理启发
10.1 区分方向正确和时间表正确
一个方向长期可能正确,不代表短期承诺可靠。复盘计划时,应分别记录“方向判断”和“时间表判断”。
10.2 对高风险任务设置外部边界
涉及健康、财务、法律、公共影响或他人安全时,不能只靠快速试错。要增加审查、缓冲和退出条件。
10.3 不要把演示当成交付
演示证明可能性,交付证明可靠性。个人项目也一样:样例跑通不等于流程稳定。
10.4 记录承诺债务
每次对外承诺时间表,都是债务。工作系统应记录承诺对象、截止时间、当前证据和风险等级,防止愿景叙事滚雪球。
10.5 把宏大愿景拆成可验证里程碑
愿景可以大,但下一步必须小。对 AI、机器人或任何复杂项目,都要拆成可测试、可失败、可复盘的阶段。
11. 一句话总结
AI、Autopilot、Optimus 和 Neuralink 展示了马斯克把科幻愿景压进工程现实的能力,也展示了他最危险的倾向:在涉及生命安全、公共道路和社会影响的领域,把长期愿景、短期承诺和快速迭代混在一起。
---
layout: post
title: 时间使用方式决定人生结构
subtitle: Codex 个人助理沉淀
date: 2026-06-11 05:00:17 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/time_management/01_时间使用方式决定人生结构.md
时间使用方式决定人生结构
核心判断
如果时间使用方式不变,人生轨道很难改变。
时间是人生的底层资源,管理时间其实是在管理人生结构。
解释
人的目标、愿望和自我叙事可以变化得很快,但人生轨道通常由每天真实发生的时间分配决定。一个人把高质量时间持续投向哪里,哪里就会逐渐长出能力、关系、资产和机会;一个人把时间持续消耗在哪里,那里也会成为生活结构的一部分。
所以时间管理不是单纯提高效率,也不是把日程填满,而是重新定义人生资源的分配方式。要改变轨道,必须让时间结构先发生变化。
可执行规则
- 每周回看一次时间实际流向,而不是只回看任务完成情况。
- 区分“想要改变的目标”和“已经投入时间的目标”,以后者判断真实优先级。
- 如果一个方向很重要,就必须在日历上有稳定、重复、不可轻易挤占的时间块。
- 对低价值但高占用的活动设置边界,否则它们会默默塑造人生结构。
下一步动作
- 做一次最近 7 天的时间流向复盘,标出工作、投资研究、写作、关系维护、放松和无目的信息输入各自占用的时间。
- 找出一个最想改变的人生方向,为它安排一个固定时间块。
---
layout: post
title: VSCode 风格博客 Reader 工作模式方案
subtitle: Codex 个人助理沉淀
date: 2026-06-11 04:20:07 -0400
tags:
- 个人助理
- 项目
- github_pages_sync
---
来源:notes/projects/github_pages_sync/02_VSCode风格博客Reader工作模式方案.md
VSCode 风格博客 Reader 工作模式方案
背景
2026-06-11 对 andywu1998.github.io 做了一轮博客阅读体验改造。目标不是把博客做得更像媒体站,而是新增一个适合上班阅读的低调工作模式:页面看起来像 VSCode 在打开 Markdown 文件,左侧是 Explorer,右侧是带行号的 Markdown 原文。
这个模式的核心诉求有三个:
- 降低博客感:减少大标题、白底文章流、社交和媒体化视觉。
- 提高工作伪装度:视觉上接近代码编辑器、内部文档和项目资料。
- 保持可用性:能按 tag、timeline、搜索快速找到文章,并支持多标签页阅读。
最终形态
新增页面:
https://andywu1998.github.io/reader/
页面结构:
左侧 Explorer
- SEARCH
- TAGS
- TIMELINE
右侧 Editor
- 顶部多标签页
- 当前 Markdown 文件路径
- open original 原博客链接
- 带行号的 Markdown 原文
关键设计决策
1. 不替换原文章详情页
原博客文章页继续保留,避免影响历史链接、SEO 和 GitHub Pages 生成逻辑。Reader 是一个新增入口,作为“工作模式”使用。
导航新增:
2. Reader 数据由 Jekyll 构建时内嵌
第一版 Reader 使用过静态 JSON:
assets/data/reader-posts.json
但这引入了额外数据生成依赖:同步 _posts 后还要刷新 JSON,否则 /reader/ 可能看不到最新文章。
后续改为由 Jekyll 在构建首页和 /reader/ 时直接遍历:
并把 metadata 和文章 HTML 内嵌到页面里:
{% for post in site.posts %}
前端不再 fetch 外部 JSON,而是读取页面内的 reader-posts-data,点击文章后从隐藏的 HTML 内容区取出文章 HTML,再转换成伪 Markdown 展示。
3. 前端全部静态实现
Reader 页面由三部分组成:
reader.html
assets/css/reader.css
assets/js/reader.js
不引入 React/Vue,不增加构建链路,保持 GitHub Pages 可直接构建。
4. 左右区域独立滚动
上线后发现原始版本仍保留顶部白色博客导航,而且左右滚动会受整页滚动影响。随后修正为:
- Reader 主区域高度使用
100vh
body 禁止滚动- 左侧 Explorer 独立滚动
- 右侧 Markdown 编辑区独立滚动
- 顶部白色导航改成左下角的小型 VSCode 风格菜单
这样鼠标在左侧时只滚 Explorer,在右侧时只滚正文。
已完成改动
Reader 第一版
提交:
385e323 Add VSCode style reader
文件:
_config.yml
reader.html
assets/css/reader.css
assets/js/reader.js
_includes/reader-app.html
实现能力:
/reader/ 页面- 左侧
SEARCH / TAGS / TIMELINE 三个视图
- 搜索标题、tag、路径、Markdown 正文
- 点击文章打开右侧内容
- 多标签页打开、切换、关闭
- URL hash 同步当前文章
localStorage 恢复已打开 tabs 和当前文章- 由渲染 HTML 转换得到的伪 Markdown 展示
- 行号展示
open original 跳转原博客文章页
Reader 布局修正
提交:
f03855c Refine reader workspace layout
修正内容:
- 去掉 Reader 顶部白色大导航条的视觉干扰
- 把导航按钮放到左下角
- Reader 页面改成全屏工作台
- 左右滚动区域独立
- 避免整页滚动影响阅读
使用方式
访问 Reader
https://andywu1998.github.io/reader/
搜索文章
进入 SEARCH 视图,输入关键词。搜索范围包括:
- 标题
- 副标题
- tag
- 本地路径
- Markdown 原文
按 tag 浏览
进入 TAGS 视图,每个 tag 是一个目录,文章是目录下的文件。
按时间线浏览
进入 TIMELINE 视图,按年份分组,文章按日期倒序展示。
多标签页
点击左侧文章:
- 如果 tab 已存在,切换到对应 tab。
- 如果 tab 不存在,新开 tab。
- 点击 tab 右侧
× 可关闭。
维护流程
新增或修改博客文章后,只需要更新 _posts 并推送。Reader 首页和 /reader/ 会在 GitHub Pages 的 Jekyll 构建阶段自动从 site.posts 读取最新文章。
不再需要:
assets/data/reader-posts.json
scripts/build_reader_data.py
如果本轮是“帮我记一下”这类个人助理记录,推荐直接运行:
cd /home/admin/code/cc-connect-work-space/codex_personal_assistant
scripts/sync_feishu_and_blog.sh
这个脚本会串联飞书同步、个人助理仓库 commit/push、博客同步和博客仓库 commit/push。Reader 数据由 Jekyll 构建自动内嵌,不再需要额外刷新。
验证记录
本地环境没有 Ruby、Bundler 和 Docker,因此不能在本机完整复现 Jekyll 构建。
已经做过的可用检查:
node --check assets/js/reader.js
git diff --check
线上页面已可访问,说明 GitHub Pages 构建和部署成功。
后续动作
- 给 Reader 增加快捷键:
Ctrl+P 搜索文章Ctrl+W 关闭当前 tabCtrl+Tab 切换 tab
- 增加“只看个人助理 / 读书笔记 / 投资研究”的快速筛选。
- 根据实际上班阅读体验,继续压缩字号和行距。
---
layout: post
title: 地平线跌破 5 元后的投资灵感
subtitle: Codex 个人助理沉淀
date: 2026-06-11 00:02:09 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/horizon_robotics/01_地平线跌破5元后的投资灵感.md
地平线跌破 5 元后的投资灵感
记录时间:2026-06-06 00:22:34 CST
原始输入
如大家看到,地平线今天跌破了5元。今天简单聊聊。
我这个号最开始写投资,吸引来一些关注,后来很大篇幅写地平线,又涨粉了一波。
我们要投资看得懂的企业,是因为经过长期跟踪,会对底部有一个察觉,知道什么时候虚高,什么时候被错杀,愿意耐心持有。
长期关注所以知道企业的业务进展。
2026-06-11 追加记录:下跌后的仓位与成本压力
原始输入:
今天地平线又是跌3个点,已经跌了50%了,在不继续充钱进股市的话,我如果全仓买入,成本就6.15。
这一条记录和“地平线跌破 5 元”的主题是连续的:价格继续下跌之后,问题不只是判断企业是否被错杀,还会转化成更具体的仓位、现金流和心理压力问题。
这里的关键变量有四个:
- 是否继续向股市投入新增资金。
- 如果不新增资金,现有资金全仓买入后的持仓成本约为 6.15。
- 股价累计下跌约 50% 后,继续加仓是在基于基本面再评估,还是主要为了摊低成本。
- 全仓之后,是否仍保留应对继续下跌、生活现金流和其他机会的空间。
这条记录不直接导向“应该买”或“不应该买”,更适合作为后续复盘的决策节点:当时面对大幅下跌,真实的约束条件是什么,买入逻辑是否仍成立,仓位纪律是否被价格波动推着走。
核心观点
投资“看得懂的企业”的价值,不只是能讲清楚商业模式,而是长期跟踪之后,会形成对企业真实进展、市场预期和股价情绪的相对判断。
这种判断至少包括三层:
- 知道企业业务是否真的在推进。
- 知道市场什么时候把预期打得过高。
- 知道市场什么时候因为短期价格或情绪把企业错杀。
可扩写成文的主线
文章可以从“地平线跌破 5 元”切入,但重点不放在短期股价,而放在为什么长期跟踪一家公司会降低投资中的心理波动。
可用结构:
- 开场:地平线跌破 5 元,引出今天想聊的不是涨跌,而是长期跟踪。
- 个人背景:这个号最早写投资,后来因为持续写地平线吸引了一批关注者。
- 核心判断:投资看得懂的企业,是为了在价格大幅波动时仍能判断企业是否变差。
- 长期跟踪的优势:知道业务进展、客户变化、产品节奏、行业位置和竞争压力。
- 投资心态:只有看得懂,才可能在虚高时克制,在错杀时拿得住。
- 收束:地平线当前价格是否到底,需要事实验证;但长期跟踪能让判断不只跟着分时线走。
待验证事实
- “地平线今天跌破 5 元”:需核验具体交易日期、市场、收盘价/盘中价。
- “2026-06-11 又跌约 3 个点、累计跌约 50%”:需核验当日价格、阶段跌幅口径和对应时间区间。
- “全仓买入后成本约 6.15”:需结合当时持仓数量、剩余可用资金、买入价格和交易费用重新计算。
- 地平线近期业务进展:可结合最近公告、研报、交付数据和主机厂合作进展补充。
- 是否属于“错杀”:需要对比估值、收入增长、毛利变化、订单和竞争格局后再判断。
下一步动作
- 如果要发公众号,先补一段事实核验:股价、成交额、跌幅、近期催化或利空。
- 从已有 Bernstein 研报笔记中提取 3 个业务进展点,作为“为什么长期关注才看得懂”的证据。
- 明确文章态度:不直接喊底,重点写“长期跟踪如何帮助判断底部区域”。
- 单独复盘仓位纪律:在不继续投入新增资金的前提下,计算全仓后的成本、最大可承受回撤和再次评估触发条件。
---
layout: post
title: 地平线股东大会问答:自研芯片、HSD、FSD 入华和股价压力
subtitle: Codex 个人助理沉淀
date: 2026-06-10 08:50:39 -0400
tags:
- 个人助理
- 项目
- 地平线机器人20260610股东大会
---
来源:notes/projects/地平线机器人20260610股东大会/02_公众号版_从股东大会看地平线的关键问题.md
地平线股东大会问答:自研芯片、HSD、FSD 入华和股价压力
说明:本文基于 2026-06-10 地平线机器人股东周年大会音频自动转写稿整理。转写稿未做逐字人工校对,个别专有名词、数字和英文人名可能存在识别误差。本文仅作为个人研究记录,不构成投资建议。
地平线这次股东周年大会,前半段是标准 AGM 流程,包括董事介绍、财报、董事重选、审计师续聘、回购授权、发行授权等决议。真正有信息量的是后半段股东问答。
这场问答里,投资人问得很直接:比亚迪自研芯片会不会影响地平线?智能驾驶供应商是不是越来越拥挤?股价跌成这样管理层怎么看?HSD 今年还能不能交付 40 万辆?研发投入这么高什么时候盈利?特斯拉 FSD 入华到底是威胁还是机会?
管理层的回答也基本围绕这几条主线展开。整场听下来,我觉得它不是一次简单的股东会问答,而是地平线对外重新解释自己商业模式的一次集中表达。
一、地平线到底想成为什么公司?
第一个重要问题,是车企自研芯片。
股东问到,比亚迪 5 月份发布自己的芯片和智能座舱 OS,比亚迪过去又是地平线的重要客户之一,那车企自研会不会挤压地平线?
管理层没有直接展开具体客户合作,而是先把地平线的定位重新讲了一遍。
他们强调,地平线不是一家单纯的芯片公司。它是“芯片 + 软件”的公司,但又不止于此。地平线想成为一个汇聚物理 AI 底层技术的平台型公司,核心资产包括:
- AI 计算架构 BPU
- 智能驾驶基座大模型
- 机器人基座大模型
- 芯片工具链
- 云端大数据开发平台
- 软件算法和开发平台
这背后的关键词是“底层赋能者”。管理层反复用类似 Arm + Android 的类比来解释自己:不是所有东西都自己大包大揽交付,而是通过生态供应、IP 授权、软件授权、工具链和平台能力,让车企和合作伙伴在地平线底座上构建自己的能力。
这个表述很重要。因为如果你把地平线理解成“卖芯片的供应商”,车企自研当然是威胁;但如果你把它理解成“卖底层架构、工具链和软件生态的平台公司”,车企自研反而可能成为另一种商业模式入口。
二、车企自研芯片,是威胁还是新商业模式?
管理层的核心回答是:地平线支持车企自研。
他们的逻辑是,车企在研发过程中,地平线可以收取一次性的 IP 授权费;一旦车企产品进入量产,地平线还能随着出货量收取 royalty,也就是版税。管理层提到,这种 IP 和版税模式的毛利率可以高达 90% 以上,并类比 Arm 对苹果的授权模式。
这其实是在告诉投资人:车企自研不一定等于地平线出局。地平线可以换一种方式参与。
更深一层,BPU 授权不只是收钱。管理层把它形容为“跑马圈地”。如果越来越多车企和芯片方案基于地平线 BPU 架构,那么围绕 BPU 的软件、算法、工具链和开发平台就会形成生态。以后算法迁移、软件适配、平台迭代都会和地平线绑定得更紧。
所以管理层给出的终局不是“车企自研 vs 地平线芯片”二选一,而是两条线都要在牌桌上:
- 车企自研部分,地平线通过 IP、软件、工具链和 royalty 参与。
- 第三方供应部分,地平线继续提供征程系列芯片、星空系列舱驾一体智能体芯片、HSD 软件和智能体 OS。
他们的判断是,车企长期会同时采取自研和第三方供应链并行的策略。手机行业里,华为、三星都自研过芯片,但并没有完全排除第三方供应商。管理层用这个例子说明,即使自研存在,第三方供应商仍然会占据重要份额。
这套逻辑是地平线当前最核心的投资叙事:自研芯片不是单纯利空,而是平台化商业模式的一部分。
三、智能驾驶行业会越来越拥挤吗?
第二个问题是竞争格局。
投资人问,最近很多智能驾驶公司都在推进 IPO,是不是说明赛道越来越拥挤?
管理层的回答很明确:短期看公司很多,长期看会高度收敛。
他们提到,很多正在推进 IPO 的智能驾驶公司本身就是地平线生态合作伙伴,其中有些地平线还是股东。管理层认为,这说明赛道已经完成 0 到 1 的商业模式验证,进入产业落地和爆发式增长阶段。
从芯片格局看,管理层把市场分成两个层次:
- L2 智能辅助驾驶市场,地平线认为自己已经是一家独大。
- 中高阶 AD 智能驾驶计算芯片市场,管理层认为是英伟达、华为、地平线三分天下,前三合计份额接近九成,形成“一超双强”的格局。
管理层还提到,2026 年一季度在中国车市承压、内需销量下滑的大背景下,地平线 AD 市场份额仍然逆势提升:
- 高速 NOA 方案市场份额环比提升 5 到 6 个百分点,超过 30%。
- 城区 NOA 方案份额环比提升两个多百分点,接近 7%。
- 高速 NOA 和城区 NOA 合计,AD 市占率约 16%,高于去年整体约 14% 的水平。
这些数字需要后续结合第三方数据验证。但管理层想表达的趋势很清楚:行业压力越大,越考验产品和交付能力;在这个过程中,份额反而会向头部集中。
四、股价下跌,管理层怎么回应?
股价问题是这场问答里最直接的一段。
股东问,作为长期持有者,管理层怎么看当前股价?
管理层先承认,地平线最近股价确实承压。然后给出的核心态度是三个字:平常心。
这段话有点像内部讲话的外部复述。管理层说,在地平线 11 周年庆典上,也对员工和员工家属谈过股价。他们认为,短期股价受很多因素影响,但最终还是要回到企业本质:产品到底好不好,用户是否认可,消费者是否愿意为体验付费。
管理层举了一个有意思的观察:过去 10 万到 20 万元价位段的消费者,大多会选低配或中配,很多人甚至不选择智能辅助驾驶配置。但最近搭载 HSD 的一些车型,消费者开始明显选择高配。例如某车型超过 50% 用户选择最高配,价格接近 20 万元。
这背后的判断是:如果用户真的因为地平线的芯片、HSD、智能体 OS 而选择一辆车,地平线才算真正成功。
对于股价,管理层还提到回购。今年 4 月以来,公司持续回购,累计回购接近 5 亿港币。股东大会也会授权未来 12 个月在合适时机继续回购。
所以股价问题的回答可以概括为两层:
- 短期股价承压,管理层理解投资者担忧。
- 长期价值要靠产品力、份额、用户体验和持续回购来证明。
五、HSD 今年到底怎么看?
投资人问到一个很关键的问题:年初曾经指引今年 HSD 出货 40 万辆,现在怎么看?
管理层没有直接确认或修正 40 万辆这个数字,而是把回答重点放在几个方向:
第一,上半年客户覆盖已经比较清晰,各车型月度销量也是公开数据。
第二,地平线更愿意把精力放在自己能驱动的事情上,也就是帮助客户把下一个车型和智能体验做到极致。
第三,城区智能驾驶正在向 15 万元以内车型下探,这会扩大地平线的市场空间。盘子变大之后,爆款车型概率和覆盖面也会提升。
第四,管理层认为今年无论 HSD 出货是什么数字,都仍然只是一个很小的初期交付量。真正关键的是未来份额和市场占有率。
这段回答比较值得注意。因为它没有直接给出明确的量化承诺,而是把问题从“今年交付多少”转向“未来空间有多大”。这对乐观投资人来说,是早期放量前的解释;对谨慎投资人来说,则意味着 HSD 的实际出货节奏仍然需要持续跟踪。
我会把这条列为后续观察的第一优先级。
六、研发投入高,什么时候看到盈利?
另一个股东问题也很尖锐:2025 年研发投入超过 50 亿元人民币,这么高强度投入,什么时候能看到回报和盈利?
管理层的回答是,高强度饱和研发投入是地平线面对未来竞争的战略选择。
他们把当前研发投入定义为训练一个“能持续进化的物理 AI 底座”。这个底座不仅服务于 HSD 和城区智能驾驶,也面向未来 L3、L4 自动驾驶,并且会向机器人领域延伸。
管理层也给出了一条底线:只有在资产负债表绝对健康的前提下,才会饱和投入研发。
他们提到,2025 年末地平线在手现金超过 200 亿元,毛利率达到 60% 以上。只要收入保持高速增长,研发费用增速不显著高于收入增速,未来盈利能力就是可期的。
这套说法本质上还是平台型科技公司的逻辑:
前期高研发投入,构建底层能力和生态位;一旦智能驾驶成为汽车标配,掌握核心底层技术的公司就会成为产业链里绕不开的基础设施。
管理层类比了手机时代的高通、PC 时代的英特尔。它想表达的不是短期利润,而是长期产业链利润池的位置。
七、FSD 入华,对地平线是威胁还是机会?
最后一个重要问题,是特斯拉 FSD 入华。
股东担心两件事:
第一,FSD 是全球智能驾驶标杆,进入中国后会不会抢走客户、挤压地平线份额?
第二,如果 FSD 在中国水土不服、体验不如国内方案、价格又高,会不会反过来打击消费者对智能驾驶的信心?
管理层的回答很直接:如果特斯拉 FSD 如预期入华,这是大好消息。
原因是它会带来行业的鲶鱼效应。特斯拉不是普通竞争者,它能把智能驾驶从科技圈话题,推到普通消费者面前。就像特斯拉上海工厂解决产能后,推动中国 EV 行业进入新阶段一样,FSD 入华也可能推动中国智能驾驶产业链重新定价。
管理层承认,特斯拉智能辅助驾驶能力全球领先,是重要参照物。这个参照物入场,会加速国内产业链向上对标迭代,也会提升中国消费者对智能驾驶体验的要求。
更关键的是软件订阅。
当前国内主机厂的智能驾驶功能,大多还是在购车环节完成销售,本质更像传统汽车零部件模式。但如果 FSD 在中国教育用户,让用户接受自动驾驶软件按月订阅,那么智能驾驶供应商的软件收入模型、盈利模式和估值体系都可能发生结构性变化。
管理层提到,FSD 在美国已经推行订阅,每月 99 美元,订阅用户数超过 120 万,每月可带来约 1.2 亿美元收入。这个数字仍需后续验证,但它代表的是一种想象空间:智能驾驶不只是一次性硬件收入,也可能是持续软件收入。
所以地平线对 FSD 入华的态度不是防御,而是希望它帮助整个行业完成消费者教育。
八、这场股东会真正释放了什么信号?
如果把整场问答压缩成一句话,我觉得是:
地平线正在努力把自己从“智能驾驶芯片供应商”讲成“智能汽车和机器人时代的底层平台公司”。
它希望投资者理解三件事:
第一,车企自研芯片不是单纯威胁。地平线可以通过 IP 授权、BPU、软件算法、工具链和 royalty 参与车企自研。
第二,智能驾驶行业不会长期分散。管理层相信市场会向少数核心平台收敛,地平线要成为其中之一。
第三,短期出货、股价和研发投入压力都存在,但地平线要押注的是长期平台地位。
这套逻辑很完整,也很有野心。但作为投资者,不能只听叙事,还要继续看兑现。
九、后续最该跟踪的几个问题
我会重点跟踪以下几件事:
- HSD 的真实出货节奏,尤其是年初 40 万辆指引是否能兑现。
- 搭载 HSD 的车型是否真的能带动消费者选择高配。
- 城区 NOA 份额能否从接近 7% 持续提升。
- 高速 NOA 超过 30% 的份额能否被第三方数据验证。
- IP 授权和 royalty 收入是否会在财报中逐渐显性化。
- 研发投入增速和收入增速之间的关系是否改善。
- 回购是否持续,以及回购价格和规模。
- FSD 入华后,国内智能驾驶软件付费意愿是否真的被教育出来。
地平线现在最重要的,不是讲清楚自己像 Arm + Android,而是让市场看到它真的在变成 Arm + Android。
这中间需要产品、客户、出货、收入结构和利润模型一步步验证。股东大会给出的只是路线图,接下来还要看执行。
---
layout: post
title: 长音频转写与博客同步流程
subtitle: Codex 个人助理沉淀
date: 2026-06-10 06:02:23 -0400
tags:
- 个人助理
- 项目
- audio_transcription_workflow
---
来源:notes/projects/audio_transcription_workflow/01_长音频转写与博客同步流程.md
长音频转写与博客同步流程
背景
2026-06-10 收到音频附件:
/home/admin/code/cc-connect-work-space/.cc-connect/attachments/地平线机器人202606.10.mp3
目标是先分析音频,再生成带时间戳逐字稿,写入个人助理,并同步到 GitHub Pages 博客。
音频基本信息
检查命令:
file .cc-connect/attachments/地平线机器人202606.10.mp3
ffprobe -v error \
-show_entries format=duration,bit_rate,size \
-show_entries stream=codec_name,channels,sample_rate \
-of default=noprint_wrappers=1 \
.cc-connect/attachments/地平线机器人202606.10.mp3
结果:
- 格式:MP3
- 采样率:44.1 kHz
- 声道:Stereo
- 码率:128 kbps
- 时长:约 3247.78 秒,约 54 分 08 秒
- 文件大小:约 51.97 MB
环境检查
系统已有:
系统没有现成语音识别库:
whisper
faster_whisper
whisperx
torch
torchaudio
transformers
speech_recognition
vosk
funasr
全局 Python 受 PEP 668 保护,不能直接 pip install --user。因此创建项目内临时虚拟环境:
python3 -m venv .venv-transcribe
.venv-transcribe/bin/pip install -U pip
Whisper 路线尝试
先安装 faster-whisper:
.venv-transcribe/bin/pip install faster-whisper
安装成功,但模型下载走 Hugging Face,访问 huggingface.co 超时:
curl -I --max-time 10 https://huggingface.co/Systran/faster-whisper-small/resolve/main/config.json
结果是连接超时。因此放弃 Whisper 模型下载路线。
FunASR 路线
ModelScope 可访问:
curl -I --max-time 10 https://modelscope.cn/models/iic/SenseVoiceSmall/summary
安装 FunASR 和 ModelScope:
.venv-transcribe/bin/pip install funasr modelscope
FunASR 需要 PyTorch 和 torchaudio,安装 CPU 版:
.venv-transcribe/bin/pip install torch --index-url https://download.pytorch.org/whl/cpu
.venv-transcribe/bin/pip install torchaudio --index-url https://download.pytorch.org/whl/cpu
最终关键依赖:
funasrmodelscopetorchtorchaudioffmpeg
模型选择
使用模型:
原因:
- 适合中文、英文混合音频。
- 可从 ModelScope 下载,避开 Hugging Face 超时问题。
- CPU 推理可接受,约 2 分钟音频片段推理 13-14 秒。
模型权重约 893 MB,首次运行会下载到:
/home/admin/.cache/modelscope/hub/models/iic/SenseVoiceSmall
样本验证
先截取前 60 秒验证模型可用:
mkdir -p .cc-connect/tmp
ffmpeg -y -v error \
-i .cc-connect/attachments/地平线机器人202606.10.mp3 \
-t 60 -ar 16000 -ac 1 \
.cc-connect/tmp/horizon_sample60.wav
测试脚本:
from funasr import AutoModel
model = AutoModel(model="iic/SenseVoiceSmall", hub="ms", device="cpu")
res = model.generate(
input=".cc-connect/tmp/horizon_sample60.wav",
language="zh",
use_itn=True,
batch_size_s=60,
)
print(res)
样本识别成功,确认音频开头是地平线机器人 2026 年股东周年大会的英文开场。
完整转写策略
长音频直接转写不利于定位问题,因此先用 ffmpeg 切成 120 秒小片段:
ffmpeg -y -v error \
-i .cc-connect/attachments/地平线机器人202606.10.mp3 \
-ar 16000 -ac 1 \
-f segment -segment_time 120 -reset_timestamps 1 \
.cc-connect/tmp/horizon_chunks/chunk_%03d.wav
完整转写脚本逻辑:
- 加载
SenseVoiceSmall。
- 逐个识别 120 秒音频片段。
- 去掉 FunASR 输出里的
<|...|> 标签。
- 给每个片段加粗略时间戳。
- 输出 TXT 和 JSONL。
关键输出:
.cc-connect/attachments/地平线机器人202606.10.funasr.transcript.txt
.cc-connect/attachments/地平线机器人202606.10.funasr.segments.jsonl
逐字稿写入个人助理
正式笔记位置:
codex_personal_assistant/notes/projects/地平线机器人20260610股东大会/01_逐字稿.md
源材料位置:
codex_personal_assistant/notes/projects/地平线机器人20260610股东大会/source_materials/
写入内容包括:
- 音频来源
- 音频时长
- 转写方式
- 校对状态
- 内容概览
- 分段摘要
- 带时间戳逐字稿
- 下一步动作
后续为了避免博客文章变成一大坨,又做了一次格式化:
- 按时间段增加章节标题。
- 每个章节增加“本段摘要”。
- 每条 2 分钟转写段之间增加空行。
- 校验所有时间戳逐字稿行与原 ASR 源文本完全一致,没有改动逐字稿原文。
校验脚本:
from pathlib import Path
note = Path("codex_personal_assistant/notes/projects/地平线机器人20260610股东大会/01_逐字稿.md")
src = Path("codex_personal_assistant/notes/projects/地平线机器人20260610股东大会/source_materials/地平线机器人202606.10.funasr.transcript.txt")
note_lines = [line for line in note.read_text(encoding="utf-8").splitlines() if line.startswith("[")]
src_lines = [line for line in src.read_text(encoding="utf-8").splitlines() if line.startswith("[")]
print(note_lines == src_lines)
飞书同步
创建飞书 Docs 文档:
lark-cli docs +create \
--api-version v2 \
--as user \
--content @codex_personal_assistant/notes/projects/地平线机器人20260610股东大会/01_逐字稿.md \
--doc-format markdown \
--parent-position my_library \
--format json
最终格式化版飞书文档:
https://my.feishu.cn/docx/JX27d4h99ojvvYxB3h5cmXmFnLe
回填到:
codex_personal_assistant/config/feishu_base.json
然后同步多维表格:
cd codex_personal_assistant
python3 scripts/sync_to_feishu_base.py
同步范围包括:
博客同步
博客仓库:
/home/admin/code/cc-connect-work-space/andywu1998.github.io
同步命令:
cd /home/admin/code/cc-connect-work-space/andywu1998.github.io
scripts/sync_personal_assistant_notes.sh
该脚本会:
- 从
../codex_personal_assistant/notes 导入 Markdown。
- 生成 Jekyll
_posts。
- 提交
_posts。
- 推送到 GitHub Pages 仓库。
本次逐字稿博客文件:
andywu1998.github.io/_posts/2026-06-10-地平线机器人-2026-06-10-股东周年大会逐字稿.md
最终博客提交:
踩坑记录
1. 全局 pip 受保护
全局 Python 环境受 PEP 668 管理,直接安装失败。解决方式是创建 .venv-transcribe。
2. Hugging Face 超时
faster-whisper 本身安装成功,但模型无法从 Hugging Face 下载。解决方式是改用 ModelScope 上的 FunASR/SenseVoiceSmall。
3. FunASR 没有自动安装 torch
安装 FunASR 后导入失败:
ModuleNotFoundError: No module named 'torch'
解决方式是安装 CPU 版 torch 和 torchaudio。
4. 飞书 Docs 更新命令参数不稳定
lark-cli docs +update 的帮助与实际校验不一致,要求内部 --command 参数但帮助没有列出。最终处理方式是重新创建格式化版飞书文档,并把配置链接替换成新文档。
5. Markdown 只有单换行会在博客里显示成大段
原始逐字稿每条记录只有单换行,Jekyll 渲染后阅读体验差。解决方式是在每条时间戳片段之间增加空行,并按主题加入二级分段。
可复用 SOP
- 检查音频格式和时长。
- 如果本机没有 ASR 环境,创建
.venv-transcribe。
- 优先尝试可访问的模型源;当前环境推荐 ModelScope + FunASR。
- 先截取 60 秒样本验证。
- 对长音频按 120 秒切片。
- 逐片识别并生成带时间戳 TXT/JSONL。
- 把正式逐字稿写入
codex_personal_assistant/notes/projects/<主题>/01_逐字稿.md。
- 将原始 ASR 文件放入
source_materials/。
- 增加分段标题、段落摘要和空行,但不要改逐字稿原文。
- 创建飞书 Docs 文档,回填
config/feishu_base.json。
- 运行
python3 scripts/sync_to_feishu_base.py。
- 运行博客同步脚本
scripts/sync_personal_assistant_notes.sh。
下一步动作
- 把完整转写脚本整理成个人助理或 cc-connect 的可复用脚本,减少下次手工命令。
- 增加“逐字稿格式化器”:自动按时间段插入标题、摘要和空行,并校验原文未变。
- 评估是否需要更高质量的二次校对流程,例如对关键问答片段单独复听修正。
---
layout: post
title: 地平线机器人 2026-06-10 股东周年大会逐字稿
subtitle: Codex 个人助理沉淀
date: 2026-06-10 05:46:18 -0400
tags:
- 个人助理
- 项目
- 地平线机器人20260610股东大会
---
来源:notes/projects/地平线机器人20260610股东大会/01_逐字稿.md
地平线机器人 2026-06-10 股东周年大会逐字稿
说明
- 来源音频:
.cc-connect/attachments/地平线机器人202606.10.mp3
- 音频时长:约 54 分 08 秒
- 转写方式:FunASR SenseVoiceSmall,本地自动语音识别
- 校对状态:未人工逐字校对;英文人名、专有名词、数字和个别断句可能存在识别误差
- 生成时间:2026-06-10
内容概览
- 00:00-10:00:AGM 开场、董事和高管介绍、会议通知、投票和 12 项决议说明
- 10:00-47:00:股东问答,涉及车企自研芯片、竞争格局、股价回购、HSD 出货、研发投入、FSD 入华
- 47:00-54:08:线上投票流程、投票等待和会议结束
逐字稿
00:00-10:00 AGM 开场与正式议程
本段摘要: 本段主要是英文会议开场、董事与高管介绍、会议通知、投票规则,以及 12 项股东大会决议的宣读。
[00:00:00 - 00:02:00] Stud begin There will be a Q and A session for shareholders participating in the annual general meeting. you can now start raising questions using the Q and A box functions on the Yi meeting System. My first introduce the company’s board, senior management members while with us today, ladies and gentlemen Dr. Kaiyu, founder, Chaman of the board, chief executive officer and executive director, members of remuneration Committee and the nomination Committee, Dr. Chang Huang, co-founder, executive director and chief Technology officer, Dr. Jian Xu, executive director and chiefy officer, Dr. Li Mingchen, executive director, and vice chairman of the board, Mr. Liang Li, non executiveive director, Mr. Qin Liu, non executiveive director, Dr. Andre Sooff non executivecutive director, Mr. Jianjunzhang, non executive director, Dr. Junp, independent non executiveive director, chairman of the A committee, member of the corporate governance Committee. Mr. Yingqiuwu, independent non executivecutive director, chairman of the nomination Committee, members of the corporate governance Committee. Dr. Catherine Rongxing, independent non executivecutive director, members of the A committee, the remuneration Committee and the nomination Committee, Dr. Ya Qingzhang, independent nonn executivecut director, Chaman of the remuneration Committee and the corporate governance Committee, member of the A committee, Mr. Qi Zhao, joint company secretary. Mr. Ka Se Jo.
[00:02:00 - 00:04:00] Company secretaryMa now pass the time to the chair of today’s meeting, Dr. KaiyLadies and gentlemen and to welcome you to the 2026 annual general meeting of Horizon robotics as the time scheduled for the annual general meeting has come and we have the necessary Q for the meeting I now call the meeting to start will now the notice and voting procedures over to you Thank you Dr. the notice of general meeting has been set up on the page1 to6 of the company’s circular data May 19 2026 the businesses and resolutions to be dealt with as this meeting are in the noticed to the rules governing anding of securities on the stock exchange of Hong Kong Li or the procedures and resolutions set up in the notice Coning the meeting will be taken by pool we have appointed the company’s branch shares re call investors service limited as of this meeting please be informed that Dr. Yu as the chair of this meeting. holdxies which have been sent in for use at this meeting and he will vote in accordance with the directions given on the relevant forms of proxy for thosexes without direction Dr. shall the to vote in favor of the resolution. I will now read the resolutions to be dealt with at this meeting. The details have been set up in the.
[00:04:00 - 00:06:00] Of AGM included in the company’s circular data 19th May 2026. The first resolution is that the audited consolidated financial statements of the company and reports of directors and auditors of the company for the year ended31 December 225 B and R hereby receive and adopted Re2 to7 relate to the reelection of directors. in accordance with the company’s articles of association Dr. Jian Xu Dr. Li Mingchen Mr. Liang Li, Mr. Qin Liu Mr. Jianjunzhang and Dr. Ya Qingzhang shall retire at this annual general meeting and be eligible will offer themselves for reelection Resol2 is that Dr. Jian Xu be reelected as executive director Res3 is that Dr. Li Mingchen be reelected as executive director Resution 4 is that Dr. Liang Li be reelected as non executive director Resol 5 is that Mr. Qin Liu be reelected as nonexive director Re6 is that Mr. Jianjunzhang be reelected as a nonexive director Re 7 is that Dr. Yaqingzhang be reelected as the independent non executiveive director resolutionsol 8 is that board of directors be authorized to fix the doctors reeration. Dr9 is that the price waterhouse Cooper be be reappointed as auditors of the company and the board of the director.
[00:06:00 - 00:08:00] Authorized to fix the auditor’s remun for the year ended31 2026 resolution 10 is that resolution is contained in the item 10 of the notice date 19th May 2026 Coning this meeting B and is hereby passed as ordinary resolution. This is to grant the directors a general mandate to repurchase the company’s shares not existing 10% of the total number issued shares excluding any treasury shares at the date of passing this resolution resolution 11 is that the resolution is content in item 11 of the notice date 19th May 2026, Coning this meeting B and is hereby passed as ordinary resolution This is to grant the directors a general mandate to one a lot issue and deal with the new class B ordinary shares and second sale and transfer Treasury shares, not existing not existing 20% of the total numbers of the issue shares of the company excluding any Treasury shares as date of passing this resolution of the company resolution 12 as that resolution as content in item 12 of this notice dated 19 May 2026, Coning this meeting B and is hereby passed as ordinary share resolution. This is to grant the directors and extend mandate where conditional upon passing the resolutions numbers 10 and 11 to extend the share issue and resume mandate to a lot issue and deal with additional class B shareholders sorry ordinary shares in the capital of the company by total number of the shares repurchase by the company under the share repurchase mandate.
[00:08:00 - 00:10:00] Treasury shares, if any, registered under the name of the company shall repurchase shares pending cancellation shall have no voting rights at thisM the trustee by the company holding shares of the share scheme of the company shall absentbs froming voting rights in of any of the above resolution except for above no other of the company is required under theing rules to from voting the resolution at this AGM shareholders attending this meeting you may now use the Q and a box functions on the in meeting system to raise questions now in the interest of time I will combine similar questions we will now take a moment to collect the questions各位东现可通过提问功提出问题因问合并似问然后现在一两分钟的时间给大家提出问题.
10:00-20:00 股东问答一:车企自研芯片与地平线平台定位
本段摘要: 本段围绕比亚迪等车企自研芯片展开,管理层解释地平线的芯片、软件、BPU、工具链、IP 授权和 royalty 模式。
[00:10:00 - 00:12:00] 我看到了比较多的问题。可能稍后我会根据问题的类型啊,帮大家总结一下啊,然后在不同的这个这个方向上去去向于博士包括管理层进行提问。啊,我我已经看到这个问题很多了。那我们先开始嗯,第一个问题也是我看到这个呃比较多问的是关于比亚迪比亚迪5月份发布了自己的玄机芯片。嗯包括在智能座舱上的这个OS滴滴虾。那我们知道比亚迪过去一直是地平线的这个重要客户之一。呃,所以有股东想请问于博士如何看待比亚迪的自研芯片,对我们的影响。于博士。好的,感谢这位股东的问题。首先呃因为地平线面对的客户比较多,所以呃我们不会去具体的去呃涉及具体的客户。
[00:12:00 - 00:14:00] 呃,我们跟他们的合作,我想从地平线的整个商业模式,以及我们的产业定位的角度来讲,以及我们跟整体的行业的这个我们的客户合作伙伴的合作的方面。首先地平线是一家芯片加软件的公司。啊,但不限于此地平线本质上是一家汇聚了各项啊phy AI物理AI底层技术的一个平台级的公司,我们的核心的知识产权,有AI计算的架构BPU也有我们智能驾驶的基座大模型,有机器人的基座大模型,还有我们的各种的开发工具,比如说像I迪平台,啊,包括我们的在芯片上面的工具链,其实都是我们的核心产品,所以我们的定位呢是成为支架和机器人行业的这种底层赋能者,就像我多次讲过的,就像ar跟安卓这样的,是我们始终坚持的一个商业定位。那么为了这个愿景,我们坚持的不是说是大包大揽的全端交付,而是生态供应。这里面包含了类似于像arCPU对外的各种的呃IP授权模式,其实也包括各种软件算法的这种IP授权模式。也包括呃我们的一些软件的工具链,甚至是呃软件的开发平台,比如说像云端的大数据的开发平台I地平台,的这种啊提供的模式。所以我们实际上是全力支持呃,无论是呃天万合作伙伴还是车企的客户,我支持他们自源芯片,我们支持他们开发自己的算法,并且我们支持他们长线的长期的去。
[00:14:00 - 00:16:00] 培育自己的自研的这种定制化开发的能力。所以我们是一个非常开放的利他的这样的一个赋能模式。在这个过程中,地平先承担的角色呢是一个技术的这个底座是基时是我们客户背后的赋能者。虽然具体的客户的情况,我们不方便去展开。但是可以跟大家分享。在车企的研发过程中,我们会收取呃比如说一次性的这种IP授权费。但一旦车企的这个产品进入量产,我们会随着出货量收取一定金额的这个roty。那就是每次出货我们都收取一定金额的这样的一个收入就是版税。在这个模式下面的话,IP和版税的这个毛利率高达90%以上。所以这个其实也是世界高科技公司大量的高级公司,我刚刚提到了其实也包括高通也包括像sop也包括像dence有很多很多的公司都是这样的一个IP授权软件授权的这种商业模式。这种商业模式的毛利非常高高达90%以上。具体来讲,大家可能熟悉ar跟苹果之间的合作模式。那么ar像苹果进行他的arPU的架构授权,包括它的指令级的授权。那么基于该授权的话,苹果也研发出了目前备受好评的它一系列的这个呃手机的CPU芯片。那我们跟车企的话呢,在这个合作上面的话,其实也是这样的一个非常类似的模式。就是我们授权软件呃no how。我们授权关于芯片方面 how。我们甚至授权整个芯片的整个的开发版方面 how。那么这个的话呢,实际上。
[00:16:00 - 00:18:00] 就是说我们收取它的授权费,也包括他的这个版税,所以是一个非常非常相似的这么一个模式。当然这段时间也有投资人来问我们,如果车企的话,我们的客户开展自研。那么即使地平线在背后做支持,会不会意味着减少我们自己的芯片啊,以及我们的HSD的出货机会。那我想跟大家分享一下,我们对这件事情的思考。我们看一下在手机行业的例子。大家知道手机行业竞争非常激烈。手机厂商也都在自研芯片,但是在受到全球风波之前,华为和三星是全球唯二的自研手机芯片SOC并且能适配这种安卓的这种主力啊机型的厂商。但即即便如此,比如说华为海思以及三星自研芯片也为独占这家手机的全部份额。2017年的份额看,华为海思占华为整体出货量的比例大概是50%左右。即使没有受到供应链影响,三星多年来一直是自研加外采高通啊,双供应链并行的这种策略。而且自研芯片装机率的话,在三星这个case一直都是不高的。从数据上看,高通和联发科占据了三星将近70%到80%的份额。所以放眼包括苹果在的整个手机产业。自研手机芯片的出货量占比大概30%左右,剩余的70%始终是第三方的供应商。其中双寡头的格局非常稳固。高通和联发科的份额高达60%。第三方仍然占有绝对的优势。而从汽车芯片的角度看,一颗芯片里面主要含是个最主要的计算和CPUGPUMCU和AI计算架构BPU那么智能驾驶软件主要是跑在AI相关的BPU上。。
[00:18:00 - 00:20:00] 那么通过BPU授权给车企客户,我们其实也提前建设,并且锁定了地平线的软件生态。自架算法和BPU它会是一个互相促进的耦合关系。那么基于其他芯片事情适配的算法,想要迁移到基于地平线BPU架构的芯片上难度比较大,大家可以把BPU授权这个模式,看作是一个这个跑马圈地。那么基于地平线BPU的这些芯片。那未来会有很多,我想不一定都是地平线去啊推出。但是天然它建设了一个以地平线BPU为核心的一个软件生态。那么这样的一个软件生态,使得地平线能够进一步的通过软件的技术算法的IP工具链去持续的提供给我们的客户,并且的话呢让地平线的核心技术的竞争力,以及不可替代性,其实是越来越强的。总而言之,我们支持车企自研,同时也把自己的真程系列自架芯片,还有星空系列的仓架一体智能体芯片,包括HSD的自架软件咔咔虾智能体OS全面导向车企。如果车企最终能自研成功。我们在自研的部分收取啊IP跟版税的收入,并且以第三方的身份做好硬件的供应商。同时向车企提供自架的一系列所需要的软件技术,包括在座舱方面的一系列的软件技术。所以就是说最终来讲,我们相信车企它一定会不断的即时自延,又是依靠第三方。那我们地平线的站在现在自研这部分,我们其实有一席之地。在它第三方这部分。
20:00-28:00 股东问答二:竞争格局与市场份额
本段摘要: 本段讨论智能驾驶供应商 IPO、赛道拥挤度、AD 芯片竞争格局,以及管理层对地平线份额提升的判断。
[00:20:00 - 00:22:00] 我们又为一席之地。所以地平线一直强调的就是说我们要有强大的这种技术的竞争力,全站的技术的能力。但是我们不一定正全站的潜。我们保持非常灵活的这种商业模式,无论车企它是采取哪一种技术战略,我们都在牌座上,我们都在牌座上面的话是一个最主要的一个合作者,最终来讲的话达到我们的目的就是在汽车的智能化时代,地平线成为这个时代的按加按卓借于波详尽的回答,那我们下一个问题,呃于博士您好,最近制架行业里面不少公司都在推进IPO我们感受到制架供应商赛道越来越拥挤了。您怎么看这个竞争态势,以及现在的市场格局。啊,感谢这位股东的问题,近期呃多家这架公司密集的推进IPO顺便我想说一下呃,这些大部分这些自架公司都是地平线的生态合作伙伴,其中有好几家我们都是他们的股东。啊,其实啊说明这个赛道已经完成了0到一的商业模式的认证。那么进入了一个产业这个深根产业落地,直至爆发式增长的阶段。那么从芯片竞争的格局来讲,那是很清晰的。就智能辅助驾驶这个如果是看A的这个市场。那么就是L2的这个市场,地平线现在是一家独大。但如果是看这个AD这个市场,就智能驾驶的计算芯片其实三分天下,格局是非常非常清晰的。那么看2025年的中高阶AD的自架芯片市场,其实英伟达华为和。
[00:22:00 - 00:24:00] 地平线三家同步企业合计的市场份额已经差不多是九成,形成了一超双强的这样的一个格局。那么地平线未来啊向来会非常依赖各家生态合作伙伴的支持。其中就包括了啊前面提到的若干家正在推进IPO的合作伙伴。那么拉长周期看,智能驾驶的核心技术供应商啊,其实我倒不觉得是越来越拥挤的一个趋势。我觉得整体的来讲会是高度收敛的趋势。那么参照PC时代的呃windows跟intel的格局wintel格局,以及在移动智能手机时代的AA格局,就是以ar架构为核心的高通跟MTK再加上这个另外一个A就是安卓这样的一个寡头的垄断的格局。我们认为未来真正要讲未来智能驾驶核心技术供应商,包括现在顺便讲一下地平线现在其约做仓家一体其实也把智能驾驶跟智能座舱作为一个整车呃智能计算的这样的一个呃平台的核心供应商,我认为未来全世界会收敛到两大3家。当然也会有大量的合作伙伴围绕这两到3家的话呢,有自己的这个一席之地。那么这一判断其实在近期的这个市场数据也是提供了验证。大家知道今年的一季度。中国国内的测试情况是比较差的啊,内需的这个销量下滑已经是超过20%。那么主要的这个是靠出口的高增速来弥补整个中国汽车产量的这么一个规模。那么全国搭载啊AD就是智能辅助驾驶高中高阶智能辅助驾驶的。
[00:24:00 - 00:26:00] 车型的销量其实也比较一般。在这个大环境下,地平线的这个AD的市场份额啊,跟大家汇报一下,还是实现了逆势的增长。那么我们在中国车企啊,如果说是高速的NOA的解决方案的市场份额,季度环比增长了6到5个啊5到6个百分点。那么现在呃超过了30%。那么城区OA解决方案的份额,在搭载HSD的绝大部分车型其实正在推向市场正在量产的过程中,那仍然是季度环比增长了两个多百分点啊,达到了接近7%的水平。所以合计的话呢,就是把这个AD市场把高速OA跟城区OA加在一起,我们的市占率超过了去年啊地平线的整体的这个14%的啊这个市占率达到了16%左右的水平。那么与此同时我们看到其实英美达的市占率,整个英美达市生态的市占率正在下降。这个呢也符合大家的预期。因为大家知道,我们在AW市场从不到5%的市占率到今天超过50%的市占率,大概只用了3到4年。我们也有信心3到4年之后,也就是说从去年地平线在11月份第一次推向推出这个城区OA的产品。那么在34年之后,我们也会是市场市占率最高的第三方城区自驾解决方案的供应商。那么车试在承压啊,但是地平线相对来讲,我们的自驾的这个呃尤其是中高端自驾的方案的市占率却在呃加速渗透。那这说明在行业压力最大的时候,它往往可能是。
[00:26:00 - 00:28:00] 机会,因为谁在这样的一个时候能够不断的发展,能够脱颖而出,能够不断的推出啊好的产品。那我觉得反而是在这样的环境里面是地平线最大的一个机会。而且我相信地平线的产品越来越会成为消费者在购买啊,车型的一个重要的购车的决策。好的,谢谢于博士,我们进入下一个问题,,尊敬的管理层我作为一个长期持有地平线的个人投资者,想冒昧的问一个可能不太好回答的问题。管理层现在对于当前的股价水平怎么看感谢这位投资人啊,长期的对地平线的支持,也呃感谢这位投资人啊,为一个相当直接的问题。那毫无疑问,我觉得地平线最近的股价是呃非常的承压的。那么表现的话呢,大家都看到的。那么对于地平线来讲,从2024年的10月24号这个登陆啊公开市场完成上市。其实我觉得这个是成长过程中,他面临的一次的考试跟考验。那么股价的短期的波动,他受多重因素的影响。大家对于近期股价的这种担忧,我完全理解。在前两天地平线成立11周年的庆典上,当着我们所有地平线员工的面。包括我们的员工的家属,我们也请了员工的家属来参加。我此。
28:00-34:00 股东问答三:股价、产品力与回购
本段摘要: 本段回应股价承压,管理层强调平常心、产品竞争力、消费者选择高配的迹象,以及公司回购动作。
[00:28:00 - 00:30:00] 也是直接的去跟大家去沟通了我对于股价的看法。那我认为最核心的我当时表达来的观点就三个字,就是啊平常心,平常心就是让事物的本质做好,就好比说当有人去争论这个一个人长得高不高,你可能不同的标准。但如果姚明一进屋子,没有人会去argue姚明长得不高,所以对我们来也一样,我觉得在大环境出现各种情况的时候,我觉得我们要回归本质,就是产品到底好不好。因为我认为只有有竞争力的产品,只有创造价值的产品,只有用户消费者真正认可的产品,我觉得才会让地平线能够长期的股价得到体现,得到一个非常正向体现。所以的话我们应该平心静气的去关注本质,去一点一滴的反而更加的专注投入到我们的研发中打磨我们的技术我们的产品,要坚持我们的目标播放弃,让每个用户甚至每个竞争对手都要说我们的产品好。我最近看到一些迹象,过去在10万到20万价位的这样的一个中国大众消费者的主流的市场。大多数的消费者都会选择一般来讲都会选择性价比的这种低配或中配车型,甚至很多人选择没有任何智能辅助驾驶的配置的车型,因为便宜。所以他们是性价比有限。但是我看到有区域的现象是搭载了地平线HSD的一系列车型。那么消费者尽管面对高配中配。
[00:30:00 - 00:32:00] 低配但是消费者一边倒的都选择了最高配。比如说最近的这个爱ica尔的V27超过50%以上的都选择这个最高配售价已经差不多到了20万元。所以我认为真正的用户体验的价值驱动的这样的一个消费拐点正在出现。所以用平常性来看,我认为只有就是我们的产品让消费者真的是他甚至都不需要去太多的比较跟思考,他就知道A地平线的产品给他带来了非常好的用户体验,哎,反而是因为地平线的真成芯片星空芯片地平线的HSD地平线的咔咔箱才选择买这样车,这才是真正的算成功。所以我们要继续努力持之以恒。我认为这个就是平常性大到之间。另外从市场的角度来讲,几个确定性的趋势很明显。第一季度的话,地平线的AD的渗透率在加速测试虽然成加,但我们的相对份额是逆势增长。终端用户正在用自己的真金白银去投票。第二,产业格局在收敛,国内的AD的市场里从芯片的角度看,投三家的份额已经接近九成。我们在这个格局里的位置,不光是确定而是在增长。而且我们也观察到英伟达的份额,最近有所下降。第三,我们从芯片到自驾软件到整车智能体OS,还能基于类似于像R加安卓这样的商业模式,给车企。
[00:32:00 - 00:34:00] 开放赋能这样的一个谦逊开放利他的定位在中国是非常的稀缺的。那么这些基本面都没有改变。并且在往更有利于地平线的方向发展。我们也用实际行动来表达对公司长期价值的信心。今年4月以来,我们持续回购,目前已经累计回购接近5亿港币。这次股东大会上,我们也提醒各位股东批准,让未来12个月公司有权利在合适的时机,以合适的价格,通过合适的方式持续的进行回购。那么历史上面,很多的非常成功的公司,甚至是伟大的公司其实在成长的过程中都经历过这样类似的考验,巨大的回调。比如说我们看到特斯拉也曾经从400美金跌到100美金的过程。我们看因为呢在历史上面也有多次的这种巨大的剧烈的股票的回调,甚至是超过50%,超过80%的回调。嗯同样我们看中国,你看我们无论是您的时代还是比亚迪,都经历了啊多次这样的过程。我相信每一次考验每一次这样的调整,可能对我们都是一个前进的进步的阶梯,都是我们成长的契机,是我们为此而慌了阵脚,而是说还是说回归平常心专注于本质专注于企业的经营企业的产品力。我还是相信巴菲特那句话,股市短期是投票机长期是成重机。我相信我们会证明。
34:00-38:00 股东问答四:HSD 出货与研发投入
本段摘要: 本段先回应 HSD 年度出货目标,再进入研发投入问题,强调城区 NOA 下探、星空芯片、物理 AI 底座和持续投入。
[00:34:00 - 00:36:00] 时间会证明地平线的长期价值。好的,谢谢于博士。我们进入下一个问题。于博士您好,年初您指引过今年40万辆HSD的出货。目前这个时间点,您如何看待今年HSD的销量指标。,好的,感谢这位投资人的问题。关于HSD的交付量,上半年我们的客户覆盖已经比较明晰。各车型的越度的销量也是公开数据。啊每款车型交付之后,我们更愿意把精力聚焦在地平线能驱动的事情上,帮助客户把下一个车型和智能体验做到极致。就像我们刚刚讲的要做屋子里那个毫无争议的大高个。而从行业的角度看,车企的自驾平权啊,我们是很兴奋的。城区自驾的增长引擎正在驱动城区OA的能力正在加速向15万元以内的车型下探。这意味着我们的市场空间是在迅速扩大。盘子大了,我们在客户中斩获爆款车型的概率跟覆盖面也会随之提升。我们未来新车型的进展更有意义。期待在今年晚些时候再和大家做具体的交流。至于今年HSD今年的出货量,我相信无论是什么数字都是一个非常的mini的交付量。但是我想跟大家表达,随着地平线增成芯片,以及我们最近推出的差价融合智能体芯片星空。那么整个这个芯片的这个竞争力。我觉得在行业里面是越来越强。甚至我自己个人觉得是无出其有。么在这样的一个跑马圈地的这种情况下面的话,那。
[00:36:00 - 00:38:00] 未来就是HSD的市场份额提供了非常好的这么一个土壤。那么我自己对于HSD的未来的出货以及它的这个市场占有率啊,我是非常的有信心,非常乐观。谢谢好的,谢谢于博士嗯,我们进入下一个问题。,管理层你们好,2025年公司研发投入超过了50亿元人民币。我理解硬科技需要持续投入,但作为股东我确实很关心这么高强度的研发投入,到底什么时候能看到相应的回报及盈利。好的,谢谢这位投资人,感谢您对公司的长期关注。高强度的饱和研发投入是地平线面对呃未来的取胜之道,是我们的战略选择。现在我们在研发上的投入,是在训练一个能持续进化的物理AI底座,他不仅是HSD打赢城区自家的关键,也是面向未来L3L4自动驾驶演进的底层能力。这一机座一旦建成。它的能力边界将不止于汽车,还会向机器人的领域延伸。所以我们还没有做到完全自动驾值前,我们会坚定的饱和投入。在最短的时间内去不断扩大我们的领先优势。让我们的高投变成强大的商业竞争力。但是我们有一条底线。我们只会在资产负债表绝对健康的前提下,饱和投入研发。2025年末地平线在手的现金是超过200个亿的这个也保证了我们持续。
38:00-40:00 股东问答五:盈利能力与长期产业地位
本段摘要: 本段延续研发投入话题,管理层解释现金、毛利率、收入增长、费用增速和未来盈利能力之间的关系。
[00:38:00 - 00:40:00] 高投入的底气。另外一方面,地平线的毛利率达到60%以上。在行业内属于比较高的水平。那我们只要持续的收入保持高度的高速的增长,研发费用增速不显著的高于收入增速,那么公司未来的盈利能力是可期的是有保障的是显而易见的。关于回报何时显现。我一贯的判断是未来支架置于汽车,就像通信基待之于手机,它不定它不再是锦上添花的卖点,它是定义产品待季的标配。那当这一天到来,掌握核心底层技术的企业,就会成为产业链中绕不开的基础设施。我们的高研发投入也就高一段段落。我们今天投入也是在构建这种绕不开的价值。就像手机时代的高通,它的整个的毛利水平,它的净利润水平,超过了除了拼果以外,几乎所有的手机厂商。就像在PC时代的intel跟利润。我相信他们的整个的盈利跟毛利,还有净利润水平也超过了所有的PC厂商,那我相信地平线在整个的智能汽车领域,我们未来的这个产业地位,会成为这样的一种啊高科技的啊领先的企业。谢谢。好,谢谢于博士。我们进入下一个问题。嗯,于博士您好,特斯拉5月21日官宣FSD监督版正式入化。作为股东,我有两个层面的担心,一是FSD毕竟是全球智能标杆。支架的标杆。他进来之后会不会抢走一部分客户,对地平线的。
40:00-48:00 股东问答六:特斯拉 FSD 入华与软件订阅
本段摘要: 本段讨论特斯拉 FSD 入华,管理层认为这会带来行业鲶鱼效应、提升用户认知,并可能推动自动驾驶软件订阅模式。
[00:40:00 - 00:42:00] 市场份额形成挤压啊、也是有分析说FSD在中国水土不服,接管率远超于国市场方案,价格还要6万多。如果特斯拉FSD最终表现不好,是不是对地平线也有挑战啊,总体来说您怎么看待FSD入滑这件事情呃总之呃我非常直接的一个回答,就如果如预期特斯拉FSD路滑。啊我将因此欣喜落况啊,这绝对是一个大好消息。它会引发国内自驾行业的鲶余效益啊,它会让整个社会公众普通的消费者,而不仅仅是科技的极刻,对于智能驾驶的技术啊,去抱有热情。所以对地平线而言,这绝对是一个巨大的这个机遇那么回顾历史啊,特斯拉在2018年解决了产能问题之后,啊,全球的EV迎来了新的发展的一个浪潮啊,我记得应该是一个突出的一个拐点应该是2020年就是上海的这个特斯拉的超级工厂解决产能,实际上那个时候EV才真正产生的拐点。那个时候国内的话呢新势力包括微小微小其实也迎来了拐点。以同时的话呢这个也催生了一大批的优质的本土的围老的EV的这些供应商。啊,包括您的时代。同样的,我相信FSD入滑将带来类似的在智能化这个产业圈所产生的。
[00:42:00 - 00:44:00] 种巨大的联鱼鲶鱼效应和这种啊呃联鱼效应。我们自己做了一些测试。特斯拉的智能辅助驾驶能力,毫无疑问,是属于全球的领先地位。那么有这样的国际参照物的这个入场,我觉得将加速整个智能驾驶产业链的向上对标迭代审计。同时的话呢他也会提升中国消费者对自驾的要求的这种啊这种品位啊,因为当如果没有这样的一个这个呃这个好的产品在市场上面具有这种号召力去设立一个产品的标准的时候,其实这个市场本身是处在一个并不是这种啊集体的消费者去拥抱这个技术的这么一个时代。所以说需要这种标杆产品。而中国的道路场景的话,远比非美复杂用户反馈和迭代节奏也很快。如果我们和特斯拉能在这种极高难度的场景中站稳脚跟。那么中国自驾产业链的价值。就像就会被重新的定价。顺便讲一下,大家知道全球范围内,特斯拉是第一个真正量产,一段是端到端的智能驾驶大模型的企业。大家知道谁是中国的一家是地平线。地平线去年推出HSD啊,所有的这些体验的这些媒体朋友,专家科技机客都惊乎这个是中国的FSD因为非常累人的非常丝滑的这种用户体验。他们之前从来没有经历过。昨天我还接待了一位啊投资圈的朋友。那么他也是地平线股东。
[00:44:00 - 00:46:00] 他对于美国的FSD特斯拉的FSD是非常熟悉的。那么他昨天体验了地平线的HSD他自己就接说哇哦,这是他现在体验过的最像这个特斯拉的FSD这种类人体验丝滑,并且带来一种安全安心感。这个是他这个觉得非常非常的印象深刻。所以当前国内主机厂的自驾产品销售。我觉得无论是全新标配还是选A还是购车环节都是在购车环节完成的。我觉得国内用户对于这个呃目前来讲的话,当自驾的这个进展,并没有真正到这种啊完全的无人驾驶的阶段,比如说L4。那么对于软件的按月付费的意愿,相对我觉得还为持上涨。那么到目前为止,我觉得还是一个这个类似于传统的汽车零部件的这样一个生意模式。那这个也是地平线目前的现状。目前的商业模式的现状。但我觉得这个并不是永远。当我们看到今年的FSD在全在美国已经全面推行了订阅机。那每月的费用从99美元啊截止到2020年的一季度其这个订阅的用户数已经超过了120万。那么仅FSD的付费,每月可以为每个月可以为特斯拉供电贡献1.2亿美金的收入。那么SFSD的落滑有机会把自驾功能变成一个用户意愿单独订阅的这样的一个呃强认值的产品。我对此抱有期待。那么一旦是哪怕不能立刻实现,至少也是加速推动。一旦特斯拉成功教于中国市场,让用户为自驾的软件订阅,这样的一个付费模式,。
[00:46:00 - 00:48:00] 成为共识。那么这家供应商的软件税务模型盈利模式甚至物资体系都会迎来一次系统结构性踊跃s through the meeting system would like of class inxy shall have one vote per share for all resolutions hold of class have1 votes share for resolution number one resolution7 and thes the number ofs or of options indicate no voting is completed please click confirm to.
48:00-54:08 投票与会议结束
本段摘要: 本段回到线上投票流程,说明投票确认、五分钟投票时间、投票关闭和结果发布。
[00:48:00 - 00:50:00] completion of the voting procedure, the system will display a set voting reference number to confirm that your voting instructions have been submitted We have approximately five minutes for voting for shareholders are to vote online现有5分钟投票时间大家在上进行投票.
[00:50:00 - 00:52:00] .
[00:52:00 - 00:54:00] hasAs all the closedThe poll will be published on websites of the and Stock exchange for your is.
[00:54:00 - 00:54:08] 。
下一步动作
- 复核 HSD 40 万辆指引、Q1 市占率、回购金额、现金和毛利率等管理层口径。
- 将问答中的关键观点拆成单独研究笔记,用于后续地平线机器人投资跟踪。
---
layout: post
title: 真正的价值投资:知乎原文排版版
subtitle: Codex 个人助理沉淀
date: 2026-06-09 22:20:49 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/value_investing/02_真正的价值投资_知乎原文排版版.md
真正的价值投资:知乎原文排版版
版权与来源
作者:Michael
链接:https://www.zhihu.com/question/1975260465501316632/answer/2046945026614224281
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
散户和伪价投眼中的价投
散户和伪价投眼中的价投:我看中一个股票,买入,然而它产生浮亏了,我又不舍得割肉,结果浮亏越来越多,然后就想到价投不就是长期持有吗,那么我也一直持有硬抗,然而最后实在扛不住了,亏了很多,然后骂价值投资是扯谈
举个例子:赛力斯,从高点 174 回撤到目前 74,很多散户不舍得卖,就告诉自己长期拿着吧,我就当做价值投资了
真正的价投
真正的价投:
1,选定标的
1,选定标的:这个标的基本面良好,赚钱能力强,我能够看懂这个公司,我相信这个公司未来 3-5 年都能够保持良好的业绩,给股东很好的回报
真正的价投从来不会去追市场的热点,也不会去追那些没有盈利的热门公司,消费类(也就是市场上所说的老登股)是真正的价投比较青睐的标的(比如老段最近买入的泡泡玛特),因为这些消费类的公司一般来说会有足够的业绩和利润支撑,真正的价投去做市场调研也比较容易
当然,真正的价投不是说一定会赚钱,看错标的了也一样会亏钱的,价投非常考验一个人选优质标的的能力
2,蹲好价,等底仓好机会
2,蹲好价,等底仓好机会:等待市场错杀,或者市场恐慌的时间点(比如 924,美伊战争,关税战等),这些关键的节点,大部分的标的股价都会大幅度的下挫回撤,真正的价投最喜欢这样的机会了,市场恐惧我贪婪,这种错杀的大幅度打折的股价正是最好的买入时机
3,控制仓位
3,控制仓位: 每次试仓加仓只买入 2%,有底仓的机会(参考第二点)可以买入多点,但每个标的的仓位控制在不超过 10%
光是上述三个操作,试问市场上有多少人做到?
4,买入后跟踪
4,买入后跟踪:真正的价投买入标的,都有自己的逻辑,买入后需要跟踪自己的买入逻辑是否还在,再结合季报年报来验证。如果买入的逻辑不成立了,或者标的的基本面发生重大反转,或者发现自己看错了,就及时止损(真正的价投,不是根据股价来止损,而是根据公司基本面来止损,即便当前的股价仍然是浮盈,也仍然会止损)
5,股价
5,股价:真正的价投,一般情况下,在买入标的后,前期会有一点浮盈(因为买入的价格已经比较低,安全垫比较足),但是真正的价投可不希望买入就浮盈,因为没买够,真正的价投希望股价能够再下来一点,这样他们能够有更好的价格来加仓
例子:几年前的宁德时代,买入2% 试仓后,股价根本没有回调过,直接上天了,这是真正的价投最不希望看到的,因为没买够仓位,股价已经上去了,但上去的股价没有足够的安全垫,价投宁愿错过也不会追高
散户和真正的价投对于加仓的区别
再说一下散户和真正的价投对于加仓的区别
散户:加仓是为了降低成本,如果最后这个标的涨不回去,就是越加越亏
价投:加仓不是为了降低成本,是为了买入更多的仓位(有时浮盈也会加仓,因为即便浮盈,但价投如果认为价格仍然合理,也会浮盈加仓),因为价投很清楚很自信,这个标的目前的低价只是暂时的,虽然不知道什么具体什么时候股价会去到真正合理的价位,但真正的价投确信这个事情一定会发生,所以真正的价投对于股价的下跌一点也不慌,反而觉得很爽
6,持有时间
6,持有时间:真正的价投,如果确信自己看对的标的,确实是长期持有,越跌越买,真正的价投持有一个标的都是按年来算的,市场上的散户恨不得天天都要操作,天天做波段做T,生怕今天不操作就赚不到钱
7,面对波动
7,面对波动:真正的价投,如果标的的基本面没有变坏,是不怕市场回撤的(参考 2,5,6 点),即便市场回撤了所有浮盈且产生大量浮亏,都不怕,反而又是一个很好的加仓机会,因为真正的价投确信,这些回撤都只是正常的市场波动,股价迟早会回到这个标的该有的价位,又因为真正的价投的买入价都很低且在真正的低位建了底仓,所以当股价回到正确的位置的时候,盈利其实相当的客观)
所以,不是真正的价投不行,而是大家都没有接触过真正的价投,又或者,知道真正的价投了,但不认可真正的价投的投资逻辑和行为,还是觉得自己天天做T做波段,追热点比较爽,那是每个人的选择,每个人终将为自己的认知买单
---
layout: post
title: 真正的价值投资不是被套后的长期持有
subtitle: Codex 个人助理沉淀
date: 2026-06-09 22:11:37 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/value_investing/01_真正的价值投资不是被套后的长期持有.md
真正的价值投资不是被套后的长期持有
来源
- 作者:Michael
- 原文链接:https://www.zhihu.com/question/1975260465501316632/answer/2046945026614224281
- 平台:知乎
- 版权说明:原回答版权归作者所有。本文为个人学习笔记和观点整理,不全文转载原文。
核心判断
这条知乎回答最有价值的地方,是把两种常被混淆的行为分开了:
- 被套后的“伪价投”:先因为看好、跟风或舍不得卖而持有,浮亏扩大后再把“长期持有”当成心理安慰。
- 真正的价值投资:在买入之前就完成标的筛选、价格等待、仓位约束、跟踪逻辑和退出规则。
所以,价值投资不是一种亏损后的解释权,而是一套买入前就存在的纪律。
真正价值投资的流程
1. 先选能看懂的优质标的
价值投资的起点不是“这个股票跌了很多”,而是“这个公司是否值得长期作为资产持有”。
需要回答几个问题:
- 公司基本面是否良好?
- 赚钱能力是否强?
- 自己是否真的看得懂这个业务?
- 未来 3-5 年是否有能力持续创造业绩和股东回报?
这里的难点不是口号,而是选标的能力。看错公司,价值投资一样会亏钱。
2. 等待好价格,而不是追热点
真正的价值投资通常不追逐市场热点,也不因为热度买入尚未验证盈利能力的公司。
更理想的机会来自市场错杀和恐慌时刻。当大部分标的因为外部冲击或流动性情绪出现大幅回撤时,优质公司可能以更好的价格出现。
这对应巴菲特式的逆向原则:市场恐惧时,优质资产的安全边际可能变厚。
3. 仓位控制是纪律的一部分
回答里强调了很具体的仓位约束:试仓、加仓都要小比例进行,有底仓机会时可以加多一些,但单个标的不应过度集中。
这个观点对个人投资尤其重要。很多所谓的长期持有,失败不只是因为标的错,也因为仓位一开始就过重,导致心理承压能力和资金周转空间被打穿。
4. 买入后跟踪逻辑,而不是只盯股价
真正的价值投资买入时有逻辑,买入后也要持续验证逻辑。
需要跟踪:
- 原始买入理由是否还成立。
- 季报、年报是否验证了经营判断。
- 公司基本面是否发生反转。
- 自己是否看错了关键变量。
如果买入逻辑不成立,或者基本面出现重大反转,就应该退出。这里的止损依据不是股价本身,而是基本面和原始判断是否破坏。即使账面仍然盈利,也可能需要止损。
5. 下跌不是自动加仓,逻辑仍成立才加仓
散户式加仓经常是为了摊低成本。问题是,如果标的本身不能回到合理价值,越加仓只是越集中地承担错误。
价值投资式加仓不是为了让账面成本更好看,而是因为投资者认为当下价格仍低于合理价值,且基本面逻辑仍然成立,所以愿意买入更多份额。
这意味着加仓前要先验证:
- 公司变差了吗?
- 行业逻辑变了吗?
- 估值是否仍有安全边际?
- 自己是否只是想通过加仓缓解亏损焦虑?
6. 持有时间来自判断,不来自硬扛
真正的长期持有,是建立在“公司仍然值得持有”的基础上。
如果看对了标的,持有周期可以按年计算,市场回撤也可能只是再次买入的机会。反过来,如果买入逻辑已经破坏,继续持有就不再是价值投资,而是拒绝承认错误。
对我的启发
这条回答可以和我最近的投资记录方法放在一起:炒股要当成一件事来做,而不是消遣。所谓“一件事”,就意味着有流程、有记录、有复盘、有退出规则。
以后判断自己是不是在做价值投资,可以先问五个问题:
- 买入前是否写过买入逻辑?
- 是否知道未来 3-5 年主要看哪些经营指标?
- 是否有明确的合理价格区间和安全边际?
- 仓位是否足够小,能允许自己继续观察和犯错?
- 如果基本面反转,是否愿意承认判断错误并退出?
如果这些问题答不上来,就不能把“长期持有”叫作价值投资。
最小行动清单
- 每个标的建立一页投资卡片:业务理解、买入逻辑、估值区间、仓位上限、跟踪指标、退出条件。
- 每次加仓前写一句话:这次加仓是因为价值更便宜,还是因为我想摊低成本?
- 每次季报和年报后复盘:原始买入逻辑被加强、削弱,还是破坏?
- 把“股价下跌”拆成两类:基本面没变的波动,基本面变差的重估。
- 不用“长期持有”解释已经没有逻辑支撑的仓位。
---
layout: post
title: 主动专注地处理事情
subtitle: Codex 个人助理沉淀
date: 2026-06-09 21:38:49 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/active_attention/01_主动专注地处理事情.md
主动专注地处理事情
核心判断
任何事情主动地、专注地去做,都比被动地去做效果更好。
关键不在于事情本身是否“高价值”,而在于它是否被主动定义成一件事:有明确目的、有时间边界、有处理动作、有结果记录。微信、炒股、放松都可以因为主动处理而变得更有效;也都可能因为被动滑入而变成消耗。
具体场景
微信
微信不只是被消息推着走的工具,也可以作为关系维护和信息整理的入口。
可以集中处理微信:
- 定期把一些感想发给朋友。
- 主动和家人连接。
- 快速梳理群聊里的关键信息。
- 把有价值的信息写入自己的笔记。
这样微信就从“被动接收消息”变成“主动维护关系和整理信息”。
炒股
炒股应当被当成一件正事来做,而不是消遣。
当它被当成一件事,就需要:
- 刻意看盘。
- 记录观察。
- 复盘判断。
- 区分投资研究和情绪刺激。
如果只是作为消遣,就容易被行情波动牵着走,也很难形成可复盘的判断体系。
放松
放松也需要主动安排。
专门让自己慢下来,比在社交网络上浪费时间更能恢复状态。真正的放松不是继续输入刺激,而是降低速度、降低信息密度,让身体和注意力恢复稳定。
可执行规则
- 对容易被动滑入的事情,先问一句:我现在要把它当成一件什么事来做?
- 微信集中处理时,同时做三件事:关系连接、信息筛选、笔记沉淀。
- 看盘时必须留下记录,否则默认只是消费行情。
- 放松时优先选择低输入活动,而不是社交网络。
下一步动作
- 建一个“微信集中处理”固定窗口,记录每次处理后的关系连接和信息沉淀。
- 给投资观察建立最小记录模板:日期、标的、盘面观察、判断、后续验证点。
- 每天至少安排一个不刷社交网络的主动放松块。
---
layout: post
title: 摩根士丹利 2026-05-29 地平线机器人研报详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-08 22:24:21 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026-05-29 Morgan Stanley
---
来源:notes/books/Horizon Robotics 2026-05-29 Morgan Stanley/01_详细解读.md
摩根士丹利 2026-05-29 地平线机器人研报详细解读
标的:地平线机器人-W 9660.HK
机构:摩根士丹利 Morgan Stanley Asia Limited
报告标题:Impact from OEMs' switch to in-house chip solutions - it's not a one/zero situation
发布时间:2026-05-29 14:39 GMT
本地原文:source_materials/HORIZON_20260529_1439.pdf
全文转换稿:source_materials/pdf_full_text.md
处理日期:2026-06-09
说明:本文是基于用户提供 PDF 的个人助理沉淀,不构成投资建议。
1. 核心结论
摩根士丹利维持地平线机器人 Overweight 评级,目标价 HK$10.00。以报告日 2026-05-29 收盘价 HK$5.29 计算,目标价隐含约 89% 上行空间。
这篇报告的核心不是否认主机厂自研芯片趋势,而是把问题从“第三方芯片供应商会不会被替代”拆成更细的商业模式问题:如果车企自研芯片成为趋势,地平线仍可能通过 BPU IP 授权、出货 royalty 和软件设计导入继续留在价值链里。
一句话概括:主机厂自研芯片是压力,但不是一刀切的归零风险;地平线的潜在解法是从“卖芯片”部分转向“卖 BPU IP + 软件生态”。
2. 报告要点
2.1 从芯片销售到 IP 授权
管理层向市场补充解释了 BPU IP 授权模式。对正在开发自研芯片的 OEM,地平线可以授权 BPU IP,并获取两类收入:
- 前期授权费。
- 按实际出货量收取的持续 royalty。
这使地平线的商业模式有点接近半导体 IP 公司,而不只是标准芯片供应商。报告提到,IP 授权模式的毛利率接近 100%,明显高于传统芯片销售的约 40-50% 毛利率。
但需要注意:管理层没有披露该模式相对传统芯片销售的收入贡献。也就是说,方向上更高毛利,但短期体量、节奏和可预测性仍待验证。
2.2 主机厂自研不是“有/无”二元问题
报告承认 in-house chip development 会成为行业趋势,但认为第三方供应商仍然有存在空间,只是合作方式会变化。
摩根士丹利列出的理由包括:
- 并非所有车企都有足够规模和经济性来自研芯片。
- 车载智能芯片规格变化快,持续跟进需要高研发投入。
- 软件和硬件集成复杂,单纯自研硬件不等于拥有完整智能驾驶能力。
- 如果车企采用地平线 BPU 架构,自研芯片反而可能带动地平线软件和 HSD 的采用。
这与市场最悲观叙事不同。最悲观叙事是“车企自研芯片,地平线卖不出去”;大摩的叙事是“车企自研芯片,地平线可能从芯片供货转成 IP 和软件供货”。
2.3 J6M 短期未受影响,但 1H26 增速承压
管理层提到,J6M 今年出货量没有受到影响。
不过报告也指出,更广泛的汽车市场疲弱可能使 2026 年上半年增长低于此前 60% YoY 目标。这里体现出两个层面的区分:
- 公司自身项目和产品节奏并未被主机厂自研立即打断。
- 行业总需求和整车销售压力仍会影响短期收入增长。
因此,短期不宜只看“自研芯片是否替代”这一条线,也要看汽车行业景气度、客户车型放量和 J6M 装车节奏。
3. 关键财务与估值信息
报告给出的主要预测如下:
| 年度 |
收入 Rmb mn |
EPS Rmb |
EBITDA Rmb mn |
ModelWare 净利润 Rmb mn |
| 2025 |
3,758 |
-0.81 |
-3,707 |
-10,469 |
| 2026E |
6,329 |
-0.21 |
-2,402 |
-2,716 |
| 2027E |
9,381 |
-0.07 |
-417 |
-926 |
| 2028E |
13,300 |
0.10 |
1,994 |
1,277 |
估值方法为概率加权 DCF:
| 情景 |
权重 |
| 牛市情景 |
25% |
| 基准情景 |
50% |
| 熊市情景 |
25% |
关键 DCF 假设:
- WACC:
12.2%
- Beta:
1.9
- 长期增长率:
3%
从预测看,大摩认为地平线仍处于亏损收窄阶段,2028 年才进入正 EBITDA 和正 EPS。也就是说,目标价的核心依赖仍是中长期 ADAS/AD 渗透、客户份额、产品放量和商业模式升级,而不是短期利润兑现。
4. 上行与下行风险
4.1 上行风险
- 中国 ADAS/AD 渗透率快于预期。
- OEM 自研硬件设计延迟或失败。
- 中国市场可选方案供应商减少,地平线相对受益。
- 客户群扩张,新增关键客户。
4.2 下行风险
- 中国 ADAS/AD 渗透率低于预期。
- 供应链扰动。
- OEM 自研硬件设计成功,并减少对地平线依赖。
- 中国关键客户整车销售承压。
5. 与瑞银、Bernstein 观点的对照
本地已沉淀过 UBS 2026-05-27、Bernstein 2026-06-02 相关材料。三者可以这样放在同一框架下理解:
| 机构 |
核心焦点 |
对地平线的含义 |
| 瑞银 |
下调 2026-2028 年收入预测但维持买入和目标价 HK$10 |
短期增长预期承压,但中长期逻辑未被完全否定 |
| 摩根士丹利 |
主机厂自研芯片不是一刀切归零,地平线可转向 BPU IP 授权和软件带动 |
把风险从“客户流失”重构为“商业模式迁移能否兑现” |
| Bernstein |
主机厂自研和需求疲弱造成近端压力,但长期 thesis 仍在 |
更强调短期订单/交付和长期架构价值之间的张力 |
大摩这篇报告的增量价值,是把“自研芯片”拆成两层:
- 硬件销售可能被替代或压缩。
- 架构 IP、royalty、软件和工具链仍可能保留甚至提高毛利率。
这个框架对后续跟踪很有用,因为它把观察点从“某车企是否自研芯片”改成“该车企自研芯片是否采用地平线 BPU/IP/软件栈”。
6. 投研含义
如果地平线只能卖标准芯片,那么主机厂自研芯片会直接压缩其长期空间,市场给硬件供应商折价是合理的。
如果地平线能把 BPU IP 授权规模化,并通过 BPU 架构带动 HSD 软件和工具链进入车企体系,那么它的估值逻辑会更接近“智能驾驶 IP/软件平台”,而不是单纯芯片硬件公司。
目前最关键的不确定性在于:IP 授权项目已经在推进,但收入规模没有披露。因此,当前只能把它视为潜在商业模式升级,而不能直接视为已经兑现的利润来源。
7. 后续跟踪动作
- 跟踪公司是否披露 BPU IP 授权客户、授权收入、royalty 口径或项目数量。
- 跟踪 J6M 2026 年装车节奏,尤其是上半年增速是否明显低于
60% YoY 目标。
- 把客户自研芯片分成三类:完全自研替代、采用外部 IP 自研、继续采购第三方芯片。
- 观察 HSD 软件是否随 BPU 架构进入更多车型,如果只授权 IP 而软件没有跟随,长期价值量会打折。
- 后续更新财报时重点看毛利率变化:若 IP/软件占比提升,理论上毛利率应有结构性改善。
8. 来源与限制
已使用来源:
- 用户提供 PDF:
source_materials/HORIZON_20260529_1439.pdf
- PDF 转换稿:
source_materials/pdf_full_text.md
限制和待验证点:
- PDF 第 3-8 页主要为披露、评级定义和覆盖列表,实质研究内容集中在第 1-2 页。
- 报告没有披露 BPU IP 授权模式的当前收入贡献。
- 报告披露摩根士丹利过去 12 个月与 Horizon Robotics 存在投行业务关系和其他服务关系,需要将其观点作为单一输入而非最终结论。
---
layout: post
title: flomo 整合进个人助理方案
subtitle: Codex 个人助理沉淀
date: 2026-06-06 20:33:55 -0400
tags:
- 个人助理
- 项目
- flomo_integration
---
来源:notes/projects/flomo_integration/01_flomo_整合进个人助理方案.md
flomo 整合进个人助理方案
结论
建议把 flomo 定位为“随手记录与灵感入口”,把个人助理工作区定位为“结构化处理、任务推进、文档沉淀和飞书同步中枢”。落地上采用两层能力:
- 第一阶段用 flomo Incoming Webhook 做稳定写入:个人助理可以把灵感、任务、复盘摘要、处理结果回写到 flomo。
- 第二阶段用 flomo MCP 做读写闭环:让 AI 工具按需读取、搜索、创建、更新 flomo 笔记,再把可执行内容同步到本地 Markdown、飞书 Docs 和飞书多维表格。
已核实能力
官方 API 与 URL Scheme
flomo 官方帮助页说明,API & URL Scheme 属于 PRO 会员能力,提供第三方工具与 flomo 交互的能力。API 页面公开说明“提供调用方便的记录 API”,详情入口在 https://flomoapp.com/mine?source=incoming_webhook,也就是登录后获取个人 incoming webhook 地址。
可用于个人助理的判断:
- 适合:从个人助理向 flomo 新建 memo。
- 不适合:稳定批量读取历史 memo、搜索 memo、更新 memo。公开帮助页没有把这些作为普通 API 能力列出。
- 约束:需要 flomo PRO;webhook URL 等同写入密钥,必须放在本地配置或环境变量,不能写入公开仓库。
URL Scheme
flomo 支持 flomo://create,可带 content 和 image_urls 参数。content 最大 5000 字,image_urls 最多 9 个 URL。
可用于个人助理的判断:
- 适合:手机端快捷打开 flomo 并预填内容。
- 不适合:服务器自动化,因为它依赖本机安装的 flomo App 和用户交互。
MCP
flomo 官方帮助页把 MCP 放在“AI 工具连接”能力下,说明可在 Claude、ChatGPT 等 AI 工具中直接读写 flomo。公开页面和页面元信息显示,该能力面向 AI 工具连接,关联创建、搜索、更新笔记及标签等操作;侧栏标注为 MAX 会员能力。
可用于个人助理的判断:
- 适合:AI 助理读取最近 memo、按标签/关键词搜索、创建 memo、更新 memo、补标签。
- 不适合:把 flomo 当作唯一数据库。MCP 更适合 AI 会话内工具调用,不适合替代本地 Markdown 和飞书 Base 的长期结构化账本。
- 约束:需要 flomo MAX;具体 token、server 地址和授权方式应以登录后的 flomo MCP 设置页为准。
导出
flomo 官方帮助页说明支持全局导出和按条件导出,导出格式为 HTML。
可用于个人助理的判断:
- 适合:一次性迁移、定期备份、补齐历史资料。
- 不适合:高频增量同步。HTML 需要解析,稳定性和字段完整性不如 API/MCP。
推荐架构
用户随手记
-> flomo
-> MCP/导出读取
-> 个人助理 inbox/capture.md
-> 分类:信息 / 任务 / 待确认
-> tasks / notes / logs
-> 飞书 Docs + 多维表格
个人助理处理结果
-> 本地 Markdown 源文件
-> 飞书 Docs / Base
-> Incoming Webhook 回写 flomo 摘要或反思卡片
核心原则:
- flomo 负责捕捉,不承载复杂项目管理。
- 个人助理负责加工,不要求用户在 flomo 里手动整理字段。
- 飞书负责展示、检索、协作和阶段性复盘。
- 本地 Markdown 仍是源文件,避免被单一 SaaS 锁死。
多维表格设计
建议在现有个人助理多维表格基础上新增或预留一张“flomo 收件箱”表。如果短期不改表结构,也可以先把整理后的结果同步到现有“知识索引”“文档资产”“待办事项”“每日记录”。
表:flomo 收件箱
| 字段 |
类型 |
用途 |
| flomo_id |
文本 |
去重主键,MCP 可读到 ID 时使用 |
| 创建时间 |
日期时间 |
memo 原始创建时间 |
| 更新时间 |
日期时间 |
memo 原始更新时间 |
| 内容 |
多行文本 |
memo 原文 |
| 标签 |
多选/文本 |
flomo 标签 |
| 来源 |
单选 |
MCP / Webhook / HTML 导出 / 手工 |
| 处理状态 |
单选 |
未处理 / 已入任务 / 已入知识库 / 已入日志 / 忽略 |
| 识别类型 |
单选 |
灵感 / 任务 / 日记 / 资料 / 待确认 |
| 关联本地路径 |
文本 |
对应 Markdown 文件 |
| 关联飞书文档 |
URL |
已沉淀文档链接 |
| 下一步动作 |
多行文本 |
助理判断出的动作 |
| 最后同步时间 |
日期时间 |
个人助理同步时间 |
表:flomo 回写日志
| 字段 |
类型 |
用途 |
| 回写时间 |
日期时间 |
个人助理写入 flomo 的时间 |
| 回写类型 |
单选 |
灵感整理 / 任务摘要 / 日复盘 / 文档摘要 |
| 内容摘要 |
多行文本 |
回写内容 |
| 写入方式 |
单选 |
Incoming Webhook / MCP / URL Scheme |
| 结果 |
单选 |
成功 / 失败 |
| 错误信息 |
多行文本 |
失败原因 |
| 关联本地路径 |
文本 |
来源文件 |
本地文件设计
建议新增配置和脚本:
codex_personal_assistant/config/flomo.json:保存非敏感配置,例如默认标签、同步窗口、处理规则。敏感 token 使用环境变量。codex_personal_assistant/scripts/flomo_write.py:通过 Incoming Webhook 写入 memo。codex_personal_assistant/scripts/flomo_mcp_ingest.py:通过 MCP 拉取最近 memo,写入 inbox 或 notes。codex_personal_assistant/scripts/sync_flomo_to_base.py:把 flomo 收件箱和回写日志同步到飞书多维表格。
环境变量建议:
export FLOMO_WEBHOOK_URL='https://flomoapp.com/iwh/your-token'
export FLOMO_MCP_URL='以 flomo 设置页为准'
export FLOMO_MCP_TOKEN='以 flomo 设置页为准'
处理规则
flomo 到个人助理
- 拉取最近 24 小时或上次同步后的 memo。
- 按标签和内容识别类型:
- 包含
#todo、#任务、要做:进入 tasks/todo.md。
- 包含
#日记、今天、时间地点事件:进入 logs/daily_log.md。
- 包含
#灵感、#选题、#研究:进入 inbox/capture.md,必要时生成 notes/topics/...。
- 包含链接或长摘录:标为资料,等待二次处理。
- 生成处理结果后同步飞书多维表格。
- 重要内容再创建或更新飞书 Docs。
个人助理到 flomo
建议只回写“高价值摘要”,避免把 flomo 变成重复备份仓库:
- 每日复盘:写入一条
#个人助理/日复盘。
- 新建正式笔记:写入一条
#个人助理/知识沉淀,包含标题、摘要、飞书 Docs 链接。
- 任务计划:写入一条
#个人助理/行动,只保留当天最重要 1-3 件事。
回写模板:
#个人助理/知识沉淀
标题:...
一句话结论:...
下一步动作:...
飞书文档:...
实施步骤
第 1 步:写入能力打通
- 在 flomo 设置页获取 Incoming Webhook。
- 本地设置
FLOMO_WEBHOOK_URL。
- 编写
flomo_write.py,支持 --content 和 --file。
- 用一条测试 memo 验证写入。
第 2 步:读能力验证
- 如果已有 flomo MAX,优先在 AI 工具中启用 MCP。
- 验证四个动作:搜索最近 memo、按标签搜索、创建 memo、更新 memo。
- 记录 MCP 返回字段,确认是否有 memo ID、创建时间、更新时间、标签。
第 3 步:建立 flomo 收件箱表
- 在飞书 Base 增加“flomo 收件箱”和“flomo 回写日志”。
- 更新
feishu_base.json 增加表 ID。
- 扩展同步脚本,把 flomo 处理状态写入多维表格。
第 4 步:半自动处理
- 每天拉取一次 flomo 最近 memo。
- 个人助理先生成分类建议,不自动删除或改写 flomo 原文。
- 用户确认后写入任务、日志或主题笔记。
第 5 步:自动化复盘
- 每天晚上自动汇总当天 flomo、todo、daily log。
- 输出一条日复盘到飞书文档/多维表格。
- 只把最终摘要回写 flomo。
风险与边界
- 普通 API 公开信息只确认“写入记录”能力,读取和更新不要押注在非官方接口上。
- MCP 能力受会员等级、客户端支持和授权方式影响,必须用你的账号实测。
- flomo 是碎片化记录工具,不适合承载复杂任务状态;任务主表仍应在个人助理和飞书 Base。
- Webhook URL 泄露会导致别人向你的 flomo 写入内容,应按密钥管理。
- HTML 导出适合作备份和迁移,不适合作实时同步。
下一步动作
- 获取并保存
FLOMO_WEBHOOK_URL,先打通个人助理到 flomo 的写入。
- 确认账号是否有 MAX,决定是否启用 MCP 读写闭环。
- 在飞书多维表格新增两张 flomo 专用表,或先用现有表做一周轻量试运行。
- 一周后复盘:保留“回写摘要”和“任务识别”,谨慎开启自动更新 flomo 原文。
来源
- flomo API & URL Scheme 官方帮助页:
https://help.flomoapp.com/advance/api.html
- flomo MCP 官方帮助页:
https://help.flomoapp.com/advance/mcp/
- flomo 存储与导出官方帮助页:
https://help.flomoapp.com/basic/storage.html
---
layout: post
title: 瑞银 2026-05-27 地平线机器人研报详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-06 10:34:52 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026-05-27 UBS
---
来源:notes/books/Horizon Robotics 2026-05-27 UBS/01_详细解读.md
瑞银 2026-05-27 地平线机器人研报详细解读
标的:地平线机器人-W 9660.HK
机构:瑞银 UBS
用户指定报告日期:2026-05-27
当前材料状态:未找到原始 PDF;本解读基于公开转载摘要、本地既有地平线研究报告中对瑞银观点的引用,以及可验证网页元信息整理。
重要说明:公开转载页面显示发布时间/报道日期接近 2026-05-29;本地旧报告也出现 2026-05-28、2026-05-29 两种引用。目录和标题按用户指定的 2026-05-27 保留,具体原始报告发布日期需以后续 PDF 为准。
1. 核心结论
瑞银这篇报告的核心不是转空地平线,而是把短期收入预期往下修,同时保留对高阶自动驾驶芯片份额提升和舱驾融合业务贡献的中长期认可。
根据公开转载摘要,瑞银将地平线机器人 2026-2028 财年收入预测下调 8%-14%,原因主要是中国汽车需求疲弱,影响智能驾驶方案的上量节奏。与此同时,瑞银维持 买入 评级,并把目标价从 HKD 13.2 下调到 HKD 10.0。
这是一种“短期节奏下修、长期逻辑未破”的观点:瑞银承认行业需求和交付节奏压力,但仍认为地平线受益于高阶自动驾驶芯片市场份额提升,以及座舱/舱驾融合产品线的增量。
2. 已确认的关键摘要
目前可验证信息包括:
- 瑞银维持地平线机器人
买入 评级。
- 目标价由
HKD 13.2 下调至 HKD 10.0。
- 2026-2028 财年收入预测下调
8%-14%。
- 下调原因是中国汽车需求疲弱。
- 正面因素是高阶自动驾驶芯片市场份额增长,以及舱驾融合业务贡献。
- 本地旧报告记录瑞银预测 2026-2028 年调整后 EPS 分别为
-0.25、-0.12、0.04 元人民币,但该组数据仍需用原始研报 PDF 复核。
3. 投资逻辑拆解
瑞银的逻辑可以拆成三层。
第一层是行业 beta 承压。2026 年上半年中国汽车需求偏弱,车企采购和车型上量节奏可能放慢。对地平线这类汽车智能化供应商来说,即使定点没有丢,收入确认和芯片出货也可能被整车销量节奏拖慢。
第二层是公司 alpha 仍在。地平线在高阶自动驾驶芯片市场的份额提升,是瑞银没有转空的关键。也就是说,瑞银下修的是行业需求和收入节奏,不是地平线的竞争地位。
第三层是舱驾融合带来的新收入曲线。舱驾融合如果能降低整车 BOM、减少控制器数量,并把智驾芯片能力扩展到更多车型平台,地平线的市场空间可能不只来自传统 ADAS/NOA 芯片,还包括一体化计算平台。
4. 与 Bernstein 的差异
瑞银和 Bernstein 都给出 HKD 10.0 目标价,但关注点不同。
Bernstein 更强调主机厂自研芯片不是简单替代地平线,地平线仍可通过 BPU IP 授权、royalty 和 HSD 软件留在价值链中。
瑞银摘要更偏业绩预测层面:承认中国汽车需求疲弱,因此下调 2026-2028 年收入预测,但仍维持买入。
这意味着两篇报告可以互补使用:瑞银用来跟踪短期收入和盈利节奏,Bernstein 用来分析“主机厂自研是否破坏长期护城河”。
5. 需要警惕的风险
第一,收入下修可能不是一次性的。如果汽车需求疲弱延续,或者智能驾驶从高端车型向大众车型下放过程中价格压力加大,地平线的收入增长可能继续低于原先高增长预期。
第二,高阶自动驾驶芯片份额提升未必自动转化为利润弹性。若客户议价能力增强,或智驾硬件价格持续下降,公司可能面临“份额上升、单车价值量下降”的组合。
第三,舱驾融合需要量产客户验证。市场通常愿意给舱驾融合高叙事估值,但真正重要的是量产车型、SOP 时间、单车收入、毛利率和后续复购。
第四,报告原文缺失。当前只能基于摘要分析,无法确认瑞银完整模型、估值倍数、假设表和风险披露。
6. 后续跟踪动作
- 补找瑞银原始 PDF 或 Bloomberg/UBS Research 摘要页,核对报告发布日期、标题、分析师、收入和 EPS 预测表。
- 跟踪地平线 2026 年中报或业绩会,验证收入增长是否低于原先约 60% 年化目标。
- 跟踪 Journey 6 系列和舱驾融合芯片的量产客户、车型价格带和出货节奏。
- 对比 UBS 与 Bernstein 同为
HKD 10.0 目标价时的估值基础:EV/Sales、收入预测和利润率假设是否一致。
- 单独建立“收入下修 vs 竞争力受损”判断表,避免把行业周期压力误判成公司长期逻辑破坏。
7. 来源与待验证
已使用来源:
- AASTOCKS 公开转载摘要:
https://www.aastocks.com/sc/stocks/analysis/china-hot-topic-content.aspx?catg=4&id=NOW.1526426&source=AAFN
- 本地旧报告引用:
ashare_monitor/company_analyze/invest_community/tools/company_report/reports/地平线机器人_20260603_173028_report.md
- 本地旧报告引用:
ashare_monitor/company_analyze/invest_community/tools/company_report/reports/地平线机器人_20260603_170210_report.md
待验证事项:
- 原始报告准确发布日期是否为 2026-05-27、2026-05-28 或 2026-05-29。
- 原始报告标题、分析师姓名、完整估值方法。
- 2026-2028 年收入、EPS、毛利率和 EV/Sales 的完整模型。
---
layout: post
title: 伯恩斯坦 2026-06-02 地平线机器人研报详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-06 10:34:52 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026-06-02 Bernstein
---
来源:notes/books/Horizon Robotics 2026-06-02 Bernstein/01_详细解读.md
伯恩斯坦 2026-06-02 地平线机器人研报详细解读
标的:地平线机器人-W 9660.HK
机构:Bernstein
原始报告:Horizon Robotics: Near-term pressure due to OEM in-house chip deployment, but long-term thesis is intact
日期:2026-06-02
原始文件:source_materials/Horizon Robotics_ Near-term pressure due to OEM in-house chip deployment, but long-term thesis is intact.pdf
全文转换稿:source_materials/pdf_full_text.md
说明:本文是独立目录下的新版结构化解读,便于与瑞银、大摩报告分开存储和独立同步飞书。
1. 核心结论
Bernstein 认为地平线机器人短期承压,主要来自两个担忧:主机厂加速自研智驾芯片,以及 2026 年中国汽车需求偏弱导致市场怀疑公司交付目标。
但报告维持 Outperform 评级,目标价 HKD 10.00。报告日收盘价为 HKD 5.43,对应约 84% 上行空间。
这份报告的核心判断是:主机厂自研芯片会改变地平线的商业模式和利润分配方式,但不必然把地平线从价值链中切出去。地平线可以通过 BPU IP 授权、royalty、HSD 软件和工具链生态继续参与价值分配。
2. 关键数据
报告披露的核心数据包括:
- 评级:
Outperform
- 目标价:
HKD 10.00
- 收盘价:
HKD 5.43
- 隐含上行空间:约
84%
- 市值:约
HKD 79.2bn
- 企业价值:约
HKD 48.9bn
- 2026E EV/Sales:
8.3x
- 2026E EPS:
-0.25 RMB
估值基于 2H27-1H28 销售额 RMB 11.5bn 和 10.3x EV/Sales。也就是说,地平线仍是高成长收入估值框架,而不是当期利润估值框架。
3. 主机厂自研的真正问题
市场担心 BYD、理想、小鹏、蔚来、特斯拉、华为等玩家自研智驾芯片,会压缩第三方供应商空间。
Bernstein 的反驳是:自研芯片和第三方芯片会共存。多数 OEM 不具备同时完成芯片、软件、算法迭代和规模经济的能力。
报告列出三类门槛:
- 规模门槛:低于约
150 万辆/年,自研芯片经济性不足。
- 软件门槛:智驾体验主要由算法、数据闭环、工程调参和量产 know-how 决定。
- 技术门槛:行业仍在从 L2++ 到 L3、从端到端到 VLA/world models 快速演进,算力和算法变化太快,OEM 很难长期摊销自研投入。
管理层估计真正能成功自研的 OEM 概率约 10%。这个数字可以争论,但它揭示了地平线管理层的底层判断:成功自研需要规模、软件深度和科技公司 DNA 同时成立。
4. ARM + Android 框架
报告最重要的框架是 ARM + Android。
ARM 代表底层 IP 授权:
- 地平线可授权 BPU 核心。
- OEM 可基于 BPU 做自研智驾芯片或舱驾融合芯片。
- 授权费可一次性或周期性收取。
- 芯片量产后,地平线可按内部芯片结算价收取 royalty。
- royalty 毛利率可达到
90%+。
Android 代表软件生态:
- HSD 智驾软件与 BPU 生态深度绑定。
- 将 NVIDIA 生态算法迁移到 BPU 难度高。
- 即使 OEM 自研芯片,只要底层使用地平线 BPU,仍可能保留在地平线生态内。
因此,OEM 自研不是简单的“地平线收入归零”,而是从直接卖芯片转向“芯片 + 软件 + IP license + royalty”的混合模式。
5. 最大风险:高毛利率不等于高绝对毛利
报告中最需要警惕的是 IP 授权模式的经济性。
IP 授权和 royalty 的毛利率很高,但不必然带来更高单车绝对毛利。若客户从购买 Journey 6 芯片和软件,转向购买 IP 并自行设计芯片,地平线可能获得更高毛利率,却损失部分单车收入和绝对毛利。
后续不能只看毛利率改善,必须跟踪:
- 单车收入是否下降。
- 单车绝对毛利是否下降。
- royalty 是否持续、可审计、可规模化。
- IP 授权是否前置确认收入,导致后续收入波动。
- 软件是否还能在 IP 客户中持续绑定。
6. 产品与客户进展
Journey 6M 是 2026 年主力放量产品之一,可支持入门级城市 NOA。它的体验弱于 Journey 6P 的完整 HSD,但能满足监管要求并提供可接受消费者体验。
Journey 6P 定位完整 HSD 平台,更适合高规格城市 NOA 和中高端智驾车型。
Starry 舱驾融合芯片的吸引力来自降本:2-box 到 1-box 可以减少电源、被动器件、PCB 面积、铝壳和液冷板等成本。第一家量产客户会形成标杆效应。
KakaClaw 座舱 OS 与部分头部国内客户适配推进中。它不强绑定地平线芯片,也可以跑在 Qualcomm 平台上,因此软件上车节奏可能快于硬件。
7. 2026 年节奏
管理层将 2026 年描述为“前低后高”。报告提到,2026 年上半年中国汽车行业偏弱,前四个月国内汽车销售同比约 -20%,5 月可能也偏软。
Bernstein 认为短期 earnings miss 风险有限,因为 2026 年销量大多来自已经获得的 design wins。真正更前瞻的指标,是 2026 年下半年到 2027 年初新增 design wins 的数量和质量。
8. 竞争格局
报告把行业供应链分为三类:
- NVIDIA + 软件伙伴。
- Horizon + 自有软件。
- OEM 自研芯片 + 自研软件。
对华为,管理层承认其会获得显著份额,但认为单一中国 OEM 集团存在规模上限。管理层判断中国约 2500 万辆 乘用车市场中,约 30%-40% 对地平线较难触达,但剩余长尾市场仍足够大。
这里的关键风险是:如果地平线最终主要拿到低价长尾市场,而高价值车型和高利润池被华为、自研 OEM 或 NVIDIA 生态拿走,公司收入和利润弹性仍会受到压缩。
9. 与瑞银观点的组合使用
瑞银和 Bernstein 都给出 HKD 10.0 目标价,但两者回答的问题不同。
瑞银更直接处理业绩节奏:因中国汽车需求疲弱,下调 2026-2028 年收入预测,但维持买入。
Bernstein 更直接处理长期护城河:主机厂自研是否会破坏地平线价值链位置。
组合起来看,当前多头逻辑是:短期行业需求和市场情绪压制真实存在,但地平线的长期平台价值尚未被证明破坏。真正的反证将来自新增定点质量下降、单车价值量下降、软件/IP 绑定失败,而不是单纯股价下跌。
10. 后续跟踪动作
- 每月跟踪主要客户车型销量和智驾方案上车节奏。
- 每季度跟踪收入增长、毛利率、绝对毛利和经营现金流。
- 单独跟踪 IP 授权客户数量、royalty 披露方式和收入确认节奏。
- 跟踪 Journey 6P、Starry、KakaClaw 的量产客户和实际体验反馈。
- 对比华为、NVIDIA、Momenta、黑芝麻等竞争方在中高端车型和大众车型中的份额变化。
11. 来源
- Bernstein 原始 PDF:
source_materials/Horizon Robotics_ Near-term pressure due to OEM in-house chip deployment, but long-term thesis is intact.pdf
- Bernstein PDF 全文转换稿:
source_materials/pdf_full_text.md
---
layout: post
title: BERT 详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-06 07:46:04 -0400
tags:
- 个人助理
- 读书笔记
- BERT
---
来源:notes/books/BERT/01_详细解读.md
BERT 详细解读
核心结论
BERT 的核心贡献是把 Transformer encoder 变成了通用语言理解底座。它通过 masked language modeling 让模型在每一层同时利用左、右上下文,从而获得深度双向表示;再通过统一的 fine-tuning 流程,把同一个预训练模型迁移到分类、句对匹配、序列标注和抽取式问答等任务上。
它改变 NLP 工作流的地方不只是“模型效果更好”,而是把大量任务从“为每个任务设计复杂结构”推进到“预训练模型 + 少量任务头 + 全参数微调”。这就是后来预训练语言模型范式的关键起点之一。
论文信息
- 标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
- 机构:Google AI Language
- arXiv:1810.04805
- 版本:v2, 2019-05-24
- 本地 PDF:
source_materials/bert.pdf
- 全文转换:
source_materials/pdf_full_text.md
背景问题
BERT 之前,语言表示预训练已经有效,但主流路线有两个限制。
第一,feature-based 方法如 ELMo 通常把预训练表示作为额外特征接入下游模型,下游任务仍然需要较多任务结构设计。
第二,fine-tuning 方法如 OpenAI GPT 使用 left-to-right language model。它适合生成,但对理解任务有天然限制:每个 token 在预训练时只能看左侧上下文,不能同时利用右侧信息。对自然语言推理、句对关系和抽取式问答这类任务,单向上下文是不充分的。
BERT 的判断是:语言理解任务需要双向上下文,而且这种双向性应该发生在 Transformer 的所有层,而不是简单拼接一个左到右模型和一个右到左模型。
方法拆解
BERT 使用多层双向 Transformer encoder。论文报告两个主要规模:
- BERTBASE:12 层,hidden size 768,12 个 attention heads,约 110M 参数。
- BERTLARGE:24 层,hidden size 1024,16 个 attention heads,约 340M 参数。
这里的关键不是 Transformer 本身,而是 attention mask。GPT 的 decoder 使用因果 mask,当前位置只能看左侧;BERT encoder 不使用因果 mask,序列中每个 token 可以关注左右两侧所有 token。
2. 输入表示:三类 embedding 相加
BERT 的输入由三部分相加:
- Token embedding:WordPiece token 表示。
- Segment embedding:区分句子 A / 句子 B。
- Position embedding:位置表示。
特殊 token:
[CLS]:放在序列开头,其最终 hidden state 用于分类任务。[SEP]:分隔两个句子或标记句子结束。
这个设计让单句任务、句对任务、问答任务都能装进同一个输入格式。
3. 预训练任务一:Masked Language Modeling
MLM 是 BERT 的核心。训练时随机选择 15% 的 WordPiece token 作为预测目标。为减少预训练和微调之间的 [MASK] 不一致,选中的 token 会按规则处理:
- 80% 替换成
[MASK]。
- 10% 替换成随机 token。
- 10% 保持原 token 不变。
模型只预测被选中的 token,而不是重建整句。这个目标允许模型同时利用左右上下文,因此可以训练深度双向表示。
MLM 的优点是解决单向语言模型的限制;缺点是预训练阶段出现 [MASK],但下游微调和真实输入没有这个 token,存在分布不一致。
4. 预训练任务二:Next Sentence Prediction
NSP 用于学习句子间关系。训练样本中,一半是连续句子对,一半是随机配对句子。模型根据 [CLS] 表示判断句子 B 是否是句子 A 的下一句。
论文认为 NSP 对问答和自然语言推理等句对任务有帮助。后续研究对 NSP 的必要性有争议,RoBERTa 等工作移除了 NSP 并获得更强结果。因此应把 NSP 理解为 BERT 原始方案的一部分,而不是预训练语言模型的永久标准。
Fine-tuning 范式
BERT 的迁移方式非常统一:下游任务直接加载预训练参数,再加一个很小的任务输出层,然后全参数微调。
典型任务适配:
- 句子分类:用
[CLS] 的 final hidden state 接分类器。
- 句对分类:输入
[CLS] sentence A [SEP] sentence B [SEP],用 segment embedding 区分两句。
- 序列标注:对每个 token 的 final hidden state 做标签预测。
- 抽取式问答:对每个 token 预测 start/end span。
这个范式显著降低了任务工程成本。以前很多 NLP 系统依赖任务特定结构,BERT 则把大部分能力前置到预训练阶段。
实验结论
论文在 11 个 NLP 任务上报告了强结果,包括 GLUE、MultiNLI、SQuAD v1.1、SQuAD v2.0 等。
关键实验意义:
- BERTLARGE 通常显著强于 BERTBASE,说明规模有作用。
- 去掉 NSP 或改成单向/浅双向表示会影响部分任务表现。
- 使用预训练参数初始化并全量微调,是性能提升的核心流程。
- BERT 对 token-level 任务如问答尤其有价值,因为这些任务需要左右上下文共同定位答案。
与 GPT 的区别
| 维度 |
BERT |
GPT/GPT-2 |
| 架构 |
encoder-only |
decoder-only |
| 注意力 |
双向 self-attention |
因果 self-attention |
| 训练目标 |
MLM + NSP |
next-token prediction |
| 强项 |
理解、分类、抽取、句对关系 |
生成、补全、开放式任务 |
| 下游方式 |
微调任务头 |
prompt / 微调 / 指令对齐 |
| 典型输出 |
表示或标签 |
文本序列 |
BERT 更像“理解型底座”,GPT 更像“生成型接口”。今天很多 embedding、reranker、分类器、抽取系统仍然沿用 BERT 系 encoder 模型;而聊天和生成系统主要沿用 GPT 系 decoder-only 模型。
与 ELMo 的区别
ELMo 也利用左右上下文,但它是分别训练左到右和右到左语言模型,再把表示拼接起来。BERT 的双向性发生在每一层 self-attention 中,token 的表示从底层开始就能融合左右上下文。这是“浅双向”和“深双向”的差异。
工程启发
1. 当任务是理解,不一定要用生成模型
如果任务是分类、相似度、抽取、检索、重排,BERT 系 encoder 往往更直接、成本更低、延迟更可控。不要把所有 NLP 问题都默认交给 decoder-only LLM。
2. 输入格式统一可以降低系统复杂度
BERT 用 [CLS]、[SEP]、segment embedding 统一单句和句对任务。这个思想在今天仍然重要:系统层面最好先把任务接口标准化,再考虑模型。
3. 预训练目标决定能力边界
MLM 适合理解,不适合原生长文本生成。next-token prediction 适合生成,但对双向 token-level 理解不如 encoder 自然。选模型时要看预训练目标是否贴合任务。
4. 微调不是只训练最后一层
BERT 的标准 fine-tuning 是全参数微调。只冻结 BERT 并训练分类头可能能跑,但通常不是论文里的最强设置。
局限与后续发展
[MASK] token 导致预训练和下游输入不一致。- NSP 是否必要存在争议。
- 最大序列长度有限,长文档任务需要切片、滑窗或长上下文变体。
- encoder-only 不适合自然生成。
- BERT 原始训练数据和规模后来被 RoBERTa、ALBERT、DeBERTa 等改进。
后续重要方向:
- RoBERTa:更强训练策略,移除 NSP。
- ALBERT:参数共享与句子顺序预测。
- DistilBERT:蒸馏压缩。
- DeBERTa:解耦注意力和增强位置表示。
- Sentence-BERT:把 BERT 改造成句向量检索/相似度模型。
阅读重点
如果只精读部分章节,建议按这个顺序:
- Abstract 和 Introduction:理解论文要解决什么问题。
- Section 3.1:模型架构和输入表示。
- Section 3.2:MLM 和 NSP。
- Section 4:fine-tuning 到不同任务的方式。
- Ablation:理解双向预训练、规模、NSP 的影响。
可执行学习任务
- 手写一张 BERT 输入结构图:
[CLS] sentence A [SEP] sentence B [SEP],标出 token/segment/position embeddings。
- 用自己的话解释为什么 BERT 不能直接用普通 left-to-right LM 目标训练。
- 对比 BERT 和 GPT-2:写出架构、目标、任务适配方式的三项差异。
- 找一个抽取式问答样例,说明 BERT 如何预测 start token 和 end token。
- 如果做工程实践,用 Hugging Face 跑一次
bert-base-uncased 文本分类微调或 embedding 抽取。
下一步动作
- 补一张
02_方法卡片.md,把 BERT 的模型选择、微调、输入构造和适用任务变成工程检查清单。
- 继续单独处理 GPT-2 或 T5,形成 encoder-only、decoder-only、encoder-decoder 三类架构的对照笔记。
---
layout: post
title: Transformer Papers 详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-06 07:39:14 -0400
tags:
- 个人助理
- 读书笔记
- Transformer Papers
---
来源:notes/books/Transformer Papers/01_详细解读.md
核心结论
这一组论文讲的是同一条技术主线:Transformer 把序列建模的核心从“按时间递推”改成“基于注意力的全局信息路由”,随后研究重心从架构本身转向预训练、规模化、上下文长度、任务统一和跨模态迁移。
最重要的变化不是某一个模块,而是范式迁移:
Attention Is All You Need 证明了不用 RNN/CNN,也可以用自注意力加前馈网络完成高质量序列到序列建模。- BERT 证明了 Transformer encoder 可以通过大规模自监督预训练,成为通用语言理解底座。
- GPT-2 证明了 Transformer decoder 只靠语言模型目标和规模,也能产生明显的零样本/弱监督任务能力。
- Transformer-XL 解决固定长度上下文的问题,把 Transformer 推向更长依赖建模。
- T5 把 NLP 任务统一为 text-to-text,系统比较预训练目标、数据、模型和迁移策略。
- ViT 证明 Transformer 不只属于文本;当图像被切成 patch 序列,纯 Transformer 也可以在视觉任务上成立,但它更依赖大规模预训练。
如果要抓住 Transformer 的本质,可以用一句话概括:它是一种可并行、可扩展、可迁移的信息混合架构;后续大模型的成功,主要来自这个架构和大规模自监督数据、算力、任务格式统一之间的配合。
论文包范围
本次处理 6 篇论文:
Attention Is All You Need:Transformer 原始架构。BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding:双向 encoder 预训练与微调。Language Models are Unsupervised Multitask Learners:GPT-2,decoder-only 语言模型与零样本迁移。Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context:长上下文、段级循环和相对位置编码。Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer:T5,统一 text-to-text 框架和系统性迁移学习实验。An Image is Worth 16x16 Words:ViT,把图像 patch 当作 token 序列。
PDF 原文与全文 Markdown 转换稿保存在 source_materials/。
技术主线
Attention Is All You Need 的关键判断是:序列转导模型不一定需要循环结构。传统 seq2seq 依赖 RNN 或 CNN 建模 token 间关系,注意力通常只是编码器和解码器之间的附加机制。Transformer 直接把注意力放到架构中心,用 multi-head self-attention 让每个 token 在每一层都可以和其他 token 建立关系。
核心模块:
- Scaled dot-product attention:用 query、key、value 计算 token 间相关性。
- Multi-head attention:把注意力拆成多个子空间,允许模型同时关注不同关系。
- Position-wise feed-forward network:每个位置共享的非线性变换。
- Positional encoding:补回自注意力本身不具备的顺序信息。
- Encoder-decoder 堆叠:encoder 表示输入,decoder 自回归生成输出。
真正的工程价值在于并行化。RNN 的时间步依赖限制训练并行度,而 Transformer 可以一次处理整个序列。代价是注意力复杂度随序列长度平方增长,因此后续才会出现大量长上下文优化。
BERT 的核心是“深度双向表示”。它使用 Transformer encoder,不做自回归生成,而是在预训练阶段让模型同时利用左右上下文。
两个预训练任务:
- Masked Language Modeling:随机遮住一部分 token,让模型根据上下文预测。
- Next Sentence Prediction:判断两个句子是否相邻,用于学习句间关系。
BERT 的重要性不只在分数提升,而在工作流变化:下游任务不再需要为每个任务设计复杂架构,通常只需在预训练模型上加一个很小的输出层并微调。这建立了“预训练模型 + 任务微调”的标准范式。
局限也很清楚:
- MLM 的 mask 分布和真实下游输入存在不一致。
- encoder-only 不适合自然自回归生成。
- NSP 后来被一些工作证明并非总是必要。
3. GPT-2:decoder-only 语言模型的规模化能力
GPT-2 走的是另一条路线:不显式做任务监督,不用任务专用格式,而是把网页文本中的自然任务描述和回答看作隐式监督。模型目标仍然是 next-token prediction,但随着数据和参数规模扩大,模型出现跨任务泛化能力。
关键点:
- 使用 decoder-only Transformer。
- 在 WebText 上训练,数据来自高质量网页文本。
- 通过提示和上下文完成问答、摘要、翻译等任务。
- 论文强调容量对零样本任务迁移很关键,模型越大,跨任务表现越好。
GPT-2 的意义是把“语言建模”从一个基础任务提升为通用接口。后来的 instruction tuning、RLHF、chat model,本质上都是在这个 decoder-only 生成范式上继续增加对齐和交互能力。
标准 Transformer 在语言建模时通常把长文本切成固定长度片段,每个片段内部自注意力,但片段之间没有连续状态。这会带来两个问题:
- 长程依赖被截断。
- 片段边界附近的 token 缺少前文上下文,形成 context fragmentation。
Transformer-XL 的解决方案:
- Segment-level recurrence:把前一个片段的 hidden states 缓存为 memory,供当前片段注意力读取。
- Relative positional encoding:避免绝对位置编码在跨片段复用 hidden states 时产生位置混乱。
它让 Transformer 更像有记忆的模型,同时保留比 RNN 更强的并行性。这个方向后来延伸到长上下文 Transformer、缓存 KV、相对位置、旋转位置编码等一系列工作。
5. T5:把所有 NLP 任务统一成 text-to-text
T5 的贡献不只是一个模型,而是一套实验框架。它把分类、问答、摘要、翻译等任务都改写成“输入文本到输出文本”的形式,例如输入里加任务前缀,输出统一由文本生成。
关键贡献:
- 统一任务格式:text-to-text。
- 系统比较 encoder-decoder、decoder-only、language modeling、span corruption 等设置。
- 使用 C4 数据集进行大规模预训练。
- 强调模型、数据、目标和迁移策略共同决定效果。
T5 对实践很有指导意义:当任务可以统一成文本生成,工程系统会变得简单。今天很多 LLM 应用把检索、分类、抽取、改写、规划都包装成 prompt,本质上沿用了这种任务统一思想。
ViT 的基本做法很直接:把图片切成固定大小 patch,每个 patch 展平成向量后映射成 token,再加位置编码,送入标准 Transformer encoder。
关键判断:
- CNN 的卷积归纳偏置不是视觉建模的绝对必要条件。
- 当预训练数据足够大时,纯 Transformer 可以学到有效视觉表示。
- 在中小数据集上直接训练 ViT 通常不如 CNN,说明它更依赖数据规模。
ViT 的意义是把 Transformer 从 NLP 架构扩展为通用序列建模架构。图片、音频、视频、代码、蛋白质、机器人轨迹,只要能被组织成 token 或 patch 序列,就可以进入类似框架。
横向对比
| 论文 |
架构重点 |
训练目标 |
解决的问题 |
后续影响 |
| Attention Is All You Need |
encoder-decoder self-attention |
监督翻译 |
去掉 RNN/CNN,提高并行化 |
Transformer 基础架构 |
| BERT |
encoder-only |
MLM + NSP |
通用语言理解表示 |
预训练 + 微调范式 |
| GPT-2 |
decoder-only |
next-token prediction |
零样本/弱监督任务迁移 |
生成式大语言模型路线 |
| Transformer-XL |
decoder with memory |
language modeling |
长上下文和片段断裂 |
长上下文建模、缓存机制 |
| T5 |
encoder-decoder |
span corruption + text-to-text |
统一 NLP 任务格式 |
text-to-text、prompt 化任务 |
| ViT |
encoder-only over image patches |
图像分类预训练/迁移 |
Transformer 迁移到视觉 |
多模态 Transformer |
学习顺序建议
- 先读
Attention Is All You Need 的第 3 节,理解 self-attention、multi-head attention、position encoding、encoder-decoder。
- 再读 BERT,重点看为什么 encoder 适合理解任务,以及 MLM 如何构造自监督信号。
- 再读 GPT-2,重点看 decoder-only、next-token prediction 和零样本迁移之间的关系。
- 然后读 Transformer-XL,理解标准 Transformer 固定上下文的限制。
- 读 T5 时不要逐页啃完,优先看任务统一、实验结论和 ablation。
- 最后读 ViT,把 Transformer 看成通用 token 混合器,而不是 NLP 专用架构。
关键概念卡片
Self-Attention
每个 token 根据自身 query 去匹配其他 token 的 key,再加权汇总 value。它解决的是“当前位置应该从哪些位置取信息”的问题。
Multi-Head Attention
多个注意力头并行工作,每个头学习不同关系。例如一个头关注局部语法,一个头关注长程指代,一个头关注结构边界。注意这只是直觉解释,实际头的语义不总是稳定可解释。
Positional Encoding
自注意力对输入顺序天然不敏感,所以必须注入位置信息。早期用 sinusoidal 或 learned absolute position,后续长上下文模型大量使用相对位置、RoPE 等变体。
Encoder-Only / Decoder-Only / Encoder-Decoder
- Encoder-only:适合理解、分类、检索、抽取,代表 BERT。
- Decoder-only:适合自回归生成和开放式任务接口,代表 GPT 系列。
- Encoder-decoder:适合输入输出都较复杂的转换任务,代表 T5、翻译模型。
Pretraining and Fine-tuning
先用大规模无标注数据学通用表示,再用小规模标注数据适配任务。BERT 把这个范式推成主流,T5 系统化比较了多种迁移学习设置。
Scaling
GPT-2 和后续 GPT-3 路线表明,模型容量、数据规模和训练计算量会显著影响泛化能力。Transformer 架构的并行性是 scaling 能跑起来的重要前提。
对今天大模型的启发
- 架构只是起点。Transformer 原始论文解决了并行序列建模,真正释放能力的是后续预训练数据、目标函数、规模化和任务接口。
- 任务格式会改变系统复杂度。BERT 统一成微调,T5 统一成 text-to-text,GPT 统一成 prompt + next-token generation。
- 长上下文不是简单扩大窗口。Transformer-XL 提醒我们,位置编码、memory 复用、片段边界和推理效率都要一起处理。
- 跨模态的关键是 token 化。ViT 的启发是,只要能把输入变成序列,Transformer 就能作为通用混合器。
- 归纳偏置和数据规模互相替代。CNN 在小数据上更强,是因为视觉归纳偏置更合适;ViT 在大数据上更强,是因为模型可以从数据中学习这些结构。
可执行学习计划
第 1 天:架构
- 精读
Attention Is All You Need 第 3 节。
- 手画一遍 Q/K/V、multi-head attention、encoder layer、decoder layer。
- 输出一个问题:为什么 attention 复杂度是 O(n^2)?
第 2 天:语言理解与生成
- 对比 BERT 和 GPT-2。
- 写出 encoder-only 和 decoder-only 的差异表。
- 用一个例子说明 MLM 和 next-token prediction 的训练信号差异。
第 3 天:长上下文
- 阅读 Transformer-XL 的 segment recurrence 和 relative positional encoding。
- 总结标准 Transformer 为什么不能直接复用上一段 hidden states。
第 4 天:任务统一
- 阅读 T5 的 text-to-text 框架。
- 选 5 个任务,把它们改写成 text-to-text 输入输出格式。
第 5 天:跨模态
- 阅读 ViT 的 patch embedding。
- 用一句话解释为什么图像 patch 可以类比文本 token。
- 思考:如果是音频、视频、时间序列,应如何 token 化?
待验证问题
- 这一组只覆盖主线论文,没有覆盖 GPT-3、RoPE、FlashAttention、PaLM、LLaMA、MoE、LoRA、RAG 等后续关键工作。
- T5 论文较长,本笔记先抽取主线结论;如果要做研究级复现,需要单独拆解实验设置。
- ViT 的结论强依赖预训练数据规模,不应简单理解为“Transformer 总是优于 CNN”。
下一步动作
- 继续补一组“现代 LLM 工程论文”:GPT-3、Chinchilla、InstructGPT、LoRA、FlashAttention、RoPE、LLaMA、RAG。
- 如果目标是工程实现,下一步应做一个最小 Transformer notebook:从 Q/K/V attention 到 decoder-only 语言模型。
- 如果目标是读论文,应把本论文包拆成 6 张方法卡,每篇论文一张。
---
layout: post
title: 卓驭科技公司研究
subtitle: Codex 个人助理沉淀
date: 2026-06-06 06:24:51 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/zhuoyu_technology/01_卓驭科技公司研究.md
卓驭科技公司研究
记录时间:2026-06-06
一句话结论
卓驭科技(深圳市卓驭科技有限公司)是原大疆车载业务独立化后的智能驾驶供应商,核心竞争力来自大疆在视觉、机器人、工程量产和成本控制上的技术迁移;它正在从乘用车 ADAS Tier 1,扩展到商用车、无人物流、Robotaxi 和“移动物理 AI”平台。
名称澄清
- 用户提到的“卓驭创新”,公开资料中更常见、可核验的主体是“深圳市卓驭科技有限公司”及“卓驭”品牌。
- 它和“大疆创新”关系密切:卓驭的前身是大疆内部智能驾驶/车载业务,后独立运营,并在 2024 年 6 月正式启用“卓驭”作为业务品牌。
基本信息
- 公司主体:深圳市卓驭科技有限公司。
- 成立时间:工商信息显示为 2022 年 10 月 28 日。
- 注册地:深圳市南山区。
- 法定代表人:朱露。
- 定位:智能驾驶系统供应商及服务商,为乘用车和商用车提供高阶辅助驾驶系统、自研核心零部件和工程交付。
- 核心产品:成行平台,覆盖高速、城市、泊车等场景,可适配不同算力、传感器和芯片配置。
历史背景与时间线
- 2016 年:大疆内部启动智能驾驶预研项目,早期约 10 人团队开始做车载智能驾驶技术。
- 2021 年:大疆车载业务品牌形成,开始更系统地面向主机厂提供智能驾驶方案。
- 2022 年 10 月:深圳市卓驭科技有限公司成立。
- 2023 年:大疆车载业务从大疆体系中分拆独立运营,卓驭成为承接主体。
- 2023 年 7 月:大疆车载发布/命名“成行平台”,强调低算力纯视觉、惯导双目等方案。
- 2024 年 6 月:正式启用“卓驭”作为业务品牌,定位智能驾驶供应商及服务商。
- 2025 年:上海车展期间公开九大合作客户;随后获得多家车企和产业资本入股。
- 2025 年 11 月:获得中国一汽超 36 亿元战略投资,投后估值据报道超过 100 亿元。
- 2026 年:公开信息显示,卓驭继续推进乘用车、重卡高速 NOA、无人物流车、Robotaxi 和基础模型方向。
创始团队与关键人物
沈劭劼
- 公开身份:卓驭科技 CEO。
- 学术背景:香港科技大学电子与计算机工程系副教授、港科大-大疆联合创新实验室主任、港科大郑家纯机器人研究所副所长。
- 技术领域:机器人、无人机、状态估计、传感器融合、自主导航、计算机视觉等。
- 与卓驭关系:多家媒体报道其是大疆车载项目牵头和技术领军人物,在卓驭独立后担任 CEO。
- 研究判断:沈劭劼的机器人和无人机视觉背景,是卓驭强调低成本视觉方案、空间智能和移动物理 AI 的核心来源。
朱露
- 公开身份:深圳市卓驭科技有限公司法定代表人;部分媒体称其担任总经理。
- 背景线索:IT之家等媒体称朱露曾为大疆人力资源总监。
- 待验证点:朱露在卓驭当前实际经营管理中的职责边界,公开信息不足。
马陆
- 公开身份:工商/媒体资料中出现为董事或早期关键成员。
- 早期角色:搜狐汽车等媒体报道,马陆在大疆车载项目中类似“团队大管家”,负责协调大疆内部资源支持车载团队。
- 待验证点:当前是否仍担任核心高管或董事,以及具体分管事项,需以后续工商变更和官方披露为准。
早期团队成员
搜狐汽车报道提到,除沈劭劼、马陆外,赵丛、封旭阳、李思晋、应佳行、陈竞等属于早期团队成员。其中赵丛曾负责智能车深度学习/机器学习相关部分。
注意:早期团队名单主要来自媒体报道,不等同于公司官方“创始人名单”。公开资料中,卓驭未系统披露完整创始人和高管团队。
高管团队公开度
目前公开可确认度较高的是:
- CEO:沈劭劼。
- 法定代表人:朱露。
- 董事/早期关键成员:马陆。
其他 CTO、CFO、COO、销售负责人、供应链负责人等信息,公开资料不完整,不建议在未核验前作为确定事实使用。
主要客户与合作伙伴
乘用车客户
公开资料中反复出现的客户包括:
- 大众汽车
- 上汽通用五菱
- 比亚迪
- 奇瑞汽车
- 长城汽车
- 中国一汽
- 东风汽车
- 奥迪
- 北汽集团
2025 年上海车展期间,多家媒体报道称卓驭首次完整公布九大合作客户,包括上述车企。截至 2025 年 4 月,成行平台已有 20 余款车型量产,另有 30 多款车型待量产落地。
商用车与重卡客户
公开报道显示,卓驭已启动重卡高速 NOA 项目,合作客户包括:
相关报道称首批重卡车型计划在 2026 年上半年量产。
生态和技术伙伴
公开资料中出现的技术生态伙伴包括:
- 高通:双方基于 Snapdragon Ride 平台推出成行平台智能驾驶方案。
- NVIDIA:媒体报道显示双方围绕下一代集中式计算平台推进合作。
- BlackBerry QNX:卓驭选择 QNX OS for Safety 支撑成行平台相关高阶智能驾驶方案。
产品与技术路线
成行平台
成行平台是卓驭的核心产品,覆盖高速、城市、泊车等高阶辅助驾驶场景。公开资料强调其特点包括:
- 低算力和高性价比;
- 纯视觉或视觉为主的方案;
- 惯导双目、惯导三目、“激目”系统等自研感知方案;
- 支持驾舱一体;
- 可兼容多种芯片与算力平台;
- 可根据车型价位和功能需求配置不同版本。
技术路线判断
卓驭的路线与大疆无人机能力有明显迁移关系:
- 无人机视觉感知能力迁移到车辆感知;
- 机器人状态估计和路径规划能力迁移到智能驾驶;
- 大疆长期形成的硬件成本控制和工程量产能力迁移到车载系统;
- 以较低算力实现可量产辅助驾驶,是其区别于高算力堆料路线的关键卖点。
融资情况
已披露/高可信信息
- 2024 年底前后:多家媒体和工商信息显示,比亚迪、大众、上汽通用五菱等产业方入股卓驭。
- 2025 年 6 月:TechNode 援引 LatePost 称,北汽产投、广汽资本等参与新一轮数亿元人民币融资,卓驭累计融资超过 25 亿元人民币。
- 2025 年 11 月:卓驭宣布获得中国一汽超 36 亿元战略投资,投后估值据报道超过 100 亿元人民币。
传闻/待验证信息
- 2026 年 3 月:多家媒体称卓驭正在推进 Pre-IPO 轮融资,规模约 20 亿元人民币,投前估值约 125 亿元,并计划赴港上市。
- 同期另有媒体报道,沈劭劼在采访中称最快或于 2027 年赴港上市。上市时间、融资进度和估值需以后续招股书或官方公告为准。
竞争位置
卓驭处于中国智能驾驶供应商赛道,竞争对手包括华为乾崑智驾、地平线生态方案、Momenta、轻舟智航、元戎启行、知行科技、福瑞泰克等不同类型玩家。
它的差异化位置主要在:
- 大疆技术背景;
- 视觉和机器人能力;
- 中低成本量产方案;
- 多主机厂客户;
- 与产业资本/主机厂深度绑定。
主要风险与待验证点
- 客户集中和主机厂议价风险:获得车企投资和订单是优势,也可能带来客户路线绑定。
- 技术路线竞争:纯视觉/低成本路线需要持续证明复杂城市和泛化场景能力。
- 独立性与合规风险:原大疆背景带来技术背书,也可能在海外客户和合规审查中形成顾虑。
- 上市节奏不确定:Pre-IPO、港股上市等仍需官方文件确认。
- 高管信息不完整:除沈劭劼、朱露、马陆外,其他高管职责公开度不足。
下一步动作
- 跟踪卓驭是否提交港股招股书;一旦提交,应重点核对收入结构、毛利率、客户集中度、研发费用、关联交易和股权结构。
- 跟踪中国一汽投资后的董事会变化、红旗车型上车节奏和一汽体系内渗透率。
- 跟踪大众、比亚迪、五菱、奇瑞等客户是否扩大定点,判断卓驭是否能从“项目型供应商”升级为“平台型供应商”。
- 跟踪重卡 NOA、无人物流车、Robotaxi 的量产和运营数据,验证其“移动物理 AI”叙事是否能商业化。
来源
- 卓驭官网:https://www.zyt.com/
- 香港科技大学沈劭劼主页:https://ri.hkust.edu.hk/people/shaojie-shen-chenshaojie
- 港科大-大疆联合创新实验室:https://hdji.hkust.edu.hk/
- IT之家,大疆车载启用“卓驭”品牌:https://m.ithome.com/html/776833.htm
- IT之家,大疆车载公众号更名“卓驭”:https://www.ithome.com/0/774/886.htm
- 搜狐汽车,大疆车载正式单飞/早期团队报道:https://www.sohu.com/a/626003551_114877
- 每日经济新闻,比亚迪等入股卓驭科技:https://www.nbd.com.cn/rss/toutiao/articles/3678355.html
- TechNode,卓驭 Pre-IPO 融资和港股上市传闻:https://cn.technode.com/post/2026-03-18/zhuoyu-tech-pre-ipo-funding-hk-ipo/
- TechNode,广汽/北汽等融资报道:https://technode.com/2025/06/09/djis-car-tech-unit-raises-new-funds-from-chinese-automakers-gac-and-baic/
- 财联社/新浪财经,中国一汽超 36 亿元战略投资:https://finance.sina.com.cn/roll/2025-11-21/doc-infycykh8356929.shtml
- IT之家,九大合作客户披露:https://m.ithome.com/html/851989.htm
- 经济观察网,重卡 NOA 和泛自动驾驶拓展:https://www.eeo.com.cn/2026/0105/777048.shtml
- 高通中国,卓驭与高通成行平台方案:https://www.qualcomm.cn/news/releases/2024/04/releases-2024-04-25-1
- BlackBerry QNX 合作报道:https://www.eetrend.com/content/2024/100585616.html
---
layout: post
title: MQB 平台介绍
subtitle: Codex 个人助理沉淀
date: 2026-06-06 05:49:27 -0400
tags:
- 个人助理
- topics
---
来源:notes/topics/automotive_platforms/MQB平台介绍.md
MQB 平台介绍
一句话结论
MQB 是大众集团面向横置发动机车型打造的模块化整车平台架构,核心不是某一个底盘,而是一套把发动机位置、前轴关系、电子电气、生产工艺和零部件接口标准化的工程体系,用来让不同品牌、不同级别车型共享开发和制造基础。
基本定义
- 全称:Modularer Querbaukasten,通常译为“横置发动机模块化平台”或“模块化横置矩阵”。
- 所属方:Volkswagen Group,大众集团。
- 覆盖对象:以横置发动机、前驱或基于前驱扩展的乘用车为主。
- 典型品牌:Volkswagen、Audi、Skoda、SEAT/CUPRA 等。
- 典型车型:大众 Golf、Polo、Passat 部分车型、Tiguan,奥迪 A3,斯柯达 Octavia,SEAT Leon 等。
它解决什么问题
传统汽车平台往往和某一类车型强绑定,车型级别、轴距、动力系统和工厂工艺变化后,开发和制造复用率有限。MQB 的目标是把“必须固定的工程接口”标准化,同时把轴距、轮距、车身长度、高度、座舱布局等可变部分开放出来。
这样做带来三个直接效果:
- 降低开发成本:多个品牌和车型可以共享发动机、变速箱、电子架构、悬架接口、空调系统、座椅骨架等模块。
- 缩短开发周期:新车型不需要从零开始设计整车基础结构。
- 提升规模效应:零部件采购、工厂生产、质量控制和售后体系可以围绕统一接口展开。
核心工程思想
MQB 最重要的标准化点,是把横置发动机安装方向、发动机与前轴之间的相对位置、踏板区域和前部结构等关键几何关系固定下来。只要这些基础接口一致,不同车型就能在同一架构上变化尺寸和定位。
可以把 MQB 理解为:
- 不是“所有车都一样”的平台,而是“关键接口一致、外围参数可调”的平台。
- 不是单一车型底盘,而是跨车型、跨品牌、跨工厂的产品开发方法。
- 不是只服务燃油车,也能兼容混动、插混、天然气等多种动力形式,但其基本逻辑仍围绕横置发动机架构展开。
常见优点
- 成本优势:共享件比例提高,研发和采购成本下降。
- 产品覆盖广:从紧凑型车到中型车、SUV、MPV 都可基于 MQB 派生。
- 技术下放快:高阶安全配置、驾驶辅助、信息娱乐系统可以更快进入大众化车型。
- 制造灵活:同一工厂或相似产线更容易生产不同车型,提高产能利用率。
- 品质一致性:关键结构和零部件标准化后,质量验证和问题复盘更集中。
主要局限
- 平台约束:为了共享接口,车型设计和包装空间必须服从平台边界,极端个性化会受限制。
- 同质化风险:不同品牌、不同车型如果差异化调校不足,驾驶感和产品性格可能趋同。
- 架构代际压力:当行业从燃油车转向纯电动车时,围绕发动机舱和传动系统设计的平台会受到纯电专属平台挑战。
- 系统性风险:共享零部件越多,某个模块出现缺陷时影响范围也可能更大。
与其他大众平台的关系
- MQB:横置发动机车型平台,服务大众集团大量燃油、混动和插混车型。
- MLB:纵置发动机车型平台,多用于奥迪等更高定位车型。
- MEB:纯电动车专属平台,围绕电池包、前后电机和电动车空间布局设计。
- PPE:更高端纯电平台,主要面向奥迪、保时捷等品牌的高端电动车。
产业意义
MQB 代表了传统车企在燃油车时代后期的规模化平台能力:用模块化降低复杂度,用跨品牌复用摊薄成本,再通过调校、设计、配置和品牌定位形成不同车型。它的价值不只在技术本身,也在集团化组织、供应链和制造体系的协同能力。
对研究汽车产业的人来说,MQB 可以作为一个观察样本:传统车企如何用平台化方法提升效率,以及为什么进入电动车时代后,纯电专属平台会成为新的竞争焦点。
下一步动作
- 如果后续研究大众集团或智能电动车平台,可以对比 MQB、MEB、PPE 三类平台的成本结构、适用车型和产业阶段。
- 如果研究某款具体车型,需要区分它使用的是 MQB、MQB A0、MQB Evo 还是其他衍生版本。
来源
- Volkswagen Newsroom: MQB / modular transverse matrix 相关官方资料,https://www.volkswagen-newsroom.com/
- Volkswagen Group 官方资料:大众集团模块化平台和车型平台信息,https://www.volkswagen-group.com/
- Audi 官方技术资料:Audi A3 等 MQB 相关车型信息,https://www.audi-mediacenter.com/
待验证点
- 不同年份、不同地区的同名车型可能使用不同平台或不同 MQB 衍生版本,具体车型需要按车型年和市场单独核查。
---
layout: post
title: 主机厂都要自研芯片了,地平线还值不值得看?
subtitle: Horizon Robotics 2026 Bernstein 研报整理
date: 2026-06-05 06:01:44 -0400
tags:
- 投资研究
- 智能驾驶
- 半导体
- Horizon Robotics
---
本文基于 Bernstein 2026 年 6 月 2 日发布的地平线机器人研报整理,只使用原报告第 1-6 页信息,不包含第 7 页及之后内容。本文仅作个人研究和阅读记录,不构成投资建议。
地平线机器人最近的股价压力,本质上来自两个问题。
第一个问题是:越来越多车企要自研智能驾驶芯片,地平线这种第三方芯片公司会不会被挤出去?
第二个问题是:2026 年中国汽车销售偏弱,地平线自己给出的高增长目标还能不能实现?
Bernstein 的结论比较明确:短期股价可能继续受情绪压制,但长期逻辑没有被破坏。它维持地平线“跑赢大盘”评级,目标价 10 港元。按照 2026 年 6 月 1 日 5.43 港元的收盘价,对应约 84% 上行空间。
这篇文章想讨论的不是目标价本身,而是这份报告背后的核心判断:主机厂自研芯片不是地平线的终局风险,更像是商业模式从“卖芯片”扩展到“卖 IP、收 royalty、绑定生态”的过程。
一、第三方芯片不会消失,只是客户结构会变
市场最担心的,是比亚迪、理想、小鹏、蔚来、特斯拉、华为,以及未来可能加入的吉利、小米,都在做自己的智能驾驶芯片。
乍看之下,这对地平线不利。因为如果主机厂都自己做芯片,第三方供应商的市场自然会被压缩。
但报告里有一个很关键的判断:自研芯片只适合少数有规模、有软件能力、有工程组织能力的公司。对大多数车企而言,第三方芯片仍然是更现实的选择。
原因有三点。
第一,人才和组织能力不容易补。智能驾驶芯片不是单纯买一批工程师就能做出来的业务,它需要芯片、AI、软件、车规工程、量产交付一起配合。传统车企要和优秀 AI 创业公司争顶尖人才,并不容易。
第二,规模经济很硬。报告提到,当年产量低于约 150 万辆时,自研芯片在经济上并不划算。地平线管理层还提到,公司今年芯片出货预计超过 500 万颗,而很少有单一中国车企能在一个平台上达到这个规模。
第三,技术曲线还在快速变陡。智能驾驶正在从 L2++ 走向 L3,从端到端走向 VLA、世界模型。算力需求、算法路线、工程方法都在快速变化。这个阶段自研,不像成熟发动机或变速箱时代那样,可以把资本开支和 know-how 在多年里缓慢摊销。
所以更可能出现的局面不是“自研芯片完全替代第三方芯片”,而是“头部车企部分自研,中长尾车企继续依赖第三方供应商”。
二、地平线真正想讲的故事,是 ARM + Android
地平线管理层这次把商业模式概括为“ARM + Android”。
这比过去市场理解的“Windows + Intel”更重要。
如果是“Windows + Intel”,大家会更关注地平线能卖多少颗 Journey 芯片,芯片 ASP 和毛利率是多少。
但如果是“ARM + Android”,逻辑就变了。地平线不仅可以卖标准芯片和软件,也可以把底层 BPU IP 授权给车企,让客户基于它开发自己的芯片,并在量产后按部署量向地平线支付 royalty。
大众 CARIZON 合资公司就是报告里提到的例子。管理层说,类似安排不止大众一家,对海外品牌尤其有吸引力。
这个模式有两个收入来源。
一是一次性 IP 授权费。客户获得底层 IP 后,可以开发自己的芯片。大众相关条款每三年重新谈判一次,新增加的 IP 会单独收费。
二是 royalty。客户自研芯片进入量产后,地平线可以从主机厂内部芯片结算价格中按比例收费。管理层称这部分毛利率超过 90%,接近纯利润。
这意味着,即使一些车企名义上“自研芯片”,也不等于地平线被踢出局。只要底层 BPU 来自地平线,算法和软件生态仍然很可能围绕地平线展开。
报告里有一句判断很值得重视:BPU 定义 AI 性能,而智能驾驶算法层会从地平线生态中生长出来。把 NVIDIA 生态上的算法迁移到 BPU 并不容易。反过来,基于地平线 BPU 的自研芯片,也天然更可能继续运行地平线的 HSD。
这就是地平线试图建立的护城河:硬件是入口,IP 是底座,软件和生态才是长期黏性。
三、2026 年不是不增长,而是“前低后高”
另一个短期担忧,是 2026 年交付节奏。
报告提到,中国汽车行业 2026 年上半年偏弱,前四个月国内汽车销量下降 20%,5 月可能也偏软。市场因此担心地平线约 60% 的年化增长目标会不会太激进。
管理层的解释是:2026 年会“前低后高”,但这个“低”是相对于 60% 年化增长目标而言,不是业务下滑。
也就是说,上半年增长可能低于 60%,但相对行业仍然是很高的增长。
从投资跟踪角度看,2026 年销量主要由已经获得的定点决定,所以短期盈利低于预期的风险相对有限。真正更重要的前瞻指标,是 2026 年下半年新增定点的数量和质量。因为这些定点会决定 2027 年及以后的出货。
这也是为什么报告认为,市场现在盯着短期汽车销量和主机厂自研新闻,可能低估了下半年定点周期带来的正向变化。
四、华为和车企自研会拿走一部分市场,但不是全部
地平线管理层并不否认华为会成功。相反,报告写得很直接:地平线预计华为会在中国汽车市场取得显著份额。
但问题在于,中国乘用车市场不是只由少数头部玩家组成。
管理层粗略估计,任何单一中国主机厂集团的上限大约是 400 万至 500 万辆。再把其他自研芯片主机厂加总,大约还有 300 万至 400 万辆。也就是说,中国约 2500 万辆乘用车市场里,大约 800 万辆,或者 30% 至 40%,可能是地平线难以触达的市场。
反过来看,仍然有约 60% 的长尾市场会继续向第三方方案开放。地平线要竞争的,是这部分市场里的 NVIDIA、Qualcomm 和其他新兴供应商。
这对地平线不是一个轻松的市场,但也不是一个消失的市场。管理层的目标是在这部分长尾市场取得超过 50% 份额。
报告还用地平线过去的份额变化做了一个类比:2022 年 Mobileye 占主导时,地平线 ADAS 份额只有约 4% 至 5%;三年后,地平线在中国供应商中达到约 50% 份额。中高端市场去年是量产第一年,份额约 14% 至 15%,今年一季度还有小幅提升。
这个类比想表达的是:只要中国替代方案足够可信,外资供应商通常会在几年内从主导位置退到少数位置。
五、这份报告里最值得警惕的一句话
虽然 Bernstein 整体偏乐观,但报告里也有一个很重要的保留意见。
管理层认为,IP 授权不会稀释盈利能力,因为前置授权费毛利率接近 100%,royalty 又接近纯利润。即使单车收入下降,净利润率也不应显著变化。
但 Bernstein 自己补了一句:在 IP 授权模式下,单车绝对毛利仍会下降。
这句话很重要。
因为市场最终不只看毛利率,还看单车经济性和总利润池。如果地平线从“直接卖芯片”变成“授权 IP + 收 royalty”,利润率可能好看,但每辆车贡献的绝对毛利可能下降。只有当授权覆盖的量足够大、软件附着足够强、royalty 条款足够稳定,这个模式才会真正好看。
所以,IP 模式不是无条件利好。它更像一个防守反击工具:当车企一定要自研时,地平线至少还能保留底层 IP 和生态入口。但如果越来越多客户只拿底层 IP,不买上层软件和完整方案,那地平线的长期利润池仍会被重新压缩。
这也是后续最该跟踪的风险。
六、接下来应该看什么
如果把这份报告压缩成几个跟踪指标,我会看五件事。
第一,看 Journey 6M 和 Journey 6P 的真实出货。J6M 是 2026 年主力放量产品,可以运行入门级城市 NOA;J6P 则对应完整规格 HSD。它们分别代表地平线在大众市场和高阶市场的渗透能力。
第二,看 2026 年下半年的新定点。管理层说 2026 年客户名单相对清晰,最大的管线变化会出现在 2026 年下半年到 2027 年初。新增定点比短期销量更能代表 2027 年之后的趋势。
第三,看 IP 授权和 royalty 的披露。尤其要看授权客户数量、royalty 计费方式、量产节奏,以及单车绝对毛利是否真的能被规模补回来。
第四,看 HSD 软件的绑定能力。如果客户基于地平线 BPU 自研芯片,但仍然运行 HSD,那么地平线的生态逻辑成立。如果客户只买底层 IP,自研上层软件,那么地平线的议价能力会弱很多。
第五,看海外进展。报告认为,地平线目前首先会服务海外 ADAS,纯海外客户面向海外市场的大规模量产不会早于 2028 至 2029 年。海外不是短期爆发点,但会影响长期天花板。
结语
地平线现在的核心矛盾,不是“主机厂自研芯片来了,所以第三方芯片公司没价值了”。
更准确的说法是:智能驾驶芯片行业正在从单一卖硬件,走向硬件、IP、软件、生态共存的阶段。头部车企会自研,一部分市场会被华为和主机厂内部方案拿走,但中长尾车企仍然需要第三方平台。地平线要证明的,是自己不仅能卖芯片,还能像 ARM 一样授权底层 IP,像 Android 一样把开发者和软件生态留在自己周围。
短期看,股价会受汽车销量、交付节奏和自研芯片新闻影响。中期看,关键在 2026 年下半年新定点。长期看,关键在 IP + royalty + HSD 这套模式能不能把单车毛利下降的问题,用更大的部署量和更强的软件黏性补回来。
这才是地平线这家公司接下来最值得观察的地方。
---
layout: post
title: 主机厂都要自研芯片了,地平线还值不值得看?
subtitle: Codex 个人助理沉淀
date: 2026-06-05 05:50:35 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026 Bernstein
---
来源:notes/books/Horizon Robotics 2026 Bernstein/03_公众号版_主机厂自研芯片压力下的地平线.md
主机厂都要自研芯片了,地平线还值不值得看?
本文基于 Bernstein 2026 年 6 月 2 日发布的地平线机器人研报整理,只使用原报告第 1-6 页信息,不包含第 7 页及之后内容。本文仅作个人研究和阅读记录,不构成投资建议。
地平线机器人最近的股价压力,本质上来自两个问题。
第一个问题是:越来越多车企要自研智能驾驶芯片,地平线这种第三方芯片公司会不会被挤出去?
第二个问题是:2026 年中国汽车销售偏弱,地平线自己给出的高增长目标还能不能实现?
Bernstein 的结论比较明确:短期股价可能继续受情绪压制,但长期逻辑没有被破坏。它维持地平线“跑赢大盘”评级,目标价 10 港元。按照 2026 年 6 月 1 日 5.43 港元的收盘价,对应约 84% 上行空间。
这篇文章想讨论的不是目标价本身,而是这份报告背后的核心判断:主机厂自研芯片不是地平线的终局风险,更像是商业模式从“卖芯片”扩展到“卖 IP、收 royalty、绑定生态”的过程。
一、第三方芯片不会消失,只是客户结构会变
市场最担心的,是比亚迪、理想、小鹏、蔚来、特斯拉、华为,以及未来可能加入的吉利、小米,都在做自己的智能驾驶芯片。
乍看之下,这对地平线不利。因为如果主机厂都自己做芯片,第三方供应商的市场自然会被压缩。
但报告里有一个很关键的判断:自研芯片只适合少数有规模、有软件能力、有工程组织能力的公司。对大多数车企而言,第三方芯片仍然是更现实的选择。
原因有三点。
第一,人才和组织能力不容易补。智能驾驶芯片不是单纯买一批工程师就能做出来的业务,它需要芯片、AI、软件、车规工程、量产交付一起配合。传统车企要和优秀 AI 创业公司争顶尖人才,并不容易。
第二,规模经济很硬。报告提到,当年产量低于约 150 万辆时,自研芯片在经济上并不划算。地平线管理层还提到,公司今年芯片出货预计超过 500 万颗,而很少有单一中国车企能在一个平台上达到这个规模。
第三,技术曲线还在快速变陡。智能驾驶正在从 L2++ 走向 L3,从端到端走向 VLA、世界模型。算力需求、算法路线、工程方法都在快速变化。这个阶段自研,不像成熟发动机或变速箱时代那样,可以把资本开支和 know-how 在多年里缓慢摊销。
所以更可能出现的局面不是“自研芯片完全替代第三方芯片”,而是“头部车企部分自研,中长尾车企继续依赖第三方供应商”。
二、地平线真正想讲的故事,是 ARM + Android
地平线管理层这次把商业模式概括为“ARM + Android”。
这比过去市场理解的“Windows + Intel”更重要。
如果是“Windows + Intel”,大家会更关注地平线能卖多少颗 Journey 芯片,芯片 ASP 和毛利率是多少。
但如果是“ARM + Android”,逻辑就变了。地平线不仅可以卖标准芯片和软件,也可以把底层 BPU IP 授权给车企,让客户基于它开发自己的芯片,并在量产后按部署量向地平线支付 royalty。
大众 CARIZON 合资公司就是报告里提到的例子。管理层说,类似安排不止大众一家,对海外品牌尤其有吸引力。
这个模式有两个收入来源。
一是一次性 IP 授权费。客户获得底层 IP 后,可以开发自己的芯片。大众相关条款每三年重新谈判一次,新增加的 IP 会单独收费。
二是 royalty。客户自研芯片进入量产后,地平线可以从主机厂内部芯片结算价格中按比例收费。管理层称这部分毛利率超过 90%,接近纯利润。
这意味着,即使一些车企名义上“自研芯片”,也不等于地平线被踢出局。只要底层 BPU 来自地平线,算法和软件生态仍然很可能围绕地平线展开。
报告里有一句判断很值得重视:BPU 定义 AI 性能,而智能驾驶算法层会从地平线生态中生长出来。把 NVIDIA 生态上的算法迁移到 BPU 并不容易。反过来,基于地平线 BPU 的自研芯片,也天然更可能继续运行地平线的 HSD。
这就是地平线试图建立的护城河:硬件是入口,IP 是底座,软件和生态才是长期黏性。
三、2026 年不是不增长,而是“前低后高”
另一个短期担忧,是 2026 年交付节奏。
报告提到,中国汽车行业 2026 年上半年偏弱,前四个月国内汽车销量下降 20%,5 月可能也偏软。市场因此担心地平线约 60% 的年化增长目标会不会太激进。
管理层的解释是:2026 年会“前低后高”,但这个“低”是相对于 60% 年化增长目标而言,不是业务下滑。
也就是说,上半年增长可能低于 60%,但相对行业仍然是很高的增长。
从投资跟踪角度看,2026 年销量主要由已经获得的定点决定,所以短期盈利低于预期的风险相对有限。真正更重要的前瞻指标,是 2026 年下半年新增定点的数量和质量。因为这些定点会决定 2027 年及以后的出货。
这也是为什么报告认为,市场现在盯着短期汽车销量和主机厂自研新闻,可能低估了下半年定点周期带来的正向变化。
四、华为和车企自研会拿走一部分市场,但不是全部
地平线管理层并不否认华为会成功。相反,报告写得很直接:地平线预计华为会在中国汽车市场取得显著份额。
但问题在于,中国乘用车市场不是只由少数头部玩家组成。
管理层粗略估计,任何单一中国主机厂集团的上限大约是 400 万至 500 万辆。再把其他自研芯片主机厂加总,大约还有 300 万至 400 万辆。也就是说,中国约 2500 万辆乘用车市场里,大约 800 万辆,或者 30% 至 40%,可能是地平线难以触达的市场。
反过来看,仍然有约 60% 的长尾市场会继续向第三方方案开放。地平线要竞争的,是这部分市场里的 NVIDIA、Qualcomm 和其他新兴供应商。
这对地平线不是一个轻松的市场,但也不是一个消失的市场。管理层的目标是在这部分长尾市场取得超过 50% 份额。
报告还用地平线过去的份额变化做了一个类比:2022 年 Mobileye 占主导时,地平线 ADAS 份额只有约 4% 至 5%;三年后,地平线在中国供应商中达到约 50% 份额。中高端市场去年是量产第一年,份额约 14% 至 15%,今年一季度还有小幅提升。
这个类比想表达的是:只要中国替代方案足够可信,外资供应商通常会在几年内从主导位置退到少数位置。
五、这份报告里最值得警惕的一句话
虽然 Bernstein 整体偏乐观,但报告里也有一个很重要的保留意见。
管理层认为,IP 授权不会稀释盈利能力,因为前置授权费毛利率接近 100%,royalty 又接近纯利润。即使单车收入下降,净利润率也不应显著变化。
但 Bernstein 自己补了一句:在 IP 授权模式下,单车绝对毛利仍会下降。
这句话很重要。
因为市场最终不只看毛利率,还看单车经济性和总利润池。如果地平线从“直接卖芯片”变成“授权 IP + 收 royalty”,利润率可能好看,但每辆车贡献的绝对毛利可能下降。只有当授权覆盖的量足够大、软件附着足够强、royalty 条款足够稳定,这个模式才会真正好看。
所以,IP 模式不是无条件利好。它更像一个防守反击工具:当车企一定要自研时,地平线至少还能保留底层 IP 和生态入口。但如果越来越多客户只拿底层 IP,不买上层软件和完整方案,那地平线的长期利润池仍会被重新压缩。
这也是后续最该跟踪的风险。
六、接下来应该看什么
如果把这份报告压缩成几个跟踪指标,我会看五件事。
第一,看 Journey 6M 和 Journey 6P 的真实出货。J6M 是 2026 年主力放量产品,可以运行入门级城市 NOA;J6P 则对应完整规格 HSD。它们分别代表地平线在大众市场和高阶市场的渗透能力。
第二,看 2026 年下半年的新定点。管理层说 2026 年客户名单相对清晰,最大的管线变化会出现在 2026 年下半年到 2027 年初。新增定点比短期销量更能代表 2027 年之后的趋势。
第三,看 IP 授权和 royalty 的披露。尤其要看授权客户数量、royalty 计费方式、量产节奏,以及单车绝对毛利是否真的能被规模补回来。
第四,看 HSD 软件的绑定能力。如果客户基于地平线 BPU 自研芯片,但仍然运行 HSD,那么地平线的生态逻辑成立。如果客户只买底层 IP,自研上层软件,那么地平线的议价能力会弱很多。
第五,看海外进展。报告认为,地平线目前首先会服务海外 ADAS,纯海外客户面向海外市场的大规模量产不会早于 2028 至 2029 年。海外不是短期爆发点,但会影响长期天花板。
结语
地平线现在的核心矛盾,不是“主机厂自研芯片来了,所以第三方芯片公司没价值了”。
更准确的说法是:智能驾驶芯片行业正在从单一卖硬件,走向硬件、IP、软件、生态共存的阶段。头部车企会自研,一部分市场会被华为和主机厂内部方案拿走,但中长尾车企仍然需要第三方平台。地平线要证明的,是自己不仅能卖芯片,还能像 ARM 一样授权底层 IP,像 Android 一样把开发者和软件生态留在自己周围。
短期看,股价会受汽车销量、交付节奏和自研芯片新闻影响。中期看,关键在 2026 年下半年新定点。长期看,关键在 IP + royalty + HSD 这套模式能不能把单车毛利下降的问题,用更大的部署量和更强的软件黏性补回来。
这才是地平线这家公司接下来最值得观察的地方。
---
layout: post
title: Horizon Robotics 2026 Bernstein 全文翻译
subtitle: Codex 个人助理沉淀
date: 2026-06-05 05:26:10 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026 Bernstein
---
来源:notes/books/Horizon Robotics 2026 Bernstein/02_全文翻译.md
Horizon Robotics 2026 Bernstein 全文翻译
来源:notes/books/Horizon Robotics 2026 Bernstein/source_materials/pdf_full_text.md
原始报告:Bernstein, Horizon Robotics: Near-term pressure due to OEM in-house chip deployment, but long-term thesis is intact, 2026-06-02。
说明:本文为用户提供 PDF 的中文翻译稿,仅供个人阅读与研究,不构成投资建议。
元数据
- 标题:地平线机器人:主机厂自研芯片部署带来短期压力,但长期投资逻辑仍然完好
- 作者:Qingyuan Lin
- 主题:公司更新
- 创建时间:2026 年 6 月 2 日
- 页数:14 页
第 1 页
2026 年 6 月 2 日
中国半导体
Qingyuan Lin, Ph.D.
+852 2123 2654
qingyuan.lin@bernsteinsg.com
Horizon Robotics
Francis Ma
+852 2123 2626
francis.ma@bernsteinsg.com
评级:跑赢大盘
目标价:9660.HK,HKD 10.00
地平线机器人:主机厂自研芯片部署带来短期压力,但长期投资逻辑仍然完好
地平线机器人的股价近期承压。市场正在消化两个担忧:一是主机厂积极部署自研智能驾驶芯片,二是在汽车销售疲弱背景下,市场对 2026 年交付目标产生疑虑。2026 年 5 月 29 日,地平线 CFO 在一场线上投资者交流会上回应了投资者担忧。公司当天还执行了 2200 万股的股票回购。
我们同意公司的观点:投资者不应让短期波动压倒仍然完好的长期逻辑。我们认为,由于市场情绪影响,股价短期可能仍会相对低迷,但从 12 个月视角看,我们维持“跑赢大盘”评级。
第三方智能驾驶芯片对大多数主机厂而言仍是最佳选择。首先,大多数主机厂缺乏相关能力。传统主机厂很难与前景良好的 AI 创业公司竞争,吸引并留住顶尖 AI 和芯片人才。其次,年产量低于约 150 万辆时,自研芯片在经济上并不可行。比亚迪的 4nm 玄玑 A3 芯片,单芯片 700 TOPS,加入了理想、小鹏、蔚来、特斯拉、华为等自研芯片阵营;吉利和小米也可能开发自己的芯片。但我们一直认为,自研芯片和第三方芯片会共存,剩余市场对第三方供应商而言仍然足够大。
展望未来,随着技术栈仍在快速演进,从 L2++ 到 L3,从端到端到世界模型,问题在于主机厂是否能足够快地升级以跟上变化。我们提醒,相关壁垒可能被低估了。
IP 授权创造了替代性商业机会。追求自研芯片的主机厂,仍然可能从地平线获得 IP 授权。大众通过 CARIZON 合资公司就是一个例子;管理层表示,公司也与其他几家主机厂有类似安排,这对海外品牌尤其有吸引力。CFO 将其描述为类似 ARM 的模式:一次性 IP 授权费,加上按部署量收取的 royalty,毛利率约为 90% 以上。然而,市场已经把这部分市场视为地平线不可触达市场,我们认为这种判断过度了。
近期盈利低于预期的风险有限;未来定点可能带来正向惊喜。2026 年销量在很大程度上取决于已经获得的定点。管理层表示,2026 年相对于其约 60% 的年化增长目标而言,会呈现“前低后高”的节奏,但公司仍有信心实现目标。更好的前瞻指标,是 2026 年下半年新增定点的数量和质量,因为这些定点将驱动 2027 年及以后的销量。许多中型主机厂仍然需要第三方城市 NOA 芯片,地平线仍然处于捕捉这一需求的最佳位置。
市场和估值数据
- 收盘日期:2026 年 6 月 1 日
9660.HK 收盘价:HKD 5.43- 目标价:
HKD 10.00
- 上行/下行空间:
84%
- 52 周区间:
HKD 11.32 / 5.07
- ASIAX:
2,010.20
- 财年结束月份:12 月
- 股息收益率:不适用
- 市值:
HKD 79,244mn
- 企业价值:
HKD 48,860mn
股价表现:
- 年初至今:
-37.3%
- 1 个月:
-25.1%
- 6 个月:
-32.4%
- 12 个月:
-23.7%
- ASIAX 同期表现:年初至今
22.9%,1 个月 9.4%,6 个月 25.5%,12 个月 47.5%
- 相对表现:年初至今
-60.2%,1 个月 -34.6%,6 个月 -57.9%,12 个月 -71.2%
来源:Bloomberg、Bernstein 估算与分析。
每股收益和估值:
- 2024A 报告 EPS:
RMB 0.51
- 2025E 报告 EPS:
RMB -0.81
- 2026E 报告 EPS:
RMB -0.25
- 2024A 调整后 EPS:
RMB 0.51
- 2025E 调整后 EPS:
RMB -0.81
- 2026E 调整后 EPS:
RMB -0.25
- 2025E EPS 增长:
-258.8%
- 2026E EPS 增长:
69.0%
- 2024A EV/Sales:
20.5x
- 2025E EV/Sales:
13.0x
- 2026E EV/Sales:
8.3x
- 2024A 报告 P/E:
10.6x
- 2025E 报告 P/E:
-6.7x
- 2026E 报告 P/E:
-21.7x
请参阅本报告披露附录中的必要披露、分析师认证及其他重要信息。也可访问我们的全球研究披露网站。
首次发布:2026 年 6 月 1 日 21:30 UTC
完成时间:2026 年 6 月 1 日 14:32 UTC
第 2 页
炉边谈话会议纪要
管理层对地平线长期逻辑表达了坚定信心。核心信息是:主机厂自研芯片开发并不构成对地平线可触达市场的重大威胁,它更像是商业模式变化和利润重新分配。
地平线拥有类似 ARM 的灵活商业模式,即 IP 授权加 royalty。2026 年会呈现“上半年低、下半年高”的节奏,但这是相对于公司自己约 60% 的年化增长目标而言,并不是业务收缩。
商业模式:ARM + Android
这一框架此前被描述为“Windows + Intel”。
地平线的标准化客户赋能沿两条路径展开:
- 标准化芯片加软件,例如 Journey 6P 芯片配套 HSD 智能驾驶软件。
- 底层 IP 授权。BPU 核心可以单独授权。
针对市场对客户侧芯片自研的担忧,管理层以大众 CARIZON 合资公司作为示例。其经济模式与 ARM 类似。
一次性 IP 授权费:客户获得底层 IP,并开发自己的芯片,类似 ARM 向 Apple 授权 CPU IP。有时是一次性收费,有时是持续收费。对于大众,IP 条款每三年重新谈判一次;新增加的 IP 不在此前框架内,会单独收费,类似会员费或入场费。
Royalty:一旦客户自研芯片进入量产,地平线会从主机厂内部芯片结算价格中按比例收取费用,毛利率超过 90%,实质上接近纯利润。
管理层强调,IP 路径不会稀释盈利能力。IP 授权长期以来就是重要收入来源,单位经济性有吸引力;royalty 流接近纯毛利,因此混合毛利结构非常接近 ARM。
硬件在结构上是多供应来源。汽车行业历史上不会对重大零部件采用单一供应。主机厂会把自研芯片作为战略优先事项,同时维持第三方供应,以便进行基准测试、获得定价杠杆和备用方案。这类似于手机厂商同时运行自研芯片和 Qualcomm 芯片。
地平线供应 BPU,也就是 AI 核心。BPU 定义 AI 性能;在其之上,客户既可以构建接近 Journey 6P 规格的专用智能驾驶芯片,也可以构建接近地平线 Starry 座舱智驾一体化芯片规格的一体化芯片。
行业现在有三条供应链:
- NVIDIA 加软件合作伙伴。
- 地平线加其软件。
- 主机厂自研芯片加自研软件。
决定性逻辑在于:由于 BPU 定义 AI,智能驾驶算法层会从地平线生态中生长出来。把 NVIDIA 生态的算法移植到 BPU 上非常困难。因此,基于地平线 BPU 构建的自研芯片,很可能运行 HSD。即便主机厂授权底层 IP 并构建自己的软件,它仍然处在地平线生态之内。无论你横向切还是纵向切,都无法把地平线切出去。利润池会因合作模式变化而重新分配,但地平线的存在仍会保留。
Journey 6M:没有看到销量受到影响的迹象;它仍然是 2026 年的主力放量产品。Journey 6M 可以运行入门级城市 NOA,相比 Journey 6P 的完整规格 HSD,干预更多、MPI 更低,但能通过监管门槛,并提供可接受的消费者体验。Journey 6P 仍然是完整规格 HSD 平台。
座舱 OS 进展:KakaClaw
与几家一线国内客户的适配和联合开发进展顺利。地平线不是软件交付公司,因此项目能力有限,只有第一批旗舰客户会获得地平线出资的工程资源。该模式有意保持灵活:它不绑定地平线芯片,座舱 OS 可以运行在 Qualcomm 上。座舱应用与硬件的耦合程度低于智能驾驶软件。如果硬件预融合验证周期较长,纯软件采用可以推进得更快。管理层指出,座舱 OS 的核心能力已经开始体现在客户产品中。
2026 年指引:上半年低,下半年高
行业在 2026 年上半年疲弱。国内汽车销量前四个月下降 20%,5 月可能也偏软。
“前低后高”的表述是相对于地平线自己约 60% 的年化增长目标而言。上半年会低于 60%,但相对行业仍是非常高的增长。这不是下滑。
第 3 页
管理层称赞比亚迪近期活动的“开创性”表述,并指出,智能驾驶在大众市场细分领域的激进普及会扩大整体蛋糕。蛋糕更大了;地平线的份额不是被切掉,而是被新模式重新塑形。
海外方面:今年产量没有显著下降,受到“中国制造、全球销售”趋势支持。ADAS 数据表现良好,并有出口贡献。目前只有两家公司能够服务大规模全球出口:Mobileye 和地平线。地平线将首先服务海外 ADAS,之后再追求高端市场。纯海外客户服务海外市场的大规模量产不会早于 2028 至 2029 年。
问答要点
Starry 座舱智驾一体化芯片
主机厂意愿很强,并且有清晰的降本逻辑:减少一套 PMIC 和被动元件,减小 PCB 面积;从双盒到单盒的转变可以去掉铝壳,节省数百元人民币,还可以去掉液冷板等。推进节奏取决于主机厂产品周期和内部部门整合。软件上车会快于硬件;今年首个量产硬件客户会形成标杆效应。
定价压力
对价格传导的担忧应与保险数据一起平衡看待。地平线 AD 市占率正在逆周期上升,环比提升 2 至 3 个百分点,同比提升 4 至 5 个百分点。竞争结构并不差;份额正在从 NVIDIA 和外资供应商手中取得,而主机厂自研项目尚未形成规模。当它们形成规模时,地平线将通过 IP 和 royalty 捕捉经济利益。真正需要关注的是芯片规格是否停止提升。如果到那时规格不再持续提升,主机厂可能只授权底层 IP,并自行开发上层栈。软件是核心,硬件是载体。
Momenta 可能自研芯片的影响
行业已经有三条供应链;开启第四条非常困难,而且新进入者的时机已经偏晚。一个软件公司如果自研芯片,就会成为 NVIDIA 和 Qualcomm 的竞争者,并可能面临自我蚕食效应:要么自有芯片出货有限,要么与 NVIDIA 和 Qualcomm 的关系恶化。无论哪种情况,可触达总市场都是有限的;成功必须在正面竞争中证明。
自研开发的理由
需要区分情形 A 和情形 B。情形 A 是自研尝试仅由能力驱动;情形 B 是能力加经济或战略理由共同驱动。管理层估计,主机厂真正成功自研的概率约为 10%,这一判断由三道壁垒支撑。
第一,规模。规模经济很重要。地平线预计今年芯片出货超过 500 万颗;很少有中国主机厂在单一平台基础上超过这一规模。
第二,软件。“软件定义芯片”。软件是主导性的、隐性的差异化因素。许多主机厂都使用 NVIDIA 芯片,但只有一两家公司在软件上执行得好。管理层将其类比为 CATL 的隐性制造 know-how,也就是在“端到端”或“VLA”等标签之下,由数千项工程实践组成的训练和调参纪律,也就是所谓模型调优的“炼丹”。
第三,行业曲线变得更陡。年度算力增长约 5 至 10 倍,加上算法持续演进,从端到端到 VLA,再到世界模型,使得自研比传统发动机和变速箱的历史类比更难。传统发动机和变速箱行业当时已经放缓,资本开支可以在多年中摊销。
底线是:成功需要规模、软件深度和真正的科技公司 DNA。谁成功了,谁就是中国版 Tesla Junior;谁没有成功,我们仍然是他们的第三方供应商。
海外定点
纯海外客户仍然困难;2026 年上半年受益于“中国制造、全球销售”。纯海外服务海外市场的大规模量产不会早于 2028 至 2029 年。
第 4 页
单车经济性:IP 授权 vs 直接销售 J6
直接芯片销售目标毛利率为 40% 至 50%,按硬件层面管理。IP 前置授权费按约 100% 毛利率确认,地平线倾向于把生命周期收入前置。Royalty 是有意义的比例,且为纯利润。单车收入会下降,但这种变化是利润重新分配;净利润率水平不应显著变化。
注意:这是管理层的说法。我们自己的观点是,在 IP 授权模式下,单车绝对毛利仍会下降。
与华为竞争
管理层并不认为华为不能成功。地平线预计华为将在中国汽车市场取得显著份额。不过,管理层粗略估计,任何单一中国主机厂集团的上限约为 400 万至 500 万辆,这受到 SKU 增多以及集团内部不同细分车型互相蚕食的限制。把其他所有自研芯片主机厂加总,还有约 300 万至 400 万辆。中国约 2500 万辆乘用车市场中,这意味着大约 800 万辆,也就是 30% 至 40% 的市场,是地平线无法触达的;还有约 60% 的长尾市场,地平线将在其中与 NVIDIA、Qualcomm 和新兴竞争者竞争。管理层目标是在这部长尾市场取得超过 50% 的份额。
管理层引用地平线历史份额轨迹作为验证:2022 年,当时 Mobileye 占主导,地平线 ADAS 份额约为 4% 至 5%;三年内,地平线在中国供应商中达到约 50% 份额。中高端市场去年是量产第一年,份额约为 14% 至 15%,一季度又有小幅提升。一旦可信的中国替代方案出现,外资供应商通常会在几年内退居少数地位。
HSD 销量
2026 年客户名单已经相对清晰。管理层不评论单个主机厂畅销车型的动态。高增长仍是框架。等下半年定点周期结束后,前瞻指引会更清晰,最大的管线变化在 2026 年下半年至 2027 年初。
第 5 页
投资含义
地平线机器人,评级跑赢大盘,目标价 HKD 10:地平线机器人是中国领先的智能驾驶芯片供应商。公司提供有特色的软硬件一体化 ADAS 解决方案,将 SoC 和算法结合,用于 L2、L2+ 和 L2++ ADAS 系统。这种一体化方式使其能够以有竞争力的价格提供高性能芯片和软件。
Bernstein 股票表
截至 2026 年 6 月 1 日:
- 标的:
9660.HK,地平线机器人
- 评级:跑赢大盘
- 货币:港元
- 收盘价:
HKD 5.43
- 目标价:
HKD 10.00
- 相对表现:
-71.2%
- 2024A 报告 EPS:
RMB 0.51
- 2025E 报告 EPS:
RMB -0.81
- 2026E 报告 EPS:
RMB -0.25
- 2024A EV/Sales:
20.5x
- 2025E EV/Sales:
13.0x
- 2026E EV/Sales:
8.3x
ASIAX:2,010.20
评级说明:O = 跑赢大盘,M = 与大盘一致,U = 跑输大盘,NR = 未评级,CS = 暂停覆盖。
来源:Bloomberg、Bernstein 估算与分析。
第 6 页
披露附录
I. 必要披露
本披露中提到的 “Bernstein” 或 “Firm” 指以下实体:Bernstein Institutional Services LLC,2024 年 4 月 1 日起;Sanford C. Bernstein & Co., LLC,2024 年 4 月 1 日前;Bernstein Autonomous LLP;BSG France S.A.,2024 年 4 月 1 日起;Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司;Sanford C. Bernstein (Canada) Limited;Sanford C. Bernstein (India) Private Limited,SEBI 注册号 INH000006378;Sanford C. Bernstein (Singapore) Private Limited;Sanford C. Bernstein Japan KK;以及 Société Générale Africa Technologies & Services 雇用的分析师,这些分析师根据 Bernstein 与 Société Générale 之间的全球服务协议为 Bernstein 研究提供内容。
Bernstein 是 Société Générale 与 AllianceBernstein, L.P. 之间合资企业的一部分。除非另有特别说明,就这些披露而言,Bernstein 的“关联方”同时指 SG 和 AB 及其各自关联方。
估值方法
地平线机器人:
我们给予地平线机器人“跑赢大盘”评级,目标价 HKD 10。该目标价基于公司未来第二预测期,即 2027 年下半年至 2028 年上半年销售额 RMB 11.5bn 的 10.3x 企业价值/销售额倍数。
风险
地平线机器人:
下行风险包括:
- 智能驾驶渗透率提升速度低于预期。
- 主机厂自研获得的份额高于预期。
- 主要客户出货或部署延迟,导致收入增长低于预期。
评级定义、基准和分布
股票评级定义
Bernstein 品牌:
Bernstein 品牌根据未来 12 个月相对于基准指数的预期表现对股票评级。美国和加拿大交易所上市股票相对于 S&P 500;欧洲交易所和亚太以外新兴市场交易所上市股票相对于 Bloomberg Europe Developed Markets Large and Mid Cap Price Return Index EUR;日本交易所上市股票相对于 Bloomberg Japan Large and Mid Cap Price Return Index USD;亚洲日本以外交易所上市股票相对于 Bloomberg Asia ex-Japan Large and Mid Cap Price Return Index,除非另有说明。
Bernstein 品牌有三类评级:
- 跑赢大盘:股票表现预计超过市场指数 15 个百分点以上。
- 与大盘一致:股票表现预计在市场指数正负 15 个百分点以内。
- 跑输大盘:股票表现预计落后市场指数 15 个百分点以上。
暂停覆盖:Bernstein 研究品牌对该公司覆盖已暂停。评级和目标价暂时暂停,不再具有当前性,因此不应依赖。
未评级:当股票目前无法被准确估值,或公司表现无法被准确预测时给出的评级。覆盖分析师仍可继续发布研究报告,以更新投资者有关公司事件和发展的信息。
未覆盖表示公司不在覆盖范围内。
Bernstein 品牌股票评级基于 12 个月时间范围。
Autonomous 品牌普通股:
Autonomous 品牌普通股评级如下。其基准包括 Bloomberg Europe 500 Banks And Financial Services Index、Bloomberg Europe Dev Mkt Financials Large and Mid Cap Price Ret Index EUR、Bloomberg Europe 500 Insurance Index、S&P 500 和 S&P Financials、S5LIFE、S&P Insurance Select Industry,以及 Bloomberg Emerging Markets Financials Large, Mid and Small Cap Price Return Index。评级相对于行业,而非整体市场。
Autonomous 品牌普通股有三类评级:
- 跑赢大盘:股票预计超过相关指数 10 个百分点以上。
- 中性:股票表现预计在市场指数正负 10 个百分点以内。
- 跑输大盘:股票表现预计落后相关指数 10 个百分点以上。
暂停覆盖:Autonomous 研究品牌对该公司覆盖已暂停。评级和目标价暂时暂停,不再具有当前性,因此不应依赖。
未评级:当股票目前无法被准确估值,或公司表现无法被准确预测时给出的评级。覆盖分析师仍可继续发布研究报告,以更新投资者有关公司事件和发展的信息。
标注为 Feature 的股票,例如 Feature Outperform 或 Feature Under Outperform,是我们的核心观点。
未覆盖表示公司不在覆盖范围内。
Autonomous 品牌普通股评级基于 12 个月时间范围。
Autonomous 品牌优先股
Autonomous 品牌优先股有三类评级:
- 跑赢:该优先工具未来六个月总回报预计跑赢相似行业或评级类别中其他发行人的优先证券。
- 中性:该优先工具未来六个月总回报预计与相似行业或评级类别中其他发行人的优先证券一致。
- 跑输:该优先工具未来六个月总回报预计跑输相似行业或评级类别中其他发行人的优先证券。
Autonomous 优先股评级基于 6 个月时间范围。
Autonomous 信用研究
如果本报告包含针对信用工具的投资建议,即欧盟市场滥用条例第 3(1)(35) 条定义的投资建议,则以下信息用于遵守其披露要求。
本报告也可能引用其他 Autonomous 或 Bernstein 分析师对本文提及发行人股本证券发表的观点。请注意,本报告作者发布的信用工具投资建议,可能不同于覆盖该发行人股票证券分析师发布的观点,反之亦然。
第 7 页
信用评级定义
Autonomous 品牌有三类信用评级:
- 信用跑赢:参考信用工具的总回报预计将在未来六个月内跑赢相似行业或评级类别其他发行人的债券信用利差。
- 信用中性:参考信用工具的总回报预计将在未来六个月内与相似行业或评级类别其他发行人的债券信用利差一致。
- 信用跑输:参考信用工具的总回报预计将在未来六个月内跑输相似行业或评级类别其他发行人的债券信用利差。
Autonomous 信用评级基于 6 个月时间范围。
作者所发布的全部投资建议及信用评级历史清单可应要求提供。
公司可自行决定何时启动、更新和终止研究覆盖。公司已建立、维持并依赖信息隔离墙,以控制公司内部一个或多个区域,即私密侧,向其他区域、单位、团队或关联方,即公开侧,传递信息。
股票评级/投行业务服务分布
截至 2026 年 3 月 31 日:
- 跑赢大盘:对应 MAR 和 FINRA 分类为买入,全球评级分布为 51.1%,其中 16.5% 存在投行业务关系。
- 与大盘一致或中性:对应持有,全球评级分布为 36.3%,其中 17.8% 存在投行业务关系。
- 跑输大盘:对应卖出,全球评级分布为 12.6%,其中 14.9% 存在投行业务关系。
这些数字代表在每一股票评级类别中,Bernstein 关联方在过去 12 个月内提供过投行业务服务的公司比例。所有数字每季度更新。
价格图表/评级和目标价历史
地平线机器人 9660.HK Bernstein 评级历史,截至 2026 年 5 月 29 日:
- 初始评级:跑赢大盘,目标价
HKD 15.00,2025 年 9 月 1 日。
- 后续评级:跑赢大盘,目标价
HKD 10.00,2026 年 5 月 11 日。
图表中的所有目标价和收盘价数据均以本报告股票表中注明的货币计价。
第 8 页
其他事项
本报告列出的分析师雇佣实体及所在地,可通过其电话号码国家代码判断:
+1:Bernstein Institutional Services LLC,美国纽约州纽约市。+44:Bernstein Autonomous LLP,英国伦敦。+212:Société Générale Africa Technologies & Services,摩洛哥卡萨布兰卡。+33:BSG France S.A.,法国巴黎。+34:BSG France S.A.,西班牙马德里。+41:Bernstein Autonomous LLP,瑞士日内瓦。+49:BSG France S.A.,德国法兰克福。+91:Sanford C. Bernstein (India) Private Limited,印度孟买。+852:Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司,中国香港。+65:Sanford C. Bernstein (Singapore) Private Limited,新加坡。+81:Sanford C. Bernstein Japan KK,日本东京。
如果本报告由非美国关联方雇佣的研究分析师编制,除非下文另有明确说明,该分析师不是 Bernstein Institutional Services LLC 或其他 SEC 注册经纪交易商的注册关联人员,也没有在 FINRA 注册或取得研究分析师资格。因此,该分析师可能不受 FINRA 关于研究分析师与被覆盖公司沟通、研究分析师与投行业务人员互动、研究分析师参与投行业务招揽和营销活动、公开露面,以及研究分析师账户持有证券交易等限制。
如果本报告由 Société Générale Africa Technologies & Services 雇佣的研究分析师编制,作为 Société Générale 集团公司的一部分,该报告是根据 Bernstein 与 Société Générale 之间的全球服务协议代表 Bernstein 公司编制。
认证
本报告列出的每位主要负责本报告内容的研究分析师均认证:本出版物中表达的所有观点准确反映该分析师本人对相关证券或发行人的个人观点;该分析师的薪酬没有、现在没有、未来也不会直接或间接与本出版物中的具体建议或观点相关。
II. 其他全球冲突披露
公司可自行决定何时启动、更新和终止研究覆盖。公司已建立、维持并依赖信息隔离墙,以控制公司内部一个或多个区域,即私密侧,向其他区域、单位、团队或关联方,即公开侧,传递信息。
III. 其他重要信息和披露
“Bernstein”和“Autonomous”研究产品保持独立品牌。
Bernstein 以 “Autonomous” 和 “Bernstein” 两个品牌生产多种不同类型的研究产品,包括基本面分析和量化分析等。由于时间范围、方法论或其他原因,不同类型研究产品中的建议可能不同。此外,同一类型研究产品在不同品牌下发布的观点或建议也可能不同。前文包含两个品牌评级系统及相关信息。
Autonomous 在以下实体内部作为独立业务单元运营:Bernstein Institutional Services LLC、Bernstein Autonomous LLP、Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司和 Sanford C. Bernstein (India) Private Limited。有关 Autonomous 品牌产品,包括部分销售材料的信息,请访问 www.autonomous.com。有关 Bernstein 品牌产品的信息,请访问 www.bernsteinresearch.com。
分析师薪酬基于其对研究业务整体贡献,包括客户渗透、生产力和投资观点主动性。分析师薪酬不基于投行业务收入表现或贡献。
本报告由欧盟 596/2014 市场滥用条例第 3(1)(34)(i) 条定义的独立分析师编制,英国国内法中保留的同一条款亦适用。
第 9 页
致美国读者
Bernstein Institutional Services LLC 是一家在美国 SEC 注册并为 FINRA 成员的经纪交易商,负责在美国分发本出版物,并对其内容承担责任。如果本材料包含债务产品分析,该材料仅面向机构投资者,不受面向零售投资者债务研究所适用的美国独立性和披露标准约束。
Bernstein Institutional Services LLC 可以以自身账户作为主事人,或作为他人,包括关联方的代理人,买卖本报告主题证券。本报告并不声称满足任何特定个人、实体或账户的目标或需要。
致加拿大读者
如果本出版物涉及一家加拿大注册公司,则由 Sanford C. Bernstein (Canada) Limited 在加拿大分发,该公司受加拿大投资监管组织许可和监管。如果本出版物涉及非加拿大注册公司,则由 Bernstein Institutional Services LLC 根据国际交易商豁免在加拿大分发,该公司同时受 SEC 和 FINRA 许可和监管。
除非接收人符合 NI 31-103 第 1.1 条定义的“许可客户”,否则不得在加拿大将本文件传递给该人。
致巴西读者
本报告由 Bernstein Institutional Services LLC 编制,在巴西由 Banco BTG Pactual S.A. 负责分发。
致英国读者
本出版物在英国由 Bernstein Autonomous LLP 发布或批准发布,该公司由 Financial Conduct Authority 授权和监管,地址为 60 London Wall, London EC2M 5SH,电话 +44 (0)20-7170-5000,英格兰和威尔士注册号 OC343985。
本文件仅分发给以下人士:在《2005 年金融服务与市场法金融推广令》第 19(5) 条所述投资事项方面具有专业经验的人士;属于该令第 49(2)(a) 至 (d) 条所述高净值公司、非法人协会等人士;位于英国境外的人士;或可合法向其传达或促成传达邀请或诱导其从事投资活动的人士。上述人士统称为“相关人士”。本文件仅面向相关人士,不得由非相关人士采取行动或依赖。本文件涉及的任何投资或投资活动仅向相关人士开放,并且只会与相关人士进行。
致欧洲经济区成员国读者
本出版物由 BSG France SA 分发,该公司由法国审慎监管与处置局和法国金融市场管理局授权和监管。
致香港读者
本出版物在香港由 Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司分发,该公司由香港证券及期货事务监察委员会许可和监管,中央编号 AXC846,可进行第 4 类受规管活动,即就证券提供意见,并受 SFC 公开登记册所列许可条件约束。本出版物仅面向《证券及期货条例》第 571 章定义的专业投资者。本报告目的仅为提供对所述发行人的分析,并非意图用于任何违反香港法律的目的。
致新加坡读者
本出版物在新加坡由 Sanford C. Bernstein (Singapore) Private Limited 分发,仅面向《2001 年证券与期货法》定义的认可投资者或机构投资者。新加坡接收人如有与本出版物有关的问题,应联系 Sanford C. Bernstein (Singapore) Private Limited。该公司受新加坡金融管理局监管,并持有资本市场服务牌照,可交易证券和集体投资计划等资本市场产品,同时为豁免财务顾问,可就证券提供建议、发布和传播分析及报告。该公司在新加坡注册,公司注册号 20213710W,地址为 One Raffles Quay, #27-11 South Tower, Singapore 048583,电话 +65-6230-4612。
第 10 页
致中华人民共和国读者
本文件提及的证券没有也不得在中华人民共和国直接或间接发售或出售。就本段而言,中华人民共和国不包括香港特别行政区、澳门特别行政区和台湾。
本文件不构成在中国向任何不得合法接受该要约或招揽的人士发出售卖证券的要约或购买证券的招揽。
我们不声明本文件可以合法分发,也不声明任何证券可以在符合中国适用注册或其他要求的情况下,或根据任何可用豁免,在中国合法发售;我们也不承担促进此类分发或发售的责任。特别是,我们未采取任何行动允许在中国进行任何证券公开发售或分发本文件。因此,证券没有通过本文件或任何其他文件在中国境内发售或出售。除非在符合适用法律法规的情况下,本文件及任何广告或其他发售材料不得在中国分发或发布。
致日本读者
本出版物在日本由 Sanford C. Bernstein Japan KK 分发,该公司在日本注册为金融工具业务运营商,关东财务局登记号为关东财务局长(金商)第 3387 号,并受金融厅监管。该公司也是日本投资顾问协会成员。本出版物仅面向日本《金融商品交易法》第 2 条第 3 款第 1 项定义的合格机构投资者。
对于通过 Daiwa Securities Group Inc. 获得 Bernstein 网站访问权限的日本机构客户,访问本文件不应被理解为 Bernstein 正在为任何目的向其提供投资建议。虽然 Bernstein 编制了本文件,但您的关系现在并将继续与 Daiwa 维持,Bernstein 与您没有合同关系,也不对您承担义务。
致澳大利亚读者
Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司负责在澳大利亚分发研究。该公司受美国法律下的证券交易委员会监管,也受英国法律下的 Financial Conduct Authority 监管,这与澳大利亚法律不同。Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司根据《2001 年公司法》豁免持有澳大利亚金融服务牌照,可向批发客户提供以下金融服务:
- 提供金融产品建议。
- 交易金融产品。
- 为金融产品做市。
- 提供托管或存管服务。
致印度读者
本出版物在印度由 Sanford C. Bernstein (India) Private Limited 分发。该公司受印度证券交易委员会许可和监管,作为研究分析实体注册号为 INH000006378,并作为股票经纪商注册号为 INZ000213537。SCB India 目前从事研究和股票经纪服务。更多信息请参阅 www.bernsteinresearch.in。
SCB India 是根据《2013 年公司法》于 2017 年 4 月 12 日成立的私人有限公司,公司识别号 U65999MH2017FTC293762,注册地址为 Level 3A, 4th Floor, First International Financial Centre, Plot Nos C-54 and C-55, G Block, Near CBI Office, Bandra Kurla Complex, Bandra East, Mumbai 400098, Maharashtra, India,电话 +91-22-68421401。
有关 SCB India 关联方的详情,请发送邮件至 MUM-BERNSTEIN-InCompliance@bernsteinsg.com。
截至本报告日期,SCB India 没有纪律处分历史。
除上文说明外,SCB India 及其关联方、本报告作者研究分析师及其亲属:
- 不持有主题公司的财务利益。
- 不实际或受益拥有主题公司 1% 或以上证券。
- 不从事印度公司的投行业务活动。
- 过去 12 个月未管理或共同管理任何印度公司的公开发行。
- 过去 12 个月未从主题公司获得投行业务或商业银行服务报酬。
- 过去 12 个月未从主题公司获得经纪服务报酬。
- 未因本报告具体建议或观点从主题公司或第三方获得报酬或其他利益。
- 目前不作为、但未来可能作为本报告覆盖公司金融工具的做市商。
- 截至本报告日期,对主题公司不存在利益冲突。
除上文说明外,主题公司在本研究报告分发日前 12 个月内不是 SCB India 的客户。SCB India 及其关联方在过去 12 个月内未从主题公司获得除投行业务、商业银行或经纪服务以外的产品或服务报酬。
编制本报告的主要研究分析师、分析师团队成员及其家庭成员,不是本报告覆盖公司的高级职员、董事、员工或顾问委员会成员。
合规官/申诉官为 Rupal Talati,可通过 +91-22-68421451 或 MUM-BERNSTEIN-InCompliance@bernsteinsg.com / Scbin-investorgrievance@bernsteinsg.com 联系。
SCB India 的研究投资者章程及条款条件可在其网站 Sanford C. Bernstein (India) Private Limited 查看。
免责声明:SEBI 授予注册以及 NISM 认证,并不以任何方式保证中介机构表现,也不向投资者提供收益保证。证券市场投资存在市场风险。投资前请仔细阅读所有相关文件。
第 11 页
致瑞士读者
本文件由 Bernstein Autonomous LLP 在瑞士提供或通过其提供,并仅提供给《瑞士集合投资计划法》第 10 条及相关集合投资计划条例规定定义的合格投资者,且严格遵守适用的瑞士法律法规。本文提到的产品可能不适合所有类型投资者。本文件基于瑞士银行家协会 2008 年 1 月发布的《金融研究独立性指引》。
致中东读者
Bernstein Autonomous LLP DIFC 分支机构主要办公室位于 Gate Village 06, DIFC, Dubai, UAE。Bernstein Autonomous LLP DIFC 分支机构由迪拜金融服务管理局监管,注册号 CL10040,并获准安排投资交易和就金融产品提供建议。所有通信和服务仅面向专业客户和市场对手方。非专业客户和市场对手方,例如零售客户,并非我们通信或服务的目标接收人。
法律
所有研究出版物均通过发布在公司密码保护网站 bernsteinresearch.com 和 autonomous.com 上向客户传播。部分但非全部研究出版物也会通过第三方供应商向客户提供,或通过其他电子方式作为便利重新分发给客户。
本出版物已经按照公司投资研究利益冲突管理政策发布和分发。该政策副本可向 Bernstein Institutional Services LLC 合规董事索取,地址为 245 Park Avenue, New York, NY 10167。关于 Bernstein 业务的其他披露和信息可在 www.bernsteinresearch.com 查看。
本报告描述的证券可能并非在所有司法辖区或面向所有类别投资者均可销售,尤其在这种销售许可与本文所列实体持有牌照不一致的情况下。本文件仅在法律允许的范围内分发。本出版物不面向、也不意图分发给或供任何位于某个地区、州、国家或其他司法辖区的人士或实体使用,如果此类分发、发布、可得性或使用会违反法律法规,或导致本文所述实体或其子公司、关联方需要在该司法辖区注册或取得许可。本出版物基于我们认为可靠的公开来源,但我们不声明本出版物准确或完整。我们不承诺通知您报告信息或观点的任何变化。本出版物由本文所述实体编制并发布,分发给合格对手方或专业客户。本出版物不是买卖任何证券的要约,也不构成投资、法律或税务建议。本文提到的投资可能不适合您。投资者必须结合自身具体情况,在咨询专业顾问后自行作出投资决策。投资价值可能波动,以外币计价的投资也可能因汇率波动而发生价值变化。过往表现不一定是未来表现的指引、指标或保证。
本报告仅面向并意图提供给上述监管机构定义的合格对手方、专业客户、机构投资者和/或专业投资者,不得重新分发给上述监管机构定义的零售客户。收到本报告的零售客户应注意,本文所列实体不向其提供服务,不应依赖本文材料作出投资决策。此类行为造成的损失不会使本文所列实体承担责任,因为这些实体没有注册、授权或获许可与零售客户交易,也不会与零售客户签订合同安排。本报告受客户与本文所列实体之间任何协议条款和条件约束。所有研究报告均通过电子发布到客户门户,同步向符合条件的客户传播。
本报告信息由 Bernstein 编制,仅供客户内部业务使用。客户可以在该有限用途下存储、显示、分析、重新格式化和打印本报告信息。未经 Bernstein 明确书面同意,客户不得出于任何目的复制、修改、创作衍生作品、转售、反向工程、商业利用、分享或分发本文任何部分信息。这些限制包括提取数据或使用内容开发指数或其他产品。此外,未经 Bernstein 明确书面同意,您不得使用本报告或其任何部分训练或微调任何第三方机器学习或人工智能系统,也不得作为此类系统的提示或输入;您也不得在自己的内部机器学习或人工智能系统中进行上述行为。
Bernstein 可能使用人工智能工具准备其材料。任何此类材料在发布前均由 Bernstein 研究分析师审核。
本报告仅为信息目的编制,基于我们认为可靠的当前公开信息,但本文所列实体不明示或暗示保证或声明本文信息或数据来源准确、完整、不具误导性,或适合预期目的。即使本文所列实体依赖声誉良好或可信的数据提供商,也不应将其作为保证。本文观点仅为作者截至材料日期的当前观点,我们不承诺通知您报告信息或观点的变化。
本出版物由本文所述实体编制并发布,分发给合格对手方或专业客户。本文信息用于一般流通,不构成买卖任何证券的要约、投资、法律或税务建议,也不构成上述监管机构定义的个人建议。它没有考虑任何个人投资者的特定投资目标、财务状况或需求。本报告未经过上述监管机构审核,也不代表上述监管机构的任何官方建议。本文提到的投资可能不适合您。接收人在承诺购买投资产品前,应咨询财务顾问,结合其具体投资目标、财务状况或特殊需求,考虑投资产品是否适合。
本文分析基于多项假设。不同假设可能导致重大不同结果。本报告信息不构成、也不属于出售或发行股份的要约、购买或认购股份的要约,或诱导从事任何其他投资活动。本文提到的任何证券或金融工具价值可能随市场状况波动。过往表现不一定是未来表现的指引、指标或保证。研究分析师在本报告中提到的未来表现估计基于可能无法实现的假设,原因包括市场波动等不可预见因素。对于以客户本币以外货币计价的证券或金融工具,汇率变动会对价值产生有利或不利影响。在根据本报告建议采取行动前,接收人应考虑投资本文所述证券或金融工具是否适当,并在必要时寻求独立专业建议。
本报告描述的证券可能并非在所有司法辖区或面向所有类别投资者均可销售,尤其在这种销售许可与本文所列实体持有牌照不一致的情况下。本文件仅在法律允许的范围内分发。它不面向、也不意图分发给或供任何位于某个地区、州、国家或其他司法辖区的人士或实体使用,如果此类分发、发布、可得性或使用会违反法律法规,或导致本文所列实体需要在该司法辖区受到监管或取得许可。
来源:Bloomberg Index Services Limited。BLOOMBERG 是 Bloomberg Finance L.P. 及其关联方的商标和服务标识。Bloomberg 或其许可方拥有 Bloomberg 指数的所有专有权。Bloomberg 或其许可方不批准或认可本材料,也不保证本文任何信息的准确性或完整性,亦不明示或暗示保证由此获得的结果。在法律允许的最大范围内,Bloomberg 或其许可方不对与本文相关的损害承担责任。
未经本文所列实体事先同意,不得复制、分发、传输或以其他方式提供本材料任何部分。版权归 Bernstein Institutional Services LLC、Bernstein Autonomous LLP、BSG France S.A.、Sanford C. Bernstein (Hong Kong) Limited 盛博香港有限公司、Sanford C. Bernstein (Canada) Limited、Sanford C. Bernstein (India) Private Limited、Sanford C. Bernstein (Singapore) Private Limited 和 Sanford C. Bernstein Japan KK 所有。保留所有权利。本文包含的商标和服务标识归其各自所有者所有。任何未经授权的使用或披露均被严格禁止。如未经授权使用导致本文所列实体以及 Bernstein 和 Autonomous 品牌下发布的研究出现诽谤或声誉风险,本文所列实体可采取法律行动。
---
layout: post
title: Horizon Robotics 2026 Bernstein 详细解读
subtitle: Codex 个人助理沉淀
date: 2026-06-05 05:05:30 -0400
tags:
- 个人助理
- 读书笔记
- Horizon Robotics 2026 Bernstein
---
来源:notes/books/Horizon Robotics 2026 Bernstein/01_详细解读.md
Horizon Robotics 2026 Bernstein 详细解读
来源:notes/books/Horizon Robotics 2026 Bernstein/source_materials/pdf_full_text.md
原始文件:Bernstein, Horizon Robotics: Near-term pressure due to OEM in-house chip deployment, but long-term thesis is intact, 2026-06-02。
说明:本文是对研报的中文结构化解读,不构成投资建议。重点是提炼报告的投资逻辑、关键假设、反方风险和后续跟踪动作。
1. 核心结论
Bernstein 认为地平线机器人短期股价受到两个因素压制:主机厂自研智驾芯片的担忧,以及市场对 2026 年交付目标的怀疑。但报告的核心判断是:这些更像短期情绪和商业模式切换压力,而不是长期逻辑被破坏。
报告维持地平线机器人 9660.HK 的 Outperform 评级,目标价 HKD 10.00。报告日收盘价为 HKD 5.43,对应约 84% 上行空间。
这份报告真正有价值的地方,不是目标价本身,而是提供了一个理解“主机厂自研是否会切走第三方供应商价值”的框架。对地平线来说,问题不只是客户会不会自己做芯片,而是客户自研之后,是否仍然需要地平线的 BPU/IP、HSD 软件、工具链、量产经验和生态迁移成本。
2. 报告背景和关键数据
报告发布时间是 2026-06-02,覆盖标的是地平线机器人。
报告日核心数据:
- 收盘价:
HKD 5.43
- 目标价:
HKD 10.00
- 隐含上行空间:约
84%
- 市值:约
HKD 79.2bn
- 企业价值:约
HKD 48.9bn
- 2026E EV/Sales:
8.3x
- 2026E EPS:
-0.25 RMB
这是一篇公司更新,主要回应两个市场担忧:
- 比亚迪、理想、小鹏、蔚来、特斯拉、华为等推进自研芯片,是否会挤压地平线的可服务市场。
- 2026 年车市偏弱,地平线约
60% 年化增长目标是否存在落空风险。
Bernstein 的回答是:短期压力真实存在,但市场把“主机厂自研”简单理解为“地平线出局”,这个判断过于粗糙。
3. 自研芯片不等于地平线被完全切走
报告认为,多数主机厂并不适合独立完成高阶智驾芯片和软件栈。
原因有三类:
第一,规模不够。
报告提到,自研芯片低于约 150 万辆/年 很难具备经济性。地平线预计今年芯片出货 500 万+,多数单一主机厂很难在同一平台上达到类似规模。
第二,软件难度被低估。
智驾不是单纯堆芯片参数。不同公司即使使用相同硬件,最终体验差异也来自算法、调参、数据闭环、工程实践和量产 know-how。报告把这类能力类比为 CATL 的制造隐性知识:外部看是“端到端”“VLA”等标签,内部其实是大量工程细节。
第三,技术曲线仍然很陡。
智驾从 L2++ 到 L3,从端到端到 VLA、world models,算力和算法持续迭代。如果行业还在快速变化,车企自研芯片很难像传统发动机或变速箱那样长期摊销。
管理层估计,真正能成功自研的 OEM 概率大约只有 10%。这个数字可以质疑,但它反映了地平线对行业门槛的判断:成功自研需要规模、软件深度和科技公司 DNA 三者同时具备。
4. 商业模式变化:从卖芯片到 ARM + Android
报告中最重要的框架是管理层把地平线描述为 ARM + Android。
ARM 对应底层 IP:
- 地平线可以授权 BPU 核心。
- 客户可基于 BPU 做自己的专用智驾芯片,或做座舱智驾一体化芯片。
- IP 授权费接近纯毛利。
- 量产后可按内部芯片结算价收取 royalty。
- 报告提到相关 royalty 毛利率可能达到
90%+。
Android 对应软件生态:
- 地平线不仅卖芯片,也提供 HSD 智驾软件。
- 智驾算法和 BPU 生态深度绑定。
- 把 NVIDIA 生态算法迁移到 BPU 难度很高。
- 即使客户做自研芯片,只要底层使用地平线 BPU,就仍然可能留在地平线生态里。
所以,这份报告的防守逻辑是:主机厂自研会改变利润池分配,但不一定把地平线完全切出局。地平线可能从“芯片直接销售”变成“芯片 + 软件 + IP license + royalty”的混合模式。
5. 关键风险:收入、毛利率和绝对毛利不能混为一谈
这份报告最值得警惕的地方,是它对 IP 授权模式的讨论。
管理层强调 IP 授权和 royalty 的毛利率很高,甚至接近 ARM 模式,因此净利润率未必明显恶化。但 Bernstein 自己也提醒:IP 授权模式下,绝对单车毛利可能低于直接销售 J6 芯片。
这意味着后续分析不能只看毛利率。必须拆成三件事:
- 单车收入是否下降。
- 单车绝对毛利是否下降。
- royalty 是否持续、可审计、可规模化。
如果未来地平线更多客户从“购买芯片 + 软件”转向“授权 IP + 自己做芯片”,公司可能出现一个看起来不错但实际弹性下降的状态:毛利率改善,但收入增速和绝对毛利增长变弱。
6. 产品和客户进展
Journey 6M:
- 报告称暂未看到明显销量影响。
- 仍是 2026 年主力放量产品之一。
- 可支持入门级城市 NOA,体验不如 Journey 6P 的完整 HSD,但可满足监管要求并提供可接受消费者体验。
Journey 6P:
- 定位为完整 HSD 平台。
- 更适合高规格城市 NOA 和中高端智驾需求。
Starry 座舱智驾一体化芯片:
- OEM 意愿较强,核心理由是降本。
- 2-box 到 1-box 可减少电源、被动器件、PCB 面积、铝壳和液冷板等成本。
- 第一家量产客户可能形成标杆效应。
KakaClaw 座舱 OS:
- 与部分头部国内客户适配和联合开发推进中。
- 不强绑定地平线芯片,也可以跑在 Qualcomm 上。
- 软件上车速度可能快于硬件。
7. 2026 年节奏:前低后高
管理层称 2026 年是“前低后高”。
报告提到,2026 年上半年中国汽车行业偏弱,前四个月国内汽车销售同比约 -20%,5 月可能也偏软。但管理层强调,这不是地平线业务收缩,而是低于公司约 60% 年化增长目标的节奏。
报告认为 2026 年销量主要来自已获得定点,因此短期业绩 miss 风险有限。真正更前瞻的指标,是 2026 年下半年到 2027 年初新增 design wins 的数量和质量,因为它们决定 2027 年及以后销量。
8. 竞争格局
报告把行业供应链分成三类:
- NVIDIA + 软件伙伴。
- Horizon + 自有软件。
- OEM 自研芯片 + 自研软件。
对于华为,管理层承认华为会在中国汽车市场拿到显著份额,但认为任何单一中国 OEM 集团有规模上限,约 400-500 万辆。所有其他自研芯片 OEM 加总可能还有 300-400 万辆。在中国约 2500 万辆 乘用车市场中,管理层认为约 30-40% 市场地平线较难触达,剩下长尾市场仍然很大。
这个判断的关键,不是华为或车企自研是否存在,而是它们会不会抢走最高价值车型和最高利润池。如果地平线最终主要拿到低价长尾市场,公司收入和利润弹性仍可能被压缩。
9. 估值框架
Bernstein 给出 HKD 10.00 目标价,基于:
2H27-1H28 销售额:RMB 11.5bn- EV/Sales 倍数:
10.3x
这说明地平线仍然是高成长估值框架,而不是利润稳定型估值框架。当前估值的关键不是当期 EPS,而是收入增长、设计定点、软件/IP 生态和长期利润池能否兑现。
10. 可复用的投研方法
这份研报适合作为“客户自研替代供应商”的案例。以后遇到类似问题,可以按以下框架拆解。
10.1 把自研替代拆成三层
不要只问“客户会不会自研”,而要问:
- 客户有没有技术能力。
- 客户有没有规模经济。
- 自研后是否仍然需要供应商的 IP、软件、工具链或生态。
用于地平线:大型 OEM 可能自研芯片,但 BPU/IP、HSD 软件和生态迁移成本可能让地平线仍能参与利润分配。
10.2 区分收入稀释和利润率改善
IP 授权常常带来更高毛利率,但不一定带来更高绝对毛利。
检查问题:
- 单车收入是否下降。
- 单车毛利是否下降。
- 授权费是否前置确认。
- royalty 是否持续且可审计。
- 公司披露的是毛利率改善,还是绝对毛利改善。
10.3 用 design wins 判断未来一年
汽车供应链公司当年收入很多来自过去已获得定点。真正前瞻指标不是当季收入,而是新增定点质量。
检查问题:
- 新增定点来自哪些客户。
- 对应车型价格带和销量潜力。
- 是低阶 ADAS,还是高阶 Urban NOA / HSD。
- SOP 时间是否明确。
- 是否存在多供应商替代风险。
10.4 判断平台型供应商是否被切走
平台型供应商是否被客户绕开,要看它是否掌握以下至少一项:
- 底层 IP。
- 软件栈。
- 开发工具链。
- 数据闭环。
- 认证和量产经验。
- 客户迁移成本。
11. 后续跟踪动作
后续应围绕“长期逻辑是否被破坏”建立跟踪清单。
每月跟踪:
- 地平线公告、业绩会和投资者交流纪要。
- 主要客户车型销量。
- 智驾方案定点新闻。
- 华为、BYD、小鹏、理想、蔚来自研芯片进展。
- 行业价格战和智驾功能下放节奏。
每季度跟踪:
- 收入增长是否接近管理层目标。
- 毛利率变化是否支持 IP 模式说法。
- design wins 数量和质量。
- 第三方供应商份额变化。
- 海外客户进展。
偏正面信号:
- Journey 6P 获得更多中高端 Urban NOA 定点。
- IP 授权客户增加,且 royalty 模式披露更清晰。
- 地平线在中国供应商中的份额继续提升。
- 车企自研项目延期或量产效果不佳。
- 海外 ADAS 客户贡献明显增长。
偏负面信号:
- 新定点主要来自低价 ADAS,缺少高价值 HSD。
- 直接芯片销售被 IP 授权替代,但收入增速明显放缓。
- 毛利率上升但绝对毛利增长疲弱。
- 华为或 BYD 自研方案在大众市场快速放量。
- 2026 下半年没有形成明显“前低后高”。
12. 待验证问题
后续需要补充验证的问题:
- 地平线的收入中,芯片、软件、IP 授权和服务分别占比多少?
- Journey 6M 和 6P 的单车 ASP 与毛利差异有多大?
- HSD 是否独立收费,还是绑定硬件销售?
- VW / CARIZON 之外,还有哪些 IP 授权客户?
- IP 授权模式下,royalty 是按车、按芯片,还是按客户内部结算价抽成?
- 主要客户是否同时采用多家供应商?
- 华为、BYD、NVIDIA、Mobileye、Qualcomm 的竞争力差异如何量化?
13. 复盘结论
这份研报的多头逻辑有说服力:市场把主机厂自研简单理解为地平线市场消失,确实过于粗糙。更合理的理解是,商业模式可能从直接卖芯片,部分转向芯片、软件、IP 和 royalty 的混合模式。
但这不等于风险消失。真正要验证的是三件事:
- 地平线是否能继续拿到高质量定点。
- IP 授权模式是否能保住足够的绝对利润。
- 智驾软件是否真的形成生态粘性,而不是被客户逐步内化。
当前应把这份研报定位为“跟踪基准材料”,不作为单独投资决策依据。下一步应补充公司公告、业绩会材料和竞争对手信息,再决定是否形成独立投资备忘录。
---
layout: post
title: cc-connect 使用手册
subtitle: Codex 个人助理沉淀
date: 2026-06-05 00:14:15 -0400
tags:
- 个人助理
- 项目
- cc-connect
---
来源:notes/projects/cc-connect/01_cc_connect_使用手册.md
cc-connect 使用手册
1. 这个项目是什么
cc-connect 是一个把本地 AI Agent 接到即时通讯工具里的桥接服务。
它的核心作用是:
- 你在飞书、钉钉、Telegram、Slack、Discord、企业微信、微信、QQ 等聊天工具里发消息。
cc-connect 收到消息后,把内容转给本机运行的 AI Agent,例如 Claude Code、Codex、Cursor Agent、Gemini CLI、Qoder CLI、OpenCode、iFlow CLI。- Agent 在本地项目目录执行任务,结果再由
cc-connect 发回聊天窗口。
一句话:它让你可以用手机里的聊天软件远程操作本机代码助手。
2. 项目位置和本机状态
本机源码目录:
/home/admin/code/cc-connect
当前目录里已经有编译好的二进制:
/home/admin/code/cc-connect/cc-connect
这个仓库当前有未提交的本地改动,我这次只阅读和整理文档,没有修改 cc-connect 项目本身。
3. 基本执行链路
聊天平台用户消息
-> 平台连接器(feishu / telegram / qq / weixin 等)
-> cc-connect Engine
-> 对应 project 的 Agent
-> Agent 在 work_dir 中执行
-> cc-connect 把结果发回聊天平台
关键配置在 config.toml:
[[projects]]
name = "my-project"
[projects.agent]
type = "codex" # 或 claudecode / cursor / gemini / qoder / opencode / iflow
[projects.agent.options]
work_dir = "/absolute/path/to/project"
mode = "default"
[[projects.platforms]]
type = "feishu"
[projects.platforms.options]
app_id = "cli_xxx"
app_secret = "xxx"
一个 cc-connect 进程可以同时管理多个 [[projects]]。每个 project 可以绑定自己的 Agent、工作目录和一个或多个聊天平台。
4. 安装方式
4.1 npm 安装
稳定版:
npm install -g cc-connect
Beta 版:
npm install -g cc-connect@beta
如果需要个人微信 weixin ilink 能力,当前文档说明应使用 beta / pre-release 版本。
4.2 GitHub Release 二进制
Linux 示例:
curl -L -o cc-connect https://github.com/chenhg5/cc-connect/releases/latest/download/cc-connect-linux-amd64
chmod +x cc-connect
sudo mv cc-connect /usr/local/bin/
4.3 源码编译
git clone https://github.com/chenhg5/cc-connect.git
cd cc-connect
make build
本机源码目录已经存在,可直接在 /home/admin/code/cc-connect 下构建或运行已有二进制。
5. 配置文件位置
cc-connect 查找配置文件的顺序:
- 命令行
-config <path> 指定的配置。
- 当前目录下的
./config.toml。
- 全局配置
~/.cc-connect/config.toml。
推荐使用全局配置:
mkdir -p ~/.cc-connect
cp /home/admin/code/cc-connect/config.example.toml ~/.cc-connect/config.toml
vim ~/.cc-connect/config.toml
如果没有配置文件,直接运行 cc-connect 会自动创建 starter config 到 ~/.cc-connect/config.toml。
6. 最小可用配置
以 Codex + 飞书为例:
[log]
level = "info"
[[projects]]
name = "personal-assistant"
admin_from = "你的飞书用户ID"
[projects.agent]
type = "codex"
[projects.agent.options]
work_dir = "/home/admin/code/cc-connect-work-space/codex_personal_assistant"
mode = "yolo"
[[projects.platforms]]
type = "feishu"
[projects.platforms.options]
app_id = "cli_xxxxxxxxxxxx"
app_secret = "xxxxxxxxxxxxxxxx"
allow_from = "*"
注意:
work_dir 必须是绝对路径。admin_from 用于限制 /dir、/shell 等高权限命令。mode 决定 Agent 权限策略。Codex 支持 suggest、auto-edit、full-auto、yolo。- 如果希望执行命令时不频繁请求审批,通常要把 Agent 模式设成更自动化的模式,例如 Codex 的
yolo 或 Claude Code 的 bypassPermissions。
7. 飞书接入
推荐使用内置 CLI:
cc-connect feishu setup --project my-project
如果已经有 App ID 和 App Secret:
cc-connect feishu setup --project my-project --app cli_xxx:sec_xxx
也可以显式使用:
cc-connect feishu new --project my-project
cc-connect feishu bind --project my-project --app cli_xxx:sec_xxx
飞书开放平台手动配置时需要:
- 创建企业自建应用。
- 启用机器人能力。
- 获取
App ID 和 App Secret。
- 开启 WebSocket 长连接事件订阅。
- 订阅
im.message.receive_v1。
- 添加并发布消息相关权限,例如接收消息、读取消息、以机器人身份发消息。
飞书平台配置示例:
[[projects.platforms]]
type = "feishu"
[projects.platforms.options]
app_id = "cli_axxxxxxxxxxxx"
app_secret = "QhkMpxxxxxxxxxxxxxxxxxxxx"
# enable_feishu_card = true
# thread_isolation = true
# progress_style = "compact" # legacy | compact | card
8. QQ 接入
cc-connect 的 QQ 平台通过 OneBot v11 协议接入,常见搭配是 NapCat。
架构:
QQ Client -> NapCat OneBot v11 -> WebSocket -> cc-connect -> Agent
Docker 启动 NapCat 示例:
docker run -d \
--name napcat \
-e ACCOUNT=<你的QQ号> \
-p 3001:3001 \
-p 6099:6099 \
mlikiowa/napcat-docker:latest
首次启动看日志扫码:
NapCat WebUI:
启用正向 WebSocket,端口通常是 3001。
cc-connect 配置:
[[projects.platforms]]
type = "qq"
[projects.platforms.options]
ws_url = "ws://127.0.0.1:3001"
token = ""
allow_from = "*"
启动后看到类似日志表示正常:
qq: connected to OneBot url=ws://127.0.0.1:3001
qq: logged in qq=123456789 nickname=MyBot
9. 启动服务
前台启动:
指定配置:
cc-connect -config ~/.cc-connect/config.toml
源码目录中运行已有二进制:
cd /home/admin/code/cc-connect
./cc-connect -config ~/.cc-connect/config.toml
启动成功后会看到:
config loaded
platform started
cc-connect is running
10. 守护进程模式
安装为后台服务:
cc-connect daemon install --config ~/.cc-connect/config.toml
常用命令:
cc-connect daemon status
cc-connect daemon logs -f
cc-connect daemon restart
cc-connect daemon stop
cc-connect daemon start
cc-connect daemon uninstall
安装守护进程时,代码会检查配置文件所在目录是否存在 config.toml。如果传入 --config ~/.cc-connect/config.toml,它会把 ~/.cc-connect 作为服务工作目录。
11. 聊天内常用命令
会话管理:
/new [名称] 创建新会话
/list 列出会话
/switch <id> 切换会话
/current 查看当前会话
/history [n] 查看最近 n 条消息
/stop 停止当前执行
/help 查看命令
工作目录:
/dir 查看当前目录和历史
/dir <路径> 切换工作目录
/dir <序号> 按历史序号切换
/dir - 返回上一个目录
/cd <路径> /dir 的别名
权限和模型:
/mode 查看当前权限模式
/mode yolo 切换到自动批准模式
/mode default 切回默认模式
/reasoning [等级] Codex 推理强度
/model 查看模型
/model switch <alias> 切换模型
/provider 查看 Provider
/provider switch <名称> 切换 Provider
飞书/附件/定时任务相关:
/quiet 开关思考和工具进度消息
/cron 列出定时任务
/cron add ... 创建定时任务
/cron del <id> 删除任务
/bind setup 写入 Agent 附件回传和绑定说明
/web setup 启用 Web 管理后台和 Bridge
12. 定时任务 Cron
聊天里创建:
/cron add 0 6 * * * 帮我收集 GitHub trending 并总结
CLI 创建:
cc-connect cron add \
--cron "0 6 * * *" \
--prompt "总结 GitHub trending" \
--desc "每日趋势"
执行 shell 命令型任务:
cc-connect cron add \
--cron "*/10 * * * *" \
--exec "bash /path/to/script.sh" \
--desc "每10分钟执行脚本"
查看和删除:
cc-connect cron list
cc-connect cron del <job-id>
可选参数:
--session-mode new_per_run
--timeout-mins 30
--data-dir ~/.cc-connect
说明:
session_mode = reuse 表示复用当前会话。new_per_run 表示每次触发创建新 Agent 会话。timeout_mins 控制单次任务最长执行时间。
13. 文件和图片回传
当 Agent 在本机生成了图片、PDF、日志、Markdown 等文件,可以通过 cc-connect send 发回当前聊天。
发送文本:
cc-connect send --message "任务完成"
发送图片:
cc-connect send --image /absolute/path/to/chart.png
发送文件:
cc-connect send --file /absolute/path/to/report.pdf
同时发送说明和附件:
cc-connect send \
--message "这是生成的报告" \
--file /absolute/path/to/report.md \
--image /absolute/path/to/chart.png
注意:
- 建议使用绝对路径。
- 附件大小限制约 50 MB。
- 当前文档显示附件回传支持飞书和 Telegram。
- 如果配置
attachment_send = "off",附件回传会被禁用。
14. 多机器人中继
在群聊里可以绑定多个项目机器人:
/bind 查看绑定
/bind claudecode 添加 claudecode 项目
/bind gemini 添加 gemini 项目
/bind -claudecode 移除 claudecode
CLI 让一个机器人询问另一个机器人:
cc-connect relay send --to gemini "你觉得这个架构怎么样?"
指定来源和会话:
cc-connect relay send \
--from codex \
--to gemini \
--session-key '<session-key>' \
--message '请给这个方案做反方审查'
15. 会话文件查看
cc-connect sessions 可以查看本地保存的会话。
cc-connect sessions list
cc-connect sessions show <session-id> -n 20
默认数据目录是:
也可以指定:
cc-connect sessions --data-dir /path/to/data list
16. Provider 和模型配置
Provider 用于在运行时切换 API Key、base_url、模型。
配置示例:
[projects.agent.options]
provider = "openai"
[[projects.agent.providers]]
name = "openai"
api_key = "sk-xxx"
base_url = "https://api.openai.com/v1"
model = "gpt-5.3-codex"
[[projects.agent.providers.models]]
model = "gpt-5.3-codex"
alias = "codex"
[[projects.agent.providers.models]]
model = "gpt-5.4"
alias = "gpt"
CLI 管理:
cc-connect provider add --project my-project --name relay --api-key sk-xxx --base-url https://api.example.com
cc-connect provider list --project my-project
cc-connect provider remove --project my-project --name relay
cc-connect provider import --project my-project
聊天内切换:
/provider list
/provider switch openai
/model
/model switch codex
17. Web 管理后台和 Bridge
聊天里启用:
它会写入:
[management]
enabled = true
port = 9820
token = "your-secret-token"
[bridge]
enabled = true
port = 9810
token = "your-bridge-secret"
path = "/bridge/ws"
启用后需要重启 cc-connect。
默认端口:
| 功能 |
端口 |
配置块 |
| Web 管理后台 / Management API |
9820 |
[management] |
| Bridge WebSocket / REST |
9810 |
[bridge] |
18. 常见排障
18.1 启动后没有收到消息
检查:
- 平台凭证是否正确。
- 飞书应用是否发布。
- 飞书事件订阅是否是 WebSocket 长连接。
allow_from 是否限制了用户 ID。cc-connect daemon logs -f 或前台日志是否有平台启动错误。
18.2 Agent 没有在预期目录执行
检查:
必要时执行:
/dir /absolute/path/to/project
/dir reset
配置里的默认目录是:
[projects.agent.options]
work_dir = "/absolute/path/to/project"
18.3 命令总是请求审批
检查当前模式:
切换更自动化的模式:
或者在配置里设置:
[projects.agent.options]
mode = "yolo"
不同 Agent 的模式名称不完全一样:
| Agent |
自动模式示例 |
| Claude Code |
bypassPermissions / yolo |
| Codex |
full-auto / yolo |
| Cursor Agent |
force / yolo |
| Gemini CLI |
yolo |
| Qoder / OpenCode / iFlow |
yolo |
18.4 定时任务不执行
检查:
cc-connect cron list
cc-connect daemon status
cc-connect daemon logs -f
注意:cc-connect cron add 需要正在运行的 cc-connect,因为 CLI 通过本地 Unix socket 写入任务。
18.5 文件发不回聊天
检查:
- 是否存在活跃聊天会话。
- 文件路径是否为绝对路径。
- 文件是否超过大小限制。
- 配置中是否有
attachment_send = "off"。
- 当前平台是否支持附件回传。
19. 我在本机看到的关键文件
/home/admin/code/cc-connect/README.zh-CN.md
/home/admin/code/cc-connect/INSTALL.md
/home/admin/code/cc-connect/docs/usage.zh-CN.md
/home/admin/code/cc-connect/docs/feishu.md
/home/admin/code/cc-connect/docs/qq.md
/home/admin/code/cc-connect/config.example.toml
/home/admin/code/cc-connect/cmd/cc-connect/main.go
/home/admin/code/cc-connect/cmd/cc-connect/cron.go
/home/admin/code/cc-connect/cmd/cc-connect/send.go
/home/admin/code/cc-connect/cmd/cc-connect/relay.go
/home/admin/code/cc-connect/cmd/cc-connect/daemon.go
20. 推荐日常使用方式
如果把它作为个人远程助理入口,建议:
- 用
~/.cc-connect/config.toml 管理所有项目。
- 每个常用工作目录建一个
[[projects]]。
- Agent 默认模式根据风险选择:日常个人仓库可用
yolo,生产高风险仓库用 default 或 auto-edit。
- 飞书作为主入口,QQ/微信等作为备用入口。
- 长任务用
/cron 或 cc-connect cron add,并设置 --timeout-mins。
- 需要交付文件时,让 Agent 使用
cc-connect send --file 或 --image。
- 服务用
cc-connect daemon install --config ~/.cc-connect/config.toml 常驻。
---
layout: post
title: 《Urban Mindfulness》方法卡片
subtitle: Codex 个人助理沉淀
date: 2026-06-04 08:37:35 -0400
tags:
- 个人助理
- 读书笔记
- Urban Mindfulness
---
来源:notes/books/Urban Mindfulness/02_方法卡片.md
《Urban Mindfulness》方法卡片
用途:把城市正念练习转成个人助理可执行规则,用于通勤、工作、公共空间和日常情绪复盘。
卡片 01:城市正念三步
- 适用场景:通勤、排队、等车、人群中、嘈杂环境。
- 触发条件:感觉烦躁、赶时间、想刷手机或开始抱怨。
- 操作步骤:停一下;感受一次呼吸;说出一个当前事实,例如“我在高铁站,脚踩在地面上”。
- 失败信号:自动打开手机或开始在心里骂环境。
- 补救动作:只做 10 秒,不追求平静。
- 效果指标:一天中成功停顿的次数。
卡片 02:等车不刷手机
- 适用场景:等地铁、等高铁、等公交、等电梯。
- 触发条件:等待开始后的前 30 秒。
- 操作步骤:先不拿手机;观察 3 个声音、2 个视觉细节、1 个身体感觉;之后再决定是否用手机。
- 失败信号:还没意识到等待,就已经在刷屏。
- 补救动作:下一次等待只要求完成一次呼吸。
- 效果指标:等待场景中无意识刷手机次数下降。
卡片 03:通勤身体扫描
- 适用场景:地铁、高铁、打车、步行途中。
- 触发条件:到达一个通勤节点时。
- 操作步骤:从脚底、腿、背、肩、脸快速扫一遍;记录最明显的身体感受。
- 失败信号:只记录位置,不知道身体状态。
- 补救动作:只问一个问题:我现在最紧的是哪里?
- 效果指标:通勤记录里出现身体感受字段。
卡片 04:噪音转提醒器
- 适用场景:邻居噪音、车流、施工、广播、公共空间嘈杂。
- 触发条件:听到噪音并产生烦躁。
- 操作步骤:先把声音当成声音;观察音量、高低、远近、持续变化;再观察自己对声音的评价。
- 失败信号:直接陷入“为什么这么吵”。
- 补救动作:把注意力放回呼吸或脚底触地。
- 效果指标:噪音触发的情绪恢复时间缩短。
卡片 05:城市广告免疫
- 适用场景:看到广告、促销、橱窗、App 推送。
- 触发条件:产生购买、比较或不满足感。
- 操作步骤:识别广告想激发什么欲望;观察身体和情绪反应;问“这是我的真实需要吗”。
- 失败信号:没意识到被刺激,就开始搜索或下单。
- 补救动作:加入 24 小时延迟规则。
- 效果指标:冲动消费次数下降。
卡片 06:公共情绪允许
- 适用场景:在公共场合感到难过、孤独、焦虑、尴尬。
- 触发条件:想压住情绪或假装没事。
- 操作步骤:承认情绪存在;找到身体位置;不急着解释原因;允许它停留一会儿。
- 失败信号:立刻用手机、食物或忙碌麻痹自己。
- 补救动作:写一句事实记录,例如“我现在在车站,感到孤独”。
- 效果指标:情绪被看见,而不是只被逃避。
卡片 07:工作日边界检查
- 适用场景:上班前、下班后、从工作切到生活时。
- 触发条件:脑子还在反复想工作。
- 操作步骤:问“我的工作日什么时候开始,什么时候结束”;用一个小仪式切换,例如走一段路、喝水、整理桌面。
- 失败信号:下班后还不断查看工作消息。
- 补救动作:结合 Deep Work 的停工仪式,写下明天第一步。
- 效果指标:下班后的工作反刍减少。
卡片 08:正念急救包
- 适用场景:焦虑、烦躁、注意力散、无法进入状态。
- 触发条件:普通呼吸练习不容易做下去。
- 操作步骤:准备几个五感物品,如图片、香味、触感物、音乐、茶或巧克力;每次只选一个做 1-3 分钟观察。
- 失败信号:把急救包变成逃避或娱乐。
- 补救动作:设定计时器,结束后记录当下状态。
- 效果指标:情绪强度下降或注意力稳定。
卡片 09:消息发送前 3 秒
- 适用场景:微信、短信、邮件、社交平台回复。
- 触发条件:准备发送一条可能带情绪或自动反应的信息。
- 操作步骤:停 3 秒;读一遍;问“这是否表达了我的真实意图”;必要时删减或延后。
- 失败信号:发送后后悔,或对方误解升级。
- 补救动作:重要消息先写草稿,不立即发。
- 效果指标:冲动回复减少。
卡片 10:游客心态
- 适用场景:熟悉路线、重复通勤、对城市麻木时。
- 触发条件:觉得每天都一样或只想快点到达。
- 操作步骤:像游客一样观察一个以前忽略的细节:招牌、建筑、树、光线、人群动作。
- 失败信号:全程自动驾驶,没有任何新观察。
- 补救动作:拍一张照片或写一句观察。
- 效果指标:重复路线中的新鲜感和在场感提升。
---
layout: post
title: 《Urban Mindfulness》内容全梳理
subtitle: Codex 个人助理沉淀
date: 2026-06-04 08:37:35 -0400
tags:
- 个人助理
- 读书笔记
- Urban Mindfulness
---
来源:notes/books/Urban Mindfulness/01_内容全梳理.md
《Urban Mindfulness》内容全梳理
中文暂译:《城市正念:在一切之中培养平静、临在与目的》
作者:Jonathan Kaplan
出版:New Harbinger Publications,2010
本笔记基于用户上传 EPUB 转换稿整理,目标是把城市生活中的正念练习转成个人助理可复用的行为方法。
1. 这本书解决什么问题
这本书解决的是:在城市这种高刺激、高密度、高压力环境里,如何不等到“有空、安静、离开城市、去修行场所”之后才练习正念,而是在真实生活现场直接练习。
作者的核心立场是:城市不是正念的障碍,而是正念的练习场。噪音、拥挤、通勤、邻居、地铁、广告、排队、工作、孤独、线上沟通,都可以成为观察当下、觉察情绪、恢复选择权的入口。
可以把全书压缩成一句话:
正念不是从城市生活中逃离,而是在城市生活里重新获得对注意力、情绪和行动的选择权。
2. 作者如何定义正念
书中把正念解释为一种特殊的注意方式:从自动驾驶中醒来,把注意力带回此时此刻,观察正在发生的身体感受、情绪、想法、知觉和环境,同时尽量不急着评判、排斥或抓取。
这一定义有几个重点:
- 正念不等于只做静坐冥想。
- 正念不要求环境安静,也不要求心里没有念头。
- 正念不是把不舒服变没,而是先看见它、允许它存在,再决定怎么回应。
- 正念可以被嵌入家里、工作、娱乐、通勤和公共空间。
3. 全书结构
全书由引言和 5 个主要场景构成,每个场景包含多个短章节和练习。
3.1 Introduction
引言说明作者从乡村/小城回到纽约后,发现城市生活让自己的平衡感、健康习惯和冥想练习被打乱。传统正念资源常假设人有安静空间和较长时间,而城市生活更需要碎片化、场景化、可立即使用的练习。
3.2 At Home
这一部分处理居住空间里的正念:小空间、室友/伴侣、宠物/孩子、垃圾、邻居噪音、房间清洁、沉默日、空城感等。
核心观点:家不是必须完美才适合练习。杂乱、噪音、拥挤和比较心,都是观察自己反应的入口。
3.3 At Play
这一部分处理娱乐和休闲:运动、气味、散步、公园、城市绿意、孩子、博物馆、穿衣、线上约会、饮酒等。
核心观点:休闲不是麻木自己,而是重新打开感官和好奇心。玩也可以是练习,尤其是在城市提供的大量体验中慢下来。
3.4 At Work
这一部分处理工作场景:咖啡、工作日边界、物品感恩、工作与玩、正念急救包、按钮、五感练习、电梯/楼梯、植物冥想、一天的积极想象等。
核心观点:工作中的正念不是降低效率,而是减少自动反应和压力惯性。很多练习只需要几十秒到几分钟。
3.5 Out and About
这一部分处理外出和城市移动:广告、公共场合的悲伤、自然、现场音乐、步行冥想、外带正念、无家可归者、地铁冥想、游客心态、窗户观察等。
核心观点:城市公共空间不是干扰物集合,而是注意力训练场。你无法控制城市,但可以改变自己和城市刺激的关系。
3.6 Anytime, Anywhere
这一部分处理任何场景可用的练习:等待公交、失物、拥堵、急躁、孤独、信息沟通、正念紧急情况、多样性、排队、存在目的等。
核心观点:最好的正念练习不依赖条件,而是在触发点出现时立刻启动。等待、拥堵、孤独、消息和冲突都是提醒器。
4. 核心主题
4.1 把城市刺激改造成提醒器
城市里有太多刺激:广告、车流、声音、人群、排队、通知。通常这些刺激会把人带进烦躁、比较、消费欲望或逃避。但作者建议反过来利用它们:每次看到广告、等电梯、听到噪音、排队时,都把它当成一次回到呼吸、身体和当下的提醒。
个人助理落地:可以把“地铁站”“高铁站”“排队”“等车”等通勤节点,标成正念练习触发器。
4.2 正念是从自动驾驶中退出
城市生活容易让人自动化:赶路、刷手机、抱怨、比较、焦虑、消费、回消息。正念的第一个动作不是改变行为,而是看见自己正在自动化。
典型问题包括:
- 我现在身体有什么感觉?
- 我是不是正在急着摆脱某种情绪?
- 我是不是把眼前的人或事贴了标签?
- 我现在的行动是选择,还是惯性?
4.3 不舒服不是失败,而是练习对象
书中反复使用城市里的不舒服场景:噪音、拥挤、悲伤、孤独、等待、失物、无家可归者、邻居、室友冲突。作者并不要求人把这些体验变成“积极”,而是先允许自己看见真实反应。
这对个人记录很有价值:记录不只记录事件,也可以记录当时的身体反应、情绪反应和自动想法。
4.4 正念可以很短、很日常
这本书的练习大多不是长时间正式冥想,而是嵌入日常动作:喝咖啡、走路、乘地铁、摸宠物、清洁、听音乐、看窗外、发消息、排队。它降低了练习门槛。
对个人助理系统来说,这意味着可以把正念记录成 30 秒到 3 分钟的小动作,而不是要求整块时间。
5. 对个人助理系统的启发
5.1 给通勤记录增加“正念节点”
你已经在记录通勤节点,例如到地铁站、到高铁站。可以在这些节点后增加一个可选字段:
- 当前身体感受
- 当前情绪
- 周围一个声音/颜色/气味
- 是否刷手机
- 是否做了 3 次呼吸
5.2 建立“城市触发器”方法标签
可以新增方法标签:城市正念。适用场景:通勤、排队、等车、电梯、噪音、人群、广告、公共空间情绪波动。
记录模板:
HH:MM 城市正念:在[场景]停下来观察[身体/声音/情绪]。标签:城市正念。
5.3 把不舒服事件记录成复盘材料
例如“地铁很挤”“高铁站排队很烦”“邻居很吵”,不要只记录抱怨,可以记录成:
事实:高铁站排队很久。
反应:烦躁、想刷手机。
练习:观察脚底触地和呼吸 1 分钟。
复盘:等待是正念触发器。
6. 最值得落地的 6 个动作
- 等车/排队时做 3 次呼吸,不立即刷手机。
- 通勤途中选择一个感官对象:声音、颜色、脚步或身体触点。
- 遇到噪音时先观察“我对噪音的反应”,而不是立刻评价噪音。
- 工作开始前用喝咖啡/喝水做 1 分钟感官练习。
- 回消息前停 3 秒,确认这条消息是否需要立刻发送。
- 每天记录一个城市正念节点,形成复盘素材。
7. 一句话总结
《Urban Mindfulness》的核心不是把城市变安静,而是在城市照常嘈杂时,让自己多一次看见、停顿和选择的机会。
---
layout: post
title: 《Deep Work》方法卡片
subtitle: Codex 个人助理沉淀
date: 2026-06-04 01:34:11 -0400
tags:
- 个人助理
- 读书笔记
- Deep Work
---
来源:notes/books/Deep Work/02_方法卡片.md
《Deep Work》方法卡片
用途:把《Deep Work》转成个人助理可执行规则,用于日常记录、专注训练和每周复盘。
卡片 01:每日 90 分钟深度工作块
- 适用场景:写方案、编码、投资研究、读书输出、复杂问题分析。
- 触发条件:当天存在一个需要高认知投入的重要任务。
- 操作步骤:提前确定一个 90 分钟窗口;写清楚唯一目标;手机离开手边;关闭非必要通知;结束后记录输出物。
- 失败信号:窗口内反复查消息、切任务、无明确产出。
- 补救动作:把窗口缩短到 45 分钟,先建立稳定性,再拉长时长。
- 效果指标:每周完成的深度工作小时数。
卡片 02:深度工作仪式
- 适用场景:启动困难、容易被环境带走时。
- 触发条件:准备进入深度工作前。
- 操作步骤:固定地点;明确开始和结束时间;定义可用工具;定义禁止事项;准备水、纸笔和必要资料。
- 失败信号:开始后还在找资料、调环境、决定做什么。
- 补救动作:把准备动作提前到前一天或上午第一件事。
- 效果指标:进入状态所需时间是否缩短。
卡片 03:极重要目标 + 深度小时记分板
- 适用场景:重要项目长期推进不动时。
- 触发条件:一周开始或项目启动时。
- 操作步骤:只选一个极重要目标;把领先指标设为深度工作小时数;每天记录投入;每周复盘计分板。
- 失败信号:只看最终结果,不知道每天该增加什么行为。
- 补救动作:把目标拆成“本周至少投入 X 小时深度工作”。
- 效果指标:深度小时数和关键产出是否同步增加。
卡片 04:生产性冥想
- 适用场景:通勤、散步、洗澡、排队等身体占用但大脑空闲的时间。
- 触发条件:有一个复杂问题需要推进。
- 操作步骤:选定一个明确问题;在走路或通勤中反复思考;走神时拉回;卡住时问“下一步问题是什么”;结束后记录结论。
- 失败信号:变成普通发散、焦虑复盘或刷手机。
- 补救动作:把问题写成一句话,例如“这个方案的核心风险是什么”。
- 效果指标:每周至少 2 次生产性冥想,并产出可记录结论。
卡片 05:固定联网窗口
- 适用场景:工作中频繁想查消息、刷网页、看行情。
- 触发条件:需要训练抗分心能力。
- 操作步骤:提前设定联网窗口;非窗口期出现想查的冲动,只记录不执行;到窗口期统一处理。
- 失败信号:一有无聊或卡顿就打开网络工具。
- 补救动作:先从 30 分钟无联网开始,不直接追求半天断网。
- 效果指标:无意识打开网络工具次数下降。
卡片 06:工具工匠审计
- 适用场景:社交媒体、资讯、短视频、IM、行情软件使用失控。
- 触发条件:一个工具占用大量注意力,但价值不明确。
- 操作步骤:写下当前最重要的 2-3 个目标;判断该工具是否显著服务这些目标;列出成本;收益不明显则停用或降级。
- 失败信号:理由只是“可能有用”“大家都用”“怕错过”。
- 补救动作:做 30 天停用实验,结束后只恢复真正必要的工具。
- 效果指标:工具使用时间减少但关键目标不受损。
卡片 07:浅层工作预算
- 适用场景:一天被消息、会议、杂事占满。
- 触发条件:开始安排当天工作时。
- 操作步骤:把任务分成深度、浅层、生活、恢复;给浅层工作设置时间上限;集中批处理消息和邮件。
- 失败信号:没有深度块,浅层事务从早拖到晚。
- 补救动作:先锁定一个不可侵犯的深度块,再安排浅层工作。
- 效果指标:浅层工作占比是否下降。
卡片 08:停工仪式
- 适用场景:下班后还反复想工作,休息质量差。
- 触发条件:每天工作结束前。
- 操作步骤:检查未完成事项;写入明天第一步;确认没有遗漏紧急事项;说出或写下“今天工作结束”。
- 失败信号:晚上继续临时处理低价值工作,或者脑子停不下来。
- 补救动作:把停工仪式固定在日历上,预留 10-15 分钟。
- 效果指标:晚上工作反刍减少,第二天启动更快。
卡片 09:深度工作周复盘
- 适用场景:每周末或周一早晨。
- 触发条件:需要评估一周是否真正推进了重要目标。
- 操作步骤:统计深度工作小时数;列出关键产出;识别最大打断来源;决定下周要保护的第一个深度块。
- 失败信号:复盘只写“忙”,没有深度小时和产出物。
- 补救动作:从 daily_log 中回填深度工作记录。
- 效果指标:下周深度小时数和产出质量提升。
卡片 10:高质量休闲替代浅刺激
- 适用场景:下班后用手机、社交媒体、短视频填满休息时间。
- 触发条件:空闲时想用低质量刺激恢复。
- 操作步骤:提前准备休闲清单,如运动、散步、纸质阅读、做饭、朋友交流、无输入发呆;休息也做主动选择。
- 失败信号:休息后更累、更焦虑、更难专注。
- 补救动作:先安排一个 30 分钟离线休闲块。
- 效果指标:休息后恢复感提升,睡前刷屏时间下降。
---
layout: post
title: 《Deep Work》内容全梳理
subtitle: Codex 个人助理沉淀
date: 2026-06-04 01:34:11 -0400
tags:
- 个人助理
- 读书笔记
- Deep Work
---
来源:notes/books/Deep Work/01_内容全梳理.md
《Deep Work》内容全梳理
中文暂译:《深度工作》
作者:Cal Newport
出版:Grand Central Publishing,2016
本笔记基于用户上传 MOBI 转换稿整理,目标是把全书内容转成个人助理可使用的工作方法知识资产。
1. 这本书解决什么问题
这本书解决的是知识工作者越来越常见的一个结构性问题:我们看起来一直很忙,但真正创造高价值成果的时间越来越少。邮件、即时通讯、社交媒体、会议、碎片化查询和不断切换的任务,让人长期停留在低认知负荷的浅层工作里。
作者的核心判断是:深度工作不是一种性格偏好,而是一项可以训练、可以安排、可以度量的职业能力。谁能在高干扰环境里保留长时间无干扰思考和产出的能力,谁就能获得更强的学习速度、创造力和职业杠杆。
可以把全书压缩成一句话:
在注意力稀缺的时代,能持续进入深度工作的人,会获得不成比例的职业回报和生活掌控感。
2. 核心概念
2.1 深度工作
深度工作指在无干扰的专注状态中进行高认知要求的专业活动。这类活动会推动认知能力到达边界,创造新价值,提升技能,并且难以被复制。
它的关键词是:无干扰、高认知负荷、创造新价值、提升技能、不可轻易复制。
2.2 浅层工作
浅层工作指低认知要求、偏事务和后勤性质的工作,通常可以在分心状态下完成。这类工作不太创造新价值,也容易被他人替代。
典型例子包括:反复查邮件、低价值会议、机械整理、即时回复、无目标搜索、为了保持在线感而进行的沟通。
2.3 深度工作假说
作者提出的核心假说是:深度工作的能力正在变得越来越稀缺,同时在经济中的价值却越来越高。因此,少数培养这项能力并把它作为工作核心的人,会获得显著优势。
这不是反技术,也不是反社交,而是一个非常实用的职业判断:复杂技能学习、复杂问题解决、高质量创作和战略判断,都依赖深度注意力。
3. 全书结构
全书分为两大部分。
Part 1:The Idea
第一部分证明为什么深度工作重要。
- Chapter 1:Deep Work Is Valuable,深度工作有价值。
- Chapter 2:Deep Work Is Rare,深度工作很稀缺。
- Chapter 3:Deep Work Is Meaningful,深度工作能带来意义感。
Part 2:The Rules
第二部分给出实践规则。
- Rule #1:Work Deeply,设计深度工作的制度。
- Rule #2:Embrace Boredom,训练大脑忍受无聊和抵抗分心。
- Rule #3:Quit Social Media,用工匠原则筛选网络工具。
- Rule #4:Drain the Shallows,压缩浅层工作。
4. Part 1:为什么深度工作重要
4.1 深度工作有价值
作者认为,在新经济环境中,有三类人更容易获得优势:能快速掌握复杂工具的人、能用高质量成果创造价值的人、能获得资本或平台放大的人。对大多数知识工作者来说,前两项都依赖深度工作。
深度工作让人能够快速学习困难技能。困难技能不是靠浏览、收藏、轻量阅读获得的,而是靠高强度专注、反馈和刻意练习获得的。深度工作也让人能在有限时间内产出更高质量成果,而不是只保持忙碌。
个人助理落地:以后记录工作时,不只记录“做了什么”,还要记录“有没有进入深度工作状态”和“产出了什么可复用成果”。
4.2 深度工作很稀缺
现代职场不但没有保护深度工作,反而经常奖励浅层工作。快速回复、会议参与、在线状态、社交媒体存在感和即时协作,会制造一种“忙碌就是生产力”的错觉。
作者指出三个原因:
- 很多知识工作的价值难以直接度量,所以组织容易用可见忙碌替代真实产出。
- 最小阻力原则让人自然选择更容易的沟通和响应,而不是困难的深度思考。
- 技术崇拜让人默认新工具一定有价值,忽略了它们对注意力的隐性成本。
这部分的关键提醒是:如果没有主动设计,工作环境会自动滑向浅层。
4.3 深度工作有意义
作者不仅从效率角度支持深度工作,也从生活质量角度论证它。深度工作会把注意力集中到有挑战、有反馈、有成长的任务上,让人更容易进入心流状态,并在专业能力上形成工匠感。
意义感不是来自“工作名称是否理想”,而是来自用高水平技能认真对待一件事。知识工作也可以像手艺一样产生意义,前提是你用深度方式打磨它,而不是被碎片事务拖着走。
5. Part 2:四条实践规则
5.1 Rule #1:Work Deeply
深度工作不能只靠临时意愿,而要制度化。作者给出四种调度哲学:
- 禁欲式:大幅消除浅层事务,把主要时间投入单一高价值目标。
- 双峰式:把时间切成深度阶段和开放阶段,在深度阶段近似禁欲。
- 节奏式:把深度工作固定成日常节奏,例如每天固定 90 分钟。
- 记者式:能在日程缝隙中快速切入深度工作,适合训练成熟的人。
对个人助理系统来说,最适合先采用“节奏式”:每天固定一个深度工作块,降低启动成本。
这一规则还包括几个关键方法:
- 为深度工作建立仪式:明确地点、时长、目标、禁止事项、补给方式。
- 做大动作:通过环境变化和承诺提高任务重要性,例如预约安静空间、断网、公开承诺。
- 像商业执行一样管理深度工作:选择极重要目标,追踪可控领先指标,建立记分板,每周复盘。
- 安排停工仪式:工作结束时清空未完成事项、确认下一步,让大脑真正休息。
5.2 Rule #2:Embrace Boredom
作者认为,专注能力不是打开就有的开关,而是需要训练的肌肉。如果一个人平时一无聊就拿手机,大脑就会习惯即时刺激,到了需要深度工作时也很难忍受单一任务。
这条规则的核心是:不要在生活的每个空隙里填入刺激。训练方式包括:
- 固定联网时间,而不是固定断网时间。
- 在离线时段产生想查东西的冲动,也先记录下来,等到联网窗口再处理。
- 做生产性冥想:在走路、通勤、洗澡等身体占用但大脑空闲的时段,专注思考一个明确问题。
- 练习结构化深思:定义变量,提出下一步问题,解决后巩固,再进入下一层。
个人助理落地:通勤和散步不一定都用来输入内容,可以指定为“生产性冥想窗口”。
作者并不是简单要求退出所有社交媒体,而是反对“任何好处原则”。很多人使用一个工具,只因为它可能带来一点好处,却没有严肃计算它夺走的注意力成本。
作者提出“工匠式工具选择”:先明确人生和工作中最重要的目标,再评估某个工具是否显著支持这些目标,并且收益是否超过成本。
实践上,可以做三件事:
- 对网络工具做目标-收益-成本评估。
- 做 30 天网络断舍离:先停用可选工具,之后只恢复真正重要的。
- 不要用网络填满休闲时间,而要主动安排高质量休闲。
对个人助理来说,这条规则可以转成工具审计:每个常用 app 都要说明服务哪个目标,否则默认降级。
5.4 Rule #4:Drain the Shallows
最后一条规则不是消灭所有浅层工作,而是系统性压缩它。浅层工作不可避免,但不能让它占据一天的主要精力。
作者的方法包括:
- 给每天每一分钟做预算,用时间块安排工作。
- 允许计划被现实修正,但不能放弃计划本身。
- 量化浅层工作比例,并和上级或自己明确可接受上限。
- 固定工作结束时间,用限制迫使自己提高白天效率。
- 降低邮件沟通成本:让来信者更清楚如何提出请求,回复时一次性推动事情闭环,对低价值邮件不默认回复。
这条规则对个人助理系统非常关键:每日记录不只记录任务,还要区分深度工作、浅层工作、生活事务和恢复时间。
6. 对个人助理系统的启发
6.1 增加“深度工作块”记录
每日记录中可以新增一个默认记录维度:
- 深度工作开始时间
- 深度工作结束时间
- 专注对象
- 输出物
- 是否被打断
- 打断来源
- 自评分
这样可以从“我今天很忙”转为“我今天有多少可验证的深度产出”。
6.2 用领先指标代替滞后指标
不要只追踪最终成果,例如文章完成、方案提交、项目上线。更应该追踪可控领先指标,例如:本周深度工作小时数、无打断块数量、重要项目推进块数量。
6.3 每周做深度工作复盘
每周复盘可以增加三个问题:
- 本周最重要目标是什么?
- 我为它投入了多少深度小时?
- 下周要减少哪一种浅层工作?
6.4 把“停工仪式”接入 daily_log
每天结束工作时记录:
这能降低晚上反复想工作的认知负担。
7. 最值得落地的 5 个动作
- 每天固定一个 90 分钟深度工作块,手机远离,网络按需关闭。
- 每周设定一个极重要目标,只追踪为它投入的深度小时数。
- 通勤或散步时做生产性冥想,只思考一个明确问题。
- 每周审计一次浅层工作,压缩低价值会议、消息和邮件。
- 每天下班前做停工仪式,写明遗留事项和明天第一步。
8. 一句话总结
《Deep Work》的核心不是“更努力工作”,而是把注意力从浅层忙碌中夺回来,集中到能真正改变能力、成果和人生质量的高价值任务上。
---
layout: post
title: 个人助理飞书多维表格同步 SOP
subtitle: Codex 个人助理沉淀
date: 2026-06-04 01:04:14 -0400
tags:
- 个人助理
- 项目
- feishu_base_sync
---
来源:notes/projects/feishu_base_sync/03_个人助理飞书同步SOP.md
个人助理飞书多维表格同步 SOP
1. 目标
把 codex_personal_assistant 本地个人助理目录中的任务、每日记录、阅读书籍、Markdown 文档资产和知识索引同步到飞书多维表格,方便在飞书端查看、检索和继续维护。
本 SOP 基于 2026-06-04 的实际执行记录沉淀。
2. 工作目录
cd /home/admin/code/cc-connect-work-space/codex_personal_assistant
3. 前置条件
3.1 lark-cli 可用
command -v lark-cli
lark-cli --version
3.2 用户授权有效
需要看到 user identity 为 ready,并且 scope 包含:
base:app:createbase:table:createbase:field:createbase:record:createbase:record:updatebase:record:readwiki:node:createdrive:file:upload
如果 user token 过期,重新发起授权:
lark-cli auth login --no-wait --json --domain base,wiki,docs,drive,markdown
把输出的 verification_url 发给用户授权。用户授权完成后执行:
lark-cli auth login --device-code '<device_code>'
4. 创建正式 Base
lark-cli base +base-create \
--as user \
--name 'Codex Personal Assistant' \
--time-zone Asia/Shanghai \
--format json
本次实际创建结果:
- Base 名称:
Codex Personal Assistant
- Base URL:https://my.feishu.cn/base/
- Base Token:
<base_token>
注意:飞书新建 Base 会自动带一个默认空表,名为 数据表。本次暂时保留。
5. 创建数据表
本次创建了 5 张表:
| 表名 |
Table ID |
用途 |
| 待办事项 |
tblq9GIYesEoELNe |
同步 tasks/*.md 中的任务。 |
| 每日记录 |
tblqceBluld0ggkk |
同步 logs/daily_log.md。 |
| 阅读书籍 |
tblyEkMACTSdVsj6 |
以书为粒度记录阅读状态。 |
| 文档资产 |
tblHEsyT90H1X2sc |
以 Markdown 文件为粒度记录飞书文档链接。 |
| 知识索引 |
tbleMlGdf84VSza6 |
同步 notes/knowledge_base.md 中的索引。 |
创建表命令示例:
lark-cli base +table-create \
--as user \
--base-token '<base_token>' \
--name '每日记录' \
--fields '[{"name":"日期","type":"text"},{"name":"标题","type":"text"}]' \
--format json
6. 字段设计注意事项
6.1 普通文本字段
{"name":"标题","type":"text"}
6.2 单选字段
{"name":"状态","type":"select","multiple":false,"options":[{"name":"Todo"},{"name":"Done"}]}
6.3 数字字段
{"name":"耗时分钟","type":"number"}
6.4 可点击 URL 字段
这是本次踩坑点。
错误做法:
{"name":"飞书文档链接","type":"text"}
这样飞书端会显示纯文本链接,移动端不能直接点击打开。
正确做法:
{"name":"内容梳理可打开","type":"text","style":{"type":"url"}}
飞书 Base 的 URL 样式字段本质仍是 type=text,但必须设置:
写入记录时,值仍然是普通 URL 字符串:
{"内容梳理可打开":"https://my.feishu.cn/file/xxx"}
CLI 读回时会显示为 Markdown 链接格式,说明飞书端已经按 URL 字段处理。
7. 上传 Markdown 到飞书
本次使用 lark-cli markdown +create 上传书籍 Markdown:
lark-cli markdown +create \
--as user \
--file 'notes/books/为什么精英都是时间控/02_方法卡片.md' \
--name '为什么精英都是时间控_02_方法卡片.md' \
--format json
本次上传结果:
| 本地文件 |
飞书链接 |
notes/books/为什么精英都是时间控/01_内容全梳理.md |
https://my.feishu.cn/file/W5ZIbFeLboGWa7xoI1FcxqjAn5c |
notes/books/为什么精英都是时间控/01_内容全梳理_基于EPUB新版.md |
https://my.feishu.cn/file/VDC1bRPg9olXzhxQnEmcUcqJnfg |
notes/books/为什么精英都是时间控/02_方法卡片.md |
https://my.feishu.cn/file/HhnibI4WRooaYkxkbyUcImRsnoI |
注意:不要用 company_analyze 的 create_doc_from_md.py 默认上传,除非显式设置:
否则它会写入研报项目的旧多维表格。
8. 写入记录
使用 record-upsert:
lark-cli base +record-upsert \
--as user \
--base-token '<base_token>' \
--table-id '<table_id>' \
--json '{"标题":"早晨通勤开始","日期":"2026-06-04"}' \
--format json
更新已有记录时传 --record-id:
lark-cli base +record-upsert \
--as user \
--base-token '<base_token>' \
--table-id '<table_id>' \
--record-id '<record_id>' \
--json '{"最后同步时间":"2026-06-04 10:38:00"}' \
--format json
本次写入记录数:
| 表名 |
记录数 |
| 待办事项 |
0 |
| 每日记录 |
10 |
| 阅读书籍 |
1 |
| 文档资产 |
3 |
| 知识索引 |
4 |
9. 本次数据来源
9.1 每日记录
来源:logs/daily_log.md
同步内容:
- 2026-06-03 返程通勤、家务记录。
- 2026-06-04 早晨打车通勤记录。
9.2 阅读书籍
来源:notes/books/为什么精英都是时间控/
同步内容:
- 书名:为什么精英都是时间控
- 作者:桦泽紫苑
- 状态:复盘中
- 主题:时间管理、精力管理、个人成长
9.3 文档资产
来源:notes/books/**/*.md
每个 Markdown 一条记录,包含:
- 标题
- 类型
- 所属主题
- 本地路径
- 飞书文档链接
- 摘要
- 标签
- 最后修改时间
- 最后同步时间
9.4 知识索引
来源:notes/knowledge_base.md
同步了 Projects 和 Reading Notes 中已有索引。
10. 验证方法
查看表列表:
lark-cli base +table-list \
--as user \
--base-token <base_token> \
--format json
查看记录:
lark-cli base +record-list \
--as user \
--base-token <base_token> \
--table-id tblqceBluld0ggkk \
--format json
统计记录数:
lark-cli base +record-list \
--as user \
--base-token <base_token> \
--table-id tblqceBluld0ggkk \
--format json | jq '.data.data | length'
注意:record-list 返回结构是 .data.data,不是 .data.items。
11. 已发现问题与修正
11.1 链接字段显示为纯文本
问题:手机端看到的是纯文本 URL,不能直接打开。
原因:字段创建成了普通文本字段:
{"type":"text","style":{"type":"plain"}}
修正:创建 URL 样式字段:
{"type":"text","style":{"type":"url"}}
并删除旧纯文本字段。
11.2 bot profile 权限不足
company_analyze bot profile 可以创建 wiki bitable 节点,但缺少 Base 表/字段/记录权限。
正确方式:使用用户授权后的默认 profile,并显式 --as user。
11.3 默认空表残留
Base 创建后自动生成默认表 数据表:
- Table ID:
tbl94z2vTjOylux4
目前保留,后续可以删除。
12. 后续改进
- 把
.tmp/write_personal_assistant_records.py 整理成正式脚本:scripts/sync_to_feishu_base.py。
- 增加本地配置文件,保存 Base Token、Table ID、字段名映射。
- 实现按业务键 upsert,避免重复写入同一条 daily log 或文档资产。
- 删除默认空表
数据表。
- 后续任务文件有内容后,同步
tasks/todo.md、tasks/in_progress.md、tasks/done.md。
13. 正式同步脚本
已将手工同步流程整理为正式脚本:
python3 scripts/sync_to_feishu_base.py
配置文件:
Dry run:
python3 scripts/sync_to_feishu_base.py --dry-run
脚本同步逻辑:
- Markdown 仍是本地源数据。
- 脚本解析 Markdown 生成结构化 records。
- 使用
lark-cli base +record-list 读取已有记录。
- 使用业务键匹配已有记录,命中则 update,未命中则 create。
- 使用
lark-cli base +record-upsert 写入飞书。
当前业务键:
| 表 |
业务键 |
| 待办事项 |
来源文件 + 标题 |
| 每日记录 |
日期 + 时间 + 详情 |
| 阅读书籍 |
书名 |
| 文档资产 |
本地路径 |
| 知识索引 |
路径 |
调试结果:
python3 -m py_compile scripts/sync_to_feishu_base.py 通过。--dry-run 正常输出待写入记录。- 真实同步成功。
- 第二次真实同步命中相同 record_id,未产生重复记录。
当前记录数:
| 表名 |
记录数 |
| 待办事项 |
2 |
| 每日记录 |
13 |
| 阅读书籍 |
1 |
| 文档资产 |
3 |
| 知识索引 |
7 |
14. 创建飞书 Docx 文档而不是 Markdown 文件
读书笔记类 Markdown 应创建为飞书 docx 文档,而不是上传为飞书 Drive Markdown 文件。
推荐命令:
lark-cli docs +create \
--api-version v2 \
--as user \
--title '<文档标题>' \
--content @'<本地 Markdown 路径>' \
--format json
不要使用:
lark-cli markdown +create --file <md>
原因:
markdown +create 创建的是飞书文件,链接形态是 /file/...。docs +create 创建的是飞书文档,链接形态是 /docx/...,更适合阅读和后续编辑。
也不要复用 company_analyze 的 create_doc_from_md.py,原因见根目录 AGENTS.md。
创建 docx 后,把返回的 data.document.url 写入 config/feishu_base.json 的 book_file_links,再运行:
python3 scripts/sync_to_feishu_base.py
---
layout: post
title: 个人助理多维表格同步结果(2026-06-04)
subtitle: Codex 个人助理沉淀
date: 2026-06-04 01:04:14 -0400
tags:
- 个人助理
- 项目
- feishu_base_sync
---
来源:notes/projects/feishu_base_sync/02_同步结果_20260604.md
个人助理多维表格同步结果(2026-06-04)
Base
- 名称:Codex Personal Assistant
- URL:https://my.feishu.cn/base/
- Base Token:
<base_token>
表结构与记录数
| 表名 |
Table ID |
记录数 |
说明 |
| 待办事项 |
tblq9GIYesEoELNe |
0 |
当前本地待办为空,未造假写入。 |
| 每日记录 |
tblqceBluld0ggkk |
10 |
已同步 logs/daily_log.md 中 2026-06-03、2026-06-04 的记录。 |
| 阅读书籍 |
tblyEkMACTSdVsj6 |
1 |
已同步《为什么精英都是时间控》。 |
| 文档资产 |
tblHEsyT90H1X2sc |
3 |
已同步并链接 3 份书籍 Markdown。 |
| 知识索引 |
tbleMlGdf84VSza6 |
4 |
已同步知识库中的项目与阅读索引。 |
Base 创建时自动生成的默认空表仍保留:
- 表名:数据表
- Table ID:
tbl94z2vTjOylux4
已上传的书籍 Markdown
| 本地文件 |
飞书链接 |
notes/books/为什么精英都是时间控/01_内容全梳理.md |
https://my.feishu.cn/file/W5ZIbFeLboGWa7xoI1FcxqjAn5c |
notes/books/为什么精英都是时间控/01_内容全梳理_基于EPUB新版.md |
https://my.feishu.cn/file/VDC1bRPg9olXzhxQnEmcUcqJnfg |
notes/books/为什么精英都是时间控/02_方法卡片.md |
https://my.feishu.cn/file/HhnibI4WRooaYkxkbyUcImRsnoI |
写入范围
本次同步写入:
logs/daily_log.mdnotes/books/为什么精英都是时间控/*.mdnotes/knowledge_base.md 中的索引条目
未写入:
tasks/todo.md、tasks/in_progress.md、tasks/done.md:当前没有有效任务内容。inbox/capture.md:当前为空。
后续建议
- 删除默认空表
数据表,避免混淆。
- 将
.tmp/write_personal_assistant_records.py 整理为正式脚本 scripts/sync_to_feishu_base.py。
- 后续改成 upsert by business key,避免重复写入同一条 daily log 或文档资产。
链接展示调整
2026-06-04 10:30 调整 阅读书籍 表的飞书链接展示:
- 旧字段
飞书文档链接 不再堆叠 3 个 URL,改为说明:见文档资产表;下方字段为常用入口。
- 新增字段:
内容梳理链接
- 新增字段:
EPUB新版链接
- 新增字段:
方法卡片链接
这样在移动端查看单本书时,每个常用入口单独占一个字段,比多行 URL 堆在同一个字段里更清晰。
URL 字段修正
2026-06-04 10:38 再次修正 阅读书籍 表链接字段:
- 根因:普通
text 字段即使填入 URL,在飞书端内也显示为纯文本,移动端不能直接点击打开。
- 正确字段定义:
{"type":"text","style":{"type":"url"}}。
- 新增可点击字段:
内容梳理可打开、EPUB新版可打开、方法卡片可打开。
- 已删除旧纯文本字段:
飞书文档链接、内容梳理链接、EPUB新版链接、方法卡片链接、测试字段 内容梳理。
新书同步:How to Break Up with Your Phone
2026-06-04 已将新上传 EPUB 产生的结构化笔记创建为飞书文档,并同步到多维表格。
飞书文档
| 本地文件 |
飞书链接 |
notes/books/How to Break Up with Your Phone/01_内容全梳理.md |
https://my.feishu.cn/file/XO9PbjEAfoKJlkx6eVscbjDqnnb |
notes/books/How to Break Up with Your Phone/02_方法卡片.md |
https://my.feishu.cn/file/VOgabuV6Yo3oVqxxDuCcrSSCnKc |
多维表格写入
阅读书籍:新增 How to Break Up with Your Phone,record_id=recvly0dTOxkyL文档资产:新增 2 条,record_id=recvly0eNHZpX2、recvly0f8SCwWv知识索引:新增 3 条,record_id=recvly0i6lkScW、recvly0ioo5uQT、recvly0iFJF8PO
当前记录数
| 表名 |
记录数 |
| 阅读书籍 |
2 |
| 文档资产 |
5 |
| 知识索引 |
10 |
说明:没有上传 EPUB 原文全文到飞书,仅上传了结构化笔记和方法卡片。
Markdown 文件链接迁移为飞书 Docx 文档
2026-06-04 13:02 已将现有 5 个结构化 Markdown 笔记重新创建为飞书 docx 文档,并更新多维表格链接。
新 Docx 链接
| 本地文件 |
飞书 Docx 链接 |
notes/books/为什么精英都是时间控/01_内容全梳理.md |
https://my.feishu.cn/docx/BKhVdgb1JoQcrJxSF6WcXpGOnzd |
notes/books/为什么精英都是时间控/01_内容全梳理_基于EPUB新版.md |
https://my.feishu.cn/docx/SQtFdt7gXoBWynxqd7FcjnlSnLb |
notes/books/为什么精英都是时间控/02_方法卡片.md |
https://my.feishu.cn/docx/J9OddtMgMo9N6ixZBQjcRgHfn5g |
notes/books/How to Break Up with Your Phone/01_内容全梳理.md |
https://my.feishu.cn/docx/Sb5wd7mTOoD8f2xbebmcYWEtnJf |
notes/books/How to Break Up with Your Phone/02_方法卡片.md |
https://my.feishu.cn/docx/JXrzdySu4oumoFxwy05cRJDpn7m |
执行原则
- 未复用
company_analyze 的任何飞书脚本。
- 使用
lark-cli docs +create --api-version v2 --as user --content @<markdown> 创建 docx。
config/feishu_base.json 中的 book_file_links 已替换为 docx 链接。- 多维表格中的
阅读书籍、文档资产、知识索引 链接已通过 scripts/sync_to_feishu_base.py 更新。
---
layout: post
title: 《How to Break Up with Your Phone》方法卡片
subtitle: Codex 个人助理沉淀
date: 2026-06-04 00:42:25 -0400
tags:
- 个人助理
- 读书笔记
- How to Break Up with Your Phone
---
来源:notes/books/How to Break Up with Your Phone/02_方法卡片.md
《How to Break Up with Your Phone》方法卡片
用途:把书中的手机关系重建方法转成个人助理可执行规则,用于日常记录、提醒和复盘。
卡片 01:WWW 手机冲动三问
- 适用场景:想无意识拿起手机时。
- 触发条件:工作中、等电梯、排队、睡前、刚醒来。
- 操作步骤:问自己
What For? 我要拿手机做什么;Why Now? 为什么必须现在做;What Else? 有没有更好的替代。
- 失败信号:手已经解锁手机,但说不出具体目的。
- 补救动作:把想做的事写进 inbox,手机放回原处。
- 效果指标:一天中无意识解锁次数减少。
卡片 02:手机起床时间
- 适用场景:早晨起床后。
- 触发条件:醒来后想立刻看微信、新闻、行情或社交媒体。
- 操作步骤:给手机设定比人晚 60 分钟的“起床时间”。
- 失败信号:睁眼后第一件事是看手机。
- 补救动作:前一晚把手机放到卧室外,使用非手机闹钟。
- 效果指标:上午第一小时是否更清醒、更少焦虑。
卡片 03:无手机区域
- 适用场景:餐桌、卧室、会议、亲密谈话、深度工作。
- 触发条件:手机出现在这些区域的桌面或手边。
- 操作步骤:提前指定区域规则,进入区域前把手机放到固定位置。
- 失败信号:吃饭或聊天时频繁看屏幕。
- 补救动作:把手机屏幕朝下不够,必须离开桌面。
- 效果指标:线下互动是否更完整。
卡片 04:应用分诊
- 适用场景:手机 app 太多,打开手机就被带走。
- 触发条件:主屏上有社交、新闻、短视频、游戏、购物等高诱惑 app。
- 操作步骤:把 app 分为工具、垃圾食品、老虎机、杂物、不可删除;删除或移走高风险 app。
- 失败信号:打开手机查一件事,十分钟后还在刷别的。
- 补救动作:把高风险 app 从手机移到电脑端或限制时段。
- 效果指标:手机主屏只剩真正工具。
卡片 05:通知最小化
- 适用场景:手机频繁震动、弹窗、红点。
- 触发条件:通知打断工作或休息。
- 操作步骤:关闭非必要通知,只保留真实紧急渠道。
- 失败信号:手机提示一响就必须看。
- 补救动作:批量关闭通知,设定固定查看窗口。
- 效果指标:工作块中断次数下降。
卡片 06:深度工作物理隔离
- 适用场景:写方案、读书、编码、投资研究。
- 触发条件:进入 45/90 分钟专注块。
- 操作步骤:手机离开手臂范围,最好放到另一个房间或包里。
- 失败信号:卡住时拿手机找刺激。
- 补救动作:把“想查/想看”的冲动写在纸上,专注块结束再处理。
- 效果指标:专注块是否完整完成。
卡片 07:替代奖励清单
- 适用场景:拿手机是为了休息、逃避、社交或缓解焦虑。
- 触发条件:感觉累、烦、无聊、焦虑。
- 操作步骤:先识别想从手机获得的奖励,再用离线方式替代。
- 失败信号:刷完更累、更焦虑。
- 补救动作:建立替代清单,如散步、喝水、伸展、找人说话、纸质阅读。
- 效果指标:休息后是否真正恢复。
卡片 08:24 小时 Trial Separation
- 适用场景:需要重置手机关系。
- 触发条件:感觉手机严重影响睡眠、专注或关系。
- 操作步骤:提前安排 24 小时关闭手机和联网屏幕,准备纸质路线、联系人、替代活动和自动回复。
- 失败信号:没有准备就突然断网,导致焦虑和混乱。
- 补救动作:先做 4 小时或半天版本。
- 效果指标:分离后对手机依赖感是否下降。
卡片 09:数字安息日
- 适用场景:周末、休息日、需要恢复注意力时。
- 触发条件:一周内屏幕时间过高或精神持续紧绷。
- 操作步骤:固定半天或一天不使用非必要屏幕。
- 失败信号:休息日比工作日还碎片化。
- 补救动作:提前安排线下活动。
- 效果指标:休息质量和下一周启动状态。
卡片 10:手机关系复盘
- 适用场景:每周复盘。
- 触发条件:周末或周日晚上。
- 操作步骤:回答四个问题:我什么时候最容易被手机带走;哪些规则有效;哪些场景失败;下周只改一个什么规则。
- 失败信号:只说“少玩手机”,没有具体场景和规则。
- 补救动作:选择一个最小规则,例如“早餐前不看手机”。
- 效果指标:下周是否能稳定执行一个规则。
---
layout: post
title: 《How to Break Up with Your Phone》内容全梳理
subtitle: Codex 个人助理沉淀
date: 2026-06-04 00:42:25 -0400
tags:
- 个人助理
- 读书笔记
- How to Break Up with Your Phone
---
来源:notes/books/How to Break Up with Your Phone/01_内容全梳理.md
《How to Break Up with Your Phone》内容全梳理
中文暂译:《如何与你的手机分手》
作者:Catherine Price
出版:Ten Speed Press,2018
本笔记基于用户上传 EPUB 转换稿整理,目标是把全书内容转成个人助理可使用的行为改变知识资产。
1. 这本书解决什么问题
这本书不是劝人彻底不用手机,也不是反科技。它要解决的是:我们和手机之间的关系已经失衡,手机从“工具”变成了“注意力支配者”。
作者的核心判断是:问题不在手机本身,而在我们没有主动设计和手机的关系。手机应用、社交媒体、通知、无限滚动和不确定奖励机制,会不断诱导我们把注意力交出去。所谓“和手机分手”,不是扔掉手机,而是暂停、观察、重设边界,重新建立一种由自己掌控的长期关系。
可以把全书压缩成一句话:
你的生活质量,取决于你把注意力交给了什么;手机关系管理,本质是注意力主权管理。
2. 全书结构
全书分为两大部分。
Part I:The Wake-Up
前半部分负责“唤醒”:解释为什么手机这么难放下,以及长期过度使用手机对注意力、记忆、睡眠、压力、社交和满足感的影响。
章节包括:
- Our Phones Are Designed to Addict Us
- Putting the Dope in Dopamine
- The Tricks of the Trade
- Why Social Media Sucks
- The Truth about Multitasking
- Your Phone Is Changing Your Brain
- Your Phone Is Killing Your Attention Span
- Your Phone Messes with Your Memory
- Stress, Sleep, and Satisfaction
- How to Take Back Your Life
Part II:The Breakup
后半部分负责“行动”:提供 30 天计划,帮助读者从观察、整理、改环境、训练注意力,到完成一次 24 小时 Trial Separation,再建立长期规则。
四周结构:
- Week 1:Technology Triage,技术分诊,先观察和诊断。
- Week 2:Changing Your Habits,改变习惯和环境。
- Week 3:Reclaiming Your Brain,重新训练大脑和注意力。
- Week 4 and Beyond:Your New Relationship,建立新的长期关系。
3. 核心观点
3.1 手机不是中立工具,它被设计成难以放下
作者强调,智能手机和社交应用利用了人类大脑的弱点:新奇偏好、不确定奖励、社交认可、焦虑缓解、逃避无聊、个性化推荐。很多产品机制不是为了让你更幸福,而是为了让你停留更久。
这对个人助理系统的启发是:不要把“少刷手机”理解为意志力问题,而要理解为环境设计问题。只靠自控很脆弱,真正有效的是减少触发器、降低入口吸引力、提高无意识使用成本。
3.2 多任务不等于高效,频繁切换会损伤深度注意力
书中反复说明,多任务处理更多时候是任务切换。每一次切换都会产生认知成本,打断工作记忆,降低效率。手机最危险的地方不是单次使用耗时,而是它制造了大量碎片化切换,让人很难进入完整思考。
对日常工作来说,这意味着:
- 深度工作时手机不能只是“静音”,最好物理移开。
- 通知不是小打扰,而是注意力系统的结构性破坏。
- 检查手机的动作会让任务边界变模糊,进而拉低产出质量。
3.3 手机会改变记忆、创造力和思考深度
作者把注意力、工作记忆、长期记忆和创造力放在一起讨论。一个人如果不断接收碎片刺激,大脑就很难把信息转成长期记忆,也很难在不同想法之间建立连接。
创造力需要空白、无聊和游荡的思维。手机填满了这些空白,所以人会感觉“不无聊”,但也更难产生深层洞察。
个人助理落地:每天需要保留“无输入时段”,例如通勤、散步、洗澡后、睡前,不要马上用手机填满。
3.4 关系修复不是禁用,而是重新定义手机的角色
书中最有价值的地方,是没有把手机妖魔化。作者承认手机有很多真实价值:联系、导航、拍照、工具、信息查询。目标是把手机重新降级为“工具”,而不是让它变成默认注意力入口。
关键问题不是“能不能用手机”,而是:
- 我为什么现在拿起手机?
- 我想从手机那里得到什么?
- 这件事有没有更好的离线替代方式?
- 使用之后,我感觉更清醒,还是更焦躁?
4. 30 天计划全梳理
Week 1:Technology Triage
目标:先观察,不急着改变。建立对自己手机使用模式的真实认知。
核心动作:
- 安装使用时间追踪工具。
- 记录自己什么时候、为什么拿起手机。
- 识别让自己感觉好和感觉坏的使用场景。
- 创建第一批 speed bumps,即在拿起手机前增加停顿。
- 明确自己想把时间和注意力用到哪里。
这一周的关键不是立刻减少时间,而是让自动行为变成可观察行为。
Week 2:Changing Your Habits
目标:通过环境设计改变习惯回路。
核心动作:
- 清理应用,把 app 分成工具类、垃圾食品类、老虎机类、杂物类、实用类等。
- 删除或移走最容易让自己沉迷的 app。
- 关闭不必要通知。
- 改变手机外观,例如灰度、整理主屏、减少视觉诱惑。
- 建立无手机区域,例如餐桌、卧室、会议、亲密谈话。
- 给手机设置“起床时间”,不要醒来后立刻碰手机。
这一周的本质是:不是和欲望硬拼,而是让坏习惯更难启动,让好替代更容易发生。
Week 3:Reclaiming Your Brain
目标:重新训练注意力,恢复大脑的自主调节能力。
核心动作:
- 练习 Stop, Breathe, and Be:停下、呼吸、回到当下。
- 练习短时间静止和无聊,不立刻找刺激。
- 做注意力训练,例如阅读、冥想、单任务。
- 准备 24 小时 Trial Separation。
- 在试分离前准备替代活动、联系人、纸质清单、自动回复等。
- 完成一次 24 小时无手机或无联网屏幕实验。
这一周的关键是让自己重新体验:没有手机也可以生活,甚至可能更平静、更有连接感。
Week 4 and Beyond:Your New Relationship
目标:把短期分手转成长期关系规则。
核心动作:
- 复盘 24 小时 Trial Separation:看见了什么、想到什么、感觉如何、还好奇什么。
- 制定长期手机规则。
- 处理邮件、社交媒体、开车、关联账号等具体场景。
- 优化设备系统:勿扰模式、离线地图、家庭固定电话或备用方案、低功能手机等。
- 建立长期原则,例如健康手机例程、礼貌规则、定期 phast、练习暂停、练习注意力。
这一周的关键是:不要只靠一次 detox,而是形成可持续的“新关系”。
5. 重要概念表
| 概念 |
含义 |
个人助理可用方式 |
| Breakup |
和手机关系重设,不是彻底不用手机 |
将“手机使用”作为可设计对象 |
| Speed Bump |
在自动拿手机前制造停顿 |
记录触发器,设置物理/流程阻力 |
| WWW |
What For / Why Now / What Else |
每次冲动前问三个问题 |
| Trial Separation |
24 小时手机分离实验 |
可安排为周末实验项目 |
| Phubbing |
用手机冷落眼前人 |
建立餐桌/会议无手机规则 |
| Digital Sabbath |
定期数字安息日 |
每周固定半天或一天无屏幕 |
| No-Phone Zone |
无手机区域 |
卧室、餐桌、工位深度工作时段 |
| Phone Wake-Up Time |
手机起床时间 |
人先起床,手机晚一小时“上班” |
6. 和个人助理系统的关系
这本书适合直接转化为个人助理的行为规则:
- 每天记录关键手机使用场景和触发器。
- 在 daily_log 中增加“注意力/手机使用”分类。
- 把手机规则写入 Preferences。
- 把 30 天计划拆成 todo 和实验记录。
- 每周复盘哪些规则有效,哪些需要调整。
7. 可落地实验
实验 1:手机起床时间
规则:醒来后 60 分钟内不看手机。
替代:洗漱、喝水、早餐、纸质阅读、今天第一任务。
记录:是否做到;做到后上午状态如何。
实验 2:餐桌无手机
规则:吃饭时手机不放桌面。
替代:聊天、观察、专心吃饭。
记录:是否更放松,是否出现拿手机冲动。
实验 3:深度工作物理隔离
规则:45/90 分钟专注块期间,手机离开手臂范围。
替代:把想查的东西写到纸上或 inbox。
记录:专注块是否更完整。
实验 4:24 小时 Trial Separation
规则:选一个周末 24 小时关闭手机或远离联网屏幕。
准备:联系人、纸质路线、替代活动、自动回复。
记录:最难、最好、最意外、后续规则。
8. 读后判断
这本书的强项不是理论深度,而是把“手机成瘾/注意力劫持”变成一个可操作的 30 天行为改变计划。它适合作为个人助理系统里的“注意力卫生”基础手册。
对于当前个人助理目录,建议下一步不是继续泛泛总结,而是直接生成:
02_方法卡片.md:把书中的方法转成规则卡片。03_30天手机关系重建计划.md:按 30 天做个人化计划。04_实验记录.md:开始记录手机起床时间、无手机区域、24 小时分离实验。
---
layout: post
title: 个人助理多维表格同步方案
subtitle: Codex 个人助理沉淀
date: 2026-06-03 22:15:48 -0400
tags:
- 个人助理
- 项目
- feishu_base_sync
---
来源:notes/projects/feishu_base_sync/01_个人助理多维表格同步方案.md
个人助理多维表格同步方案
1. lark-cli 能力验证
当前可用能力
lark-cli 当前没有 bitable 命令,相关能力在 base 命令下:
base +base-create:创建 Base 资源base +table-create:创建数据表base +field-create:创建字段base +record-upsert:创建/更新记录base +record-list / +record-search:读取记录
另一个可用入口是:
wiki +node-create --obj-type bitable:创建多维表格 Wiki 节点
实测结果
已用 company_analyze profile 测试:
- 直接
base +base-create 失败,缺少权限:base:app:create
- 通过
wiki +node-create --obj-type bitable 创建多维表格节点成功
- 对该 bitable 继续执行
base +table-list 失败,缺少权限:base:table:read
- 创建表
base +table-create 失败,缺少权限:base:table:create
测试创建的临时多维表格:
- 标题:
Codex Personal Assistant Test Bitable 20260604
- Wiki URL:
https://my.feishu.cn/wiki/UF9iw1JixiPgzjkgS2scak6cnxe
- Base/Object Token:
LhPJbBJZBansjXshH0DcZEWbn5p
结论:当前 lark-cli 支持创建多维表格,但当前飞书应用权限不完整。现在只能创建 bitable 容器,不能创建表、字段或写记录。
用户授权后复测结果
2026-06-04 通过 lark-cli auth login --domain base,wiki,docs,drive,markdown 由用户完成授权后,默认 profile 已具备 Base 用户权限。
已成功验证:
- 创建 Base:
Codex Personal Assistant Auth Test 20260604
- Base URL:
https://my.feishu.cn/base/IYkUbQQcGa2B8gsYLYncVp6sndb
- Base Token:
IYkUbQQcGa2B8gsYLYncVp6sndb
- 创建表:
待办事项
- Table ID:
tblTpZg5MFIk12GK
- 创建字段:
标题、状态、优先级、来源文件、更新时间
- 写入测试记录:
验证个人助理多维表格写入
- Record ID:
recvlxnxCxkZmZ
更新后的结论:使用用户授权后的默认 profile,可以完成 Base 创建、表创建、字段创建和记录写入。后续正式同步个人助理数据应优先使用该用户授权 profile,而不是 company_analyze bot profile。
2. 需要补充的飞书权限
至少需要申请:
base:app:create:直接创建 Base 资源,可选;如果继续用 wiki 创建 bitable,可以不作为第一优先级。base:table:read:读取数据表。base:table:create:创建数据表。base:field:read:读取字段。base:field:create:创建字段。base:record:read:读取记录,用于去重和同步。base:record:create:新增记录。base:record:update:更新记录。
如果要删除、归档或重建:
base:table:deletebase:record:delete
3. 当前个人助理目录可入表内容
当前目录:/home/admin/code/cc-connect-work-space/codex_personal_assistant
3.1 待办事项
来源文件:
tasks/todo.mdtasks/in_progress.mdtasks/done.md
当前内容基本为空,但结构适合入表。
建议表:待办事项
字段:
标题:文本,任务标题。状态:单选,Todo / In Progress / Done。优先级:单选,High / Medium / Low。截止时间:日期时间,可空。下一步动作:长文本。来源文件:文本,如 tasks/todo.md。本地路径:文本。创建时间:日期时间。更新时间:日期时间。备注:长文本。
3.2 每日记录
来源文件:
当前已有:
- 2026-06-03 返程通勤、家务记录。
- 2026-06-04 早晨打车通勤记录。
建议表:每日记录
字段:
日期:日期。时间:文本或日期时间。类型:单选,通勤 / 家务 / 工作 / 阅读 / 生活 / 复盘。标题:文本。详情:长文本。耗时分钟:数字。地点/节点:文本。交通方式:单选,打车 / 地铁 / 步行 / 公交 / 自驾 / 其他。来源文件:文本。本地路径:文本。
3.3 阅读书籍
来源目录:
当前书籍 Markdown:
01_内容全梳理.md01_内容全梳理_基于EPUB新版.md02_方法卡片.md
建议表:阅读书籍
字段:
书名:文本。作者:文本。状态:单选,待读 / 阅读中 / 已读 / 复盘中。主题:多选,例如 时间管理、精力管理、个人成长。开始日期:日期。完成日期:日期。一句话总结:文本。本地目录:文本。飞书文档链接:URL 或文本,指向书籍总文档或索引文档。最后同步时间:日期时间。
3.4 阅读笔记 / 文档资产
来源:
notes/books/**/*.mdnotes/knowledge_base.md- 未来的
notes/projects/**/*.md、notes/topics/**/*.md
建议表:文档资产
字段:
标题:文本。类型:单选,书籍内容梳理 / 方法卡片 / 落地计划 / 复盘 / 项目笔记 / 主题笔记。所属主题:文本,如 为什么精英都是时间控。本地路径:文本。飞书文档链接:URL 或文本。摘要:长文本。标签:多选。最后修改时间:日期时间。最后同步时间:日期时间。
3.5 知识库索引
来源文件:
建议表:知识索引
字段:
标题:文本。分类:单选,People / Projects / Preferences / References / Reading Notes。路径:文本。摘要:长文本。关联文档链接:URL 或文本。更新时间:日期时间。
4. 书籍 Markdown 上传到飞书并回填链接
推荐流程:
- 扫描
notes/books/<书名>/*.md。
- 每个 Markdown 上传为飞书文档。
- 上传时必须设置
FEISHU_SKIP_BITABLE=1,避免上传脚本自动写入旧多维表格。
- 拿到飞书文档链接。
- 在
文档资产 表写一条记录。
- 在
阅读书籍 表写或更新该书记录,保存书籍目录、总链接和同步状态。
推荐使用已有脚本:
FEISHU_SKIP_BITABLE=1 python /home/admin/code/cc-connect-work-space/ashare_monitor/company_analyze/invest_community/tools/feishu/create_doc_from_md.py <markdown_file>
注意:这个脚本当前依赖 company_analyze/invest_community/.env 的飞书配置。为了个人助理长期使用,建议迁移出一个独立的个人助理飞书配置,避免继续复用研报项目的表格配置。
5. 推荐正式多维表格结构
建议新建一个 Base:Codex Personal Assistant
包含 5 张表:
第一阶段优先同步:
每日记录:已有真实数据,结构稳定。阅读书籍:已有一本书和 3 份 Markdown,可以验证“上传文档 -> 回填链接”。文档资产:用于承载所有 Markdown 文档链接。
第二阶段再同步:
待办事项:当前内容为空,等后续任务体系稳定后再自动同步。知识索引:可从 knowledge_base.md 解析,但建议先统一索引格式。
6. 下一步动作
- 在飞书开放平台给
company_analyze 应用补充 Base 权限,至少包含 table/field/record read/create/update。
- 权限生效后,用
wiki +node-create --obj-type bitable 正式创建 Codex Personal Assistant Base。
- 创建 5 张表和字段。
- 写一个同步脚本:
scripts/sync_to_feishu_base.py。
- 先同步
logs/daily_log.md 和 notes/books/为什么精英都是时间控/*.md。
---
layout: post
title: 《为什么精英都是时间控》内容全梳理(基于 EPUB 新版)
subtitle: Codex 个人助理沉淀
date: 2026-06-02 23:01:38 -0400
tags:
- 个人助理
- 读书笔记
- 为什么精英都是时间控
---
来源:notes/books/为什么精英都是时间控/01_内容全梳理_基于EPUB新版.md
《为什么精英都是时间控》内容全梳理(基于 EPUB 新版)
说明:本版基于已上传 EPUB 文件实读整理,不再主要依赖外部资料。目标不是复述全文,而是把全书结构、核心观点和可落地方法重新梳理成个人助理可使用的知识资产。
1. 书籍与文件信息
- 书名:为什么精英都是时间控
- 作者:【日】桦泽紫苑
- 译者:郭勇
- 出版社:湖南文艺出版社
- EPUB 文本规模:约 10.5 万字/字符级文本
- EPUB 结构:前言、序章、6 个正文章节、后记、时间管理日志
这本书的真实主题不是“更努力地挤时间”,而是“根据大脑专注力曲线重新设计一天”。作者把时间管理建立在专注力、睡眠、运动、重启、自我投资这些因素上,核心目标是:在不牺牲健康和自由时间的情况下,提高单位时间产出。
2. 全书核心框架
全书可以压缩成一个公式和一条路径:
- 公式:
工作量 = 专注力 × 时间
- 路径:提高专注力密度 -> 在正确时段做正确任务 -> 用重启恢复脑力 -> 省出时间 -> 投入自我投资和主动娱乐 -> 形成长期正循环
作者反复强调,人的时间每天都是 24 小时,但不同时间段的大脑状态不同。真正的时间管理不是平均分配时间,而是把“高专注力时段”留给高价值任务,把低专注力时段用于沟通、杂事、恢复和低负荷任务。
3. 前言:为什么要改变时间管理方式
前言先建立问题意识:很多人想工作更高效、学习更多、陪伴家人、休闲放松,但现实是每天被工作追着跑。
作者用自己的经历说明时间管理的必要性:他曾经作为医生长期处于高压工作状态,出现由压力导致的身体问题,于是开始重新设计时间使用方式。后来,他形成了一套高产工作与大量自由时间并存的生活方式。
前言的重点不是炫耀工作量,而是提出一个判断:如果时间使用方式不变,人生轨道很难改变。时间是人生的底层资源,管理时间其实是在管理人生结构。
4. 序章:神之时间管理术四原则
序章是全书的总纲,提出四个原则和一个最终目标。
4.1 第一原则:以专注力为中心分配时间
核心观点:时间本身不是均质资源,专注力高的 1 小时和专注力低的 1 小时价值不同。
作者强调大脑有黄金时间,尤其是早晨刚醒后的几个小时。高专注力时段应放入写作、分析、决策、复杂学习等任务,低专注力时段则处理沟通、杂务、简单执行。
这里最重要的方法是“时间拼图”:不是把任务随便塞进日程,而是根据任务所需专注力,把它放到匹配的时间块里。
4.2 第二原则:重启专注力,创造时间
核心观点:专注力会消耗,也可以通过睡眠、休息、运动、场景切换恢复。
作者把传统时间管理称为“一维”,只看时间长度;把自己的方法称为“二维”,同时看时间和专注力。真正提高产出的方法不是一直硬扛,而是在疲劳前休息,在状态下降时重启。
睡眠被放在很重要的位置:睡眠不是浪费时间,而是恢复专注力的基础投资。
4.3 第三原则:掌握高效率工作方式
核心观点:通过工作方式优化,把同样任务用更少时间完成。
这一部分引出后文的 For You、ASAP、提前行动、严格守时、快速判断等方法。作者认为高效率不只是个人技巧,也包含对协作者时间成本的尊重。
4.4 第四原则:把时间用于自我投资
核心观点:时间管理的目的不是让自己更忙,而是创造可用于成长和生活的时间。
如果省下来的时间继续全部投入工作,时间管理就会变成新的压榨工具。正确做法是把自由时间投入学习、运动、关系、兴趣和恢复,让能力继续提高。
4.5 最终目标:为了快乐使用时间
作者在序章末尾明确说,时间管理最终不是为了工作本身,而是为了更自由、更丰富、更快乐地生活。
5. 第一章:提高专注力的方法
第一章解决的是“如何让一个时间块更有效”。
5.1 15/45/90 法则
作者把专注节奏拆成 15 分钟、45 分钟、90 分钟三个尺度:
- 15 分钟:适合高度紧张的小段专注,也适合启动困难时使用。
- 45 分钟:接近课堂和常规工作块,适合中等强度任务。
- 90 分钟:适合深度工作,但需要中间有节奏地休息。
这套方法的落地点是:不要指望自己无限专注,要顺着大脑节奏安排任务。
5.2 杂念排除法
作者把杂念分为四类:
- 外物造成的杂念:桌面、物品、文件、电脑环境混乱。
- 思考造成的杂念:脑子里挂着大量未决事项。
- 人造成的杂念:他人打断、开放环境干扰。
- 通信造成的杂念:邮件、聊天、通知、社交网络。
核心方法是“把杂念外部化”:想到的事写下来,环境中不必要的东西移走,通信集中处理,给自己创造专注空间。
5.3 时间限制工作术
作者认为截止时间会制造工作高峰。没有限制的任务会自然膨胀,有明确时间限制的任务更容易集中注意力。
这里的实践要点是:任务开始前先定义结束时间和交付标准,而不是边做边决定做到什么程度。
6. 第二章:利用早晨黄金时间
第二章解决的是“一天中最高价值时间怎么用”。
6.1 早晨是大脑黄金时间
作者认为早晨适合做专注性工作。对个人助理系统来说,这意味着上午默认不应该被消息、会议和琐事填满。
适合放在早晨的任务包括:
- 写作和输出
- 复杂分析
- 投资研究
- 代码设计
- 重要决策
- 深度学习
6.2 上班后最初 30 分钟
作者特别强调上班后的最初 30 分钟。这段时间如果立刻进入高价值任务,会显著提升全天产出;如果先处理消息和杂务,黄金状态会被消耗掉。
6.3 超轻松起床术
本章提供了 5 个早晨启动方法:
- 早上冲澡
- 开着窗帘睡觉,让早晨光线帮助唤醒
- 不动明王起床术,也就是醒来后避免赖床式翻滚
- 有节奏的运动
- 细嚼慢咽吃早餐
这些方法共同指向一个目标:尽快把大脑从睡眠状态切换到清醒、稳定、可专注状态。
6.4 早晨不该做的事
早晨最不应该做的是先接收大量低价值信息,比如刷手机、刷消息、看新闻。这会让高质量注意力被外部输入占用。
7. 第三章:午后重启术
第三章解决的是“下午效率下降怎么办”。
7.1 午餐外出重启
作者建议不要一直待在工位吃午餐。外出、咀嚼、走动、换环境,本质上都是在帮助大脑重启。
书中将午餐重启拆成三个角度:
- 血清素:帮助情绪和状态回归平稳。
- 场所神经元:换地方能刺激记忆和认知切换。
- 乙酰胆碱:与灵感、注意和认知活动相关。
这些解释不必机械理解成严格医学处方,但实践建议明确:午餐应该成为下午工作的恢复节点,而不是继续盯屏幕。
7.2 小睡技巧
作者推荐 20-30 分钟午睡。重点是短睡或闭眼休息,而不是长时间昏睡。
对执行来说,如果没有条件午睡,也可以做 5-10 分钟闭眼休息,让大脑暂停输入。
7.3 下午重启工作术
书中列出多种下午重启方法:
- 运动重启
- 更换场所
- 穿插重启
- 小憩重启
- 5 分钟小睡
下午不是适合硬扛的时间。更合理的安排是:用重启恢复执行力,然后处理沟通、整理、推进、复盘等任务。
7.4 下午工作方法
作者建议确定离开公司的时间,并使用“后有约定”工作术。也就是在工作后安排真实约定,用外部边界限制工作无限延长。
8. 第四章:夜晚、运动与睡眠
第四章解决的是“如何利用晚上,同时保护第二天状态”。
8.1 运动创造第二黄金时间
作者认为适度运动能让大脑恢复活跃,形成晚上的第二个高效窗口。尤其对于脑力劳动者,运动不是占用时间,而是在创造更高质量的时间。
但运动不能过度,也不宜过晚影响睡眠。
8.2 不让压力和疲惫过夜
作者强调下班后要把工作和生活切开。压力如果带到睡前,会影响睡眠,也会影响第二天的专注力。
实践上,可以把未完成事项写下来,并定义明天第一步,让大脑停止后台运转。
8.3 睡前 2 小时
睡前 2 小时决定睡眠质量。作者建议避免强刺激输入、工作、夜宵和让大脑兴奋的内容。
这部分可以转成个人助理规则:晚上后段不安排复杂决策和强输入,改为放松、轻阅读、复盘。
8.4 睡前 15 分钟
作者认为睡前 15 分钟适合记忆巩固。适合做轻复盘、记录当天有价值的事、回顾学习重点。
不适合在睡前继续输入大量新信息。
8.5 周末恢复
作者反对靠周末大量补觉恢复。他更推荐保持节律,并用运动、主动休息、互补休息来恢复。
9. 第五章:创造时间的工作术
第五章解决的是“如何减少工作中的拖延和损耗”。
9.1 For You 工作术
For You 的含义是为对方考虑,减少协作成本。它包括:
- ASAP 工作术:能立刻处理的小事不要堆积。
- 提前 30 分钟行动:给承诺和约定留缓冲。
- 严格守时:尊重他人时间,建立可信度。
这一章把效率和可靠性绑定在一起:高效不是只顾自己快,而是让整个协作链条更顺畅。
9.2 趁现在工作术
这一组方法专门处理拖延和未决事项:
- 2 分钟判断术
- 30 秒决断术
- 无法决断就标为未决,并安排日后决断
- 不只写截止日,而要写执行时间
- 立刻预约
- 和善于把握现在的人一起工作
核心思想是减少“悬而未决”的精神负担。很多时间不是被任务本身消耗,而是被反复犹豫、反复想起、反复切换消耗。
9.3 并行工作术
作者区分了低效的“一边做这个一边做那个”和合理的“并行工作”。
合理并行不是多任务同时抢注意力,而是在不同资源维度上安排任务。例如:
- 移动读书:通勤或等待时阅读。
- 耳学:走路、家务、移动时听内容。
- 思考:利用空白时间构思和整理问题。
关键是不要让两个高认知任务抢同一个注意力资源。
10. 第六章:自由时间、自我投资与自我更新
第六章解决的是“省出来的时间到底用来干什么”。
10.1 自由时间不要用于工作
作者明确反对把效率提升后省下来的时间继续全部填回工作。否则时间管理只会让人更忙。
正确方向是:工作追求质量提升,自由时间用于长期成长和生活质量。
10.2 投资自己
作者建议先投资主要专长,再扩展其他能力。对个人助理系统来说,这意味着学习计划需要有主线,不能只被兴趣和热点牵着走。
10.3 主动性娱乐
作者区分主动性娱乐和被动性娱乐。主动性娱乐更能恢复能量,例如运动、读书、创作、社交、旅行、兴趣活动;被动性娱乐容易让人消耗时间却不恢复状态。
重点不是完全禁止电视、游戏或短内容,而是避免自由时间被低质量被动娱乐自动吞掉。
10.4 玩乐清单
作者建议制作玩乐 TO DO 清单。这个方法很适合个人助理系统:提前记录想体验、想见、想去、想学的内容,避免有空时不知道做什么。
11. 后记与时间管理日志
后记说明作者为什么以神经科医生身份写时间管理书:他希望把脑科学、心理学和个人实践结合起来,帮助读者避免被工作压垮。
书末的时间管理日志说明,这本书不是只用于阅读,而是希望读者记录、实验、复盘。它和个人助理系统天然匹配:每天记录时间使用、专注状态、重启动作和明日优先级。
12. 全书方法总表
| 模块 |
方法 |
目的 |
| 专注力 |
15/45/90 法则 |
顺应注意力节奏 |
| 专注力 |
杂念排除法 |
减少外部和内部干扰 |
| 专注力 |
时间限制工作术 |
用截止边界提升密度 |
| 早晨 |
黄金时间保护 |
把最佳脑力用于高价值任务 |
| 早晨 |
起床启动术 |
快速进入清醒状态 |
| 白天 |
午餐外出 |
让午餐成为重启点 |
| 白天 |
20-30 分钟午睡 |
恢复下午专注力 |
| 白天 |
运动/换场景/穿插 |
对抗下午低效 |
| 夜晚 |
运动重启 |
创造第二高效窗口 |
| 夜晚 |
睡前 2 小时降刺激 |
保证睡眠质量 |
| 夜晚 |
睡前 15 分钟复盘 |
巩固记忆和正向体验 |
| 工作 |
ASAP |
减少小事堆积 |
| 工作 |
2 分钟判断/30 秒决断 |
减少未决负担 |
| 工作 |
立刻预约 |
把想法变成日历事件 |
| 学习 |
移动读书/耳学 |
利用碎片时间 |
| 自由时间 |
主专长投资 |
长期增强核心能力 |
| 自由时间 |
主动性娱乐 |
恢复能量和生活质量 |
| 复盘 |
时间管理日志 |
持续校准系统 |
13. 个人助理系统落地建议
基于 EPUB 新版梳理,本书最适合在个人助理系统中拆成 4 层:
- 规则层:上午保护深度工作,下午安排重启,晚上保护睡眠。
- 卡片层:把具体方法拆成可触发的执行卡片,目前已沉淀在
02_方法卡片.md。
- 日程层:把方法映射到每天的默认时间块,下一步应生成
03_个人落地计划.md。
- 复盘层:用
logs/daily_log.md 或专门的实验记录追踪执行效果。
14. 本版和旧版的差异
- 旧版主要基于外部资料和目录重构。
- 本版基于 EPUB 实际目录和正文结构重新整理。
- 本版补足了更多小节级方法,例如
For You、趁现在、午餐重启、睡前 15 分钟、玩乐清单等。
- 本版更适合继续生成个人落地计划和每日复盘模板。
15. 下一步
- 已完成:
02_方法卡片.md
- 建议继续:
03_个人落地计划.md
- 建议内容:每日时间块、一周执行模板、个人助理触发规则、复盘指标
---
layout: post
title: 《为什么精英都是时间控》方法卡片
subtitle: Codex 个人助理沉淀
date: 2026-06-02 21:36:00 -0400
tags:
- 个人助理
- 读书笔记
- 为什么精英都是时间控
---
来源:notes/books/为什么精英都是时间控/02_方法卡片.md
《为什么精英都是时间控》方法卡片
用途:把书中的时间管理原则转成可执行卡片,方便个人助理后续帮你安排日程、复盘执行和调整规则。
卡片 01:上午黄金时间保护
- 适用场景:每天上午有 1-3 小时相对完整时间。
- 触发条件:当天有写作、分析、决策、代码设计、投资研究等高认知任务。
- 操作步骤:先安排最难的产出任务,再处理沟通、消息和杂事。
- 失败信号:上午先刷消息、处理零碎事,导致核心任务被拖到下午。
- 补救动作:把当天最重要任务切成 45 分钟块,立刻开始第一块。
- 效果指标:上午是否完成一个可交付结果。
卡片 02:15/45/90 专注节奏
- 适用场景:任务需要持续注意力,但容易疲劳或走神。
- 触发条件:开始写作、阅读、编码、研究、整理资料。
- 操作步骤:小任务用 15 分钟,中等任务用 45 分钟,大块深度任务用 90 分钟。
- 失败信号:没有时间边界,做到一半开始拖延或分心。
- 补救动作:重新设一个更短的 15 分钟计时,只完成最小下一步。
- 效果指标:每个时间块结束时是否有明确产出。
卡片 03:时间限制工作术
- 适用场景:任务边界模糊,容易无限打磨。
- 触发条件:开始一件没有明确截止时间的任务。
- 操作步骤:先定结束时间,再定交付标准,最后开始执行。
- 失败信号:一直说“再改一下”,但结果没有本质提升。
- 补救动作:把交付标准降到“可用版本”,到点提交。
- 效果指标:是否按时结束并进入下一步。
卡片 04:后有约定工作术
- 适用场景:下午或傍晚工作容易拖长。
- 触发条件:发现下班时间不断后移。
- 操作步骤:在工作结束后安排一个真实约定,如运动、吃饭、阅读、散步。
- 失败信号:没有硬边界,工作自然膨胀。
- 补救动作:当天只保留一个必须完成项,其余移入待办。
- 效果指标:是否在约定前结束工作。
卡片 05:杂念外部化
- 适用场景:脑子里同时挂着很多事。
- 触发条件:做任务时反复想到其他未完成事项。
- 操作步骤:把所有杂念写到 inbox,再回到当前任务。
- 失败信号:边做边想,任务切换频繁。
- 补救动作:暂停 3 分钟清空脑内清单,只选择一件继续。
- 效果指标:当前任务是否能连续推进 15 分钟。
卡片 06:桌面和文件降噪
- 适用场景:工作环境或电脑文件混乱。
- 触发条件:找资料、找文件、切窗口耗时明显。
- 操作步骤:只保留当前任务需要的物品、窗口和文件夹。
- 失败信号:开始任务前先被无关内容吸引。
- 补救动作:创建临时目录或临时桌面,只放本轮材料。
- 效果指标:开始任务前准备时间是否少于 5 分钟。
卡片 07:通信批处理
- 适用场景:消息、邮件、群聊持续打断。
- 触发条件:当天需要深度工作。
- 操作步骤:设定固定消息处理窗口,其余时间关闭提醒。
- 失败信号:每次通知都打开看,深度任务被切碎。
- 补救动作:立即静音 45 分钟,并记录需要回复的人。
- 效果指标:上午是否有至少一个无通知时间块。
卡片 08:专注空间切换
- 适用场景:当前位置难以进入状态。
- 触发条件:同一任务启动失败两次。
- 操作步骤:换到会议室、咖啡店、图书馆或安静角落重新开始。
- 失败信号:在同一位置反复打开无关内容。
- 补救动作:带上最少工具,换一个场景做 15 分钟。
- 效果指标:换场景后是否开始产出。
卡片 09:早晨启动仪式
- 适用场景:起床后进入工作慢。
- 触发条件:醒来后昏沉、拖延、刷手机。
- 操作步骤:光照、洗漱、喝水、早餐咀嚼、短运动,按固定顺序启动。
- 失败信号:起床后 30 分钟仍未进入清醒状态。
- 补救动作:立刻出门走 5-10 分钟或冲澡。
- 效果指标:起床后 60 分钟内是否开始第一项核心任务。
卡片 10:上班后最初 30 分钟
- 适用场景:刚进入工作状态时容易被杂事占据。
- 触发条件:打开电脑后的第一个工作窗口。
- 操作步骤:不看消息,直接打开当天最重要任务。
- 失败信号:第一件事是刷邮箱、群聊、新闻。
- 补救动作:关闭所有通信窗口,执行一个 15 分钟核心任务。
- 效果指标:最初 30 分钟是否用于高价值产出。
卡片 11:午餐外出重启
- 适用场景:上午后注意力下降。
- 触发条件:午饭时间到,下午仍有任务。
- 操作步骤:离开工位吃饭,咀嚼充分,顺便短距离走动。
- 失败信号:边吃边看屏幕,吃完仍疲劳。
- 补救动作:饭后离开屏幕散步 5-10 分钟。
- 效果指标:下午第一小时是否能恢复执行力。
卡片 12:20-30 分钟午睡
- 适用场景:午后明显困倦。
- 触发条件:注意力下降、读不进去、反复犯错。
- 操作步骤:午后安排 20-30 分钟闭眼或午睡。
- 失败信号:硬撑导致下午效率持续降低。
- 补救动作:即使睡不着,也闭眼休息 10 分钟。
- 效果指标:醒后 30 分钟内是否恢复清醒。
卡片 13:下午运动重启
- 适用场景:下午卡住、疲劳、情绪低。
- 触发条件:连续 30 分钟推进困难。
- 操作步骤:做 5-15 分钟轻运动,如快走、拉伸、爬楼。
- 失败信号:继续坐着硬熬。
- 补救动作:站起来离开工位,完成一次短运动。
- 效果指标:运动后是否能重新开始任务。
卡片 14:穿插重启
- 适用场景:单一任务做久后效率下降。
- 触发条件:出现疲劳但还不适合休息。
- 操作步骤:从高认知任务切到低认知任务,再切回来。
- 失败信号:继续做同一任务但没有推进。
- 补救动作:处理一个 10 分钟内可完成的小任务。
- 效果指标:切回主任务后是否更容易继续。
卡片 15:5 分钟小睡法
- 适用场景:时间很短但大脑过载。
- 触发条件:没条件午睡,但需要快速恢复。
- 操作步骤:闭眼 5 分钟,屏蔽输入,让大脑暂停。
- 失败信号:用刷手机当休息。
- 补救动作:手机远离手边,只闭眼。
- 效果指标:是否减少烦躁和疲惫感。
卡片 16:晚间运动第二黄金时间
- 适用场景:晚上仍希望学习、阅读或输出。
- 触发条件:下班后精神涣散,但晚上还有成长任务。
- 操作步骤:安排适度运动,运动后进入轻学习或复盘。
- 失败信号:下班后直接瘫坐,晚上完全被动娱乐。
- 补救动作:先做 10 分钟低门槛运动。
- 效果指标:运动后是否完成一项自我投资任务。
卡片 17:睡前 2 小时降刺激
- 适用场景:睡眠质量差或第二天状态差。
- 触发条件:接近睡前 2 小时。
- 操作步骤:减少工作、强刺激内容、夜宵和高强度输入。
- 失败信号:睡前还在处理工作或刷刺激内容。
- 补救动作:切换到纸质书、轻复盘、洗漱和放松。
- 效果指标:入睡速度和第二天清醒度。
卡片 18:睡前 15 分钟记忆窗口
- 适用场景:想巩固学习内容或做日复盘。
- 触发条件:准备睡觉前。
- 操作步骤:只复盘当天重点、趣事或轻量学习内容。
- 失败信号:睡前输入大量新信息。
- 补救动作:写下 3 条今日收获后停止输入。
- 效果指标:第二天是否记得重点内容。
卡片 19:不让压力过夜
- 适用场景:工作压力带入晚上。
- 触发条件:下班后仍反复想工作。
- 操作步骤:写下未完成事项和明天第一步,然后停止处理。
- 失败信号:晚上继续脑内加班。
- 补救动作:把担忧转成明天待办,安排具体时间。
- 效果指标:睡前是否不再反复思考同一问题。
卡片 20:周末节律保护
- 适用场景:周末作息容易失控。
- 触发条件:周五晚上或周末早晨。
- 操作步骤:保持接近平日的起床时间,用运动和主动休息恢复。
- 失败信号:报复性熬夜和补觉,周一更疲惫。
- 补救动作:周末至少固定一个早晨活动。
- 效果指标:周一早晨状态是否稳定。
卡片 21:ASAP 工作术
- 适用场景:小事项容易堆积。
- 触发条件:遇到 2 分钟内可处理的事项。
- 操作步骤:能立刻完成就立刻完成,不能就写入待办。
- 失败信号:小事长期占据注意力。
- 补救动作:每天安排 15 分钟清理小事项。
- 效果指标:未决小事项数量是否下降。
卡片 22:提前 30 分钟行动
- 适用场景:会议、出行、交付容易压线。
- 触发条件:有明确约定或截止时间。
- 操作步骤:把开始时间提前 30 分钟,预留缓冲。
- 失败信号:总是在最后一刻赶。
- 补救动作:把日历开始时间改成真实提前时间。
- 效果指标:是否减少迟到和临时慌乱。
卡片 23:严格守时
- 适用场景:协作任务、会议、对外承诺。
- 触发条件:对他人承诺时间。
- 操作步骤:把守时视为对协作者成本的尊重。
- 失败信号:频繁让别人等或临时改期。
- 补救动作:提前同步风险,并给出新的确定时间。
- 效果指标:是否提升协作可信度。
卡片 24:2 分钟判断术
- 适用场景:需要快速筛选事项。
- 触发条件:面对新请求、新信息、新任务。
- 操作步骤:用 2 分钟判断是做、推迟、拒绝还是转交。
- 失败信号:长期悬而未决。
- 补救动作:如果无法判断,标记为“未决”并设置下次判断时间。
- 效果指标:未决事项是否有明确归宿。
卡片 25:30 秒决断术
- 适用场景:低风险选择过度犹豫。
- 触发条件:选择成本高于选择收益。
- 操作步骤:限定 30 秒做决定,并接受小误差。
- 失败信号:在低价值选择上反复比较。
- 补救动作:使用默认选项或第一个满足条件的选项。
- 效果指标:低价值决策耗时是否减少。
卡片 26:不是截止日,而是执行时段
- 适用场景:任务只写了截止日期但迟迟不开工。
- 触发条件:新增任务时。
- 操作步骤:不要只写“什么时候之前完成”,要写“什么时候做”。
- 失败信号:到截止日前才开始。
- 补救动作:立刻在日历里放入第一个执行块。
- 效果指标:任务是否在截止前启动。
卡片 27:立刻预约
- 适用场景:需要和别人约时间。
- 触发条件:决定要见面、沟通、体检、学习、运动。
- 操作步骤:当下就发起预约或放入日历。
- 失败信号:口头说“之后约”,但没有发生。
- 补救动作:打开日历,给出两个可选时间。
- 效果指标:计划是否从想法变成日历事件。
卡片 28:移动读书
- 适用场景:通勤、等待、碎片时间。
- 触发条件:出现 10 分钟以上空档。
- 操作步骤:提前选好一本书,碎片时间只读这一本。
- 失败信号:空档时间刷短内容。
- 补救动作:把当前书放到最容易打开的位置。
- 效果指标:每周碎片阅读页数或章节数。
卡片 29:读书后必须输出
- 适用场景:读完书容易忘。
- 触发条件:读完一章或一个方法。
- 操作步骤:写 3 条要点、1 条应用、1 个问题。
- 失败信号:只输入不整理。
- 补救动作:用 5 分钟写最小读书卡片。
- 效果指标:是否形成可复用笔记。
卡片 30:耳学
- 适用场景:手眼被占用但耳朵空闲。
- 触发条件:走路、通勤、做家务、低认知活动。
- 操作步骤:听书、播客、课程或复盘录音。
- 失败信号:用低质量音频填满所有空隙。
- 补救动作:只保留一个当前学习主题。
- 效果指标:听完后是否能说出 1 条收获。
卡片 31:自由时间不回流工作
- 适用场景:效率提升后空出时间。
- 触发条件:提前完成当天任务。
- 操作步骤:把空出的时间分给学习、运动、关系、兴趣或恢复。
- 失败信号:省下来的时间自动继续加班。
- 补救动作:提前定义“完成后做什么”。
- 效果指标:自由时间是否用于非工作目标。
卡片 32:主专长投资
- 适用场景:想长期提高职业能力。
- 触发条件:每周计划自我投资时间。
- 操作步骤:优先投入主专长,再补辅助技能。
- 失败信号:学习很多零散主题,但主线没有增强。
- 补救动作:本周只保留一个主专长学习目标。
- 效果指标:是否产出和主业相关的成果。
卡片 33:主动性娱乐
- 适用场景:休息后仍觉得空虚或疲惫。
- 触发条件:准备娱乐放松时。
- 操作步骤:优先选择运动、阅读、创作、社交、旅行等主动活动。
- 失败信号:长时间被动刷屏或看电视。
- 补救动作:把被动娱乐限定时间,并安排一个主动娱乐。
- 效果指标:娱乐后是否恢复能量。
卡片 34:玩乐清单
- 适用场景:自由时间不知道做什么。
- 触发条件:周计划或周末前。
- 操作步骤:列出想体验、想学习、想见的人和想去的地方。
- 失败信号:有空却默认刷手机。
- 补救动作:从清单里选一个 30 分钟内可开始的项目。
- 效果指标:每周是否完成至少一项主动玩乐。
卡片 35:每日时间管理日志
- 适用场景:想持续优化时间系统。
- 触发条件:每天结束前。
- 操作步骤:记录今日完成、低效时段、重启动作、明日第一优先级。
- 失败信号:只凭感觉判断效率。
- 补救动作:用 3 分钟写最小复盘。
- 效果指标:是否能发现重复低效模式。
建议的个人助理落地方式
- 每天上午:默认调用卡片 01、02、03、10。
- 每天下午:默认调用卡片 11、12、13、14。
- 每天晚上:默认调用卡片 16、17、18、19、35。
- 每周复盘:重点检查卡片 20、31、32、33、34。
- 任务管理:所有未决事项先进入
inbox/capture.md,再转入 tasks/todo.md 或日历执行时段。
---
layout: post
title: 《为什么精英都是时间控》内容全梳理(第一版)
subtitle: Codex 个人助理沉淀
date: 2026-06-01 07:13:57 -0400
tags:
- 个人助理
- 读书笔记
- 为什么精英都是时间控
---
来源:notes/books/为什么精英都是时间控/01_内容全梳理.md
《为什么精英都是时间控》内容全梳理(第一版)
说明:本梳理基于中文书目信息、中文目录页、日文原版出版社介绍与多篇读者总结交叉整理,侧重“可执行提炼”。
1. 书籍识别与版本对应
- 中文书名:
为什么精英都是时间控
- 作者:
[日] 桦泽紫苑
- 中文版原作名:
脳のパフォーマンスを最大まで引き出す 神・時間術
- 中文出版信息(豆瓣条目):湖南文艺出版社,2018-03,ISBN
9787540484705
- 日文原版信息(大和书房):
神・時間術,2017-04-13,ISBN 9784479795827
关键点:这本书本质不是传统“日程管理手册”,而是把脑科学(专注力机制)和时间配置结合起来,目标是“同样24小时,产出更高,同时自由时间更多”。
2. 全书总论:它到底在讲什么
2.1 核心问题
书中试图回答:
- 为什么同样是24小时,有的人长期高产且不那么疲惫?
- 时间管理失败,往往不是意志力差,而是忽视了大脑状态曲线。
2.2 中心公式
工作量 = 专注力(效率) × 时间- 管理重点从“塞满时间”转为“提高单位时间专注质量”。
2.3 总体路线
- 识别一天内专注力高低波动(早高峰、午后回落、晚间二次高峰)。
- 按认知负荷分配任务(专注型 vs 非专注型)。
- 通过重启手段恢复专注(运动、小憩、切换场所等)。
- 省下的时间不再回填给低效工作,而是投入自我成长与主动休闲,形成正循环。
3. 章节内容地图(按目录重构)
3.1 序章:神之时间管理术四原则
可提炼为四条:
- 以专注力为中心分配时间。
- 通过“重启”机制创造时间(不是硬扛)。
- 引入高效率工作方式(快速响应、时间边界、提前行动)。
- 终极目标不是更忙,而是“为了快乐使用时间”。
3.2 第一章:专注力最大化
核心内容:
15/45/90 节奏法:以可持续专注时长切分任务。- 杂念排除:外物干扰、内部思绪、人际打断、通信干扰(消息/社媒)。
- 时间限制工作术:把任务放进明确时段,借“截止效应”提速。
本章本质:先把注意力系统“关进笼子”。
3.3 第二章:早晨黄金时段
核心内容:
- 上午是高认知任务优先窗口(写作、决策、复杂分析)。
- 一组起床与清醒策略(如光照、节律化动作、早餐咀嚼等)用于快速进入状态。
- 早晨工作组织:先难后易,先产出后沟通。
本章本质:把一天最清醒的大脑,用在最值钱的任务上。
3.4 第三章:午后重启
核心内容:
- 午餐与短时外出不只是“休息”,而是认知重启。
- 短午睡/闭眼休息优于强撑。
- 午后效率恢复手段:短运动、换场景、任务穿插、5分钟小睡。
- 下午安排偏执行、协作、沟通类工作。
本章本质:不对抗疲劳,而是管理疲劳。
3.5 第四章:夜间与睡眠重启
核心内容:
- 晚间运动可带来“第二个高效窗口”(但与入睡时间要拉开)。
- 睡前2小时决定睡眠质量(减少刺激输入)。
- 睡前15分钟是记忆巩固窗口,适合复盘与轻学习。
- 周末不是报复性补觉,而是节律校准与恢复。
本章本质:用夜晚保证第二天,而不是透支第二天。
3.6 第五章:工作系统提效(创造时间)
核心内容:
For You 工作术:强调对他人与协作场景的可靠性(快速响应、守时、提前)。- ASAP 工作术:能现在处理就别堆积。
- “趁现在”决断:缩短决策拖延,未决事项显性化。
- 并行工作术:通勤听学、碎片输入、移动学习等。
本章本质:减少切换损耗与拖延债务。
3.7 第六章:自由时间的再投资
核心内容:
- 自由时间不应默认回流给工作。
- 优先投资主专长,再补辅助能力。
- 主动性娱乐(有恢复作用)优于被动性消耗。
- 通过“玩乐清单”把休息也变成可执行计划。
本章本质:时间管理的收益最终体现在“人生结构升级”。
4. 方法清单(可执行视角)
可归并为 6 大类:
- 任务分层:专注型/非专注型任务分流。
- 时段匹配:高认知任务放早晨,低认知任务放午后。
- 专注周期:15/45/90节奏,番茄类倒计时,硬截止。
- 干扰治理:消息批处理、环境降噪、杂念外部化(写下来)。
- 重启机制:午后短休息、微运动、场景切换、闭眼恢复。
- 收益再分配:把节省时间投入学习、健康、关系、兴趣,而非纯加班。
5. 这本书的底层假设
- 时间差距的根源是“认知状态管理差距”。
- 高效不是“做更多事”,而是“在正确状态做正确事”。
- 自律可持续依赖系统设计,而不是单次意志力爆发。
6. 可能的局限与使用边界
- 偏个人效率视角,对组织结构性低效讨论有限。
- 对轮班、夜班、照护型工作者可迁移度较低。
- 若执行过度,可能滑向“优化焦虑”;需保留弹性和恢复日。
7. 面向“个人助理”场景的存储建议(本次已采用)
当前目录设计:
notes/books/为什么精英都是时间控/01_内容全梳理.md(你正在看)
建议继续补的文件:
02_方法卡片.md:每条方法一页(触发条件/步骤/反例/替代方案)03_个人落地计划.md:把方法映射到你的日程现实04_实验记录.md:按周记录执行效果(专注时长、完成度、体感)05_复盘与修订.md:每月迭代“你的时间系统”
建议的数据字段(方便后续自动化):
- 方法名、适用场景、耗时、认知负荷、触发时段、失败信号、补救动作、效果评分。
8. 下一步(建议)
- 第二步:把本书拆成
20~30 张“执行卡片”(每张都能直接用)。
- 第三步:基于你当前工作流,做一份“你的神时间术一周模板”。
9. 资料来源(本版)
- 豆瓣书目与目录页(中文,含原作名与章节目录)
- https://book.douban.com/subject/30188003/
- 日文原版出版社页(大和书房,含原版定位与内容介绍)
- https://www.daiwashobo.co.jp/book/b280522.html
- 辅助参考(读者总结与方法项交叉校验)
- https://sspai.com/post/52968
- https://www.cnblogs.com/pprp/p/10827735.html
---
layout: post
title: 周志明的软件架构课
date: 2024-05-21 20:00:00 -0400
tags:
- 读书笔记
- 技术笔记
- 软件架构
---
Obsidian同步到博客
cp 'C:\Users\10785\Documents\obsidian\drivehq\drivehq\知识\图书馆\周志明的软件架构课\周志明的软件架构课笔记.md' C:\Users\10785\code\andywu1998.github.io\_posts\2024-05-22-周志明的软件架构课.md
20| 常见的四层负载均衡的工作模式是怎样的
提到了什么名词
- 负载均衡
- 四层负载均衡
- 七层负载均衡
- 数据链路层负载均衡
- 虚拟IP地址
- 网络层负载均衡
- IP隧道模式
- 应用层负载均衡
- 均衡策略
- 轮询均衡
- 权重轮询均衡
- 随机均衡
- 权重随机均衡
- 一致性hash均衡
- 响应速度均衡
- 最小连接均衡
名词解释
负载均衡
个人理解,是为了让网络请求能够分散到不同的服务器处理,分为四层负载均衡和七层负载均衡。
七层
- 应用层
- 表达层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
四层负载均衡
四层负载均衡指的是都维持同一个TCP连接,而不是它只工作在第四层。其实主要工作在数据链路层和网络层。所以就有数据链路层负载均衡和网络层负载均衡两种四层负载均衡。
数据链路层负载均衡
数据链路层传输的内容是数据帧,用来表示地址的是MAC源地址,MAC目标地址。
四层负载均衡做的事情就是修改MAC目标地址,让用户原本是发给负载均衡器的数据帧被二层交换机转发到服务器中。
Virtual IP Adress VIP
在使用数据链路层负载均衡的时候,需要把服务器的虚拟IP地址改成和负载均衡器的虚拟IP一样。
数据链路层负载均衡的响应工作模式
因为源地址没有被改变,所以服务器可以直接把相应发给客户端,不需要经过负载均衡器。
所以请求的链路是:客户端->负载均衡器->实际服务器->客户端
数据链路层负载均衡的局限
因为它只能改MAC地址交给第二层交换机去转发到目的服务器,所以它只能工作在同一个子网中,必须是二层可达的。
网络层负载均衡
网络层是表示源和目的的是源IP地址和目的IP地址
网络层负载均衡的两种修改方式 隧道(套娃)模式
套娃模式,就是保持原来的IP数据包不变,给它包一层,原来的一整个包就是新包的payload,然后新包的目的地址是真实服务器地址。真实服务器拿到包之后先把外层的包拆掉。因为原来的数据包的源地址还是客户端的地址,所以这种模式仍然可以不经过负载均衡器就直接相应客户端。
缺点:
- 服务器必须会拆包,不过几乎所有linux都支持这种模式。
- 真实服务器必须有和负载均衡器相同的虚拟IP地址。
网络层负载均衡模式之 NAT模式
负载均衡器直接把真实数据包的目的地址改掉,改成实际的服务器地址。
这样会产生一个问题,就是服务器的地址和负载均衡器的地址不是同一个地址,所以服务器不能直接响应客户端,因为客户端本来发送的目的地址是负载均衡器的地址,如果它收到源地址是实际服务器的地址的话它会不认识。所以就需要实际服务器把相应再次发给负载均衡器,负载均衡器把源地址改成负载均衡器自己的地址。这样才能保证客户端认识真实服务器发出去的数据包。
缺点,因为相应和要回到负载均衡器,所以会有较大的性能损耗。
- 还有一种更彻底的NAT模式叫Source NAT就是负载均衡器不但把目标地址改了,也把源地址改成自己的。这样的好处是网关都不用配置了,能让流量正常的经过三层路由,回到负载均衡上。这样的是真的透明的。
- 缺点:真实服务器拿不到真实的客户端地址,有一些需要根据IP做的业务逻辑就不能做了。
应用层负载均衡
四层负载均衡就像是一个自动排号机,每个到达的客户都能被指定到相应窗口。七层负载均衡像是大堂经理,确认客户要办的业务,然后根据内部资源同样协调客户到哪个窗口,并且如果有一些很简单的业务,大堂经理直接解决了。
优点
- 静态资源缓存
- 协议升级
- 安全防护
- 访问控制
- 更智能的实现:比如根据用户身份路由,导流到贵宾服务器。
均衡策略
轮询
简单轮流
权重轮询
按照权重来轮询
随机
权重随机
有一定权重的随机
一致性hash均衡
用MAC IP地址或者更上层的东西计算hash,计算请求应该落到哪些节点上。
相应速度均衡
最少链接数均衡
适合长时间处理的业务,比如FTP业务。
21- 服务端缓存的三种属性
提到的名词
- 缓存
- 缓存属性
- 吞吐量
- 命中率
- 拓展功能
- 分布式支持
- 命中率和淘汰策略
- FIFO
- LRU
- LFU
- Tiny LFU
- W-TinyLFU
- 加载器
- 淘汰策略
- 失效策略
- 事件通知
- 并发级别
- 容量控制
- 引用方式
- 统计信息
- 持久化
名词解释
缓存属性
- 吞吐量
- 命中率
- 拓展功能
- 分布式支持
本讲讲前三种属性。
吞吐量
- 线程安全会带来一定的吞吐量损失。
- 主流方案:Caffeine,ConcurrentLinkedHashMap,LinkedHashMap, Guava Cache, Ehcache, Infinispan Embedded
- 避免数据竞争,Caffeine用环形缓冲区来避免数据竞争。将原来写在map上的锁转移到日志追加上。
命中率和淘汰策略
- 缓存有时候不会命中,所以有命中率。
- FIFO:先进先出的淘汰策略,会很大幅度降低命中率。因为越早进入的往往越经常被访问。
- LRU:优先淘汰最久未被访问的数据。但如果有一些数据经常被访问,只是最近因为某种原因没被访问,仍然面临被淘汰的命运,所以LRU仍然可能淘汰高价值的数据。
- LFU:优先淘汰最不经常使用的数据,给每个数据添加访问计数器,每访问一次就加一
- 需要维护一个计数器,开销昂贵,会影响吞吐量。
- 如果某一个数据曾经经常被访问,但现在不需要了,也很难清除缓存。
- TinyLFU:采用Sketch结构,借用Count-Min Sketch算法可以用相对小得多得空间来记录频率和空间。
- W-TinyLFU:TinyLFU实现减少计数器维护频率的同事,也无法很好解决稀疏突发访问问题。
- 系数突发访问是一些绝对频率较小,但突发访问频率很高的数据。
- 整体LFU,局部LRU。
- 把新记录放到Window Cache的LRU缓存前面。让这些对象在Window Cache里积累热度,如果能通过Tiny LFU的过滤器,再进入MainCache里。
- Main Cache根据访问频繁程度分为不同的段,从某一个段局部来看是LRU的,当一个段满了就淘汰到后一段去存储。知道最后一段也满了就彻底清楚缓存。
22 分布式缓存如何与本地缓存配合,提高系统性能
提到了哪些名词
- 分布式缓存
- 复制式缓存
- 集中式缓存
- 透明多级缓存
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存污染
复制式缓存
- 每个节点都有自己的内存缓存,同时还有一个分布式缓存。
- 内存缓存的数据来源于从分布式缓存的复制。
集中式缓存
- 需要网络访问
- 独立的进程空间,这样能够多语言一起用一个缓存。
透明多级缓存
- 相关的JDK把缓存分层,先查进程内缓存,查不到去查分布式缓存(redis),再查不到去查真正数据源。
- 从数据源回填到分布式缓存
- 从分布式缓存回填到进程内缓存。
缓存穿透
- 访问数据库里本来就没有的数据,这样每次请求都会打到数据库。
- 一定时间内缓存空值。
- 用布隆过滤器来过滤数据库里肯定不存在的值。
缓存击穿
- 热点数据失效了,并发请求都到达真实数据源。
- 解决方法:加锁,只有一个请求可以流入真实数据源。如果是分布式缓存问题,就分布式锁。
缓存雪崩
- 相比于缓存击穿是针对单个热点数据,而缓存雪崩是大批量热点数据失效。这可能是因为批量预热导致的。
- 分布式缓存集群。
- 启用透明多级缓存。
- 随机过期时间。
缓存污染
- Cache Aside模式
- 简单说就是读的时候先读缓存,没读到再读数据源。
- 写数据直接写数据源,然后失效而不是更新缓存。
- 有一个风险,如果一个数据一开始没有缓存的,在读数据源之后,回填缓存之前,数据源的数据更新了,这个时候就会造成缓存和数据源不一致。但是这个概率非常低。
- 如果这个概率也想避免的话可以用paxos算法。
23 认证:系统如何正确分辨操作用户的真实身份?
提到哪些名词
- 认证
- 授权
- 凭证
- 保密
- 传输
- 验证
认证
- 基于通讯信道上的认证
- 建立连接之前,先证明你是谁。典型是SSL/TLS
- 通讯协议上的认证
- http协议认证
- 通讯内容认证
- web内容认证。
http认证
http认证框架
- 客户端访问需要鉴权的资源。
- 服务端返回Unauthorized(401)
- 客户端认证
- 带着认证访问资源
- 服务端认证。
多种方案:
- Digest
- Bearer
- HOBA
基于通讯内容:web认证
一个开放标准:WebAuthn
WebAuthn彻底抛弃传统的密码登录方式,采用生物识别或者实体密钥来作为身份验证。主要分为注册和登录两部分。
注册部分
- 用户进入系统注册界面填的信息不属于标准范围。
- 用户点击提交注册信息的时候,服务端暂存用户提交的数据,返回一个随机字符串(challenge)和用户的UserID
- 客户端的webAuthn API收到challenge和UserID,把这些信息发送给验证器,验证器可以是Touch Bar或者Face ID
- 验证器提示用户验证,验证结果是一对公钥和私钥,验证器存好密钥,用户信息和域名。用私钥对challenge签名。把签名结果 userID 和公钥返回给客户端。
- 客户端返回给服务器
- 服务器检查UserID是否一致,用公钥来解密签名结果判断和challenge是否一致。
- 一致的话,服务器存储对应的公钥。
登录部分
- 用户点击登录按钮
- 服务器返回随机字符串Challenge和UserID
- 浏览器讲Challenge 和 UserID转发给验证器
- 验证器在注册阶段已经存储了域名的私钥和用户信息,如果域名和用户都相同的话,就不需要生成新的密钥对了。用私钥加密Challenge返回给浏览器。
- 服务端用注册时存储的公钥来解密,如果解密成功并且和发的challenge一样则表示登录成功。
---
layout: post
title: gocontext
date: 2023-10-14 20:00:00 -0400
tags:
- 技术笔记
- Go
---
context简介
一个用于go routine之间传播取消信号,过期信号和普通变量值的内部库。
context是一个用于在不同的go routine之间传递变量和取消信号的库。
context接口的具体实现可以分为两大类,传值和传取消信号。
-
传值,用valueCtx来实现,每个valueCtx包含key和value两个interface,还嵌入一个Context接口作为父context。对context写值的方式是context.WithValue(parent, key, value)。其实就是给定一个父context,然后包装一个子context,这个子context的父节点是传进来的context,同时它维护了传给他的key和value作为它的字段。
当我们对一个context做调Value方法的时候,它首先判断当前节点的key是不是要找的key,如果不是的话,继续递归找它的父节点。直到找到根或者找到为止。
-
传取消信号,传取消信号用cancelCtx来实现。在调用context.WithCancel的时候返回一个包装好的context和一个cancelFunc,当用户调用cancelFunc的时候就传递了取消信号。
在另外一个go routine里,用select监听ctx.Done(),Done的返回值是一个channel,一旦channel收到close信号,就表示收到取消信号。可以取消go routine的运行。
在WithCancel基础之上,还有一个WithCancelCause接口,它返回也是cancelCtx,不过后面跟随的是CancelCauseFunc,CancelCauseFunc和CancelFunc的区别在于CancelCauseFunc允许用户传一个error值。其他go routine可以调用context.Err()来查看这个Error。
在普通的手动取消的实现cancelCtx基础上,还实现了定时取消。定时取消是用timerCtx实现的。timerCtx在继承了cancelCtx的基础上,多了timer和和deadline字段。timer是time.Timer,deadline是time.Time。用于time.Timer来实现定时取消,其实就是定时调用cancelCtx的cancelFunc。
timerCtx对外有两个接口,一个是withDeadline,接受的是一个具体的时间。一个是WithTimeout,withTimeout接收的是一个时间长度,其实也是用当前时间加上时间长度之后直接调用WithDeadline来实现。
总的来说,context分为两大类,一类是传值。用valueCtx来实现。一类是传取消信号,传取消信号又分为手动取消和定时取消两种。手动取消有不接收error的cancelFunc,也有接收error的cancelCauseFunc。定时取消的时间是手动取消的基础上加上定时器和一个时间戳,它对外有两种接口,一种接收时间戳,一种接收时间长度。本质上接收时间长度也会直接用当前时间加上时间长度转成时间戳。
type timerCtx struct {
*cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
done atomic.Value
接口定义:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}
使用
1. 上下文传值
package main
import (
"context"
"fmt"
"time"
)
const (
key = "key"
)
func PrintlnValue(ctx context.Context) {
fmt.Println("value = ", ctx.Value(key))
}
func TestWithValue() {
ctx := context.WithValue(context.Background(), key, "hello")
go PrintlnValue(ctx)
time.Sleep(time.Second)
}
func main() {
TestWithValue()
}
2. 取消go routine
这功能用于一个go routine创建另外一个go routine的时候,父go routine能够取消运行子go routine。
并且,当一个cancel context父节点取消的时候,它的子节点也会取消。
下面的代码创建了一个父context,两个子context,先取消子context 1,context2不自己取消,而是用父context取消,仍然是生效的。
func withCancel(name string, ctx context.Context) {
ticker := time.Tick(time.Second)
count := 0
for {
select {
case <-ticker:
fmt.Printf("%v excute %v times\n", name, count)
count++
case <-ctx.Done():
fmt.Printf("%v canceled\n", name)
return
}
}
}
func TestWithTimeOut() {
// 新建一个cancle context
ctx, cancel := context.WithCancel(context.Background())
// 用上面的ctx当作父节点,创建两个子节点context
childCtx1, childCancel1 := context.WithCancel(ctx)
childCtx2, _ := context.WithCancel(ctx)
go withCancel("parent", ctx)
go withCancel("child 1", childCtx1)
go withCancel("child 2", childCtx2)
// sleep 5s之后取消子节点1,父节点和子节点2仍然运行
time.Sleep(5 * time.Second)
childCancel1()
// 再sleep 5s后取消父context
time.Sleep(5 * time.Second)
cancel()
time.Sleep(5 * time.Second)
}
3. 设定超时时间和DDL
设置超时时间(时间长度)和设置DDL(时间戳)本质上是一样的。简单来说就是设定一个时间,到时间后ctx.Done()会传入一个close信号。
func TestWithDDL() {
timeout := 2 * time.Second
ctxWithDeadLine, _ := context.WithDeadline(context.Background(), time.Now().Add(timeout))
ctxWithTimeout, _ := context.WithTimeout(context.Background(), timeout)
go withCancel("ddl", ctxWithDeadLine)
go withCancel("timeout", ctxWithTimeout)
time.Sleep(5 * time.Second)
}
func withCancel(name string, ctx context.Context) {
ticker := time.Tick(time.Second)
count := 0
for {
select {
case <-ticker:
fmt.Printf("%v excute %v times\n", name, count)
count++
case <-ctx.Done():
fmt.Printf("%v canceled\n", name)
return
}
}
}
四种实现
context接口在context里有四种实现,emptyCtx,
emptyCtx
一般用于初始化一个context,不包含任何内容,只是定义了函数。
cancelCtx
一个cancelCtx可以被取消,当它取消的时候,它的子节点也会被取消。
// A cancelCtx can be canceled. When canceled, it also cancels any children
// that implement canceler.
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
cause error // set to non-nil by the first cancel call
}
一般用WithCancel来构造一个CancelContext,返回值包括一个Context接口和一个CancelFunc,返回的CancelFunc的时候表示这个context取消了。
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := withCancel(parent)
return c, func() { c.cancel(true, Canceled, nil) }
}
func withCancel(parent Context) *cancelCtx {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
propagateCancel(parent, c)
return c
}
func newCancelCtx(parent Context) *cancelCtx {
return &cancelCtx{Context: parent}
}
timerCtx
// A timerCtx carries a timer and a deadline. It embeds a cancelCtx to
// implement Done and Err. It implements cancel by stopping its timer then
// delegating to cancelCtx.cancel.
type timerCtx struct {
*cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
timerCtx里面包含了一个cancelCtx,用来实现Done和Err函数。它通过停止计时器来实现取消,然后委托给concelCtx.cancel
valueCtx
valueCtx实现了携带键值对
// A valueCtx carries a key-value pair. It implements Value for that key and
// delegates all other calls to the embedded Context.
type valueCtx struct {
Context
key, val any
}
这里实现的是“上下文传值”
源码解析 ctx.Value
对于valueCtx来说,它实现value的方式是,先看一下当前的ctx的key是不是要找的key,如果是的话直接返回,不是的话则把父Ctx设置为当前ctx,然后继续查找。简单来说就是一层一层往上找。
func (c *valueCtx) Value(key any) any {
if c.key == key {
fmt.Println("return in Value")
return c.val
}
return value(c.Context, key)
}
func value(c Context, key any) any {
i := 0
for {
i++
fmt.Println("i", i)
switch ctx := c.(type) {
case *valueCtx:
fmt.Println("valueCtx")
if key == ctx.key {
fmt.Println("return")
return ctx.val
}
c = ctx.Context
case *cancelCtx:
fmt.Println("cancelCtx")
if key == &cancelCtxKey {
fmt.Println("return")
return c
}
c = ctx.Context
case *timerCtx:
fmt.Println("timerCtx")
if key == &cancelCtxKey {
fmt.Println("return")
return ctx.cancelCtx
}
c = ctx.Context
case *emptyCtx:
fmt.Println("emptyCtx")
return nil
default:
fmt.Println("default")
return c.Value(key)
}
}
}
源码解析,如何实现父context取消的时候,子context也取消?
在构建cancleCtx的时候,调用propagateCancel来实现父子绑定
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := withCancel(parent)
return c, func() { c.cancel(true, Canceled, nil) }
}
func withCancel(parent Context) *cancelCtx {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent)
propagateCancel(parent, c)
return c
}
func propagateCancel(parent Context, child canceler) {
done := parent.Done()
if done == nil {
return // parent is never canceled
}
select {
case <-done:
// parent is already canceled
child.cancel(false, parent.Err(), Cause(parent))
return
default:
}
if p, ok := parentCancelCtx(parent); ok {
p.mu.Lock()
if p.err != nil {
// parent has already been canceled
child.cancel(false, p.err, p.cause)
} else {
if p.children == nil {
p.children = make(map[canceler]struct{})
}
p.children[child] = struct{}{}
}
p.mu.Unlock()
} else {
goroutines.Add(1)
// 启动一个go routine来监听parent的Done,如果parent.Done()收到信号,就调用child.cancel
go func() {
select {
case <-parent.Done():
child.cancel(false, parent.Err(), Cause(parent))
case <-child.Done():
}
}()
}
}
这里用到的parentCancelCtx,在慢慢解析
// parentCancelCtx returns the underlying *cancelCtx for parent.
// It does this by looking up parent.Value(&cancelCtxKey) to find
// the innermost enclosing *cancelCtx and then checking whether
// parent.Done() matches that *cancelCtx. (If not, the *cancelCtx
// has been wrapped in a custom implementation providing a
// different done channel, in which case we should not bypass it.)
func parentCancelCtx(parent Context) (*cancelCtx, bool) {
done := parent.Done()
if done == closedchan || done == nil {
return nil, false
}
p, ok := parent.Value(&cancelCtxKey).(*cancelCtx)
if !ok {
return nil, false
}
pdone, _ := p.done.Load().(chan struct{})
if pdone != done {
return nil, false
}
return p, true
}
---
layout: post
title: 占坑,实现跳表
date: 2023-10-10 20:00:00 -0400
tags:
- 技术笔记
- 算法
- 跳表
---
https://oi-wiki.org/ds/skiplist/
先埋个坑,之后用自己熟悉的编程语言用跳表实现一个map
---
layout: post
title: redis多路复用
date: 2023-10-10 20:00:00 -0400
tags:
- 技术笔记
- Redis
---
redis的网络模型是IO多路复用,这也是它能够单线程也很快的原因,正是因为它用了IO多路复用,所以不会产生IO阻塞问题,能够在同一时间内与多个client通信。
redis课程的老师只说了epoll,但其实redis是封装了一套接口,对于不同的操作系统用不同的处理方式。有epoll, evport, kqueue, select几种。
编译的时候用宏定义来决定编译几种。
下面的代码中,每个.c就对应着不同的IO多路复用方式。
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
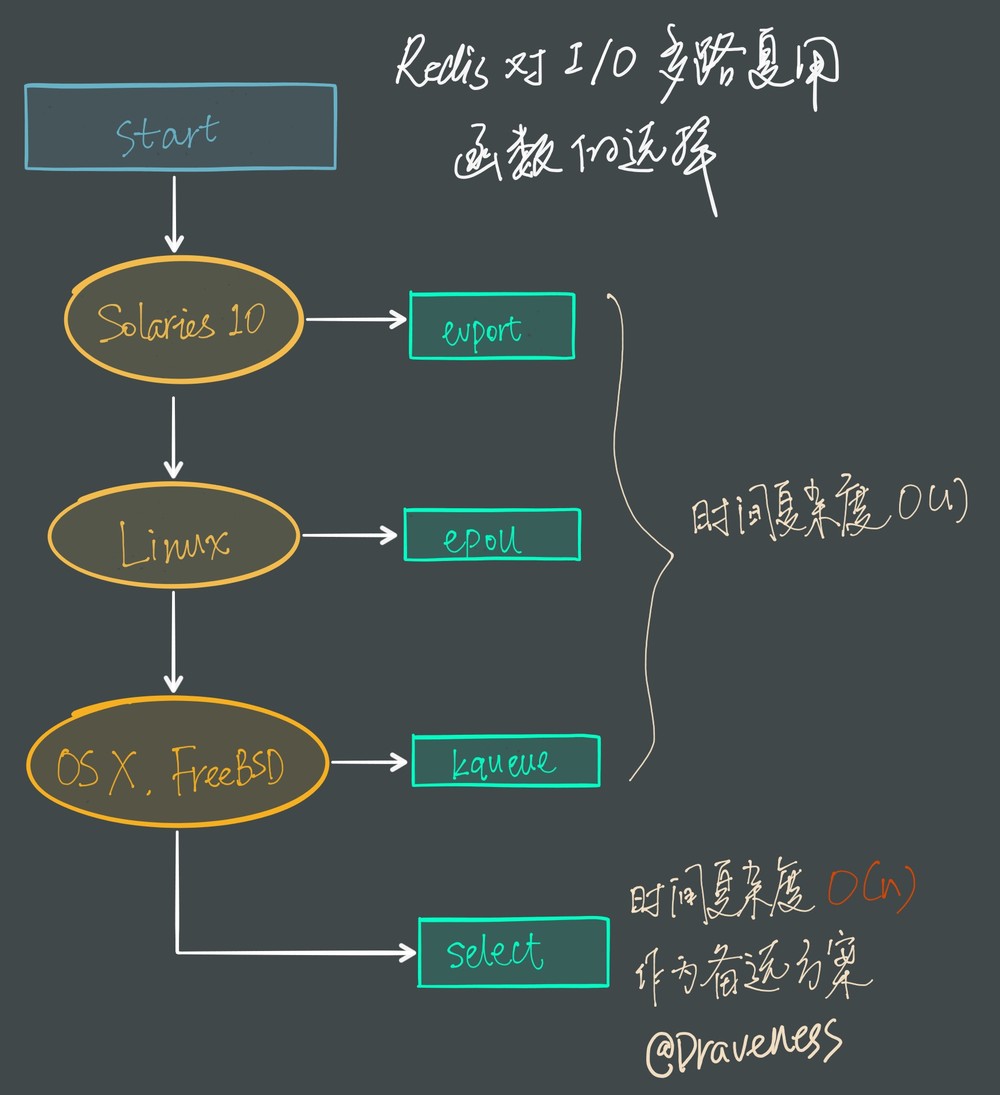
---
layout: post
title: go里的map是怎么判断并发读写的?
date: 2023-10-08 20:00:00 -0400
tags:
- 技术笔记
- Go
---
map如何知道自己被抢占
map的底层实现是hmap结构体,有一个叫flags的uint8类型字段。
下面这些常量表示flag每一个位的作用
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
其中这里关于如何判断锁冲突的是hashWriting字段
写
// 因为h.flags默认为0,所以hashWriting初始化应该为0,如果不为0说明其他goroutine在写
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// 开始写,writing位置为1
h.flags ^= hashWriting
// 写之后判断,因为刚刚已经把writting置位1了,这里不应该为0,如果为0说明在写的过程中有人改过了。
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
// 恢复原状
h.flags &^= hashWriting
删除
// 判断是否为0,如果不为0则fatal
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// 开始删除,置为1
h.flags ^= hashWriting
// 如果等于0表示又其他go routine把它置为1了,fatal
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
// 恢复原状
h.flags &^= hashWriting
读
// 读的时候只需要判断,不需要修改。
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
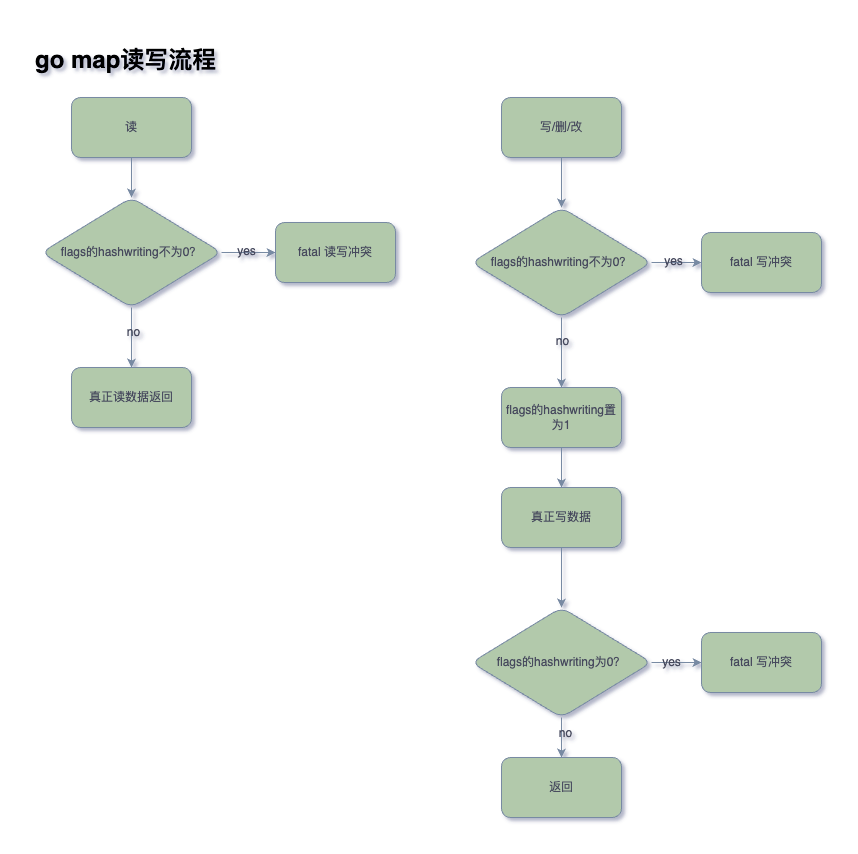
番外篇 &^ 运算
&^被定义为bit clear运算,表示用右边的操作数清空左边的操作数的指定位。
0110 &^ 0010 表示清空0110的右数第2位。清空之后变成0100
package main
import "fmt"
func test(testCases [][]int) {
for _, testCase := range testCases {
ret := testCase[0] &^ testCase[1]
fmt.Printf("%v &^ %v = %v\n", testCase[0], testCase[1], ret)
}
}
func main() {
testcase := [][]int{
{0, 0},
{0, 1},
{1, 0},
{1, 1},
{6, 4},
}
test(testcase)
}
结果
0 &^ 0 = 0
0 &^ 1 = 0
1 &^ 0 = 1
1 &^ 1 = 0
6 &^ 4 = 2
---
layout: post
title: redis
date: 2023-09-27 20:00:00 -0400
tags:
- 技术笔记
- Redis
---
---
layout: post
title: leetcode
date: 2023-09-27 20:00:00 -0400
tags:
- 技术笔记
- 算法
- LeetCode
---
leetcode 2251 花期内花的数目(2023.9.28)
题目
给你一个下标从 0 开始的二维整数数组 flowers ,其中 flowers[i] = [starti, endi] 表示第 i 朵花的 花期 从 starti 到 endi (都 包含)。同时给你一个下标从 0 开始大小为 n 的整数数组 people ,people[i] 是第 i 个人来看花的时间。
请你返回一个大小为 n 的整数数组 answer ,其中 answer[i]是第 i 个人到达时在花期内花的 数目 。
1 <= flowers.length <= 5 * 1e4
flowers[i].length == 2
1 <= starti <= endi <= 1e9
1 <= people.length <= 5 * 1e4
1 <= people[i] <= 1e9
题解
这道题乍一看就是差分+前缀和,实际上我写完提交了才发现,区间的范围最大值是1e9,所以得考虑离散化的方案。
感谢房宝给的解法:因为已经提前知道了查询的内容,所以可以做离线,简单来说就是开一个map用来代替差分数组,map记为presum,然后开始处理区间之前,先初始化presum[person[i]] = 0
接下来是走正常的差分流程。
presum[l]++
presum[r + 1]–
最后按照key的大小来排序,求前缀和。因为已经初始化了presum[person[i]] = 0,所以求完前缀和之后presum[person[i]]就是答案。
func fullBloomFlowers(flowers [][]int, people []int) []int {
max := 0
for _, flower := range flowers {
if flower[1] > max {
max = flower[1]
}
}
presum := make(map[int]int)
for _, p := range people {
presum[p] = 0
}
for _, flow := range flowers {
if _, ok := presum[flow[0]]; ok {
presum[flow[0]]++
} else {
presum[flow[0]] = 1
}
if _, ok := presum[flow[1] + 1]; ok {
presum[flow[1] + 1]--
} else {
presum[flow[1] + 1] = -1
}
}
// fmt.Println(presum)
keys := make([]int, 0)
for k, _ := range presum {
keys = append(keys, k)
}
sort.Ints(keys)
for i := 1; i < len(keys); i++{
presum[keys[i]] = presum[keys[i]] + presum[keys[i - 1]]
}
// fmt.Println(presum)
res := make([]int, 0)
for _, p := range people {
res = append(res, presum[p])
}
return res
}
leetcode 947 移除最多的同行或同列石头 2023.09.27
题意
https://leetcode.cn/problems/most-stones-removed-with-same-row-or-column/
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。
示例 1:
输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
解释:一种移除 5 块石头的方法如下所示:
- 移除石头 [2,2] ,因为它和 [2,1] 同行。
- 移除石头 [2,1] ,因为它和 [0,1] 同列。
- 移除石头 [1,2] ,因为它和 [1,0] 同行。
- 移除石头 [1,0] ,因为它和 [0,0] 同列。
- 移除石头 [0,1] ,因为它和 [0,0] 同行。
石头 [0,0] 不能移除,因为它没有与另一块石头同行/列。
示例 2:
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
解释:一种移除 3 块石头的方法如下所示:
- 移除石头 [2,2] ,因为它和 [2,0] 同行。
- 移除石头 [2,0] ,因为它和 [0,0] 同列。
- 移除石头 [0,2] ,因为它和 [0,0] 同行。
石头 [0,0] 和 [1,1] 不能移除,因为它们没有与另一块石头同行/列。
示例 3:
输入:stones = [[0,0]]
输出:0
解释:[0,0] 是平面上唯一一块石头,所以不可以移除它。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/most-stones-removed-with-same-row-or-column
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
1 <= stones.length <= 1000
0 <= xi, yi <= 1e4
题解
这道题是一个并查集的应用,但问题就在于,如何构建并查集?
主要目的是:让相同列或者相同行的石子处于同一个集合里。一开始思路是把每个石子的x和y放到同一个集合,但提交之后发现这行不通。一个反例就是
[1, 0], [0, 1]
这两个点是不同行且不同列的,如果单纯把x y放同一个集合的话,第一个点1 0一个集合,第二个点0 1一个集合,最终他们会组成一个集合。这就不对了。
这里学习了题解里最巧妙的地方:union(x + 10001, y),因为x和y的最大取值是1e4,所以让x+10001。这样就能保证,只要两个点的x值是相等的,它们+10001之后也相等,所以他们会落入同一个集合中。并且x的取值范围变成了10001~20001,与y不冲突,所以不会出现上面说的[0,1],[1,0]被加入同一个集合的情况。
另外,因为这道题的取值范围1e4,所以用map来代替并查集的数组会好一些。在本题中还收到另外的启发,集合的个数,可以记录下来。集合的个数=根的个数,一个元素成为了根,集合个数就+1,当一个元素被另外一个集合合并,它就不是根了,集合个数-1。
/*
* @lc app=leetcode.cn id=2251 lang=golang
*
* [2251] 花期内花的数目
*/
package main
import (
"fmt"
"sort"
)
// @lc code=start
func fullBloomFlowers(flowers [][]int, people []int) []int {
max := 0
for _, flower := range flowers {
if flower[1] > max {
max = flower[1]
}
}
presum := make(map[int]int)
for _, p := range people {
presum[p] = 0
}
for _, flow := range flowers {
if _, ok := presum[flow[0]]; ok {
presum[flow[0]]++
} else {
presum[flow[0]] = 1
}
if _, ok := presum[flow[1] + 1]; ok {
presum[flow[1] + 1]--
} else {
presum[flow[1] + 1] = -1
}
}
// fmt.Println(presum)
keys := make([]int, 0)
for k, _ := range presum {
keys = append(keys, k)
}
sort.Ints(keys)
for i := 1; i < len(keys); i++{
presum[keys[i]] = presum[keys[i]] + presum[keys[i - 1]]
}
// fmt.Println(presum)
res := make([]int, 0)
for _, p := range people {
res = append(res, presum[p])
}
return res
}
// @lc code=end
func main() {
flowers := [][]int{
{1, 6},
{3, 7},
{9, 12},
{4, 13},
}
people := []int{
2, 3, 7, 11,
}
fmt.Println(fullBloomFlowers(flowers, people))
}
---
layout: post
title: 面试记录
date: 2023-01-15 19:00:00 -0500
tags:
- 面试
- 工作
---
合合信息
- 为什么用Ti DB不用MySQL?
- 对TiDB的数据库原理有了解吗?
- Redis的集群架构有了解吗?
- redis的AOF和RDB模式的区别吗
- Kafka是如何实高可用的?
- 你们的消费者有多少个
- 讲一下MySQL索引的原理
- 建表的时候设计索引需要考虑什么
- 怎么理解golang里的interface
FOMO pay 1.16
- 在头条百科怎么做的数据质量提升
- 如何定义词条的缺陷
- K8s里如何存储密码 私钥信息
- 修改博客用的是原生JS还是框架
- 如果自己做项目的话,会选择怎样的技术。
- 工作过的团队都有多大,都有不同的角色吗,如何沟通交流。
- 需求是比较明确的是吗
- 和其他团队成员的交流是怎样的
- 会做测试吗 怎么做测试
- 有写过单元测试吗
- 需求是现成的对吧,有没有涉及到怎么样去获得需求这个问题
- 得到需求之后如何评估是可实现不可实现的
- 对软件的生命周期了解吗,假如说这个过程中会发生一个问题,你会希望他发生在哪个阶段呢
- 假设说提出的需求和现有系统是有冲突,是不可实现的,这个时候会怎么做
- 事件冒泡和事件捕捉有了解吗
- 用过哪些数据库
- 平常怎么保持对技术发展和了解
- 做过的项目中有哪个是值得你比较自豪的
百度网盘
- channel的底层实现
- 常见的panic情况
- 读已经关闭的channel会panic吗
- 往一个值为nil的channel写数据会panic吗
- 还知道其他panic的形式吗
- Go的切片有什么注意事项呢
- context包有了解吗?
- 反射有了解吗?
- 在go里面用过设计模式吗
- 有了解过哪些设计模式呢
- redis有用过吗
- 分布式锁有什么需要注意的吗
- Lua脚本有用过吗(在redis里用lua)
- 最左匹配的原理?为什么满足最左匹配就可以复用索引
- 联合索引的叶子结点也是主键ID吗
- MySQL中联合索引使用的是B+树结构来组织索引数据。在B+树中,叶子结点存储了索引数据的具体信息。在联合索引中,叶子结点存储的是整个联合索引的值,以及该值对应的记录在数据表中的主键值。这样在查询时,MySQL就可以根据索引的值来快速查找到数据表中的记录。
- 分表有用过吗
- 写个快排
星汉未来
- VM的业务量级有多大,QPS能达到多少,健康度是怎么监控的
- 如果业务增长了10倍,需要对现有系统做哪些改造,怎么评估需要扩多少呢
- 在工作这一年半中有没有没一些发挥主观能动性做的一些创新或者一些有意思的东西
- Go全局变量 常量 还有init的调用顺序是怎样的
- 切片的实现,capacity和length的区别是什么,切片的越界越的是length还是capacity
- Map是并发安全的吗
- Map可以边循环边删除吗
矩阵起源
- 说一下LRU,写一下LRU
- Go routine的调度逻辑
- Go里的并发安全怎么做?
- Channel是并发安全的吗?是怎么做到并发安全的?
- TCP里的Time wait和close wait
核经传媒
- 切片使用过程中需要注意的地方
- 对于有缓冲channel,如果读的那边太慢了,怎么让写的这边不阻塞? 用Select 的default
- 反转链表
字节跳动
- 短链API的的时延多少?数据量有多少?区分热点数据吗?
- 32操作系统和64操作系统有什么区别?
- 虚拟内存和物理内存的区别?为什么需要用虚拟内存?
- 32位操作系统的寻址空间是多大?
- 打开shell,输入Ctrl C的时候一般程序会退出,描述一下这个过程
- 在服务里发现大量time wait的状态,知道time wait是什么状态吗?主要来解决什么问题?
- http 1.0和http 1.1的区别?1.1相比于1.0的解决了什么问题?
- Golang里的连接池可以聊一下吗?
- MySQL某几次查询特别高的话怎么定位?
- 可以聊一下隔离级别吗?
- TiDB提供的哪种的隔离级别
富途
提交接口,一个人,只能有一条处理中的任务,但他可以用无数条可以撤销的任务。
实现一个接口,先去数据库查询这个数据有没有写入,如果有写入就不可以再提交。
核心,一个人只能有一个处理中的任务,但是可以有很多条已撤销的任务。也就是说,对于这个接口,如果查询到已经有一条处理中的任务,就要报错。如果没有处理中的任务,就insert一条处理中的任务。
数据库的表结构大概是这样 (userid, taskid, state) taskid就是任务ID,state=1表示处理中,state=2表示已撤销。对于每次请求,需要确保表中对于当前用户没有state=1的数据,才可以insert,否则就报错。
---
layout: post
title: MySQL45note1
date: 2023-01-07 19:00:00 -0500
tags:
- 技术笔记
- MySQL
---
MySQL 实战 45 讲
02 | 日志系统:一条SQL更新语句是如何执行的?
MySQL的更新流程。
首先判断要修改的数据页是否在内存中,如果不在的话则去磁盘里面取出来然后放到内存里。在的话就直接写。
然后把把数据更新到内存。
写入redolog 处于prepare阶段
写入binlog
提交事务,把redolog改成commit阶段
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
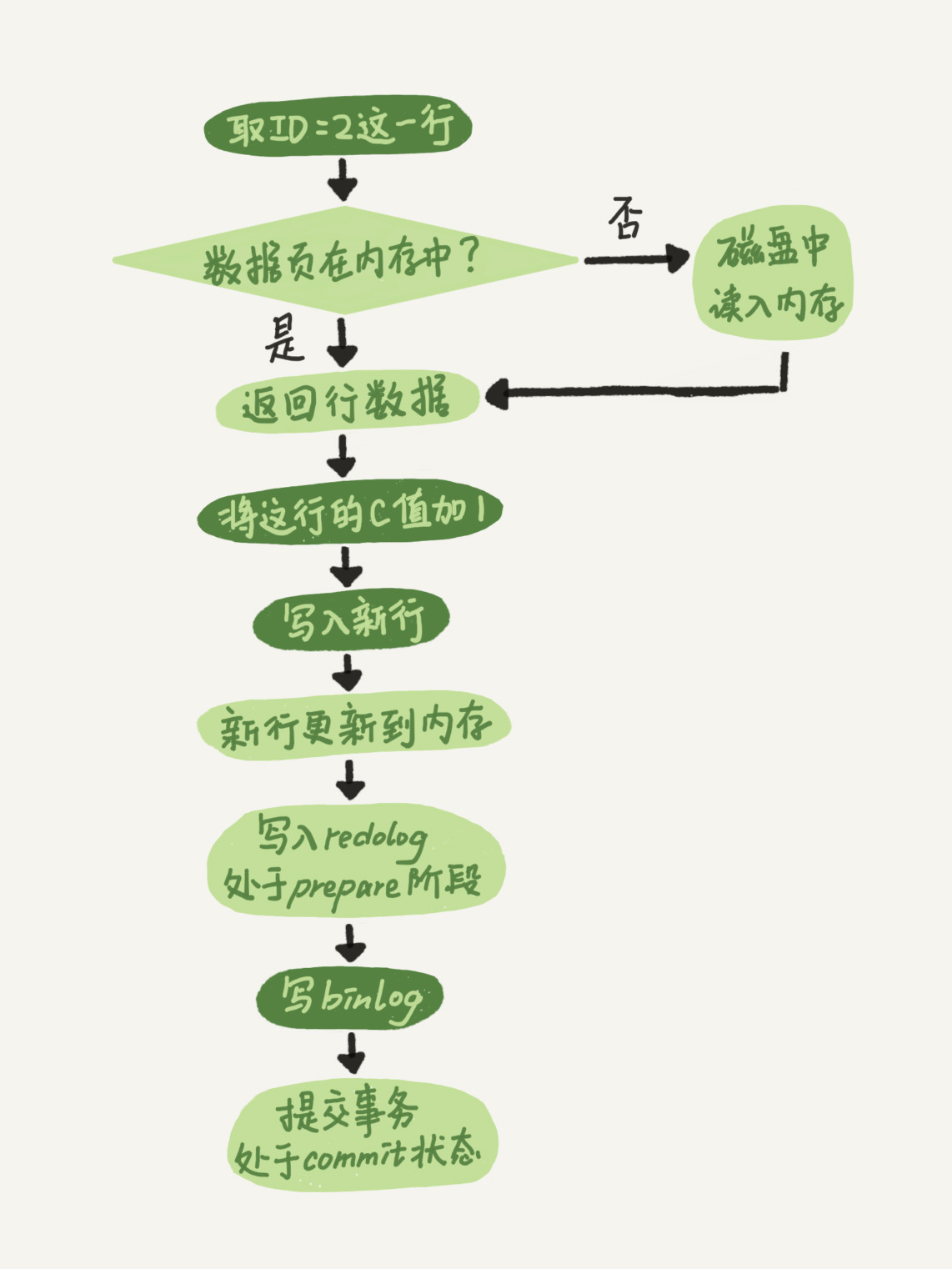
4 深入浅出索引 上
索引的结构
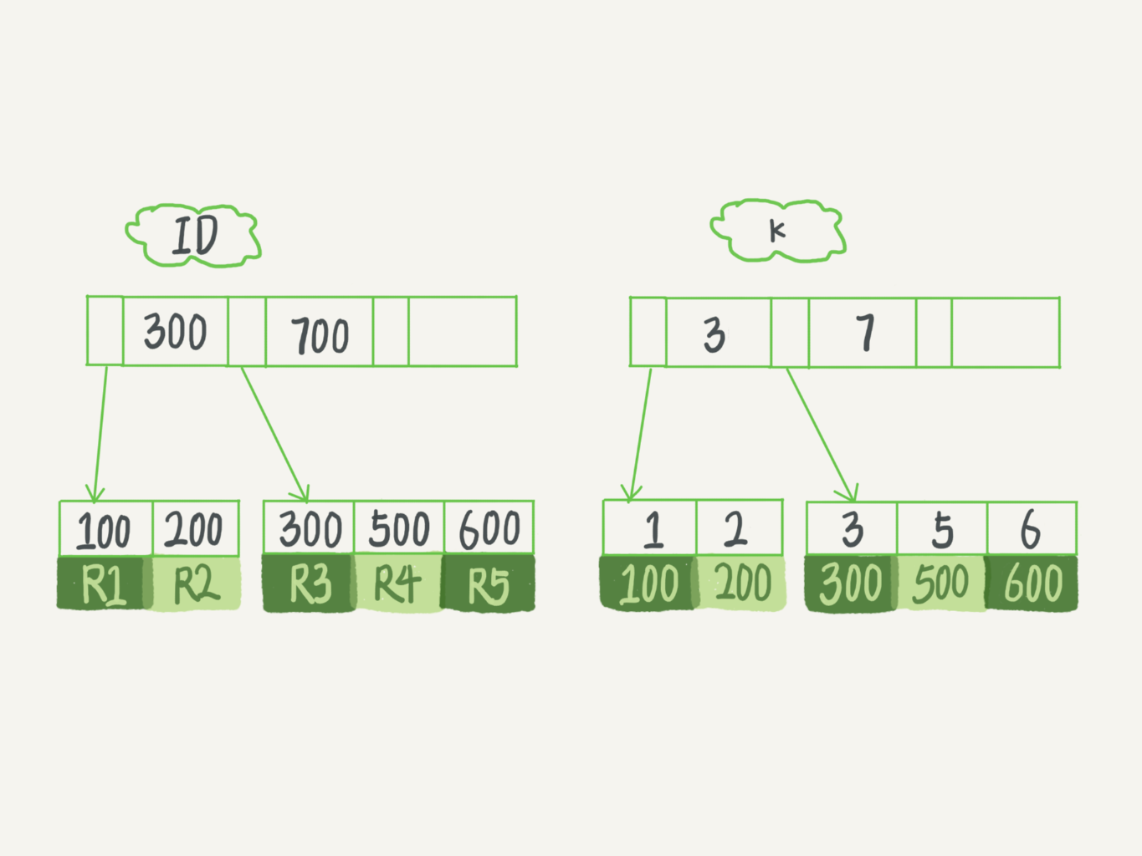
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
问题
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
最后,我给你留下一个问题吧。对于上面例子中的 InnoDB 表 T,如果你要重建索引 k,你的两个 SQL 语句可以这么写
alter table T drop index k;
alter table T add index(k);
如果你要重建主键索引,也可以这么写:
alter table T drop primary key;
alter table T add primary key(id);
我的问题是,对于上面这两个重建索引的作法,说出你的理解。如果有不合适的,为什么,更好的方法是什么?
重建索引 k 的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table T engine=InnoDB(这个语句在innobDB里会触发mysql重建该表,并进行碎片处理)。
4 深入浅出索引 下
索引覆盖
索引包含的信息就足以满足查询要求,不需要回表(回表指的是通过索引查到主键之后通过主键去表里查询记录的过程)。
如果我们有一个高频请求,是在市民表通过身份证查询名字。这个时候建立索引(身份证号、姓名),就可以简单通过索引来查到名字,而不需要回表。
最左前缀原则
对于索引(a, b),如果查询字段是a,那还是可以用这个索引的。
所以索引(a, b)可以用来查询字段a,b,也可以单独查询字段a。如果还要单独查询b的话,就需要建立一个索引b。
如果能通过调整顺序,减少维护一个索引是最好的。
如果a和b都有分别查询的需求,我们需要创建(a, b),(b)还是(b, a), (a)呢?可以从空间的角度来衡量,单独为a字段创建索引还是为b字段创建索引更节省空间。
索引下推
在 MySQL 5.6 之前,只能从 ID3 开始一个个回表。到主键索引上找出数据行,再对比字段值。而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
查询
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
也就是说,对于这个索引(name, age),在遍历这个索引的时候可以事先把age ≠10的排除掉,就不用去回表了。
没有索引下推:
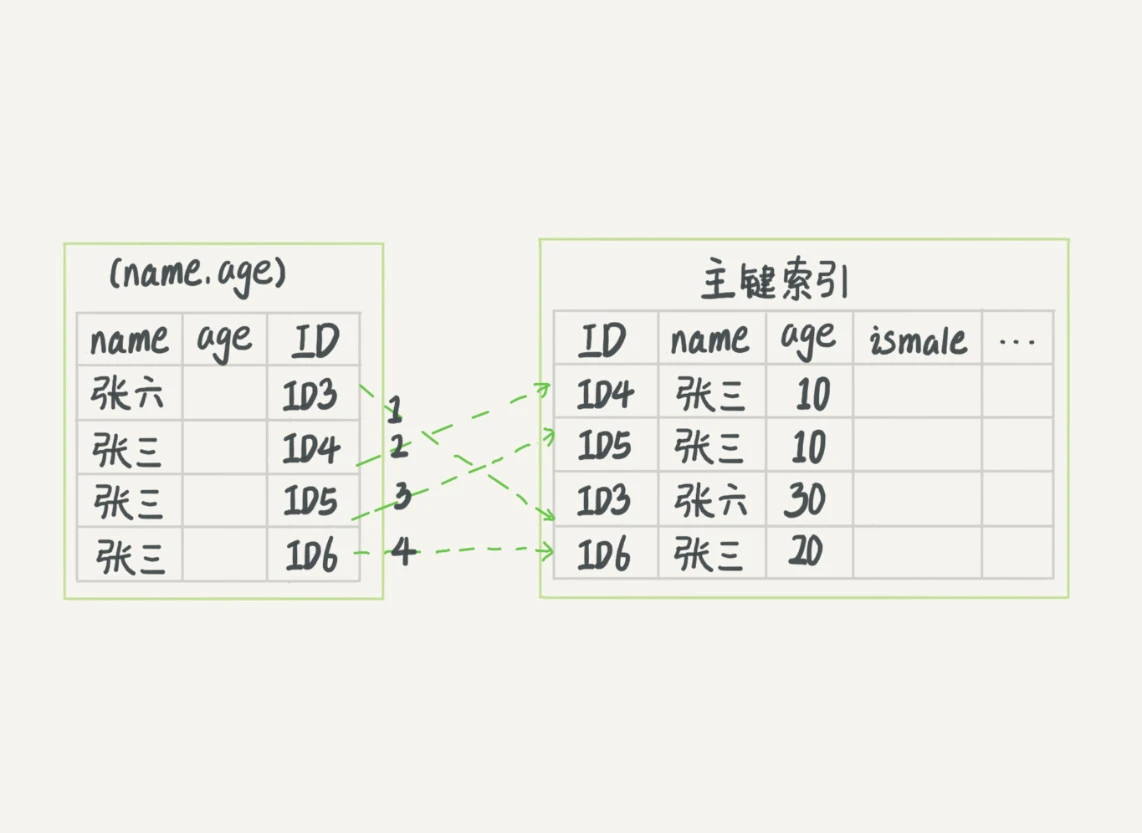
索引下推:
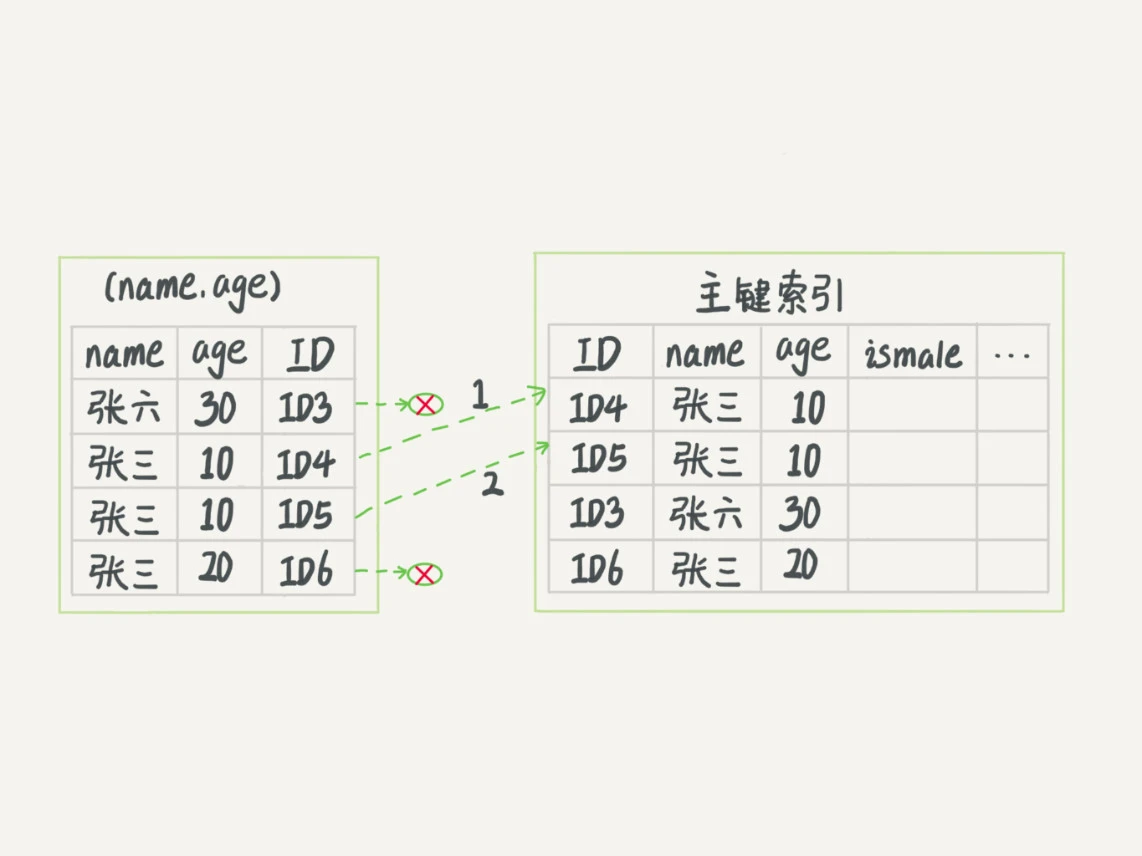
06 | 全局锁和表锁 :给表加个字段怎么有这么多阻碍?
全局锁
Flush tables with read lock (FTWRL)
全局备份的时候用,这是为了解决备份时事务不一致问题,所以需要加锁。举个例子,比如用户买课这个场景,会使得余额表-20,课程表多出来一门课。如果先备份了余额表,然后用户买课,这个时刻开始备份,买完课之后课程表多了一门课,并且扣了钱。所以备份的数据就会备份购买之前的余额,以及购买之后的课程表,就会使得事务不一致。
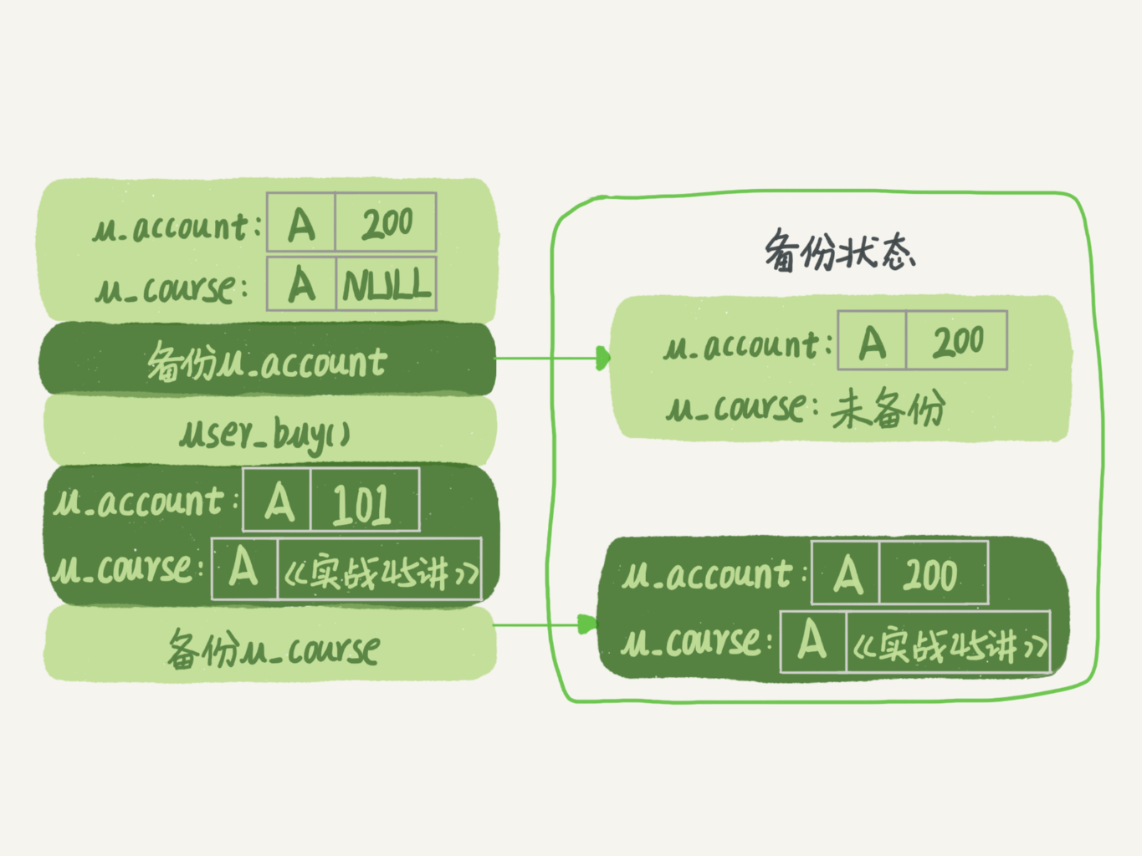
官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数–single-transaction 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
为什么有了这个功能,还需要全局锁?
因为可能有不支持事务的引擎。
你也许会问,既然要全库只读,为什么不使用 set global readonly=true 的方式呢?确实 readonly 方式也可以让全库进入只读状态,但我还是会建议你用 FTWRL 方式,主要有两个原因:一是,在有些系统中,readonly 的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改 global 变量的方式影响面更大,我不建议你使用。二是,在异常处理机制上有差异。如果执行 FTWRL 命令之后由于客户端发生异常断开,那么 MySQL 会自动释放这个全局锁,整个库回到可以正常更新的状态。而将整个库设置为 readonly 之后,如果客户端发生异常,则数据库就会一直保持 readonly 状态,这样会导致整个库长时间处于不可写状态,风险较高。
表级锁
在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大。
另外表级的锁是 MDL(metadata lock)MDL 不需要显式使用,在访问一个表的时候会被自动加上。MDL 的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
这个的作用就是在修改表结构的时候加写锁,增删改查的时候加读锁。所以修改表结构的时候就不能进行增删改查,但是增删改查之间不影响。
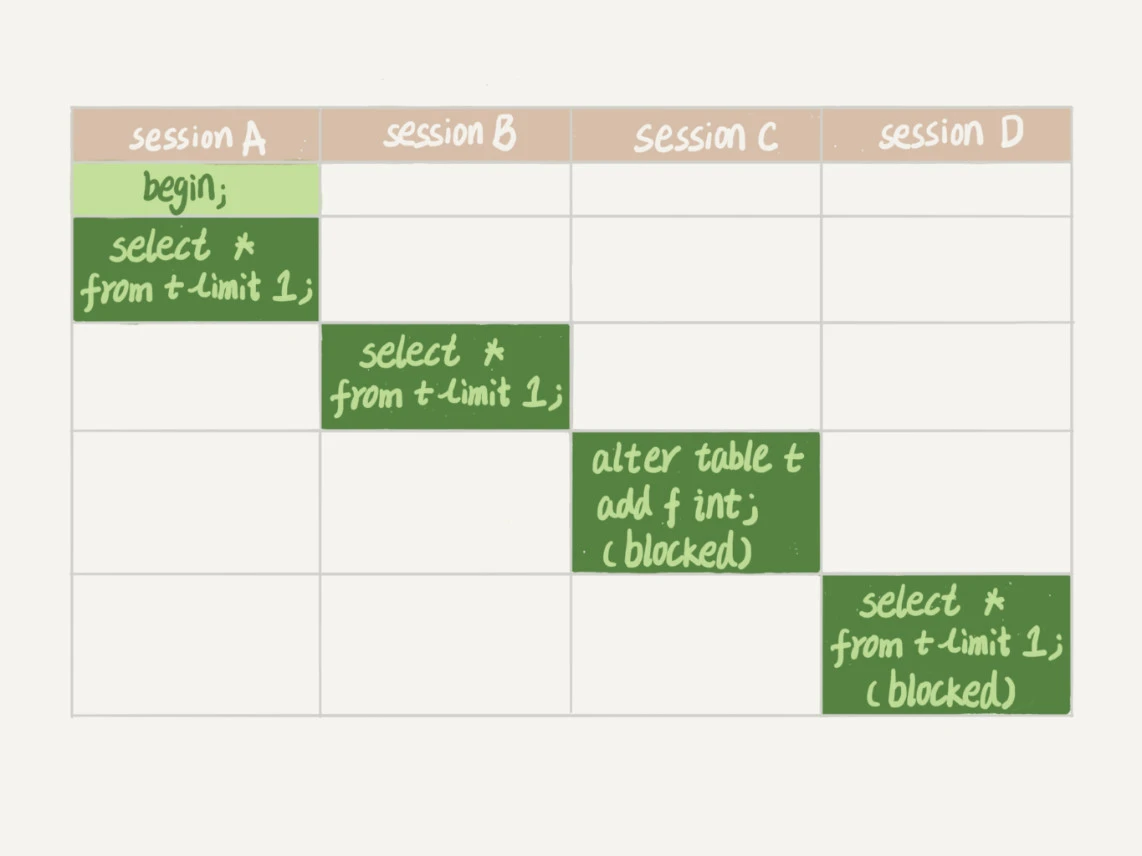
上面这张图,Session A开启了事务,所以上了读锁。sessionB也需要读锁所以不影响。但是session C需要的是写锁,它就阻塞了。它阻塞会导致后面的需要加读锁的session D也阻塞了,整个表就不能读写了。
这里的解决方案是,
- 排查长事务问题。
- 执行改表操作的时候设定一个等待时间,如果超过了这个时间就自动放弃。
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
07 | 行锁功过:怎么减少行锁对性能的影响?
两阶段锁
行锁在需要的时候添加,但是要在事务结束之后才释放。
死锁和死锁检测

当出现死锁以后,有两种策略:
一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数 innodb_lock_wait_timeout 来设置。
另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑。
在 InnoDB 中,innodb_lock_wait_timeout 的默认值是 50s,意味着如果采用第一个策略,当出现死锁以后,第一个被锁住的线程要过 50s 才会超时退出,然后其他线程才有可能继续执行。对于在线服务来说,这个等待时间往往是无法接受的。
但是,我们又不可能直接把这个时间设置成一个很小的值,比如 1s。这样当出现死锁的时候,确实很快就可以解开,但如果不是死锁,而是简单的锁等待呢?所以,超时时间设置太短的话,会出现很多误伤。
正常情况下我们还是要采用第二种策略,即:主动死锁检测,而且 innodb_deadlock_detect 的默认值本身就是 on。主动死锁检测在发生死锁的时候,是能够快速发现并进行处理的,但是它也是有额外负担的。
怎么解决由这种热点行更新导致的性能问题呢?
- 在客户端里控制并发度,比如同一个客户端最多10个线程同时更新。但这样也有问题,如果有600个客户端,每个客户端5个并发线程,这样也有3000个了。
- 修改mysql源码,对于相同行的更新,进入引擎之前排队。
- 你可以考虑通过将一行改成逻辑上的多行来减少锁冲突。还是以影院账户为例,可以考虑放在多条记录上,比如 10 个记录,影院的账户总额等于这 10 个记录的值的总和。这样每次要给影院账户加金额的时候,随机选其中一条记录来加。这样每次冲突概率变成原来的 1/10,可以减少锁等待个数,也就减少了死锁检测的 CPU 消耗。这个方案看上去是无损的,但其实这类方案需要根据业务逻辑做详细设计。如果账户余额可能会减少,比如退票逻辑,那么这时候就需要考虑当一部分行记录变成 0 的时候,代码要有特殊处理。
08 | 事务到底是隔离的还是不隔离的?
这里说到可重复读是怎么实现的,以及可重复读的快照实现原理。
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);

对于上面这个图,事务A查询到的是1,而事务B查询到的值是3。
先简单说一下我自己的理解:事务B在查询之前做了一次更新,这次更新要依赖于id=1这行数据的最新的已经提交的版本,所以最新版本是事务C的更新,所以最新版本是(1,2),事务B更新之后,变成了(1,3),所以事务B读出来的结果是3。这就叫当前读。而事务A因为只做查询没做更新,所以按照可重复读的定义,它读的结果和它这个事务启动时的结果一致,就是1。
原理:
在InnoDB里,每个事务都有唯一的ID,叫transaction ID,是按照申请顺序唯一严格递增的。每一行数据也是有多个版本的,当事务修改数据时,把transaction ID赋值给版本,记为row trx_id。
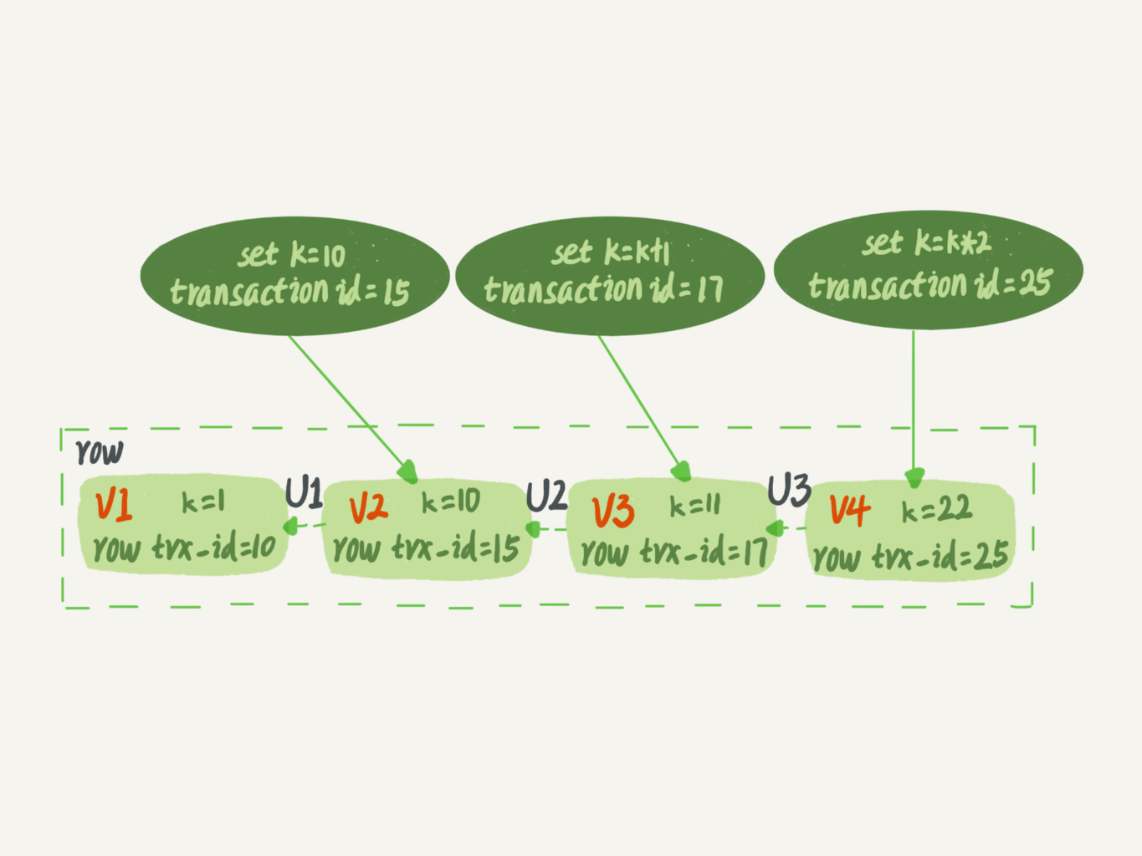
如图是一行数据被不同事物更新之后的不同版本,实际上v1,v2,v3不是物理存在的,当需要v2的时候会从v4开始回滚两次得到。按照可重复读的定义,对于事物启动之前所有提交的结果,事务是可见的,但是对于事物启动之后提交的结果,是不可见的。
InnoDB在事务启动的时候,为每一个事务维护了一个数组,表示事务启动瞬间所有活跃的事务。活跃指的是启动了还没提交。
数组里面事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。
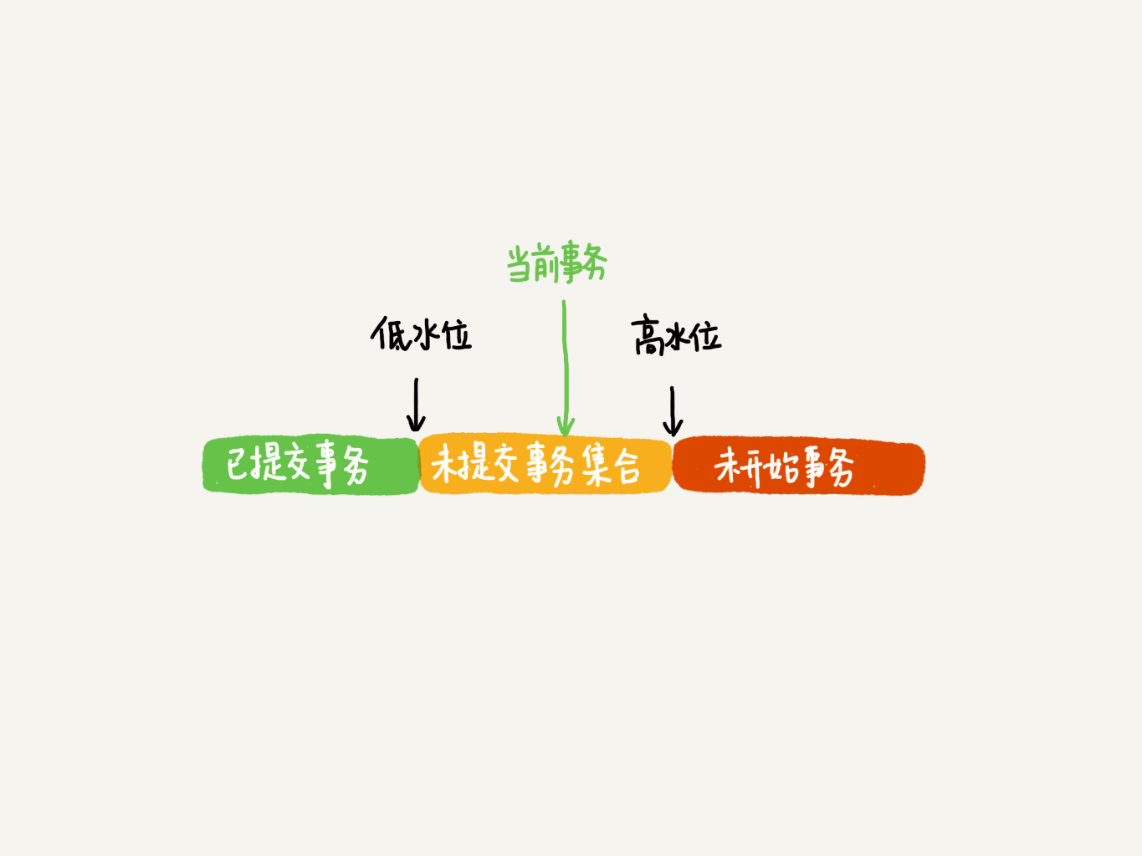
我们假设:
- 事务 A 开始前,系统里面只有一个活跃事务 ID 是 99;
- 事务 A、B、C 的版本号分别是 100、101、102,且当前系统里只有这四个事务;
- 三个事务开始前,(1,1)这一行数据的 row trx_id 是 90。
这样,事务 A 的视图数组就是[99,100], 事务 B 的视图数组是[99,100,101], 事务 C 的视图数组是[99,100,101,102]。
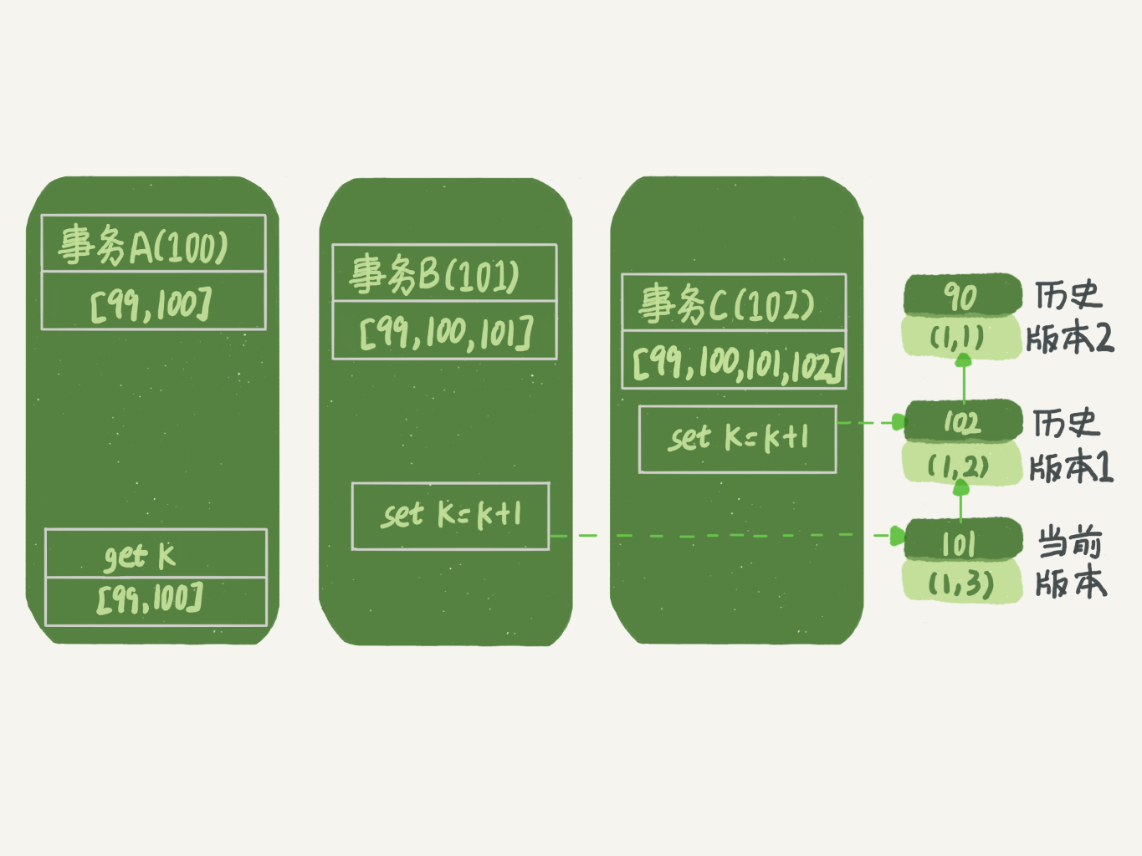
第一个有效更新是事务C把(1,1)改成了(1,2),所以这行数据有一个版本是以c的transaction ID为准的102版本。
第二个有效更新是事务 B,把数据从 (1,2) 改成了 (1,3)。这时候,这个数据的最新版本(即 row trx_id)是 101,而 102 又成为了历史版本。
好,现在事务 A 要来读数据了,它的视图数组是[99,100]。当然了,读数据都是从当前版本读起的。所以,事务 A 查询语句的读数据流程是这样的:找到 (1,3) 的时候,判断出 row trx_id=101,比高水位大,处于红色区域,不可见;接着,找到上一个历史版本,一看 row trx_id=102,比高水位大,处于红色区域,不可见;再往前找,终于找到了(1,1),它的 row trx_id=90,比低水位小,处于绿色区域,可见。这样执行下来,虽然期间这一行数据被修改过,但是事务 A 不论在什么时候查询,看到这行数据的结果都是一致的,所以我们称之为一致性读。
事务B的更新,按照一致性读的原则,好像是不对的。这个是因为B去更新数据的时候,最新的版本已经是C更新的这个102版本的(1,2)了,它不能按照历史版本来更新,因为如果按照历史版本来更新的话事务C的更新就会丢失了。
所以,这里就用到了这样一条规则:更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read)。
因此,在更新的时候,当前读拿到的数据是 (1,2),更新后生成了新版本的数据 (1,3),这个新版本的 row trx_id 是 101。
所以,在执行事务 B 查询语句的时候,一看自己的版本号是 101,最新数据的版本号也是 101,是自己的更新,可以直接使用,所以查询得到的 k 的值是 3。
这里我们提到了一个概念,叫作当前读。其实,除了 update 语句外,select 语句如果加锁,也是当前读。所以,如果把事务 A 的查询语句 select * from t where id=1 修改一下,加上 lock in share mode 或 for update,也都可以读到版本号是 101 的数据,返回的 k 的值是 3。下面这两个 select 语句,就是分别加了读锁(S 锁,共享锁)和写锁(X 锁,排他锁)
再往前一步,假设事务 C 不是马上提交的,而是变成了下面的事务 C’,会怎么样呢?

事务 C’的不同是,更新后并没有马上提交,在它提交前,事务 B 的更新语句先发起了。前面说过了,虽然事务 C’还没提交,但是 (1,2) 这个版本也已经生成了,并且是当前的最新版本。那么,事务 B 的更新语句会怎么处理呢?这时候,我们在上一篇文章中提到的“两阶段锁协议”就要上场了。事务 C’没提交,也就是说 (1,2) 这个版本上的写锁还没释放。而事务 B 是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务 C’释放这个锁,才能继续它的当前读。
如果隔离级别是读提交呢?
而读提交的逻辑和可重复读的逻辑类似,它们最主要的区别是:
- 在可重复读隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都共用这个一致性视图;
- 在读提交隔离级别下,每一个语句执行前都会重新算出一个新的视图。
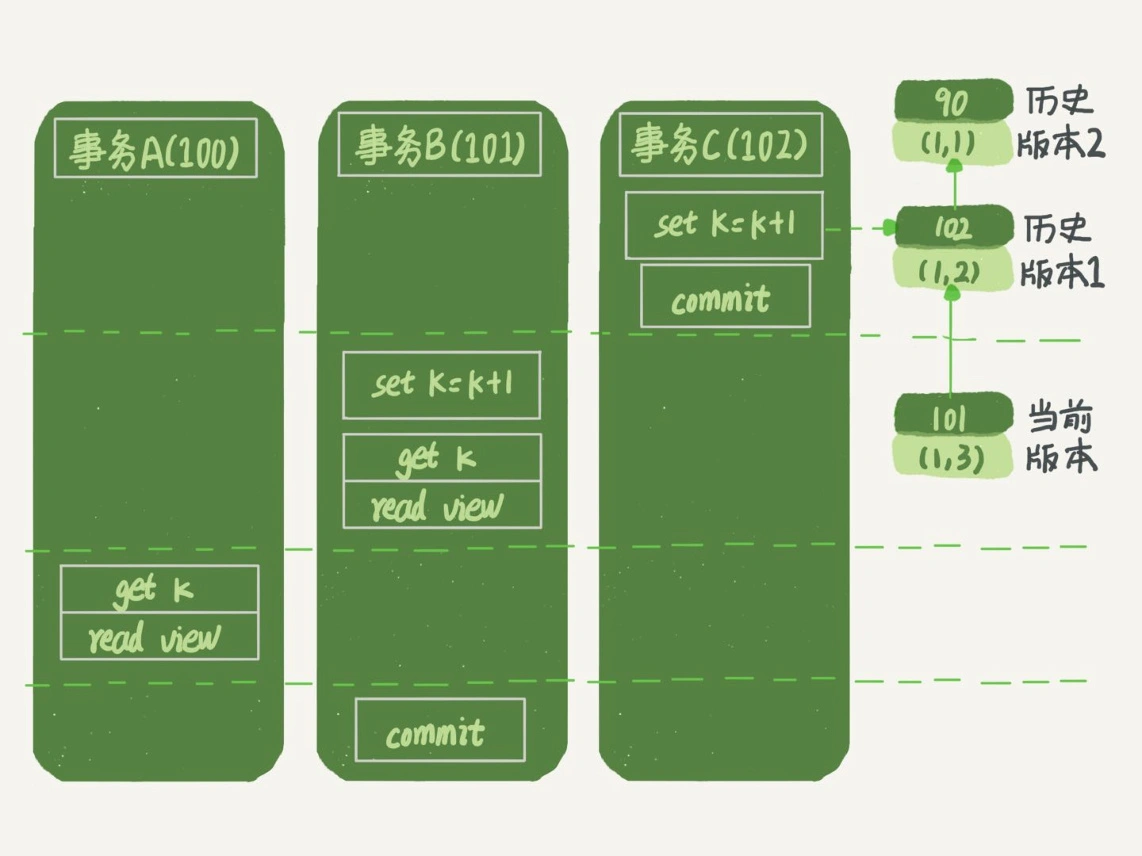
在读提交级别下,因为C的修改是已经提交的,所以事务A读到的结果是1,2。B读到的结果很显然是自己的更新,所以是(1,3)
09 | 普通索引和唯一索引,应该怎么选择?
维护一张市民表,经常用身份证号来查名字,所以要给身份证号加索引。这里业务可以保证不会重复写入身份证号,所以你应该给身份证号加普通索引还是唯一索引呢?
在查询方面,唯一索引和写入索引区别不大。
对于唯一索引,因为有了唯一约束,在B+树里找到满足要求的叶子后便不再寻找。而对于普通索引,则需要再向后找,直到不满足为止,如果要找的值在数据页中,那就是一次指针挪动,可以忽略不计。当然如果正好要找的值是数据页的最后一项,就需要查下一个页,但是一个页有很多条索引数据,所以这个概率很低。
在写入方面,因为有change buffer的优化,所以会差别很大。
change buffer是做什么的呢,就是当我们要更新数据的时候,如果数据在内存中,就直接更新。如果不在内存中,则先将数据写入change buffer。这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
因为唯一索引需要保证唯一,所以不能用change buffer。
假如唯一索引现在已经有了3和5,要插入一个4。
第一种情况是,这个记录要更新的目标页在内存中。
这时,InnoDB 的处理流程如下:
对于唯一索引来说,找到 3 和 5 之间的位置,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,找到 3 和 5 之间的位置,插入这个值,语句执行结束。
重点是对于要更新的目标页不在内存中的。
对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,则是将更新记录在 change buffer,语句执行就结束了。
回到我们文章开头的问题,普通索引和唯一索引应该怎么选择。其实,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。所以,我建议你尽量选择普通索引。
change buffer什么时候开关
如果所有的更新后面,都马上伴随着对这个记录的查询,那么你应该关闭 change buffer。而在其他情况下,change buffer 都能提升更新性能。在实际使用中,你会发现,普通索引和 change buffer 的配合使用,对于数据量大的表的更新优化还是很明显的。特别地,在使用机械硬盘时,change buffer 这个机制的收效是非常显著的。所以,当你有一个类似“历史数据”的库,并且出于成本考虑用的是机械硬盘时,那你应该特别关注这些表里的索引,尽量使用普通索引,然后把 change buffer 尽量开大,以确保这个“历史数据”表的数据写入速度。
10 | MySQL为什么有时候会选错索引?
- mysql存在优化器选择错索引的情况,这个时候需要优化引导,或者加上force index来选择正确的索引。前缀索引的优点是节省空间。
- 这里因为涉及到mysql的一些bug,所以作者没有展开讲原理。
11|如何给字符串加索引?
- 字符串索引是可以加前缀索引的。
- 使用前缀索引后,可能会导致查询语句读数据的次数变多。
- 使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
- 考虑前缀的区分度。算出前缀的区分度。
mysql> select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7,from SUser;
当然,使用前缀索引很可能会损失区分度,所以你需要预先设定一个可以接受的损失比例,比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,你就可以选择前缀长度为 6。
也就是说,使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。
倒序存储:
第一种方式是使用倒序存储。如果你存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写:
mysql> select field_list from t where id_card = reverse('input_id_card_string');
第二种方式是使用 hash 字段。你可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
- 都不支持范围查询,只能支持等值查询
- 倒叙存储不会消耗
倒序存储和hash的异同。
它们的区别,主要体现在以下三个方面:从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。如果只从这两个函数的计算复杂度来看的话,reverse 函数额外消耗的 CPU 资源会更小些。从查询效率上看,使用 hash 字段方式的查询性能相对更稳定一些。因为 crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。而倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
12 | 为什么我的MySQL会“抖”一下?
一个可能的原因是可能会碰到刷脏页的情况,也就是内存满了,redo log满了,这个时候需要将数据写到磁盘中,再相应用户的查询请求,所以会变得慢。这里可以通过设置一些参数来控制刷脏页的速度,以及脏页比例。
13 | 为什么表数据删掉一半,表文件大小不变?
delete 命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。也就是说,通过 delete 命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是“空洞”。
如果数据是按照索引递增顺序插入的,那么索引是紧凑的。但如果数据是随机插入的,就可能造成索引的数据页分裂。假设图 1 中 page A 已经满了,这时我要再插入一行数据,会怎样呢?
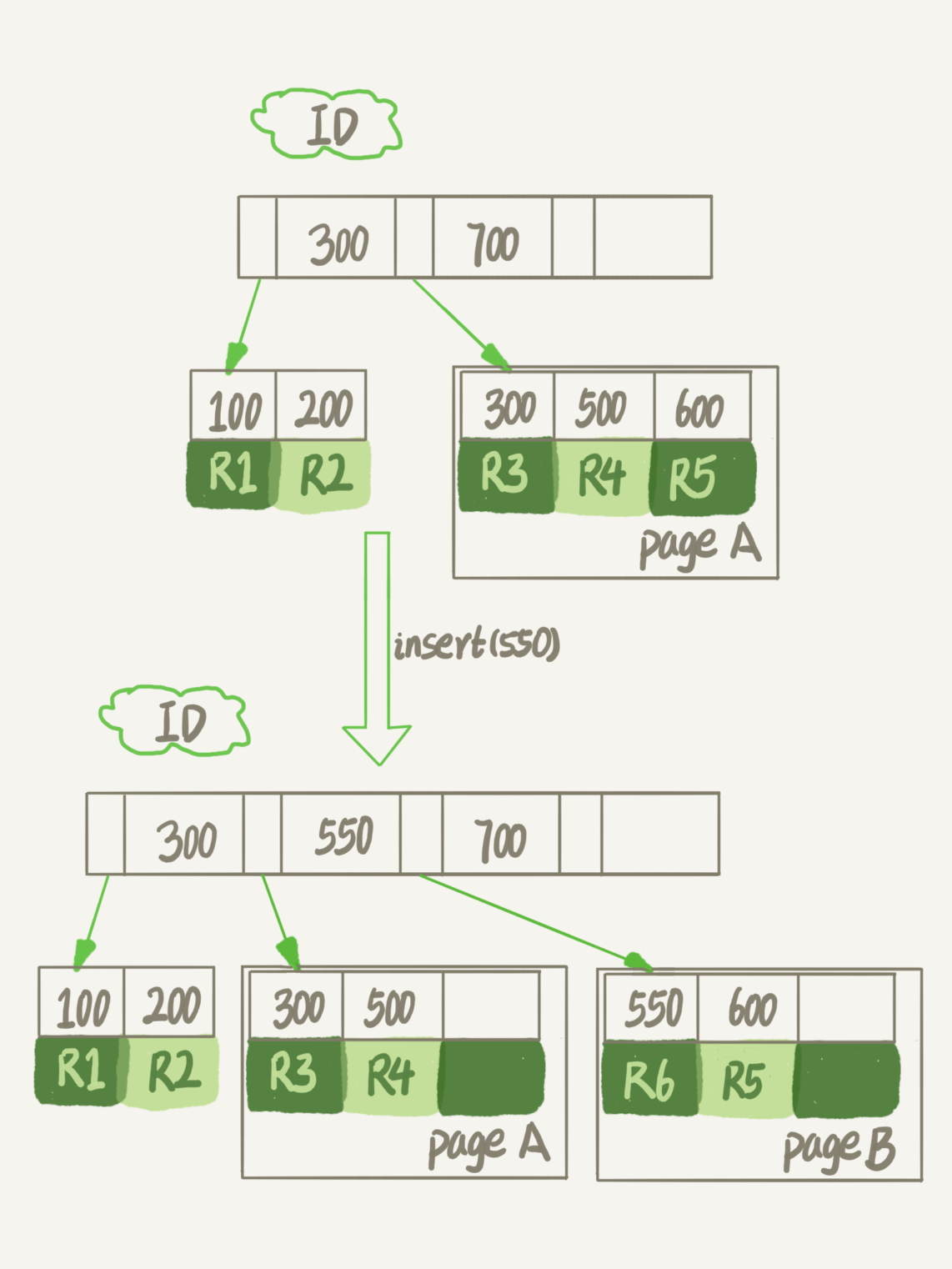
另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造成空洞的。也就是说,经过大量增删改的表,都是可能是存在空洞的。所以,如果能够把这些空洞去掉,就能达到收缩表空间的目的。而重建表,就可以达到这样的目的。
重建表
试想一下,如果你现在有一个表 A,需要做空间收缩,为了把表中存在的空洞去掉,你可以怎么做呢?你可以新建一个与表 A 结构相同的表 B,然后按照主键 ID 递增的顺序,把数据一行一行地从表 A 里读出来再插入到表 B 中。由于表 B 是新建的表,所以表 A 主键索引上的空洞,在表 B 中就都不存在了。显然地,表 B 的主键索引更紧凑,数据页的利用率也更高。如果我们把表 B 作为临时表,数据从表 A 导入表 B 的操作完成后,用表 B 替换 A,从效果上看,就起到了收缩表 A 空间的作用。这里,你可以使用 alter table A engine=InnoDB 命令来重建表。在 MySQL 5.5 版本之前,这个命令的执行流程跟我们前面描述的差不多,区别只是这个临时表 B 不需要你自己创建,MySQL 会自动完成转存数据、交换表名、删除旧表的操作。
我给你简单描述一下引入了 Online DDL 之后,重建表的流程:建立一个临时文件,扫描表 A 主键的所有数据页;用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中,对应的是图中 state2 的状态;临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态;用临时文件替换表 A 的数据文件。
14 | count(*)这么慢,我该怎么办?
count(*)对于MyISAM是计数的,但Innodb是取记录算出来的,因为它要支持事务所以它不能用变量计数。
对于计数问题:
- MyISAM 表虽然 count() 很快,但是不支持事务;
- show table status 命令虽然返回很快,但是不准确;
- InnoDB 表直接 count() 会遍历全表,虽然结果准确,但会导致性能问题。
对于计数问题我们可以用redis来做,但会出现逻辑上的不准确的问题。
对于这个场景,会话B插入读redis计数的时候还没有+1,但是最近100条已经有了一行新的数据。会话A的两个操作对调,则会出现redis计数确实+1了,但是记录还没有被插入。
解决办法是用事务,并且是把计数存到单独一张表里

对于 count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。对于 count(1) 来说,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。单看这两个用法的差别的话,你能对比出来,count(1) 执行得要比 count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据行,以及拷贝字段值的操作。
对于 count(字段) 来说:如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。也就是前面的第一条原则,server 层要什么字段,InnoDB 就返回什么字段。
但是 count() 是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count() 肯定不是 null,按行累加。看到这里,你一定会说,优化器就不能自己判断一下吗,主键 id 肯定非空啊,为什么不能按照 count() 来处理,多么简单的优化啊。当然,MySQL 专门针对这个语句进行优化,也不是不可以。但是这种需要专门优化的情况太多了,而且 MySQL 已经优化过 count() 了,你直接使用这种用法就可以了。
所以结论是:按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(),所以我建议你,尽量使用 count()。
15 | 答疑文章(一):日志和索引相关问题
追问 8:正常运行中的实例,数据写入后的最终落盘,是从 redo log 更新过来的还是从 buffer pool 更新过来的呢?
回答:这个问题其实问得非常好。这里涉及到了,“redo log 里面到底是什么”的问题。实际上,redo log 并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由 redo log 更新过去”的情况。如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与 redo log 毫无关系。
在崩溃恢复场景中,InnoDB 如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让 redo log 更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。
从这里可以看到,redo log的作用是用来防止WAL(Write-Ahead Logging)的时候把数据修改写到位于内存的数据页中后,还没落盘的时候发生了crash是用来恢复那些还没有被落盘的数据用的。
业务设计问题
问题是这样的(我文字上稍微做了点修改,方便大家理解):
业务上有这样的需求,A、B 两个用户,如果互相关注,则成为好友。设计上是有两张表,一个是 like 表,一个是 friend 表,like 表有 user_id、liker_id 两个字段,我设置为复合唯一索引即 uk_user_id_liker_id。语句执行逻辑是这样的:
以 A 关注 B 为例:第一步,先查询对方有没有关注自己(B 有没有关注 A)select * from like where user_id = B and liker_id = A;
如果有,则成为好友insert into friend;
没有,则只是单向关注关系insert into like;
但是如果 A、B 同时关注对方,会出现不会成为好友的情况。因为上面第 1 步,双方都没关注对方。第 1 步即使使用了排他锁也不行,因为记录不存在,行锁无法生效。请问这种情况,在 MySQL 锁层面有没有办法处理?
CREATE TABLE `like` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`liker_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_id_liker_id` (`user_id`,`liker_id`)
) ENGINE=InnoDB;
CREATE TABLE `friend` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`friend_1_id` int(11) NOT NULL,
`friend_2_id` int(11) NOT NULL,
UNIQUE KEY `uk_friend` (`friend_1_id`,`friend_2_id`),
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
原来的逻辑:

首先,要给“like”表增加一个字段,比如叫作 relation_ship,并设为整型,取值 1、2、3。
值是 1 的时候,表示 user_id 关注 liker_id;
值是 2 的时候,表示 liker_id 关注 user_id;
值是 3 的时候,表示互相关注。
然后,当 A 关注 B 的时候,逻辑改成如下所示的样子:
应用代码里面,比较 A 和 B 的(ID)大小,如果A < B 就执行下面的逻辑
mysql> begin; /*启动事务*/
insert into `like`(user_id, liker_id, relation_ship) values(A, B, 1) on duplicate key update relation_ship=relation_ship | 1;
select relation_ship from `like` where user_id=A and liker_id=B;
/*代码中判断返回的 relation_ship,
如果是1,事务结束,执行 commit
如果是3,则执行下面这两个语句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(A,B);
commit;
如果 A>B,则执行下面的逻辑
mysql> begin; /*启动事务*/
insert into `like`(user_id, liker_id, relation_ship) values(B, A, 2) on duplicate key update relation_ship=relation_ship | 2;
select relation_ship from `like` where user_id=B and liker_id=A;
/*代码中判断返回的 relation_ship,
如果是2,事务结束,执行 commit
如果是3,则执行下面这两个语句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(B,A);
commit;
这两个代码的不同之处在于,relation_ship的值是1还是2,以及谁是user_id, 谁是like_id。在应用代码里保证里user_id永远小于like_id,所以两个用户相互关注的时候,在like里创建的user_id和like_id是一模一样的,都是小的在前。只是relation_ship不一样,如此一来,他们在关注的时候就会有唯一索引冲突,就会触发on duplicate
这个设计里,让“like”表里的数据保证 user_id < liker_id,这样不论是 A 关注 B,还是 B 关注 A,在操作“like”表的时候,如果反向的关系已经存在,就会出现行锁冲突。
然后,insert … on duplicate 语句,确保了在事务内部,执行了这个 SQL 语句后,就强行占住了这个行锁,之后的 select 判断 relation_ship 这个逻辑时就确保了是在行锁保护下的读操作。
| 操作符 “ |
” 是按位或,连同最后一句 insert 语句里的 ignore,是为了保证重复调用时的幂等性。这样,即使在双方“同时”执行关注操作,最终数据库里的结果,也是 like 表里面有一条关于 A 和 B 的记录,而且 relation_ship 的值是 3, 并且 friend 表里面也有了 A 和 B 的这条记录。 |
16 | “order by”是怎么工作的?
全字段排序
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;按照排序结果取前 1000 行返回给客户端。
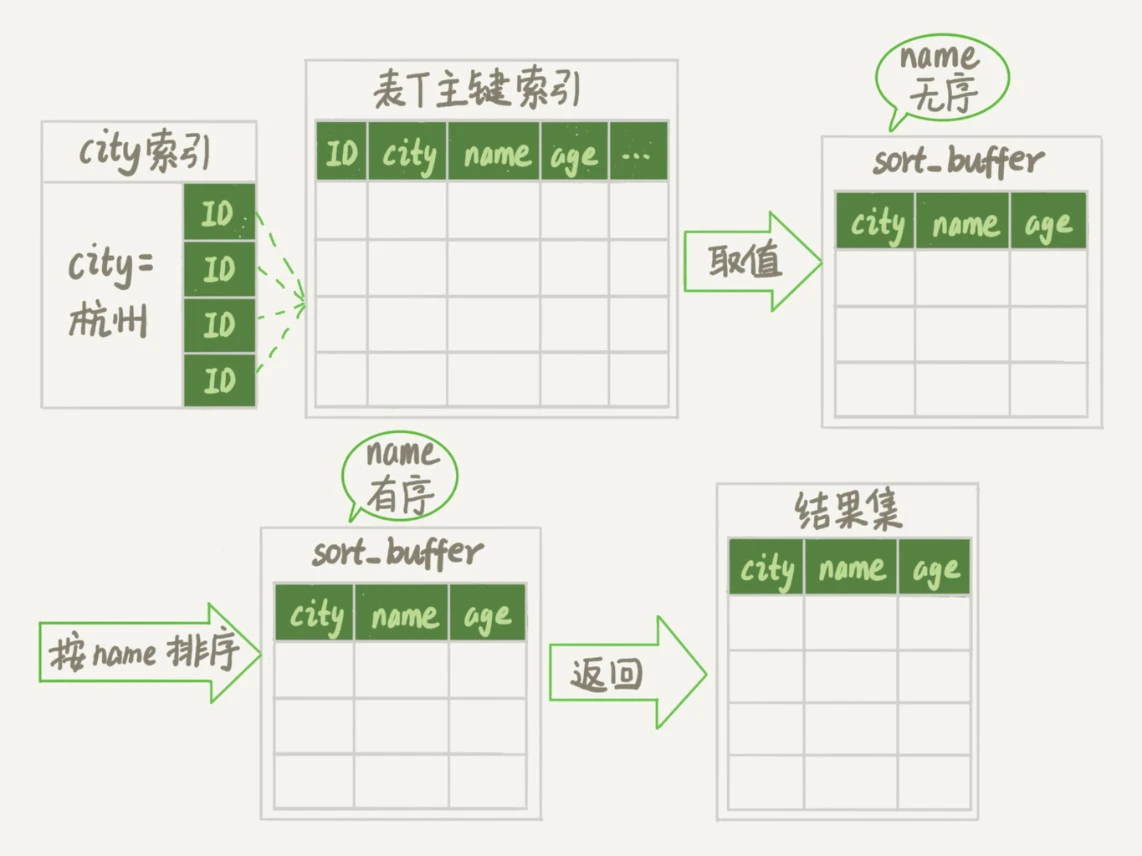
rowid 排序
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city=’杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
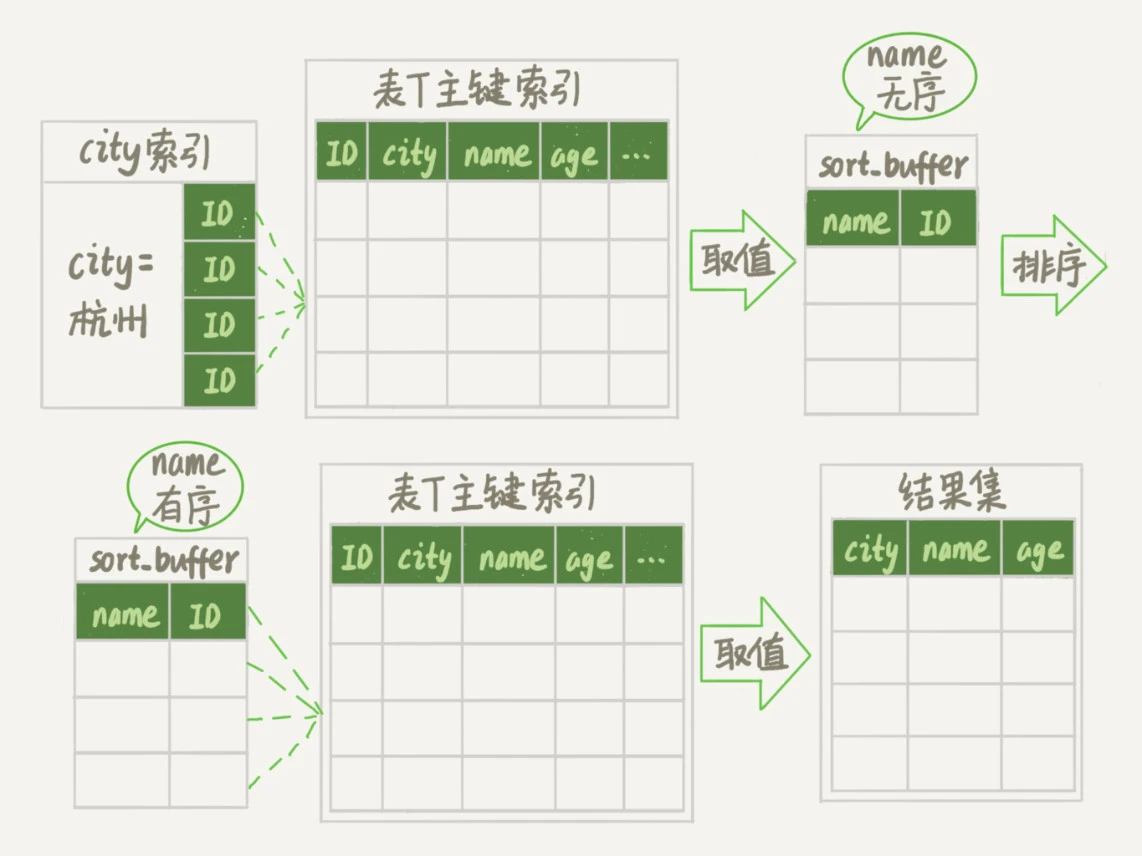
创建联合索引使得不用排序
所以,我们可以在这个市民表上创建一个 city 和 name 的联合索引,对应的 SQL 语句是:
alter table t add index city_user(city, name);
https://www.notion.so
在这个索引里面,我们依然可以用树搜索的方式定位到第一个满足 city=’杭州’的记录,并且额外确保了,接下来按顺序取“下一条记录”的遍历过程中,只要 city 的值是杭州,name 的值就一定是有序的。
- 从索引 (city,name) 找到第一个满足 city=’杭州’条件的主键 id;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,作为结果集的一部分直接返回
- 从索引 (city,name) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city=’杭州’条件时循环结束。
索引覆盖使得不用回表
alter table t add index city_user_age(city, name, age);
这时,对于 city 字段的值相同的行来说,还是按照 name 字段的值递增排序的,此时的查询语句也就不再需要排序了。这样整个查询语句的执行流程就变成了:
- 从索引 (city,name,age) 找到第一个满足 city=’杭州’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
- 重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city=’杭州’条件时循环结束。
17 | 如何正确地显示随机消息?
需求是在单词表里随机取3个单词。
用order by rand()来实现的话,如果MySQL使用快排或者归并来实现,会导致没有必要的排序。但后来My SQL新增了优先队列排序算法,就是找出top K。
随机方法2
- 取得整个表的行数,并记为 C。
- 取得 Y = floor(C * rand())。 floor 函数在这里的作用,就是取整数部分。
- 再用 limit Y,1 取得一行。
mysql> select count(*) into @C from t;
set @Y = floor(@C * rand());
set @sql = concat("select * from t limit ", @Y, ",1");
prepare stmt from @sql;
execute stmt;
DEALLOCATE prepare stmt;
随机方法3
- 得整个表的行数,记为 C;
- 根据相同的随机方法得到 Y1、Y2、Y3;
- 再执行三个 limit Y, 1 语句得到三行数据。
mysql> select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; //在应用代码里面取Y1、Y2、Y3值,拼出SQL后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
事务遇到唯一索引冲突会马上回滚吗?
签到系统的设计
autocommit的作用?
mvcc是什么?
多版本并发控制
读提交是怎么实现的?
redo log是什么?
DDL 是什么
---
layout: post
title: markdow嵌入html之markdown todolist的进度条
date: 2023-01-06 00:00:00 -0500
tags:
- 技术笔记
- 博客
- Markdown
---
突发奇想,对于markdown里的todolist,我想做一个进度条。所以就开始尝试。
首先打开我的博客,F12看我的markdown里todolist的渲染结果,也就是一个html页面的源代码,看到的todolist渲染结果大概是这样的。
<ul class="task-list" id="l1">
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled" />《幸福课》9
积极情绪</li>
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled" />《幸福课》10
如何去改变</li>
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled" />《幸福课》11
养成良好习惯</li>
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"
checked="checked" />10 MySQL为什么有时候会选错索引?</li>
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"
checked="checked" />11 怎么给字符串字段加索引?</li>
</ul>
所以我要做的是
- 用
document.querySelectorAll('ul')来获取所有的ul,
- 对于每个ul,遍历它的子节点。统计checked=”checked”的个数记为checked
- 判断checked个数是否大于0,不大于则直接跳出不处理。(因为ul可能是其他的ul,不一定包含checkbox,这里偷懒了,直接checked==0则返回)
- 得到数据之后创建progress元素。
- 把progress元素插入到ul之前。
也就是下面的代码,把下面的代码插入.md中,就可以实现给todo list加进度条了,哈哈哈。
很显然,对于jekyll框架来说,不需要每个.md底下都加,直接在layouts文件夹里找到渲染文章的那个html,往那里面加就好了。
这篇文章的markdownw文件里是有加下面这段代码的,所以我随便写几个todolist,在界面上应该能看到进度条。(同时因为我的博客渲染的时候也会插入相同的代码,所以这篇文章会看到两个进度条,问题不大。
<script>
function getProcess(ul) {
let total = 0, checked = 0;
var childs = ul.childNodes;
for (let i = 0; i < ul.childNodes.length; i++) {
var item = ul.childNodes[i]
if (item.childNodes.length > 0) {
// console.log(1)
// console.log(item.childNodes[0].checked)
if (item.childNodes[0].checked) {
checked++
}
total++
}
}
return [checked, total]
}
function createProgressDiv(max, value) {
let sp1 = document.createElement("div");
let progress = document.createElement("progress")
progress.value = value
progress.max = max
sp1.appendChild(progress)
let text = ` ${value}/${max}`
let progressInNumber = document.createTextNode(text)
sp1.appendChild(progressInNumber)
return sp1
}
function insertBeforeUL(ul) {
const [checked, total] = getProcess(ul);
if (checked == 0) {
return;
}
let progressDiv = createProgressDiv(total, checked)
let parentDiv = ul.parentNode;
parentDiv.insertBefore(progressDiv, ul);
}
var ulList = document.querySelectorAll('ul')
for (let i = 0; i < ulList.length; i++) {
insertBeforeUL(ulList[i])
}
</script>
示例
1
2
---
layout: post
title: 记录一次面试LRU
date: 2023-01-01 19:00:00 -0500
tags:
- 技术笔记
- 面试
- 算法
---
面试某家公司居然让我写LRU,写了40分钟才写出来orz我好菜。然后交给面试官的版本有bug。
面试后去leetcode提交又debug了下,可以通过了。
leetcode地址:https://leetcode.cn/problems/lru-cache/
我封装了一个链表,所以写LRU的时候就比较简洁。
func (this *LRUCache) Get(key int) int {
if v, ok := this.m[key]; ok {
this.linkedList.Remove(this.m[key])
this.linkedList.PutOnHead(this.m[key])
return v.val
} else {
return -1
}
}
func (this *LRUCache) Put(key int, value int) {
if v, ok := this.m[key]; ok {
v.val = value
this.linkedList.Remove(this.m[key])
this.linkedList.PutOnHead(this.m[key])
} else {
this.m[key] = &Node{key: key, val: value}
this.linkedList.PutOnHead(this.m[key])
this.len++
if this.len > this.capacity {
delete(this.m, this.linkedList.GetTail().key)
this.linkedList.Pop()
this.len--
}
}
}
但是对于链表要注意的事项:
- remove的时候要如果remove的是tail的话,记得更新tail
- remove的时候如果要remove的是head的话,需要更新head为head.next。
- 并且如果更新head之后是nil,那l.head.prev = nil是不需要的。这个主要是应对capacity=1的特例。
type LRUCache struct {
m map[int]*Node
capacity int
len int
linkedList *LinkedList
}
type Node struct {
key int
val int
prev *Node
next *Node
}
type LinkedList struct {
head *Node
tail *Node
}
func NewLinkedList() *LinkedList {
t := &LinkedList{}
return t
}
func (l *LinkedList) GetHead() *Node {
return l.head
}
func (l *LinkedList) GetTail() *Node {
return l.tail
}
func (l *LinkedList) Pop() {
if l.tail == nil {
return
}
l.tail = l.tail.prev
l.tail.next = nil
}
func (l *LinkedList) PutOnHead(node *Node) {
if l.head == nil {
l.head = node
l.tail = node
l.head.next = nil
l.head.prev = nil
return
}
node.next = l.head
l.head.prev = node
l.head = node
node.prev = nil
}
func (l *LinkedList) Remove(node *Node) {
if node == l.head {
l.head = l.head.next
if l.head != nil {
l.head.prev = nil
}
return
}
if node == l.tail {
l.tail = l.tail.prev
l.tail.next = nil
return
}
if node.prev != nil {
node.prev.next = node.next
}
if node.next != nil {
node.next.prev = node.prev
}
}
func Constructor(capacity int) LRUCache {
t := LRUCache{
m: make(map[int]*Node),
capacity: capacity,
linkedList: NewLinkedList(),
}
return t
}
func (this *LRUCache) Get(key int) int {
if v, ok := this.m[key]; ok {
this.linkedList.Remove(this.m[key])
this.linkedList.PutOnHead(this.m[key])
return v.val
} else {
return -1
}
}
func (this *LRUCache) Put(key int, value int) {
if v, ok := this.m[key]; ok {
v.val = value
this.linkedList.Remove(this.m[key])
this.linkedList.PutOnHead(this.m[key])
} else {
this.m[key] = &Node{key: key, val: value}
this.linkedList.PutOnHead(this.m[key])
this.len++
if this.len > this.capacity {
delete(this.m, this.linkedList.GetTail().key)
this.linkedList.Pop()
this.len--
}
}
}
---
layout: post
title: jekyll更新不生效问题
date: 2022-12-29 19:00:00 -0500
tags:
- 技术笔记
- 博客
- Jekyll
---
经常写文章发现不更新,找了下原因。
在这儿 https://blog.csdn.net/u011342224/article/details/107319003 找到了,原来是时间问题。
文章的时间
我在今天写了一篇博客,本地jekyll编译没有任何问题,但是Github Pages上却始终没有更新。 Google了一番,发现是个时区问题。Github Pages的server应该是跑在UTC时区下的,而 我所在的时区是北京时区,也就是UTC+8。在我今天发布的这篇博客里,所有的时间用的都是 UTC+8时区的本地时间。Github Pages估计只会编译server的当前时刻之前的文件。
把我的文章所用的时间都设置成前一天,再push一下,Github Pages就立马更新了。
---
layout: post
title: 2022_2023
date: 2022-12-29 19:00:00 -0500
tags:
- 年度总结
- 自我成长
---
2022
之前生日的时候会写一篇文章,当然那主要是感想,对于这一年想做的事那系列文章一般不写。所以这里应该需要简单记录一下
回顾2022
1月,《中国人眼中的朝鲜战争》1.28回家过年。
2月,《股票作手回忆录》
3月,《股票作手回忆录》
4月,《股票作手回忆录》,居家办公。
5月,《人民的名义》,五一假期回家,爬南山。
6月,《人民的名义》,买了尼康z5,尝试学摄影。
7月,《接纳不完美的自己》,买了Macbook Air m1。
8月,《接纳不完美的自己》,买了飞傲K5 pro和森海塞尔HD650,轻烧HiFi。
9月,《强风吹拂》,去了七娘山。写了一篇《如果今年是未来最好的一年,也请你关注美好的事物》。
10月,《哈佛幸福课》,国庆回家。
11月,《哈佛幸福课》,双十一买了跑鞋但一直都没去跑,11.21被告知裁员,11.25从Shopee离职。11.29过了24岁生日,发了一篇《24》
12月,《强风吹拂》12.14从深圳回家。
杂感
这一年没什么目标,所以也无从评判。只能简单记录下了。这一年英语水平有所提高,主要是在交流方面可以唠嗑和英文面试了,也尝试在读英文版的名著。然后因为工作需要学习了一些k8s相关的知识。
追求成长和进步肯定是没错的,但是没有了目标和方向,就不太好评判过去的这一段时间,并且,成长和进步也需要加上时间限制,否则虽然确实在成长但很慢,虽然说也没什么问题,但是到了需要竞争的时候就有问题了。不能说高考之后再把那些不会的高中数学知识学会是没有积极意义的,但如果提前一点,就能改变得更多。这也是我开始规划的原因。
2023
- 每个月开始之前要写一篇展望,这个月要完成什么,重心在什么地方。
- 每个月都要写一篇回顾,记录一下读了哪些书,取得哪些成就,有什么感想。
- 雅思6.5。
- 学习前端和JAVA(毕竟要吃饭的)
- 出国旅游。
- 读书,(读书计划具体每个月再定)
---
layout: post
title: 24
date: 2022-11-28 19:00:00 -0500
tags:
- 生日专题
- 生活
---
24
Created: November 29, 2022 12:08 PM
太长不看版
- 关于每年生日的文章
- 已经是第6篇了,穿越了我整个大学。
- 曾经觉得写这些可能没什么用,纯属自娱自乐。
- 后来发现人这一生,归根结底还是要把自己的事情想明白,这就够了。
并且很多朋友每年都看,有时候跟人交谈时,也会有一点用。
- 23->24
- 参加了一些稍微复杂的项目,也学习了新的技术。
- 这一年工作和生活很平衡。
- 英语水平有所提高。
- 感谢我的父母给予我,鼓励和自由
- 自由,包括高考报志愿,去什么地方工作这种大选择都是由我自己决定。
- 从小的兴趣爱好,打篮球,玩电子产品,都被支持。
- 从小到大伴随的鼓励,使得我在低谷时我觉得我可以逆天改命。
- 和这个世界谈谈
- 这一年里,很喜欢线下交谈,喜欢和我的好朋友去小酒馆,喜欢和他人交换对这个世界的看法。
- 寒冬
- 我觉得最近这几年这个世界不会好了,但是你可以越来越好,不是说你周遭的环境越来越好,而是说你这个人本身。做一些具体的事情,锻炼、学习和思考,就会让你比没做这些事情之前好一点点,这些和环境没有关系。
关于每年生日的文章
可能以前我会觉得我每年过生日写这么长的文章是不是有点矫情,但我后来发现,这么多年保持的写作习惯,是很有用的。虽然写得这么长,又大多是关于自己的事情,没有那么多人愿意看,但在写作的过程中我很好地表达了我自己。我庆幸我还保留着这个习惯,让我受益匪浅。
这样一篇记录我每年的想法的文章,从我19岁开始写,已经写了第6篇,可能有一天不会再公开发表,但我依然会保持写作。因为这一系列的文章,我再回看的时候,能够很清晰地看到过去的我是怎样想的,这比很多记录生活的朋友圈,丰富的视频和文字都要有意义。
我后来发现,人这一生,把自己的问题想明白,就够了。
并且,一个把自己的问题想明白的人,对别人也会有用的。想明白了自己的问题,当有一天我跟友人促膝长谈的时候,这些思考就他人很有用了。也就是俗话说的聊聊人生聊聊理想。
所以,这是有用,有意义的,不只是对我有用,当有一天我和我的朋友深入交谈时,对他人也有用。
23->24
回看去年的文章,去年这个时候,我刚刚毕业来到深圳,在shopee做着一个很简单的项目。对未来还很迷茫,文章里也不想去互联网大厂。
这一年参加了一个稍微复杂一点的项目,也学了一些新的技术。对未来还是那么明确的规划,不过把目光聚焦在了自己能做的事情,自己的状态上,很坦然接受周遭的一切,有在好好生活,一点儿也没有焦虑。再次,哪怕已经失业了我依然不想去国内互联网大厂。
已经工作一年多了,在Shopee的这一年半,工作和生活还是蛮平衡的,有时间去运动,去看书,去玩。同时我也很享受没有人打扰我的专注工作时间。当然有时候也有焦头烂额的时候,但总归来说不太多。这一年平平淡淡。不过在11.21的那天我通知被裁员了,也算是预料之中,甚至期盼已久,我应该要开始3个月不工作的时光了,万一明年找不到合适的工作还可以延长。
有一句鸡汤,“未来的你一定会感谢现在的自己。”我现在站在未来视角,很感谢过去的自己,我这一年以来下班都不搞技术,不刷题,不背八股,虽然菜得抠脚,但是这一年好快乐,学习拍照,学习社交,和我的好朋友们深夜饮酒,在家附近骑着我的单车吃吃喝喝。感谢之前那个夜以继日地学习刷题,风险意识很强,颓废几天就会焦虑到不行然后继续打起精神学习的自己,是那个时候的积淀让我暂时地快乐了一年。
这一年英语水平有所提高。刚来虾皮的时候参与的业务有一部分需要和不会说中文的同事打交道,所以英文沟通水平提高了不少,口语还马马虎虎,可以去蛇口的酒吧跟外国人聊天,参加全英文面试,就是稍微有点听不懂。在以前,被应试教育影响太深了,总觉得担心发音不标准,说错啥的,但其实真正用英语去交流,语法不太严谨,发音也不太标准这有影响但不大,重要的还是要迈出第一步。当然,语法和发音还是要注意的,不能摆烂。毕竟换位思考一下,一个中文说得不太好的老外用中文跟你交流,你虽然能听得懂,但听着也不舒服。
感谢我的父母,给予我鼓励和自由
和其他大多数中国父母一样,在物质上父母总是竭尽全力把最好的给孩子,他们真的尽力了。除此之外,我的父母在精神上给予了我很大程度的自由和鼓励,让我一直都能够追逐自己的梦想,听自己内心的声音。哪怕身处低谷,我也依然相信我可以改变。
我并非一路都是学霸,直到现在也只是个普普通通的(刚刚失业的)工程师。小考没考上我们县城重点,但最后从那所县城非重点初中考到了省重点。高考滑铁卢,但也能在普通学校里摸索着未来,摸到一线互联网企业的门槛。
现在,暂时失去了一份工作,但这也没什么大不了的。甚至去签字解约的时候我忍不住开心,马上要迎来假期了,根本算不上什么坎坷。
自由,让我遵从内心的声音。
鼓励,让我觉得我可以改变。
这一切,都感谢他们,物质上尽力而为,精神上充分给予我自由和鼓励。
好汉不提当年勇,我过去虽然有点成绩但放到更大的世界里不值一提。我只是想说,一个人,一个小孩,需要被鼓励,而不是打压。如果在小考没考好的时候我的父母就此骂我笨蛋,那可能真的就笨蛋了。另外,也需要自由。
如果你的父母也很开明,并且觉得这很正常,那恭喜你。但也不要觉得这理所当然,我这成长路上我见过太多伙伴从小被父母骂笨蛋,再加上确实受到一些挫折,再后来,他们会说,“反正我是笨蛋,就这样吧”。
和这个世界谈谈
最近的这一年,越来越敢于表达自己的想法,也很喜欢和他人交换想法。
交谈这是一件比较有意思的事情,这是我在忙于应试,沉迷技术的岁月里不曾意识到的快乐。也算是最近一两年的变化,我不再是只会网络群聊,靠写字来表达,现实沉默寡言的,我变成了愿意倾听,敢于表达,喜欢线下社交的。
然后我发现,比起大的饭局,我更喜欢二三人的促膝长谈,那样能够比较深入地真实地交谈,我可以勇敢说出我内心的真实想法,也能听到对方的真实想法。这也是两三人的聚会的好处,人多的时候大概都会为了烘托氛围讲段子,为了刷存在感而发言,或者为了考虑更多人的感受和自己的面子而隐藏了一些想法。
接纳自己的同时,也接纳了别人,接纳了这个世界。
寒冬
前不久我发表过一篇文章,《如果今年是未来十年最好的一年,也请你关注美好的事物》,那个时候公司正在传出裁员的消息,还没波及到我,现在波及了,更应该坚持那篇文章里的观点。
其实,我们的大脑是依据我们关注的事物来构建世界观的。如果你关注的是癌症诊断,你的生活就会变得不幸福、暗无天日;但是如果你关注的是夜间的一杯马提尼,你的生活将变得更加美好——尽管两种情境下的外部环境都是一样的。
加拉格尔总结道:“你的为人、你的思考、你的感受和所做之事,以及你的喜好,恰是你所关注事物的概括。”
前阵子一个群里有人问,“这个世界会好吗”
我说:“我觉得最近几年这个世界不会好了,但是你可以越来越好,不是说你周遭的环境越来越好,而是说你这个人本身。做一些具体的事情,锻炼 学习和思考,就是会让你比没做这些事情之前好一点点,这些和环境没有关系。”
我是悲观的,但又是乐观的。
还是可以做我喜欢的事情,享受专注工作带来的体验。没什么好担忧的。
---
layout: post
title: go_concurrency_control
date: 2022-05-12 20:00:00 -0400
tags:
- 技术笔记
- Go
---
在vmalert的代码里学到了一种控制并发数量的方法,指定并发数为concurrency,开一个concurrency长度的channel,每个routine执行的时候先往channel里塞空结构体,执行完了就把channel里的东西取出来。当channel满的时候就会塞不进去,就会阻塞住,从而控制了并发数。
package concurrency
import (
"fmt"
"sync"
"time"
)
type Rule struct {
ID int
}
type Group struct {
concurrency int
currentConcurrency int
mutex sync.Mutex
rules []Rule
}
func NewGroup(concurrency int, ruleNum int) Group {
g := Group{
concurrency: concurrency,
}
for i := 0; i < ruleNum; i++ {
g.rules = append(g.rules, Rule{ID: i})
}
return g
}
func (r *Rule) Run() {
// do your job
time.Sleep(time.Second)
}
func (g *Group) PrintStart(rule Rule) {
g.mutex.Lock()
g.currentConcurrency++
fmt.Printf("%v, start to run %v, concurrency num: %v\n", time.Now(), rule.ID, g.currentConcurrency)
g.mutex.Unlock()
}
func (g *Group) PrintEnd(rule Rule) {
g.mutex.Lock()
g.currentConcurrency--
fmt.Printf("%v, finish to run %v, concurrency num: %v\n", time.Now(), rule.ID, g.currentConcurrency)
g.mutex.Unlock()
}
func (g Group) Start() {
concurrencyChan := make(chan struct{}, g.concurrency)
wg := &sync.WaitGroup{}
for _, rule := range g.rules {
wg.Add(1)
go func(wg *sync.WaitGroup, rule2 Rule) {
defer wg.Done()
defer func() {
<- concurrencyChan
}()
concurrencyChan <- struct{}{}
g.PrintStart(rule2)
rule2.Run()
g.PrintEnd(rule2)
}(wg, rule)
}
wg.Wait()
}
---
layout: post
title: trying_to_write_eng_blog
date: 2022-04-23 20:00:00 -0400
tags:
- 写作
- 博客
---
background
Recently, I found some ways to improve my English ability.
- think in English
- watch English video
- write English text, for example blogs, documents.
- find someone to talk in English
- go travel to some country where speak English, and only speak English during traveling.
---
layout: post
title: ndrj_crawl
date: 2022-04-23 20:00:00 -0400
tags:
- 技术笔记
- 爬虫
---
- 登陆https://nideriji.cn
- 打开浏览器的开发者模式,复制auth
- 把auth粘贴到22行
- python main.py就可以了,可能需要安装requests包,这个自行用搜索引擎查怎么安装
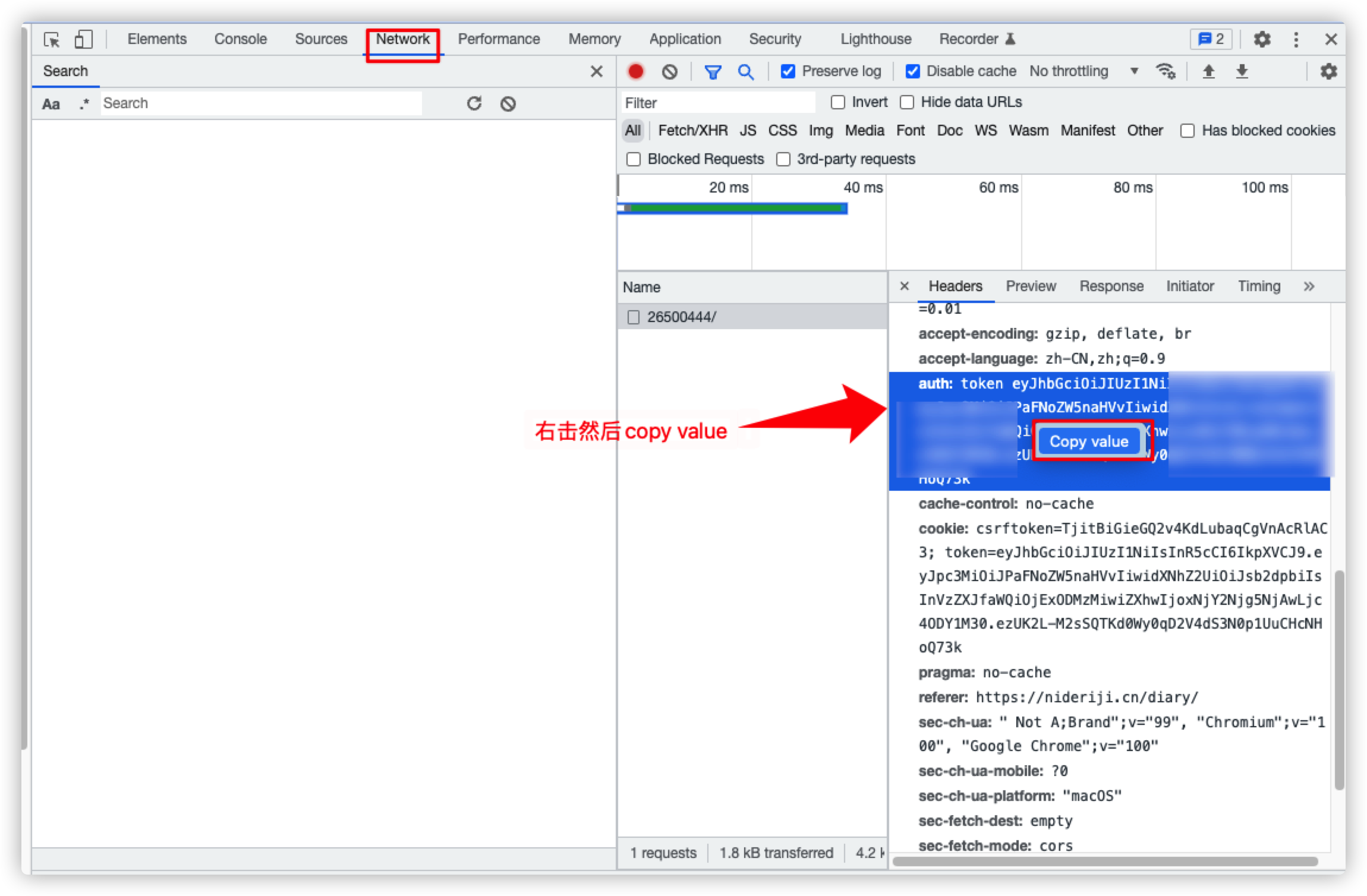
# This is a sample Python script.
# Press ⌃R to execute it or replace it with your code.
# Press Double ⇧ to search everywhere for classes, files, tool windows, actions, and settings.
import json
import time
import csv
import requests
# 输入你自己的auth
auth = '[连方括号一起去掉然后换成你的auth]'
headers_dict = {"auth": auth}
def get(url):
resp = requests.get(url, headers=headers_dict)
time.sleep(0.5)
return resp
def get_dirary_id(year, month):
url = "https://nideriji.cn/api/diary/simple_by_month/{}/{}/".format(year, month)
print(url)
resp = get(url)
resp_json = resp.json()
return resp_json['diaries']
def get_diary_from_id(id):
url = 'https://nideriji.cn/api/diary/{}'.format(id)
resp = get(url)
resp_json = resp.json()
return resp_json
def get_diary(a):
global auth
auth = a
csvfile = open('eggs1.csv', 'w', newline='\n')
spamwriter = csv.writer(csvfile, delimiter=',')
for year in range(2017,2023):
for month in range(1, 13):
print(year, month)
id_map = get_dirary_id(year, month)
for key in id_map:
id = id_map[key]
print(key, id_map[key])
resp = get_diary_from_id(id)
print(resp)
res = json.dumps(resp, ensure_ascii=False)
csvfile.write(res + '\n')
csvfile.flush()
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press ⌘F8 to toggle the breakpoint.
get_dirary_id(2021, 3)
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
get_diary()
# See PyCharm help at https://www.jetbrains.com/help/pycharm/
---
layout: post
title: 不用图床放图的方法
date: 2022-01-18 19:00:00 -0500
tags:
- 技术笔记
- 博客
---
相对路径
At some point, you’ll want to include images, downloads, or other digital assets along with your text content. One common solution is to create a folder in the root of the project directory called something like assets, into which any images, files or other resources are placed. Then, from within any post, they can be linked to using the site’s root as the path for the asset to include. The best way to do this depends on the way your site’s (sub)domain and path are configured, but here are some simple examples in Markdown:
简单来说就是以/开头的路径,是起始于项目仓库的根目录的。所以需要把图片放到根目录下的文件夹里就好。
 然后这么嵌入就可以了:
然后这么嵌入就可以了:

下边是效果

遗憾的是用typora本地渲染会不成功,只能发布到网站上之后才能见效,目前想不到好的办法
---
layout: post
title: test_vnote
date: 2022-01-17 19:00:00 -0500
tags:
- 技术笔记
- 博客
---
note
I want to insert a image

---
layout: post
title: 23
date: 2021-11-28 19:00:00 -0500
tags:
- 生日专题
- 生活
---
2021-11-29-23
写在前面
从上大学开始每年生日都会写一篇文章,19~23,居然已经写了5篇了。我们家的习俗是过农历生日所以我每年发布的公历时间都不一样,所以往年生日发出的文章时间都不一样。工作了怕忙忘了,所以我决定从今年开始每年公历生日11.29发。
虽然开始工作之后的日子平平无奇,立的flag也没有完成,列的书单也没看。但是时间过得越来越快,总要写下点什么。
22→23
时间回拨到去年生日,那时我秋招失利,只有虾皮一个offer,还没开始做毕业设计。从字节跳动离职之后抽空把驾照考了,还春招捡漏拿了两个offer。最后都没去,还是选择了虾皮。本着能过就行的态度做了很水的毕设,当然也顺利地过了。答辩完了还没毕业的时候一个人去了内蒙古和天津。再之后回家住了半个月才来的深圳。
突然想起来在北京的时候一个饭局,竞赛圈的几个小伙伴去吃自助。cch对我说:“好像就你一个人要离开北京”。结果,阴差阳错他也来了深圳。.在我来深圳之前cch就把房子找好了,我一来有得住。来的那天搬着行李,一只小黑猫跟着我进了楼,然后我们决定收养了它。
总的来说来深圳之后过得还不错,我还有时间一周去两次私健身房。平时经常骑单车上下班。下班回家撸猫。周末心情好自己下厨做点菜。深圳这边的吃的也比较符合我的胃口哈哈哈,偏清淡一些,符合我海南人的口味。比如烧鸭、烧鹅、白切鸡、粿条汤等等。看了下我的美团,上次点外卖是8月底的事情了,两个多月没有点外卖了。我平时都自己做或者去楼下吃。
去年的flag
敢于直面惨淡的flag
近日所思
工作之后思考的未来比读书的时候难很多,大学的时候我计划好了大一大二打竞赛,大三去实习,然后校招冲bat,确实也拿到了ba的offer,总归是做到了。但工作之后变量太多,且面对的不是象牙塔里的环境,而是真实的世界了。
比如要在这家公司工作几年,什么时候攒到买房的钱,买老家省会的还是小县城的,什么时候回家工作,什么时候结婚。这些问题想起来会睡不着觉的。活在当下走一步看一步吧。在这么多不确定的情况下,还是有很多确定性的东西,那就是我的行为和态度。比如几点起床,几点睡觉,工作的时候尽量专注,闲的时候读一些书,坚持记账,去锻炼身体等。充分掌控这些我能掌控,也就不会那么焦虑了。
对,到了现在这个境遇,尝试着去健身,去读书,去钻研一些技术并不是多高大上的行为,而单纯只是因为除了这些事情本身的收益以外,还有好处就是能够缓解焦虑,如同我上文所说,“这些事情想起来会睡不着觉的”
居然已经是第5篇了
从我开始过生日的时候写文章开始,已经过去了4周年,到了今年已经是第5篇了。
翻开过去写的文章,就会觉得挺好玩的。19岁生日的时候想要一个ipad,对于未来要考研还是工作还没有想法。20岁京东白条买了ipad然后吃了几个月的土,以及那年的校内赛预计800块钱的奖金,结果学校拖了半年都没发。还有21岁那年和队友给学校带回两枚铜牌,如愿以偿去了心中向往的公司实习。再有就是22岁那年理想照进现实之后产生的迷茫,刚开始接触编程时希望有朝一日能进入bat工作,去实习之后却觉得那不是我想要的生活。这也影响了我后来校招时的决策,在百度阿里虾皮之间选择了虾皮。
每年生日的时候写一篇,已经过去了4年,大概已经成为习惯了,相信有小伙伴每年都会看。虽然平时也会更新博客,但把博客发到朋友圈和QQ空间每年只会有1次,其他时间就悄咪咪地在一个安静的地方写字就好了。写博客其实大部分还是给自己看,自己回顾一下过去的想法,就好像我现在能回顾我大一时对未来是怎么想的。如果足够幸运和新朋友混熟到他们愿意看我过去在小角落里写的文字,也是一个新朋友了解我的方式。
stay young
forever young是一种不可能但又要极力去保持的态度。就好像曾经因为去实习之后开始厌倦写代码,然后努力找回当初写代码的乐趣一样,有很多因素会使得我的心态不再年轻,但终究要努力保持forever young。
慢慢地发现我现在的执行力远不如刚上大学的时候,那个时候真是一步一个脚印,上大学时的愿望全都实现了。除了归结于环境从象牙塔到了真实世界,干扰因素多了等一些外力因素以外,我是不是也得反思一点呢?
现在能归因的就是,没有那种里程碑式的目标了。
这里描述一下里程碑式的目标。简而言之就是一旦达成了,就不可改变了。比如刚上大学的时候希望能进bat工作,那入职了就是达到了。哪怕入职之后又离职,在某个时刻“入职”这个目标也算是成功了。我把这类目标归位里程碑式的目标。这类目标会给某个阶段的我们极大的动力,比如高中时期梦想的大学,就吸引着无数考生奋笔疾书。但同时也有一个缺点,就是一旦达成之后,在某个时间段可能没想好下一步该追求什么,会陷入迷茫和慵懒中。
那么,我目前是没有十分确信的、每天都全力以赴奔向的目标的。有的只是一些摇摆不定的想法。比如有时候想攒钱出国读书,有时候又想回家买个小房子躺平。对一些普遍的目标,比如要在一线买房,要达到什么职级这种,我几乎没有想法。
如我在《大学的终场》里说
在大学毕业之际,我选择暂时放弃了这个赛道。当然不是说我不追求技术成长了,只是可能对于大厂的title和薪资,暂时先不管了,不会因为我的同龄人在更好的企业有更好的待遇而焦虑。——我还是希望我能够保持对写代码和计算机科学的热爱。
虽然对于世俗的目标没有太多想法,但还是没有放弃成为一个优秀的工程师这个理想,在放弃了去国内一线大厂来虾皮之后,我又幸运地找回了那份热爱,现在在虾皮写一个很easy但又对性能和稳定性要求高的服务,要花心思提升服务性能,设计新的版本,我觉得还挺有意思的。当我在设计新版本的时候,才觉得我算是一个工程师,而不是一个简单coding的工具人。总的来说,希望延续学生时代对编程的热爱。其实主要还是喜欢解决问题之后的成就感吧,就好像刷题的时候获得很多次各种错误反馈,但最后把题目解出来了的那种成就感。
如《程序员的修炼之道》里说
我们,采集的只是石头,却必须时刻展望未来的大教堂。——采石工人的信条
一百年之后,我们的工程看起来或许已很古老,就像是中世纪的大教堂建造者所使用的技术在今天的土木工程师看来很古老一样,但我们的技艺却仍将受到尊重。
我其实并非对世俗的目标没有想法,这里无意于创造一个淡薄名利的形象。一切选择都只不过是投入和成本之间的权衡。比如对于诸如在一线买房、去国内一线大厂呆几年升职然后跳槽加薪这种在世俗意义上收获更多的事情,背后是要牺牲掉很多东西的。比如去到国内一线大厂,工作强度肯定是要比在虾皮高,因为我体验过所以很确信。在一线买房的话要背上二三十年的房贷,生活质量降低,以及30岁之后的职场危机等等。我无非就是权衡了之后觉得还是单纯地做一个不断提升的工程师比较舒服。
知乎上有个问题,“学计算机的你有什么理想”,我的回答是很沮丧的。
说起来还有点悲凉,上大学以前我的理想是进bat,高考之前写在了小卡片上的。上大学之后我确实也努力实现了,从我了去百度之后就没有理想了。后来校招bat拿了两家都没去。年少无知,那时的理想怎么这么浅薄,居然理想是给马老板们和李老板打工?从此以后都不会拿进某一家公司当理想。
不过如果你是计算机专业的学子,倒是可以拿“bat随便去”作为毕业时的目标,努力成为同一届学生中的佼佼者,虽然等你达到了你会觉得不过如此,但至少大学四年会比较充实,不负时光。
我现在很平庸,没有什么理想,但我很怀念曾经那些追逐理想的日子。
“那些为了理想的战斗,也不过是为了钱”——《没有理想的人不伤心》
如上文,现在确实没什么理想,但也能够静下心来思考和做一些事情。一切又是重新的开始,正式地步入职场的第一年,要思考新的方向和路径了。
to 24
- 保持读书写作的习惯,数量不做要求
- 继续保持今年养成的健身习惯,不要中断超过两周。
- 坚持每天尽可能半小时回顾一下在做什么,如同最近4周尝试的那样。
现在github写博客越来越方便了,可以写好了.md文件上传。也可以用github自带的网页版vscode。
---
layout: post
title: helloworld8years
date: 2021-09-20 20:00:00 -0400
tags:
- 程序人生
- 自我成长
---
在某天晚上,我突然想起来我的QQ空间里有一个相册,《IT杂图》,是我初中的时候创建的,存放了一些折腾关于IT相关的东西的照片。比如学PS的时候P的图,去参加比赛时拍的照,以及那个时候的书。我发现,那张hello world的程序截图,是2013年9月20号发的,最近我刚刚毕业正式参加工作,眼看着9月20号也快了,距离我写出来第一个程序,已经将要过去8年了,突然想写点东西。
在初中的时候我就比较喜欢折腾一些电子设备,比如我的诺基亚手机不支持后台挂QQ功能,当时有个塞班论坛,上面有很多DIY手机的教程。我照着论坛上的教程给我的手机DIY出来了后台挂QQ功能,还帮当时的同学 还有一个实习的老师的手机也刷成功了。这大概是接触IT的起源。实习的老师跟我说了一个网站,51自学网,在上面可以学一些IT知识。我在上面看到了一个java基础课程,就跟着学了,相册里的代码就是照着视频课程敲出来的,从相册的时间来看,大概是在我初二的时候。说个题外话,虽然我的第一个程序是用java写的,学的第一门语言是java,但在之后的日子里,我几乎没有写过java(java选修课写过一点点),也没有进阶学习java。那门课只讲了java基础,大概从变量开始讲、讲到了面向对象吧。
当时我初中的学校,也会象征意义上去参加一下NOIP(全国信息学奥林匹克竞赛),大概就是叫几个人,下课之后去电脑教师,信息老师教计算机发展史,比如现在用的电脑体系结构是冯诺伊曼结构,数字在计算机中怎么表示,二进制的原码补码反码这些计算机基础知识,不教编程。NOIP分为初赛和复赛,初赛是笔试,考的就是计算机基础,还有一些代码填空之类的。复赛是上机考试,做编程题。我们的目标只是进入复赛,海南省在信息竞赛这方面比较弱,进复赛大概率就能拿三等奖了。
然后等我上高中的时候,买了一本《C语言入门到精通》还有一个windows系统的平板,装了VC++6.0,把C语言语法基础也学了。我的高中没有参加NOIP的队伍了,不过以前还是有的,有一个老师负责,我找到了那个老师,她也没有教什么,但给了我电脑教室的钥匙,让我抽空去练习。于是在高二的时候每天中午晚上还有周末我都去机房练。不过也没练出来什么成绩,还是三等奖。。
后来上大学也follow my heart,考砸了也要报低20分的学校,为了能报计算机专业。上了大学参加了acm竞赛,成绩惨淡。大学生活写得比较多就不赘述了。总之从我开始写hello world之后的很长一段时间,我都没有参与过软件开发,哪怕上了大学,我都是在写算法题,在学校里从来没有写过项目。直到后来去企业实习的时候才真正参与了工程类的开发。
附上一段我18年新年伊始时写的文章,“有一种说法不知道是否正确:算法是程序员的基本功,算法功底决定了一个程序员能去什么样的公司。上面的说法我没有去验证过,不确定真伪。”,如今回过头看,确实验证了当时的想法。
《你好,acm集训队》
我还是挺愿意成为一名ACMer的,高中的时候学校没有信息学竞赛队伍,我自己一个人报名参赛,那个时候没有人培训,一个人在机房跟算法死磕,始终不得要领。当然也不全是环境的原因,也跟个人的努力程度和天赋有关。但现在我有了这么好的环境,我就应该去拼一下,我知道那些登上顶端的人都是天赋异禀,但我还是不愿意相信天赋。因为不管做什么事情,一旦相信了天赋,那么你不但不能超越那些天赋异禀的人,甚至连努力的普通人你都没办法超越了。
再者,有一种说法不知道是否正确:算法是程序员的基本功,算法功底决定了一个程序员能去什么样的公司。上面的说法我没有去验证过,不确定真伪。不管怎么样,挑战一下算法竞赛,对于思维的提升和日后编写程序的都会产生积极地影响。
更切实际的,自从迷上了算法,写线代和高数头也不疼了。C语言考试对于竞赛选手哪怕是我这种渣渣来说也是很容易就秒杀的。
总之,我要继续努力翻过高中的时候没翻过的山,看那个时候想看的风景,继续脚踏实地地走到更远的地方。
共勉。
2018.1.4。
感想
如果要用一个词来概括的话,大概还是惭愧吧。
我的人生剧情没有往天才少年的方向发展,最后也只是成为了一名普普通通的工程师,在传统程序设计竞赛和软件开发方面都没有很显赫的成就。之前广为流传的一个一万小时理论,简而言之就是一个人在一个领域干了1万个小时就会称为这个领域的专家。但后来有一本书叫《刻意练习》反驳了这个理论,说单纯有1万个小时是没有用的,还得是1万个小时的刻意练习才有用,所谓的刻意练习,就是不断地走出舒适区。不过仔细想象,在大学之前我只是课余时间写代码,应该没花那么长时间,也许不到1w个小时,哈哈哈。另外,在走出舒适区这方面我可能做得也不是很好,程序设计竞赛打了三年最后只拿了一块含金量不高的铜牌。也没有很深入地去学计算机科学。
不过同时又觉得自己是幸运的,儿时的梦想没有被扼杀在摇篮里,至少在我初中的时候,我的父母也没有说玩电脑影响学习就不让我玩,在高考报志愿的时候没有左右我的选择。虽然会遗憾自己起步那么早却这么普通,但又不是那么遗憾,至少还够得着职业门槛了,也算真正去体验了一把梦想中的职业是怎样的。
— 尝试一下github的云写作
---
layout: post
title: 大学的终场
date: 2021-06-28 20:00:00 -0400
tags:
- 大学
- 自我成长
---
大学的终场
我之前在公众号写过一篇《大学的中场》,回顾了一下大学的“上半场”,以及写下一些思考。现在已经毕业了,写一篇《大学的终场》作为呼应,也顺带写写下半场的一些想法,当然有些文字之前已经以零碎的形式发表过。权当大学毕业时的记录以及与这个世界交流。
写《中场》的时候,我还没有去实习,也没有拿icpc的奖牌。在中场之后,我去了百度和字节跳动实习,也拿了一个微不足道的竞赛奖牌。但这篇文章主要还是记录一些想法,竞赛和实习体验之类的之前说过了。
中场之后虽然变得更好了,但其实下半场的努力其实没有那么地热血,更多的还是之前努力的变现吧。
比如icpc竞赛打到大三才拿奖牌,但是我们队的成员都是大一入学就开始训练了。不得不提我的队友smc和pby,如果没有他们我应该没有奖牌,可能也就不会去百度实习了。同样地,可能因为字节比较喜欢百度的简历,所以字节跳动叫我去面试实习岗位就叫了5次。我还是真的很菜,第5次才面过。但还是希望读者意识到,这不是一个励志和逆袭的故事,我也无意于打造这种故事。因为我入职之后内推很多朋友和同学,过简历关的特别少,只有两个。所以这单纯是一手好牌打得不是特别差也不好的故事。
我的秋招差不多首战告捷,20年8月份,还没上大四的时候就拿了shopee的offer。但是之后百度快手京东什么的全都挂了,我一整个秋招只有1个offer。这其实也是自己的问题,因为实习太忙太累就没有去准备面试,几乎都是裸面,结果被毒打了。所以互联网程序员求职其实不容易,我稍微蹉跎了一阵子,就直接无缘第一梯队互联网公司了。
我当然也就不甘心,21年3月中旬回北京就离职准备面试了,最后也拿了百度和阿里的offer。但最后也还是选择shopee了。这个之后的章节会说。
想跟读者说:不必太焦虑,思考和行动终究会积累起来的。
关于人生选择
背景
我或者说大部分青少年高考之前的路,基本上没有什么自我选择。唯一有的可能也就是高中选择文理分科,毕竟中考能选的学校也就那几所,什么分上什么学校,选择的余地也不大,考量因素也不多,而且不管去哪最终的终点都是高考。
高考之后选择就来了:报什么学校、选什么专业、上大学要往哪个方向去努力,是刷绩点、搞竞赛、去实习、搞科研、还是做跟专业牛马不相及但自己喜欢的事情。毕业的时候也要考虑去哪个城市工作、去哪个公司工作、去做什么。
这里简单介绍一下个人背景和时代背景,我在高考之后很长一段时间没有怎么迷茫,报志愿也直接报比自己低20分的学校的以确保能报计算机。上大学之后也规划得很好,最终目标还是希望能进入bat工作,大一大二打竞赛、大三去实习,大四校招收割offer。甚至对于考研还是工作,我大二的时候就想好了。再说说时代背景,移动互联网催生以TMD(字节跳动、美团、滴滴)为代表的小巨头,所以bat也就可能不是首选了。
然后具体事件是这样,我秋招的时候只拿了shopee的offer,没有bat tmd以及其他大厂的offer,所以其实很不甘心,从字节跳动离职之后还是在准备面试,最终百度和阿里的offer都拿了,我却因为打听到他们工作强度都不小,给拒掉了。。当然另外原因是shopee目前大家都说工作强度比国内大厂要好(也说不好、变数很大)、而且我被分配到基础架构部门,开发用golang语言也是我比较喜欢做的,而阿里是java开发。
一次剖析
我前几天突然想到,我的两次选择,还是会反映出我本身的性格特征。在高考报志愿的时候,我的分数其实够去东北大学秦皇岛分校和西北农林科技大学的,这两所都是985,但未必能选到计算机专业。因为我听说大学转专业很困难,再加上当时我们学校有一个同学因为在转专业失败大三回我们高中复读。给我的感觉就是,要是被调剂到一些专业我会很痛苦。后来在网络上我认识了zoomdong大佬,他是东秦的材料专业的。自学了计算机,去了实习工资巨高(比字节跳动还高)的公司实习,秋招拿了某顶级部门的offer。所以我就在想,虽然我没有他那么努力以及优秀的成就,但仿佛他是我高考时的另外一种选择,仿佛平行宇宙。就结果来看,我当时做的选择并不是最优的,转专业可以尝试,转不成功还能自学计算机,zoomdong大佬就是例子。
最近的选择也是这样,从功利角度来说去阿里比较好,虽然累点,得学之前没用过的语言,但大厂镀金的效果还是很好的,甚至在工资层面阿里给得比shopee高一点点。但那也许会牺牲掉很多,快乐和幸福感,以及对工作的热情。
所以我前几天突然找到了我做选择的根本原因:我特别在意主观体验,并且不愿意吃苦。穷日子过习惯了,所以对于物质追求也只是小富即安。相比于名利,更希望幸福快乐,以及做自己喜欢的事情的成就感。
就好像打竞赛的时候,写的代码很难,训练强度很大,基本上所有时间精力都得投入进去。几乎是没有赚钱的,最多的一次比赛奖金只有800。但那种看到自己一点点进步的成就感,以及代表学校去跟全国高校同场竞技的荣誉感,是多少钱都买不来的。
当然还有一些其他原因,一个是因为开源文化的盛行,所以学技术不一定非得去大公司。有很多优秀的书籍和源码可以学习。二是我在两家大厂实习过,想去外企体验体验(虽然是东南亚的外企)。第三点有点膨胀,我想以后再去大厂应该也不难吧,毕竟我也不会完全躺平,还是会追求成长的,而且虾皮也不算小公司了。再加上我好多朋友在大厂,求内推也不难。(到时候抬一手啊大佬们)。
这些年的赛道假设
这里引用采铜的《精进:如何成为一个很厉害的人》一书中的一段话
“不要让孩 子输在起跑线上”这句话就是赛道假设的体现。暗自认同赛道假设的人,认为人生就是一场漫长的比赛,比赛的项目是设定好的,而获胜者寥寥无几。于是他们就容易陷入对竞争的焦虑和对失败的恐惧中。他们可能由于害怕失败而不敢尝试、不敢试错,只能战战兢兢、亦步亦趋地在-一个被外界固化了的轨道上不停地跑着。
大多数青少年的经历都是相同的,从小就被迫地加入到赛道中。从小到大都有排名,中考排名高考排名,甚至求职也是一样。越靠前的人的可选项就越多且越好。所以就会不由自主地比较。高考之前是所有人都在高考这一个赛道上,考上好的中学,就更有可能考上好的大学。
高考之后有所变化,变化就是就是可以自己选赛道了,不是所有同龄人都一起去卷一个赛道了。首先高考之后就得自己考虑去学什么专业。上了大学之后也有了更多的可选项,比如去搞科研,去刷绩点,去做工程,去参加竞赛,当然也有很多人选择去做跟专业不相干的事情(做成了也没什么不好)。毕竟资源有限,企业的招人名额和学校的保研名额都是有限的,所以还是需要去努力、去竞争。
大学毕业之后,当然也可以继续卷,比如说程序员赛道,人们在里面比大厂的职级,年薪等。比如工作就要达到阿里p几,要多少w的年薪,这种基于工作年限的比较,比较就会造成焦虑,当然也会促进努力吧。这不是我说着玩的,而是真的不少程序员都在比。
在大学毕业之际,我选择暂时放弃了这个赛道。当然不是说我不追求技术成长了,只是可能对于大厂的title和薪资,暂时先不管了,不会因为我的同龄人在更好的企业有更好的待遇而焦虑。——我还是希望我能够保持对写代码和计算机科学的热爱。
竞争是不可避免的,还是需要静下心来思考,自己内心真正想要的是什么,而不应该盲目比较。
所以,如果我选择去阿里的话,从程序员的职业生涯上看是最优解,可能也是最赚钱的路线。但对我个人来说,我最近两年长胖了很多,一直缠绕我的皮肤问题也没有很好地解决,所以还是希望有时间去锻炼身体和护肤,以及工作上的心智负担不那么大,让我有好心情好好生活。
工作之后的三次思想转变
这一段是二月份在知乎发表的一篇文章,因为我现在的想法还是没有改变,所以姑且改都没改搬过来了。
从19年10月去实习打工到现在,已经1年4个月了。在这期间我发生了很多变化。
一开始会觉得特别累,压力也很大,比在学校的时候大得多。但其实客观来说当时的公司和部门,算很舒服的了,就这也让我感觉压力很大。具体来说就是很晚下班和要开会汇报的时候感到的压力。
然后就是觉得很不值得,那么多年来对程序员这个职业的憧憬都不那么美好了。我以前觉得我要从事我喜欢的职业,我的工作就像兴趣爱好一样快乐。但那段时间的感受是,我真正工作了,虽然确实是我理想的职业,但也不过是为了钱。
简单说,那个时候的观点就是:我虽然喜欢写代码,但不喜欢上班。写代码是兴趣爱好,但上班真的只是为了钱
后来我跑到了另外一家公司实习,老实说,薪资翻了一倍,但工作压力就更大了。之前“单纯为了钱”的观点也没有改变。
直到后来我的秋招受到了很大的挫折,虽然最后签约给的钱也不少,但对我来说,我没有去百度腾讯美团字节等公司,相比于我第一家实习就在百度的起点来说,又对比我在竞赛圈的大厂收割机来说,我是很失败的存在。
但是随着挫败感而来的,还有我的反思和思想的转变。那就是,改变了原来混口饭吃的思想,意识到追求极致的重要性。
也就是说,我得主动地让自己成长,在日常繁杂的工作中,抽出时间去业务之外的学习技术,或者去思考如何把业务做得更好。
知易行难。行动上我开始了一点点,开始抽时间看书,看源码,注重提升。但老实说做得还不够吧。
现在面临的挑战是过去的人生里从来没有遇见过的。之前从来没有既要工作又要学习还都得做好的情况。
对于精力,时间,和情绪来说都是很大的挑战。
有一天我突然想到一个模型,并且手画了一张图,就是一个三层蛋糕的样子,最底层是生活,中间层是终身学习,最上层是工作。
生活是一切上层建筑的基础,情绪稳定,身体健康是最重要的。也就要求要早睡早起,要控制好情绪,以及学会专注。
再上一层是终身学习,更直接一点说,包含对行业的认知,对社会的认识,甚至经济学和历史也需要去学习。
再上一层才是工作,因为只有前两层做好了,才有可能去任职更优秀的岗位。
这大概是我的想法,从热爱程序员这个职业,到觉得上班只是为了钱,又到开始意识到追求极致的重要性,再到现在的3层模型。
杂谈
这就属于强行插入的一段碎碎念了
一个人的社交圈子大致都是跟自己有点相似的人,有共同的经历或者是相同的爱好。上大学之后因为打竞赛且爱水群,认识了好多全国各地高校的朋友,学校层次也接近,大部分还双非一本的,985/211少部分。
我们有很多共同点:学校层次差不多,都是打icpc竞赛的,大多都去了大厂实习。这3个特点加起来,其实就是一个很小众的群体了。也正因为这样,这些人不由自主地组成了一个小圈子。
在我22岁这一年,我在北京上学和实习,有好多上面说的网友从全国各地来北京上班。都在一个城市的话,虽然大家都比较忙,但也还是可以偶尔聚聚餐,吃饭聊得最多的还是关于各大厂的技术,日常的工作,竞赛的往事等等。还有大部分我未曾谋面,但可能日常网络交流还是挺多。
虽然现在很多人的社交都从QQ转到微信了,我还是很经常QQ,QQ空间还是经常发,就是因为我的很多朋友还在用吧。
这些很小众的群体,因为代码技艺高超从弱校冲进大厂,也许若干年后这些人里会出现顶级企业的中层或高层领导,未来可期。
展望
其实我只知道我去shopee的infra(基础架构)部门,但具体做什么我也还不知道呢。前几天参加了一个golang的开发者大会,觉得golang做的事情也挺多,现在基础架构,云原生也是技术的一个趋势,所以未来有空的话还是会玩玩开源社区,说来惭愧,我本科前半段在写算法题,后半段去企业搬砖,没怎么上过开源社区。。。
我有好多书还没看,有时间看看书吧,就当是业余爱好了。对,业余爱好——计算机科学。
至于职业生涯规划嘛,这可说不好,市场行情变化莫测,走一步看一步吧。
- 成为对开源社区有贡献的人。
- 能对shopee的基础架构做出自己的突出贡献。
- 锻炼身体
- 护肤
---
layout: post
title: 工作一年多的几次思想转变
date: 2021-02-11 19:00:00 -0500
tags:
- 工作
- 程序人生
- 自我成长
---
2021-02-12-工作一年多的几次思想转变
从19年10月去实习打工到现在,已经1年4个月了。在这期间我发生了很多变化。
一开始会觉得特别累,压力也很大,比在学校的时候大得多。但其实客观来说当时的公司和部门,算很舒服的了,就这也让我感觉压力很大。具体来说就是很晚下班和要开会汇报的时候感到的压力。
然后就是觉得很不值得,那么多年来对程序员这个职业的憧憬都不那么美好了。我以前觉得我要从事我喜欢的职业,我的工作就像兴趣爱好一样快乐。但那段时间的感受是,我真正工作了,虽然确实是我理想的职业,但也不过是为了钱。
简单说,那个时候的观点就是:我虽然喜欢写代码,但不喜欢上班。写代码是兴趣爱好,但上班真的只是为了钱
后来我跑到了另外一家公司实习,老实说,薪资翻了一倍,但工作压力就更大了。之前“单纯为了钱”的观点也没有改变。
直到后来我的秋招受到了很大的挫折,虽然最后签约给的钱也不少,但对我来说,我没有去百度腾讯美团字节等公司,相比于我第一家实习就在百度的起点来说,又对比我在竞赛圈的大厂收割机来说,我是很失败的存在。
但是随着挫败感而来的,还有我的反思和思想的转变。那就是,改变了原来混口饭吃的思想,意识到追求极致的重要性。
也就是说,我得主动地让自己成长,在日常繁杂的工作中,抽出时间去业务之外的学习技术,或者去思考如何把业务做得更好。
知易行难。行动上我开始了一点点,开始抽时间看书,看源码,注重提升。但老实说做得还不够吧。
现在面临的挑战是过去的人生里从来没有遇见过的。之前从来没有既要工作又要学习还都得做好的情况。
对于精力,时间,和情绪来说都是很大的挑战。
有一天我突然想到一个模型,并且手画了一张图,就是一个三层蛋糕的样子,最底层是生活,中间层是终身学习,最上层是工作。
生活是一切上层建筑的基础,情绪稳定,身体健康是最重要的。也就要求要早睡早起,要控制好情绪,以及学会专注。
再上一层是终身学习,更直接一点说,包含对行业的认知,对社会的认识,甚至经济学和历史也需要去学习。
再上一层才是工作,因为只有前两层做好了,才有可能去任职更优秀的岗位。
这大概是我的想法,从热爱程序员这个职业,到觉得上班只是为了钱,又到开始意识到追求极致的重要性,再到现在的3层模型。
---
layout: post
title: 22
date: 2020-11-24 19:00:00 -0500
tags:
- 生日专题
- 生活
---
2020-11-25-22
写在前面
我22岁了,从上大学的第一个生日开始,我每年过生日的时候都会发一篇杂文。也许有很多朋友从大一看到了大四,非常感谢你们追更,一晃三年过去了。
最近我突然发现了写作记录生活和思想是一件很有意义的事情。前几天gy小姐姐跟我说想听我讲故事,我就发了我的公众号,然后她看了之后说可以出书了,还想看。我突然想起来我之前每年生日都会在简书发一篇文章,然后就给了她链接。接着我们就讨论起来了这几年,比如去年我文章里的愿望有没有实现,不打竞赛去实习也没有后悔。以及她说19,20岁的文章写了很多感想,但21写得少了。
这倒提醒了我,今年要好好写了。
写作记录生活的意义就在这里,尽管记录,如果有一天有人想了解我过去的生活,看一下我每年写的文章就知道个大概了。
之前的文章可以点击原文链接查看,还没有全部搬到公众号。
- 19:刚上大学,在纠结考研还是工作,但无论考研还是工作都不妨碍把当下的事情做好,考研和工作时两条路,但它们是有共同的地方的,如果基础扎实,那么考研和工作你都可以选。
- 20:想好了要工作了,努力拿一个acm比赛的奖牌。不要想太多,努力去做。
- 21:acm拿了一个铜牌,去了百度实习。
- 22:请往下看。
21->22
时间线
- 2019:
- 2020:
- 1-3月春招面试,主要是阿里腾讯和字节的实习,阿里腾讯都挂,字节跳动过了。
- 4.7从百度离职
- 4.23字节跳动面试offer
- 4.29入职字节跳动
- 8.14shopee意向书
- 7-10忙着面试,百度京东快手都挂了
- 10.2被告知转正失败
- 11.13签约shopee
实习的一年
我足够幸运,有幸在百度开启了我人生第一次实习,关于实习的体验,在我入职一个月的时候我在知乎上写过一个回答了。不得不说,作为技术序列的员工,在百度的工作还是很愉快的。就我自身的体验来看,在百度感觉是很温暖的,实习期间接触的人都很nice,离职的时候得到的也是祝福,前段时间回了一趟百度科技园见到老同事也倍感亲切,他们会问竞赛打得怎么样了,真的不读研了吗,在头条忙不忙呀之类的,很像初高中毕业之后回去看望老师。
总之,作为用户和作为员工的两种视角里的百度,是完全不一样的。(作为用户我也吐槽百度的产品hhh)
再说说字节跳动,相比于在百度的安逸和舒适,在字节就不那么舒适了,但另外一方面我在字节跳动成长了很多。我的大数据技能和踢毽子技能都在字节跳动实现了从无到有的巨大提升哈哈哈。也慢慢地从一开始需要人带,变成独立地去跟产品运营同学沟通,独立完成需求。
刚去百度的时候我是一个只会刷题的竞赛选手,在度厂同事leader很友好让我没有受到太大的挫折,让我很好地完成了从一个只会刷题的竞赛选手到一个工程师的过渡。字节虽然对实习生要做的事情要求更高,更独立一些,但好在有之前在百度的一点铺垫,遇到问题也有热心同事答疑解惑,让我成长了很多。
开始迷茫的一年
大概是从初二看了乔布斯传之后立志要成为程序员开始,我的每一步都在朝着一个目标走,从小县城到省重点。后来虽然高考失利,但也很坚定地选择了计算机专业和中国互联网最发达的城市。
高中分文理科,大学报志愿这些大部分同龄人迷茫的事情,我几乎都没有怎么迷茫,走的每一步都是在追梦。在大学里我规划得很好,几乎每一步都不偏不倚地达到了。大一大二刷题训练,大三拿奖,大厂实习。跟我刚上大学的规划几乎是一致的,除了最近秋招没有拿到一线大厂的offer以外。
但是,自从我去百度实习开始就迷茫了。
梦想是比较抽象的,这么多年的梦想快实现了,它从一个很抽象的东西变成我了的日常生活,这就是梦想中的BAT,我已经能近距离地体验到了大厂程序员的生活,那之后的路怎么走呢?
我可能过了一年还没想明白,就在我迷茫的这几个月,无数地挫败接踵而来,一是字节的转正失败,二是百度京东快手的面试全都挂了。
用最近几天很流行的话说就是,“我大意了!”,秋招期间一直在字节上班,也没有好好背书准备,因为找实习顺风顺水 + 以为在字节可以转正 + 8月就拿了shopee的意向书,所以我秋招就没当回事,结果结局不尽人意,不过还能接受吧。有很多同学安慰我,我可以拿很好的offer的,只是我没有好好准备,像极了当年高考之后高中同学安慰我的样子。
再说回到迷茫的问题,相比于之前,我可以很清晰地规划这四年,但是工作之后仿佛是无限的,所以相对来之前来说比较迷茫。
然后我前几天看了我19岁生日写的文章,我那时是这么说的
要考研呢还是工作呢,我怎么知道呢,以后再决定吧,就现在来说,这个并不重要。因为这两条路并不是完全冲突的,如果能力足够强,本科毕业就能去不错的岗位,那岂不是很好,再者说现在要把基础打牢,还不细分方向。要是学习能力很强,奋战一年考个北邮也不是问题啊。总之,那不是现在要考虑的问题,我要做的只是让自己变得更强大,希望明年生日会给自己一个答复吧。
所以现在还是比较坦然,踏踏实实地感受当下,工作,看书,锻炼身体,游玩。
至于未来的职业,我目前觉得走技术路线还是一条比较稳妥的、我喜欢并且我能做到的路线。
大起大落的的困局
在我秋招失败之后,我突然就回忆起来这么多年的人生,真是大起大落,小考没考上县重点,却能中考逆天改命全校第2考上省重。高考失利去了双非,也能逆风翻盘大三实习就冲进大厂,结果现在秋招失利了。
其实这应该是更深层的原因导致的,跌落是因为我稍微有点成绩就很容易知足,然后止步不前,殊不知人生每个阶段都是需要很努力的。我好像在追一条及格线,一旦过那条自己心里的及格线了就开始躺,然后如果很落后的话就会用尽一切的力气试图翻盘。好在运气好,没有被完全被打败得丧失信心,几个知耻而后勇的阶段都能取得不错的成绩,然后进入下一个循环。
关于追求极致
在经历了秋招的惨痛失败和转正失败之后,我突然意识到了追求极致的重要性,其实挺嘲讽的,我认同公司的想法居然是在被外界毒打之后。没错,之前我并不信奉字节范里的“追求极致“,因为那样大概会创造出更大的剩余价值,工作时间也会延长很多。
但好像当竞争很激烈的时候,只有追求极致的人会胜出,像我这样差不多先生就只能是差不多的水平,而不是top了。
大概也跟这么多年的学生思维有关,考试嘛,对于我来说,过了分数线就能上了,过线之后的极致好像并不是很重要。但是最近一年我也慢慢走出了学校,接触了现实世界,所以才慢慢意识到了追求极致的重要性。
差不多先生的性格应该是很深入的,不那么容易改变,但是好歹我意识到了这一点,多多少少会刻意暗示自己吧。
去年的flag
反思一下,去年有的计划没有很明确的指标,只是说要看书,要刷题,但并没有很明确的指标。
明年的自己:竞赛有没有取得更好的成绩(银牌及以上)啊?——没有有没有把书单里的书看完啊?——没看几本书,而且我居然忘了是哪个书单了?有没有把题刷了啊?——刷题频率降低了很多,而且去年说的是哪些题??有没有拿很好的offer啊?——不是最满意的,但也还行吧~
诗和远方
- 至少要看10本闲书,5本专业书。先随便列一些听说但是还没看的书,以免不知道实现flag的时候不知道干啥hhh。
- 《贫穷的本质》
- 《生命不可承受之轻》
- 《明朝那些事》
- 《霍乱时期的爱情》
- 《智能陷阱》
- 《时间简史》
- 《人类简史》《未来简史》《今日简史》
- 《TCP/IP详解》
- 《高性能MySQL》
- 现在leetcode 152题,明年生日之前刷到300道!
- 最近几年要么忙着打竞赛要么忙着工作,现在竞赛退役了工作也落实了,是时候谈个恋爱了。
- 好好工作,有了两段实习铺垫,正式工作的时候应该能很好地熟悉业务了,努力成为校招生里表现优秀的人。
虽然有时候很认真干一件事会耗费很多时间,但是对你自己来说你也可以提升很多的。
---
layout: post
title: 半年百度,半年字节,记录实习一周年
date: 2020-10-26 20:00:00 -0400
tags:
- 工作
- 程序人生
- 实习
---
2020-10-27-半年百度,半年字节,记录实习一周年
图文流水账
百度
2019年10月9号,我可能一辈子都不会忘记这个日子,那天我走进了百度大厦和百度科技园,开启了我的实习之路。
其实去百度的面试很好玩,我坐了一个小时地铁到后场村的百度科技园,发现百度科技园的这个滑梯挺好玩,后来入职了我也玩了几次,挺好玩的哈哈哈。

第一个程序员节(10月24日)是在百度过的

然后百度科技园有几个乒乓球室,还有乒乓球社团,我还跟同事约了乒乓球。
后厂村路有一个神奇的十字路口,十字路口的四边分别是新浪,腾讯,网易和百度

在度厂过了我21岁生日,度厂还送了小度熊。

在我考完期末考试的那天,正好赶上aig的年会。

然后我就回家了,本想着过完春节就回来上班,结果碰到疫情,在家办公了很长一段时间,直到4月份离职。
字节跳动
我在离职之前,并没有字节跳动的offer,但有一个在面试的流程,当时项目压力太大,再加上在家办公安逸的环境和巨大的工作压力形成强烈对比,就想请两个月的假,但是实习生不给请那么长的假,所以就离职了。
离职之后的那个月字节的offer到了,虽然说因为工作压力大才离职的,但我还是接了,因为比较缺钱hhh。然后就远程入职了字节跳动。
远程入职的后半段,考完期末之后我还去了字节在海口的工区蹭了工位

海口工区的零食

在城西商务中心拍的海口

在城西商务中心拍的海口
啊,8.1号学校终于批准了我的返京申请,然后我就来北京上班了!



在天作国际中心拍的几张图



字节的下午茶和自助餐
文字篇
这一篇更多的是细节和一些感想
感谢
我去年去百度实习是在大三上学期。因为那是竞赛的最后一个赛季了,我就想打完竞赛去找实习。其实这一路走来,要说个人努力吧,确实有,但更多的是运气,还有他人的帮助。
一开始是鼎鼎学长和戚导跟我说大厂实习对以后加分很大,所以我找实习的时候除了投小公司以外还投了360和百度。
非常感谢我的队友,如果不是他们我可能没有那一枚邀请赛的铜牌,也可能过不去简历关。
还有当时百度的面试官源哥和晗姐,实习面试是在19年的9月初,一面的时候我说了我想打竞赛到12月再来实习,但源哥还是叫了二面面试官晗姐来面。两位面试官的评价都是表现还可以,但是12月再来有点不太稳妥,如果这个岗位招满了就不招了。
然后我就回去了,在水群的时候听当时跟我同样大三的zoomdong大佬说他暑期在小米实习,但后来学校有事就离职了。不过他说以后想实习走一下入职流程就好了。
然后我转头一想,我的面试可能也过了,能不能跟面试官联系一下,以后我想去实习了也走个流程就好呢?
然后就从通话记录里联系了源哥,我还记得当时我在去秦皇岛比赛的火车上,秦皇岛是我倒数第二场比赛了。源哥很痛快地就答应了,说提前一个月跟他说就好。
虽然说还有几场比赛没打完,纠结了好久,最后还是入职了。
总之就是,因为遇到了一些人,他们不经意间说的话和做的事,就促成了我的第一段实习。
梦想之后
在我初中的时候,2011年,乔布斯逝世,《乔布斯传》出版,卖60多吧,挺贵的,我吵着我爸拿钱去新华书店买了一本。乔布斯传里有一个人苹果联合创始人 沃兹尼亚克,他真的太酷了,他做出一种免费打长途电话的蓝盒子,自己买元器件做电脑。他负责技术,乔布斯负责把他做出来的东西变成钱。
好像是从初中看乔布斯传的时候我就对IT很感兴趣,写出第一行代码是在2013年。所以印象中我高一的同学就知道我要搞IT了,自学C语言确实也是高一下学期的事。不过因为我在算法竞赛的表现实在不行,所以我也不太想说我初中就会写代码这个事情,谁初中开始写还这么菜呢。
在那个时候,我觉得程序员是一个很酷的职业,受乔布斯传的影响,人活着是要改变世界的,而程序员也是改变世界的行业。但在我上大学之后的这几年,到处都是贩卖情怀,画大饼,996,35裁员这些字眼。再加上在字节跳动的工作时间确实很长,或者说整个行业几乎都这样。我就在想,我到底想要什么,早上去办公室坐到晚上,这真的是我想要的生活吗?
前面说了我初中对程序员的看法和现在对这个行业的看法有巨大的反差。我想主要是因为:大概在乔布斯那个时候,折腾这些电子器件,编程语言,其实是很小众的,也赚不了什么钱,只是看起来很酷炫罢了。所以大家想起来一些大佬,都会有很geek,技术宅,怪咖的样子。算是一个小众的职业吧。
然后那些远古时期(其实也就上世纪60到90年代)的怪咖,要解决的问题比我们现在要难得多。哪怕是现在的人去读linux和C++的底层源码,也不是一般人能读得下去的。所以真的很酷啊。
但现在就不一样了,经过了这么多年发展,开发技术已经很成熟了,门槛大大降低了。就比如果一个程序员不会写汇编和C,不知道底层,但熟悉各种框架,那他还是可以找到工作的,甚至还能进大厂。在远古时期恐怕不行。另外一方面,大量的资本涌入互联网,薪资水涨船高。
毕竟,一个app就有可能撑起上千亿美元的企业。
归纳一下,主要有两个方面,一是因为门槛降低了,二是给钱多了。这就会导致有越来越多的人进来这个行业。大很多人都不会有像远古时期的技术宅怪咖一样认真搞技术心态了,首先要想的就是公司给我开多少钱工资。因为这点东西,可能不需要热爱,就能做得差不多了。大家技术都差不多的情况下,普通人的竞争力在哪呢?时间和精力(也就是加班)呗。。
虽然说我没想明白我要做什么,现在处于一个迷茫的状态,但最近深刻意识到自己技术层面其实水平还不够。
所以,可能最近几年还是要潜心搞技术。
---
layout: post
title: 如果你想报考北京信息科技大学
date: 2020-07-08 20:00:00 -0400
tags:
- 大学
- 经验分享
---
2020-07-09-如果你想报考北京信息科技大学
回望我的高考,已经是3年前的事了,如今我已经快要大四了。这篇文章主要是以一个过来人的角度给学弟学妹们一些建议,尤其是打算报考北京信息科技大学的,又或者,提前写好给即将入学的学弟学妹看吧。这篇文章与其说是报志愿的建议,倒不如说是提前给新生写好的建议。
关于笔者andywu
- 北京信息科技大学计算机学院的17级本科生(就要大四啦!)
- 大一参加学校程序设计竞赛拿过第2名。
- 和smc和pby一起代表学校拿过一枚acm-icpc区域赛铜牌和邀请赛铜牌(算是底层竞赛选手了)
- 曾经的acm集训队队长
- iflab社团导师
- 大三上学期去了百度实习。
- 现在在字节跳动实习。
个人经历
在大二的暑假,我写过这样一篇文章大学中场的一些感想 这里就简单说说。
大一还没入学的时候,pj学长就跟我们几个学弟上了一堂科普课,比如什么是前端、后端、以及各类程序员主要的工作、业界的开发流程等。这对一个刚刚高考完即将学计算机的孩子来说,帮助挺大的。
不过后来我被kirai学长带到了acm集训队,走上了竞赛的路线,在此之后我的工作重心主要是竞赛,感谢我的队友,我和他们一起拿了两个铜牌。
大三上学期面试百度居然过了,于是就去了百度实习。在最近4月份从百度离职,之后来了字节跳动。
关于报志愿
在出分数之前我想的是我去西电呢还是北邮呢,实在不行杭电也行嘛。结果出分数之后整个人都不好了,当时有人建议我报东北大学秦皇岛分校和西北农林科技大学,我已经填上去了,不过思前想后,我还是第一志愿就报了我校,我比我校去年分数线高20分,这样我大概率能选计算机专业。去东秦也挺好的,但我很怕我选不上计算机专业。
如果你真的要报考北京信息科技大学。。。
这不完全是一篇给自己学校打广告的文章,只是基于我的个人立场给出的一些看法,所以,不足的地方我也会说。
地处北京的地域优势,同时因为地域拉高了分数线。
我们学校的分数在我高考之前大概是一本线过一点吧,最近几年可能变高一些了。在信息科大最大的优势就是在北京,如果真的想来北京,分数又不够其他高校,那可以考虑一下,这可能也是大部分人报我校的原因。
它可能不适合高考之后对未来没有一点想法的考生
我个人还是挺喜欢我们学校的,所以这个论点不是黑它的意思。请往下看
三年了,我在大学见到了从14级的学长学姐,到19级的学弟学妹,足足有6届同学了。我觉得,大部分在信息科大成长起来的人,刚上大学的时候就比较有想法,或者说不随波逐流的。在之后的几节,我会简单说一下我的大学同学。
简单说就是,如果一个考生,高考之后没有什么想法,稀里糊涂就来了信息科大,还被“高考完了你就可以浪了”这种想法毒害,那他可能不适合来信息科大。
那么什么样的人适合来呢?
如果你想来北京,并且热爱计算机,上大学之后也能保持很自律的状态,能够自己获取有用的信息,社交能力OK,那么欢迎你报考北京信息科技大学。
- 热爱计算机。因为互联网行业想来说不那么卡学历,北京的互联网又如此发达。所以来信息科大比去偏远地区的211要好很多。还有,如果是其他专业,比如生化环材或者文科类的,学校很重要,而且学校提供的科研资源也很重要。而计算机,只需要一台电脑跟网线你就能干很多事情。
- 上大学之后还能保持自律。这一点也非常重要,这可能是一切的前提。因为大学很自由,而且我校的学习氛围没有好到让一个堕落的人受到熏陶而发奋图强的地步。
- 能自己获取有用信息。这一点也很重要,比如你想打竞赛,那你可以找到竞赛的集训队,又或者你想找实习,也得自己找招聘信息。说白了,在学校接触到的信息是很有限的。
- 社交能力OK,这一点其实跟上面一点很像。促进信息的流通嘛。
信息科大给的资源还是可以的,就比如我们acm集训队,训练场地、比赛的差旅、报名费什么的,学校都会全大力支持。还有你想搞科技创新,也有支持。甚至想创业,也能提供创业中心的办公室。
总之就是,对于有想法的人,学校提供的资源虽然说不多,但还是够用的。
关于计算机专业的学习
上大学你就要明白一件事,就是一切都得靠自学,别人只是辅助。
我之前在社团的网站写过,计算机专业书籍推荐,如果你来了计算机学院,强烈建议你看一下。
需要注意的一点就是,学校学的,很大概率你去企业或者去读研是不会直接用上的,更多知识一些基础的学习。
我认识的四种选手
绩点选手
顾名思义,就是绩点很高的同学。计算机学院一般计科2、软工2、网工1个保研名额。刷绩点保研是一条出路,但是你也要做好你在第3到第15名的
我们学校的保研,14级lzg学长去了中科院计算所,jhj学姐去了北邮。15级fy学长去了清华。16级前阵子听说年级第一去了北航。所以,从质量上保研还是很优秀的。
至于数量就很让人心疼了,专业第2名和第3名的努力程度其实是不相上下的,但他们面临的挑战就完全不一样了。
不过总归说来,绩点高的好处多多,你好好学习本来就是学生分内的事,学校还会给你发奖学金,何乐而不为呢?这一点上我可以说是反面教材了,大一的时候还拿过三等奖学金,大二忙着打竞赛,只能说没挂科。大三翘课去百度实习,还挂科了。
竞赛选手
竞赛选手是很少一部分,其实就是我们集训队队员了。竞赛这条路需要有很大的投入,有很大的不确定性,也需要长远的耐心。但是,竞赛训练的代码基本功那可是终身受益的。竞赛带来的好处对我来说很直观,我大三就能去百度实习也算是竞赛的功劳。
竞赛选手,像我去了业界搬砖,我的队友在准备考研,kirai学长考上了中科院计算所,出路也是很好的。
欢迎参加acm竞赛!
工程选手
我校的工程选手也是很强的,像wrq和他的小伙伴一起写出了造福全校同学的课程表软件,jzw给创新杯写的网站报名,以及qyz、wpj、xzk学长靠着写着一手iOS,大二就去实习,从小厂,到网易/滴滴,再到字节跳动。还有很多iflab社团的同学,都能靠写项目赚点零花钱。
我的前辈和同学们
- pj学长。在上文提过他,靠着优秀的ios技能,从大二就出去实习,先是一家小厂,再到滴滴,又到了字节跳动。顺便安利一下他的博客,http://pjhubs.com/
- kirai学长,kirai是我前进道路的指路人,对竞赛有十足的热爱,大学四年都在打竞赛,最后考研去了中科院计算所。
- 鼎鼎学长,鼎鼎学长算是他毕业后我们才混熟的,校招就去了美团,在我实习之后给了我很多建议。
- wxd,连续三年他们专业绩点第一,属实佩服。
- smc,我的队友,竞赛实力比我强多了,如果没有他可能我也没有奖牌,也就没有后来去百度字节跳动的事了。
- wrq,工程能力巨强,对业界的主流技术也有很广泛的了解。
- lsq,是一个很有想法的小姐姐,励志要做游戏。最近去了腾讯暑期实习。
正所谓见贤思齐焉,很高兴在信息科大遇到你们!
介绍他们主要还是想说,他们都离我还不算太远,至少肉眼可见来了信息科大还是有可能有好的成就的。
写在最后
好久没有写文章了,这次算是攒了很久,还蹭了个热点吧,啰嗦这么多。
感谢阅读,欢迎点赞关注转发三连哦!
---
layout: post
title: actual_world
date: 2019-12-22 05:56:50 -0500
tags:
- 大学
- 自我成长
---
我还是象牙塔里的人,但同时也活在现实世界。想说一下象牙塔里和真实世界的不同。现实世界太难预测了,在象牙塔里,我努力一点,肯定就有进步。但是现实世界可能会出现挣的钱多了,但房价涨得更快了的情况。
以后开个网吧?
这个故事得从初三暑假讲起,中考结束的那个暑假,我去了我们县城的一家电脑店打工,老板是个80后,就叫鹏哥吧。就是组装机器、卖电脑、擦内存条、换零件之类的活,不过对于当时的我来说觉得很新鲜,哈哈。当时电脑点还有一项业务:给县城的网吧提供技术支持,也就是网吧的计费服务器啊,网吧的机器和网线啊之类的。电脑店的老板说,网吧一天收入能有1万,然后我就算,假设有200台机器,一天上座率80%的,纯上机时间18个小时,1个小时5块钱算的话,一天有14400的收入。当然,这个假设很有学生思维,假设一切都是理想的,没有文化局抓未成年人上网,寒暑假之类的考量。
后来我就上高中了,我跟我的小伙伴叶林和大帅说,我以后写代码挣钱,现在码农一个月有1w吧(当时听说的),等写不动了我就回我们县城开一家网吧,一天能收入1w块。
事实上,我上高二回家的时候,电脑店已经不开了,转型成了一家水吧。我回去问鹏哥(前面说的电脑店老板),为啥不开了啊,他说,现在的手机太好玩了,大家都玩手机了,家里的电脑坏了也懒得拿去修了。
对啊,为啥啊,因为4G普及了,移动互联网慢慢兴起,手机比以前好玩了,玩电脑的人就比以前少了。所以,网吧和电脑店就不如以前挣钱了。
我初中的时候对未来的预判,肯定是有偏差的,而且我现在回想起来还觉得很荒唐。
生涯规划
这是高一时一个心理课的作业,很多同学都是随便写写,但我当时,是真的认真想了,虽然说现在回想起来很搞笑,23333。

当时想着,北邮好还是西电好呢?最后最后杭电都考不上,来了北京信息科技大学。这也是我对于未来预测翻车最严重的一次,大概算上我
大家可以注意到,我当时做ppt的时候,配图是robin和百度大厦,这肯定是我当时随便找的。当时百度应该还是国内第一大厂,魏则西事件等一系列使得百度风评变差的事情还没发生。
万万没想到,我居然走进了当年ppt里的那座大厦。
这个故事就比较近了。刚上大学的时候,因为刚刚经历过人生最大的挫折(唉),我没敢想别的事情,只是看书刷题写代码。然后在iflab(我校一个技术社团)见到很多厉害的学长。一个很厉害的学长是在爱奇艺,后来社团里有学长去了美团、滴滴之类的企业。我就觉得,我如果努力的话,毕业了应该也能这样吧,但我还是向往bat的。
然后,我今年8月份开始找实习,最开始只是投一家小公司。面试官看我是打竞赛的,啥开发也不会,就问了算法题,还挺简单的,我当时就秒了,最后到了主管面。“小伙子代码写得不错啊,我就不跟你讨论技术问题了”,然后安利以后工作的事情,要不要读研啊,刚刚的一面面试官是xx的初创员工、二面面试官是xx的后端核心,我们的学习氛围还是不错的等等。
接着又接到了360的面试邀请,我就去了,算法题全秒,但计算机网络我答不上来,也就挂了。一周之后又接到了百度HR的电话。这次我不敢那么莽了,面试前复习了一下一些常问的知识,还找学长和老师请教了一下,于是很巧的就面过了。
入职第一天,我走进了百度大厦,之后的办公地点是百度科技园。有一天经过大厦的时候,我突然想起来,这不是我当时做ppt时的那个楼吗?然后找了个角度,还真能拍出来和当年ppt里差不多的场景。万万没想到,当年随便找的图,过了几年后,我居然走进了当年的那张ppt里。
大厂兴衰
我之前从来没有关注公司市值,也不知道这一个东西。只是在拿offer之后才了解的,BAT里,AT的市值几乎是B的十倍。美团700亿美元左右,最近来看是稳坐第三了,我也不知道这是具体什么时候发生的,大概就是移动互联网兴起的这几年吧。
如果时间点回到2012年的毕业季,一个很优秀的应届生去了百度,BAT三大巨头之一,一个一般的应届生去了字节跳动,当时能让人知道的就只有今日头条这一个app的公司。过了几年,到了今天,这两个人的单纯财富上的差距应该很大了吧。
百度是我第一家实习的公司,我入职前和入职后的对百度的看法还是很不一样的。在我看来百度的工作体验和办公环境都非常好、技术氛围也很好,经常有技术讲座,跟大学里大家都看手机的讲座不同,听众是会跟主讲人讨论具体技术问题的。不过也有可能是因为我没有其他公司作为参照对比,总之也许不是业界最好,但至少不算差。度厂能否借助人工智能逆风翻盘,这个谁也不好说。
象牙塔和现实世界
在象牙塔里,朝着一个方向努力大概率能取得进步,但是现实世界很可能不是这样的,变动太大了。比如,虽然说挣的钱更多了,但是房价突然涨得更快了。本来算法岗其实竞争不大的,但是人工智能被炒得火爆,算法岗也就变成神仙打架了。同事跟我说,他校招的时候,算法岗只需要会一些简单的算法就差不多了,等到过两年面试新人的时候,竞争太激烈了,得有顶会论文才行了。
个人选择
首先,大部分人是没有早期加入一个初创公司,然后公司逐渐成长为巨头的眼光和运气的,虽然说可能碰巧遇到这种事情,实现财富自由的梦想,但那毕竟是少数。
我觉得这种事情遇上了就是运气好+眼光独到,遇不上也很正常。但是个人的技术水平和学习能力好歹能让一个人安身立命,小富即安吧。
我更加关注个人成长和主观体验吧,很多时候,我们不能用看其他人的旁观者的眼光去看自己,觉得a选择了x路线结果翻车了,混的不咋地,b选择了y路线,如鱼得水的,羡慕死了。事实上,哪条路都有哪条路的痛苦和快乐,你不再是一个旁观者,你做出的选择,是你自己要去经历的。而且,世界变化莫测,前人的经验可能已经不再管用,先入场割韭菜,后入场被割韭菜的事情也多得很。
现在,我走到了一个人生的十字路口。是要读研呢,还是工作呢?
工作的话,努力争取一下转正,或者面其他公司,应该很大概率能进入大厂工作。考研是个很大的未知数,能不能考上是一个问题,考上了3年之后就业的形势又是一个问题。
外人只看结果,自己独撑过程。
这个人说得很有道理,但毕竟不是四海皆宜的真理
就如同知乎上的,轮子哥不推荐打acm,Morgan不推荐考研,还有刚刚跟我交流过的马力老师。他们说得都一定有他们的道理,但毕竟不是对每个人都适用。需要自己想清楚,然后去选择吧,有什么痛苦和快乐,都是自己的。

就从我目前的认知以及我个人情况看来,考研考的专业课,面试也是会问的,所以好好复习并不会亏什么。而且工作我体验过了,读研和备战考研是我还没体验过的,我可以去尝试一下。如果撑不下去了,去投简历,大概率还是会得到面试机会的。所以个人选择和知乎大V对大部分人的建议,是要区分开的,具体问题,具体分析。
旁观者的评价和你的主观感受
旁观者的评价,更多的是基于过去发生的一些事情,以及他的视角来看的。这个并不能代表你的主观感受,甚至截然相反。就好像我前不久acm比赛中拿了铜牌,又进了百度实习。而我又在一个很一般的学校,所以在大家看来应该是很厉害了。但是,如果在更优秀的985高校,其实这点成就不算什么对吧。
还有,我在竞赛圈里其实是很菜的,拿了铜之后又觉得差点拿银很遗憾,进百度之后突然找不到了以后的目标。
这是我的主观感受,旁人是不会知道的。
所以,我的选择更看重我的主观感受和我是否会得到成长,在旁人看来很成功,那跟我其实没啥关系。
---
layout: post
title: 我的象牙塔与真实世界
date: 2019-12-21 19:00:00 -0500
tags:
- 大学
- 自我成长
---
2019-12-22-我的象牙塔与真实世界
我还是象牙塔里的人,但同时也活在现实世界。想说一下象牙塔里和真实世界的不同。现实世界太难预测了,在象牙塔里,我努力一点,肯定就有进步。但是现实世界可能会出现挣的钱多了,但房价涨得更快了的情况。
以后开个网吧?
这个故事得从初三暑假讲起,中考结束的那个暑假,我去了我们县城的一家电脑店打工,老板是个80后,就叫鹏哥吧。就是组装机器、卖电脑、擦内存条、换零件之类的活,不过对于当时的我来说觉得很新鲜,哈哈。当时电脑点还有一项业务:给县城的网吧提供技术支持,也就是网吧的计费服务器啊,网吧的机器和网线啊之类的。电脑店的老板说,网吧一天收入能有1万,然后我就算,假设有200台机器,一天上座率80%的,纯上机时间18个小时,1个小时5块钱算的话,一天有14400的收入。当然,这个假设很有学生思维,假设一切都是理想的,没有文化局抓未成年人上网,寒暑假之类的考量。
后来我就上高中了,我跟我的小伙伴叶林和大帅说,我以后写代码挣钱,现在码农一个月有1w吧(当时听说的),等写不动了我就回我们县城开一家网吧,一天能收入1w块。
事实上,我上高二回家的时候,电脑店已经不开了,转型成了一家水吧。我回去问鹏哥(前面说的电脑店老板),为啥不开了啊,他说,现在的手机太好玩了,大家都玩手机了,家里的电脑坏了也懒得拿去修了。
对啊,为啥啊,因为4G普及了,移动互联网慢慢兴起,手机比以前好玩了,玩电脑的人就比以前少了。所以,网吧和电脑店就不如以前挣钱了。
我初中的时候对未来的预判,肯定是有偏差的,而且我现在回想起来还觉得很荒唐。
生涯规划
这是高一时一个心理课的作业,很多同学都是随便写写,但我当时,是真的认真想了,虽然说现在回想起来很搞笑,23333。
|  |
share_289293797.png
当时想着,北邮好还是西电好呢?最后最后杭电都考不上,来了北京信息科技大学。这也是我对于未来预测翻车最严重的一次,大概算上我
大家可以注意到,我当时做ppt的时候,配图是robin和百度大厦,这肯定是我当时随便找的。当时百度应该还是国内第一大厂,魏则西事件等一系列使得百度风评变差的事情还没发生。
万万没想到,我居然走进了当年ppt里的那座大厦。
这个故事就比较近了。刚上大学的时候,因为刚刚经历过人生最大的挫折(唉),我没敢想别的事情,只是看书刷题写代码。然后在iflab(我校一个技术社团)见到很多厉害的学长。一个很厉害的学长是在爱奇艺,后来社团里有学长去了美团、滴滴之类的企业。我就觉得,我如果努力的话,毕业了应该也能这样吧,但我还是向往bat的。
然后,我今年8月份开始找实习,最开始只是投一家小公司。面试官看我是打竞赛的,啥开发也不会,就问了算法题,还挺简单的,我当时就秒了,最后到了主管面。“小伙子代码写得不错啊,我就不跟你讨论技术问题了”,然后安利以后工作的事情,要不要读研啊,刚刚的一面面试官是xx的初创员工、二面面试官是xx的后端核心,我们的学习氛围还是不错的等等。
接着又接到了360的面试邀请,我就去了,算法题全秒,但计算机网络我答不上来,也就挂了。一周之后又接到了百度HR的电话。这次我不敢那么莽了,面试前复习了一下一些常问的知识,还找学长和老师请教了一下,于是很巧的就面过了。
入职第一天,我走进了百度大厦,之后的办公地点是百度科技园。有一天经过大厦的时候,我突然想起来,这不是我当时做ppt时的那个楼吗?然后找了个角度,还真能拍出来和当年ppt里差不多的场景。万万没想到,当年随便找的图,过了几年后,我居然走进了当年的那张ppt里。
大厂兴衰
我之前从来没有关注公司市值,也不知道这一个东西。只是在拿offer之后才了解的,BAT里,AT的市值几乎是B的十倍。美团700亿美元左右,最近来看是稳坐第三了,我也不知道这是具体什么时候发生的,大概就是移动互联网兴起的这几年吧。
如果时间点回到2012年的毕业季,一个很优秀的应届生去了百度,BAT三大巨头之一,一个一般的应届生去了字节跳动,当时能让人知道的就只有今日头条这一个app的公司。过了几年,到了今天,这两个人的单纯财富上的差距应该很大了吧。
百度是我第一家实习的公司,我入职前和入职后的对百度的看法还是很不一样的。在我看来百度的工作体验和办公环境都非常好、技术氛围也很好,经常有技术讲座,跟大学里大家都看手机的讲座不同,听众是会跟主讲人讨论具体技术问题的。不过也有可能是因为我没有其他公司作为参照对比,总之也许不是业界最好,但至少不算差。度厂能否借助人工智能逆风翻盘,这个谁也不好说。
象牙塔和现实世界
在象牙塔里,朝着一个方向努力大概率能取得进步,但是现实世界很可能不是这样的,变动太大了。比如,虽然说挣的钱更多了,但是房价突然涨得更快了。本来算法岗其实竞争不大的,但是人工智能被炒得火爆,算法岗也就变成神仙打架了。同事跟我说,他校招的时候,算法岗只需要会一些简单的算法就差不多了,等到过两年面试新人的时候,竞争太激烈了,得有顶会论文才行了。
个人选择
首先,大部分人是没有早期加入一个初创公司,然后公司逐渐成长为巨头的眼光和运气的,虽然说可能碰巧遇到这种事情,实现财富自由的梦想,但那毕竟是少数。
我觉得这种事情遇上了就是运气好+眼光独到,遇不上也很正常。但是个人的技术水平和学习能力好歹能让一个人安身立命,小富即安吧。
我更加关注个人成长和主观体验吧,很多时候,我们不能用看其他人的旁观者的眼光去看自己,觉得a选择了x路线结果翻车了,混的不咋地,b选择了y路线,如鱼得水的,羡慕死了。事实上,哪条路都有哪条路的痛苦和快乐,你不再是一个旁观者,你做出的选择,是你自己要去经历的。而且,世界变化莫测,前人的经验可能已经不再管用,先入场割韭菜,后入场被割韭菜的事情也多得很。
现在,我走到了一个人生的十字路口。是要读研呢,还是工作呢?
工作的话,努力争取一下转正,或者面其他公司,应该很大概率能进入大厂工作。考研是个很大的未知数,能不能考上是一个问题,考上了3年之后就业的形势又是一个问题。
外人只看结果,自己独撑过程。
这个人说得很有道理,但毕竟不是四海皆宜的真理
就如同知乎上的,轮子哥不推荐打acm,Morgan不推荐考研,还有刚刚跟我交流过的马力老师。他们说得都一定有他们的道理,但毕竟不是对每个人都适用。需要自己想清楚,然后去选择吧,有什么痛苦和快乐,都是自己的。
|  |
image.png
就从我目前的认知以及我个人情况看来,考研考的专业课,面试也是会问的,所以好好复习并不会亏什么。而且工作我体验过了,读研和备战考研是我还没体验过的,我可以去尝试一下。如果撑不下去了,去投简历,大概率还是会得到面试机会的。所以个人选择和知乎大V对大部分人的建议,是要区分开的,具体问题,具体分析。
旁观者的评价和你的主观感受
旁观者的评价,更多的是基于过去发生的一些事情,以及他的视角来看的。这个并不能代表你的主观感受,甚至截然相反。就好像我前不久acm比赛中拿了铜牌,又进了百度实习。而我又在一个很一般的学校,所以在大家看来应该是很厉害了。但是,如果在更优秀的985高校,其实这点成就不算什么对吧。
还有,我在竞赛圈里其实是很菜的,拿了铜之后又觉得差点拿银很遗憾,进百度之后突然找不到了以后的目标。
这是我的主观感受,旁人是不会知道的。
所以,我的选择更看重我的主观感受和我是否会得到成长,在旁人看来很成功,那跟我其实没啥关系。
---
layout: post
title: 好好生活
date: 2019-11-29 06:34:27 -0500
tags:
- 生活
- 自我成长
---
首先,这些观点不是我发明的。很多观点从科学实验里诞生,到论文,再传到畅销书作者那里,最后再传到我这读者这里,已经是很多手的知识了。
主要来源于一些书籍,《暗时间》、《学习之道》、《深度工作:如何利用一点脑力》、《从行动开始》、《反本能:如何对抗你的习以为常》。
但也不是背书那么简单,书里讲的具体内容我应该都忘记得差不多了,只是有一些观点,经过我长时间的思考和反思,对我产生了潜移默化的影响,印在了我的脑海里,我写在这里分享给大家。
写在前面
首先,这些观点不是我发明的。很多观点从科学实验里诞生,到论文,再传到畅销书作者那里,最后再传到我这读者这里,已经是很多手的知识了。
主要来源于一些书籍,《暗时间》、《学习之道》、《深度工作:如何利用一点脑力》、《从行动开始》、《反本能:如何对抗你的习以为常》。
但也不是背书那么简单,书里讲的具体内容我应该都忘记得差不多了,只是有一些观点,经过我长时间的思考和反思,对我产生了潜移默化的影响,印在了我的脑海里,我写在这里分享给大家。
2019.12.5开始写。
接纳现在的自己
这个观点的主要来源是《从行动开始》
我现在成绩很差。那我这时候有两种选择,一种是责怪自己,“为什么成绩这么差还不努力啊”,“真是太失败了呢”。还有一种是“不如起来写几道题,看看知识点吧”
很多人认为,让自己知道现在有多么不堪,可以激发自己的动力,但实际这个行为本身不会让情况变好,只是在你的脑子里多出来了一种“我不行”的想法,这个想法对物理世界没有一点儿积极的影响。但是如果你选择去做一点事情,哪怕是一点点,这个行动真实的发生在了物理世界里,虽然说这个改变很微不足道,但它确实是发生了,并且给现实世界造成了积极的影响,你学了一个知识点,这个知识点会在你的脑海里留下痕迹的,哪怕你会忘,但再次学的时候还是会跟从来没学过有差别的,这一点差别就是你行动的意义。
大一的时候,我总是说“如果大四的时候像学长一样优秀我就知足了”。这句话的隐含意思是,我希望大四时候的我能够很优秀,但是,大四的我也是我,他不是另外一个人,“希望”这个动词的执行者和承受者都是我。所以,只有现在的我做出一点改变,大四那个时刻的我,才会更好一些。只是凭空希望,是没用的。
不过如果你认同了我之前说的,你可能又会出现一个问题,就是觉得自己当下的努力没用,看这一页书,真的有用吗?刷了这道题,也不会使你的能力提升多少吧?确实是这样的,大家都是普通人,不会突然地就变强起来。但我们还是要从实际出发,在一个时间段内,你有两个选择,第一个,去看书,刷题。另外一个选择,你开始怀疑自己当下的努力没用。这个时间段结束之后,哪种对于改变状况更好呢?
就好像我现在正在写这个稿子,我不知道我能写多久,我也不想着我要写多久,只是写了这一章,我敲下的键盘,这篇博文就多了一章,这就是这段时间的意义。
5号开始起笔,今天(8号)写了第一章,也是因为今天状态不是很好,需要写作来改善一下。是的,没错,状态不好的时候写点东西对改善状态挺有帮助的,一方面是梳理了思路,另外一方面呢,写作是一段专注的工作时间,这专注的时间过去了,状态也会好起来。就比如说,一个很久没运动的人,去慢跑几圈,状态也会变好的。
《反本能:如何对抗你的习以为常》
比如,我的一个朋友曾经抱怨说:“我那么努力成绩却那么差,努力还有什么用呢?”我当即反问他:“你不努力的话会比努力过得更好吗?”
后来,我跟他表达了我的看法。我们不应该拿努力的自己与不努力却学习成绩好的人比较,而是应该拿读书的自己和不读书的自己来比较。前者只是我们知觉到的不平等,后者则是我们努力带来的价值。我们不应该拿这种想法来惩罚自己,作为自己不上进的借口。
2019.12.8
---
layout: post
title: 竞赛杂感
date: 2019-11-28 08:22:13 -0500
tags:
- 竞赛
- 程序人生
---
我的大部分成就,都跟我队友有关。
看了claris的文章我感觉很沉重。
可能因为我在社交网络比较活跃,运气不错进了百度实习,上届集训队队长的title,给大家一种我是个很厉害的人的错觉。但实际上我的队友和我的学长远比我强得多,solo水平我是绝对不如他们的,如果没有他们我也不会有站上领奖台的机会,可能也就不会有实习的机会。所以我的成就大部分都跟队友有关,教练夸我们打得好的时候我也会说主要还是他们两个的功劳,我的贡献约等于订机票酒店和报销。
我很清楚我很菜,同时对于一切吹捧我都默认对方在开玩笑,我自己什么水平我还是有点B数的。
最近又是实习又是功课的,训练确实有点怠惰,还是尽力挤出时间来训练吧,不希望自己成为文中里喷的那种人。
原文链接:我的最后一次ICPC WF是如何爆炸的? - clrs97的文章 - 知乎
https://zhuanlan.zhihu.com/p/94048942
作者:clrs97
链接:https://zhuanlan.zhihu.com/p/94048942
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大家好,我是Claris,我在BZOJ刷了4031题,是
@snowy smile
的WF2018队友,队名HDU-AcmKeHaoWanLe,今天我来给大家复盘一下我的第二年WF。
最近我的队友wkc在ICPC上海命题时出了一点问题,他认识到了自己在一定程度上的失职,目前事情已经告一段落。他发表了一篇回应文,希望我给出一个客观公允的评价和认真的回复,所以我不得不跟大家说清楚:wkc已经认识到了自己命题经验的缺失和命题工作上的失职,但是我要告诉大家:所谓“热爱ICPC”的wkc,在WF前究竟是如何训练的,是如何造成我ICPC选手生涯最痛苦的事情的。
组队
当时学校里除了我就是wkc的水平比较突出,为了在WF上争取拿个好成绩,我肯定是要跟他组队的。剩下的同学里水平没有特别突出的,他的女朋友zjs跟他配合不错,英文阅读、计算几何等方面也有一些特长,于是我们就组了队。当时wkc在我心目中确实跟大家现在的认识一样,是个“热爱 ICPC”的人,我WF17虽然没拿到奖牌,但打的还算可以(在三个人没训练的情况下获得rk20),如果跟一个热爱ICPC竞赛的人一起追梦,是不是真的有希望完成梦想,甚至冲击奖牌?
然而渐渐地, wkc让我知道,什么叫做真正的“热爱”。
区域赛
区域赛上没什么可说的,虽然有成功、有失误,但他确实很拼,我们一起努力训练。我们在ICPC沈阳和CCPC杭州连续夺得两次季军,轻松出线WF2018,我感觉到我离我的梦想越来越近了。
出线之后的那个春节
虽然早就知道稳了,但在我们看到黄教授的博客官宣后,我们三个都还是挺开心的。在北京举办的WF2018时间比以前相对早了很多(在4月19日),时间所剩无几,我摩拳擦掌地开始安排紧张的训练计划。那个寒假清华有个ITMO训练营,根据对俄罗斯题目的好感,我认为这个训练营质量应该还不错,于是在群里拉着队友一起报名:
我:“快来报名ITMO Camp!”
wkc:“这个质量听说不好啊”
我:“我个人感觉题目质量应该比较正常”
wkc:“但是你不是都会,也学不到什么嘛哈哈哈”
我:“主要是为了你们俩的训练”
wkc:“这个太贵了,不如我们自己练,你看北师北航都不去”
我:“他们的目标就是当旅游队,你们不训练的话你们的状态呢?”
wkc:“3月回来狂训!”
……(搪塞一大堆理由)
wkc:“寒假训练不了,我和zjs现在正在游戏公司实习”
我当时瞬间就懵了。这个时候离WF还有不到三个月,wkc不仅一点没跟我说过实习的事,一开始居然还想说服我,让我本人因“质量差”、“贵”等理由主动放弃寒假的训练。这时我终于明白之前和人吹水群聊的时候,别人那句“你的队友现在在我们公司”是什么意思了,我也终于明白刘老师跟我说的“我看别人发公司日常,照片里有wkc,他是不是去实习了?”是怎么回事了。
“实习前还是首先确保了、明确得到HR同意说,可以提早结束实习、不耽误训练才答应的。”
你是得到了HR的同意,但是你得到了队友的同意吗?这是一个“热爱ICPC”的人在WF前应该做的事情吗?
当时的我虽然生气,但他已经在实习了,我也没办法,只能寄希望于3月份狂训。我就忍了下来,自行做题,把BZOJ的题量刷到了3700多。
3月狂训
3月开学后,我们在一起疯狂训练,和之前说好的一样,几乎每天一场的频率,除非有课或者其它突发不可抗力因素。我们此时在opentrain的几场训练成绩也比较好,这给了我很大的希望和继续努力的动力。
《人权说》
虽然我小时候爱哭,但是我现在不会哭。然而看到这段话,我的眼泪直接就流了下来,在宿舍里一个人失声痛哭了整整一个下午,哭到天黑。
去日本旅游,是得到了Indeed的免费面试、旅游机会。假如我是一个有人权的人,我一年不算春节,包括周末内在内的事假、病假,加在一起也没有超过7天。去日本,因为免费的机票和住宿,顺带玩了5天,是我整个大学期间,都很少有的”休假”旅游行为。如果是你,请告诉我,你会放弃这个机会吗?
为什么WF前的训练是违反人权的,我就没有人权么?这所谓的人权是不是拿队友的努力开玩笑?具体细节是这样的:
3月13日(3月12日我要上课)中午,我在集训室等待着约定俗成的12点的训练的开始,但是到了12点30却发现队友仍然没有赶来。于是我在QQ上问,得到的回复是“不好意思,我们去日本面试了,没几天就回来了”当时天真的我还是相信了队友的话,觉得他虽然有微软等offer,但是去海外发展应该也不错,并在心里祝他面试成功,觉得最多过个一周他应该就回来了,就和寒假时的先斩后奏一样,我只能寄希望于他所答应的三月狂训并非虚言,尽快面试完赶回来恢复训练。但是万万没想到,队友一去就是将近两个星期,人影全无,训练计划根本无法进行。3月18日我们在QQ群里讨论算法问题的时候,wkc说他明天要面试了,很慌。这时我感到时间很不对劲,质问道:
我:“你怎么明天才面试,你前几天干嘛去了”
wkc:“前几天旅游买游戏机了[/斜眼笑]”
WF2018本来时间就很早(4月19日),这意味着寒假不训练的话,那么我们就只有开学后的短短一个月的时间,而一个月又有多少个两星期可以浪费?直到我看完回应文,我才知道他去面试只是为了蹭面试报销的差旅费去玩了5天,根本不是为了什么更好的offer。说好的不去寒假训练,3月狂训补上呢?
我身为一个打过一次WF的人,我的目标肯定不是止步于“从中国出线进入WF”,我第二次(或者说最后一次)打WF是为了什么?难道是去WF的举办地旅游吗?当然是冲击更好的成绩、甚至是奖牌啊!我连WF安排爬长城的那天都在酒店里打模拟训练赛。我不明白、也不理解wkc对于赛前鸽了训练去日本旅游的行为,更不能理解队友说的什么“人权”,以及什么换个人也会像他这么做。我询问了很多选手,他们都表示肯定选择训练,甚至有选手调侃道:“如果我校WF队这样会被教练xxx锤爆头”。
没错,你拿你的“人权”,践踏了我的努力。这就是我的客观公允的评价。
赛后
通过上面几件事,想必大家应该猜到了,WF2018果然爆炸了(rk31),哪有天上掉馅饼的事。赛后我回到学校,在宿舍里自闭了两周,一个电话也不接,一个QQ也不回复,家里人都很着急,刘老师也频频安慰我。
我翻来覆去地思考,到底是哪里出了问题,我为了准备WF18放弃了许多东西,甚至没有在实习招聘黄金时间去找实习,直到WF18赛后各个公司人都快招完了才匆忙去找实习,最后差点没有找到实习。
所以应该不是我的问题,我最终得出的结论是:如果一个队三个人不是都充满斗志的,那么这支队伍在WF基本就是没戏的。
在没看到他的回应文之前,虽然我对他这两件事很不满,但毕竟是队友,要包容。像这次出题的事情我也是热心帮忙的,在过生日的时候抽出时间帮忙验了题,并给出了相关修改意见。
这篇回应文,简直刷新了我的认知——他是一个自称“热爱生活、热爱训练、一年只休息几天的训练狂、工作狂”,而我是一个无知的、误解了他的、“不考虑人权”的人。因为他的“热爱”,我的努力几乎都白费了,换来了比17年更差的WF成绩。我的梦想毁于一旦,我的热爱却被掩盖在他所谓的“热爱ICPC”之下了。
后记
2019年11月27日这个下午,我哭了,从来没有这么难受、这么委屈。
早知这样,我大可选择战术隐忍到大四甚至研究生阶段,和真正“热爱ICPC”的人一起去努力。
我心中的那朵花,在这个下午,大概的确已经死掉了。
---
layout: post
title: 21
date: 2019-11-16 10:47:37 -0500
tags:
- 生日专题
- 生活
---
21岁的近况与想法。
我每年生日都会发一篇文章,而且还是提前一个月开始执笔。而这次,生日前一天看日历才知道我要过生日了。因为最近真的很忙,一边上班一边兼顾功课。
我每年生日都会发一篇文章,而且还是提前一个月开始执笔。而这次,生日前一天看日历才知道我要过生日了。因为最近真的很忙,一边上班一边兼顾功课。
20到21这一年
竞赛终于拿奖了
在我和两个队友和齐心协力下,我终于站上了全国赛场的领奖台,虽然说只是两个铜奖。非常感谢我的两个队友,smc和pby,能和你们一起代表学校参加全国的比赛,是我这辈子最充满荣耀感的事。
找了实习
这真是一件过于锦鲤的事情。我在8月份给百度视觉技术部投的简历,在9月被约面试了。面试官问的题刚好我都会,面试官说表现还行。但是我当时说我要打比赛,12月才能入职,所以二面之后就没有然后了。但过了一周,在某招聘软件上,一位滴滴的工程师说服了我,说实习和竞赛是可以兼顾的,于是。。。我就从通话记录里找了当时百度的一面面试官,那位面试官也是我后来的mentor,他很爽快地就让HR走流程了,然后我就顺利入职了,快一个月了。好感谢我的mentor啊。(后来我向那位滴滴的工程师道歉了,真是对不住orz)
奖学金没了。。
忙于竞赛,期末没考好,再加上大类分流计科大佬太多了,唉,学习优秀奖学金就这么没了。。。
回望
我从上大学的第一个生日开始每年生日都写一点东西。链接:19, 20
第一年:不知道要考研还是工作,但要老老实实把当下的事情做好。
第二年:工作!竞赛要拿奖牌!
第三年:找了实习,竞赛也拿了牌。
诗和远方
每天都要开心快乐,在这个基础上才能更好地努力。认真看书刷题写代码,明年拿很好的offer。一定要保持运动量,要不然会扛不住工作压力的。
虽然说已经实习了,但我想明年继续打比赛。
明年的自己:
竞赛有没有取得更好的成绩(银牌及以上)啊?
有没有把书单里的书看完啊?
有没有把题刷了啊?
有没有拿很好的offer啊?
---
layout: post
title: 那些影响我的书
date: 2019-09-30 20:00:00 -0400
tags:
- 读书笔记
- 书单
- 自我成长
---
2019-10-01-那些影响我的书
所谓的正书,乃是过了七月份就没用的书,所谓闲书,乃是一辈子都受用的书。——韩寒 《三重门》
虽然现在韩寒不经常发表图书作品了,但我还是要承认,在我从初二的开始阅读课外读物的时候,读的就是韩寒的《我所理解的生活》。其实我初一的时候读过郭敬明的《爱与痛的边缘》,那应该也算是启蒙读物,但对我的三观影响最大的应该是《我所理解的生活》。
我读的书大多都是畅销书吧,没读过几本经典。现在趁着回忆还有翻阅资料写一下。
《我所理解的生活》
韩寒写《我所理解的生活》时笔锋已经没那么犀利了,读起来很像是一个叛逆的少年在跟这个世界讲和。我对这个社会的认识大概就是从那个时候开始的。在读这本书之前,我只知道他以犀利的笔锋批判现实,但如果仔细读的话就会发现,他不是一个愤青,而是一个很理智的知识分子,他虽然批判,但却能理解批判的现实背后的原因。虽然也许他说得不对,也许他的见解不是当下最优秀的,但对于一个初中生来说,还是有几乎正确的影响吧。
也许很多人认为,中国的当务之急就是一人一张选票选主席,其实这并不是中国最急迫的事。民主是一个复杂、艰难而必然的社会历程,并不是靠“普选”、“多党制”这些脱口而出的简单词汇可以轻易达成的。如果你对司法和出版从来都没有关心过,你关心普选有什么意义呢?无非就是说起来更拉风一点。这和那些一说起赛车只会提F1,一说起足球只知道世界杯的人有什么区别呢?
大概是2011年左右吧,在读这本书之前,我对这个社会的认识会受到当时网络的影响,有太多悲观的、带有批判和嘲讽的言论。读了之后我开始尝试着去理解,而不是批判。说白了,跟着愤青骂几句、嘲讽几句那都是再简单不过的事情,但真正理解那些我们所批判的东西,才是最难做到的。
所以,这本书告诉我的是:尝试着多一些理解,而不是批判。
《乔布斯传》
这本书点燃了一个少年的梦想。
2011年,乔布斯逝世,由著名传记作者沃森写的官方传记《乔布斯传》开始发行。我记得我是初二刚开学时买的那本书,可贵了,60多块,还跟家人闹了一会儿才买的。
乔布斯有太多的超级“酷”的观点,相信大家都知道。比如说“改变世界”、“追求完美”之类的。当时看得我热血沸腾,现在我已经上大学了,慢慢意识到自己也是很平庸的人类,但是,那些理想主义者和完美主义者的观点依然影响着我。
《乔布斯传》从乔布斯出生前的故事讲起了他的身世,他是被领养的,她的亲生母亲在怀上她的时候还在读研究生,然后因为家长反对等各种原因不能结婚,所以就把他送给一对普通工薪阶层的夫妇领养。他的父亲保罗·乔布斯的工作把旧车低价买回来然后修好了再卖出去。他的技艺很精湛,家里的柜子啥的都是自己做的。
我到现在还记得乔布斯父亲的一个观点,大概意思是,柜子背面的木板用户是看不到的,但也要把它做得完美。这样的观点应该对乔布斯产生了巨大的影响,以至于他也那么追求完美吧。
书里有一个不怎么为大众所知,但却是苹果公司发展历程中一个非常重要的人物——斯蒂夫·沃兹尼亚克。
沃兹尼亚克是一个真正的极客,1970年夏天,沃兹尼亚克刚上大二就休学了,在邻居比尔·费尔南德斯家的车库里,二人一起将芯片拼凑起来组成了一台计算机,也因为他们在组装电脑时爱喝奶油苏打汽水,所以这台计算机就被命名为“奶油苏打计算机”。
经费尔南德斯介绍,沃兹尼亚克和乔布斯认识了。一个技术上极其优秀的极客少年,和一个对设计极具灵感的天才少年一起,开始了计算机发展史的新篇章。
最开始的时候,沃兹尼亚克捣鼓出了一个可以利用电话运营商的漏洞的免费打电话的东西,叫做“蓝盒子”。沃兹尼亚克造出产品,乔布斯想办法把产品换成钱。于是他们开始兜售“蓝盒子”,最后因为被盘查而告终。这大概是二人合作的开始。
在一个DIY计算机的展览会上,沃兹获取一份仿英特尔8008微处理器的技术规格文件,赫然发现竟与五年前自己设计的奶油苏打计算机相去不远,他内心里的自制计算机梦再次被激发。
在聚会之后,他利用课余时间在惠普的办公室里搭建了第一代苹果计算机,在1975年6月29日的晚上10点钟,苹果一号的屏幕上显示出键盘所输入的字符,个人计算机历史翻开了新的一页。
后来,他们在乔布斯父亲的车库里,成立了苹果公司。碍于篇幅有限,故事的复述就到这里。
总之,这本书给我展现了上世纪七八十年代,计算机刚刚发展时的样子,沃兹尼亚克的“酷”深深影响了我,我对计算机的认识大概也是从那个时候开始的。
所以,这本书点燃了一个少年的梦想。
未完待续
---
layout: post
title: 大学的中场
date: 2019-08-26 20:00:00 -0400
tags:
- 大学
- 自我成长
---
2019-08-27-大学的中场
还得从那个暑假说起
在高考完的那个暑假,被录取之后。热心的wpj学长找到了我们几个学弟,给我们大概讲了一下计算机业界的一些知识,比如什么是前端什么是后端之类的。我对大学的认识也就是从那个时候开始的。
大二下的暑假是个很神奇的节点,pj学长给我们科普的时候他就是大二刚结束,转眼间我的大二也结束了,他也刚刚毕业了。这也大概是我动笔写这篇文章的原因。
acm真香
我明明说我不打acm了,结果不但打了还打了挺久,甚至acm会贯穿我的整个大学生活。
入学之后,我就一直都在iflab社团待着,那里有很多热爱技术的学长和老师,总之这是我们学校实力很强并且学习氛围很好的社团,我入学之后的朋友大多也是那里认识的。
然后有一天在iflba的群可能说到了打竞赛还是啥的,kirai学长就加了我,把我拉进acm交流群。我记得我说了句:“我不想打acm,我只想学一些基础的算法。”,学长说,“没事没事,这是交流群,不是集训队群。”后来的事我不太记得了。
后来我就真香了,不但打了acm还成了集训队队长。
印象最深的一次是18年刚开始的那几天,C语言考试半个小时满分走人了(试卷太水),然后kirai学长刚考完研也有时间,就带我去acm集训队的实验室玩。就记得那里堆着好多书,什么《算法导论》《具体数学》《数学之美》之类的,我就觉得我好喜欢这里,于是就入队了。
当时还写了篇博客,https://www.jianshu.com/p/537d6fd063b4。
哦对,在入队之前,12月底的时候我跟smc同学一起去地质大学打了校赛,那是我上大学之后的第一场现场赛,做了签到题之后,就再也没有做出题了。回来的路上我整个人都不好了。
总之呢竞赛生涯就开始了。
大一下学期印象最深的是三场比赛。
集训队举办的校赛,计算中心的C语言基本技能比赛,还有西安邀请赛。
4月份集训队举行了校赛,我本来想在校赛上证明自己的,但是那天预约了牙医。不过我还是去了赛场,开场抢了一发签到题,然后去看牙医,看牙医回来比赛还没结束,又写了一道题。最后居然还拿了三等奖hhh。
之后我就跟yzd还有smc去打了西安邀请赛,那场比赛是我们第一次参加国内赛场的比赛。结果很惨,做了一个签到题,后面就自闭了。
6月初的时候,学校举办C语言基本技能比赛,校队的基本都去参加了。那场比赛我前期超级自闭,感觉要爆零了。不过在我突然就过了一道题之后,便接二连三地过题。最后拿了新生组第二,第一是smc。总排名靠前面都是校队的。
说起来那场比赛是我在校内的最后一场比赛了,因为今年C语言竞赛没有举办,校赛的话因为我当队长了,我得组织举办比赛了2333。
大二上,去秦皇岛打了一场比赛,那场比赛我们感觉真的快要摸到奖牌了,1个题是题目有点问题,还有1个是当场陷入思维误区,然后就凉了。还有ec-final,去划了个水,签到自闭。
然后寒假的时候回家继续训练,开始开virtual judge,和smc一场一场地开。
大二下,也就是这个学期,我们尝试日常训练,我们组织了校队的日常训练,慢慢地开始每周都开训练赛。我们训练的同时还开新生训练赛,和18级的学弟学妹一起打。校队也算慢慢有点起色了。
这学期打了西安邀请赛,拿了个铜牌,那是我们开始竞赛以来第一次在国内赛场拿牌,最后一发提交通过之后,跟smc重重地击掌。当时的感觉太难用言语来形容了,就是,我们被虐了这么久,终于有了一点成绩了,太不容易了。
能跟smc和pby组队真是太好了,在bistu很难再凑到3个这样的人了。有什么比赛,问“去吗?”“去!”,“今晚开训练赛?”“好啊!”。3个人都很有干劲的话就觉得充满了希望。
再说回来两位学长
我去iflab还要acm集训队,有我自身的原因,但直接原因还是因为两位学长。现在回过头看,那真是很正确的决定。就bistu来看他们大概是最优秀的一批人了。大一的时候认识他们也算是有了很好的榜样。当然,抛开bistu这个范围,他们也是极其优秀的。一位正在努力成为全栈的ios工程师,在tmd(头条、美团、滴滴)三小巨头的两个offer,现在在其中一家,当然最强的还当属他是WWDC19大中华区学生奖学金获得者(一个苹果发的奖,大概国内就几个人有)。还有另外一位,考上了中科院的研究生,期间还去了google实习。
这两年来我问了他们很多问题,他们给过我很好的建议。虽然后来打acm之后主要跟kirai学长交流比较多,但最近面试啥的,问pj学长,他也是知无不言,言无不尽。
在我们学校整体大氛围不是很好的情况下,大一的时候有这两位学长指点迷津,再加上榜样的力量影响,我确实很幸运了。除了指点迷津以外,更重要的一方面是他们让我看到了希望。
之前在一位小姐姐的朋友圈看到一句话,“不管你去的是什么样的学校,成绩和荣光都是前面的学长学姐们的努力换来的,在学校学习的目的不应该是分享前人的荣誉,而应该是为自己努力,为学校争光才对叭”
然后可能要说这两年的心路历程了
说来惭愧,高考出分之前我想的都是北邮好还是西电好。出分之后整个人都不好了。但是,高考之前我的目标非常明确,我要学计算机专业。所以我第一志愿就报了比自己低20分的bistu,以便能报计算机专业。什么“争一争,保一保,稳一稳”,我才不听呢,我就是要报计算机,录取不到我就复读。最后的结果当然是我如愿以偿了。
接着呢就来学校了,见了pj学长和kirai学长这个上面说过了。再说学习方面,我来自一个高考弱省,按照前人的说法,我们的学生上大学跟强省竞争起来很吃力,可能会挂科啥的。在加上有前辈的影响,我没有说上大学了就浪得飞起,高数那么难orz,万一挂了可咋整啊。当然最后没挂,考得还行。
印象比较深的是C语言考试,题目太简单了,我半个小时就满分走了。我说这件事真的不是想炫耀,当然,我也许会跟学弟学妹们说,也只是想告诉他们这考试不难,不要慌。随之而来的更多是迷茫,我当时觉得,如果是985/211的考试,绝对不会这么简单就水过去的。我不能在这种舒适区待着。
后来参加了竞赛,简单说就是校内能打到很前排,top5还是有的(比赛结果17新生组rank2)。当时甚至觉得,然后走出学校就被吊打。去了地大、北航的校赛,都打得特别惨,别的学校怎么这么强啊。现在可能可以轻描淡写,但当时真的很怀疑人生。
后来得出一个结论,“相对水平只是能偶尔捞点奖学金罢了,没什么用的,不可以沾沾自喜”
渐渐地,我们在别的学校校赛打得还行了,国家级的比赛也能拿个小奖什么的,准确的说,我只是打得稍微好了一些,至少不那么自闭了。
原来我羡慕的人也在羡慕我
放暑假的时候我去了上海玩了一趟,找了复旦的高中同学。我们两年没有见了,然后吃了顿饭在复旦校园散散步,聊了许多。她说她上了大学之后发现她学的专业不是原来她想的那样子的,不过好在她已经从那种很迷茫的状态走出来了。然后她说她很羡慕我,学了自己喜欢的专业。
可能她也就是随口一说吧,但这句话真的让我思考了很久。前面说了,高考失利,以及校内外的落差,都让我很羡慕那些好学校的同学,复旦的就更不用说了。但跟她聊了之后发现,原来我也是被羡慕的。我羡慕的人也在羡慕我。
说实话,我一直都挺悲观的,后来才慢慢意识到,我还是挺幸运的。
最近的面试
开学我就大三了,想着竞赛退役之后去实习,然后就投了简历,面了两家。
第一家,凡普金科,算法实习生。因为我不会机器学习啥的,面试官就没问。问的两道算法题我都做出来了。HR说我面试通过了,但是他们原来想招一位大四的,所以要为了去申请一个短期实习生的名额。今天说名额下来了,我应该可以拿到offer。下午面了360的后端实习生岗位,我感觉算法题可能不会太难,3道算法题我都给手撕了。问了多态是什么?怎么实现的?大一的时候dmm的面向对象课我认真听了所以还记得多态是啥。还问了高并发是怎么实现的?说一些建立连接过程。这些我都没答上来。还有让写hash,我写得不好。
其实我没有想好我要做什么,算法或者后端,或许考个研?当然,实习是12月竞赛结束之后的事。
但面试会让我知道哪里不足,哪里需要学习。大概就是,算法和数据结构,语言底层原理,计算机网络,操作系统吧,这些都得好好学。
学到什么程度?学到能对着计算机相关人士流畅的说清楚原理的地步
写在最后
非常感谢您的阅读,说实话我本想让这篇文章藏在我的便签里,但也许发表出来也许会对一些人有用吧。2019.8.27
---
layout: post
title: 21~25 五年计划
date: 2019-08-12 06:15:38 -0400
tags:
- 五年计划
- 自我成长
---
在blog里悄咪咪地写下五年的计划,时间跨度为21到25岁。这个计划是受采铜的《如何成为一个很厉害的人》启发。我们在思考远期目标时,通常都想得很抽象,往往不会考虑具体如何实现。而在思考近期目标时,又难免会短视,局限于当下的认知,回避了更有意义同时也更具有挑战的事。而五年是一个刚刚好的时间跨度。
”如果把五年作为做成一件事的时间跨度,那就意味着你需要忍受头几年的挫折、煎熬和孤独,乃至别人的无解、嘲笑和攻击“————采铜 《如何成为一个很厉害的人》
写在前面
在blog里悄咪咪地写下五年的计划,时间跨度为21到25岁。这个计划是受采铜的《如何成为一个很厉害的人》启发。我们在思考远期目标时,通常都想得很抽象,往往不会考虑具体如何实现。而在思考近期目标时,又难免会短视,局限于当下的认知,回避了更有意义同时也更具有挑战的事。而五年是一个刚刚好的时间跨度,因为时间跨度很长,所以我们会从长期价值考虑计划的意义,但五年又是一个很具体的时间,现在2019年,我过完生日就21岁。等到我25岁,那就是2023年。从现在开始数,也就是毕业之后工作3年的时候,已经很具体了对吧。
日常生活
身体健康真的很重要,有好的身体才能好好工作。
务必每天都要锻炼身体
什么项目不做硬性要求,本人接触的运动项目有:骑车、健身、乒乓球、跑步。
跑步是最方便的,乒乓球需要约人,健身和骑车都有点耗时间,所以如果没条件开展其他运动的话,就晚上去跑步,一般3km以上。当然如果有其他运动或者一天走了很长的路的话那就不用跑步了。
每周至少去一次健身房,这个要求有点低,但我经常一周也不去一次,或者一时兴起一周去几次。保证每周至少一次的话就不会因为太久没去反而更不想去了。
作息规律
已经习惯12点睡觉7点起了,继续保持下去。虽然说12点也不早,但因为住在学校宿舍所以一般都这个点睡,如果以后自己租房的话可以考虑提前一点(也不知道工作允不允许hhh
三餐要按时
学校食堂有时候特别难吃,但还是得按时去吃吧。一定要吃早餐。
护肤
我之前有很严重的痘痘,最近治疗好很多了,就剩几颗了,但还有痘印,后期在医生的指导下看看能不能改善一些吧。
恋爱
这5年里就不要主动勾搭了,除非遇到非常合适的。
心智成长
多读书
我还是有看闲书的习惯的,只是从来没有给自己提要求说一年要看多少本,一直都随缘。最近在看《深度工作》、《人类简史》。
那就每个月至少一本好了。
2019年
6月:《月亮与六便士》
7月:《深度工作》
8月:《人类简史》、《向死而生:我修的死亡学分》
9月:《未来简史》
降低对物质的欲望
衣着方面,每年打比赛都发一大堆衣服,所以我日常穿的基本上都是比赛发的T恤,然后上网随便买几条裤子。鞋子的话我很喜欢美津浓,穿得很舒服。
衣着打扮和发型很容易改变的,只要有钱。所以先不管。但是像皮肤还有身材这种是需要长时间努力才能保持的,所以现在要注意。当然不代表我以后不会改变,那是下个五年要做的事情。
电子产品方面,6s plus还够用,等拿了奖学金换个7还是8。苹果产品有一个优点就是几年前的产品还是很流畅,哈哈哈。我的macbook air还够用,等不能用了再换pro。
吃的方面,偶尔吃顿好的,大部分还是吃学校食堂。
职业生涯
成为一个优秀的后端开发工程师
算法
保持日常训练,争取拿银牌,大四也要继续打区域赛。常读《算法》和《算法导论》
操作系统
认真读《现代操作系统》和《深入理解计算机操作系统》
数据库
在实践中学习吧
计算机网络
谢希仁版《计算机网络》,《计算机网络:自顶向下方法》
编程语言
C++:《C++ primer》
golang:我还没想好,目前看来官网的教程就不错。
写在后面
这是一个可以调节的计划,我会根据实际情况调节。
执行情况记录
2019.8.24
- 开始北大的《操作系统》,第二周完成。
- 《C++ primer》还没开始看。
2019.8.28
面了360后端实习生岗位,计算机网络和操作系统没掌握好。算法题倒是还行。
凡普金科NLP算法实习岗已经收offer,竞赛退役了去实习体验一下。如果真的很喜欢搞算法可以准备考研。
一定要好好学计算机网络啊!
2019.9.21
应该是能拿到百度的后端实习offer了吧。
最近没有好好看书哦,唉,要加油呀!认真刷完《C++ primer》好不好。
2019.10.1
百度的offer几天前到啦!我10.9入职。讲道理这份工作充满了巧合,冥冥中一切都是最好的安排。我没有搞过什么项目,也没参加过开发,所以实习是一个很好的机会,能让我的代码基础发挥作用了。
好好工作吧!
最近学业上有点倦怠,是因为最近发生了不太方便在blog里说的一些事情,情绪有点波动。静下心来看看书刷刷题就好了,真的。
2019.10.16
经常回顾,经常反思。
最近迷上了骑车,跟pj学长买了一辆车,可以骑去郊区玩,体验极佳。一定要锻炼身体啊,没有病痛,身体状态好,那其他问题都不是事!
最近也看了几页《C++ primer》,虽然说看得不多,但我可以抽一段时间把一页书吃透,还时常回忆。估计玩着玩着大部头就看完了吧!加油!
---
layout: post
title: bistu acm训练记录
date: 2019-06-17 05:51:00 -0400
tags:
- 集训队相关
- 竞赛
- 程序人生
---
这篇文章整理记录了我们每一次的训练,有的在virtual judge开的virtual contest,有的在codeforces直接开的。virtual judge的可以直接看,codeforces上的需要联系我提供ID我发邀请。
关于
我们第一次尝试组织日常训练,然后最开始几场是我开的,后面是队友smc开的,然后因为有时候在华科的VJ有时候在北交的VJ又有时候在codeforces,所以可能有点乱。
19年寒假进阶训练赛
如果有密码的话密码就是bistuacm
第一场
https://vjudge.net/contest/280427
第二场
https://vjudge.net/contest/280739
第三场
https://vjudge.net/contest/281495
第四场
https://vjudge.net/contest/282349
开学后的日常训练
日常训练1
https://vjudge.net/contest/286142#rank
日常训练2
https://vjudge.net/contest/287756
日常训练3
https://vjudge.net/contest/289576
开学后的2019进阶训练赛
有一些榜上是空的是因为当时vj卡了我们就去另外一个学校搭建的vj打了
进阶训练1
https://vjudge.net/contest/291095#rank
进阶训练2
https://vjudge.net/contest/292312#overview
进阶训练3
这是用的BJTU的VJ,我不确定以后还能不能外网访问
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=309#overview
进阶训练4
https://vjudge.net/contest/295670#rank
进阶训练5
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=326#rank
进阶训练6
https://codeforces.com/contests/244103
进阶训练7
http://codeforces.com/contests/245661
新生训练赛
如果有密码的话密码就是bistuacm
新生赛第一场
https://vjudge.net/contest/280151
新生赛第二场
(这场跟日常训练是同一场)
https://vjudge.net/contest/287756
新生赛第三场
https://vjudge.net/contest/291487#overview
新生赛第四场
https://vjudge.net/contest/293430#overview
新生赛第五场
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=311#overview
新生赛第六场
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=316#rank
新生赛第七场
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=320#overview
新生赛第八场
http://citel.bjtu.edu.cn/vjudge/contest/view.action?cid=328#overview
新生赛第九场
https://vjudge.net/contest/305002
新生赛第十场
在codeforces上开的没有被邀请不能访问,如果需要的话联系我邀请
https://codeforces.com/contests/245824
作者联系方式
1078539713@qq.com
---
layout: post
title: 一篇杂文
date: 2019-06-09 13:31:53 -0400
tags:
- 杂文
- 生活
---
我偶尔会看看闲书,也会想一些东西,以前我在偶尔会在简书或者自己的日记写一些杂文,表达自己一些观点。但我想这个博客就主要以技术文章为主,杂文不会写太多。
大多都是废话,如果不是很无聊我建议您不要打开
关于本文
我偶尔会看看闲书,也会胡思乱想一些东西,以前我在偶尔会在简书写一些杂文,表达自己一些观点。但我想这个博客就主要以技术文章为主,所以杂文只写这一篇。
Q:为什么要写?
A:说到底还是因为杂念太多,只是想安静的在自己的角落里写点东西。
Q:写点什么?
A:随便写吧,写一些我想写的,大致也就是此时此刻我对这个世界的看法。
Q:什么时候开始?
A: 2019年6月9日。
自己是成功或者失败?
我觉得这个不好说,先往下看吧。
初中是在一个县城的二流中学,初一初二的成绩不怎么样,然后初三逆袭考了全校第二上了我们省的重点中学。我说这个倒不是想说自己厉害,你想啊,一个人如果对一件事引以为傲,那大概率是因为这件事之后他就没什么成就了吧。
嗯,然后虽然说高中我也有好好学习,但最后只上了个双非一本。但不可否认,高中三年是我人生中最幸福的三年。
上大学之后也马马虎虎,成绩也就是弱校的三等奖学金水平,也一般吧。做了比较有意义的事情就是参加程序设计竞赛,拿了一些不足挂齿的奖。正在努力向前。
体育方面,我小时候喜欢打篮球,但怎么打也打不好。后来上高中就不打了,改打乒乓球了,打得还行,但遇到基础扎实的对手是真的打不过。然后长跑也一般般,最近偶尔练,跑3km的话5分12秒一圈(前几天keep记的数据)。哦对了,有一个比较傲人的成绩就是我能做12个引体向上,我也不知道为什么,体育考试的时候班里大部分人只能做一两个的,所以相对来说这也算比较厉害的了,但跟健身达人比起来还是太菜了。
关于爱情,啊,万年单身狗,从高中到现在我喜欢的小姐姐都不喜欢我。
上面大概就是我这20年来为数不多的成就了,要是在看这篇文章的您是个很优秀的人,那我大约是失败的。但是对于一些人来说我也很厉害了(毕竟在学校还是有人称大佬的)。
所以嘛,我只能说自己不算成功也不算失败咯。这个评价其实没什么意义,成功如何,失败又如何,谁还不是一样,要面对当下的生活呢?
继续走就对了。
对心智的一些看法
我以前看过一些心理学的科普文章,说心智可以划分为两种,一种是成长型心智,还有一种是僵固性心智。感兴趣的可以去查一下专业术语,但在这里我要用我自己的话给大家解释这两个概念。
僵固性心智的人会相信人的某些能力是天生的,很多东西都是生来就有的,不是后天努力能改变的。简单说就是一个人很擅长做某事,那么僵固性心智的人会觉得是他天分好,而不是他足够努力。当自己做不好某件事情是,僵固型心智的人会觉得,我就是做不好,这事我做不来。
成长型心智的人相信人是可以成长的,以前做不好的事情不代表以后做不好,这类人更倾向于人的成就是可以通过后天努力来提升的。如果你跟他们说某个人某方面很强,那成长型心智的人大概会承认那个人有天赋,但也不会否认他的努力。
我觉得我属于成长型心智,因为我一直都相信我可以通过我的努力把事情做好的。
这也是我参加程序设计竞赛的原因。这项运动是非常有挑战性的,在程序设计竞赛的领域里,有的人高中就是世界冠军,也有的人打到大学才摸到一块奖牌。人跟人之间的差距很大,我自己本身的水平也不高,但正是因为我相信我可以通过努力提升自己的水平,所以我热爱算法竞赛。
这些年来的朋友
每个人最早交的朋友大概是小时候一块玩儿的发小,不过现在还来往的就只有一个了。然后还有小学时候的同学,现在偶尔回家还聚聚,不过生活都早已不同。初中的时候打球认识的一帮朋友,也很少联系了。
现在还会有联系的大概就只有几个高中同学了,前面说了高中三年是我人生最幸福的三年,其中一个原因是那个时候的朋友都很要好,友情很单纯。上大学之后我去过几次有高中同学的城市,都玩得特别开心。还有几个高中同学在北京,偶尔还会一起出去玩吃个饭什么的,也很开心。
上大学之后的朋友其实就很少了,不过还是有的,除了并肩作战的队友,还有几个能够说得来话的好朋友。
梦想
前面说了,小时候我喜欢打篮球,所以那个时候的梦想是当职业篮球运动员,想着也许可以打CBA什么的。不过后来慢慢就看清楚了,哪怕没有身高限制,自己的技术也太菜了。
后来呢,高中的时候,我喜欢计算机,我要成为一个IT精英,我要考北邮。
虽然说高考成绩里北邮差个十万八千里,但考的学校离北邮并不远,坐公交车半个小时就到了哈哈哈。好歹也是学了计算机了。为了学计算机直接报了比自己分低20分的北京信息科技大学了。
额,学了计算机专业之后,我要干啥呢?其实我也不知道,然后就一直参加ACM-ICPC(国际大学生程序设计竞赛)了。第一年没有拿奖牌,所以目标是要拿奖牌。5月份的时候我跟队友在一场比赛中拿了铜牌,也算是一个里程碑了。
近期打算是今年努力争取拿银牌及以上,明年着手准备考研。
update:决定不考研了,要成为一个后端工程师。2019.8.12
一定要开心
前面说了很多,关于成功与失败,关于心智,关于朋友,关于梦想。但我觉得,这一切的基础都是,我是开心快乐的。
成功与否我已经不想评价,因为成功与失败要看跟谁比。但我要是不开心,那么这一切的一切都没有意义。
我想说的开心,不是指享乐,而是指自己意愿上的开心。
举个简单例子,比如说一个人要减肥,那他要锻炼身体,要节食。这些都是苦,但做了这些也许他就能达到他的目标,所以说虽然他受了苦,但他也是开心的。
其他事情也一样,为了提高自己的知识水平,我就得去学习和练习,这个过程是很痛苦的,但我可以看见自己在一点一点的进步,虽然会有痛苦,有挫折,但因为我按照我自己的意愿来行动,所以我还是很开心。
所以,我说的开心,是指一定要忠于自己的意愿。
最后以一句经典台词结尾。
做人,最重要的就是开心。
---
layout: post
title: linux笔记
date: 2019-04-10 18:24:40 -0400
tags:
- 技术笔记
- linux
---
本文为某天晚上阅读《鸟哥的Linux私房菜》第11章时著,读者可以自行�查阅原版书籍。
题外话:markdown的换行必须在前一行的末尾�加两个空格
本文为晚上阅读《鸟哥的Linux私房菜》第11章时著,读者可以自行�查阅原版书籍。
shell和shell script
变量
- 双引号包住的符号可以保持原来的特性
- 比如“var=”lang is $LANG””
可以得到 lang is zh_CN.UTF-8
- 用�斜单引号把命令括起来然后赋值给变量,变量的值是�单引号里的命令的返回结果
比如var=pwd,那var的值就是执行pwd的结果,也就是当前路径。
- �子进程只会集成父进程的环境变量,而不会继承父进程的自定义变量。
- 但是可以用“export 变量名”的方式把自定义变量变成环境变量,这样子进程就能使用该变量了。
- 自定义变量 = 局部变量; 环境变量 = 全局变量
- declare [-aixr] variable
-a 把变量设置�成数组
-i 把变量设置成整型
-x 把�变量设置成环境变量
-r 把�变量设置成只读变量
read
read [-pt] 变量名
-p “提示内容”
-t [限定时间]
比如
read -p "please input your name" -t 30 name
在屏幕上打出“”please input your name””提示用户在30秒内输入名字(如果30秒内没有输入,将结束进程,不再等待)
declare和typeset
执行
会发现输出的是“1+2+3”而不是6,因为这个变量类型是文字
执行
declare -i sum=1+2+3
echo $sum
就会输出6,�因为这里的sum是整型的
�注:linux中的运算最多仅能达到整型,1/3=0
数组类型
�var[index]=content
var[0]=small
var[1]=middle
var[2]=big
echo "${var[0]}, ${var[1]}, ${var[2]}"
输出:small, middle, big
一般来说,建议以${}的�形式读取数组更精准无误
ulimit
ulimit [-SHacdfltu]
-a, 列出目前身份的所有�限制数据数值
-f [配额] 设置此shell可以创建的最大�文件容量
变量内容的删除、替代与替换
这里涉及到了通配符的知识,可以跳到本篇笔记的后面去看。
${变量#�关键字} #若变量从头开始的数据符合“关键字”,则将符合的最短数据删除
${变量##�关键字} #若变量从头开始的数据符合“关键字”,则将符合的最长数据删除
${变量#%关键字} #若变量从尾向前的数据符合“关键字”,则将符合的最短数据删除
${变量#�%%关键字} #若变量从尾向前的数据符合“关键字”,则将符合的最长数据删除
例子(书上的例子不是太好懂,我�重新举了例子)
#和##的例子 �
bash-3.2$ a=12345678:1234:abcde: #给a赋这么一大串值
bash-3.2$ echo ${a#1*3} #删除满足从头开始满足1*3的内容,删最短的。其实也就是开头的123,所以输出结果如下
45678:1234:abcde:
bash-3.2$ echo ${a##1*3} #删除满足从头开始满足1*3的内容,删最长的。跟上面不同的是,这里要删的从1开始,一直找到了'12345678'这个�串中的‘3’所以就把12345678:123全删除了。结果如下
4:abcde:
%和%%的例子
bash-3.2$ a=12345678:45678:
bash-3.2$ echo ${a%6*8:} # 从后往前匹配到‘6*8:’就删了
12345678:45
bash-3.2$ echo ${a%%6*8:} #也是从后往前匹配'6*8:'但明显从'12345678'中的'6'匹配到最末尾的'8:'是最长的,所以最后只剩下前缀12345了
12345
(这一节感觉不太好懂,我第二遍才看懂的,不过弄懂了很开心hhh)
命令别名设置:alias, unalias
alias 别名=原始命令
之后执行l的效果就等同于ls -a
history会列出bash执行过的所有命令
参数
n 列出最近n条命令
-c 把�所有history的内容全部删除
-a 将目前�新增的history命令�加入histfiles中,如果不存在的话就写入~/.bash_history
Bash shell的操作环境
路径与命令查找顺序
当我们执行某个命令时,命令运行的顺序如下
- 以相对或者绝对路径执行命令
- 由alias找到该命令执行
- 由bash内置的buitin�命令执行
- 通过$PATH这个变量的顺序找到第一个命令来执行
bash的环境配置文件
login shell
(还是没看懂)
通配符与特殊符号
* 0到无穷个任意字符
? �一定有一个任意字符
[] 一定有一个中括号里的任意字符
[-] 编码顺序内的所有字符,比如[1-9],表示一定有1~9
[^abc] 表示只要�一个字符不是abc中的任意一个就OK
数据重定向
标准输出重定向
注:1>等价于>
1»等价于»
因为>和»的默认代码是1
这样所执行命令的�正确输出就会写入到给定的文件中。
注意:>的左右没有空格
如果执行>,那么文件会被重写,但如果是»,正确输出就会追加到�给定文件中
错误��输出重定向
以覆盖的形式将错误数据写入到给定文件中
注:这里2>是固定不变的命令,命令和文件名可以是任意的
�
正确输入重定向
PS: 明天再写 2019.4.10
---
layout: post
title: 大二学习计划
date: 2019-04-08 18:58:36 -0400
tags:
- 学习计划
- 大学
---
只是一份简单的计划啦,加油!
�算法竞赛
- 认真看完《算法竞赛进阶指南》。
- 专题学习
- 日常刷codeforces。
- 务必要补题。
计算机网络
- 上课认真听讲。
- 认真看一遍谢希仁版的教材。
- 刷一点考研题。
计算机组成原理
- 上课认真听讲。
- 作业好好做。
- �ppt看懂是最基础的要求。
- 哈工大的教材和本校教材都要好好读。
- 刷考研的题。
算法设计与分析
- 虽然说不想看本校教材,但还是看一点吧。
- 在算法导论上找对应的内容看。
- 一定要代码实现书上的算法。
数据库原理
- 在自己的机器上实践一下。
- 基本上照着打就能学很多了。
- 多尝试一些组合命令。
linux
- 根据书上的内容,对应到鸟哥的Linux私房菜仔细研读。
- �实践出真知。
- 学校的要求太简单了,要往难了学。
结果
- 《算法竞赛进阶指南》看了一点,学了线段树,对最近的竞赛确实有帮助。
- 计算机网络考得不好啊,看了谢希仁的教材但后面没认真看,考研题没刷。
- 计组的后面考试前才搞懂的,也没有认真读哈工大的教材。
- 算法:书上代码都能实现,然而算法导论看都没看。
- 数据库,emmm还行吧。
- linux,看了《鸟哥的linux私房菜》
总的来说完成度不是很高,还需要继续努力。
---
layout: post
title: 20
date: 2018-11-18 16:33:00 -0500
tags:
- 生日专题
- 生活
---
应该是从去年开始的惯例吧,生日了要写点东西,不过今年似乎没有去年刚上大学时候那么多感悟了。
应该是从去年开始的惯例吧,生日了要写点东西,不过今年似乎没有去年刚上大学时候那么多感悟了。
19→20
- 打校内比赛拿了一等奖,以为奖金很快会发就白条买了ipad,结果奖金到现在还没发,吃了三个月的土。
- 进了集训队,代表学校跟国内高校同场竞技啦。打了两场ACM区域赛,战绩很弱啊,都是签到滚粗,不过我会继续练的,保持训练量,备战下个赛季。
- 进校队以后堂哥赞助了个cherry入门级别的机械键盘,就是现在打字的这个,用得很爽,它应该能陪伴我很多年吧。
- 去看了五月天的演唱会,喜欢他们很多年了,也算圆了一直以来的愿望。
- 去了秦皇岛、西安还有武汉,对于上大学之前就没离开过小岛的我来说去别的城市还是挺好玩的。北京和海南的生活节奏是忙碌和悠闲的两个极端,去了别的城市,才知道这两个极端之间有很多中间态。
- 去年的我觉得奖学金应该跟我没有半毛钱关系吧,没想到还水了个三等。
学习
似乎除了学了一点算法和校内的课程以外没有学别的东西了。唔。。。该反思
朋友
上大学之后我的交际圈变得很小很小,不过我很开心啦,虽然就几个朋友但是都玩得挺好的。圈子好单纯呀,跟小伙伴们走路的时候都在讨论算法,平时会喊队友去打网络赛啊,画风就跟组团开黑似的。平时吃饭也是离不开这方面的谈论。大概大学最好的朋友也就是大一时候认识的那几个吧。
还有最珍贵的是跟高中时候要好的朋友还保持着联系。
just do it
我之前总爱说,我希望能xxx怎么样,但是现在的感悟是,如果不落实到实际行动的话,再多的希望也是没用的。
再也不那么患得患失了,每个人的条件都不同,我只需要把握好现在,做好现在该做的事就好了,不需要担心太多,最后的结果不管怎么样,都已经是从开始努力那一刻到结束那一刻这个过程中做出的最大改变了,不需要再埋怨自己了。
希望要有,但也千万别停下行动的脚步:就比如说我要走路去一个地方,我今天要做的只是走出今天能走出的最大距离,明天也是,如此往复就够了,而不是停下来说:“好希望我能走到啊。”就算到了某个时刻还是没有达到自己的目标,但在这个过程中我每天都走出了最大的距离,也无怨无悔了,而且在那个时刻,我还是可以继续往前走呀。
不能像高中那样毒舌了啊
高中的时候跟小伙伴们最有意思的就是互黑,还有在某个人装逼的时候当场打脸,当然这并不影响我们的关系,跟当年那些互黑的人现在还保持联系,被我黑得最惨的人是我最好的朋友。
不过还是要收敛啦,不能像高中时候那样任性了。有些事情就看透不说透吧,哪怕真的是事实,说出来也让人难堪。除了那些真正的好朋友以外,还是不要指出人家的毛病了吧。虽然出发点是善意的但是别人不一定乐意听啊。所以我现在觉得,如果有人能够指出我哪一点不足,真是感激不尽了,因为如果我的缺点没有涉及到他人利益的话,人家完全可以不指出来,让我接着错的。
诗和远方
去年在纠结是要考研还是工作呢,今年很明确了,直接工作。好好备战区域赛,大三去实习吧。是啊,然后又需要明年的我来给现在的我一个答复了呢!
“区域赛有没有打好啊?有没有找到好的实习呀?”
“我会努力让你能回答好这个问题的!”
---
layout: post
title: 一个菜鸡Acmer的反思和记录
date: 2018-11-16 19:00:00 -0500
tags:
- 程序人生
- 集训队相关
- 竞赛
- 自我成长
---
2018-11-17-一个菜鸡Acmer的反思和记录
昨天打完codeforces之后在QQ空间发了很长的傻逼错误检讨,我觉得我需要在博客上记录一下。前面是傻逼错误集锦,看不懂可以跳过,后面才是感想。
- 数组开小了,习惯性数1后面有多少个0开了1e6,但没注意看人家的数据范围是2 000 000
- 其他变量用了long long却在for里写了个int i 这两道题当时的算法都是想出来正解的,当时返回TLE就很懵逼,明明算法规模不超时,我还没遇到卡常的问题,怀疑是不是第一次遇到了呢。至于为什么数组越界也返回tle而不是run time error呢就不比深究了。刚刚试了一下好像全局数组开小了就直接RE了,要不以后还是全局吧(啊呸当然要仔细读题)。
- 还有傍晚的牛客出现了用string数组存字符矩阵的的时候跑dfs求联通块直接卡死的问题,也不知道是为什么,问了pby用两层vector<vector>才过的,还有这几天不记得哪道题出现cin超时scanf或者关同步才过的情况了。啊对了还发现了push结构体的构造函数tle但把一个结构体变量声明好之后再push就能过的情况,也不知道是为什么。总之这些都是之前没有遇到的问题。
最近的训练量加大了,这周好像打4场比赛了呢,也慢慢发现了许多问题。不能说越练越菜吧,我也不想活在自我否定的挫败感中,毕竟不练也发现不了问题,发现问题然后纠正还是会有进步的。
算法竞赛有没有出路不知道,但真的很爽啊,真的热爱就够了吧。毕竟在这个学校里以打比赛刷题为乐的人太少了,以至于集训队人很少。能够凑到几个平时一起训练的人也是很可贵了。从学校的采集样本来看能够喜欢这种东西确实是小概率事件,既然喜欢就继续做呗。
再也不想说希望以后能够达到怎么样的高度这种话,希望是希望不来的,只有去做才可以。
---
layout: post
title: 2018书单
date: 2018-05-02 20:00:00 -0400
tags:
- 读书笔记
- 书单
---
2018-05-03-2018书单
转眼间18年就要过一半了,写一下书单,纯粹记录用
闲书
- 《人间失格》
- 《目送》
- 《第五项修炼》
- 《晨间日记的奇迹》
- 《哲学起步》
- 《少年pi的奇幻漂流》
- 《男人来自金星,女人来自火星》
- 《拆掉思维的墙》
- 《孤独深处》
专业书
1.《C++ primer plus》ing2.《深入理解计算机系统》ing3.《算法竞赛入门经典》ing4.《python程序设计基础》ing
总结
还是看的闲书太多,专业书太少。这篇文章2018.5.3编写,到年底看看有没有什么进步吧。
---
layout: post
title: 辩论赛
date: 2018-02-27 19:00:00 -0500
tags:
- 生活
- 辩论
---
2018-02-28-辩论赛
看了一场绝佳的辩论赛。2003年中山大学对阵世新大学。马薇薇VS黄执中
其实某个命题既然被选成了辩题,那么这个命题就不会有绝对正确或者错误。就是在某种情况下正方是对的,另一种情况下反方是对的。
所以辩题到底正不正确是不重要的,我觉得比赛的意义在于选手如何在短时间内想出来如何辩论,如何对答如流。
至于辩论场下的命题,前辈讲得很清楚了,具体问题具体分析。哪怕是科学的定理,也是在一定的适用范围内才是正确的,这点高中物理也说得很清楚。
有时候我们也会自己跟自己辩论,某个时刻顽固地相信一些东西。但可能过了一段时间,观点又会变得不同,又说服了自己服从了对立的观点。用一个词来表示就是——纠结,或者改变。
曾经我哭闹,心里想,为什么父母这么狠心,任我哭闹都不理我。直到有一天我哄着3岁的外甥,面对他哭闹着提出的没办法满足的要求,我也只能任其哭闹。当然,他哭了一会儿就好了。第二天还是会找我玩。我也渐渐地理解,小时候我也很无理取闹,父母也是没有办法才任我哭闹的。
去年刚上大学的时候进了一个技术社团,那里大部分学长都选择了就业这条路,而且薪水也很可观,我就想着,本科毕业就直接工作好了。今年去了另一个实验室,实验室有一位保研的学姐,带我去实验室的那位学长一心专注科研,其他学长也都是打算读研。我就感觉,似乎读研对人生的影响更大一些,视野会更宽广一些。然后,我最近缺钱了,家里也有点事需要钱。我又想着,不如工作吧?
未来的两条路只是一个缩影,在其他方面也是,只要那个未来还没有来,对未来的思考就一直在变。
不知道其他人,反正我是这样子。
所以,我的选择是好好地专注当下,可以看书,敲代码,刷算法题,去锻炼身体,去社交。今天过得很开心,就足够了。
并不是说完全不思考未来,而是说,时间是一直在走,从来不会停,当下去行动起来,做一些有意义的事情,那么这段时间就比对未来的空想更有意义一点。
这篇自言自语的文章,看起来是在说服别人,其实是在自己告诫自己罢了。
认真过好现在,未来自然会很美好。
---
layout: post
title: 你好,acm集训队
date: 2018-01-03 19:00:00 -0500
tags:
- 程序人生
- 集训队相关
- 竞赛
---
入坑前后
18年刚开始,好开心。C语言考试半小时满分走人。然后刚刚考研结束的xwd学长有空带我来ACM实验室,跟队员混了个脸熟,我好喜欢这里的环境,就决定要入队了,xwd学长跟队长沟通一下我就进队了。今天实验室负责人帮我录了实验室的指纹。我就是ACM集训队的一员了。我以后可以随时来这里啦,还能把书和电脑放在这里,今天学姐还问我要不要加个显示器,真的太好了。一直都梦寐以求能有个办公的地方,本来以为应该到大二成为iflab实验室的导师的时候才会有自己的工位。幸福来得太突然。对于一个要当程序员的少年来说,能有这么好的工作学习环境真的太幸福了。
上大学以来有两次感叹这才是我想要的大学生活,第一次是在iflab社团实验室,第二次是在ACM实验室。在iflab实验室看到学长在忙着敲代码,来这里看到学长们桌子上如高三一样的专业书。我一点都不怀疑这就是我一直以来想要的生活。
来到一个不怎么样的大学,但是学了自己喜欢的专业,还是可以努力变成自己喜欢的样子的。一点也不后悔当时考得那么烂还非得为了学计算机报比自己低20分的学校。
刚好我从小就喜欢,刚好最近几年很火。一切都是那么自然。
我还是挺愿意成为一名ACMer的,高中的时候学校没有信息学竞赛队伍,我自己一个人报名参赛,那个时候没有人培训,一个人在机房跟算法死磕,始终不得要领。当然也不全是环境的原因,也跟个人的努力程度和天赋有关。但现在我有了这么好的环境,我就应该去拼一下,我知道那些登上顶端的人都是天赋异禀,但我还是不愿意相信天赋。因为不管做什么事情,一旦相信了天赋,那么你不但不能超越那些天赋异禀的人,甚至连努力的普通人你都没办法超越了。
再者,有一种说法不知道是否正确:算法是程序员的基本功,算法功底决定了一个程序员能去什么样的公司。上面的说法我没有去验证过,不确定真伪。不管怎么样,挑战一下算法竞赛,对于思维的提升和日后编写程序的都会产生积极地影响。
更切实际的,自从迷上了算法,写线代和高数头也不疼了。C语言考试对于竞赛选手哪怕是我这种渣渣来说也是很容易就秒杀的。
总之,我要继续努力翻过高中的时候没翻过的山,看那个时候想看的风景,继续脚踏实地地走到更远的地方。
共勉。
2018.1.4。
---
layout: post
title: 你好,acm集训队
date: 2018-01-03 19:00:00 -0500
tags:
- 程序人生
- 集训队相关
- 竞赛
---
2018-01-04-你好,acm集训队
18年刚开始,好开心。C语言考试半小时满分走人。然后刚刚考研结束的xwd学长有空带我来ACM实验室,跟队员混了个脸熟,我好喜欢这里的环境,就决定要入队了,xwd学长跟队长沟通一下我就进队了。今天实验室负责人帮我录了实验室的指纹。我就是ACM集训队的一员了。我以后可以随时来这里啦,还能把书和电脑放在这里,今天学姐还问我要不要加个显示器,真的太好了。一直都梦寐以求能有个办公的地方,本来以为应该到大二成为iflab实验室的导师的时候才会有自己的工位。幸福来得太突然。对于一个要当程序员的少年来说,能有这么好的工作学习环境真的太幸福了。
上大学以来有两次感叹这才是我想要的大学生活,第一次是在iflab社团实验室,第二次是在ACM实验室。在iflab实验室看到学长在忙着敲代码,来这里看到学长们桌子上如高三一样的专业书。我一点都不怀疑这就是我一直以来想要的生活。
来到一个不怎么样的大学,但是学了自己喜欢的专业,还是可以努力变成自己喜欢的样子的。一点也不后悔当时考得那么烂还非得为了学计算机报比自己低20分的学校。
刚好我从小就喜欢,刚好最近几年很火。一切都是那么自然。
我还是挺愿意成为一名ACMer的,高中的时候学校没有信息学竞赛队伍,我自己一个人报名参赛,那个时候没有人培训,一个人在机房跟算法死磕,始终不得要领。当然也不全是环境的原因,也跟个人的努力程度和天赋有关。但现在我有了这么好的环境,我就应该去拼一下,我知道那些登上顶端的人都是天赋异禀,但我还是不愿意相信天赋。因为不管做什么事情,一旦相信了天赋,那么你不但不能超越那些天赋异禀的人,甚至连努力的普通人你都没办法超越了。
再者,有一种说法不知道是否正确:算法是程序员的基本功,算法功底决定了一个程序员能去什么样的公司。上面的说法我没有去验证过,不确定真伪。不管怎么样,挑战一下算法竞赛,对于思维的提升和日后编写程序的都会产生积极地影响。
更切实际的,自从迷上了算法,写线代和高数头也不疼了。C语言考试对于竞赛选手哪怕是我这种渣渣来说也是很容易就秒杀的。
总之,我要继续努力翻过高中的时候没翻过的山,看那个时候想看的风景,继续脚踏实地地走到更远的地方。
共勉。2018.1.4。
---
layout: post
title: 顽固
date: 2018-01-02 19:00:00 -0500
tags:
- 生活
- 自我成长
---
2018-01-03-顽固
MV主角是梁家辉演的一个大叔,大叔在超市买便当。一个穿着宇航服的人递给他一本《明日科学 火箭篇》,于是回家筹备造一艘火箭。
|  |
图片发自简书App
|  |
图片发自简书App
在这期间那个穿着宇航服的人一直陪伴着他。他在公司扫地被boss嫌弃,在工地干活被包工头斥骂,在路边小吃摊打杂。火箭被小混混砸坏,纵使生活有很多不容易,他和那个穿着宇航服的人还在依然坚持着。
|  |
图片发自简书App
|  |
图片发自简书App
|  |
图片发自简书App
终于,火箭升空了。这时那个穿着宇航服的人摘下了头盔,原来那个人就是小时候的大叔,小时候的自己陪伴着大叔一步一步把儿时的梦想完成。
|  |
图片发自简书App
|  |
图片发自简书App
与此同时,boss看见了穿着棒球服的自己,摆摊的大妈看到了当环球小姐的自己,超市小妹看到背着滑翔翼的自己,包工头看到了穿舞服的自己。
我也看见了,那个在读《乔布斯传》的初中生。
|  |
图片发自简书App
|  |
图片发自简书App
|  |
图片发自简书App
|  |
图片发自简书App
故事还没完,火箭最后坠毁了。大叔看着满地的碎片哭,这时小时候的大叔笑着走过来,送上一本杂志——《明日科学 太空站篇》
end
“我身在当时你幻想的未来里”
现状不那么好,但也没那么坏。
虽然很菜但从没停止过追求进步。
虽然跟设想的路线有点偏差,但还是朝着原来的方向走着。
继续,踏踏实实地去把学习路线完成。
---
layout: post
title: 我安静了,这个世界就不会太吵
date: 2017-12-15 19:00:00 -0500
tags:
- 生活
- 自我成长
---
2017-12-16-我安静了,这个世界就不会太吵
好久没发简书了,发篇小短文刷一发存在感吧
这个观点有点唯心主义,不过确实是这样的。
我有个不好习惯,就是有手机在就很容易分心。
所以每次去上自习我都会刻意地把手机放在别的地方,宿舍,或者图书馆外边的柜子里。还有有时候出去玩,手机没电了。我总以为隔离手机一段时间就会错过很多消息。但每次我满怀期待地打开手机的时候,发现除了软件推送以外,并没有什么消息。
为什么这样?我这么长时间不看手机,消息应该累积很多才对。
但本来就应该这样的。我不刷朋友圈、空间和微博,不去评论,也不发表,自然就不会有什么消息。我不去看群,不参与讨论,当然也不会有消息。有人问我问题,找我聊天,没得到回应,自然就去其他地方寻求帮助了,或者找别人聊天去了,不会产生太多消息。
有时候就该静下来,看看书,写写代码,专心做自己的事情,等我再回到网络,发现没有我的声音,这个世界还是很正常地运行着。
我安静地时候,这个世界吵不到我,我也不吵这个世界。
---
layout: post
title: 19
date: 2017-11-28 08:32:00 -0500
tags:
- 生日专题
- 生活
---
这是2017年过19岁生日写的(我过农历生日,所以每年的公历时间都不一样)
19岁生日,大一,在北京。
为什么想写这篇日志,大概是因为受傅园慧的影响吧,她过20岁生日的时候发了一条长微博,于是我也想写一下。
这一年经历得挺多的,18岁生日是高三,没过。上大学了手头很紧,朋友不多,也不想过了。其实没什么过不过的,时间是不会停的,只不过就是生日那天不开party罢了。
#序
19岁生日,大一,在北京。
为什么想写这篇日志,大概是因为受傅园慧的影响吧,她过20岁生日的时候发了一条长微博,于是我也想写一下。
这一年经历得挺多的,18岁生日是高三,没过。上大学了手头很紧,朋友不多,也不想过了。其实没什么过不过的,时间是不会停的,只不过就是生日那天不开party罢了。
没有在社交网络上说自己生日,就默默地发在这里吧。
#在自己喜欢的路上奔跑
高考发挥失常,但还是固执地第一志愿就选比自己低20分的学校,为了能选到计算机专业。最终还是如愿以偿了。虽然学校不怎么样,但是城市和专业都满足了我的要求,就算是发挥失常之后选的最优解了。
上大学之后,看了高中同学的生活,我还是觉得我没有选错,在学自己喜欢的的东西,做自己喜欢的事情,多好啊。
当然,并没有说选了计算机,就很轻松了,还是有很多东西要去学,高中业余学的C语言也就只能用来应付大一的考试而已。而且,不断学习是程序员的宿命,所以当然得好好学习啦。
不管怎样,我都在自己喜欢的路上奔跑了,对于未来还是充满期待的呢。那些计算机行业的经典书籍,当然要去读啦,还有前沿的技术,也要去学。很多东西都是从不懂弄到懂再到熟练的,认真的去反思,去砸时间,我相信我可以做得好的。
#大学
不知道其他专业,反正就计算机来说,这个学校还是很好的。目前遇到的老师都很好,有很多厉害的学长可以请教,还有时间去自学一些东西,我觉得,不够优秀只能是自己的问题,大学本来就是一分钱一分货,自己选择的,没什么好抱怨的。有时间抱怨还不如去学习呢。而且计算机专业主要靠自学。
#朋友
大学的生活真的不像高中那样一个班都是好朋友,现在微信朋友圈的互动主要还是高中同学。当然,开学这么久了,还是有一些志同道合的朋友啦。未来的日子,请多多指教。
#想要的礼物
开学的时候咬牙买了kindle,空闲时间可以读书又方便携带真是太爽了。所以我还想再买几台用得很爽的设备。
这是要自己攒钱买的,ipad,macbook pro
#诗和远方
要考研呢还是工作呢,我怎么知道呢,以后再决定吧,就现在来说,这个并不重要。因为这两条路并不是完全冲突的,如果能力足够强,本科毕业就能去不错的岗位,那岂不是很好,再者说现在要把基础打牢,还不细分方向。要是学习能力很强,奋战一年考个北邮也不是问题啊。总之,那不是现在要考虑的问题,我要做的只是让自己变得更强大,希望明年生日会给自己一个答复吧。
---
layout: post
title: 哲学起步 邓晓芒 讲座记录
date: 2017-11-23 19:00:00 -0500
tags:
- 读书笔记
- 哲学
---
2017-11-24-哲学起步 邓晓芒 讲座记录
前言
高中的时候读过邓晓芒的《纯粹理性批判讲演录》,碍于才疏学浅,当时实在是看不懂,不过还是觉得哲学是个有趣的东西。偶然知道邓教授要来北京开讲座,于是11月23号下午就去参加了北大的那场讲座。讲座还没开始就已经爆满,台阶上加了很多凳子,还有很多人站着听。我坐在过道一个狭小的角落,一边听一遍做笔记。讲座很通俗易懂,我收获颇丰。
讲座的来由
本来是邓教授给华中科技大学的学生讲的哲学导论课,教授说,这门课的最大特点就是通俗易懂,哲学是人学,哲学不是学出来的,而是活出来的。教授以高更的三个问题为引子,带我们慢慢地走入哲学之门。这三个问题分别是:
我们从哪里来?我们是谁?我们要到哪里去?
我们从哪里来?(人类起源)
这个得从人类的起源开始说起,也就是人猿之别。人的本质是什么?哲学家们对人类的定义是:人是可以制造和使用工具的动物。但是后来人们发现,非洲大陆的黑猩猩会将树枝伸进白蚁的巢里,等到很多白蚁爬到树枝上的时候,就把树枝拿起来,吃掉上面的白蚁。之后人们还发现了,乌鸦等其他动物也是会使用工具的,所以,上面的理论就站不住脚了,人们开始重新思考人的本质。于是又有人提出:人类是可以用工具造出另外一种工具的动物。
但邓教授觉得这个太绕了,结合自己的研究,提出了新的观点:人类是制造、使用和携带工具的动物,为什么加上了一个携带呢?因为黑猩猩用完一根树枝,它就扔了,但是人不会。因为人类使用的工具制造过程非常地不容易,一个石器的打磨往往需要几个月甚至几年的时间。所以人类带着工具,从而工具就成了身体的一部分。这就有了一种物为人所用的感觉,人类对大自然产生亲切感和征服感。
而且,邓教授还提出了推测,由于要携带工具,所以手就被占用了,导致了人类开始直立行走。关于人类直立行走,还有别的解释,是说人类直立行走是为了发现天敌。但是邓教授对此观点提出了反驳,有些动物为了防范天敌,会设置类似哨兵的角色,并不需要直立。
直立行走导致了爬树能力的退化,和奔跑速度的下降,但是随着工具的出现,也会对这些退化的功能有所弥补。爬树是为了躲避天敌,但是人类有了棍棒也能抵御天敌。跑得慢了对捕食猎物有影响,但是人类可以造出标枪来捕食猎物。目前仍然有一些少数民族的人们习惯带刀出行,因为带着刀就不会害怕猛兽,心中会有一种安全感。
卡希尔说,人是制造和使用符号的动物。其中符号包括了工具和语言,动物虽然也有语言,但人和动物也有很多区别。动物的语言是简单的,主要的作用是用于求爱,只有元音没有辅音。而人的语言是复杂的,并带有命题的,所谓命题就是A是B这样的陈述句,给实物命名了,就可以在实物不在眼前的时候也能说,就比如说你没有看见苹果,但你知道苹果是一种水果,你可以说你想要吃苹果。但是苹果并不在你眼前。而动物就不一样,动物不会给事物命名,所以它们看见东西会叫,但是叫声都一样,只是一种信号。
J·皮亚杰的《发生认识论》里研究了婴儿是如何学会说话的,首先,通过感知的内化,形成了语言模式,逐渐开始认识世界,语言模式开始外化出语言,创造句子。
语言其实是在人类历史发展到很晚才产生的,人类在地球上生存了200万年,但是语言的产生只是在50万年前。人们有了语言之后,就可以记录,交谈,于是就有了历史,人类是有历史的,而动物的历史,是人给的。所谓历史,就是能讲述的故事,但又有两个条件:由文字记载的,能够上书的。才能称为历史。
在原始部落,人们可以用肢体语言,或者其他方式传达信息,但是最方便的还是用声音来传达,经过漫长的训练和进化,人类产生了语言。原始的语言是缺少共象,缺少概念的,他们的命名都是专名,例如说牛,他们会说奔跑的牛,凶猛的牛,每一个牛都有一种叫法,但不会有牛这个统称的概念。原始部落的语言非常丰富,超出我们的想象。但是它缺乏共象。有的原始部落甚至“我”都不会说,只是每个人起一个名字,不分你我他。就像小孩子一样,一般小孩子3岁以前都不会说“我”。当一个小孩子会说“我”字的时候,他的内心就升起一道智慧的光芒,因为“我”字不是那么容易说的,你要意识到这个“我”字是代表我个人,同时,别人也可以用,你不能阻止别人用,但是“我”和“我”是不一样的。小孩子会用自己的名字来代表自己,例如我两岁半的外甥就会说,“仔仔要吃糖”,“舅舅带仔仔去玩”。
我们是谁?(自我意识)
(由于前一个内容讲了太长时间所以后面稍微有所精简)自我意识的本质结构,在康德那里是个迷,但是黑格尔说:对象和自我既对立又统一。一个对象在我面前,它是它,我是我,我们既不同,又相同。
自我意识有两个方面,一个方面是把自己当对象看,也就是通过别人的眼光来看自己。另一个方面是把对象当自己看,也就是所谓的将心比心,换位思考。
自我意识是无法被完全认识的,人的内心是个无底洞,但正因为这样,人就可以不断地认识自己,不断地认识自己,就会爆发出创造力。
我们要到哪里去?(追求自由)
自由只是一种幻想,本质是不自由的。人具有意志力和超感性,在原始人那主要体现为,迁徙需要带上厚重的工具,种子和鱼饵是不能吃的。但是这种意志力和超感性,其实是带有理想和功利性的。
劳动分为两种,精神劳动和物质劳动,在古代,从事精神劳动的主要是奴隶主,因为他们闲着没事干,所以仰望星空,这也可以解释为什么早期的哲学家基本都是大富大贵之人。正因为有了这些人的思考,才有了人类的精神文明。早期从事精神劳动的人闲着没事干,并不是说哲学是无用的,一个哲学的学生找不到工作,你想,什么样的工作需要哲学?但同时他又什么都能做。法律的知识他能讲,经济学的知识他也能讲,哲学家们要是想赚起钱来是非常容易的。
真正的自由是人类超越自然和感性的设想,人的自由是合乎道德的。
问答
问:阶级分化是怎样形成的?答:阶级分化是因为人的生产资料有所剩余,就需要分配,但是部落主的分配是不公的,会给自己的家族多一点。于是就产生了家庭个体化,然后人的资产也有所分化。一个人或者家族的生产资料有所剩余,他就可以拿这些剩余的资料来供养奴隶,最后就形成了奴隶主和奴隶的关系。但是在早起奴隶主和奴隶的关系是非常和睦的,奴隶主养着奴隶,感激奴隶主的不杀之恩。他们之间的关系是到后面才发展恶化的。
感悟和反思
- 上次听了安卓技术大会之后就意识到听讲座得做笔记,这次做到了,但是笔记记得实在潦草,过后看起来很懵逼。听讲座得时的笔记写的特别工整,虽说都是把本子垫在大腿上写字,但人家写的就工整多了。
- 理工科知识解决你的吃饭问题,人文社科知识解决你的灵魂问题。不过兴趣广泛是好事,但还是要努力把自己的专业学好。
---
layout: post
title: 为什么你应该(从现在开始就)写博客
date: 2017-10-08 10:21:40 -0400
tags:
- 为什么写博客
- 写作
---
用一句话来说就是,写一个博客有很多好处,却没有任何明显的坏处。(阿灵顿的情况属于例外,而非常态,就像不能拿抽烟活到一百岁的英国老太太的个例来反驳抽烟对健康的极大损伤一样)
为什么你应该(从现在开始就)写博客
(一)为什么你应该(从现在开始就)写博客
**
用一句话来说就是,写一个博客有很多好处,却没有任何明显的坏处。(阿灵顿的情况属于例外,而非常态,就像不能拿抽烟活到一百岁的英国老太太的个例来反驳抽烟对健康的极大损伤一样) 让我说得更明确一点:用博客的形式来记录下你有价值的思考,会带来很多好处,却没有任何明显的坏处。Note:碎碎念不算思考、心情琐记不算思考、唠唠叨叨也不算思考、没话找话也不算思考,请以此类推。
下面是我个人认为写一个长期的价值博客的最大的几点好处:
1) 能够交到很多志同道合的朋友。我自己既写博客,也读别人的博客,在这个时代,对于生活中的绝大多数人来说,拓宽朋友圈子的途径几乎只有一个,通过网络,而如何在网络中寻找到气味相投的朋友,如何判断别人和自己是否有共同语言?显然,通过天天在SNS上碎碎念的那些日记是难以做到的。我佩服的一些朋友几乎全都是长期用博客记录想法的人,因此,和他们即便不打照面,也是心照不宣。即便素未谋面也能坐下来就聊得热火朝天。
为什么博客在结交志同道合的朋友方面的潜力要远胜于原始的交谈方式?很简单,第一,博客无地域限制,整个互联网上从A到B只有一个点击的距离,而传统的建立朋友圈子的方法则受到地域限制。第二,也是更重要的一点,即如果按照以前结交朋友的方式,需要互相聊天,交流观点,然后才逐渐熟悉起来,这需要一个较长的过程,而且更糟糕的是,当你遇到另一个陌生人,又要把整个过程重复一次,表达你已经对老友表达过的那番想法。可博客却做到了“一次表达,无数次阅读”,当我看到一个写了好几年的博客,看完了之后我仿佛和这个人交谈了很久,用程序员们喜欢听的话来说就是,“博客极大地增强了话语的复用性”。
我曾在CSDN上写了近六年的博客,在一年半前建立了一个Google Groups(TopLanguage),由于我的博客的长期阅读者都是互相有共同语言的,因此这个Group一开始就热火朝天,而高质量的技术讨论则进一步吸引了更多的牛人的参与,雪球滚起来之后,就很难停下来了,将近一年半下来,从这个Group的讨论中我获益良多[1]。而对于非程序员朋友,科学松鼠会则是一个很好的例子。
2) 书写是为了更好的思考。我在《书写是为了更好的思考》里面详细总结了书写的好处,这里就不拷贝粘贴了。有些想法如果不写下来,也就忘掉了,有一个广为流传的《数学牛人们的轶事》(荣耀属于ukim)里面讲了希尔伯特的一个故事:一次在Hilbert的讨论班上,一个年轻人报告,其中用了一个很漂亮的定理,Hilbert说“这真是一个妙不可言(wunderbaschon)的定理呀,是谁发现的?”那个年轻人茫然的站了很久,对Hilbert说:“是你.……”。
3) “教”是最好的“学”。**如果一件事情你不能讲清楚,十有八九你还没有完全理解**。绝大多数人应该都知道在程序员行业面试官经常要求你讲解一个东西给他听,他会说他不懂这个东西(他如果真的不懂的话效果其实是最好的),而你的任务则是说到让他理解为止。
为了让一个不明白的人做到明白,你必须要知道从明白到不明白他究竟需要掌握哪些概念,这就迫使我们对我们大脑中整个的知识体系来个寻根究底,把藏在水面之下的那些东西统统挖出来,把大脑中的那些我们知道、但不知道自己知道的潜在概念或假设(assumptions)都挖出来,把它们从内隐记忆拉扯到外显记忆中。因为只有完全知道、并知道自己知道一切来龙去脉的人,才能真正把一件事情讲得通通透透。
但是,你可能会怀疑,那除了能够讲清楚之外,弄清自己到底知道哪些东西还有其他什么好处吗?如果没有其他好处,那我又何必费这个劲呢?我又不当老师。
TopLanguage上的一位朋友sagasw曾经讲了这样一个小故事:据说在某个著名软件公司里,开发组的桌上会放着一只小熊,大家互相问问题之前,先对着小熊把问题说一遍,看能不能把问题描述的清晰,基本上说的比较有条理以后,答案也就随之而来了。当然,你不一定要对小熊说,你可以在大脑中虚构一个听众,一个不懂行的听众,然后你说给他听。这是可行的,我经常在路上用。不过如果你能坐下来,我建议你还是说给实际的听众听——即写下你的思考,因为书写是更好的思考。
我们的绝大多数知识在绝大多数时候都隐藏在潜意识中,其实我们意识的窗口很小,我们的工作记忆只能容纳寥寥数个条目(记得那个“看你能够记住屏幕上同时闪现的多少个数字”的flash小游戏吗?),我们平时所作的推理过程很大部分都是自动的,发生在潜意识中,而我们只能感知到一些中间结论。不信你回忆一下你在和别人讨论问题的时候有多少次觉得“反正就是这样,我感觉得到它是对的,但是你问我,我也说不清到底怎么回事”,对此你不觉得很奇怪吗?如果你都不能从逻辑上支持你的结论,你怎么就能确信它是对的呢?仅仅因为你的直觉强烈地告诉你它是对的?那如果旁边有另一个人,他和你持相反的观念,而他的直觉也强烈地告诉他他是对的。这时候你又怎么想?“他的直觉错了,我的直觉是对的”?难道你这么自信你的直觉是世界上最可靠的?**
我自己则是非常珍惜类似这样的机会,即当“我强烈地觉得它是对的,但我却说不出所以然来”,这时候往往是到大脑中翻箱倒柜的时候,弄清来龙去脉的时候,深入反思的时候,纠正一直以来错误的潜在前提假设的时候。另一方面,“我强烈地觉得这个说法有问题,但我却说不清它为什么有问题,到底哪有问题”,这也是一个极有意义的瞬间,它几乎总是意味着你对一个问题的认识有潜在的偏差,肯定是在你自己都没有觉知到的地方引入了一个潜在的假设、偷换了一个重要的概念,等等。而这种时候就是深入反思的时候,当你终于潜到问题的底层,触摸到问题的实质,把水面之下的冰山整体看清了的时候你会有一种通体舒泰的感觉。
为什么说以上这些?因为刚才说的是你必须等待这样的反思机会,但如果你选择经常总结自己的知识体系,并说出来给你的读者听,你就会发现你自己创造了这样的机会。如果我们平时不反思,我们觉得很多事情都是当然的,但结果如果要你一开口说给别人听,常常会发现事情就开始变得不那么明显了,你说着说着,就开始莫名其妙地发现自己需要用到“反正”这个词了。
于是,反思的机会就来了。
一旦你把自己潜意识里面的东西从幕后拉出来,你就有了面对并反思它们的可能,而不是任它们在幕后阴险地左右你的思维。很多时候我们的思路出了问题并不是我们不会反思,而是不知道自己的思维中有那些隐含的假设(assumptions),如果你只感觉到答案,却不知道你大脑得到这个答案之前做了哪些推理,你又怎么知道哪一环可能出了问题呢?另一方面,一旦你弄清了自己到底是怎么想的,离意识到问题就不远了,很简单的道理——如果别人和你争辩的时候总是只摆立场,你就很难和他辩,但如果他把自己的推理过程原原本本暴露给你,批判起来总是容易得多的。(也正因为这个原因有很多人总是把逻辑藏在背后,不敢暴露出来)
绝大多数时候其实我们都会不假思索地得出一些结论,就像上了发条的自动机,但其实我们并不知道这些结论到底怎么来的,在思维的背后到底发生了哪些事情,故而当我们发现我们的结论错了的时候,一头雾水,没法着手寻找到底在哪错了。如果你注意一下很多人的发言(论坛、博客等等),如果你把他们的发言分为“前提”、“假设”、“逻辑”、“结论”这四个部分,你会发现一大堆人只会不停地下结论,摆立场,却见不到这些结论或离场的前提、假设和个中逻辑,倒也不是他们不愿意写出逻辑,而是因为反思自己的思维过程实在是一件困难非常的事情,我们的推理过程很大一部分发生在意识的水面之下,只有当有了重要结论的时候这条逻辑链才会浮出来冒一个泡,让我们的意识捕捉到。更何况绝大多数时候我们用的其实并不是完整严密的逻辑思维,而是思维捷径。
去教一个完全不懂的人,则是一种最最强大和彻底的反思途径——因为他没有任何预备的知识,所以要让他弄懂你所知道的,你就必须彻底反思你的知识体系,弄清这座大厦的根基在什么地方,弄清它的骨架在什么地方,一砖一瓦到底是怎么垒起来的,你不能自己站在11层上,然后假设你的读者站在第10层,指望着只要告诉他第11层有那些内容就让他明白。你的读者站在第一层,你必须知道你脚下踩着的另外10层到底是怎么构造的。这就迫使你对你所掌握的、或之前认为正确的那些东西作彻彻底底的、深刻的反思,你的受众越是不懂,你需要反思得就越深刻。
4) 讨论是绝佳的反思。另一方面,很多时候我们并不是有机会说给完全不懂的人听,更大的可能性是说给同领域有一定基础的人听,这个时候并不代表就不能促使反思了,实际上,你会发现,如果你公开你的想法,几乎总能看到与你持不同意见的人,然后你通过比较你和他的观念之间的差别,会发现你们在一开始的思路上就存在差异,差异从哪里来的?在进一步讨论中你们就会不断地迫使对方拿出更深层次的理由,这同样也是一种非常有效地促使自己反思的方法,在讨论的过程中双方的理由自然会变得越来越深入,越来越接近问题的本质,一些平时难以注意到的深层面的差异性就会逐渐浮现出来,你也就多了一次难得的机会去审视自己的思维中到底存放了哪些错误的信息。
5) 激励你去持续学习和思考。如果你没有持续学习和思考的习惯,你的博客很快就会没有内容可写,就只能整点碎碎念或者转载,然后你就会失去读者,然后你就会关掉博客,然后一旦关掉博客之后你也就死了写博客的心,然后就少了一条激励你去思考和总结的途径,然后你变得更不高兴总结和思考,然后…
为了打破这个死循环,不要永久停止更新你的博客,就算你两个月,三个月都不写,只要你每篇都是写自己思考的产物,写有价值的东西,在互联网上,金子的确总是会发光的,因为有无数的信息聚合平台在期待这些有价值的内容,有搜索引擎为你的内容提供海量的潜在读者,有海量的人肉在手动挖掘和转载那些有价值的东西。我们所能做的最差的一个决策莫过于停止做一件没有任何坏处,却有一大堆好处的事情。
为了让你的博客有价值,你必须不断总结自己学习的结果,你必须不断思考,给出比别人深刻、独到的见解。这看起来有点本末倒置,但很快本和末就会正过来。
6) 学会持之以恒地做一件事情。很多人在生活中容易觉得迷失,不知道想要做什么,是因为没有一件能够持续地做的事情,用俗话来说就是没有主心骨。用积极心理学的话来说就是没有一件能够创造流体验的事情,而书写自己的思想则是一件容易产生流体验的事情,在书写的时候,特别是理性地书写的时候,大脑逐渐进入推理分析模块,一切不愉快的情绪,烦躁感都会逐渐消隐下去。不过前提是你得开始,并且坚持过一开始的困难期,以后的一切便成了习惯成自然。
7) 一个长期的价值博客是一份很好的简历。这里的“简历”并非是狭义上的求职简历,毕竟现在还没有到价值博客的时代,很多人写博客都是到处转载或者干脆碎碎念,正因此面试官未必拿个人博客当成了解一个人的更可靠窗口。这里的“简历”是指一个让别人了解自己的窗口,虽然我们未必做得到像罗永浩、Keso这样的博客,个人的影响力已经足以支撑出一份事业(牛博和5gme),但至少你会因此而结识更多的人,你的博客价值越高,你结识的人就越牛,跟牛人交流又会让你的眼界得到极大的开阔,打开一扇又一扇你原本不知道的门,于是你就变得更牛… 这是一个良性循环。
(二)怎么做到长期写一个价值博客
**
注意到我并没有说“怎么做到长期坚持写一个价值博客”,因为当思考和总结成为习惯之后,诉诸文字以及借助书写来进一步思考就变成了一件自然而然的事情,就变成了一件“因为你在思考和总结从而必须书写下来”的事情,博客就变成了副产品。
一开始的时候你是因为要写博客而去使劲地思考和总结,指望给出令人眼睛一亮的东西,到了后来,就变成了因为你习惯了思考和总结,因为你意识到书写是更好的思考,你就必须使你的想法成为文字。至此本和末就会各归原位,不再颠倒。
怎样做到长期写一个价值博客?也许有人会给出很多有趣有用的小技巧来提供动机和激励,譬如如何做SEO,如何鼓励读者留言等等,但是这些我都不想说,我只想说最最重要的,那就是:
**让你自己成为一个持续学习和思考的人,并只写你真正思考和总结之后的产物,其他一切就会随之而来。
就像那句经常被人传阅的话:只做你最感兴趣的事情,钱会随之而来[2]。
这方面的具体例子大家可以留意一下,随处可见,就不一一举了。我想再重复一下的是,千万不要碎碎念,我能理解每个人都想偶尔发发牢骚的冲动,但是现在已经有了一个很好的窗口:twitter,所以立即停止在你的博客上碎碎念,阅读博客的人希望得到信息而非噪音。如果实在忍不住想碎碎念的话不妨换一下位置,这么来告诉自己:如果你看到别人博客来上这么一段,你会有兴趣看吗?
(三)可能出现的问题以及怎样应付
**
即便上文给出了N条写博客的理由,但有时候只要一条不写的理由就会让人停止做一件事情。所以我特别加上一节“可能出现的问题以及怎样应付”,《影响力2》[3]第五章雄辩地证明,“Much of Will is Skill”,意志力很大程度上来源于有正确的方法,而非天生。
1) 担心别人认为没有价值。事实是,你面临过的问题总会有人面临过,你独立思考了,别人没有,你的文章对他们就会有价值。当然,肯定会对某些人没有价值,他们早就知道了,但就算你再厉害,也总是有人比你厉害的,不能说因为这些原因就不记录你自己的想法了,你自己思考了之后理解得最深刻,就算有别人想过了,总有人没有想到的。况且,思考成了习惯,你的思考能力也会越来越强,你的文章也会越来越有价值。重复,无论你面临什么困惑,总会有很多人同样面临过,于是你苦苦思索之后的结果,肯定会对很多人有意义。**
或者,你想通了之后觉得其实也很简单于是不愿意或者不好意思写了,但要知道,问题在想通了之后总是简单的,问题的困难程度不在于想通了之后还觉得有多难,而在于从你觉得它难到你觉得它简单需要耗费多少思维体力,你耗费的时间越长,说明有越多的人最终还是没有想明白(路越长走到底的人越少)。
最后,虽然我现在看一年前的文章觉得挺不成熟,但是如果没有那些不成熟的思考,也不会有现在更成熟的思考,我几年后来看现在写的东西,还是会觉得不成熟。
2) 担心想法太幼稚或有漏洞等等被别人笑话。人非圣贤。正是因为单个人的想法总是有漏洞,才值得拿出来交流(《书写是更好的思考》,讨论是绝佳的反思),被别人指出问题正是改进的空间,藏着掖着的想法永远不可能变得更成熟。
Much of intelligence is knowledge,有这么一个非常发人深省的经典心理学实验[4]:
将孩子们分成两组,通过给他们不同的阅读材料让一组相信智力是天生的,不可在后天改变的,另一组则让他们相信智力其实只是知识和技能的代名词,完全是后天习得的。接下来让他们做一组任务,那些被相信智力天生说的孩子,倾向于回避困难的任务,选择较容易的任务,这里的逻辑想必是这样的:如果做困难的任务,就增大了失败的几率,就在降低了自己在别人和自己心目中的智力的值。为了保护这个智力的值不被降低,应该避免那些有失败风险的项目。而另一组孩子则对于有挑战性的事情跃跃欲试,并且在失败的时候明显没有前者沮丧,因为失败也是学得新的东西,不管怎样都是“智力”的提高。
让我说得更明确一点:用博客的形式来记录下你有价值的思考,会带来很多好处,却没有任何明显的坏处。Note:碎碎念不算思考、心情琐记不算思考、唠唠叨叨也不算思考、没话找话也不算思考,请以此类推。
下面是我个人认为写一个长期的价值博客的最大的几点好处:
1) 能够交到很多志同道合的朋友。我自己既写博客,也读别人的博客,在这个时代,对于生活中的绝大多数人来说,拓宽朋友圈子的途径几乎只有一个,通过网络,而如何在网络中寻找到气味相投的朋友,如何判断别人和自己是否有共同语言?显然,通过天天在SNS上碎碎念的那些日记是难以做到的。我佩服的一些朋友几乎全都是长期用博客记录想法的人,因此,和他们即便不打照面,也是心照不宣。即便素未谋面也能坐下来就聊得热火朝天。
为什么博客在结交志同道合的朋友方面的潜力要远胜于原始的交谈方式?很简单,第一,博客无地域限制,整个互联网上从A到B只有一个点击的距离,而传统的建立朋友圈子的方法则受到地域限制。第二,也是更重要的一点,即如果按照以前结交朋友的方式,需要互相聊天,交流观点,然后才逐渐熟悉起来,这需要一个较长的过程,而且更糟糕的是,当你遇到另一个陌生人,又要把整个过程重复一次,表达你已经对老友表达过的那番想法。可博客却做到了“一次表达,无数次阅读”,当我看到一个写了好几年的博客,看完了之后我仿佛和这个人交谈了很久,用程序员们喜欢听的话来说就是,“博客极大地增强了话语的复用性”。
我曾在CSDN上写了近六年的博客,在一年半前建立了一个Google Groups(TopLanguage),由于我的博客的长期阅读者都是互相有共同语言的,因此这个Group一开始就热火朝天,而高质量的技术讨论则进一步吸引了更多的牛人的参与,雪球滚起来之后,就很难停下来了,将近一年半下来,从这个Group的讨论中我获益良多[1]。而对于非程序员朋友,科学松鼠会则是一个很好的例子。
2) 书写是为了更好的思考。我在《书写是为了更好的思考》里面详细总结了书写的好处,这里就不拷贝粘贴了。有些想法如果不写下来,也就忘掉了,有一个广为流传的《数学牛人们的轶事》(荣耀属于ukim)里面讲了希尔伯特的一个故事:一次在Hilbert的讨论班上,一个年轻人报告,其中用了一个很漂亮的定理,Hilbert说“这真是一个妙不可言(wunderbaschon)的定理呀,是谁发现的?”那个年轻人茫然的站了很久,对Hilbert说:“是你.……”。
3) “教”是最好的“学”。**如果一件事情你不能讲清楚,十有八九你还没有完全理解**。绝大多数人应该都知道在程序员行业面试官经常要求你讲解一个东西给他听,他会说他不懂这个东西(他如果真的不懂的话效果其实是最好的),而你的任务则是说到让他理解为止。
为了让一个不明白的人做到明白,你必须要知道从明白到不明白他究竟需要掌握哪些概念,这就迫使我们对我们大脑中整个的知识体系来个寻根究底,把藏在水面之下的那些东西统统挖出来,把大脑中的那些我们知道、但不知道自己知道的潜在概念或假设(assumptions)都挖出来,把它们从内隐记忆拉扯到外显记忆中。因为只有完全知道、并知道自己知道一切来龙去脉的人,才能真正把一件事情讲得通通透透。
但是,你可能会怀疑,那除了能够讲清楚之外,弄清自己到底知道哪些东西还有其他什么好处吗?如果没有其他好处,那我又何必费这个劲呢?我又不当老师。
TopLanguage上的一位朋友sagasw曾经讲了这样一个小故事:据说在某个著名软件公司里,开发组的桌上会放着一只小熊,大家互相问问题之前,先对着小熊把问题说一遍,看能不能把问题描述的清晰,基本上说的比较有条理以后,答案也就随之而来了。当然,你不一定要对小熊说,你可以在大脑中虚构一个听众,一个不懂行的听众,然后你说给他听。这是可行的,我经常在路上用。不过如果你能坐下来,我建议你还是说给实际的听众听——即写下你的思考,因为书写是更好的思考。
我们的绝大多数知识在绝大多数时候都隐藏在潜意识中,其实我们意识的窗口很小,我们的工作记忆只能容纳寥寥数个条目(记得那个“看你能够记住屏幕上同时闪现的多少个数字”的flash小游戏吗?),我们平时所作的推理过程很大部分都是自动的,发生在潜意识中,而我们只能感知到一些中间结论。不信你回忆一下你在和别人讨论问题的时候有多少次觉得“反正就是这样,我感觉得到它是对的,但是你问我,我也说不清到底怎么回事”,对此你不觉得很奇怪吗?如果你都不能从逻辑上支持你的结论,你怎么就能确信它是对的呢?仅仅因为你的直觉强烈地告诉你它是对的?那如果旁边有另一个人,他和你持相反的观念,而他的直觉也强烈地告诉他他是对的。这时候你又怎么想?“他的直觉错了,我的直觉是对的”?难道你这么自信你的直觉是世界上最可靠的?**
我自己则是非常珍惜类似这样的机会,即当“我强烈地觉得它是对的,但我却说不出所以然来”,这时候往往是到大脑中翻箱倒柜的时候,弄清来龙去脉的时候,深入反思的时候,纠正一直以来错误的潜在前提假设的时候。另一方面,“我强烈地觉得这个说法有问题,但我却说不清它为什么有问题,到底哪有问题”,这也是一个极有意义的瞬间,它几乎总是意味着你对一个问题的认识有潜在的偏差,肯定是在你自己都没有觉知到的地方引入了一个潜在的假设、偷换了一个重要的概念,等等。而这种时候就是深入反思的时候,当你终于潜到问题的底层,触摸到问题的实质,把水面之下的冰山整体看清了的时候你会有一种通体舒泰的感觉。
为什么说以上这些?因为刚才说的是你必须等待这样的反思机会,但如果你选择经常总结自己的知识体系,并说出来给你的读者听,你就会发现你自己创造了这样的机会。如果我们平时不反思,我们觉得很多事情都是当然的,但结果如果要你一开口说给别人听,常常会发现事情就开始变得不那么明显了,你说着说着,就开始莫名其妙地发现自己需要用到“反正”这个词了。
于是,反思的机会就来了。
一旦你把自己潜意识里面的东西从幕后拉出来,你就有了面对并反思它们的可能,而不是任它们在幕后阴险地左右你的思维。很多时候我们的思路出了问题并不是我们不会反思,而是不知道自己的思维中有那些隐含的假设(assumptions),如果你只感觉到答案,却不知道你大脑得到这个答案之前做了哪些推理,你又怎么知道哪一环可能出了问题呢?另一方面,一旦你弄清了自己到底是怎么想的,离意识到问题就不远了,很简单的道理——如果别人和你争辩的时候总是只摆立场,你就很难和他辩,但如果他把自己的推理过程原原本本暴露给你,批判起来总是容易得多的。(也正因为这个原因有很多人总是把逻辑藏在背后,不敢暴露出来)
绝大多数时候其实我们都会不假思索地得出一些结论,就像上了发条的自动机,但其实我们并不知道这些结论到底怎么来的,在思维的背后到底发生了哪些事情,故而当我们发现我们的结论错了的时候,一头雾水,没法着手寻找到底在哪错了。如果你注意一下很多人的发言(论坛、博客等等),如果你把他们的发言分为“前提”、“假设”、“逻辑”、“结论”这四个部分,你会发现一大堆人只会不停地下结论,摆立场,却见不到这些结论或离场的前提、假设和个中逻辑,倒也不是他们不愿意写出逻辑,而是因为反思自己的思维过程实在是一件困难非常的事情,我们的推理过程很大一部分发生在意识的水面之下,只有当有了重要结论的时候这条逻辑链才会浮出来冒一个泡,让我们的意识捕捉到。更何况绝大多数时候我们用的其实并不是完整严密的逻辑思维,而是思维捷径。
去教一个完全不懂的人,则是一种最最强大和彻底的反思途径——因为他没有任何预备的知识,所以要让他弄懂你所知道的,你就必须彻底反思你的知识体系,弄清这座大厦的根基在什么地方,弄清它的骨架在什么地方,一砖一瓦到底是怎么垒起来的,你不能自己站在11层上,然后假设你的读者站在第10层,指望着只要告诉他第11层有那些内容就让他明白。你的读者站在第一层,你必须知道你脚下踩着的另外10层到底是怎么构造的。这就迫使你对你所掌握的、或之前认为正确的那些东西作彻彻底底的、深刻的反思,你的受众越是不懂,你需要反思得就越深刻。
4) 讨论是绝佳的反思。另一方面,很多时候我们并不是有机会说给完全不懂的人听,更大的可能性是说给同领域有一定基础的人听,这个时候并不代表就不能促使反思了,实际上,你会发现,如果你公开你的想法,几乎总能看到与你持不同意见的人,然后你通过比较你和他的观念之间的差别,会发现你们在一开始的思路上就存在差异,差异从哪里来的?在进一步讨论中你们就会不断地迫使对方拿出更深层次的理由,这同样也是一种非常有效地促使自己反思的方法,在讨论的过程中双方的理由自然会变得越来越深入,越来越接近问题的本质,一些平时难以注意到的深层面的差异性就会逐渐浮现出来,你也就多了一次难得的机会去审视自己的思维中到底存放了哪些错误的信息。
5) 激励你去持续学习和思考。如果你没有持续学习和思考的习惯,你的博客很快就会没有内容可写,就只能整点碎碎念或者转载,然后你就会失去读者,然后你就会关掉博客,然后一旦关掉博客之后你也就死了写博客的心,然后就少了一条激励你去思考和总结的途径,然后你变得更不高兴总结和思考,然后…
为了打破这个死循环,不要永久停止更新你的博客,就算你两个月,三个月都不写,只要你每篇都是写自己思考的产物,写有价值的东西,在互联网上,金子的确总是会发光的,因为有无数的信息聚合平台在期待这些有价值的内容,有搜索引擎为你的内容提供海量的潜在读者,有海量的人肉在手动挖掘和转载那些有价值的东西。我们所能做的最差的一个决策莫过于停止做一件没有任何坏处,却有一大堆好处的事情。
为了让你的博客有价值,你必须不断总结自己学习的结果,你必须不断思考,给出比别人深刻、独到的见解。这看起来有点本末倒置,但很快本和末就会正过来。
6) 学会持之以恒地做一件事情。很多人在生活中容易觉得迷失,不知道想要做什么,是因为没有一件能够持续地做的事情,用俗话来说就是没有主心骨。用积极心理学的话来说就是没有一件能够创造流体验的事情,而书写自己的思想则是一件容易产生流体验的事情,在书写的时候,特别是理性地书写的时候,大脑逐渐进入推理分析模块,一切不愉快的情绪,烦躁感都会逐渐消隐下去。不过前提是你得开始,并且坚持过一开始的困难期,以后的一切便成了习惯成自然。
7) 一个长期的价值博客是一份很好的简历。这里的“简历”并非是狭义上的求职简历,毕竟现在还没有到价值博客的时代,很多人写博客都是到处转载或者干脆碎碎念,正因此面试官未必拿个人博客当成了解一个人的更可靠窗口。这里的“简历”是指一个让别人了解自己的窗口,虽然我们未必做得到像罗永浩、Keso这样的博客,个人的影响力已经足以支撑出一份事业(牛博和5gme),但至少你会因此而结识更多的人,你的博客价值越高,你结识的人就越牛,跟牛人交流又会让你的眼界得到极大的开阔,打开一扇又一扇你原本不知道的门,于是你就变得更牛… 这是一个良性循环。
(二)怎么做到长期写一个价值博客
**
注意到我并没有说“怎么做到长期坚持写一个价值博客”,因为当思考和总结成为习惯之后,诉诸文字以及借助书写来进一步思考就变成了一件自然而然的事情,就变成了一件“因为你在思考和总结从而必须书写下来”的事情,博客就变成了副产品。
一开始的时候你是因为要写博客而去使劲地思考和总结,指望给出令人眼睛一亮的东西,到了后来,就变成了因为你习惯了思考和总结,因为你意识到书写是更好的思考,你就必须使你的想法成为文字。至此本和末就会各归原位,不再颠倒。
怎样做到长期写一个价值博客?也许有人会给出很多有趣有用的小技巧来提供动机和激励,譬如如何做SEO,如何鼓励读者留言等等,但是这些我都不想说,我只想说最最重要的,那就是:
**让你自己成为一个持续学习和思考的人,并只写你真正思考和总结之后的产物,其他一切就会随之而来。
就像那句经常被人传阅的话:只做你最感兴趣的事情,钱会随之而来[2]。
这方面的具体例子大家可以留意一下,随处可见,就不一一举了。我想再重复一下的是,千万不要碎碎念,我能理解每个人都想偶尔发发牢骚的冲动,但是现在已经有了一个很好的窗口:twitter,所以立即停止在你的博客上碎碎念,阅读博客的人希望得到信息而非噪音。如果实在忍不住想碎碎念的话不妨换一下位置,这么来告诉自己:如果你看到别人博客来上这么一段,你会有兴趣看吗?
(三)可能出现的问题以及怎样应付
**
即便上文给出了N条写博客的理由,但有时候只要一条不写的理由就会让人停止做一件事情。所以我特别加上一节“可能出现的问题以及怎样应付”,《影响力2》[3]第五章雄辩地证明,“Much of Will is Skill”,意志力很大程度上来源于有正确的方法,而非天生。
1) 担心别人认为没有价值。事实是,你面临过的问题总会有人面临过,你独立思考了,别人没有,你的文章对他们就会有价值。当然,肯定会对某些人没有价值,他们早就知道了,但就算你再厉害,也总是有人比你厉害的,不能说因为这些原因就不记录你自己的想法了,你自己思考了之后理解得最深刻,就算有别人想过了,总有人没有想到的。况且,思考成了习惯,你的思考能力也会越来越强,你的文章也会越来越有价值。重复,无论你面临什么困惑,总会有很多人同样面临过,于是你苦苦思索之后的结果,肯定会对很多人有意义。**
或者,你想通了之后觉得其实也很简单于是不愿意或者不好意思写了,但要知道,问题在想通了之后总是简单的,问题的困难程度不在于想通了之后还觉得有多难,而在于从你觉得它难到你觉得它简单需要耗费多少思维体力,你耗费的时间越长,说明有越多的人最终还是没有想明白(路越长走到底的人越少)。
最后,虽然我现在看一年前的文章觉得挺不成熟,但是如果没有那些不成熟的思考,也不会有现在更成熟的思考,我几年后来看现在写的东西,还是会觉得不成熟。
2) 担心想法太幼稚或有漏洞等等被别人笑话。人非圣贤。正是因为单个人的想法总是有漏洞,才值得拿出来交流(《书写是更好的思考》,讨论是绝佳的反思),被别人指出问题正是改进的空间,藏着掖着的想法永远不可能变得更成熟。
Much of intelligence is knowledge,有这么一个非常发人深省的经典心理学实验[4]:
将孩子们分成两组,通过给他们不同的阅读材料让一组相信智力是天生的,不可在后天改变的,另一组则让他们相信智力其实只是知识和技能的代名词,完全是后天习得的。接下来让他们做一组任务,那些被相信智力天生说的孩子,倾向于回避困难的任务,选择较容易的任务,这里的逻辑想必是这样的:如果做困难的任务,就增大了失败的几率,就在降低了自己在别人和自己心目中的智力的值。为了保护这个智力的值不被降低,应该避免那些有失败风险的项目。而另一组孩子则对于有挑战性的事情跃跃欲试,并且在失败的时候明显没有前者沮丧,因为失败也是学得新的东西,不管怎样都是“智力”的提高。
况且,只会批判乃至嘲笑别人的人是最不知道怎么建设的人,忽略他们。
3) 得不到激励。这其实是个最无聊的问题了,只有写碎碎念的博客才会面对“激励”的问题。如果写自己的总结,写自己独立的思考,那么书写下来、理解通透,本身就是一个极大的激励。就算放在自己的私密笔记本里面也一样有成就感。况且,如果你真做到了书写价值博客,那么绝对不用担心你的观点得不到传播,也许一开始会耗时长一点,但是这在任何事情上都是必要的初始阶段,Gmail小组的核心人物、FriendFeed创始人Paul Buchheit,和编程界名博Coding Horror的博主Jeff Atwood都曾经感叹过:Overnight success takes a long time ((1),(2)),不过对于价值博客来说,现在网络上的聚合类服务这么多,机器的、人肉的、半人肉的都有,情况又要好得多了,而且我相信情况还会越来越好。
4) 写不出来。这个问题也比较无聊,思考本不是一件急于求成的事情。长期订阅我的博客的朋友知道我一般发文频率在一个月三五篇,实际上有不少次我个把月也不发布文章,原因很简单,要么是有手头的事情要处理思考的时间被压缩了,要么是遇到比较大或者比较困难的问题需要长时间的思考和积淀,没有关系,如果没有想清楚就再想想,爱思考的人和不爱思考的人有一个本质的区别,前者在生活中总是挂着几个问题在大脑中,它们时常都会冒出来骚扰你一下,让你琢磨琢磨,不爱思考的则是没事不主动想问题,遇到问题还要先想想是否能找捷径(找人帮忙)解决。
无论如何,不用急于求成,在一个主题上深入下去思考,总能挖到别人挖不到的角落。你能让一个问题在大脑中停留的时间越长,就越是能够发现新的东西,一般来说,我认为有价值的问题我会让他在意识或潜意识中待短则一个星期,长则一个月(视问题大小而定),利用走路吃饭的时间琢磨(我发现很多我佩服的人也都有这个习惯),有时即便已经想通了写下来了发出去了,大脑仍然还是会在回味问题,还没有把它撤出潜意识,然后看到某篇文章或某本书的时候忽然又有所新的感悟。
能够把问题长时间停靠在潜意识中是一种技能,能够带来很大的好处,停留得越长你越琢磨得透彻,比别人看到的就越多。我们必须要带着问题的眼镜看待事物才能发现新的视角,否则就会出现视而不见效应,别的不说,广为人知的例子是阿基米德的“尤里卡!”,如果不是长时间琢磨着一个问题,一直把它放在思维中,是不会从洗澡领悟到“排水测体积”的,否则他洗了那么多年澡怎么不早发现呢?[5]
所以,如果你习惯了思考问题,就总会有东西写,先有思考,然后有总结,然后在总结中进一步思考。
当然你也可以试试把不成熟的想法写下来,试图整理成条理清晰的文字,然后看看能否在整理的过程中走得更远。这往往是可行的。比如这篇文章在我的简记里面原本其实只有三行字(包含大约十来个备忘关键词),而最初在我的大脑里面其实只有一个走路时冒出来的问题——为什么要写博客?
—
[1] 你可以看一下我收藏的一些精彩主题。
[2] 尽管我并不完全同意这句话本身,但它这种解决问题链上更基本环节的问题的精神是我赞同的。
[3] 《影响力2》这个名字起得很聪明,其实它并不是《影响力》的作者写的。
[4] 我忘了这则实验的出处了,但实验的精神是记忆犹新的,哪位同学记得原始出处的麻烦提醒我一下。
[5] 对于阿基米德这个故事的真实性是有争议的,毕竟几千年久远的事情谁弄得清呢。但是故事的道理是很本质的,我们平时也经常有类似的体验,加上阿基米德的“尤里卡”实在太出名了,所以我相信用用无妨。
---
layout: post
title: 2017书单
date: 2017-10-07 20:00:00 -0400
tags:
- 读书笔记
- 书单
---
2017-10-08-2017书单
- 浪潮之巅
描绘得很精彩的IT行业的发展史,包含了作者对IT历史的看法,和未来的预测。
- 黑客与画家
黑客里画画最好的人对这个世界的独特见解。
- 编码:隐匿在计算机软硬件背后的语言
计算机入门书籍,通俗易懂,但后半段对我来说有点难。从生活中常见的灯泡讲起,如何通过灯泡的闪烁来传输数据,通过灯泡的闪烁时长类比了电报里的点和划。通过布莱特盲文的例子,引入了二进制这个概念,然后构造了一个继电器(原理很简单),接着由继电器的组合可以组成与或非异或等逻辑门,通过这些逻辑门可以进行二进制加法运算。向读者发问,如何进行减法运算。然后引入了补码这个概念。通过补码的相加和转换就可以进行加减法运算了。后面的我读得没有前面那么细致,理解得也不够透彻,不能如此信手拈来地复述了。下周吧!2017.10.15前理解透彻再来更!
- 从行动开始
你要看清你现在的局面,想得那么多,不如做点微小的行动。哪怕很微小,都是有利的,行动的结果又会激励你持之以恒地坚持。未来遥不可及,过去无法改变,你能做的只有把我现在。人们对现实有很多认知偏差,例如说某个人只是没注意看见你所以没跟你打招呼,但是有的人内心就会产生对方不喜欢自己的想法。还有的可能因为偶尔执行力不强,就给自己贴上了“懒”等其他负面的标签,以后就可以以这些标签为借口,继续逃避显示。引用《精进:如何成为一个很厉害的人》里的一句话,那些很难的事情,一但你着手去做,事情就会变得越来越简单。虽然我复述得有点鸡汤,不过这本书确实确实提供了很好的实践方法,并非空洞的鸡汤
- 数学之美
还没看。拖得太久了。放上来让空格催促我读书吧
- 《朝花夕拾》
小学生读物了吧,可是我还没看过。在kindle上看到就买了。鲁迅对于童年的回忆。《阿长与山海经》就出自这里。古老的乡村,有很多有趣的文化,但也有许多封建腐朽的东西。
- 《疯狂的程序员》
- 《好好学习》
---
layout: post
title: 2016年的书单
date: 2017-10-06 20:00:00 -0400
tags:
- 读书笔记
- 书单
---
2017-10-07-2016年的书单
1《平凡的世界——路遥》
质朴的文笔。
上世纪六七十年代陕北农民生活。
书中主人公的悲哀是时代的缩影。
2《程序员的爱情》
跟朋友逛图书馆看到就借了,还行吧。
3《暗时间——刘未鹏》
关于学习方法和时间管理。
这本书和《和时间做朋友》《精进》都是讲如何自我提升的有效方法。
作者建议读者应该学点哲学,心理学,社会学,因为这些学科跨学科的。哲学为系统科学提供方法论嘛,哈哈。所以我借了两本关于康德的哲学书。
4《乔治速读记忆法》
内容忘记了。
5《一日学习法》
6《一日学习法2》
韩国高考状元写的书。
有一定可实践性。
7《把时间当做朋友——李笑来》
类似于《暗时间》,也是关于学习的书。
强调心智的力量。
态度:先努力去做一些事,你会收到反馈,你就会喜欢去做,而不是因为你喜欢你才为之付出努力。
8《三重门》
韩寒成名作。
现在看起来没那么精彩,但这是他十六七岁时写的书。
9《遥远的救世主》
讲述一个怪才书写商业传奇的故事,太好看。
主旨:能救你的只有你自己。
10《这本书能让你戒烟》
想戒烟的可以看看,
我不喜欢抽烟,这书是阅读软件送的书。
11《被置换的孩子》
舍友的书,随便翻翻。
12《你体内的囤积欲》
关于杂物整理。
13《干校六记——杨绛》
我读的第一本杨绛的书。
记录杨绛与钱钟书某个时期被安排到农村从事农业劳动的经历。
喜欢杨绛细腻的文笔。
羡慕杨绛跟钱钟书的生活。我一定要找个爱看书的女朋友, 两个书虫宅在一起就不会无聊了。
14《我与地坛——史铁生》
我读的第一本史铁生的书。
史铁生每天推着轮椅到地坛公园写作。写了一些关于自身命运自己这个世界的看法。
如果不能在超越自我局限的无尽旅途上去理解幸福,那么史铁生的不能跑与刘易斯的不能跑得更快就完全等同,都是沮丧与痛苦的根源。
幸福是享受,痛苦也是享受。
15《走出软件作坊——阿朱》
作者是软件公司的CTO(首席技术执行官)
如何安排工作流程,如何与同事沟通,如何展示软件之类的。以后会对我有用。
16《精进——采铜》
知乎大V写的。
关于人生道路选择和学习方法有很独到的见解。
17《自控力》
你需要相信科学的方法可以提升你的自控力。
对于自控力弱的朋友,你要知道:你需要科学的方法训练,然后更从容地接受自己,而不是那些肤浅的只能激励你一时的毒鸡汤。
18《创新者的窘境》
剖析几个行业的案例。
19《活着你就得有趣——李敖》
第一本李敖的书,刚开始认识李敖。
读李敖的书之前我觉得韩寒是当代鲁迅一点不为过,读了之后我觉得岳父比起李敖还是too simple。
20《孤独六讲——蒋勋》
从几个方面写孤独,看完了我更喜欢独处了。
孤独是我们逃避不了的,学会独处你会过得很好。
喜欢独处跟性格孤僻是两码事。
交际能力还是要有的。
21《人性的优点——卡耐基》
英文名是
How to Stop Worrying and Start Living
如果你经常焦虑你需要这本书。
卡耐基的成功学跟现在臭名昭著的肤浅的成功学真的不一样,就例如这本书,卡耐基提供的是可以实践的缓解焦虑的方法,而当下更多“成功学”只是嚷嚷着让你如何如何努力,一点用处都没有。
好像很多人黑卡耐基,可能我还没到那个境界吧。
22《超越智商》
看不懂,过段时间再回看好了。
23《杀死一只知更鸟》
我读的第一本外国名著。这本书对我为人处世影响巨大。
上世纪美国二三十年代,种族歧视十分严重,主人公是单亲爸爸,也是一名律师。小说围绕他为一名黑人打官司展开。
主人公对孩子的教育方式以及他的处世方式是文中具有教育意义的一大亮点。
你不可能了解一个人,除非你站在他的角度看问题。
要讨论对方感兴趣的内容,而不是自己感兴趣的内容。当然有交集就更好啦。
24《假面饭店——东野圭吾》
侦探小说,很好看。
25《我所不理解的生活——胡适》
第一本胡适的书。
胡适的杂文集,关于胡适对宗教,政治,文学,哲学的看法。
书中提到了哲学与人生。我对哲学更感兴趣了。
26《娱乐至死 ——尼尔波兹曼》
人们会爱上那些对他们毫无用处,使他们丧失思考能力的工艺。
人们越来越喜欢上毫无用处的娱乐。拒绝严肃的思考。不信你看看现在的娱乐圈,
对于个人来说,这本书起到警醒的作用,但是对于群体来说,这只是一个悲观的预言,哪怕有人说出来,这个趋势是不会改变的。
人们越来越喜欢毫无用处的娱乐活动,而放弃了严谨且严肃的思考。其实导致这种局面的不是先进地媒介,而是人类对娱乐的需求。包括现在的网络也一样,网络上有那么多优质的学习资源,而那么多人拿来进行娱乐消遣。
27《纯粹理性批判演讲录》
武汉大学哲学教授的课堂录音整理。
哲学虽然很枯燥很难读。
这本书读了好久。
看不下去啦,太费劲。
28《追时间的人》
内容太杂,看不懂。
29《奇特的一生》
一个前苏联科学家的传记风格的小说。
书里介绍了一种记录时间的方法,我至今还在使用。
使用了一段时间就放弃了。
30《学习之道》
综合脑科学和心理学来研究学习方法的书
31《刻意练习》
跟《学习之道》很像,举例子太多。
32《如何高效学习》
感觉用处不大。
33《把时间当做朋友》
关于心智的成长。
---
layout: post
title: yuuji
date: 2017-10-01 20:00:00 -0400
tags:
- 生活
- 青春回忆
---
2017-10-02-yuuji
起因
某天下午,我不想去上C语言的课,但最后还是被同学劝去了,坐在机房最后一排,旁边坐着一个白人,在看着俄语的C++的维基。我在社团的群里说旁边作者一个俄罗斯小哥,然后社团的老师就让我问问他愿不愿意加入我们社团。我在电脑上敲了一个行“Hi would u like to join my association?”他很兴奋的敲了“Which association?””technology….”,他说,“你能说中文吗?”。然后我就用中文跟一个外国人聊了一节课,加了他的微信。之后社团主席微信面试了他,他就加入我们社团啦。
原来不只俄罗斯说俄语
因为看见他浏览俄语的网页,所以我一直以为他是俄罗斯人,后来才知道他是吉尔吉斯斯坦的。虽然他们有自己的语言,但是官方语言是俄语。
学语言最好的方式应该是与人交流,而不是照本宣科。
他说微信帮他学中文。他只学了一年中文,但是中文真的很好啊,卧槽,666,牛逼啊他都能理解。他喜欢闲聊,所以中文说得很好,但是阅读不怎么好。
求同存异
来这里饮食很不习惯,我说,中国的东西不是很好吃的么?大家都说中国的东西好吃啊。他说,你们觉得好吃,但别人觉得不好吃。然后他给我一块类似于奶酪的东西,我试着咬了一口,根本吃不了啊,然后他说他们觉得很好吃。他从家里带了好多过来。他说他对中国食物的感觉,和我刚刚吃的那块东西是一样的。他去吃西餐,但是中国的西餐又巨贵,只能偶尔吃吃。
中国制造
他的手机是华为的,我就问问他觉得华为的手机怎么样?他说华为很好,他们国家现在很多人用华为,回家的时候看到很多华为的广告。但是如果以前看到中国的手机,就觉得很垃圾,是不会用的。但是现在华为的很好,会提醒他他已经玩了5个小时的微信和游戏,该休息一下了。“我的朋友都没这么关心我过”。他还给我演示了华为的语音助手,特别好用,如果找不到手机,喊一下,“小E,你在哪里?“他就会响。然后还有其他一些人性化的功能,我觉得可以跟苹果的Siri媲美了。
但是还有别的,他们国家有很多中国的东西,但是质量不好,广州的最不好。在苏联国家的东西可以用十年,但是中国的产品两三个月就坏了。在中国的阿迪店买的鞋跟他在国外买的不一样。
原来中国制造有Make in China和Make in PRC之分,前者是劣质的,后者是好的,中国在努力做后者。有点惭愧,这是一个外国人告诉我我才知道的。
结语
多去与那些有趣的人交流。
---
layout: post
title: 给那些人
date: 2017-08-02 20:00:00 -0400
tags:
- 生活
- 青春回忆
---
2017-08-03-给那些人
某天夜里一时兴起写的文章,不出现在文章里的人不是说不重要,只是,我不想再写了,要是你想听就告诉我我跟你单独说吧。
A
那时候是初二,你是个高冷学霸,从转到我们班开始直到中考一直都是第一。偶然跟你有一次交谈,然后发现其实你挺有趣的,跟你聊天很愉快。我问你怎么能写得完那么多练习,你说“我的时间很多的,不想像你们一样虚度光阴”“我没有虚度光阴,我的电脑技术很好(原话,挺不谦虚的当时)”“…”。在那之后我才珍惜时间学习,初三戒了游戏,一回家就学习,各种砸时间。好在初中不难,初一初二也有点基础,于是排名一路狂飙。你一直都是第一,我的排名离你越来越近,嗯,中考是排名最好的一次,第二(学校成绩不好,也就是刚好国兴的水平)。要是没有你,我应该不会遇见接下来这些人。(那时候能逆袭是天时地利人和吧,有点鸡汤味,没有炫耀的意思,高中我想来一次逆袭,但最后考得很平庸。)
B
之前跟你并不熟,只知道你是隔壁班成绩很好的同学,你报海师附中,我报国兴,按理说我们不会有什么交集。报志愿最后一天,校长让几个家长和学生去他办公室,说是要把学籍留在母校,然后去别的学校借读。最后我和你一起来国兴了。这三年一起经历了太多,一起上学,一起回家,一起回来办手续,一起会考高考,都是很难忘的记忆啊。我们会去不同的城市,保重。
C
军训的时候我就觉得你很美,现在也觉得你很美。原谅我高一时如此莽撞、闹得全班人起哄。不过当时起哄的人应该大多都忘了这件事了吧。谢谢你,总是会考虑我的感受。随着我慢慢成长,我意识到我应该想办法把自己变得更好,而不应该想着怎么追到你,靠感动得来的爱情并不能长久。
D
接着就到你啦,军训的时候戴个白框眼镜,那时候4G刚刚兴起,我用中兴的4g,你从班群加我,问我用的是不是5s。后来你说,看我相册有骑车照片就加了。嗯,能遇上有共同爱好的小伙伴也是挺难得的。跑操的时候总是跟你谈天说地,然后高一下学期我被分去2班了。分班之后我很努力学习,想考回1班,没想到校长为了提高一本率竟然只让每个普通班中等的学生去组建新的次重点,我就去不成了。是你陪我一起去找级长,所以最后我又跟你同班。从那时起一直同桌,直到高三班主任实行单人单桌。我们又可以继续跑操的时候谈天说地了。
E
我军训第三天才去学校的,在教室黑板上看到竞选班干部的候选人,看到了你的名字,小学同学,只是知道名字,并不认识,居然高中同班。在食堂打饭你很友好地问我要不要一起坐你爸的车回家,接下来三年我和B几乎都是坐你爸的车回家的,每次都把绕远送我到家门口,开学期末还回帮我搬行李。还有很佩服你的学习态度,高中我是不怎么努力,大学应该会像你一样,心无旁骛地学习。非常感谢你,还有你的家人,你们都对我太好了。谢谢!
F
接着到谁,我想想,就是你了。刚开学的时候我看你很不顺眼,傻了吧唧地问别人你写的字好不好看,还在班群里爆粗口。奇怪的是后来那个我讨厌的那个人不见了。不知道怎么就跟你混熟了,然后各种“黑”,当时班里同学们的关系太好了,都爱互黑。我各种补刀,后来基本上不随便黑人了,怕闹得人家不高兴。虽然说就跟你同班一个学期,但是对你的黑还真是有增无减。“第一次看你不太顺眼,没想到后来关系那么密切”
---
layout: post
title: 初中这三年
date: 2013-11-29 19:00:00 -0500
tags:
- 生活
- 青春回忆
---
2013-11-30-初中这三年
2011初秋,来到了城南
来到城南,不是一件很好的事情。可是也比实验的普通班好多了。我们没有专用的多媒体教室,可是同是尖子班的2班不知为何总是隔三差五的去多媒体教室上课,多媒体的演示文稿--只是我们的班主任偶尔弄,字是他用搜狗一个一个打出来的,跟电脑老师的五笔龙飞凤舞相差甚远(他的QQ五年了才七级)。我们的班主任是一位八零后的男语文老师,而隔壁班的却是英语老师。这。我们可以知道,只要熟悉键盘,很短的时间打上一篇英语课的演示文稿不是很难。这应该是二班经常去多媒体教室的原因了。
我的城南——只有一栋教学楼的初级中学
城南,我的好感就是标准的四百米跑道,有宽带的电脑教室,尖子班跟普通班的教室是一样的,还有两个可以可以逃学的后门。有几位领导几乎每天都开早会。有一位戴眼镜的政治老师说话老是打嗝儿。有一位勤劳的光头历史老师骑自行车出行
一般的班主任
既然说他是八零后,他也会有80后火气,也像年轻人似的幽默,但不同的是,他已是妻管严,生活很是悲哀的,他每天开着龟速的破电动车来到学校,经常拿着已停产的诺基亚发短信。没有抽烟的习惯。语文,中国文化的科目,之所以。遇到他感兴趣的话题,他总是扯得很远,很远。一道辨析题就扯到了自己身上
送走迎来的兄弟
我们是尖子班,刚开学的时候,人数总是一两的增加。可也还是送走了两个兄弟。陈锐,军训是就认识了的,一班走的第一个。似乎也是去了海口一个跟城南一样流氓的学校,不知道他现在是否还牵挂着一班,牵挂着一班的某位“漂亮”女孩。
“越南仔”,名字挺多笔画,拼音又很难找到,所以名字就不打了。被染过的头发,头发下一张长长的脸,不知道他总是打打杀杀的,总是说着带有“我村”开头的话,就想是他们村比定安的任何一个都好似的。怕事的我总觉得他很威武,毕竟穿着城南校服进出的是另一所中学,他走的那个晚修是“特大号猴子”送他回宿舍的,猴子说他半路就被人给扯下来打了。第二天就知道了班主任让他休学的消息。
周克涛,从九班来的,他的成绩——在九班也能进前50的家伙。大佬说:长一颗痔就是从乡下来的,长两颗就是过南渡江才到家的。这是没有根据的话,不过他不是一般的乡巴佬。看见一辆奥迪开过,——后面四个零(奥迪的标志)的车叫什么了?
一般的人
男生
大姥,么庄,小肥羊,符国芳,妖怪,老鼠,吴淑生,胖哥,胖四,班长。不知道漏了谁捏?反正也都是男生。——以下观点属于吴礼尉QQ1078539713个人观点。吴礼尉本人不承担任何法律责任
大佬,类似朋克的发型。跟他牛B的语言。虽然有点自恋。总是说一句话就惹得全班人大笑,奔跑。他的奔跑速度和体能都很好,我们来城南的第一届奥运会,三项都报满。初赛,决赛。初赛,决赛。初赛,决赛。他把跑钉鞋换来换去。
校运会。我悲哀的跳高——班主任为了充数。把我给报了上去,结果不出我所料。。。连最低高度一米一都没跳过。
妖怪。1班的笑星之——耍老师的学生。他的成绩与他的身材仿佛呈反比
胖哥。乐观的孩纸。遇到一点事就大声笑————跑了一千米之后又喘气一千米的人
胖四。资深网迷——飞车120级。少尉6。
班长。体重!150。好孩纸的模样。似乎连打架也是
吴礼尉,虽然是组长,可几乎从不交英语作业
女生
一班有个画画很好的女孩叫陈言叙,黑板报都是她画的
一班有个力气很大的女孩叫陈香言,校运会投掷项目都报了。听说铅球第一名
一班有个英语天才叫符怡,每次英语考试都是第一
以上是去年的原文。接下来是变化的
1.班牌变了,由七(1)变成了八(9)。
2、人员的变动,去年日志里写的人已经走了,大佬,老鼠,林资礼,程子仙,周克涛走了。来了的:冯庆圆,吴媛媛,蔡秋旧,陈小玉,王嫘,莫兴业,符椿。貌似造成男女比例不均衡了。欢迎新同学。
3、班主任换人了。林书英是谁啊?哦!我知道了,她不就是我的网游飞车上的那只小宠物么?不想多介绍我的新班主任。前任班主任莫贤富赴侨中学习一年。不管走前还是走后,都很关心我们。初一下学期末,他说他要去XX名牌中学任职。他语重心长的提醒了我们好几天。说他所能做的,就是给我们向学校要求一个英语班主任,还叫学校那照相来拍了张合影,那时我还跟我同桌还不信他要走这件事。
初二报名那天,在外面吃早餐,又看见他骑着破电车来学校了。一起吃早餐的胖四调侃说:他去海口任职这么快就回来了啊。等吃完早餐去学校,他居然给我们介绍说那是新班主任。呵呵,这次他没有骗我们,他真的要走了。在走之前的暑假还给我们落实了贫困生补助的事,走之后还在班里的群问候我们班同学,确实这样的班主人已经很好了。不像我的某某宠物。
4.学校很重视我们尖子班,去年所说的没有专用的多媒体教室,今年已经有了。今年我们的晚修多了一节。400米的跑道,已经变成工地好长一段时间了。
5.在去年日志里说的人物,有所变化。
胖四的飞车已经133级了。英语最好的符怡不知道什么原因已经成了全民攻敌。在最近的一次考试中,张跃已经不是以往的第一了,而是新来九班的冯庆圆,尽管这样,但是本人我,每次考试还是排在冯庆圆前面的。(其实是考试时的坐位)那位打嗝的政治老师已经因为生病好久没有在学校露面了。还有,去年写班长徐恩裕的体重有点夸张了,今年的他的体重就不要公布于众了哈。生活水平提高进,前任班主任的诺基亚已经换成安卓了。
没有变的还是有一些的。
1.自习老师,电脑老师体育老师也没有变,体育老师是那个超无聊的年级主任。整天拿赶出九班来吓人的。
2,还是原教室。
3、我们的友情。
这一年,我们班来了两位美女过客,两位实习老师。我们相处的时间只有两个月,--黄赛,郑伟妃。
待续。2013年2月6日 11:56:34。
[L]青春是人生的实验课,错也错的很值得。前面的有语病就不改了。
PS:手机端编写,自然段前空两格就没有做到。不好意思了、
最后一年,学校又把班号给换了——“九(8)班
”很庆幸,很庆幸我的宠物没跟上来教初三。很遗憾 ,很遗憾初一的班主任由于工作安排的原因不能回来任教我们初三。so,我们初中三年换了三个班主任。
旧事重提,老师说:得人心的老师也是领那么些薪水,不得人心的老师也是得那么些薪水。没错!说不定没师德的老师的薪水更高呢——拿师德换的。不过我相信,不会高太多的,因为师德本来就不多嘛。。我们学生对于不好的老师也没有扣您薪水的能力, 只不过跟学生关系好的老师走在街上更多学生打招呼罢了,打招呼的能力我还是有的。敲键盘的能力我还是有的。真希望借你吉言班里面的同学一定会有人当guard。guard如果能热爱自己的职业,没愧对自己的职业。足矣!谢谢您举得例子让我一辈子都记住了这个单词。所以我见了您还是会打招呼我一个十几岁的学生可能做不到客观的评价一个人,做不到客观的评价一个老师有没有师德。倘若多年后我终于明白了你的苦口婆心,那就当全班52-1位年少轻狂的同学近视眼吧![/L]
“1”是怎么回事?“1”也就是初一时候文章里写的英语代表,一个英语极好的人。由于种种原因成为了班里的全民公敌。至于什么原因那我就分析不了了。可能是因为人家把班里面一些事情抖出来了而已。哈哈。
新学期刚刚开始,对新童鞋新班主任了解不多。待续~~
2013年9月15日
我们忙碌的初三
这个学期发生的事太多,突然不知道从哪写起,也许是因为之前想写的太多又因为太忙而没有动键盘的缘故吧 !
忙碌的初三,改变了我们太多,最明显的就是符椿知道学习了,每天一回家就碰电脑的我到周末才玩了。还有很多人在改变。你在变,我也在变。我们变得充满正能量,所有的奔忙只为了明年六月的一纸书信。
刚开学的时候,听同桌说符椿每天下晚修都会在教室里自习到十点多才回去,刚开始我不相信,但过了几天我也留了下来。因为——我一回家就爱玩手机。
八班的老师
新班主任是林朝燕,对我不错,我觉得她对其他人也很好,对学生很严但是又没有那种我所认为的“蛮横”。首先主观上我觉得她很好。像初二时候那样一个全班男生都讨厌的班主任,也有极少数女生人喜欢。总会有不同观点的嘛!我也懒得拿两个班主任来对比,虽然我做过这类事。刚开学的时候,我看见前班主任想打个招呼,当时我想,打个招呼没啥,就算曾经那么讨厌她,现在她也不能再罚我去跑圈对我大吼了,该过去的总要过去。可是被人家无视了,装看不见,第二次,第三次。再后来我就跟全班男同学说,见她不要打招呼了,没想到我得到的回复却是“谁想跟她打招呼,你以前跟她闹得那么凶你也打招呼啊?”
林老师已经教了很多年初三,据说咱们班的七科班主任除英语老师之外的六个老师,都跟她合作了很多年。她说出这一信息给我的感觉就是,这群老师也跟IT业的开发团队一样。还有就是八班的七科老师,五个老师是学校门口展出的“优秀教师一览”里的优秀教师。 这真是学校对咱们尖子班的优待啊!
物理老师是个中年愤青,估计都把课本背熟了,每次来上课都不带课本的。可能正因为如此,他上课老爱扯淡,不过物理化学每节的内容都不多,又很简单,倒是没有影响教学进度,每节课都觉得很轻松。一个人在日常生活中接触某类事物多了,在与他人闲聊的时候就会不知觉的显露出来,就像物理老师讲的课堂题外话一样。总之我觉得他知道的真多,被他扯到的话题差不多有这些:名车,国产车,中国人用盗版windows,一些计算机常识之类的,还有大美利坚,国人素质等等。当然每次当他扯关于国人素质的时候总不能说多久的,我会想办法让他停下来,其实这真的没什么好说的。谁都这样,小孩没素质也是受大人影响的。要是谁都教好自己的孩子不带孩子“跨栏”。那就不会有那么多问题了,可是想想,谁都是迫不得已。
化学老师跟数学老师年纪差不多,都是年过花甲的老人,都是有孙子的了。像化学老师那样七十年代的大学生才是令人佩服的杰出人物。据说数学老师是前任校长。乔布斯说,”工作将是人生中很重要的一部分。如果你还没找到真正喜欢做的事,接着寻找,别妥协。“因为只有从事自己热爱自己的职业,才能坚持那么多年而从来没有抱怨的心态。他们年轻时候的业绩令人佩服,年老的时候依然热爱自己的职业也令人佩服。倒是有的时候年轻老师却抱怨更多。
也许因为数理化是我喜欢的科目,所以在我看来其他老师没有什么特质好写的,不过八班的其他科老师确实也很好。今天就到这。
2013年11月30日
---
layout: post
title: 当我自我感觉良好的时候
date: 2013-10-24 20:00:00 -0400
tags:
- 生活
- 自我成长
---
2013-10-25-当我自我感觉良好的时候
这篇文章最早发表在QQ空间
当你自我感觉良好的时候,有可能是你被笑得最惨的时候。
就好像我正在写日志,灌输我的观点,也会有人笑而不语的。等等一些事情也总会有人在笑,那只是因为观点不同而发出的笑声。如果追寻自己的心,发出的嘲笑声,那真的没什么可介意的。嗯,就这样。我认为每个人都应该追寻自己的心,去把你的内心的声音发出来,去做你喜欢做的事。那样一定会有人暗地里笑你。经常想起自己会在几十年后的一天死去,生前受到的嘲笑与赞扬,都会消失;也就不会害怕他人的嘲笑。有时候这就好像试新衣服的时候被家人笑还是穿出去被很多人笑的问题。尽管你不需要过多的嘲笑,但你需要被嘲笑之后成长的自己。你也需要有一个能经得起众人嘲笑的梦想。断章取义引用beyond的一句歌词:风雨里追赶 雾里分不清影踪,天空海阔你与我可会变,多少次 迎着冷眼与嘲笑,从没有放弃过心中的理想。——《海阔天空》
跟风狗
谁都是要跟风的,要不然我们也不会用筷子吃饭,只是如果你今天刚学会用筷子吃饭下个月就去学用刀叉吃饭。我只想说。“你赢了”。零零后的孩子(因为人类进步太快,所以请允许我称最多小我十一岁的人为孩子)跟风去追男神女神,一个星期就多一位男神。我们救不了这些孩子。打个比方,正常人就是早期的只能一次性擦写光盘,感觉好了,有了喜欢的东西,也就擦不掉了。而跟风狗,就是随着科技的发展出现的新型可重复性读写的存储器,容量也更大。例如有的人可以大言不惭的说“我爱XXX一生一世”,“XXX明星是我的信仰”然后呢,重复说了N遍,就是不带重样的。
观点容易被他人左右的人是悲催的,喜欢刷空间的人,看见空间里太多人吐槽数理化很难,女生说脏话,抽烟喝酒只是不装纯。便自暴自弃。1024表示十分值得惋惜。
我知道我的精力金钱时间都是有限的,喜欢X件事物或人,就会对每件事物或人付出X分之一的时间精力金钱,喜欢的东西或人越多,每份就会变分的越少。不过人跟人是不同的,那些跟风狗也许有更多的时间精力,这跟古代有钱人三妻四妾一个道理。什么时候你找了个跟风狗对象。那我绝对会送上我最真挚的祝福!
好了,我终于说完了跟风狗,有时间再谈谈装逼党。也许我以后会变得跟他们一样,到时候你们再揪出我十五岁写的文章来笑我好了,我觉得应该没那个必要。不过估计也不可能,毕竟一次性可擦写光盘是几乎不可能改造成可重复读写的存储器的。我还是很希望你们能留下评论——1024
---
layout: post
title: 不相信例子,你独一无二。(写给自己的话)
date: 2013-06-25 20:00:00 -0400
tags:
- 生活
- 自我成长
---
2013-06-26-不相信例子,你独一无二。(写给自己的话)
30年前,我以一挑亿,跑赢了其他所有的精子,那么我必然生来就是牛逼的——韩寒
你跑赢所有精子来到这个世界不是为了跟脑残吵架,也不是为了挣够钱让大部分人羡慕你,更不是为了赢得所有人的赞同。而唯一的目的就是——生来为了做自己喜欢的事情
支持你的人可能跟你一样傻,当所有人都支持你的时候你也不一定是对的。所以你也没必要赢得所有人的支持。
这个世界没有对与错,所有人都会认为自己现在所做的事情是对的,所有人都可以理解现在的自己所做的事情。跟你作对的人也一样。当你认为你是对的,你就必须坚持自己,如果有人让你意识到自己的错误,也要感谢那些让你知道错了的人
亚里士多德认为各物体只有在一个不断作用着的推动者直接接触下,才能够保持运动。根据亚里士多德的说法,“真空”是不能存在的,因为空间必须装满物质。这样才能通过直接接触来传递物理作用。 后世的物理学家牛顿指出了亚里士多德这一论断的谬误,指出了“力不是保持物体运动的直接原因。力只能改变物体的运动状态。”可以说,在牛顿经典力学体系的大厦没有造起来之前,整个西方世界都被亚里士多德的物理学统治着。虽然牛顿后来证明了亚里士多德的说法是错误的,但是亚里士多德的年代,他就是对的。——判断某件事对与错需要加上时间限制。不过有一种行为不管在那个年代,都必须是错的,都遭人唾弃。那就是,不孝敬父母。
。
不要相信例子
不要相信例子,给你举例子的人是为了达到他想要的目的。长辈为了说服你好好读书可以举N个学业有成并取得成功的人的例子。但是希望晚辈能好好读书一点也没错。要是举出退学了还成功的例子也大有人在。乔布斯,比尔盖茨,韩寒。很显然,乔布斯退学之后旁听了里德学院当时堪称全美最好的书法课,以至于后来苹果电脑有如此美妙的字体。他晚年回顾,最不后悔的事就是没读完大学。当然退学了无所事事的人也有很多。
可能会因为身高问题以后不能打职业篮球又能怎么样,你在做自己喜欢的事情,你生来就是为了做自己喜欢的事情。只不过业余篮球与职业篮球的区别在于你的战靴,需要自己掏钱买,职业篮球则相反。因为大多数人都会考完成学业取得成功,极少部分人会好好利用退学的时间从而取得赢在起跑线上的绝对优势。我的朋友提醒过我要注意两个对立的例子之间的比例问题。这一切源于你心里相信什么。你相信你会像大多数人一样完成学业取得成功,或者你像韩寒与乔布斯一样自命不凡,认为自己不会走他人的老路。这也都没有错。
人不能跟动物一样,活着只为了繁殖后代。
在本文结尾想想,活着就一定要奔向成功么?也不一定。其实只需要混个文凭找份工作然后娶老婆生孩子再努力挣钱把孩子拉扯大就安详的死去就OK啦!可是这不是生物课本上所说的鸟儿的一生一样了么?求偶,交配,筑巢,产卵,孵卵,育雏。但你是人啊!
就算多年之后你变成庸庸碌碌上班挣钱养活老婆孩子的人也没关系,至少十五岁的你是这样认为的。
2013年6月27日
---
layout: post
title: 生命里的盛夏
date: 2012-06-16 20:00:00 -0400
tags:
- 生活
- 青春回忆
---
2012-06-17-生命里的盛夏
写于2012年6月,那个时候我14岁,还在上初中,很喜欢打篮球。
在未来,那里有我们生命的尽头。那些憧憬着美好未来的人们,可曾想到过。在我看来,那些期盼未来的人们,无谓就是盼着早点死
对于死。我很害怕
外婆陪了我一年半
爷爷陪了我两年
外公陪了我12年
而我,今年14。我的心脏从一出生就跳动着,我的心脏跳动了14年。
14年了。一个婴儿变成了一个少年,那些认识我的人啊,你们可曾记得我的变化。你们可曾知道我长大了。随着我长大了,你们也都一起长大,一起变老,有的老人悄然离去,对于在各个阶段的我来说,都是巨大的悲痛。
从一岁开始牙牙学语,我的嘴巴讲了13年的话。从两岁开始走路,我的双脚走了12年的路。从三年级学英语,我学了4年的英语。从四年级打篮球,我的双手打了3年的篮球。
3年了,多少个朝阳在球场等我。我又送走了多少个夕阳。在篮球的道路上。我一直都一帆风顺。至少,我在懵懂中坚持了三年。至少,我不曾受过很大的伤。
在我的菜鸟时代,我就遇见了三群人。
一群是在工作之余打篮球的成年人,他们也许和我一样,不!是我和他们一样,在学生时代怀揣篮球梦想。然后又觉得梦想是如此般遥远,那个CBA是多么的遥远啊!于是就在街头度过了职业生涯。尽管他们不是职业的高手,自但他们十几年的球龄,是不容小视的。他们有的人在大公司工作,能参加公司的篮球队,就能享受一下有裁判的正规比赛,还有啦啦队的加油助威,是我何等的羡慕。
还有一群是与我现在的年纪相仿的(3年前,我4年级,他们初一)由于他们也在不断地进步中,所以他们对我没有丝毫的高傲。都很耐心的教我一个一个动作,尽管现在我还是球技平平。但我仍会感谢他们教我的东西。现在在球场见了他们,我会万般惊喜的向他们跑去,像个孩子见了妈妈。因为现在他们现在穿上了不同高中的校服,有的也不在定安,他们能在一起打球时很少见的。
还有一群是和我一样是菜鸟的人。我们的习惯都是打半场球。一个球场的一半是那群少年,还有一半是那些成年人。我们总是为了没球场而发愁。我们会在下午两点多(地理课本中说的当天的最高温)烈日当空练球。练到那些大人们下班,我们也该休息了。坐在球场边的长椅上,看着球场的两边不同的精彩时刻。
对于那个十五层楼下压着的球场,我有很深的回忆,尽管我只在它的背上跳过了一个春秋和冬夏。但那是我的篮球开始的地方。我从前天真的“计划”着己的篮球的道路,先打校队,然后再打CBA,就能进入国家队,最后就能像姚明一样风靡全球了。
当然,那是无稽之谈,在海南历史上还是没有过的,海南连一支正规的CBA球队都没有。我当时也不知道,姚明,易建联,等那些著名的球员们,他们在我这个年龄,已经长得比我爸还高了。
其实,我的梦想可以不要那么遥远。因为梦想只是一种职业。是有商业目的的。我也有父辈们为我铺下的道路,凭着我三个叔叔在车站工作的人脉。在我成年时,我只需要一本小小的驾照,就足以养活我自己或许还有我的家人。然后像老爸一样,碌碌的领着退休金度过此生。
现在,正值盛夏。我正在读初一,正在面对着七课功课。正在为了留在一班而跻身前一
百名,偏科是我们共有的问题。生物,我最恨的科目。刚开学的时候,我就认为,生物这个科目研究的就只有那些有关性的东西。生物课我也没多听。尽管我错了,生物是研究生命的科目,而并不是那些变态的关于性的科目。初一第一学期的段考,有历史陪着生物不及格。556分。我到现在还记得,那是我来城南的第一次考试。我没有安于现状,但生物,我真的是很讨厌,第一学期的期考,说到我来城南的第二次考试,我崩溃了。我的生物只考了18分,这回好了,六科都几个了,生物我一点都不会。说实话,我那次的确把班主任给气爆了。我敢保证的说,班主任要是看了我的试卷,那我可能会吃不完,打包走。我在所有的选择题上都写了A,其他题一道也没写。苍天啊。大地啊。为什么那次考试是A的答案那么少呢?一道题3分,这么说我才对了6道。
我们班大多数的人偏的都是英语。我的英语成绩很好,但不是110满分就考100分以上那样,只是在班里就算好一点。对于英语老师发的那些格子小小的报纸试卷。我都不屑的做,有时候会两道大题都没做。这算是我的一点宣泄吧,因为那些格子对我来说实在太小了。我写的字不是一般的大。而且,我最爱的科目,历史。历史的晚修总是被英语老师拿来测试英语。但我对单词真的很有灵感,单词表的单词我总是把他积得很多再记,用几分钟就能记一个topic了(我不敢保证一辈子都不忘)
我知道,我们学习每一个科目都是为了把分数加到总分上,可我偏的是生物。生地会考不过关,什么都是浮云。所以,我必须逼着自己学生物。可是我又觉得,我逼着自己学生物,不就是为了生地会考吗?为了生地会考,再为了高考,然后大学毕业找个好工作,取个好老婆。最后就能安然的死去了。
我对我们学习的科目,我有我自己的见解,我们学习就是为了考试,有的数学题超前的出得很深奥,我们傻傻的在那里想,可是。这些题人家会考吗?语文的一些单元活动,有的老师拿一节课的时间来开一次辩论会,最后就是为了让你写一篇作文。对我来说是极其无聊的。
我的英语老师就是很现实的人,她是这么说的:“你们回家根本不可能学习的,家里有电脑,电视等更多吸引你的东西,在课堂上你都不学,你回家怎么可能学习呢?”我们没有人敢向老师承认,我回家练书本碰都不碰。但英语老师就是这样说的,她总不可能去你家看过吧。对于周末的安排,我的日程里是这样安排的:下午如果下雨的话就在家里写作业,嘎嘎。同是尖子班的二班比我们一班的成绩好的很多,我们就会说他们作弊。英语老师说,人家放水你又没看见,你们不要再这里乱说人家,回去用工背单词比什么都好。
我对自己是如此的放纵,这跟我喜欢的篮球有很大的关系。篮球本来就是一项自由的运动,就好比有的人明明知道上QQ无聊还要为了剩下的流量而在网上泡。对英语单词一窍不通也硬要徒劳无功的背单词。我极少逼着自己做一件事。这可能是一种骄傲。爱迪生说过——我的一生从来没有工作过一天,我每天都过的其乐无穷。对啊。本来就是这样,状态不好就下场,然后躺在长椅上看辣酱,听音乐,我喜欢篮球,所以我也不会逼着自己练球。我喜欢学习,所以我绝对不会逼着自己学习。老师总说,作弊抄来的答案印象不深刻。但我觉得,冒着被收试卷的危险弄来的答案难道会不深刻吗?就好比那些打彩票的大人,他们如果认为抄来的号码不真实而不打的话,那谁都会说他是傻子。说实话,我有时候很讨厌某位老师,但我知道,我学习他教的科目不为了他,绝对不为了他。
我讨厌我的体育老师,他就只会那些三角猫的功夫,今天教足球,明天又教排球。教的都不像样,总喜欢拿自己年级长的官位压人,动不动就说要把我们赶出尖子班。我们上体育课就是想玩得开心一点,对于三年后中考的体育,我才不在乎,我的长跑很好。他应该是城南中学最喜欢装B的人了,家离学校两公里还买一辆破东风,拉风的要命。
好了,在暑假将到来之际,我的盛夏告一段落了。
2012-6-17
